Abstract
CNN은 학습 데이터셋에 따라 texture와 shape 두 특성에 대해 bias를 갖는다. 그리고 각 bias는 상호보완적 관계이기 때문에 둘 중에 하나의 cue에 대해서만 학습을 진행할 경우 모델 성능에 좋지 못한 영향을 끼친다.
이 논문은 bias를 제거함으로써 모델 성능에 texture나 shape bias가 영향을 끼치지 못하도록 하는 shape-texture debiased learning 을 제안한다.
논문에서는 하나의 cue에만 영향을 받아서 representation 되는 것을 방지하기 위해 shape와 texture 정보 모두를 conflicting 한다고 한다.
실험을 통해 논문에서 제시한 방법론이 몇 가지 image recognition benchmarks와 adversarial robustness에서 성능이 더 좋음을 보였다.
Introduction
지난 10년 간 vision 연구자들은 CNN이 객체(object)를 잘 학습할 수 있도록 다양한 shape나 texture, 혹은 이 둘을 합성한 feature를 수동으로 디자인해왔다.
최근에는 모델이 자동으로 feature learning을 할 수 있도록 모델을 디자인했고, 더 이상 feature engineering에서 사람의 노력이 크게 필요하지 않았다.
그리고 2019년에는 학습 데이터셋에 따라 모델이 feature learning을 할 때, shape나 texture bias에 영향을 받는다는 것을 실험적으로 밝혔다. (texture bias가 더 심하다고 결론이 남)
하지만 이 논문에서는 이 bias가 모델의 성능을 약화시킨다고 주장한다.
또한, shape bias와 texture bias가 상호 보완적인 관계에 있으며, 각각의 cue에 편향되면 필연적으로 모델 성능에 제한이 걸린다고 말한다.

위의 그림을 보면, shape이나 texture bias 중 한쪽에 의존하는 모델은 정확한 분류를 해내지 못한다.
논문에서 제시하는 것처럼 shape-texture debiased model이 두 특성을 모두 반영하여 올바르게 분류를 했다.
논문에서 제시하는 방법론은 CNN이 training dataset에서 bias를 자동적으로 피하도록 하는 data-driven 접근법이다. 특히, 저자들은 style transfer를 통해 cue conflict image를 증강하는데, 이 때 shape와 texture 간의 상관관계를 배제시키는 방식으로 진행한다. 그리고 가장 중요한 부분은 증강 데이터셋에 관하여 supervision이 필요하며, 만약 supervision이 없다면 bias가 남아있게 된다.
이와 같이 논문에서 제안한 모델은 실험을 통해 유의미한 성능 향상을 보였다.(뒤 실험 파트에서 더 자세히 다룸)
Shape/Texture Biased Neural Networks
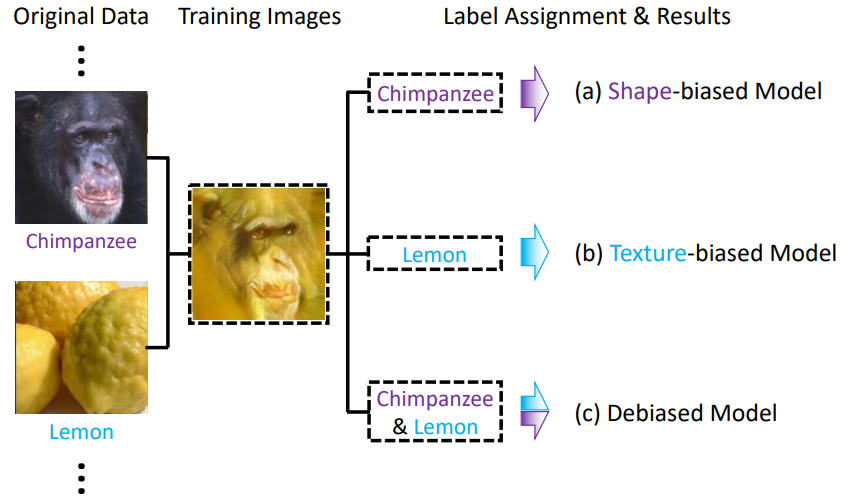
기존 방식대로 shape bias / texture bias에 의존하는 모델은 위의 그림처럼 generate된 이미지에 대해서 올바르게 분류해내지 못한다. 이 논문은 이러한 문제를 해결하기 위해 랜덤한 이미지 쌍을 샘플링해서 shape와 texture를 blend하는 방식으로 데이터를 증강한다.
Label assignment는 말 그대로 어떤 bias를 더 집중적으로 보는가에 따라 다른 레이블을 줄 수 있다. 대부분의 CNN 모델처럼 texture bias에 의존적이게 한다면 위의 그림에서 (b)처럼 lemon 이라는 레이블이 부여될 것이다. 반면, shape biased model이라면 침팬지라는 레이블이 부여될 것이며 이러한 특징을 이용해서 cue conflict image에 레이블을 부여할 수 있다.
