https://github.com/nalinzip/ml_study/blob/main/ML_week10_1.ipynb
https://github.com/nalinzip/ml_study/blob/main/ML_Week10_2.ipynb
https://github.com/nalinzip/ml_study/blob/main/ML_Week10_3.ipynb
1. K-평균 알고리즘 이해
- K-평균은 군집화 (Clustering) 에서 가장 일반적으로 사용되는 알고리즘
- K-평균은 군집 중심점 (centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법
- 군집 중심점은 선택된 포인트의 평균 지점으로 이동하고 이동된 중심점에서 다시 가까운 포인트를 선택, 다시 중심점을 평균 지점으로 이동하는 프로세스를 반복적으로 수행
- 모든 데이터 포인트에서 더 이상 중심점의 이동이 없을 경우에 반복을 멈추고 해당 중심점에 속하는 데이터 포인트들을 군집화하는 기법
K-평균이 동작 시각적 표현
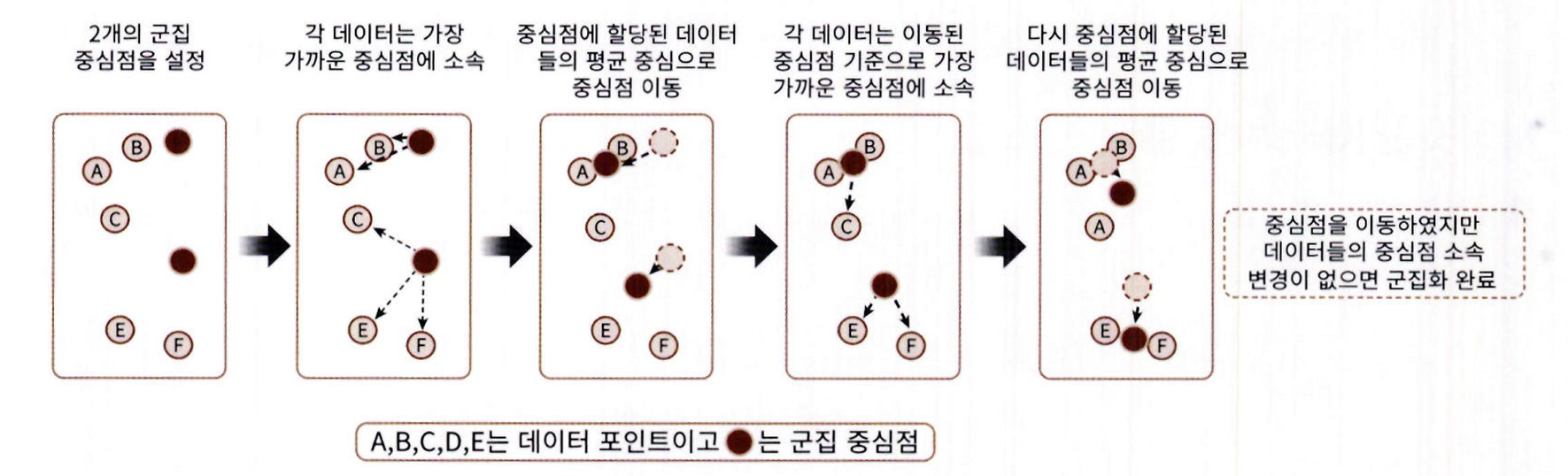
1. 군집 개수만큼 초기 중심점(centroid)을 임의의 위치에 설정
2. 각 데이터 포인트를 가장 가까운 중심점에 소속시킴
3. 각 군집의 중심점을 소속된 데이터들의 평균 위치로 이동
4. 중심점 이동 후, 더 가까운 중심점이 생기면 소속 군집 변경
5. 변경된 소속에 따라 중심점을 다시 평균 위치로 이동
6. 더 이상 데이터의 군집 소속이 바뀌지 않으면 반복 종료
K-평균의 장점
- 일반적인 군집화에서 가장 많이 활용
- 쉽고 간결
K-평균의 단점
- 거리 기반 알고리즘으로 속성의 개수가 매우 많을 경우 군집화 정확도가 떨어짐 (이를 위해 PCA 로 차원 감소를 적용해야 할 수도 있음).
- 반복 횟수가 많을 경우 수행 시간이 매우 느려짐
- 몇 개의 군집 (cluster) 을 선택해야 할지 가이드하기가 어려움
사이킷런 KMeans 클래스
K-평균을 구현하기 위해 KMeans 클래스를 제공
KMeans 초기화 파라미터
class sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001,
precompute_distances='auto', verbose=0, random_state=None,
copy_x=True, n_jobs=1, algorithm='auto')- 가장 중요한 파라미터는 n_clusters = 군집화할 개수 , 즉 군집 중심점의 개수
- init = 초기에 군집 중심점의 좌표를 설정할 방식, 보통은 임의로 중심을 설정하지 않고 일반적으로 k-means++방식으로 최초 설정
- max_iter 는 최대 반복 횟수 (이전에 모든 데이터의 중심점 이동이 없으면 종료합니다.)
