시작하기에 앞서
- 본 포스팅은 2024년 1월 2일부터 1월 29일까지 진행되는 LG Aimers 4기의 온라인 교육 내용 중 하나인,
Machine Learning 개론 - Bias and Variance강의를 수강하며 공부한 내용을 정리한 포스팅입니다. - 출처가 명시되어있지 않은 이미지들은 LG Aimers 에서 제공한 강의 자료로부터 발췌한 것임을 밝힙니다.
- 강의에서 언급한 내용 모두를 다루지는 않고, 기억에 남았던 부분을 위주로 정리하였습니다.
Machine Learning
- Bias와 variance가 무엇인지 더 잘 이해하기 위해서, 우선 machine learning 의 정의에 대해 알아봅시다.

- 집합 는 우리가 풀고자 하는 문제의 데이터를 모아둔 집합 로부터 sampling 한 training data 입니다.
- 집합 (training data) 를 수집하고 model class 를 선택한 상황에서, machine learning 의 목표는 집합 에 대해 예측을 잘 할 수 있는 를 찾는 것입니다.
- 이를 좀 더 일반화하여 적어본다면, 집합 의 일부인 집합 (training data) 를 이용하여 집합 전체에 대해 예측을 잘 할 수 있는 parameter 를 찾는 것이라고 얘기할 수 있습니다.
- 목표를 달성하기 위해서는 objective function (목적 함수, loss function (손실 함수) 라고 얘기하기도 함) 을 최적화하는 과정이 필요한데요. 수식은 다음과 같습니다.
- 는 모델의 예측을, 는 실제 정답을 의미합니다. 이를 바탕으로 수식을 해석하자면, 모델의 예측과 정답 간의 loss 를 최소화하는 를 찾으라는 얘기입니다.
Generalization
- 앞서 말했듯이, machine learning 의 목표는 집합 의 일부인 집합 (training data) 를 이용하여, 집합 에 대해 예측을 잘 할 수 있는 parameter 를 찾는 것입니다.
- 하지만 이는 machine learning 의 목표일 뿐, 성능이 좋은 모델을 만드는 것과는 관련이 없습니다.
- 다시 말해서, 집합 에 대해 예측을 잘 하는 parameter 를 찾았다고 하더라도, 성능이 좋은 모델이라고 얘기할 수는 없다는 것입니다.
- 여기서 말하는 성능은 generalization 성능을 의미하는데요. Generalization 이 무엇인지, generalization 성능이 높은 모델이 좋은 모델인 이유는 무엇인지 알아보도록 하겠습니다.

- Machine learning 에서 generalization 이란, 학습에 사용된 data (seen data) 뿐만 아니라 학습에 사용되지 않은 data (unseen data) 또한 잘 예측하는 능력 이라고 얘기할 수 있습니다.
- 즉 generalization 성능이 높다는 것은 seen data 와 unseen data 모두 잘 예측한다는 것을 의미합니다.
- 그렇다면 generalization 성능이 높아야 하는 이유는 무엇일까요? 이를 이해하기 위해서는 training data 와 test data 를 알아야 합니다.
training data vs test data
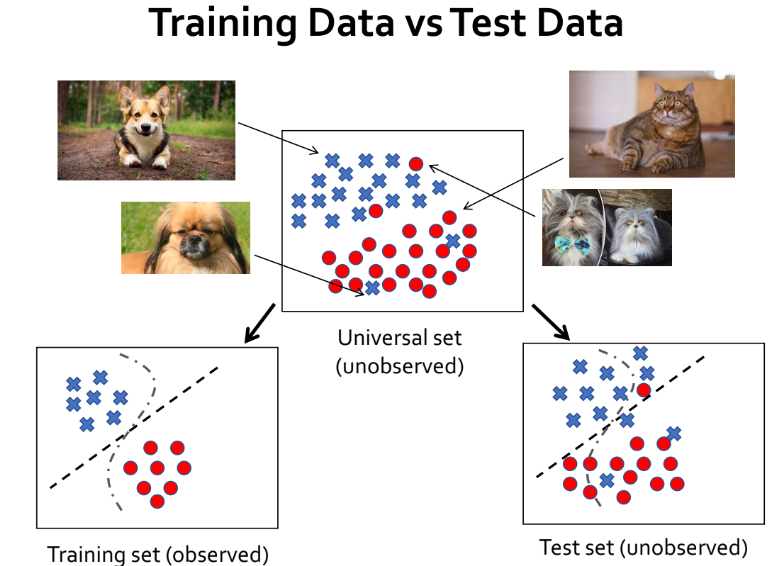
- 결론부터 말하자면,
- 집합 (universal set) 전체를 수집하는 것은 현실적으로 불가능합니다.
