시작하기에 앞서
- 본 포스팅은 2024년 1월 2일부터 1월 29일까지 진행되는 LG Aimers 4기의 온라인 교육 내용 중 하나인,
Machine Learning 개론 - Introduction to Machine Learning강의를 수강하며 공부한 내용을 정리한 포스팅입니다. - 출처가 명시되어있지 않은 이미지들은 LG Aimers에서 제공한 강의 자료로부터 발췌한 것임을 밝힙니다.
- 강의에서 언급한 내용 모두를 다루지는 않고, 기억에 남았던 부분을 위주로 정리하였습니다.
AI, ML, DL
 Source: Difference between Artificial Intelligence, Machine learning, and deep learning
Source: Difference between Artificial Intelligence, Machine learning, and deep learning
- 위 그림처럼,
AI>ML>DL이라고 생각할 수 있습니다. AI가 가장 넓은 범주의 개념이고, ML은 AI에 속하는 한 분야이며, DL은 ML에 속하는 분야입니다. - 본 포스팅에서는
ML이 무엇인지 알아보도록 하겠습니다.
Machine Learning
Definition
A computer program is said to learn from experience E with respect to some class of tasks T and performance meausre P, if its performance at tasks in T, as measured by P, improves with experience E. - Tom Mitchell
- 쉽게 말해서,
경험을 기반으로특정 작업에 대한성능을 높이기 위한 과정이라고 할 수 있습니다.
Traditional Programming vs Machine Learning
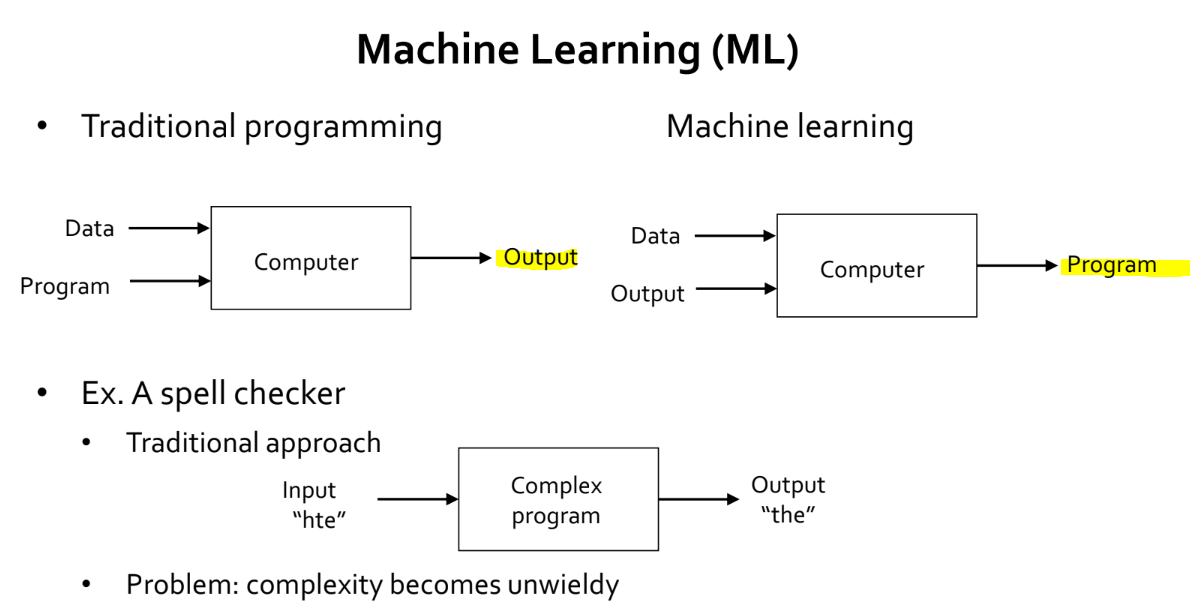
- 전통적인 프로그래밍과 머신 러닝의 차이라고 한다면,
입력과 출력이라고 할 수 있습니다. - 전통적인 프로그래밍은
데이터와프로그램이 주어지면, 그에 따른결과를 출력합니다. 반면에 머신 러닝은데이터와결과가 주어지면,프로그램을 만들어줍니다. - 여기서 프로그램을 만들어준다는 것의 의미는, 처음부터 끝까지 만들어준다는 것이 아닙니다.
