시작하기에 앞서
- 본 포스팅은 2024년 1월 2일부터 1월 29일까지 진행되는 LG Aimers 4기의 온라인 교육 내용 중 하나인,
Machine Learning 개론 - Recent Progress of Large Language Models강의를 수강하며 공부한 내용을 정리한 포스팅입니다. - 출처가 명시되어있지 않은 이미지들은 LG Aimers 에서 제공한 강의 자료로부터 발췌한 것임을 밝힙니다.
- 강의에서 언급한 내용 모두를 다루지는 않고, 기억에 남았던 부분을 위주로 정리하였습니다.
OpenAI
GPT-3

- 범용적으로 사용하고자 하는 목적을 가지고
OpenAI에서 출시한 알고리즘입니다. - 범용적인 알고리즘이라는 얘기는, 여러 가지의 task 를 단 하나의 알고리즘으로 해결할 수 있다는 얘기입니다. (이전에는 question answering, translation, text writing 과 같은 task 들을 각기 다른 알고리즘, 즉 task-specific 한 알고리즘을 사용하여 풀고자 했습니다)
- 1750억 개의 parameters 를 기반으로 동작합니다. 흔히 사용하는
FloatTensor32dtype 을 기준으로 한다면, parameters 크기만 대략 700 GB (...) 입니다. 어마어마한 크기인 것이죠.
InstructGPT (GPT-3.5)

GPT-3의 문제점이라고 한다면, 언어 이해 (language understanding) 는 곧잘 하지만 질문에 대한 답변 생성 능력이 떨어진다는 점이었습니다.- 따라서 사용자의 질문 의도를 이해하고, 사용자가 원할 것으로 예상되는 답변을 생성하는 능력을 높이기 위해
InstructGPT가 등장했습니다.
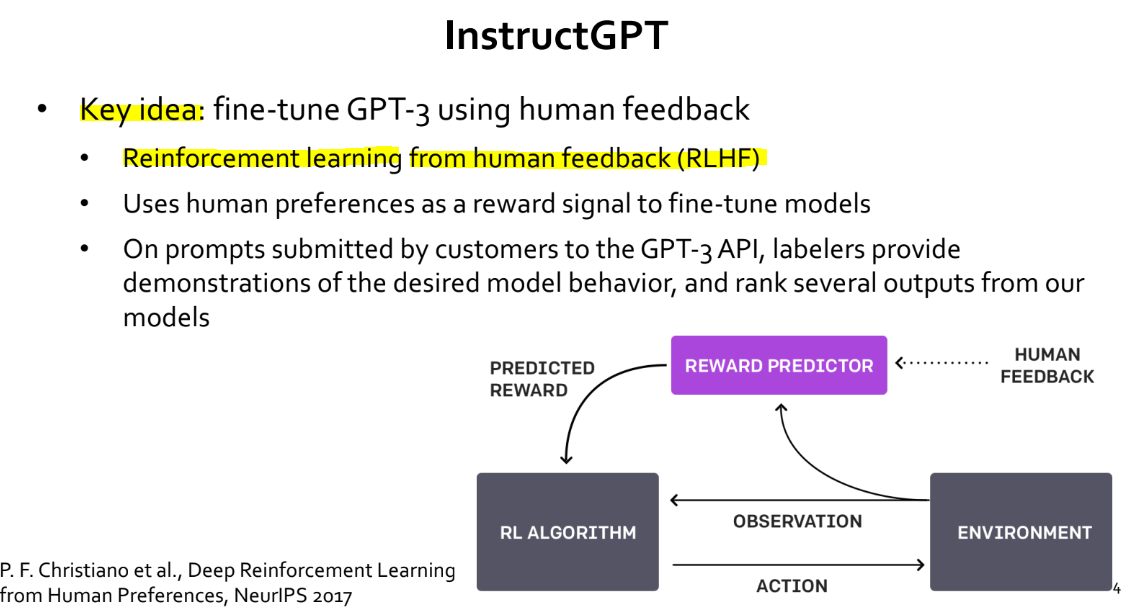
- 이를 가능하게끔 만든 핵심 아이디어는, 그 유명한
RLHF (Reinforcement learning from human feedback)입니다. RLHF에 대한 상세한 리뷰는 추가 포스팅을 통해 진행하도록 하고, 본 포스팅에서는 간략하게만 짚고 넘어가도록 하겠습니다.

