Unsupervised embedded feature learning for deep clustering with stacked sparse auto-encoder
Abstract
이 논문은 딥 클러스터링이 클러스터링 문제에 도움이 되는 특징을 찾기 위해 노력하는데, 기존 딥 클러스터링 방법에는 지역 구조와 입력 데이터의 희박한 특성을 고려하지 못하는 단점이 있다.
그래서 논문은 sparse embedded clustering 방법을 제안하며, 이는 지역 구조를 보존하고 sparse한 특성을 고려하여 특징을 찾도록 훈련된다.
제안된 방법은 클러스터링과 재구성 손실을 사용하여 입력 데이터의 특징을 포착하며, 재구성 손실은 특징 공간을 망가뜨리지 않고 지역 구조를 보존한다.
또한 encoder에 sparse constraint를 추가하여 중요하지 않은 특징을 배우지 않도록 한다.
제안된 방법은 재구성 및 클러스터링 손실을 최소화하여 클러스터링 중심의 특징을 함께 학습하고 클러스터 레이블을 최적화할 수 있다고 한다.
Introduction
클러스터링은 unsupervised machine learning의 대표적인 방법론이다.
클러스터링 알고리즘의 목표는 유사한 데이터들이 동일한 특정 클러스터에 밀집하고, 각 클러스터끼리는 분리되게 나타내는 것이다.
전통적으로 K-means, DBSCAN처럼 다양한 클러스터링 기법이 있었지만, 데이터 크기와 차원이 증가하면서 고전 알고리즘들은 이러한 데이터들에 굉장히 비효율적이기 때문에 사용하기가 어려워졌다.
따라서 large scale image dataset과 같이 최근 연구되는 데이터셋들을 어떻게 군집화할 것인지가 challenge이다.
이에 대해서 fCM(fuzzy C-Means), deep clustering, IDEC(Improved Deep Clustering) 등 다양한 방법론들이 탄생했다.
최근 real-world image data는 고차원 특성을 띄고, 그만큼 불필요한 정보 또한 많이 담고 있다.
이러한 불필요한 정보들은 DEC와 같은 auto-encoder 기반의 전통적인 알고리즘이 feature learning을 제대로 하지 못하게 한다.
때문에 논문에서는 Deep Stacked Sparse Embedded Clustering(DSSEC) 방법론을 제안한다.
- sparse auto-encoder를 쌓은 구조로 더 효율적인 feature learning이 가능하도록 한다.
- hidden layer의 sparse constraint를 통해 local structure preservation strategy(?)를 개선한다. 이에 따라 더 대표되는 feature를 학습할 수 있다고 한다.
- sparse embedded representation learning을 적용하는 데에 새로운 관점을 제시한다.
- image clustering에서 비교군(다른 클러스터링 알고리즘)에 비해서 outperform을 달성했다고 한다.
Related works
이 파트에서는 기반이 되는 알고리즘인 auto-encoder와 deep clustering에 대해서 언급한다.
-
deep clustering
Deep Clustering은 단일 dnn상에서 feature representation과 clustering을 함께 수행하는 프로세스이다.
이 알고리즘은 크게 두 form으로 나눌 수 있다.- 첫 번째 타입: embedded representation learning과 clustering을 두 개의 단독 프로세스 과정으로 학습하는 것.
PCA나 Auto-encoder로 feature를 학습하고, clustering에 직접 사용하는 방법
Marginalized Graph Auto-Encoder(MGAE), Infinite Ensemble Clustering(IEC) 등이 있음 - 다른 deep clustering 타입은 clustering과 embedded representation learning을 동시에 최적화 시키는 방법이다. (이전글에 나와있는 deep fuzzy clustering 논문 또한 이와 같은 방법론)
Deep Embedding Clustering(DEC)와 Improved Deep Embedded Clustering(IDEC)가 대표적인 모델
- 첫 번째 타입: embedded representation learning과 clustering을 두 개의 단독 프로세스 과정으로 학습하는 것.
-
Auto-encoder
auto encoder의 가장 기본적인 구조는 input data의 특징을 추출하고, 이를 재구축하여 input data와 reconstruction data 간의 차이를 줄여 최대한 input data의 특질을 잘 추출하도록 하는 것이다.
AE는 사람들에게 각광받았던 모델인 만큼 다양한 바리에이션이 존재한다.
Variational Auto-Encoder(VAE), Multi-modal Deep Auto-encoder(MDA) 등
하지만 이러한 모델들은 large scale image data를 clustering하기 적합하진 않고, 보통 샘플을 생성하는 성능을 극대화 하거나 text data에 적합한 모델들이다.