- 따라서 집합 를 잘 표현할 수 있는 일부인 training data (training set) 와 test data (test set) 를 이용하여 모델의 generalization 성능을 측정합니다.
- 측정한 성능을 바탕으로 전체 집합 에 대한 성능 또한 가늠합니다.
- 정리하자면 집합 의 일부인 training data 와 test data 에 대한 성능을 바탕으로 집합 에 대한 성능 또한 예상하기 때문에, generalization 성능이 중요한 것입니다.
- 예를 들어 주어진 이미지가 개인지 고양이인지 분류하는 모델을 만들기 위해 개와 고양이 사진을 수집해야 한다고 생각해봅시다.
- 개 / 고양이 분류 모델을 만들기 위해 지구 상에 존재하는 모든 개 / 고양이 사진 (universal set) 을 수집하는 것은 불가능합니다. 하지만 개 / 고양이 사진 일부 (training set, test set) 를 수집하는 것은 가능하죠.
- 이를 다르게 생각해보면, training set 과 test set 을 universal set 으로부터 sampling 했다고 생각할 수 있습니다.
- Sampling 과정을 적절히 수행했다면 training set 과 test set 이 universal set 을 잘 표현할 수 있다는 가정을 할 수 있습니다.
- 따라서 universal set 을 수집할 수 없음에도 universal set 을 잘 표현하는 dataset 일부를 수집함으로써 generalization 성능을 측정할 수 있게 되고, 측정한 성능을 기반으로 universal set 에 대한 성능 또한 예상하는 것입니다. 그렇기 때문에 generalization 성능이 중요한 것이죠.
- Generalization 이 무엇인지, 왜 중요한지는 이해가 됩니다. 그렇다면 모델의 generalization 성능은 어떻게 측정할 수 있을까요? 성능을 측정할 수 있어야 모델의 상태를 판단할 수 있고, 모델을 개선할 수 있을 텐데요.
Generalization Error
- 모델의 상태와 generalization 성능은 강한 관련이 있으므로, 현재 모델의 generalization 성능을 측정할 수 있는 방법이 필요한데요. 그러기 위해서 generalization error 를 정의할 수 있어야 합니다.

- Generalization error 수식을 한 번 살펴봅시다.
- 는 universal set 을 의미합니다. 와 는 입력과 정답을 의미하고, 는 모델의 예측 결과를 의미합니다.
- 즉 위 수식은 universal set 으로부터 sampling 한 와 를 가지고 계산한 loss 의 기댓값 () 을 말합니다. 쉽게 말해 지구 상에 존재하는 모든 data 에 대해 계산한 error 값의 평균이라고 할 수 있습니다.
- 앞서 얘기했던 것처럼 를 수집하는 것은 불가능한 일이기에, 일반적으로는 test data 만을 이용하여 generalization error 를 측정합니다.
- Generalization error 가 낮을수록 model 의 generalization 성능이 높음을 의미합니다.
- Generalization error 를 정의했기 때문에, 이를 이용하여 모델의 상태를 진단할 수 있습니다. 모델의 상태는 크게 overfitting, underfitting 으로 나뉩니다.
Underfitting
- Generalization error < Training error
- 한국어로 과소적합이라고 얘기합니다.
- Training error 가 더 높다는 것은 training data 조차 학습을 제대로 하지 못했다는 것을 의미합니다.
- Underfitting 상태의 모델은 generalization 성능이 높다고도, 낮다고도 할 수 없습니다.
- 따라서 training data 에 대해 잘 학습할 수 있도록 적절한 조취를 취해야만 합니다.
Overfitting
- Generalization error > Training error
- 한국어로 과적합이라고 얘기합니다.
