Abstract
Time series forecasting task는 real-world의 dynamic system에서 중요한 만큼 활발히 연구되는 분야이다. 하지만 NLP나 CV 처럼 large model이 없어서 time series task는 제한이 많다. (희소하기도 하고 초대형 데이터셋을 구축하기도 어려움)
최근 연구되고 있는 LLM은 복잡한 시퀀스 토큰에 대한 패턴 인식 및 추론 능력이 매우 뛰어나다는 평가가 이어지고 있다. 시계열 또한 시퀀스 데이터를 통해 추론하기 때문에 LLM을 적용하려는 시도들이 이어지고 있지만 아직까지 자연어와 시계열 데이터 간의 차이를 align하는데 문제가 발생한다.
이 논문에서는 백본 LLM을 그대로 유지하되, reprogramming framework라는 것을 통해서 일반적인 시계열 데이터를 추론할 수 있도록 하는 Time-LLM을 제안한다.
시계열 input을 LLM에 넣기 전에 text prototype으로 reprogramming하고, LLM의 추론 능력을 강화하기 위해서 input context를 풍부하게 하며 input patch들을 변환하는 Prompt-as-Prefix(PaP) 방법론을 제안한다.
이렇게 변환된 시계열 patch들은 LLM으로 하여금 forecasting 문제를 풀 수 있게 한다. 그 결과 Time-LLM은 SOTA를 달성하여 강력한 time series forecasting learner임을 보였다. 이에 더해 Time-LLM은 few-shot과 zero-shot learning 시나리오에도 뛰어나다고 한다.
Introduction
Time series forecasting은 real-world의 동적 시스템의 다양한 도메인에 활용된다. 각 forecasting task들은 도메인 전문 지식과 task-specific한 모델 디자인을 필요로 하는데, 이는 광범위한 task를 커버할 수 있고, 데이터가 적어도 추론이 가능한 few-shot이나 zero-shot이 가능한 언어 모델과 극명한 차이를 보인다.
LLM은 Vision과 NLP 분야에 굉장히 빠르게 적용됐지만, 시계열의 경우에는 그 이점을 충분히 누리지 못했다. 그러나 시계열 예측 분야에서 LLM에 영감을 받아 이것의 이점을 활용하고자 하는 연구가 진행되고 있다.
-
Generalizability - LLM이 few-shot, zero-shot transfer learning을 잘 수행한다는 것은 이미 입증이 됐다. 이러한 특징은 forecasting에서 domain간에 다른 특징 때문에 retrain하는 번거로움 없이 일반화 성능이 높은 모델을 구축할 수 있게 한다.
-
Data efficiency - LLM은 이미 사전학습이 되어있기 때문에 적은 양의 데이터로도 새로운 task에 대해서 좋은 퍼포먼스를 보인다. 시계열이 고질적으로 가지고 있던 데이터 부족 현상(특히, in-domain data)은 이러한 LLM의 특징으로 완화될 수 있다.
-
Reasoning - LLM의 정밀한 추론과 패턴 인식 능력은 고수준(high-level)의 개념을 잘 인식하여 정확한 forecasting이 가능하도록 한다. LLM이 아닌 모델은 이러한 내재적인 추론 능력보다 통계적인 방법 위주로 예측을 진행한다.
-
Multimodal knowledge - LLM 구조와 학습 테크닉의 발전에 따라, text 뿐만 아니라 vision, speech 등 다양한 지식들을 습득할 수 있게 됐다. 이러한 지식들을 활용하면, 서로 다른 데이터 타입을 융합한 시너지스틱한 예측이 가능하게 된다. 물론, 전통적인 방법들은 이와 같이 다양한 knowledge들을 공동으로 학습하는 방법이 부족하다.
-
Easy optimization - LLM은 거대 컴퓨터로 한 번 학습이 됐기 때문에 처음부터 학습할 필요 없이 forecasting과 같은 downstream task에 적용될 수 있다. 따라서 기존의 학습 모델들을 최적화 하는 것에 비하면 훨씬 쉽고 빠르다.
위와 같이 다양한 이점을 가지는 강력한 LLM을 시계열에 적용하면 아직 밝혀지지 않은 유의미한 포텐셜들을 포착해낼 수 있을 것이다.
하지만 이를 위해 time series와 natural language 데이터 간 align을 하는 데에서 몇 가지 문제가 생긴다.
우선, LLM은 discrete token에 의해서 작동되지만 time series는 continuous하며, time series pattern은 sequential 한 것은 맞지만 LLM이 사전학습한 자연어의 패턴과는 근본적으로 다르다.