때문에 최근에는 Sparse Auto-Encoder(SAE)를 통해 high-dimensional data를 처리하는 연구가 지속되고 있다.
SAE는 representation이 embedded layer에서 sparsity를 유지하도록 하는데, 이 말은 embedded representation이 모든 정보를 다 들고 있는 것이 아니라 중요한 정보에만 집중하도록 하는 것이다.
이러한 특징은 고차원 데이터를 클러스터링 하는데 유용하다.
Deep Stacked Sparse Embedded Clustering
DEC는 클러스터링에서 좋은 성능을 달성했지만, 고차원 데이터처리와 가혹한 외부 조건(harsh external condition)으로 인해 DEC 내 Auto-encoder가 좋지 못한 영향을 받는 문제가 있다.
이러한 문제를 극복하기 위해서 논문은 AE를 Stacked Sparse Auto-Encoder(SSAE)로 대체한 Deep Stacked Sparse Embedded Clustering(DSSEC)을 제안한다.
-
Network Structure
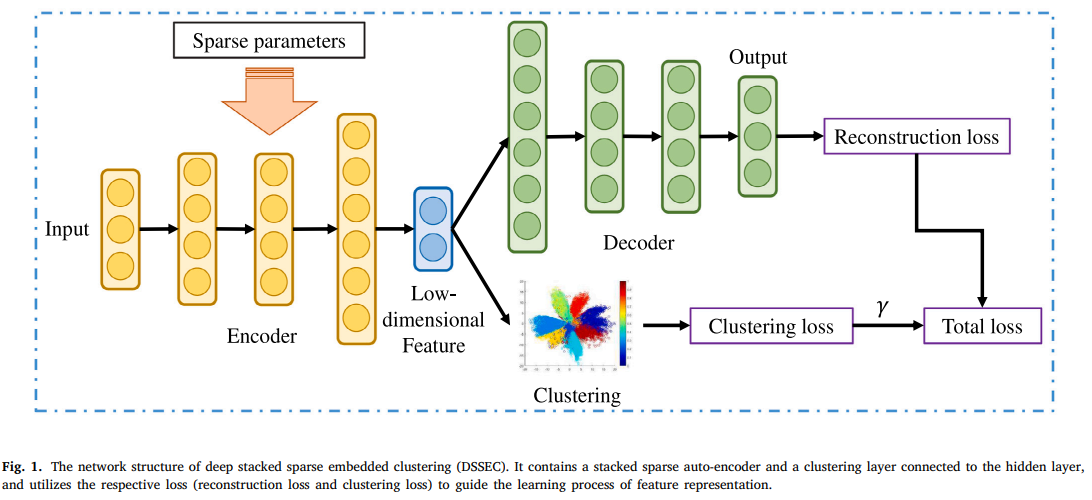
논문은 위의 사진과 같은 구조를 제안한다.
기존 AE와 동일하게 input data 에서 embedded feature representation 를 추출한다. 이 때, 기존 구조와 다른점은 Sparse parameter를 추가하여 embedded representation에 sparsity를 부여한다는 점이다.
그리고 clustering layer 부분에서는 embedded feature space 상의 representation point 에 soft label을 부여하고, clustering loss를 통해 최적화를 진행한다.
clustering loss는 KL-Divergence로 target 분포와 soft label분포 간 유사도를 계산하는 방식으로 이뤄진다. (이후 자세히 설명)
그리고 최종적으로 논문에서 제안하는 DSSEC의 목적함수는 다음과 같다.
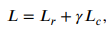
은 위의 그림에서 볼 수 있듯이 decoder의 결과 값을 통해 계산된 reconstruction loss이고, 는 clustering loss이다.
이 때, 는 feature space 상의 왜곡 정도를 조절할 수 있는 상관계수라고 한다.
( 일 때, DEC의 loss와 유사함) -
Clustering loss
Clustering loss는 DEC에서 제안된 것을 이 논문에서도 따른다.
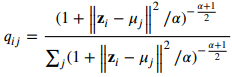
encoder를 통해 차원 축소된 feature representation 가 있을 때, 우리는 soft label 분포 를 위와 같이 Student's-t distribution에 따라 구할 수 있다.
는 embedded layer에 나타난 representation point이고, 는 j번째 cluster의 center이다.
는 t분포에서 사용되는 자유도(degree of freedom)이고, 논문에서는 1로 값을 고정한다.