프로그램이 이렇게 동작하기를 원한다와 같은 의도가 담긴프로그램의 형태 (Architecture, Model Class, Hypothesis Class)를 직접 설계하면, 해당 프로그램이의도에 맞는 동작을 하기 위해 필요한 값 (Parameter)들을 찾아주는 것입니다. - 붕어빵으로 비유를 하자면, 철판 (프로그램의 형태) 이랑 원하는 붕어빵의 모양 (데이터) 을 가지고 외주업체 (컴퓨터) 에 맡기면, 업체에서 해당 붕어빵을 만들 수 있는 틀 (파라미터) 을 만들어주는 것이라고 할 수 있겠네요.
Types of Learning
- 이번엔 학습의 종류에 대해 알아보도록 합시다.
1. Supervised Learning (지도 학습)
Given , learn a function to predict given .
- 를 입력 데이터, 를 정답이라고 했을 때, 주어진 에 대해 를 예측하는 함수 를 학습하는 것을 Supervised Learning이라고 합니다.
- 즉
(입력 데이터, 정답 데이터) 쌍을 기반으로함수 (또는 알고리즘) 를 학습하는 것입니다. - 지도 학습의 종류로는 크게
classification (분류),regression (회귀)가 있습니다.- Classification은 정답 데이터가
categorical (범주형, e.g., 개 / 고양이) 데이터입니다. - Regression은 정답 데이터가
continuous (연속형, e.g., 주택 가격) 데이터입니다.
- Classification은 정답 데이터가
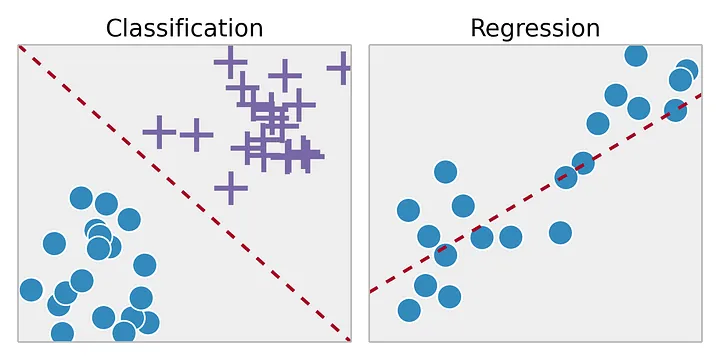 Source:
Source: 2. Unsupervised Learning (비지도 학습)
Given , find a hidden structure. (e.g, clusters)
-
Unsupervised Learning은 입력 데이터만 주어진 상황에서, 데이터가 가지고 있는 의미를 찾아내는 학습 방법론이라고 할 수 있습니다. (정답 데이터는 주어지지 않습니다)
-
Unsupervised Learning의 종류로는
clustering,anomaly detection,density estimation등이 있습니다. -
Supervised Learning과 비교한다면, 성능이 나쁘다고 할 수 있습니다. 주어진 데이터로 무엇을 하는 것이 정답인지 모르기 때문입니다. 사람으로 비유하자면, 문제를 풀기 위한 개념을 알려주지 않은 채로 문제집을 풀라는 상황이라고 할 수 있습니다.