- Generalization error 가 더 높다는 것은 training data 를 너무 많이 학습했다는 것을 의미합니다.
- Overfitting 상태의 모델은 generalization 성능이 낮다고 얘기할 수 있습니다. Training data 를 너무 많이 학습하는 바람에, test data 를 잘 예측하지 못하는 상황인 것이죠.
- 따라서 test data 에 대해서도 잘 예측할 수 있도록 적절한 조취를 취해야만 합니다.
- 좋은 model 을 만든다는 것은, 먼저 training error 를 줄인 뒤에, training error 와 test error 간의 차이를 줄이는 것이라고 할 수 있겠습니다. Training error 를 줄임으로써 underfitting 상태에서 벗어나고, gap 을 줄임으로써 overfitting 상태에서 벗어나는 것이죠.
- Generalization error 를 정의함으로써 모델의 상태를 진단할 수 있게 되었고, 모델의 상태에는 어떤 것이 있는지 알게 되었습니다.
- 그렇다면 모델의 상태에 영향을 주는 요인은 어떤 것일까요? 요인을 알아야 모델의 generalization 성능이 낮을 때 이를 개선할 수 있을 것이기 때문입니다.
Model's Capacity
- 그 중 하나는 capacity 입니다. Capacity 는 단순히 말하면 모델의 복잡도라고 할 수 있습니다. 여기서 복잡도는, 데이터의 패턴 또는 관계를 표현할 수 있는 능력을 의미합니다. 복잡도가 높을수록 표현 능력이 높아지고, 복잡도가 낮을수록 표현 능력이 떨어집니다.
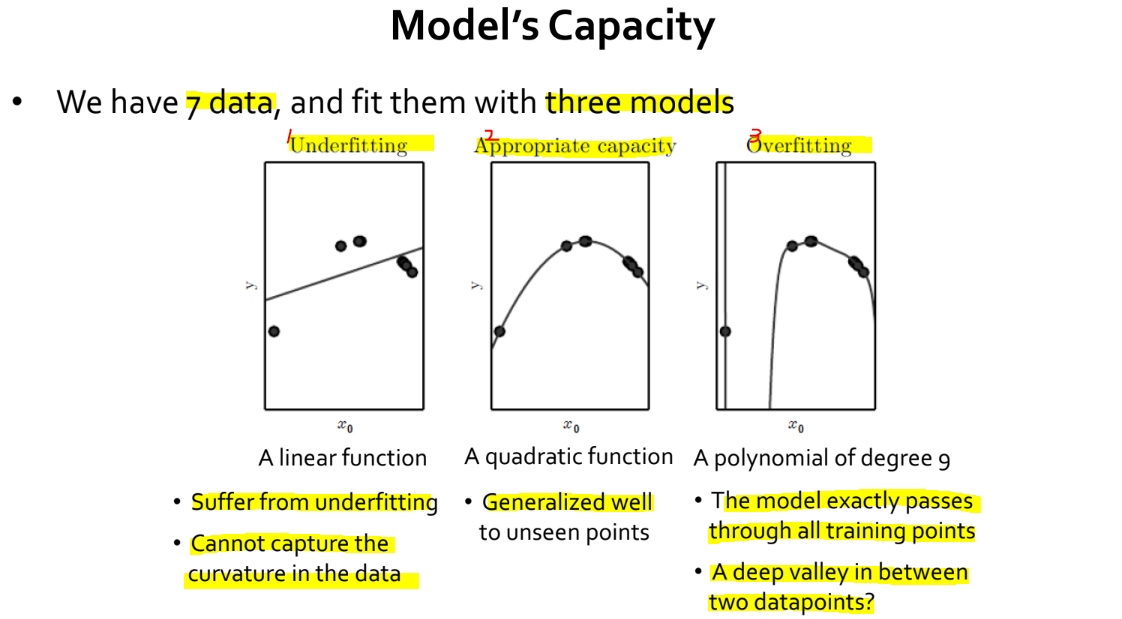
- 위 이미지를 봅시다. 7개의 data 가 주어졌을 때, 각기 다른 3개의 모델을 학습한 뒤 그 결과를 시각화한 모습입니다.