위 수식의 의미는 sample 는 representation point가 이고, 이 와 의 유사도를 구한다는 것이다.
즉, 가 cluster 에 속하게 될 확률을 구하는 것이다.
그렇다면 target distribution인 를 구해봐야 한다.
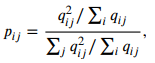
는 를 제곱한 후, 클러스터 당 빈도(?)수로 정규화를 진행하여 해당 클러스터에 속할 것이라는 신뢰도를 높이는 방식으로 계산된다.
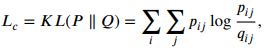
이렇게 계산된 와 분포간의 유사도를 KL-Divergence를 통해 계산하여 Clustering loss를 구한다. -
Local structure preservation
만약 clustering loss만 사용한다면 feature learning에서 중요하지 않은 정보를 학습하는 왜곡이 일어났을 때, clustering performance에서 좋지 않은 영향을 미칠 것이다.
따라서 reconstruction loss를 추가해주는데, 논문에서는 DEC와 같이 AE 네트워크가 아닌 SSAE로 대체했으므로 이에 맞게 loss function을 설정한다.
AE와 SSAE의 가장 큰 차이점은 hidden layer에 sparse constraint를 주는가 이다. SSAE의 경우 sparse 제약을 주기 때문에 hidden units가 많더라도 중요한 embedded feature를 계속 탐색하는 방식을 취할 수 있다.
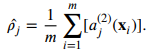
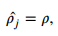
위의 식에서 input 에 대해서 hidden unit 가 activation 되려면 첫 번째 수식과 같고, 에 sparse constraint를 주면 두 번째 수식을 따른다.
는 sparsity parameter이고, 보통 0에 가까운 값으로 세팅된다.
와 가 유의미하게 유사도가 다른지를 reconstruction loss의 penalty term으로 준다.
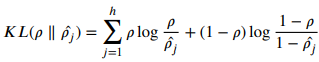
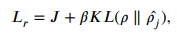
-
Optimization Strategy
먼저, 네트워크는 stacked auto-encoder의 초기 target distribution에 대해 pre-trained 되어있고, initial cluster center는 K-Means를 통해 생성된다.
Clustering loss의 경우, DEC를 따르기 때문에 gradient descent 또한 아래와 같이 DEC 기법과 동일하게 가져간다.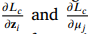
이로써 DSSEC는 SGD를 통해 backpropagation을 하여 encoder-decoder, cluster center를 직접적으로 업데이트할 수 있다.
그리고 라벨링의 경우, 당연한 얘기겠지만 가장 높은 확률로 속하는 클러스터가 라벨이 된다.
그리고 computing적으로 세부 동작 및 threshold setting을 구현해서 학습을 하기 때문에 다음과 같은 pseudo-code를 보면 이해가 더 쉬울 것이다.

Experiment Analysis
-
Data sets
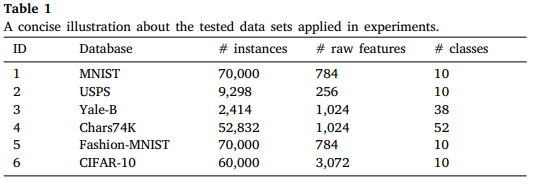
실험은 위와 같은 데이터 셋들에서 진행되었다. -
Parameter settings
비교 모델군은 다음과 같은 조합으로 이루어져 있다.
<clustering 모델>
1) PCA + K-Means
2) AE + K-Means
3) SAE + K-Means
4) LCAE + K-Means
<deep clustering 모델>
1) DEC
2) IDEC
3) DSSEC
clustering 모델군에 대해서는 dimension을 10으로 수정했다.