-
다만 Unsupervised Learning의 경우,
정답 데이터 없이도 어느정도 목적을 달성할 수 있는 task인 경우가 많습니다.-
Clustering: 한국어로군집화라고 합니다. 데이터들이 어떤 집합에 속하는지 알아내는 것이 목표입니다. Clustering의 경우 데이터 간의 거리를 기반으로 군집을 파악하는 것이 가능하기 때문에, 정답이 없어도 목적을 달성할 순 있습니다. 다만 데이터가 어떤 집합에 속하는지 정답 데이터가 주어진 채로 학습을 완료한 프로그램보다는 성능이 낮을 수 밖에 없습니다. (Supervised Learning 보단 성능이 낮을 수 밖에 없다는 얘기입니다) -
Anomaly Detection: 한국어로이상치 탐지라고 합니다. 주어진 데이터 샘플에서 이상치 (Outlier) 를 검출하는 것이 목표인 task입니다. 아래 그림을 봅시다.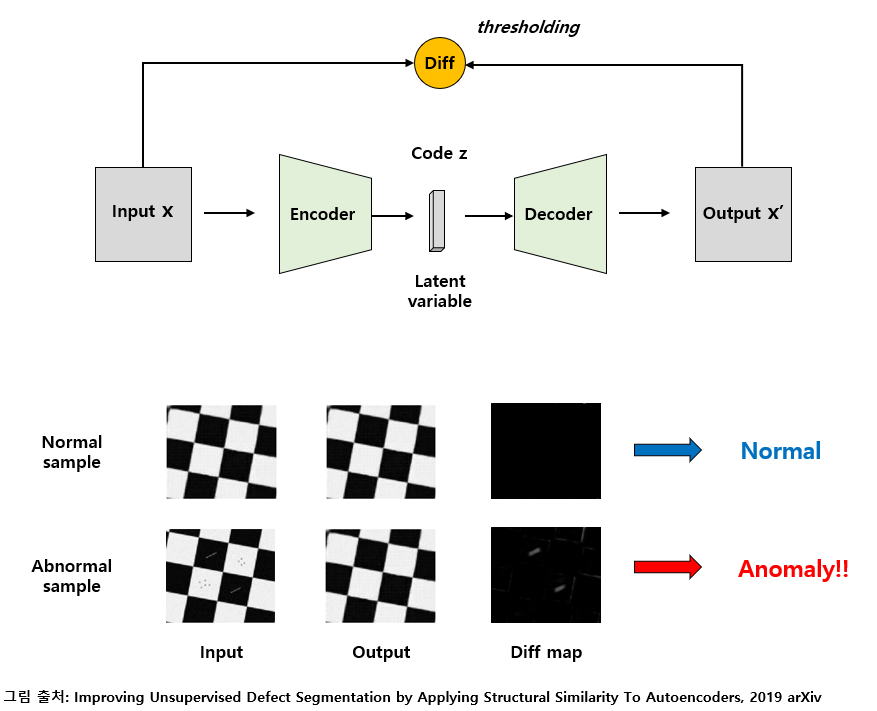 Source: Anomaly Detection 개요: [1] 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적용 사례 정리
Source: Anomaly Detection 개요: [1] 이상치 탐지 분야에 대한 소개 및 주요 문제와 핵심 용어, 산업 현장 적용 사례 정리
- 위 그림은
autoencoder기반의 unsupervised anomaly detection 방법론입니다. 주어진 데이터 속 대부분의 샘플이 정상이라고 가정하고, autoencoder 구조를 이용하여 원본 data를reconstruction하는 방식으로 학습을 수행합니다. - 학습 데이터에 정상 데이터 샘플이 더 많기 때문에, 모델은 정상 데이터를 정상 데이터로 reconstruction하는 방법을 학습하게 됩니다. 따라서 비정상 데이터가 입력된다면, 모델은 정상 데이터처럼 reconstruction하게 됩니다.
- 원본 데이터와 reconstruction한 결과 간의 차이를 보았을 때, 정상 데이터의 경우 눈에 보이지 않을 정도로 차이가 미미하지만, 비정상 데이터의 경우 차이가 뚜렷합니다. 이를 이용하여 이상치를 탐지하는 방법론입니다. (Supervised learning에 비해 성능은 좋지 않습니다)
- 위 그림은
-
3. Semi-Supervised Learning (준지도 학습)
-
Supervised Learning과 Unsupervised Learning 사이의 어딘가에 있는 학습 방식이라는 것을 이름으로부터 유추할 수 있습니다.
-
일부 데이터에 대한 정답만 주어지고 나머지 데이터에 대한 정답은 주어지지 않은 상황에서 모델을 학습하는 방식입니다.
-
Semi-Supervised Learning에는 두 가지 시나리오가 존재합니다.
-
LU learningLearning with a small set of Labeled examples and a large set of Unlabeled examples.
- 데이터는 조금, 데이터가 많이 있는 상황에서 모델을 학습시키는 방식입니다.
-
PU learningLearning with Postive and Unlabeled examples. (no labeled negative examples)
- LU learning과 유사한데, 데이터를 구성하는 에 오직 만 존재하는 경우입니다.