- 1번 그래프는 underfitting 상태로, 7개의 data 가 가지고 있는 곡선 패턴을 파악하지 못했습니다. Data 에 비해 capacity 가 너무 낮아 underfitting 이 발생한 것으로 보입니다.
- 2번 그래프는 data 가 가지고 있는 곡선 패턴을 잘 파악한 것으로 보입니다. 따라서 unseen data 가 주어졌을 때에도 잘 예측할 것 같습니다.
- 3번 그래프는 overfitting 상태로, training data 를 너무 많이 학습한 것으로 보입니다.. Data 에 비해 capacity 가 너무 높아 overfitting 이 발생한 것 같네요.
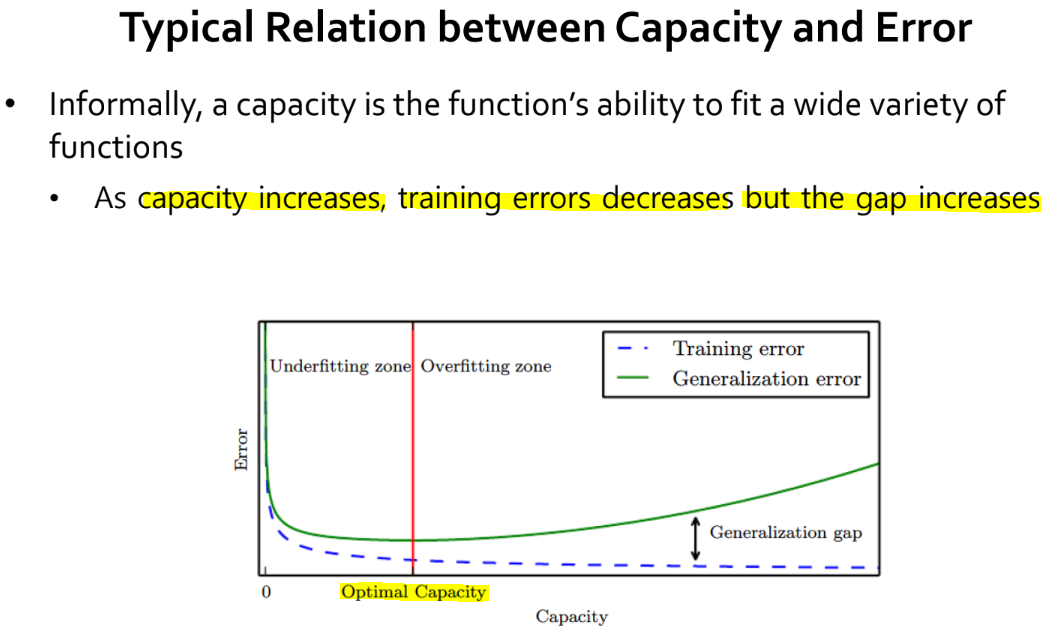
- 일반적으로 capacity 와 generalization error 는 위 그림과 같은 관계를 가집니다.
- Capacity 가 높아질수록, training error 는 낮아지지만 generalization error 는 높아집니다. 이 말은 모델이 overfitting 상태가 될 수 있다는 얘기입니다.
- 따라서 적절한 capacity 를 선정하는 것 또한 모델의 generalization 성능을 높이기 위해 중요하게 고려해야 할 부분입니다.
- Generalization 성능을 높이는 방법에는 또 어떤 것이 있을까요?
Regularization

- 대표적으로 regularization (규제화) 이 있습니다.
- Regularization 을 간략하게 설명하면, 복잡한 함수를 단순하게 만들기 위해서, 모델을 구성하는 parameter 에 규제를 가하는 것이라고 얘기할 수 있습니다.
- Parameter 에 규제를 가하여 generalization error 를 낮추는 것이 regularization 의 목표입니다. (training error 를 낮추는 것이 아닙니다)
- 대표적인 예시로 weight decay 가 있는데요. Objective function 에 parameter 에 대한 값을 추가함으로써 특정 parameter 값이 너무 커지는 것을 방지하는 기법입니다. 와 같은 hyperparameter 를 통해 정도를 조절하구요.