encoder는 d-500-500-2000-10 size (d는 input dimension)
decoder는 10-2000-500-500-d size (d는 output dimension == input dimension)
pre-trained network의 iterations: 200, learning rate: 0.001
IDEC, DSSEC의 clustering loss에서
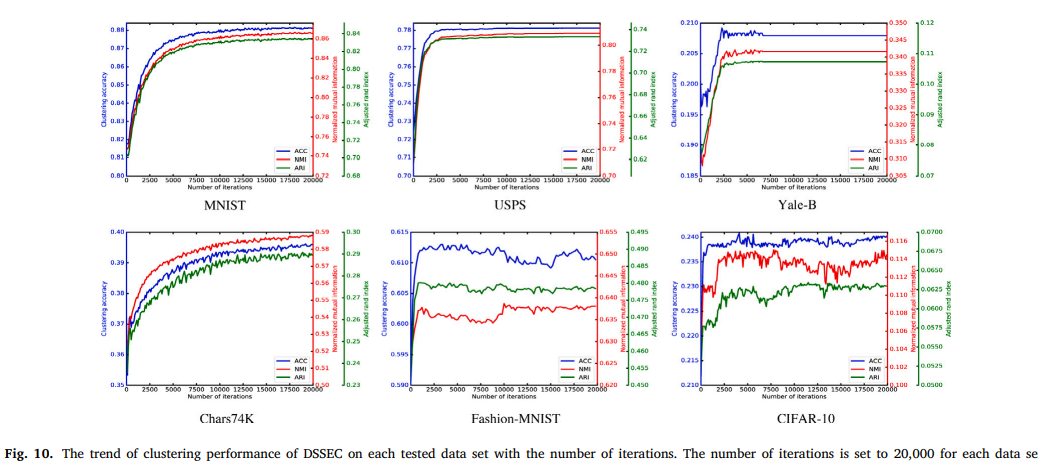
DSSEC에서 sparsity parameter , max iteration: 20,000
threshold -
Experimental Visualization


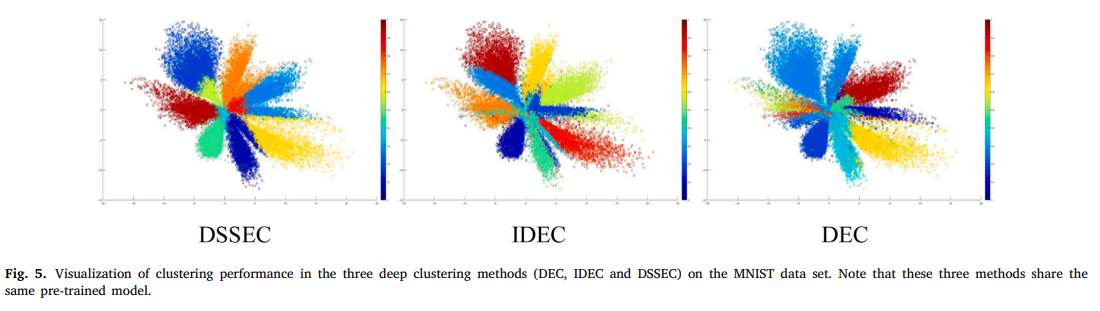
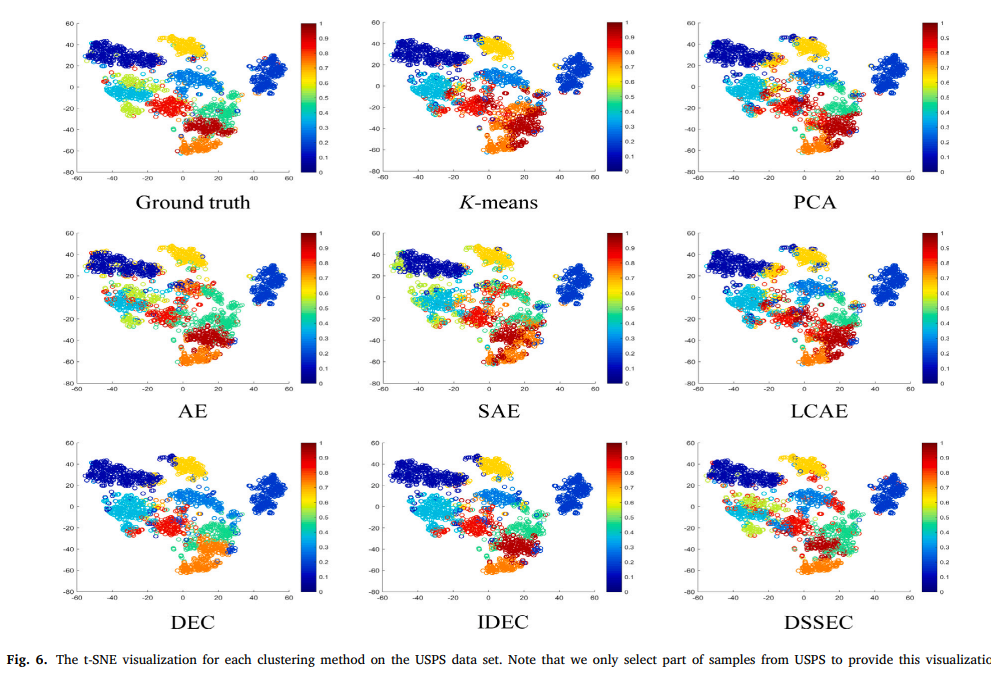
-
Evaluation metrics
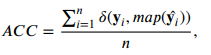
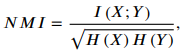
는 X와 Y변수에 대한 mutual information(MI)을 나타낸 것.
metric은 기반 metric이며, 는 information entropies량이다.