- LU learning의 예로는
binary classification이 있습니다. Binary classification은 한국어로이진 분류라고 하며, 분류 결과가 두 가지인 분류 작업을 의미합니다. - 예를 들어, 임의의 이미지가 주어졌을 때 해당 이미지가 개인지 고양이인지 구분하는 모델을 만든다고 해봅시다.
PU learning 상황이라면, 학습 데이터 속 개 이미지 일부에는 정답이 부여되어 있고 (positive label), 고양이 이미지에는 아무 정답도 부여되지 않은 것입니다. - PU learning 상황에서 모델의 학습 방향을 생각해본다면, positive label 쪽으로 overfitting 된다고 생각할 수 있겠습니다. 만약 그렇다면, 학습 데이터와 유사한 개 이미지가 입력됐을 때 개일 확률을 높게 예측할 것이고, 고양이 이미지가 입력됐을 때 개일 확률을 낮게 예측할 것입니다.
-
-
Unlabeled data를 학습에 활용한 경우와 활용하지 않은 경우를 비교했을 때, 전자의 경우가 더 좋은 성능을 기록할 확률이 높았다고 합니다. 왜냐하면, Unlabeled data는 서로 다른 data간의 경계를 더욱 정확하게 파악하는 과정에 도움을 줄 확률이 높기 때문입니다. 다음 그림을 봅시다.
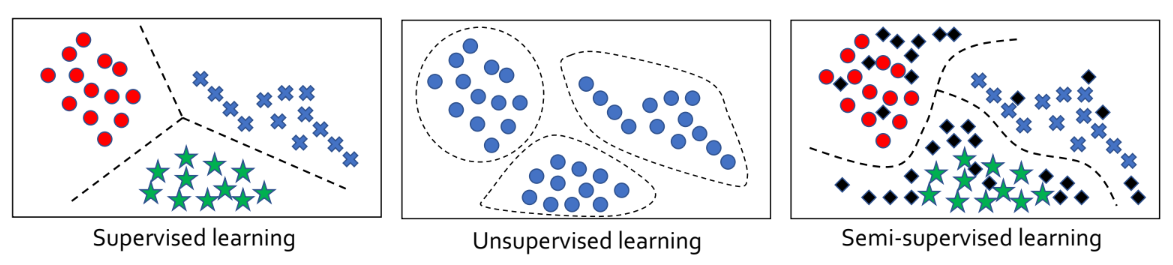
-
검정색 마름모 기호 (◆) 가 unlabeled data를 의미하는데요. 해당 데이터들의 실제 정답이 무엇인지 알 수는 없지만, 일반적으로 생각했을 때 가까운 곳에 있는 데이터들의 정답과 동일한 확률이 높을 것입니다. 그렇기에 서로 다른 데이터 (○, ☆, ×) 간의 경계를 파악하는 것에 도움을 줄 수 있습니다.
-
Semi-Supervised Learning 하면 대표적으로 떠오르는 것이
Pseudo-labelling (Proxy labelling)입니다. 아래 그림을 봅시다. -
Pseudo-labelling이란 한국어로
가짜 정답 달아주기정도로 의역할 수 있겠네요. 제일 먼저 labeled data를 이용해 모델을 학습합니다. 이후 학습한 모델을 이용해 unlabeled data에 대한 label (pseudo-label) 을 만들어줍니다. 마지막으로 labeled data와 pseudo-labeled data를 이용하여 모델을 재학습합니다. -
Pseudo-labeled data가 항상 모델의 성능을 향상시키는 것은 아니기에, pseudo-labeled data 중 신뢰도가 높은 (쉽게 말해, 가짜 정답이 실제로 진짜 정답일 확률이 높은) 것들만 골라서 사용하기도 합니다.
 Source:
Source: 4. Reinforcement Learning (강화 학습)
A feedback loop between the learning system and its environment.