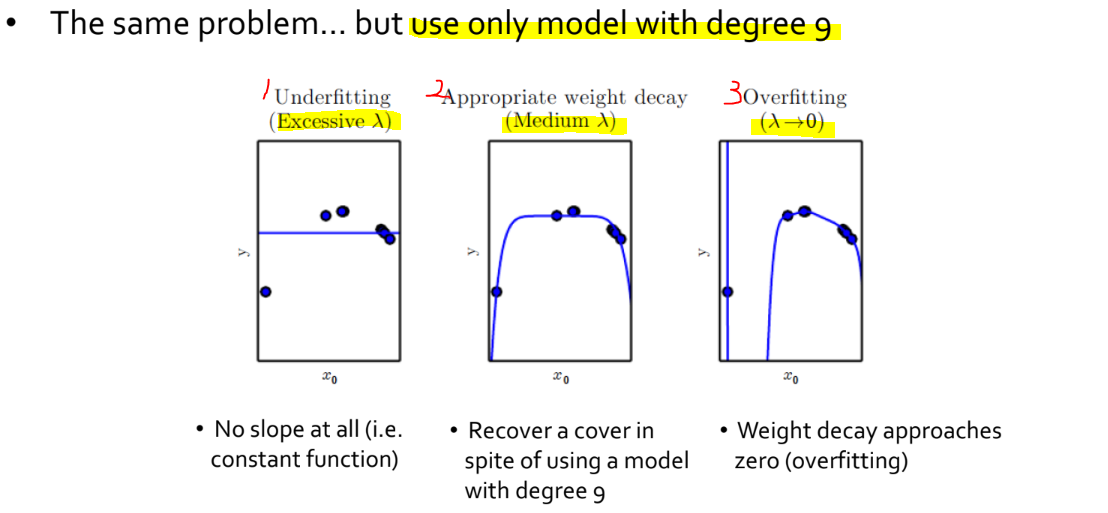
- 동일한 capacity 의 모델을 사용하되 서로 다른 값을 사용하여 모델을 학습시킨 결과입니다.
- 1번 그래프의 경우 과도하게 큰 값으로 인해 parameter 값 대부분이 사라지면서 모델이 너무 단순해졌고, 이로 인해 underfitting 이 발생했습니다.
- 2번 그래프의 경우 적절한 값을 설정한 덕분에 모델이 data 의 패턴을 잘 표현하고 있습니다.
- 3번 그래프의 경우는 이기 때문에 아무런 규제가 가해지지 않았고, 모델이 너무 복잡하여 overfitting 이 발생한 모습입니다.
- 이처럼 capacity 가 높은 모델이라고 할 지라도, 적절한 regularization 을 통해 generalization 성능을 높일 수 있습니다.
Bias and Variance
- 마지막으로 bias 와 variance 에 대해 알아보도록 합시다.
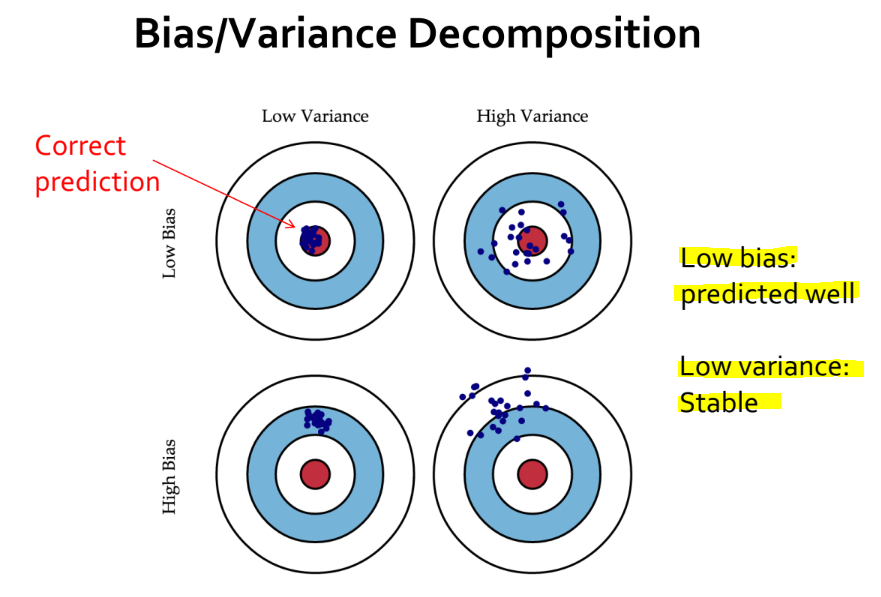
- Bias 와 variance 도 모델의 상태를 나타내는 용어입니다. Overfitting 과 underfitting 처럼 말이죠.