따라서 본 논문에서는 reprogramming framework를 통해 LLM을 backbone으로 해서 time series forecasting에 적용하는 Time-LLM을 제안한다.
핵심 아이디어는 time series input을 text prototype representation으로 reprogram 해서 language model에 맞게 transforming 한다는 것이다.
그리고 모델의 time series 추론 능력을 강화시키기 위해서 context를 추가하여 input time series를 더 풍부하게 만들고, 자연어 modality로 task guidance를 제공하는 아이디어인 Prompt-as-Prefix(PaP)라는 것을 새롭게 제안한다.
(이는 reprogrammed input에 적용할 변환에 대해서 declarative guidance를 제공하고, language model의 output은 time series forecast를 생성하기 위해 projection 된다고 함.)
또한, 논문은 reprogramming approach를 통해 LLM이 few-shot, zero-shot에 대해서 시계열 학습 모델로 동작할 수 있음을 실험을 통해 입증했고, forecasting task에 specific하게 디자인된 모델의 성능을 능가했다고 한다.
뿐만 아니라, 모델은 손대지 않고 LLM의 추론 능력만을 활용해서 자연어와 sequential 데이터 모두에게서 뛰어난 성능을 보이는 멀티모달의 기초 모델로 향하는 길을 제시했다고 하며, 논문에서 제안한 reprogramming framework는 기존의 사전 학습을 넘어서 새로운 능력을 대형 모델에게 부여하기 위한 확장 가능한 패러다임을 제공했다고 한다.

Related work
-
Task-specific Learning - 대부분의 time series forecasting 모델들은 특정 task나 domain에 특화되어 small-scale data를 end-to-end로 학습한다.
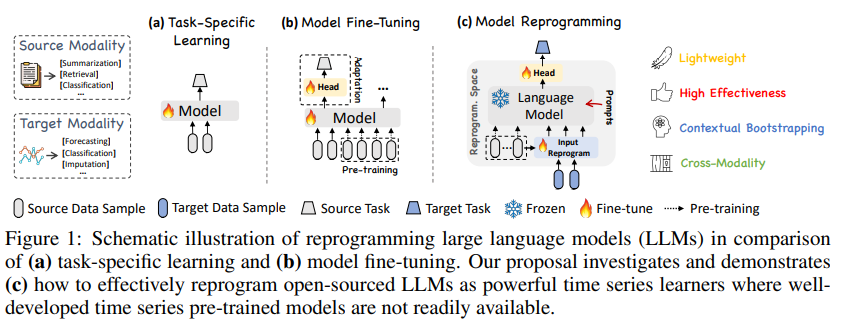
예를 들어, Figure 1-(a)에서 처럼 ARIMA나 LSTM, transformer 등 longer temporal dependencies를 포착하기 위해서 굉장히 많은 연구가 진행됐었지만 좁은 풀의 task에서 좋은 퍼포먼스를 달성해도 다양한 time series data에 대해서는 다양성과 일반화 성능이 부족한 것이 사실이다. -
In-modality Adaptation - Figure 1-(b)처럼 CV나 NLP의 pre-trained model들은 다양한 downstream task에 fine-tuned를 통해 적합되므로 training cost가 굉장히 효율적이다. 이러한 사전 학습 모델에서 영감을 받아 시계열 사전 학습 모델을 구축하기 위한 노력이 있었다(supervised or self-supervised). 이러한 모델들은 다양한 시계열 데이터를 학습해서 비슷한 도메인의 downstream task에 fine-tuned 할 수 있었다. 그러나, NLP나 CV에서 처럼 굉장히 큰 스케일의 데이터셋이 없기 때문에 (데이터 희소성 때문) 결국 한계를 극복하지 못했다.
-
Cross-modality Adaptation - 최근에는 multimodal fine-tuning, model reprogramming 등의 방법론을 통해 NLP나 CV와 같이 사전 학습이 충분히 된 모델의 지식을 time series model에 이전시키는 연구가 진행되었다.
이 논문에서 제안하는 방법 또한 이와 같은 카테고리이지만, 기존에 시계열 데이터에 적용시키려는 관련 연구가 제한적이었다.
[Voice2Series] : 음성 인식에서 사용되는 음향 모델(Acustic Model, AM)을 시계열 분류 문제에 적용하기 위해 시계열을 AM에 적합한 형식으로 수정했다.
[LLM4TS] : 시계열에 대한 supervised pre-trained 후, task specific fine-tuning을 하는 두 단계의 fine-tuning 과정을 거친다.