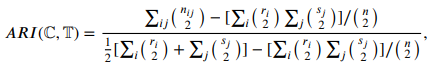
Adjusted rand index(ARI)
두 클러스터링 샘플의 유사도를 측정할 수 있는 지표
클러스터링 결과인 와 ground truth인 를 비교
는 클러스터 내에 있는 데이터 포인트 개수
는 클러스터 내에 있는 데이터 포인트 개수 -
Parameter sensitivity
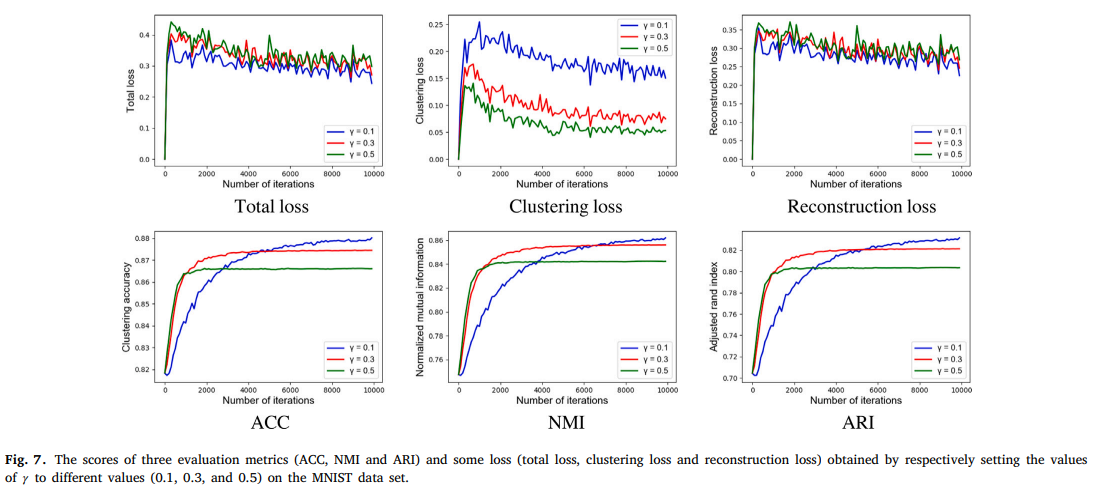
여기서 사용하는 는 DSSEC의 total loss에서 clustering loss의 가중치이다.
이 파라미터가 중요한 이유는 값에 따라 reconstruction loss의 기여도가 정해지기 때문이다. (voting 방식이기 때문)
위의 그림에서 값을 0.1, 0.3, 0.5로 조정한 결과값을 확인할 수 있다.
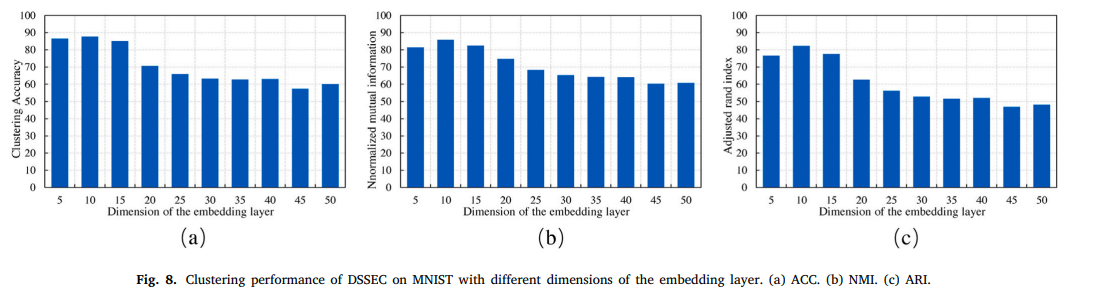
위의 그림은 MNIST에 대해서 앞서 보았던 3가지 평가지표를 사용한 결과이고, 그 안에서 embedding layer의 dimension에 따른 결과값 변동을 보인다.
