IMAGENET-TRAINED CNNS ARE BIASED TOWARDS TEXTURE; INCREASING SHAPE BIAS IMPROVES ACCURACY AND ROBUSTNESS 리뷰
Abstract
CNN(Convolutional Neural Networks)이 일반적으로 물체(이미지)를 인지하는 방법은 물체의 형태(shape)의 점점 더 복잡한 표현들을 학습하는 것임.
하지만 몇 연구에서는 shape이 아니라 texture를 학습한다고 함.
따라서 이 논문에서는 과연 CNN이 이미지 인식에서 shape과 texture 중 어떤 특성을 주로 기준으로 잡는지 알아보려 함.
이를 위해서 텍스쳐 기반 모델이 Image-Net에 Style transfer를 추가한 Stylized-ImageNet에서 shape를 학습할 수 있다는 가설을 검증하는 실험을 진행함.
인간의 물체 인식과 비교해보기 위해서 97명의 관측자들을 대상으로도 실험도 진행했다고 함.
그 결과, 예상치 못한 이점을 발견했는데, object detection performance가 향상됐고, 이미지 왜곡에 대한 robustness를 볼 수 있었으며 shape-based representation의 장점들이 강조되었다고 함.
Introduction
CNN은 과연 어떤 cue(논문에서의 cue는 CNN이 이미지 인지를 위해 주로 학습하는 특성을 뜻한다. ex. texture, shape)에 의해서 이미지를 인지하고 판별하는지에 대한 의견이 분분하다.
우선, shape를 주로 반영한다는 가설이 있다.
이 가설은 경험적 탐색을 통해 뒷받침된다.
예를 들면, De-convolutional Networks는 high-level feature map에서 나타나는 물체의 형태가 low-level로 갈수록 어떻게 변하는 지에 대해서 강조한다.
high-level의 경우, edge와 같은 특성들을 추출하고, low-level로 갈수록 더 복잡한 특성들을 결합해가며 학습하기 때문에 CNN은 물체의 shape를 주로 학습하며 이를 통해 물체를 인지한다고 말한다.
이 가설을 뒷받침하는 많은 논문들이 있고, 이들은 결론적으로 CNN은 물체의 색, 사이즈, 텍스쳐와 같은 cue들이 아니라 shape에 영향을 많이 받으며, 인간 또한 물체를 인지할 때 shape를 통해서 인지한다고 말한다.
반면에 몇 논문들은 texture가 shape보다 더 중요한 cue라고 주장한다.
CNN은 shape 구조가 망가져도 여전히 texture에 따라 이미지를 잘 분류해낸다고 하며, 오히려 texture에 문제가 생기면 분류 성능이 나빠진다고 한다.
그리고 최근, ImageNet의 이미지들을 기존 shape-based model들이 학습하던 것보다 훨씬 작은 patch로 학습시켰음에도(shape를 통해 recognition하는 기준보다 더 작은 local patch) 굉장히 높은 성능을 낸 모델이 등장하기도 했다.
이러한 결과들을 보면 texture에 대한 가설 또한 고려할 때가 왔다고 논문에서는 말한다.
이와 같이 상반된 두 가설은 human vision과 neuroscience 두 집단 모두에게 중요하다. 따라서 이 논문에서는 신중한 실험 설계를 통해 직접적인 상관관계를 탐색하고자 한다.
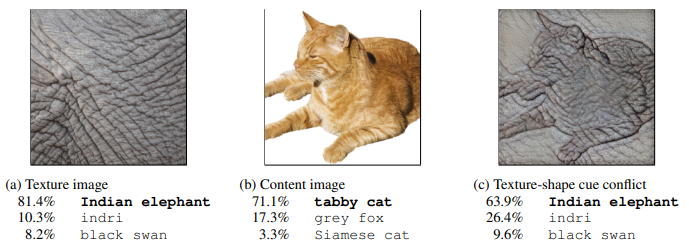
위 figure에서 볼 수 있듯이, style transfer를 통해 기존 이미지의 스타일을 변형시킨다. 이를 통해 인간과 CNN에서의 texture / shape bias를 살펴볼 수 있다.