[One Fits All] : self attention과 feed forward를 수정하지 않고 pre-trained된 언어 모델을 사용한다. 이 모델은 다양한 시계열 분석 task들에서 fined-tuned 및 evaluate 되었으며, 사전 학습된 언어 모델로부터 지식을 전이시켜 SOTA를 달성했다.
이러한 방법들과는 달리, 이 논문은 input time series나 backbone LLM을 fine-tuning하지 않는다 .대신, Figure 1-(c)처럼 원본 데이터의 modality와 prompting을 사용해서 LLM을 하나의 효과적인 시계열 분석 모델로 사용하기 위해 reprogramming을 진행한다.
Methodology
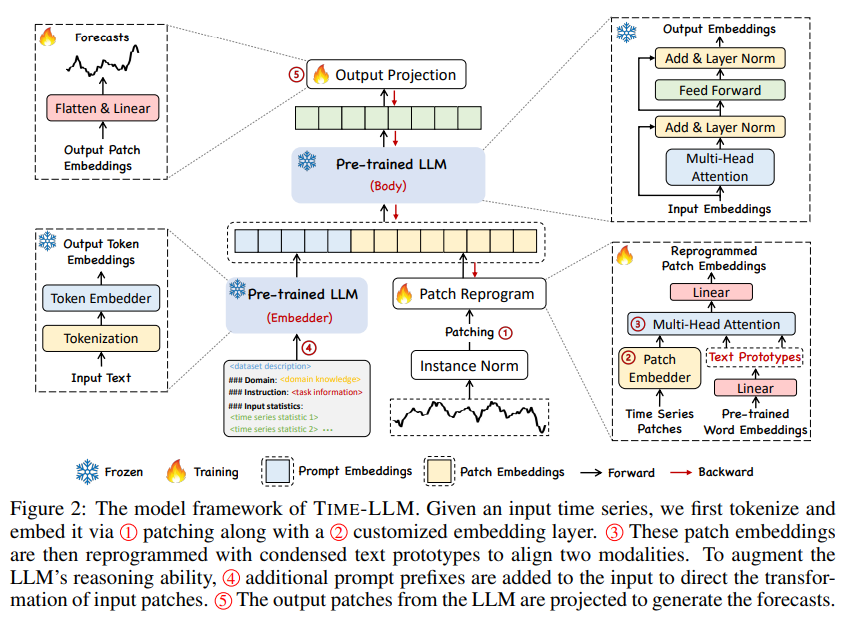
위 그림은 Time-LLM의 전체적인 architecture이다. Llame나 GPT-2와 같은 embedding-visible 언어 기반 모델을 fine-tuning할 필요 없이 reprogramming을 통해 general time series forecasting 한다.

기본적인 notation으로는, N개의 서로 다른 1차원 변수가 T time steps 만큼 있다면 X는 위와 같이 표현된다. 그리고 LLM f()가 input time series를 이해하고, H time steps 만큼 forecast한 결과는 위의 수식과 같다. objective function은 MSE(Mean Squared Errors)로 설정했다.
Figure 2의 전체적인 아키텍쳐를 구성하는 요소들을 크게 나누면 다음과 같다.
1) input transformation
2) pre-trained and frozen LLM
3) ouput projection
다변량 시계열 데이터인 경우에는 N개의 단변량 시계열로 분해된다. i번째 시리즈는 로 나타낼 수 있고, 이러한 input은 학습된 텍스트 프로토타입으로 reprogramming 되기 전에, normalization, patching을 통해 source와 target의 modality를 align 하는 과정을 거친다.
최종 예측값인 은 output representation을 projection 시킨 값이다. output representation을 생성하기 위해 pre-trained LLM을 앞서 reprogram된 패치들과 함께 프롬프팅함으로써 LLM의 시계열 추론 능력을 강화시킨다.
학습은 backbone LLM model은 frozen 시키고, light weight input transformation과 output projection에 해당하는 부분만 tuned 되므로 cross-modality 쌍을 fine-tuning하는 vision-language나 다른 multimodal language model과 다르게 적은 양의 time series와 적은 training epoch만 있어도 쉽게 사용이 가능하다. 따라서 large domain-specific한 모델을 처음부터 학습하거나 fine-tuning 시키는 것보다 효율이 더 높고, 리소스 제약이 더 적다. 추후에 memory footprints(프로그램이 동작할 때 사용되는 메인 메모리의 양)를 더 줄이기 위해서는 기존의 양자화와 같은 방법론들을 통합하여 Time-LLM을 더 slim하게 만들 수 있을 것이라고 한다.
Model Structure
- Input Embedding :

각 Input 채널인 는 정규 분포로 표준화 시킨다. 이 때, normalization에 RevIN(Reversible Instance Normalization)을 사용하는데, 이는 시계열의 distribution shift를 완화시킬 수 있다.