- Reinforcement Learning은 데이터가 주어지지 않고,
환경 (Environment)이 주어진 상태에서에이전트 (Agent)가 취해야 할행동 (Action)을보상 (Reward)과상태 (State)를 기반으로 찾아나가는 학습 방법입니다. 순서를 따지자면 다음과 같습니다.에이전트 (Agent, 모델과 유사한 말)는 주어진 환경에서 어떠한행동 (Action)을 취합니다.- 행동의 결과로 환경이 변화합니다. 환경의 변화에 따라
보상 (Reward)과상태 (State)가 정해집니다. - 에이전트는 보상과 상태를 기반으로 다음 행동을 결정합니다.
- 일련의 과정을 반복합니다.
- 간단한 예시를 들어봅시다.
횡단보도를 안전하게 건너기 위한 적절한 방법을 아이에게 가르치기를 강화 학습의 형태로 구성해봅시다. 환경은 횡단보도,에이전트는 아이,행동은 걷기/뛰기,보상은 칭찬/훈계,상태는 횡단보도의 신호등 색깔 (빨간색/초록색) 이라고 해봅시다.- 현재 횡단보도 신호등 색깔이 빨간색인데, 뛰기를 선택했다고 해봅시다. 보상으로 강한 훈계가 돌아옵니다.
- 현재 횡단보도 신호등 색깔이 빨간색인데, 걷기를 선택했다고 해봅시다. 보상으로 훈계가 돌아옵니다.
- 현재 횡단보도 신호등 색깔이 초록색인데, 뛰기를 선택했다고 해봅시다. 보상으로 칭찬이 돌아옵니다.
- 현재 횡단보도 신호등 색깔이 초록색인데, 걷기를 선택했다고 해봅시다. 보상으로 큰 칭찬이 돌아옵니다.
- 이 과정을 반복적으로 수행하다보면, 아이는 횡단보도 신호등 색깔이 초록색일 때 걸어서 건너는 것이 적절한 방법이라는 것을 깨닫게 될 것입니다. 직접 해보면서 정답에 가까운 선택을 할 수 있게 되는 것이죠.
- 이처럼 강화 학습은 명확한 정답을 알려주기 보다, 주어진 상황에서 어떤 선택이 가장 적절한지 스스로 찾게 만드는 방법입니다. 그렇기 때문에, 학습 난이도가 매우 어려운 편입니다.
- 학습 난이도가 어려운 이유에는 여러 가지가 있겠지만, 반복적인 행동을 통해 충분한 데이터를 쌓아야지만 적절한 선택을 내릴 수 있다는 점 또한 학습 난이도가 어려워지는 요인 중 하나입니다.
정리
- 본 포스팅에서는
Machine Learning이란 무엇인지, Machine Learning 방법론에는 어떤 것이 있는지 (Supervised Learning,Unsupervised Learning,Semi-Supervised Learning,Reinforcement Learning) 에 대해 알아보았습니다.
- 다양한 Machine Learning 방법론을 보면서, 어떤 생각이 드셨을지 궁금합니다. 저는 데이터가 정말 중요하구나,, 라는 생각이 들었습니다.
- Supervised Learning 만큼 단순하고 강력한 방법은 없습니다. 다만 이 세상에서 발생하는 모든 일들을 입력 / 정답과 같은 형식으로 데이터화하는 것은 현실적으로 불가능하기 때문에, 이러한 문제점을 해결하고자 여러 방법론들이 등장한 것입니다.
⭐⭐ 중요 ⭐⭐
- 포스팅을 잘 보면,
확률이 높다와 같은 표현이 자주 쓰인 것을 볼 수 있습니다. 이는 달리 말해그렇지 않을 확률도 있다는 얘기입니다. - No Free Lunch Thoerem이라는 정리가 있습니다. 한국어로
공짜 점심은 없다는 얘기인데요. Machine Learning에서도 이 이론이 적용됩니다. 쉽게 말해 모든 문제에 대해 최고의 성능을 보이는 ML 알고리즘은 없다는 얘기입니다. - 그렇기에 문제를 해결할 때에는 최대한 다양한 방법을 시도해보는 것이 좋습니다. 일반적으로는 좋지 않다고 알려져 있는 알고리즘이라 할 지라도, 내가 풀고 있는 문제에 좋을 수도 있기 때문입니다. 해보기 전엔 모르기 때문이죠.
- 다음 시간에는 Machine Learning의 핵심인
Generalization과Bias and Variance에 대해 자세히 알아보도록 하겠습니다.
