DP방법은 모델 p(s',r|s,a)를 알고있을때 사용 가능한 방법이다.
이를 모를때에는 몬테카를로 방법을 사용할 수 있다.
문제
동전을 던져서 앞면이 나올시 배팅액만큼 벌고,
뒷면이 나올시 배팅액을 잃는 게임이 있다.
지민이는 100원을 벌어야 한다.
앞면이 나올 확률이 0.4라고 할 때
현재 가지고 있는 금액에서 얼마를 배팅하는것이 좋은지 정책을 마련하라.
방법
- 100원에 달성할시 보상을 1로, 그 외 나머지는 0으로 설정해준다.
- 가치반복을 이용하여 임의로 설정된 가치함수를 최적가치함수로 수렴하게끔 해준다.
- 가치함수를 이용하여 탐욕적 정책을 찾는다.
가치반복을 이해하기 위해서 정책평가, 정책향상, 정책반복을 이해해야 한다.
정책 향상 정리 링크
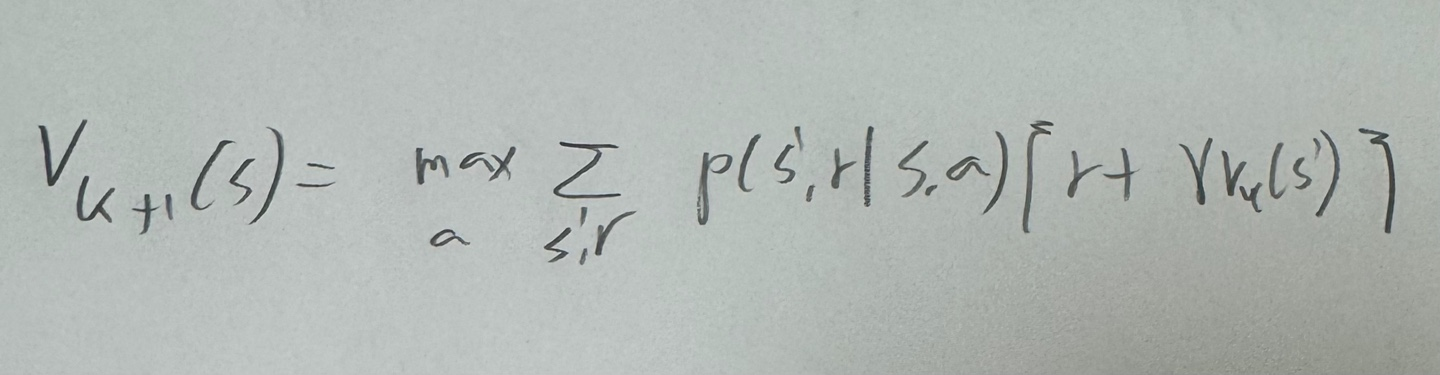
각 상황에서 가치함수를 탐욕적으로 이용할때의 가치함수이다.
각 상황에 대입해서 가치함수를 업데이트 해주면 이는 최적가치함수로 수렴한다.
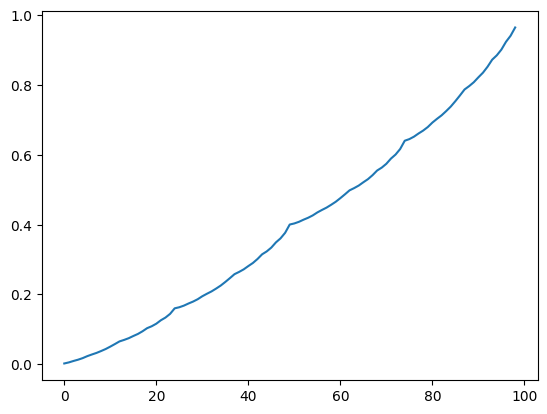
위 그림이 아래 코드에 대한 결과이다.
https://github.com/nrye4286/reinforcementLearning/blob/main/23012103_%EC%9D%B4%EC%A7%80%EB%AF%BC.ipynb
번외
어떤 문제에 대한 최적정책은 무조건 하나 이상 존재하며, 그들은 동일한 최적가치함수를 가진다고 했었다.
이 문제를 풀며 직접 확인할 수 있었다.
위 함수값이 최댓값인 배팅값을 선택하는데, 값이 같을경우 더 작은 베팅값을 plot시킨 그래프이다.
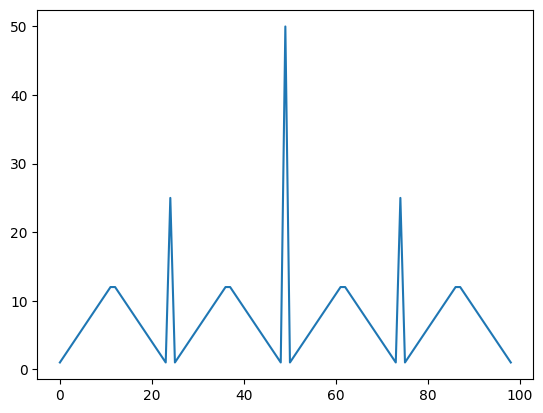
하지만 더 작은 베팅값 조건을 빼버린다면 아래와 같은 그래프가 그려진다.
특정상황에서 최적행동은 어러개 존재할수 있다는 증거이다.
26원일때 1원과 26원 모두 최적행동이다.