그리고 을 몇 개의 overlap 혹은 non-overlap patch로 나눈다. 이 때 patch의 길이는 로 나타내고, input patch의 총 개수는 위에 P로 나타나있으며 이 때 S는 수평 방향으로 sliding 되는 stride이다.
여기서 가져가는 motivation은 크게 2가지이다.
1) 각 로컬 패치들의 정보를 집계해서 로컬 의미 정보를 더 잘 보존한다.
2) tokenization 역할을 해서 compact sequence of input tokens form을 만들고 이를 통해 computational cost를 줄인다.
그리고 위와 같은 과정을 거쳐서 patching이 됐을 때, 차원으로 embedding을 시키기 위해 simple linear layer를 태워서 patch embedder가 차원으로 embedding할 수 있도록 한다.
-
Patch Reprogramming : 앞서 진행한 patch embedding을 source data representation space로 modaltity를 align하는 reprogram 과정을 거쳐서 LLM backbone이 time series를 잘 추론할 수 있도록 한다.
기존에는 사전학습된 source model이 target data에 대해서 잘 추론하기 위해 parameter update 등의 tuning 과정을 거치지 않고, target input sample을 "noise" 형태로 학습해왔다. 이러한 방식은 유사하거나 동일한 data modality를 이어주는 데에는 실현 가능하다. 예를 들어, vision model을 cross-domain image에 대해서 reprogramming 한다던가, acoustic model을 통해 time series data를 핸들링 하는 것은 가능하다. 이러한 경우에는 source data와 target data 간에 명시적이고 학습 가능한 transformation이 존재하기 때문에 input sample에 직접적인 변환을 할 수 있다. 하지만 시계열을 자연어로 직접 변환하거나 정보 손실 없이 fine-tuning 할 수 없기 때문에 LLM이 시계열을 이해할 수 있도록 직접 bootstrap 해야하는 어려움이 있다.
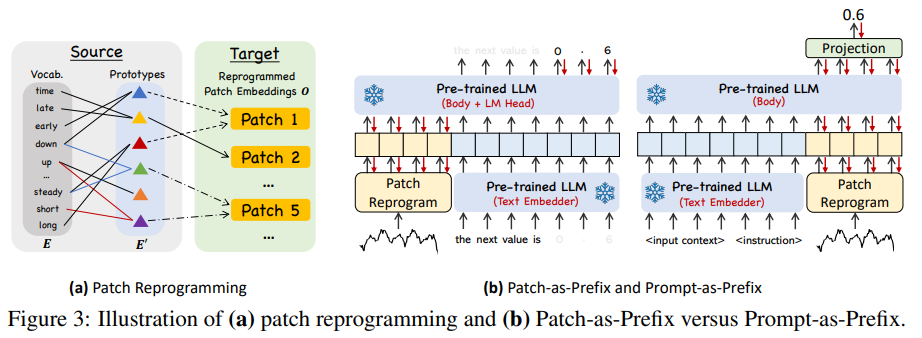
이러한 어려움을 극복하기 위해서 이 논문은 새로운 reprogramming method를 제안한다.
backbone에서 사전학습된 word embedding인 (where V is vocabulary size)를 사용해서 reprogramming된 를 제안한다.
하지만 word embedding을 알고 있다고 하더라도 어떤 token이 연관있는지에 대한 사전 지식은 없기 때문에 단순히 E를 활용하면 reprogramming space는 단지 더 크고 밀집된 형태로 도출될 것이다.
가장 간단한 솔루션은 E를 linearly probing(참고. https://jicoding.tistory.com/67)을 통해서 text prototype 집합으로 축소시키는 방법이다. 이 때, linearly probing 는 , where 로 나타낸다.
위와 같은 작업은 Figure 3-(a)에서 확인할 수 있다. text prototypes는 앞의 word embedding으로 부터 language cues를 학습하는데, 예를 들면 빨간색 선으로 이루어진 prototype은 "short up", 파란색 선은 "steady down"을 나타낸다. 이렇게 구축된 text prototype들은 pre-trained language model space를 벗어나지 않고 local patch information과 결합할 수 있게 된다 (예를 들면, 시계열 patch 5에 대해서 "short up then down steadily"라는 자연어로 시계열 patch의 특성에 관한 설명이 가능함).