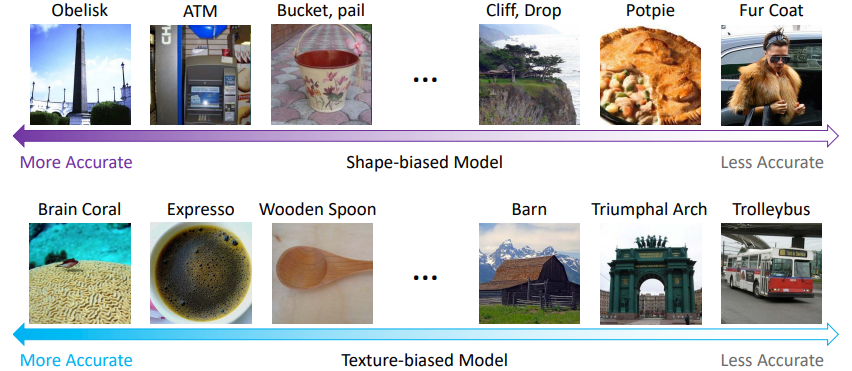
위 그림에서 볼 수 있듯이 shape-biased model과 texture-biased model은 서로 다른 객체 카테고리에 대해서 성능이 좋거나 나쁘다. 당연한 얘기지만, shape-biased model은 shape에서 유의미한 정보를 얻을 수 있어야 하고, texture-biased model은 질감에서 얻는 정보가 유의미해야 한다.
즉, 이 둘은 서로 상호 보완적인 관계이므로 한 쪽만 배제시키는 것은 모델 성능 악화를 초래할 수 있다.
Shape-Texture Debiased Neural Network Training
shape-texture debiased neural network의 목적식은 상당히 심플하다.
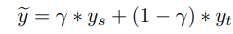
는 shape-source image의 one-hot label이고, 는 texture-source image에 대한 one-hot label이다.
shape-texture coefficient 는 각 label에 대한 가중치(상대적 중요성)이고, 최적의 값을 구하면 위의 수식을 통해 soft label 를 얻을 수 있다.
[?] 이미지 페어를 구성했을 때, 증강된 이미지가 shape와 texture 중 어느 쪽이 dominant한지, 전부 hand-craft로 한 것인지가 궁금함.
분명 shape와 texture을 섞었을 때, 생각만큼 잘 나오지 않아서 한 쪽 특성이 주류가 될 가능성이 높고, 그렇게 되면 이에 따른 값을 조정해야 하는데 어떻게 조정하는지?
Experiments
- ImageNet dataset (train: 1.2m / valid: 50k, 1k classes)
- PASCAL VOC 2012 segmentation dataset(20 foreground object classes, one background class, train: 10,582 / valid: 1,449)

vanilla 학습과 vanilla 학습에서 epoch을 2배로 하여 실험한 것, shape-biased, texture-biased, Debiased model의 실험결과이다. Shape 또는 texture에 bias 되는 경우 성능이 저하되는 것을 볼 수 있고, debiased model의 경우 network 사이즈가 커질수록 성능이 더욱 향상되는 것을 볼 수 있다. 2xepoch과 비교하여 단순히 학습을 더 많이 하는 것은 의미 없다는 것을 알 수 있다.
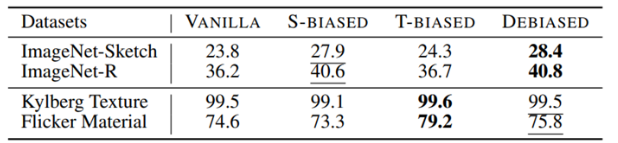
debiased model이 shape과 texture 정보를 모두 적절히 잘 표현하도록 학습되었는지 확인하기 위해 shape dataset인 ImageNet-Sketch, ImageNet-R과 texture dataset인 Kylberg Texture, Flicker Material dataset으로 실험한 결과이다. Shape dataset의 경우 S-biased model 보다도 debiased model이 성능이 더 좋고 texture dataset의 경우 T-biased 보다는 성능이 좋지 않지만 vanilla 보다 성능이 향상되는 것을 볼 수 있다.
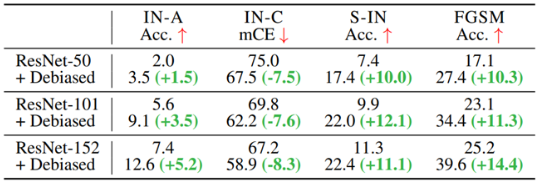
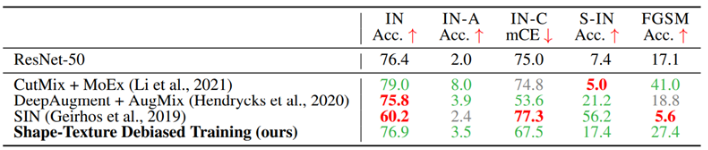
ImageNet-A(natural adversarial example 포함), ImageNet-C(75개의 visual corruption 적용), stylized-ImageNet에서 모델의 일반화 성능과 FGSM adversarial attack에 대한 robustness를 실험한 결과이다. 모든 STOA의 개선사항은 여러 벤치마크에서 일관되지 않지만 debiased 모델은 vanilla training baseline을 능가하는 유일한 방법이다.
Conclusion
오랫동안 객체 인식에서 shape와 texture 중 어떤 cue가 우세한지에 대해 논쟁이 있었다. 결론적으로 어느 쪽이든 bias에 치우친 학습을 하게 되면 모델 성능 저하로 이어지지만, shape와 texture bias는 상호 보완적이며 둘 다 이미지 인식에 중요한 특성임을 알 수 있었다. 이를 바탕으로, CNN이 더 나은 예측을 할 수 있도록 shape-texture debiased neural network가 제안되었다. 논문에서 제시한 방법론의 핵심은 shape-texture debiased model을 학습할 때, supervision을 제공해야한다는 점이었다.
실험을 통해 이 모델이 shape-biased와 texture-biased model보다 성능이 더 좋다는 것을 보였고, robustness 또한 더 낫다는 것을 보였다.
개념적으로 간단하지만 이미지 처리의 객체 인식 측면에서 분명한 기여점이 있는 논문이다.