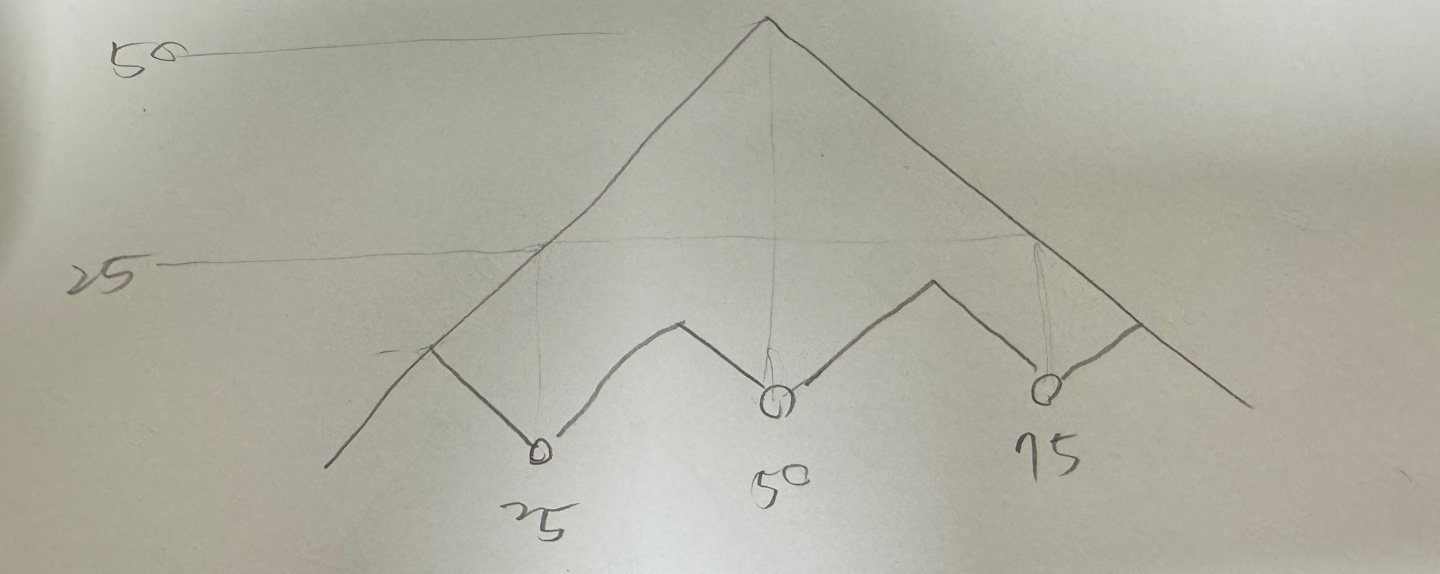
가능한 최적행동을 겹쳐보면 이런 그래프일것으로 예상된다.
번외2
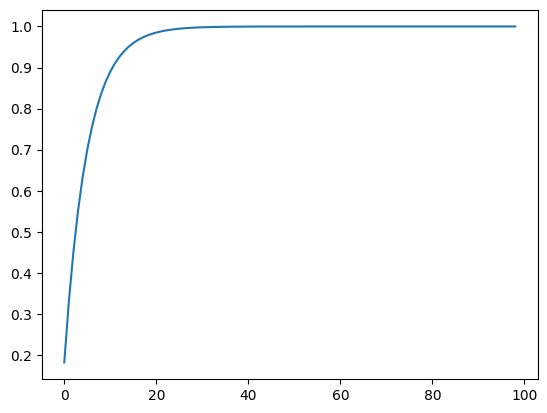
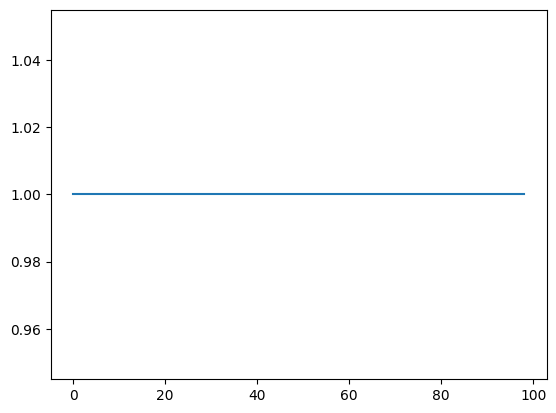
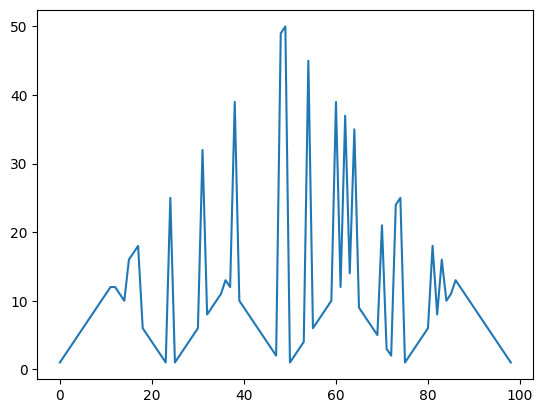
앞면의 확률이 0.55일시의 그래프이다.
0.5를 초과할 경우 1원씩 베팅을 하게되면 대수의 법칙에 따라서 100원에 도달할 확률이 높기 때문에 1원이 최적정책으로 뽑힌것 같다.
하지만 이는 최적행동 중 낮은 배팅값을 plot한 그래프이므로 다른 배팅값또한 최적행동일수도 있다.