- KMeans 는 사이킷런의 비지도학습 클래스와 마찬가지로 fit( 데이터 세트 ) 또는 fit_transform(데이터 세트) 메서드를 이용해 수행하면 됨
- 이렇게 수행된 KMeans 객체는 군집화 수행이 완료돼 군집화와 관련된 주요 속성을 알 수가 있음
• labels_: 각 데이터 포인트가 속한 군집 중심점 레이블
• cluster_centers: 각 군집 중심점 좌표 (Shape 는 [군집 개수 , 피처 개수]). 이를 이용하면 군집 중심점 좌표가 어디인지 시각화 가능
K- 평균을 이용한 붓꽃 데이터 세트 군집화
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
# 더 편리한 데이터 핸들링을위해 DataFrame으로 변환
irisDF = pd.DataFrame(data=iris.data, columns=['sepal_length', 'sepal_width', 'petal_length','petal_width'])
irisDF.head(3)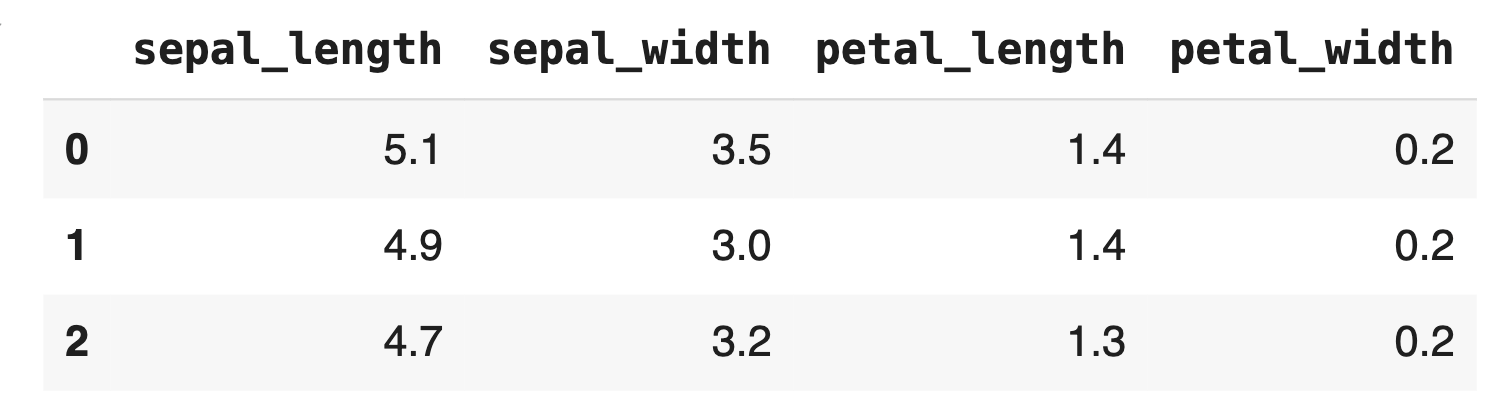
붓꽃 데이터 세트를 3 개 그룹으로 군집화
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300,random_state=0)
kmeans.fit(irisDF)
- fit( )을 수행해 irisDF 데이터에 대한 군집화 수행 결과가 kmeans 객체 변수로 반환
- kmeans 의 labels_ 속성값을 확인해 보면 irisDF 의 각 데이터가 어떤 중심에 속하는지를 알 수 있음
labels_ 속성값을 출력
print(kmeans.labels_)

- labels_ 의 값이 0, 1, 2 로 돼 있으며 , 이는 각 레코드가 첫 번째 군집 , 두 번째 군집 , 세 번째 군집에 속함을 의미
실제 붓꽃 품종 분류 값과 얼마나 차이가 나는지로 군집화가 효과적으로 됐는지 확인
- 붓꽃 데이터 세트의 target 값을 target 칼럼으로 추가
- K-평균 결과인 labels_ 값을 cluster 칼럼으로 추가
- irisDF DataFrame 에 target 과 cluster 칼럼 포함
- groupby(['target', 'cluster']) 로 군집 결과와 실제 분류값 간의 관계 비교
irisDF['target'] = iris.target
irisDF['cluster']=kmeans.labels_
iris_result = irisDF.groupby(['target', 'cluster' ])['sepal_length'].count()
print(iris_result)
- Target 값이 0인 데이터는 1번 군집으로 모두 잘 그루핑됨
- Target 값이 1인 데이터는 2개만 2번 군집으로, 나머지 48개는 0번 군집으로 그루핑됨
- Target 값이 2인 데이터는 0번 군집에 14개, 2번 군집에 36개로 분산되어 그루핑됨
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_transformed = pca.fit_transform(iris.data)
