Abstract
time series에서 unsupervised anomaly detection을 하는 것은 비지도 학습을 통해 모델이 데이터를 구별할 수 있는 기준점을 도출하기를 요구하므로 상당히 어려운 문제이다.
이전의 방법들은 pointwise한 representation이나 pairwise한 연관성을 학습하였지만 둘 다 데이터의 복잡한 상관관계를 학습하기엔 부족했다.
최근 transformer는 pointwise representation과 pairwise association을 통합하여 좋은 성능을 보였고, 각 시점의 self-attention 가중치 분포가 곧 전체 시계열의 분포와 연관성이 있다는 것을 알아냈다.
본 논문의 핵심 관점은 anomaly의 희소성 때문에 전체 시계열과의 연관성이 크게 다를 것이고, 그러므로 anomaly는 인접한 시점들과 연관성이 클 것이라는 점이다.
논문에서는 이것을 adjacent-concentration bias(인접 집중 편향)라고 하며, 연관성 기반 모델의 기준점이 될 수 있고, 이는 본 논문에서 제시하는 Association Discrepancy 에 의해서 강조된다.
본 논문은 위의 내용을 토대로 한 Anomaly Transformer 를 제안하고, 이는 연관 불일치(Association Discrepancy)를 통해 normal과 abnormal의 연관성을 minimax 전략으로 구분지을 수 있게하여 unsupervised time series anomaly detection 벤치마크들에서 SOTA(state-of-the-art)를 달성했다고 한다.
Introduction
real-world system은 multi-sensor로 지속적인 모니터링이 이뤄지고 있으며, 산업 설비나 우주 탐사선과 같은 장비들에서 continuous data를 수집한다. 이러한 시스템 모니터링을 통해서 수집된 데이터들에서는 장비의 오작동들이 발견되는데, 이는 anomaly detection을 통해서 감소시킬 수 있으며 나아가 금전적 손실과 보안 문제를 완화시킬 수 있다. 하지만 이상(anomaly)은 굉장히 많은 normal points들에 비해 희소하게 발생하며, 데이터 라벨링을 어렵게 만들고 비싼 비용을 야기한다. 때문에 논문은 time series anomaly detection을 unsupervised learning으로 해결할 필요가 있다고 말한다.
unsupervised time series anomaly detection은 이전부터 굉장히 어려운 과제로 자리잡고 있었다. 모델은 복잡한 시계열 데이터로부터 유의미한 정보를 표현학습(representation learning) 해야 하고, 심지어 굉장히 많은 normal time points 사이에서 희소한 anomaly를 구별해낼 수 있는 기준점(criterion)을 찾아내야 한다.
고전적인 비지도 학습 이상 탐지 기법들 중에는 LOF(Local Outlier Factor), OC-SVM(One Class SVM), SVDD 등이 있지만 이 모델들은 시간 정보를 고려하지 않고, unseen data에 대해서 일반화 성능이 떨어지기 때문에 실제 환경에 적합하지 않다.
이러한 이유로 딥러닝 모델을 이용한 표현학습 방법론들이 등장했고, 높은 성능을 달성했다. 이 중에서 pointwise representation에 초점을 맞춘 방법론들의 핵심은 well-designed recurrent networks를 통해 유의미한 정보를 잘 표현학습하고, recontruction이나 autoregressive task를 통해 self-supervised 될 수 있다는 것이다. 이 방법론들의 criterion은 주로 reconstruction error 혹은 prediction error 이다. 하지만 anomaly는 희소하기 때문에 pointwise representation은 복잡한 시계열 데이터의 상관관계를 잘 고려하지 못하고, 이는 곧 이상을 올바르게 탐지하기 어렵다는 문제가 있다. 또한, reconstruction or prediction error는 point by point로 계산되기 때문에 temporal information이 반영된 criterion이 아니라는 단점이 있다.
다른 관점의 방법론들 중에는 association을 기반으로 모델링하는게 있다. 여기에는 GNN(graph neural network)을 통해 그래프 기반으로 서로 다른 time point 간의 연관성을 분석하는 방법이나 subsequence로 time series를 분할해서 각 subsequence 간의 연관성을 통해 anomaly detection을 하는 방법 등이 있다. 하지만 이 방법들 역시 한계가 존재한다. Graph-based는 단일 시점에 대해서는 연관성을 잘 표현하지만, 복잡한 시계열 패턴이 불충분하면 이상을 잘 탐지하지 못하고, subsequence-based 방법론은 시간적 정보를 subsequence를 통해 고려할 수 있지만 각 time point들과 전체 시계열 간의 연관성은 고려하지 못한다.
