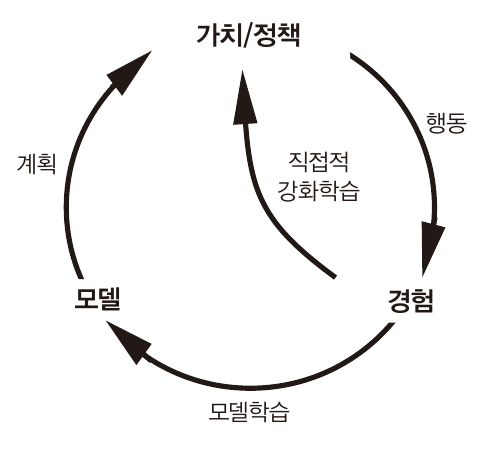
시간차학습은 강화학습에서 모델이라고 부르는 p(s',r|s,a)를 사용하지 않는다.
동적프로그래밍 방식은 모델을 이용하여 학습한다.
시간차학습 도중에 모델을 학습하는 방식으로 위 둘을 통합할수 있다.
모델의 종류로 각 가능성에 대한 확률을 제공하는 분포 모델
모든 가능성 중에서 확률에 따라 하나의 가능성을 제공하는 표본 모델이 있다.
행동을 통해 경험을 만들고 이를 이용하여 학습하는것을 직접적 강화학습이라고 하고
경험을 이용하여 모델을 학습, 이를 통해 학습하는것(계획)을 간접적 강화학습이라고 한다.
이를 이용한 학습 알고리즘으로
p(s',r|s,a)를 기억,
직접적 강화학습을 한번 할때마다 간접적 강화학습을 n번 하는 방법이 있다.

n에 따른 성능을 비교할 수 있는 코드이다.
https://github.com/nrye4286/reinforcementLearning/blob/main/planning_nDifference.ipynb
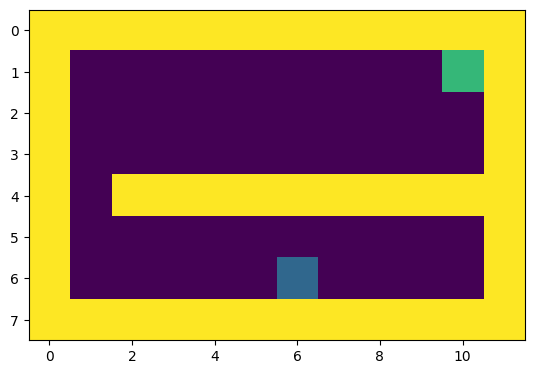
파란색지점에서 출발, 초록색 지점에 도착할 시 1의 보상을 얻는다.
하나의 시간단계마다 상하좌우 1칸씩 이동할수 있을때 시간단계당 누적 보상을 그린 그래프이다.
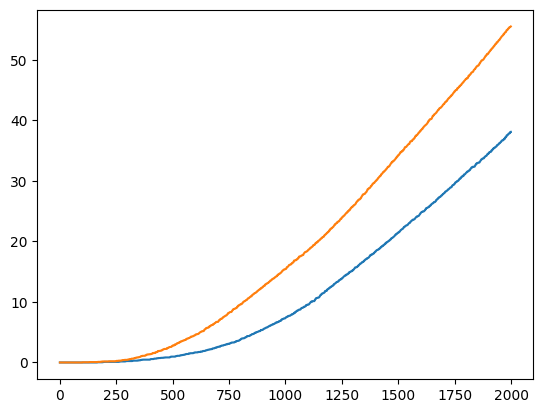
파랑: n=5, 주황: n=20
시간단계당 누적보상을 보여준다.
최적정책을 찾았을 시 기울기가 수렴하는 모습을 보이는데,
n이 클 시 더 빠르게 수렴하는 것을 볼 수 있다.
사실 하나의 시간단계당 n번 더 계산하는것이라 이 실험에서는 속도면에서 월등히 뛰어나다고 판단하기는 어렵다.
하지만 실제 표본을 획득하기 어려운 상황에서는 위 방법이 효율적일 것이라 예상된다.
환경이 변화하는 미로 예제
환경이 변화하는 문제에 대해 모델을 이용한 강화학습을 적용해 보았다.