irisDF['pca_x'] = pca_transformed[:, 0]
irisDF['pca_y'] = pca_transformed[:, 1]
irisDF.head(3)
- pca_x는 X 좌표 값, pca_y는 Y 좌표 값을 나타냄
- 군집별 마커는 다음과 같이 지정됨:
cluster 0 → 마커 'o'
cluster 1 → 마커 's'
cluster 2 → 마커 '^' - matplotlib의 산점도(scatter)는 여러 마커를 한 번에 표현할 수 없으므로, 각 마커별로 별도의 산점도를 수행함
# 군집 값이 0, 1, 2 인 경우마다 별도의 인덱스로 추출
marker0_ind = irisDF[irisDF['cluster']==0].index
marker1_ind = irisDF[irisDF['cluster']==1].index
marker2_ind = irisDF[irisDF['cluster']==2].index
# 군집 값 0 , 1, 2 에 해당하는 인덱스로 각 군집 레벨의 pca_x, pcay 값 추출. 0, s, ^ 로 마커 표시
plt.scatter(x=irisDF.loc[marker0_ind, 'pca_x'], y=irisDF.loc[marker0_ind, 'pca_y'], marker='o')
plt.scatter(x=irisDF.loc[marker1_ind, 'pca_x'], y=irisDF.loc[marker1_ind, 'pca_y'], marker='s')
plt.scatter(x=irisDF.loc[marker2_ind, 'pca_x'], y=irisDF.loc[marker2_ind, 'pca_y'], marker='^')
plt.xlabel( 'PCA 1')
plt.ylabel('PCA 2')
plt.title('3 Clusters Visualization by 2 PCA Components')
plt.show()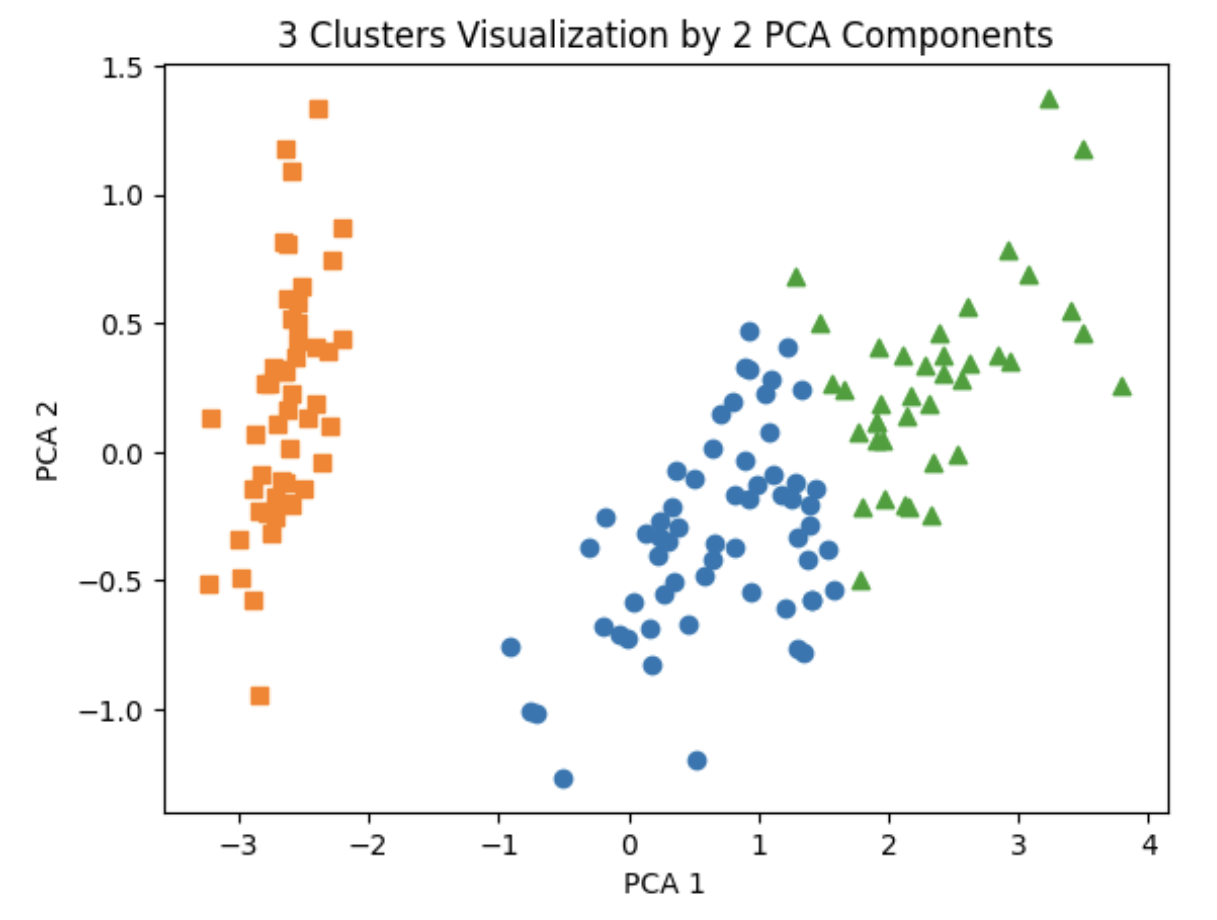
Cluster 0 과 1 의 경우 속성의 위치 자체가 명확히 분리되기 어
려운 부분이 존재함을 알 수 있음
군집화 알고리즘 테스트를 위한 데이터 생성
- 대표적인 데이터 생성기:
make_blobs()와make_classification()
make_blobs() :
- 군집 중심점과 표준 편차 설정 가능
- 군집화 중심 기반 데이터 생성에 유리함
-피처 데이터와 타깃 데이터를 튜플 형태로 반환함
make_classification() :
- 노이즈가 포함된 분류용 데이터 생성에 유용함
make_circles(), make_moons():
- 중심 기반 군집화로 해결하기 어려운 비선형 구조의 데이터 생성 가능
make_blobs() 의 호출 파라미터
- n_samples: 생성할 총 데이터의 개수 (디폴트는 100 개)
- nfeatures: 데이터의 피처 개수( 시각화를 목표로 할 경우 2 개로 설정해 보통 첫 번째 피처는 x 좌표 , 두 번째 피처는 y 좌표상에 표현)