위의 그림(c)에 대한 결과로는 CNN은 texture에 따라 Indian elephant로 예측했으나, 사람의 경우 shape에 영향을 더 많이 받아 여전히 cat으로 예측했다.
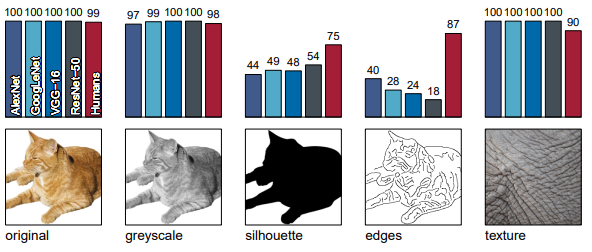
위의 그림을 보면 CNN 모델들은 texture에 영향을 많이 받으나 사람은 shape에 영향을 많이 받는다는 사실을 알 수 있다.
이 실험은 2가지 main contribution이 있다.
- texture bias를 갖는 CNN model들을 shape bias를 갖도록 변형함.
- 앞서 말했던 bias changing model들은 많은 이점들을 가진다는 것.
Methods
사람이 어떤 cue로 물체를 인지하는지를 실험을 통해 확인한다.
사람에게 다양한 사진을 보여주고 해당 사진을 classification 시키는 실험이다.
실험은 6개의 메인 실험으로 이루어져있고, 위의 figure에서 볼 수 있듯이 5개의 실험을 통해 인간과 CNN model들이 각각 어떤 bias를 갖고 있는지를 보기 위한 실험이다.
cue conflict를 적용하기 위해서 16개의 카테고리마다 80개의 이미지를 선별하여 1280개의 데이터셋을 구성했고, style transfer를 통해 cue conflict를 적용했다.
transfer를 진행하기 전 이미지에 대해서 CNN 모델들이 분류를 잘 해냈기 때문에 대조실험을 통해 어떤 cue에 영향을 받는지 설명할 수 있다.
이 논문에서는 shape와 texture를 명확히 구분한다.
우선 여기서 말하는 shape는 단순히 silhouette만을 말하지 않는다.
실루엣은 물체의 경계 윤곽을 나타내는 말이며, 논문이 다루는 shape는 이보다 더 넓은 범위의 의미이다.
예를 들면, 3D형태의 shape는 윤곽들의 집합이므로 실루엣에 포함되지 않는 윤곽들이 존재할 수도 있다.
텍스쳐의 경우, spatially stationalry statistics 특징을 가져야한다.
(텍스쳐가 같다는 것을 수학적으로 풀어쓴 말로 이해함)
단일 병은 정적이지만 여러 개의 병이 함께 있으면 서로 텍스쳐가 비슷할 수 있다.(?)
Result
grayscale은 shape와 texture의 특징을 모두 갖고 있다고 주장한다.
실루엣과 엣지에서는 사람과 CNN의 성능 차이가 심하다. 즉, 사람이 texture 정보가 없는 이미지에 더 잘 대응한다는 것을 나타낸다.
특히, CNN은 domain shift에 취약한 것으로 드러났다.
CNN 입장에서는 학습한 데이터가 natural image이고, texture가 앖는 sketch 이미지는 training때 사용되지 않은 이미지이다.
즉, sketch 이미지르 inference할 때는 완전히 다른 도메인을 추론한다고 볼 수 있다.