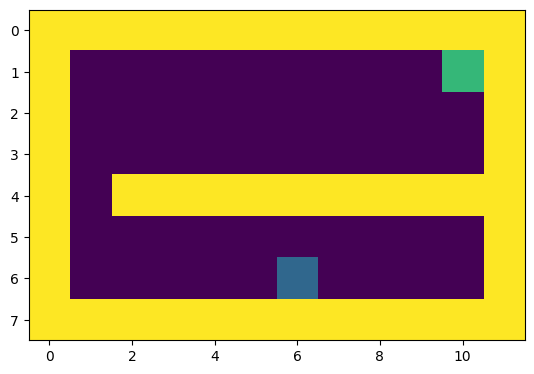
파란색 구역에서 초록색으로 가도록 학습을 하는 도중 오른쪽에 지름길이 생기게 된다.
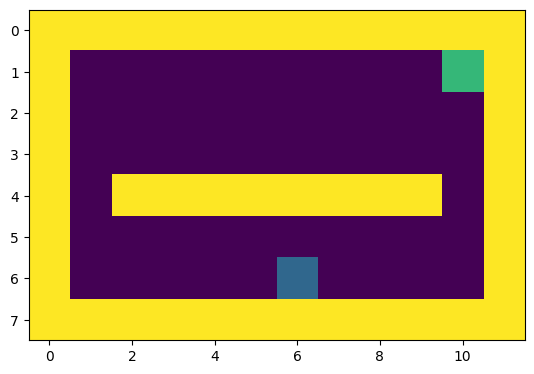
지름길을 찾기 위해서는 탐험을 연속적으로 해야한다.
탐험의 확률을 낮게 설정했기 때문에 일반적인 방식으로는 지름길을 못찾게 된다.
모델을 이용한 간접적 강화학습단계에서 시도한지 오래된 상태, 행동쌍에 대해 추가적인 보상을 주는 방식을 이용하는 방식으로 해결 가능하다.
안한지 오래된 상태, 행동쌍이 큰 가치를 갖게 되고 이를 수행하기 위한 연속적인 상태, 행동쌍들까지 하도록 장려할 수 있다.
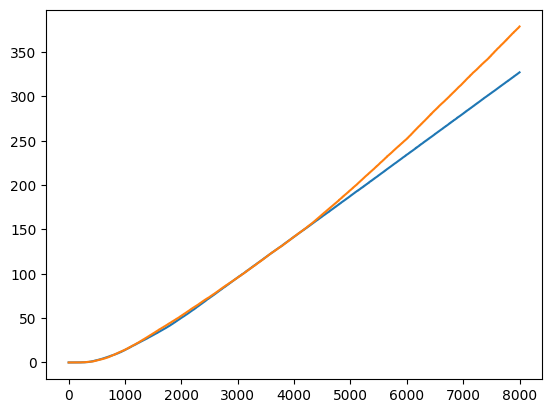
(3000시간단계에서 지름길이 생김)
주황색 그래프가 위를 적용했을시의 모습이며
시간단계당 누적보상을 보여준다.
https://github.com/nrye4286/reinforcementLearning/blob/main/planning_newWay.ipynb
단순히 위 알고리즘만 적용하게 되면 성능이 오히려 떨어지게 된다.
위 알고리즘을 적용하지 않았을 시에는 첫번째 에피소드, 즉 첫 보상(목표지점 달성)을 얻기 전까지는 모든 상태, 행동쌍의 가치가 0이며 이에 따라 랜덤하게 행동을 선택하게 된다.
하지만 위 알고리즘을 적용할시에는 했던 행동만을 반복하며 첫 보상을 획득하는 시점이 매우 연기된다.
간접적 강화학습은 했던 상태, 행동쌍에 대해서만 진행되기 때문이다.
따라서 첫 에피소드에서는 위 알고리즘을 적용안하는 방식으로 해결하였다.
그리고 시간단계마다의 간접적 강화학습의 수에 따라서도 성능이 좌지우지 된다.
5, 20, 50번까지는 성능이 오히려 안좋은 모습을 보이다가, 100으로 늘리니까 안정적인 모습을 보였다.