-
InstructGPT를 학습하는 과정은 총 세 단계로 나눌 수 있습니다.
1. Supervised fine-tuning (SFT)- Prompt dataset 에서 prompt 를 sampling 합니다.
- Sampling 한 prompt 에 대한 답변을 사람이 작성합니다.
- (prompt, answer) 쌍을 이용하여
GPT-3모델을 학습합니다.
2. Reward model (RM) training
- 1번 과정을 통해 학습을 마친
GPT-3를 이용하여, 하나의 prompt 에 대해 여러 개의 답변을 생성합니다. - 사람이
GPT-3가 생성한 여러 개의 답변에 순위를 매깁니다. - (여러 개의 답변, 여러 개의 답변에 대해 사람이 매긴 순위) pair 를 이용하여 reward model 을 학습합니다.
3. Reinforcement learning (RL) via Proximal Policy Optimization (PPO)
- 학습에 사용하지 않았던 새로운 prompt 를 가져옵니다.
- 1번 과정을 통해 학습을 마친
GPT-3모델을 이용하여 답변을 생성합니다. - 생성한 답변을 reward model 에 입력하여, 해당 답변에 대한 점수 (순위) 를 계산합니다.
- 계산한 점수와 생성한 답변을 기반으로, 강화학습 기반의 PPO 알고리즘을 사용하여
GPT-3모델을 재학습합니다.
-
GPT-3모델을 학습하는 과정에 사람의 피드백 (1, 2번 과정) 을 제공함으로써, 사람이 원하는 답변을 생성할 수 있는 능력이 좋아지게 됩니다.
ChatGPT
ChatGPT는InstructGPT에 대화형 User Interface 를 연결한 챗봇입니다. (새로운 방법론이 아닙니다)- 단 2달 만에 100만 MAU 를 달성했습니다.
GPT-4

- 이전 버전의
GPT들은 text input 을 받아서 text output 을 생성했다고 한다면,GPT-4의 경우 image input 을 받아서 text output 을 생성하는 것이 가능해졌습니다. - 다양한 도메인의 데이터 (e.g., image, text, audio, etc) 를 처리할 수 있는 능력을 갖춘 모델을
multimodal model이라고 얘기하는데요.GPT-4역시 multimodal model (image, text) 입니다.
GPT-4부터는technical report에 기술적인 세부 내용들 (architecture, model size, etc) 이 작성되지 않았습니다.GPT-3.5와 비교했을 때,context length가 8배 가량 증가했습니다.- Context length 는 새로운 답변을 생성할 때 이전 대화를 얼마나 고려할 것인지 나타내는 값입니다. Context length 가 길다는 얘기는, 이전에 사용자와 나누었던 대화를 많이 참고한다는 얘기이므로, 대화의 흐름을 고려한 답변을 할 수 있게 됩니다. (생뚱맞은 답변을 하지 않게 됩니다)
- Context length 는 새로운 답변을 생성할 때 이전 대화를 얼마나 고려할 것인지 나타내는 값입니다. Context length 가 길다는 얘기는, 이전에 사용자와 나누었던 대화를 많이 참고한다는 얘기이므로, 대화의 흐름을 고려한 답변을 할 수 있게 됩니다. (생뚱맞은 답변을 하지 않게 됩니다)
Limitations
GPT시리즈 모델의 한계점에 대해 알아봅시다.- 아래에서 언급한 한계점들은 비교적 빠른 속도로 개선되고 있습니다.

- 답변을 완전히 신뢰할 수 없습니다.
- 사실이 아닌 내용을 사실처럼 얘기하거나 (hallucination) 추론 오류 (reasoning error) 를 범합니다.
- 문장에 예민합니다.
- 두 문장이 같은 의미일지라도, 문장을 구성하는 데 사용한 단어 등의 차이 (paraphrasing) 로 인해 답변의 품질이 떨어질 수 있습니다.
- 같은 질문에 다른 답변을 합니다.
- 편향된 답변을 할 수 있습니다.
- 사람의 피드백을 학습하는 과정에서 편향된 지식을 학습했을 수 있습니다.
- 2021년 9월 이후의 지식이 부족합니다.
- 2021년 9월까지의 데이터만 이용하여 학습했기 때문에 그 이후 지식이 부족합니다.
- 경험을 기반으로 학습하지 않습니다.
- 검증 과정에 신경쓰지 않습니다.
Bard