본 논문에서는 Transformer를 적용하여 unsupervised time series anomaly detection을 수행한다. Transformer는 현재 NLP나 Vision 뿐만 아니라 time series 분야에서도 뛰어난 성능을 보인다. 특히 time series에서는 global representation과 long-range relation을 고려하기 때문에 Transformer의 self-attention map에서 나타나는 각 시점과 전체 시점간의 연관성 정보를 토대로 높은 성능을 기대할 수 있다.
self-attention map은 각 시점과 전체 시점간의 분포 연관성을 제공하고, 이는 temporal context를 더 유익하게 설명할 수 있으며 시계열의 trend와 period와 같은 동적 패턴을 나타낼 수 있다. 논문은 이러한 연관 분포를 series-association 이라고 명명한다.
또한, anomaly가 희소하기 때문에 모델은 normal pattern에 dominant 되기 쉽다. 때문에 anomaly는 전체 시계열과 강한 연관성을 갖지 못하므로 이상 패턴과 연관이 있을 수 있는 인접 시점(이상 패턴에 인접한 시점)에 집중해야 한다. 이러한 adjacent-concentration bias(인접 집중 편향)는 논문에서 prior-association으로 명명한다.
반대로, normal time points에 dominate 되는 것은 인접 시점 뿐만 아니라 전체 시계열에 대한 연관성을 설명할 수 있다. 따라서 본 논문은 prior-association과 series-association을 통해서 각 시점의 이상을 판별할 수 있는 criterion을 만들어낼 수 있다고 하며, 각 시점에 해당하는 두 assiciation간의 거리를 Association Discrepancy 라고 명명한다.
핵심은 다음과 같다.
- unsupervised time series anomaly detection에 Transformer를 적용함.
- 각 시점의 prior-association과 series-association을 고려해서 anomaly-attention을 계산하고 이를 Association Discrepancy라고 함.
- prior-association은 learnable Gaussian kernel을 통과시켜서 인접 시점을 집중적으로 학습할 수 있도록 함.
- series-association은 raw time series data를 그대로 학습하여 self-attention map 구성하도록 함.
- minimax strategy로 두 연관성 분포 간의 거리를 조정해서 normal-abnormal 구별이 가능한 criterion을 구축함.
논문에서 말하는 핵심 기여점은 다음과 같다.
- prior-association과 series-association의 유사도를 통해 anomaly-attention 매커니즘을 활용한 Association Discrepancy와 이를 토대로 구축한 Anomaly Transformer 모델을 제안함.
- minimax strategy로 normal-abnormal 판별을 잘 해낼 수 있는 새로운 association-based criterion을 제안함.
- Anomaly Transforemr로 6개의 벤치마크에서 SOTA를 달성함.
Related Work
Unsupervised Time Series Anomaly Detection
앞서 언급했듯이 비지도 학습 기반 시계열 이상 탐지 방법론은 과거에도 꾸준히 연구되어 왔다. 여기에는 clustering-based, reconstruction-based 등 다양한 접근법이 존재하고, LOF, SVDD, LSTM-VAE 등 다양한 모델이 연구되었다.
본 논문은 기존의 random walk와 subsequence-based 방법론들과 다르게 새로운 association-based criterion을 제안하며, time point에 대해 더 설명력 있는 정보를 학습하는 시계열 모델을 구축했다.
Transformer for Time Series Analysis
Transformer는 time-series task에 이미 적용되고 있었다. 하지만 기존의 적용법과 다르게 본 논문의 Anomaly Transformer는 self-attention 매커니즘을 통해 Anomaly-Attention을 구현하고, 이를 기반으로 Assiciation Discrepancy를 분석한다.
Method
방법론 설명에 들어가기에 앞서, notation에 대해서 간략히 설명하면 다음과 같다.
모니터링 시스템 를 측정했을 때, 관측된 time series 는 이고, 이 때 는 time 에서 관측된 값이다.
비지도 학습은 이 에 label이 없는 상태에서 anomaly detection 문제를 풀어야하기 때문에 어려운 과제이다.