위 수식에서 볼 수 있듯이, 앞에서 구했었던 patch embedding과 text prototype은 multi-head attention을 통해서 결합된다. 이 때, query 값으로 patch embedding이 들어가고, key와 value에는 pre-trained model의 text prototype이 들어간다. 그리고 LLM backbone의 hidden layer의 dimension에 맞게 linear projection을 한 결과가 논문에서 말하는 reprogramming이고, 결과적으로 time series patch embedding과 LLM의 text prototype의 결합으로 LLM backbone이 time series를 이해할 수 있게 된다. -
Prompt-as-Prefix : Prompting은 LLM에게 하나의 guidance가 되어 task-specific하게 동작할 수 있도록 해준다. 하지만 time series를 자연어로 직접 translation하는 것은 어려운 문제이므로 데이터셋에 대한 guidance나 성능 저하 없이 prompting하는 것을 방해한다.
그래도 최근 연구들에서 image와 같은 분야에 prefix-prompt를 통해 input data에 대한 추론 성능을 높인 사례가 나타났다. 이러한 연구 결과에서 영감을 받아 본 연구에서는 real-world time series에 직접 적용하여 prompt가 input의 prefix에서 동작하여 input context를 더 풍부하게 만들고, reprogram된 time series patch의 가이드 역할을 할 수 있는지를 생각한다.
논문은 이에 대해 Prompt-as-Prefix(PaP)라고 부르며 LLM이 downstream task에 유의미하게 적응 가능한지를 실험한다. Figure 3-(b)에서 두 가지 방식이 나온다. -
Patch-as-Prefix : 언어 모델이 자연어로 표현된 시계열에서 다음 값을 예측하도록 요구된다. 그러나 이 방법은 몇 가지 제약 사항이 있다.
1) 언어 모델은 일반적으로 외부 도구의 도움 없이 고정밀 수치 값을 처리하는데에 민감하지 못하다. 따라서 long term prediction을 실용적으로 하는 데에 어려움이 있다.
2) LLM은 다양한 말뭉치로 사전 훈련 되었기 때문에 고정밀 수치로 다시 생성할 때 토큰화 유형이 달라질 수 있다. 따라서 다양한 언어 모델에 대해 정교하고 맞춤형 후처리가 필요하다. 예를 들면, 이 제약으로 인해서 0.61이라는 값의 소수점을 표현하기 위해서 언어 모델로 토큰화를 하면 어떤 모델은 ['0', '.', '6', '1']로 나오고, 어떤 모델은 ['0', '.', '61']로 나오기도 한다. -
Prompt-as-Prefix : 반면에 Prompt-as-Prefix는 위에서 나온 제약을 피해간다. 논문 저자들은 효과적인 prompt를 구축하기 위해서 3가지 중요한 요소들을 식별했다.
1) data context
2) task instruction
3) input statistics
이 요소들을 고려한 프롬프트 예시는 아래와 같다.

dataset context는 LLM에 입력 시계열에 대한 필수적인 배경 정보를 제공하여 다양한 도메인에서 종종 독특한 특성을 나타낸다.
task instruction은 LLM이 특정 작업을 위해 patch embedding을 변환하는 데에 중요한 안내 역할을 한다.
input statistics를 통해 trend나 lag와 같은 input time series에 대한 추가적인 통계적 특징을 더 풍부하게 할 수 있고, 패턴 인식 및 추론을 더 잘 할 수 있게 한다. -
Output Projection : Figure 2에서 볼 수 있듯이 prompt와 패치 임베딩 O(i)를 frozen LLM을 통해 packing하고 feedforwarding한 후, prefix 부분을 버리고 출력을 얻는다. 그 후에 출력값을 flatten하고 linear projection하면 최종 forecasting 결과인 값이 도출된다.
Main Results
Time-LLM은 time series forecasting task에서 SOTA를 달성했고, 특히 few-shot과 zero-shot 시나리오에서 더 큰 성능 차이를 보였다. 성능 비교를 하기 위해서 최근 각광받고 있는 transformer-based model들과 benchmark에서 상위권 성능을 보이고 있는 GPT4TS, LLMTime, DLinear,N-HiTS 등 다양한 모델들과 비교했다.