dimension이 20을 넘어가면서 성능이 유의미하게 하락하는 것을 볼 수 있다. -
Experimental results
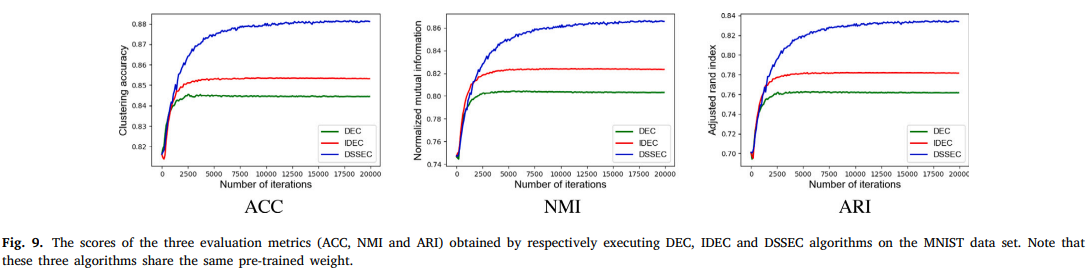
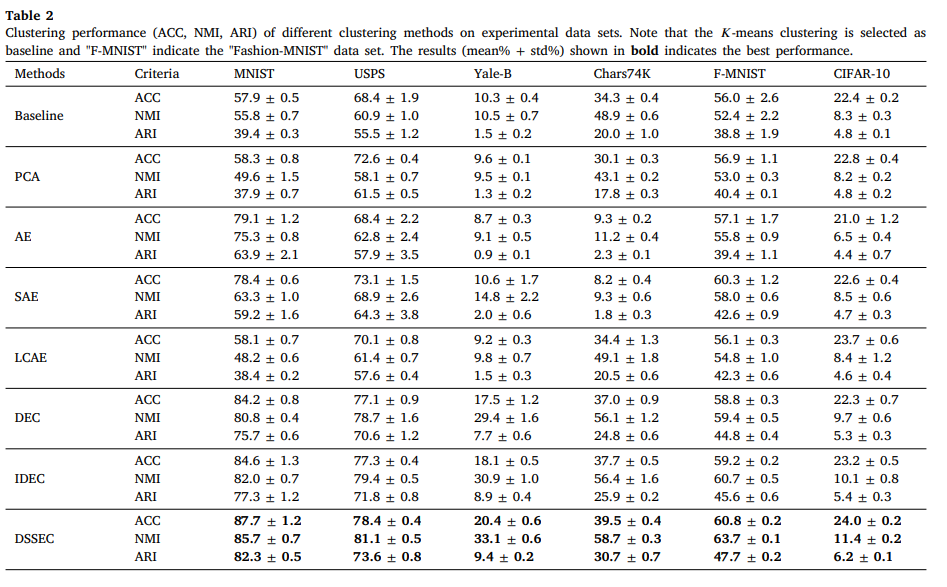
IDEC가 DEC보다 좋은 이유는 reconstruction loss에서 input의 local structure를 retain해서 feature space에서의 정보 왜곡을 방지했기 때문이다.
그리고 IDEC가 갖는 high-dimension image dataset에 대한 문제를 DSSEC가 극복했다는 점을 볼 수 있다.
또한, unsupervised algorithm인 PCA, AE, SAE, semi-supervised algorithm인 LCAE까지 비교 실험을 해보면서 DSSEC가 굉장히 효과적임을 알아볼 수 있었다.
Conclusion
논문에서는 Deep Stacked Sparse Embedded Clustering(DSSEC) method를 새롭게 제안했다.
기존 모델과 가장 큰 차이점은 AE구조를 그대로 가져가지 않고, high-dimensional image data에 맞게 sparse auto-encoder 구조로 대체했다는 점이다.
이는 local structure를 유지시켜 정보 왜곡을 방지하는 방법(IDEC)을 sparse constraint를 부여해서 중요하지 않은 정보는 거의 학습하지 않는 방법으로 대체하여 성공적인 결과를 얻었음을 뜻한다.
논문은 6개의 이미지 데이터셋을 다양한 모델들과 비교실험을 진행했고, 제안한 모델이 가장 좋은 성능임을 보였다.
하지만 real-world의 많은 클러스터링 문제들은 noise와 같은 외부 간섭에 더 많은 영향을 받는 경향이 있기 때문에 현재까지도 계속 도전과제로 남아있다.
따라서 future work에서 저자들은 deep clustering method를 그러한 데이터셋들에 맞추는 시나리오를 짜보겠다고 한다.