3.1 Anomaly Transformer
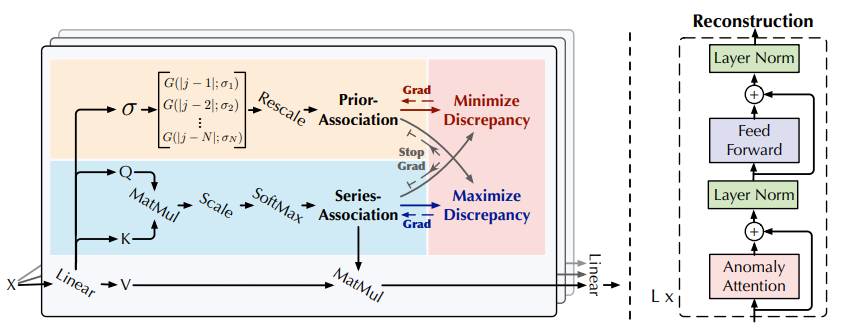
기존의 vanila Transformer로는 anomaly detection 과제를 수행하기 어렵기 때문에 다음과 같이 Anomaly-Attention 매커니즘을 토대로 Anomaly Transformer Architecture를 설계했다.
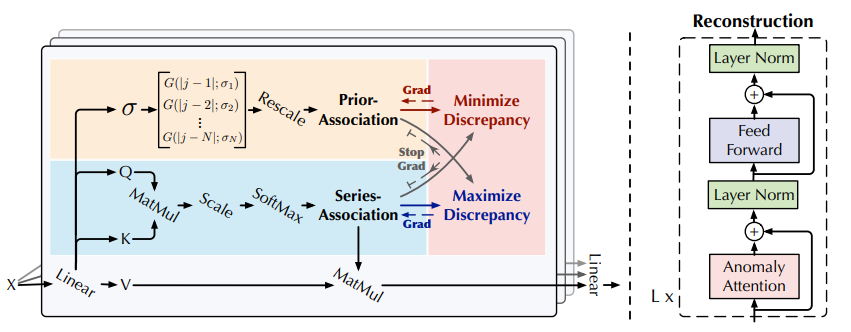
위 그림에서 왼쪽 그림이 Anomaly Attention이고, 오른쪽은 Anomaly Transformer의 전체적인 동작 과정이다.
input time series 를 만족하고, layer에 대해서 다음과 같은 계산이 이뤄진다. (L은 모델의 layer 개수, N은 input time series 길이)
-
-
은 - layer with channels의 output
initial input 는 raw time series를 embedding 한다.
는 - layer의 hidden representation
Anomaly-Attention()은 association discrepancy를 계산
Anomaly Attention에는 prior-association과 series association이 있었다.
prior-association은 learnable Gaussian kernel을 통해서 인접 시점의 가중치를 높이도록 계산된다. 또한, 가우시안 커널의 는 learnable parameter이기 때문에 scale이 다양한 time series pattern에 적응 가능하다.
series association은 raw series의 연관성을 학습하여 가장 의미있는 연관성을 찾는다.
Anomaly Attention에서 각각의 association은 다음과 같이 계산된다.
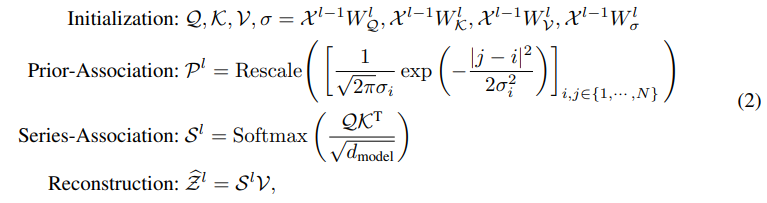

Conclusion
본 논문은 unsupervised time series anomaly detection에서 기존의 time-point association을 활용한 Transformer와 다른 관점으로 이상을 탐지하는 Anomaly Transformer 를 제안했다.
이 모델은 normal과 abnormal 시점의 연관 불일치성을 minimax 전략을 통해 극대화시켜서 모델이 이상을 구별할 수 있는 기준(criterion)을 제시했다.
Anomaly Transformer 는 SOTA를 달성했고, 향후에는 autoregression이나 state space model을 고려한 고전적인 분석까지 진행하여 Anomaly Transformer 의 이론연구가 더 필요하다고 밝혔다.