Long-Term Forecasting
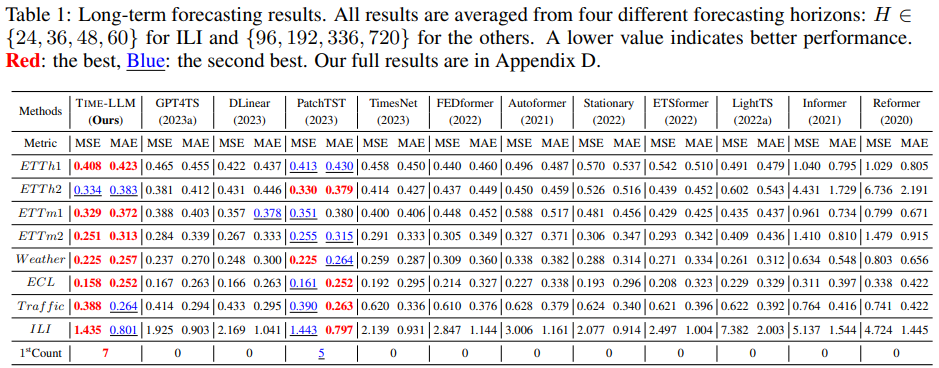

Table 1에서 볼 수 있듯이 TIME-LLM이 대부분의 경우에서 모든 Baseline을 능가했으며, 특히 GPT4TS와 비교했을 때 유의미한 성능 차이를 보였다. GPT4TS는 LLM을 Time series에 적용한 최신 논문으로, LLM backbone을 fine tuning하는 과정을 포함한다. TIME-LLM은 GPT4TS와 TimesNet에 비해 각각 평균 12%와 20%의 성능 향상을 보였고, SOTA를 찍은 Transformer 모델인 PatchTST와 비교했을 때에도 TIME-LLM은 가장 작은 Llama를 Reprogramming하여 평균 MSE를 1.4% 감소시켰다. DLinear와 같은 다른 모델에 비해서도 TIME-LLM은 12% 이상의 두드러진 성능 향상을 기록했다.
Short-Term Forecasting
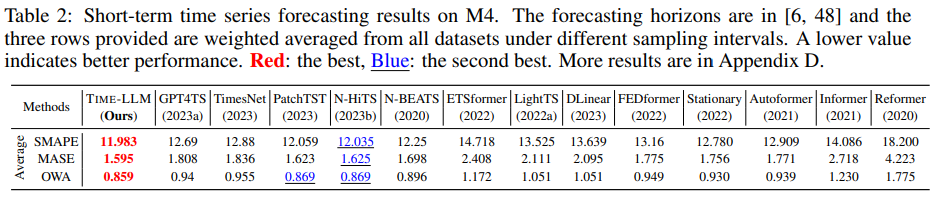

Table 2에서 볼 수 있듯이 Short-term forecasting에서도 TimeLLM은 baseline들의 성능을 모두 뛰어넘는다. 특히, 모든 지표에서 GPT4TS보다 우수하다는 점과 기존의 SOTA 모델인 N-HiTs를 능가하는 성능을 보였다는 것이 눈여겨 볼 부분이다.
Few-shot Forecasting
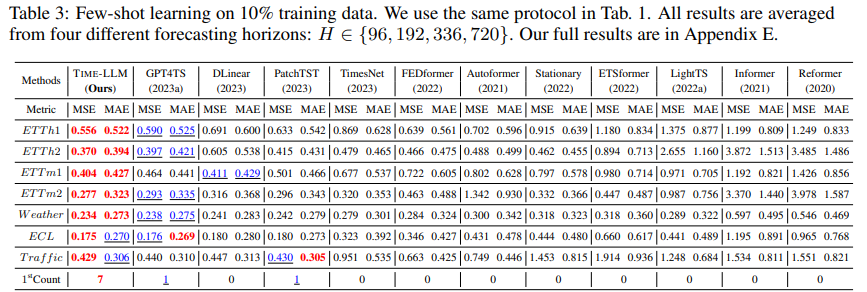
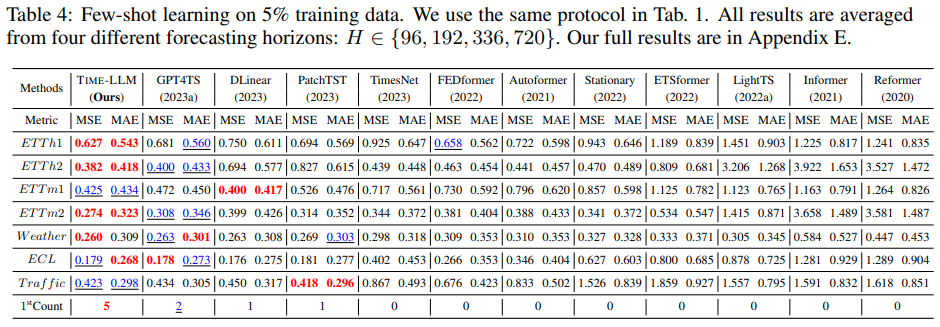

few-shot을 가정하고 평가하기 위해서 training data의 처음 5%, 10%만을 사용해서 학습을 진행했다.