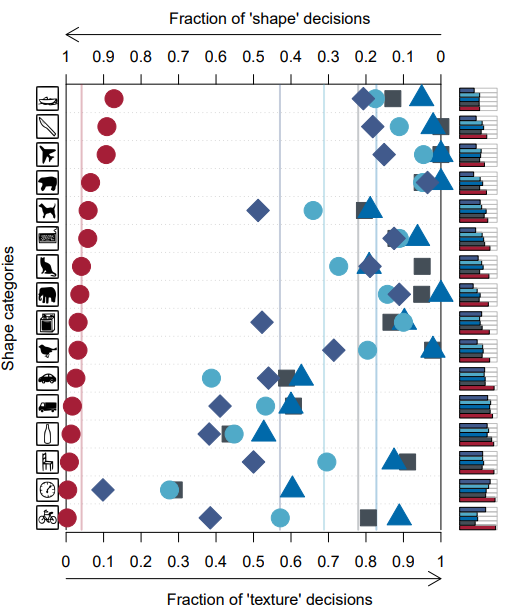
위의 그림에서 y축은 CNN 모델들고 ㅏ사람의 16개 모든 카테고리 classification 평균 결과이다.
좌측에 위치할수록 shape-based, 우측에 위치할수록 texture-based classification한다고 논문은 얘기한다.
앞선 실험을 통해 CNN 모델은 texture bias하다는 것을 알았고, 따라서 이 논문은 CNN이 많은 local texture features를 기반으로 classification한다고 추론했다.
그리고 실험에서 texture bias를 shape bias로 changing 시키려는 시도를 했다.
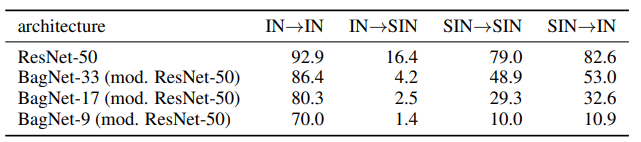
SIN은 Stylized-ImageNet, IN은 그냥 ImageNet이다.
위와 같은 결과가 나온 것으로 미루어 보았을 때, SIN 데이터로 학습된 CNN은 더 이상 텍스쳐 정보에 큰 영향을 받지 않기 때문에 SIN으로만 학습하고 evaluation하는것이 더 어려운 task임을 보여준다.(특히, IN으로 학습하고 SIN에서 evaluation 할 때)
하지만 shape bias로 changing된 결과, SIN으로 학습해도 IN에서 괜찮은 성능을 보인다.
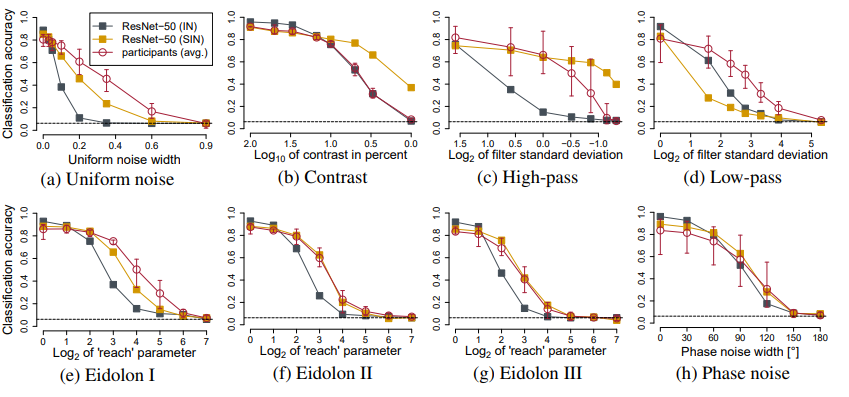
결국 이들이 말하고자 하는 것은 SIN 데이터셋 자체가 학습하는데 매우 robust하다는 것이다. 위의 그림처럼 이미지에 여러 noise를 추가해서 model(IN)/model(SIN)/human에게 분류 작업을 시켰을 때, model(SIN)이 인간과 가까운 성능을 보였음을 알 수 있다.
즉, 기존에 알고 있던 것과 달리 CNN은 shape를 학습하는 것이 아니라, texture를 학습하는 것이다.
SIN 데이터 셋을 일반 데이터셋처럼 활용하면 더 robust한 모델을 만들 수 있으며, SIN 데이터셋 자체가 robust한 모델을 만들 수 잇는 이미지 source이다.
[참조]
https://bluediary8.tistory.com/39
https://89douner.tistory.com/247