- centers: int 값 , 예를 들어 3 으로 설정하면 군집의 개수를 나타냄. 그렇지 않고 ndarray 형태로 표현할 경우 개별 군집 중심점의 좌표를 의미함
- cluster_std: 생성될 군집 데이터의 표준 편차를 의미합니다. 만일 float 값 0.8 과 같은 형태로 지정하면 군집 내에서 데이터가 표준편차 0.8 을 가진 값으로 만들어집니다. [0.8, 1.2, 0.6] 과 같은 형태로 표현되면 3 개의 군집에서 첫 번째 군집 내데이터의 표준편차는 0.8, 두 번째 군집 내 데이터의 표준 편차는 1.2, 세 번째 군집 내 데이터의 표준편차는 0.6 으로 만듦. 군집별로 서로 다른 표준 편차를 가진 데이터 세트를 만들 때 사용함
X, y= make_blobs(n_samples=200, n_features=2, centers=3, random_state=0) 을 호출하면 총200 개의 레코드와 2 개의 피처가 3 개의 군집화 기반 분포도를 가진 피처 데이터 세트 X 와 , 동시에 3개의 군집화 값을 가진 타깃 데이터 세트 y 가 반환
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
%matplotlib inline
X, y = make_blobs (n_samples=200, n_features=2, centers=3, cluster_std=0.8, random_state=0)
print (X.shape, y.shape)
# y target 값의 분포를 확인
unique, counts = np.unique(y, return_counts=True)
print(unique, counts)
피처 데이터 세트 X 는 200 개의 레코드와 2 개의 피처를 가지므로 shape 은 (200, 2), 군집 타깃 데이터세트인 y 의 shape 은 (200,), 그리고 3 개의 cluster의 값은 [0, 1, 2] 이며 각각 67, 67, 66 개로 균일하
게 구성
데이터 가공을 편리하게 하기 위해서 위 데이터 세트를 DataFrame 으로 변
경 (피처의 이름은 ful, ftr2)
import pandas as pd
clusterDF = pd.DataFrame(data=X, columns=['ftr1', 'ftr2'])
clusterDF['target'] = y
clusterDF.head(3)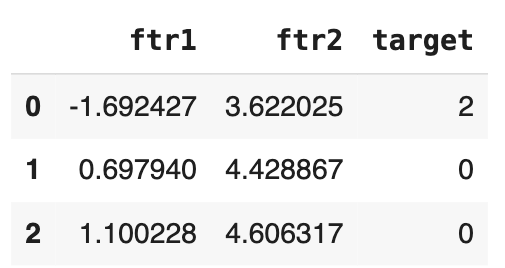
make_blob()으로 만든 피처 데이터 세트가 어떠한 군집화 분포를 가지고 만들어졌는지 확인
0 타깃값 0, 1, 2 에 따라 마커를 다르게 해서 산점도를 그려보면 다음과 같이 3 개의 구분될수 있는 군집 영역 (make_blobs() 이 y반환 값 ) 으로 피처 데이터 세트가 만들어졌음을 알 수 있음
target_list = np.unique(y)
#각 타깃별 산점도의 마커 값.
markers=['o', 's', '^', 'P', 'D', 'H', 'x']