- 구글에서 출시한
Bard는 구글의 LLM (LaMDA, PaLM, Gemini, etc) 에 대화형 User Interface 를 연결한 챗봇입니다. - 최근까지의 데이터를 학습한 모델을 사용하고 있습니다. (Gemini 의 경우 2023년 12월 6일 이전까지의 데이터를 사용)
Meta
LLaMA
- 메타에서 공개한
LLaMA는 하나의 모델입니다. (챗봇이 아님) - 다른 LLM 과 달리,
LLaMA의 경우 소스 코드 및 기학습된 모델들을 무료로 공개하고 있습니다.
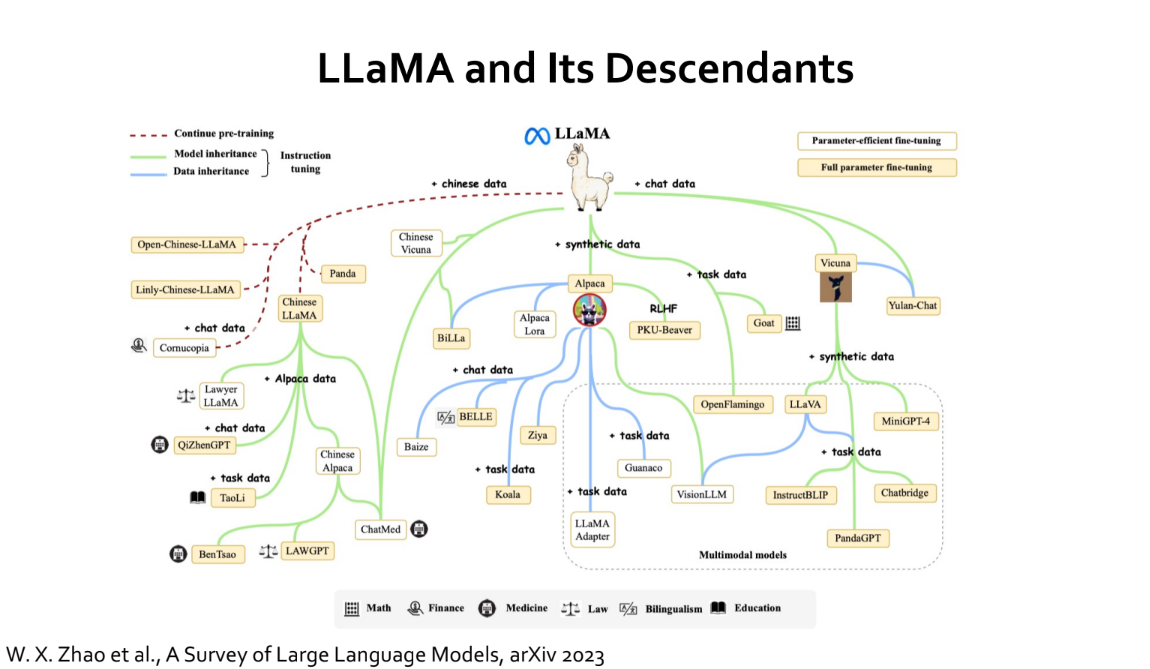
- 소스 코드와 기학습된 모델이 공개되면서 많은 사람들이
LLaMA를 기반으로 LLM 연구를 하기 시작했고, 그 결과 다양한 파생 모델들이 등장하게 되었습니다. (Alpaca, Vicuna, etc)
Leaderboard
- HuggingFace_Open LLM Leadeboard :
HuggingFace에서 호스팅하고 있는 LLM Leaderboard 입니다. - AIHUB_Open KO-LLM Leaderboard :
AI Hub에서 호스팅하고 있는, 한국어 LLM Leaderboard 입니다. - 두 leaderboard 모두
LLaMA를 기반으로 한 모델들이 상위권을 차지하고 있는 모습입니다.
정리
- 본 포스팅에서는
OpenAI의GPT시리즈,Google의Bard,Meta의LLaMA에 대해 간략하게 다루었습니다. - LLM 의 경우 하루가 멀다하고 새로운 모델들이 공개되고 있기 때문에, 꾸준히 공부하면서 트렌드를 따라가는 것이 중요하겠습니다.

AI Engineer