10% 및 5% few-shot 학습 결과는 각각 Table 3과 Table 4에 나타나 있다. TIME-LLM은 모든 Baseline 방법론들을 뛰어넘는 성능을 보여주었으며, 이는 Reprogramming된 LLM에서 knowledge가 성공적으로 활성화 되었음을 뒷받침한다. 또한, TimeLLM과 GPT4TS가 다른 Baseline들의 성능을 능가하는 것으로 미루어 보았을 때, 언어 모델이 시계열 예측에서 뛰어난 성능을 발휘할 잠재력이 있음을 나타낸다.
10% few-shot 학습
- TimeLLM은 GPT4TS에 비해 MSE를 5% 감소시켰으며, LLM에 대한 fine tuning 없이 이 성과를 달성했다.
- 최신 SOTA 모델(PatchTST, DLinear, TimesNet)과 비교할 때, 평균적으로 MSE가 각각 8%, 12%, 33% 이상 향상되었다.
5% few-shot 학습
- GPT4TS에 비해 평균 5% 이상의 성능 향상을 보였다.
- PatchTST, DLinear, TimesNet과 비교했을 때, TIME-LLM은 MSE에서 평균 20% 이상의 유의미한 성능 향상을 보여주었다.
Zero-shot Forecasting
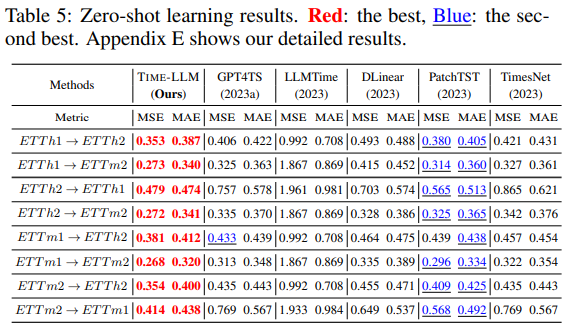
Zero-shot Forecasting을 실험하기 위해서 실험 데이터셋을 cross-domain adaptation 환경을 만들었다. 즉, 화살표(->) 이전 데이터셋으로 학습한 모델이 화살표(->) 이후 데이터셋에 얼마나 잘 적용될 수 있는 지에 대해서 평가했다.
Table 5에 결과를 보면, TIME-LLM이 경쟁력 있는 baseline 모델들을 큰 차이로 능가했다. 특히 MSE 감소 측면에서 두 번째로 좋은 모델에 비해 14.2% 이상의 성과를 보였다. few-shot 학습 결과를 보면, LLM을 Reprogramming하면 데이터가 부족한 상황에서도 훨씬 더 나은 결과를 얻을 수 있었다. 예를 들어, GPT4TS와 비교했을 때 10% few-shot 예측에서 7.7%, 5% few-shot 예측에서 8.4%, 제로샷 예측에서 22%의 전반적인 오류 감소를 달성했다.
가장 최근의 접근 방식인 LLMTime과 비교해도, TIME-LLM은 유사한 크기(7B)의 백본 LLM을 사용하면서 75% 이상의 상당한 개선을 보여줬다. 이는 TIME-LLM이 시계열 task를 수행할 때 자원을 효율적인 방식으로 사용해서 LLM의 knowledge transfer 및 reasoning 능력을 더 잘 활성화할 수 있었기 때문이다.
이 결과는 TIME-LLM이 시계열 예측에서 뛰어난 성능을 발휘하며, 특히 데이터가 부족한 상황에서도 매우 효과적임을 보여줬다. 이를 통해 시계열 예측 작업에서 우리의 접근 방식이 얼마나 유망한지 확인할 수 있었다.
Model Analysis
-
Language Model Variants :
위에서처럼 용량이 다른 두 대표적인 backbone을 비교한다(Llama, GPT-2)
LLM의 기본 가정에는 모델의 용량이 커질수록 성능이 높아진다는 스케일링 법칙(물리의 상전이 현상과 유사함. 어느 정도의 용량을 넘어가게 되면 성능이 비약적으로 상승하는 현상이 기존 PLM(Pre-trained Language Model)에도 있었고 여기서 착안된게 LLM임.)이 존재하는데 이 실험 결과에서도 Reprogramming을 통해 시계열 데이터를 처리함에도 이 법칙이 깨지지 않음을 보여준다. -
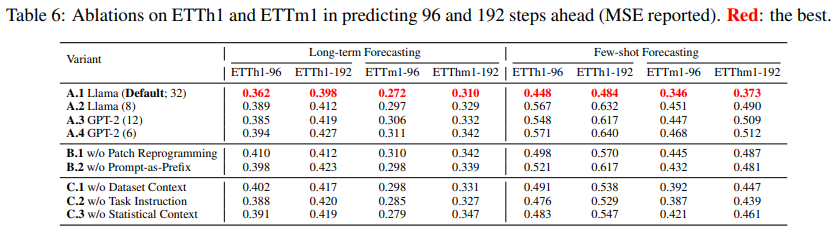
Cross-modality Alignment : 위의 Table 6에서 볼 수 있듯이 Patch Reprogramming이나 Prompt-as-Prefix를 제거하면 LLM이 시계열 예측을 효과적으로 하는 '지식 전이'현상에 문제가 생겨서 성능이 저하된다. 즉, Reprogramming과 Prompting 모두 시계열 예측에 중요한 역할을 하며, reprogramming을 통해 두 modality 간의 표현 정렬이 필수적이고, 외부 지식이 prompt를 통해 자연스럽게 input과 통합되며 모델의 학습과 추론을 용이하게 할 수 있다는 것을 알 수 있다.