- 좋은 모델이라 함은 low bias and variance 를 가집니다.
- Bias 가 낮다는 것은 비교적 잘 예측한다는 얘기입니다.
- Variance 가 낮다는 것은 예측에 일관성이 있다는 얘기입니다.
- Low bias and variance 는 모델이 정답과 유사한 예측을 할 수 있고, 그 예측 결과에 일관성이 있다는 얘기입니다.

- Generalization error 를 의미하는 test error 는 bias 와 variance 의 합으로 나타낼 수 있습니다.
- Bias 는 모델의 예측 값과 실제 정답 간의 차이를 의미하고, variance 는 모델의 예측 값이 얼마나 흩어져있는지를 의미합니다.
- 가장 좋은 것은 bias 와 variance 를 모두 낮추는 것이지만, 이 둘 사이에는 trade-off (상충 관계) 가 존재합니다. 즉 bias 를 낮추면 variance 가 높아지고, variance 를 낮추면 bias 가 높아지는 것이죠.
- 따라서 좋은 모델이라 함은 bias 또는 variance 한 쪽만 낮은 모델이 아닌, bias and variance 가 적절히 낮은 모델이라고 얘기할 수 있겠습니다.
- 일반적으로 capacity 를 높이는 경우 bias 는 낮아지고 variance 가 높아집니다.
- 마지막으로 bias and variance 와 overfitting and underfitting 간의 관계에 대해 알아보겠습니다.

High variance implies overfitting
- Variance 가 높다는 것은, 모델의 예측에 일관성이 없다는 얘기입니다. 일관성이 없다는 얘기는 다시 말해서, 예측 결과가 왔다갔다 한다는 얘기입니다.
- 예측 결과가 왔다갔다 한다는 얘기는, 모델이 training data 를 너무 많이 학습하여 overfitting 상태에 놓여있다고 의심할 수 있습니다. (확신이 아닌 의심입니다)
- 모델의 상태에 영향을 주는 요인에는 capacity 가 있었는데요. Capacity 가 높은 경우 variance 또한 높아지기 때문에, capcity 자체를 낮추거나 regularization 등을 통해 복잡도를 낮추어야 합니다.
- 또는 data 를 더 수집하는 방법이 있습니다. 높은 capacity 가 문제가 되는 이유는, 보통 수집한 data 의 양이 capacity 만큼 충분하지 않아서 그렇습니다. Data 의 양이 적다 보니 data 에서 발견할 수 있는 패턴 자체가 단순한 상황인데, 너무 높은 capacity 를 가진 모델을 사용한 것이죠. 그래서 training data 를 더 확보하는 것은 overfitting 또는 high variance 를 해결하는 하나의 방법이 될 수 있습니다.
High bias implies underfitting
- Bias 가 높다는 것은, 모델의 예측이 정답과 다르다는 얘기입니다.
- 모델의 예측과 정답이 다른 이유는 여러 방향으로 해석할 수 있겠지만, 주어진 data 의 패턴을 학습하지 못한, underfitting 상태를 의심할 수 있습니다.
- 이 경우 capacity 를 높여 data 의 패턴을 학습할 수 있도록 만드는 것이 좋습니다.
정리
- 본 포스팅에서는 높은 성능의 모델을 만들기 위해 알아야 할 다양한 요인 (generalization, overfitting, underfitting, capacity, regularization, bias, varaince, ) 들의 정의 및 의미에 대해 다루었습니다.
- 모델의 성능을 판단하는 것에 있어 중요한 요인들이기에, 자주 복습하면서 그 의미를 새기는 것이 중요하겠습니다.

AI Engineer