# 3 개의 군집 영역으로 구분한 데이터 세트를 생성했으므로 target list는 [0, 1, 2 ]
# target=0, target=1, target=2 로 scatter plot 을 marker 별로 생성.
for target in target_list:
target_cluster = clusterDF[clusterDF['target']==target ]
plt.scatter(x=target_cluster['ftr1'], y=target_cluster['ftr2'], edgecolor='k',
marker=markers[target])
plt.show()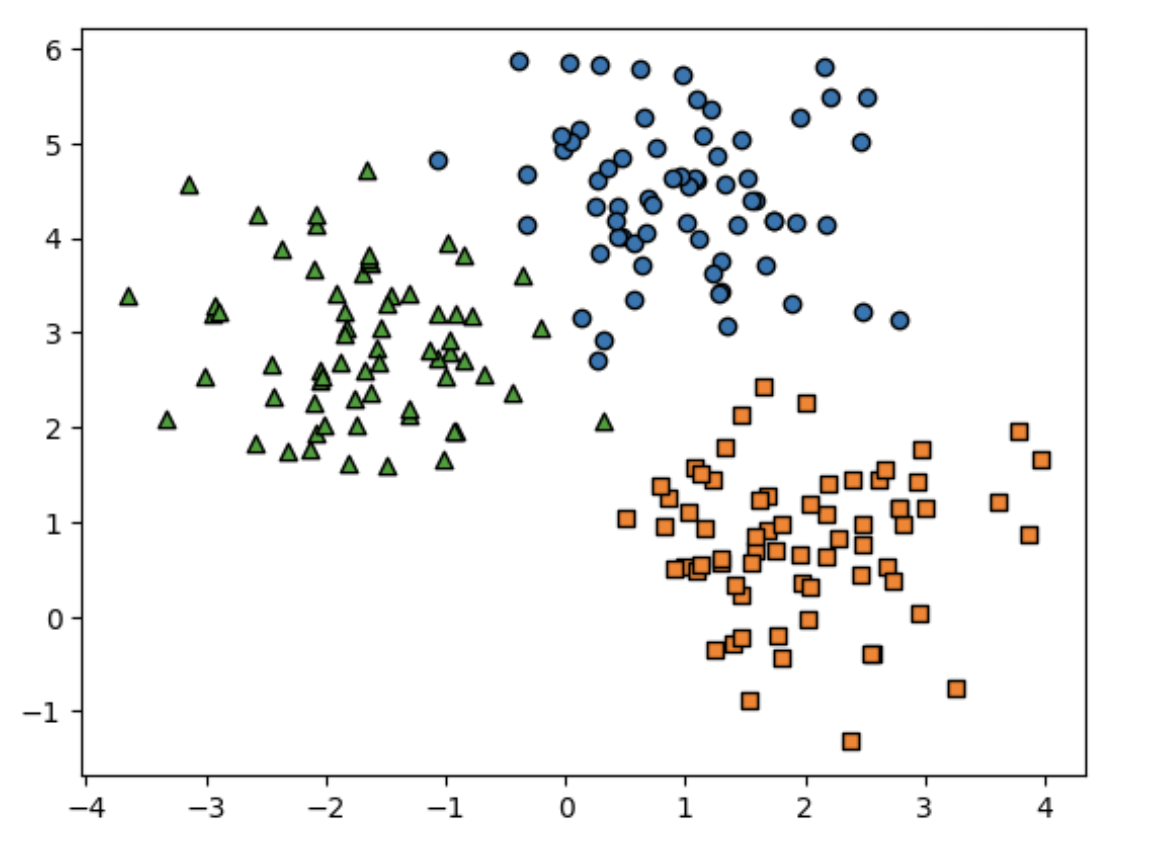
군집별로 시각화
- 먼저 KMeans 객체에 fit_predict(X)를 수행해 make_blobs( ) 의 피처 데이터 세트인 X 데이터를 군집화
- 이를 앞에서 구한 clusterDF DataFrame 의 'kmeans_label 칼럼으로 저장
- 그리고 KMeans 객체의 clustercenters속성은 개별 군집의 중심 위치 좌표를 나타내기 위해 사용
# KMeans 객체를 이용해 X 데이터를 K-Means 클러스터링 수행
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=200, random_state=0)
cluster_labels = kmeans.fit_predict(X)
clusterDF['kmeans_label'] = cluster_labels
# cluster_centers_는 개별 클러스터의 중심 위치 좌표 시각화를 위해 추출
centers = kmeans.cluster_centers_
unique_labels = np.unique(cluster_labels)
markers=['o', 's', '^', 'P', 'D', 'H', 'x']