-
Reprogramming Interpretation :
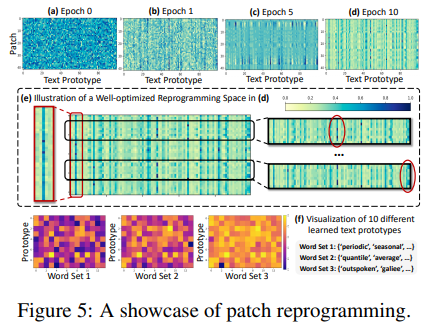
Figure 5에 ETTh1 데이터셋의 48개 시계열 패치를 100개의 텍스트 프로토타입으로 재프로그래밍한 사례를 제시했다. 상위 4개의 서브플롯은 랜덤 초기화(a)에서 최적화된 상태(d)로 optimization of reprogramming space를 시각화한다. 서브플롯(e)에서 소수의 프로토타입(column)만이 입력 패치(row)의 reprogrammnig에 참여하는 것을 발견했다. 또한, 패치들은 다양한 프로토타입의 조합을 통해 다른 표현으로 변화한다.
이는 다음과 같이 해석될 수 있다.
1. 텍스트 프로토타입은 language cue를 요약하는 것을 배우고, 일부 선택된 프로토타입이 지역 시계열 패치의 정보를 표현하는 데 매우 관련성이 높다. 이는 서브플롯(f)에서 무작위로 선택한 10개를 시각화하여 확인할 수 있다. 그 결과, 시계열 속성을 설명하는 단어 집합(단어 세트 1과 2)과 높은 관련성을 나타냈다.
2. 패치들은 보통 다른 기본 의미를 가지므로, 이를 표현하기 위해 다양한 프로토타입이 필요하다.
- Reprogramming Efficiency :

Table 7에서 TIME-LLM의 백본 LLM을 사용한 경우와 사용하지 않은 경우의 전체 효율성을 분석했다. 제안된 재프로그래밍 네트워크 자체(D.3)는 시계열 예측을 위한 LLM의 능력을 활성화하는 데 경량화되어 있으며(약 660만 개의 학습 가능 파라미터, Llama-7B의 전체 파라미터의 약 0.2%에 불과함), TIME-LLM의 전체 효율성은 실제로 활용된 백본(D.1과 D.2)에 의해 제한된다. 이는 QLoRA와 같은 파라미터 효율적인 fine tuning 방법과 비교했을 때, 작업 성능과 효율성의 균형을 맞추는 데 유리하다.
Conclusion and Future Work
Time-LLM은 LLM에 맞게 시계열을 더 자연어적인 text prototype으로 reprogramming해서 frozen LLM에 시계열 데이터를 적용시키는 모델이다. 그리고 Prompt-as-Prefix(PaP)를 통한 자연어 guidance를 제공해서 추론 능력을 강화시켰다.
또한, 모델 평가를 통해 시계열에 adapted된 LLM이 기존의 task-specific한 시계열 모델보다 더 우수한 성능을 보임으로써 시계열 처리에 잠재적인 능력이 있다는 것을 보였다.
결과적으로 시계열 예측을 하나의 'language task'로 볼 수 있다는 새로운 관점을 제시하고, Time-LLM을 통해 높은 성능을 달성할 수 있다는 것을 보여준다.
Future work로는 최적의 reprogramming method를 탐구하고, 지속적인 사전 훈련을 통해 명시적인 time series knowledge를 LLM에 전달하며 시계열, 자연어 외에 다른 모달리티 간의 공동 추론을 할 수 있는 multi-modal model을 구축하는 방향성을 제시한다.
또한 reprogramming을 통해 LLM에 더 넓은 시계열 분석 능력이나 다른 기능을 더할 수도 있다.
