미리 알아야 하는 지식- MDP, 정책, 가치함수 등 강화학습 기초
모든 상태 s에 대해서 아래 수식을 만족하면 π'는 π만큼 좋거나 그 이상으로 좋다고 말할 수 있다.
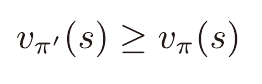
어떠한 정책π 의 가치함수를 안다면 그 가치함수에 탐욕적이도록 하는 새로운 정책π'을 찾을수 있다.
위 π'은 기존의 π만큼 좋거나 그 이상으로 좋음이 보장되며 이를 정책 향상 정리라고 한다.
원리
qπ는 특정 상태에서 특정 행동을 한 뒤 다음상태부터 정책π를 따를시의 가치를 나타낸다.
특정 상태에서 qπ에 대해 가장 큰 가치를 가지는 행동을 택한뒤 π를 따를시
그냥 π를 따를때보다 좋거나, π를 따를때 만큼 좋음은 자명하다.
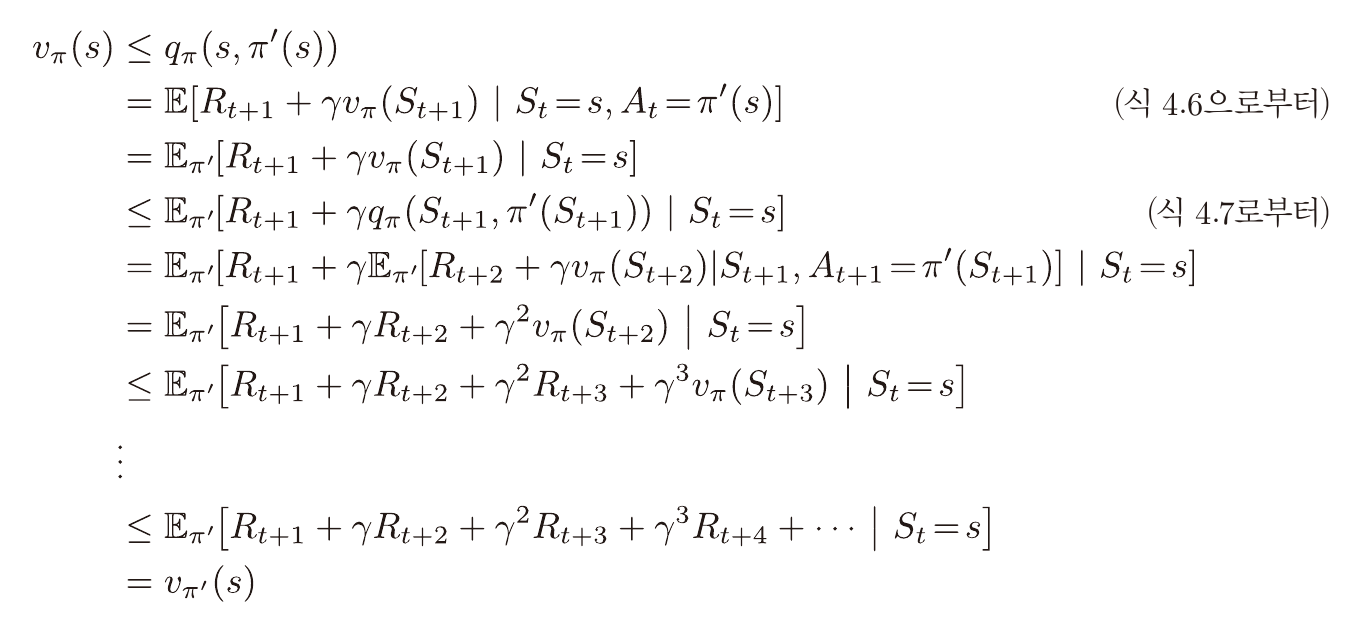
위 원리를 반복 적용 할 시 위 수식과 같이 표현이 가능하다.
정책 반복
정책을 정의 한 뒤,
정책평가(가치 근사) -> 정책향상
을 반복하는것을 정책 반복이라 부른다.
이를 반복할 시 정책과 가치는 최적으로 수렴하게 된다.
정책평가는 다양한 표본 및 많은 계산을 통해 이루어지기 때문에
정책반복에는 많은 시간이 소요된다.
가치 반복
위 단점을 극복하기 위해 나온것이 가치 반복이다.
정책을 처음부터 가치에 탐욕적이도록 정의하게 된다면
가치 근사가 업데이트 될 때 마다 정책 향상이 이루어지는 것과 유사한 효과를 내게 된다.
이를 반복할 시 정책과 가치는 최적으로 수렴하게 된다.