# 군집된 1abel 유형별로 iteration 하면서 marker 별로 scatter plot 수행.
for label in unique_labels:
label_cluster = clusterDF[clusterDF['kmeans_label']==label]
center_x_y = centers[label]
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'], edgecolor='k',
marker=markers[label])
# 군집별 중심 위치 좌표 시각화
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=200, color='white',
alpha=0.9, edgecolor='k', marker=markers[label])
plt.scatter (x=center_x_y[0], y=center_x_y[1], s=70, color='k', edgecolor='k',
marker='$%d$' % label)
plt.show()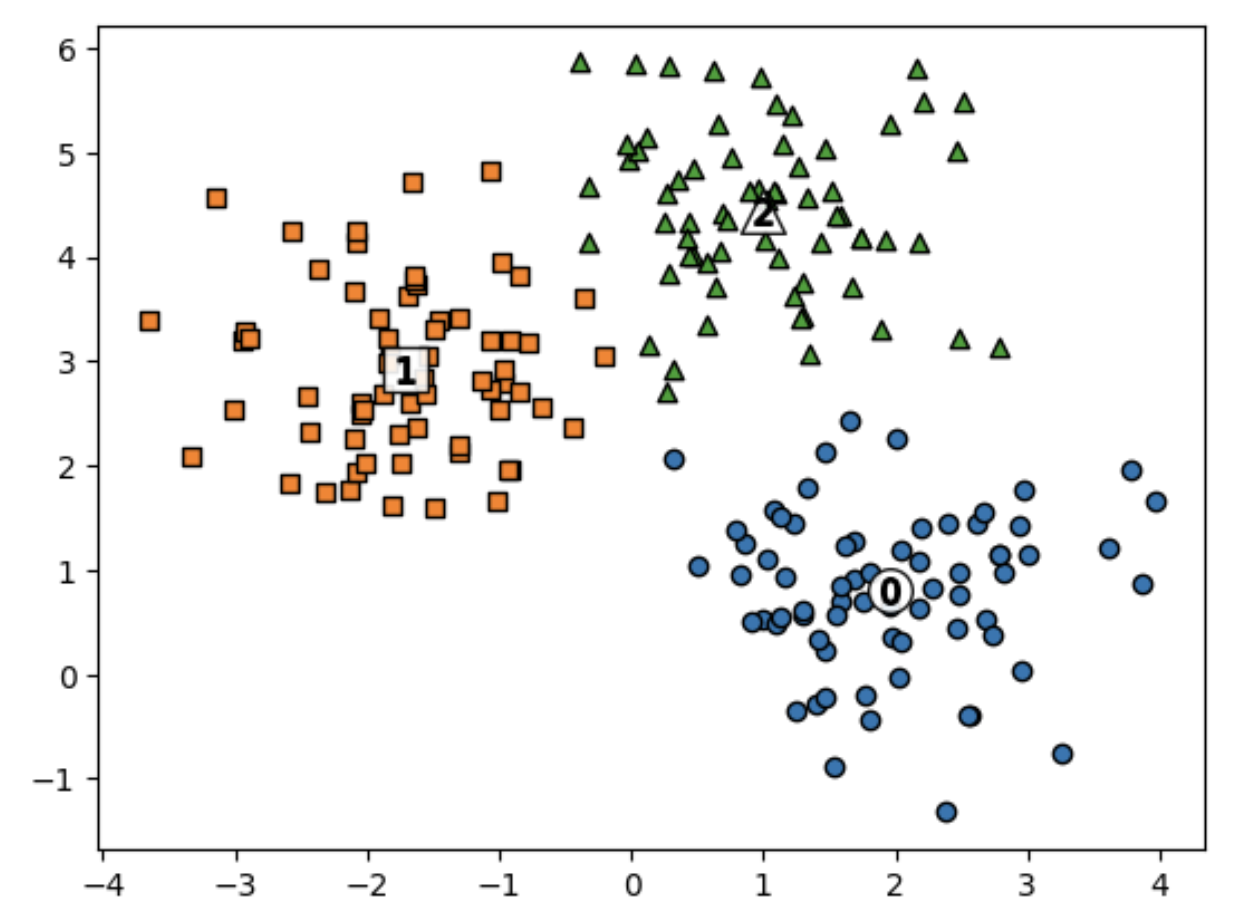
make_blobs()의 타깃과 kmeans_label은 군집 번호를 의미하므로 서로 다른 값으로 매핑될 수 있음
print(clusterDF.groupby('target')['kmeans_label'].value_counts())
cluster_std가 작을수록 군집 중심에 데이터가 모여 있으며 , 클수록 데이터가 퍼져 있음을
2. 군집 평가(Cluster Evaluation)
- 붓꽃 데이터처럼 타깃 레이블이 있는 경우 군집화 효율을 비교할 수 있음
- 대부분의 실제 군집화 데이터는 타깃 레이블이 없음
- 군집화는 분류와 비슷해 보이나, 목적과 성격이 다름
- 숨겨진 그룹 탐색, 동일 분류 내 세분화, 서로 다른 분류의 통합 등 다양한 목적
- 비지도학습 특성상 군집화 성능을 정량적으로 평가하기 어려움
- 대표적인 군집화 성능 평가 지표:
실루엣 분석 (Silhouette Analysis)
실루엣 분석
-
실루엣 분석 (silhouette analysis): 군집화가 얼마나 잘 분리됐는지 평가하는 방법
-
잘 분리된 군집이란:
다른 군집과의 거리는 멀고
같은 군집 내에서는 데이터들이 서로 가까이 모여 있음 -
실루엣 계수 (silhouette coefficient):
개별 데이터의 군집화 품질을 수치화
같은 군집 내 데이터와의 거리(응집도)가 작을수록 좋음
다른 군집과의 거리(분리도)가 클수록 좋음
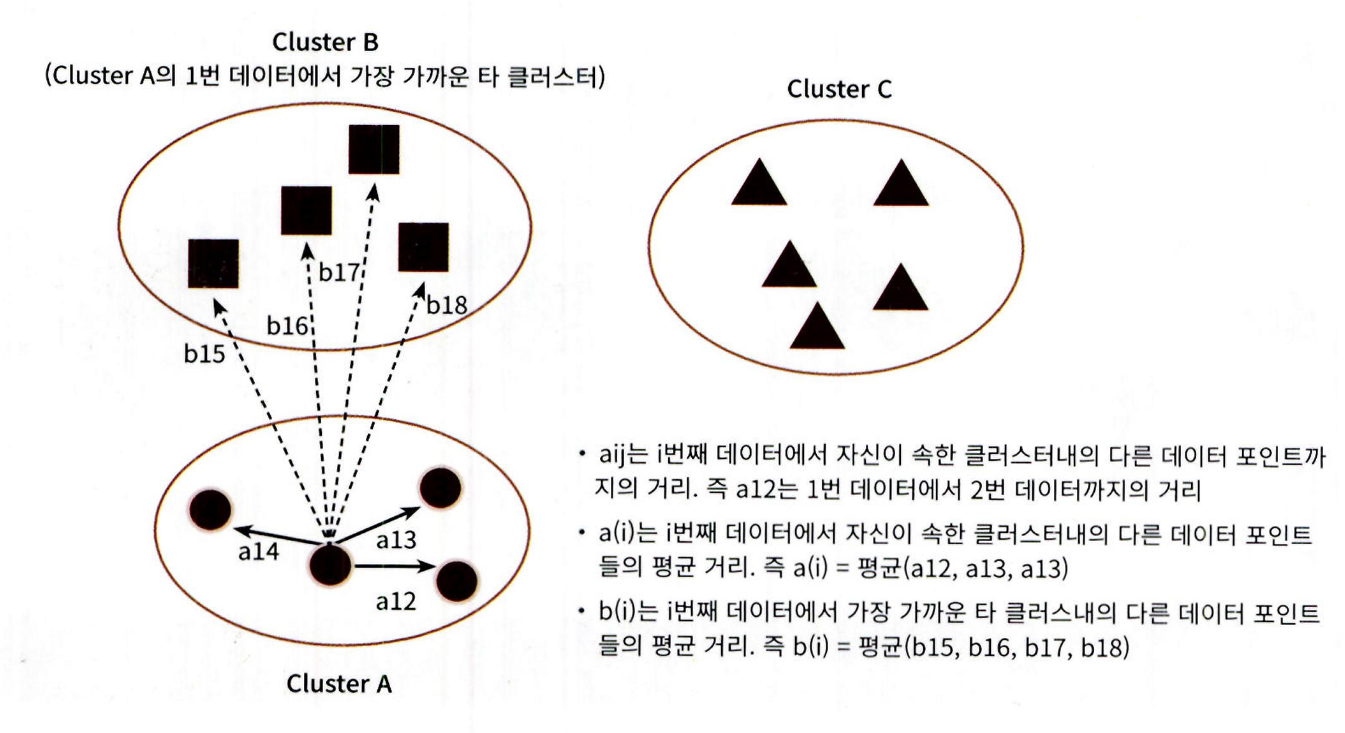
-
특정 데이터 포인트의 실루엣 계수 값은 해당 데이터 포인트와 같은 군집 내에 있는 다른 데이터 포인트와의 거리를 평균한 값 a(i), 해당 데이터 포인트가 속하지 않은 군집 중 가장 가까운 군집과의 평균거리 b(i) 를 기반으로 계산됩니다. 두 군집 간의 거리가 얼마나 떨어져 있는가의 값은 b(i) - a(i) 이며이 값을 정규화하기 위해 MAX( a(), b(i) ) 값으로 나눔
따라서 i 번째 데이터 포인트의 실루엣 수 값 s(i) 는 다음과 같이 정의
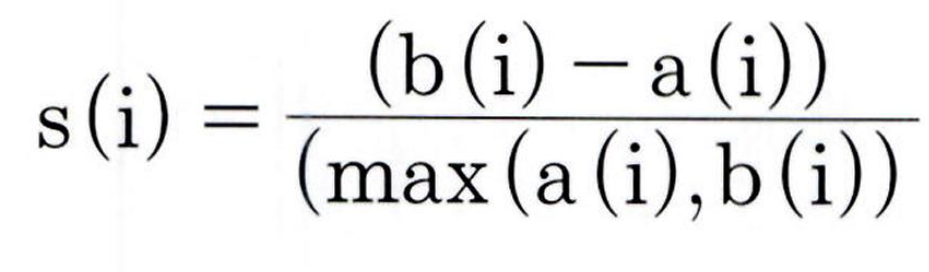
- 실루엣 계수는 1 에서 1 사이의 값을 가지며 , 1 로 가까워질수록 근처의 군집과 더 멀리 떨어져 있다는것이고 0 에 가까울수록 근처의 군집과 가까워진다는 것
- 값은 아예 다른 군집에 데이터 포인트가 할당됐음
실루엣 분석을 위해 메서드
- sklearn.metrics.silhouette_samples(X, labels, metric='euclidean ', **kwds): 인자로 X feature 데이터 세트와 각
피처 데이터 세트가 속한 군집 레이블 값인 labels 데이터를 입력해주면 각 데이터 포인트의 실루엣 계수를 계산해 반환 - sklearn.metrics.silhouette_score(X, labels, metric='euclidean', sample_size=None, **kwds): 인자로 X
feature 데이터 세트와 각 피처 데이터 세트가 속한 군집 레이블 값인 labels 데이터를 입력해주면 전체 데이터의 실루엣 계수 값을 평균해 반환
즉 , np.mean(sihouette_samples()) 입니다. 일반적으로 이 값이 높을수록 군집화가 어느정도 잘 됐다고 판단할 수 있음
하지만 무조건 이 값이 높다고 해서 군집화가 잘 됐다고 판단할 수는 없음
좋은 군집화가 되려면 다음 기준 조건을 만족
- 전체 실루엣 계수의 평균값 , 즉 사이킷런의 Silhouette_score() 값은 0~ 1 사이의 값을 가지며 , 1 에 가까울수록 좋음
- 하지만 전체 실루엣 계수의 평균값과 더불어 개별 군집의 평균값의 편차가 크지 않아야 합니다. 즉 , 개별 군집의 실루엣 계수 평균값이 전체 실루엣 계수의 평균값에서 크게 벗어나지 않는 것이 중요합니다. 만약 전체 실루엣 계수의 평균값은 높지만 , 특정 군집의 실루엣 계수 평균값만 유난히 높고 다른 군집들의 실루엣 계수 평균값은 낮으면 좋은 군집화 조건이 아님
붓꽃 데이터 세트를 이용한 군집 평가
sklearn.metrics 모듈의 silhouette_samples()와 silhouette_score()를 이용하여 군집화 결과를 실루엣 분석으로 평가
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
# 실루엣 분석 평가 지표 값을 구하기 위한 API 추가
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
feature_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
irisDF = pd.DataFrame(data=iris.data, columns=feature_names)
kmeans = KMeans(n_clusters=3, init='k-means++' , max_iter=300, random_state=0).fit(irisDF)
irisDF['cluster'] = kmeans.labels_
# iris의 모든 개별 데이터에 실루엣 계수 값을 구함.
score_samples = silhouette_samples(iris.data, irisDF[ 'cluster'])
print('silhouette_samples ( ) return 값의 shape', score_samples. shape)
# irisDF에 실루엣 계수 칼럼 추가
irisDF['silhouette_coeff'] = score_samples
#모든 데이터의 평균 실루엣 계수 값을 구함.
average_score = silhouette_score(iris.data, irisDF[ 'cluster'])
print('붓꽃 데이터 세트 Silhouette Analysis Score:{0:.3f}'.format(average_score))
irisDF.head(3)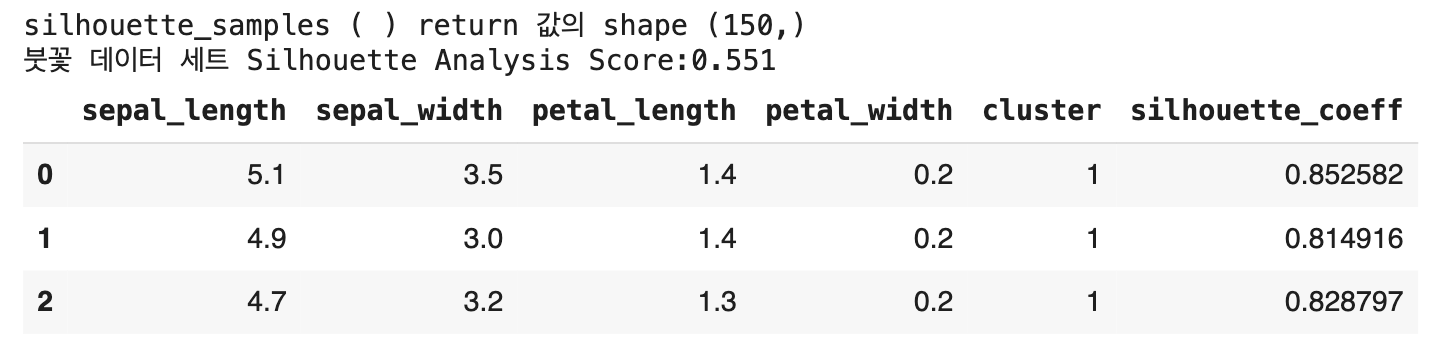
- 붓꽃 데이터 세트의 전체 평균 실루엣 계수: 약 0.553
- 1번 군집의 실루엣 계수:
예시 값: 0.8529, 0.8154, 0.8293
평균적으로 약 0.8 수준으로 높음 - 다른 군집들의 실루엣 계수: 낮은 값 분포
이로 인해 전체 평균 실루엣 계수는 0.553으로 낮아짐 - 군집별 실루엣 계수 분석 방법:
groupby('cluster')['silhouette_coeff'].mean() 사용 - 군집별 클러스터 품질 비교 가능
irisDF.groupby('cluster')['silhouette_coeff'].mean()
- 1 번 군집은 실루엣 계수 평균 값이 약 0.79 인데 반해 , 0 번은 약 0.41, 2 번은 0.45 로 상대적으로 평균값이 1 번에 비해 낮음
군집별 평균 실루엣 계수의 시각화를 통한 군집 개수 최적화 방법
- 평균 실루엣 계수(score)가 높다고 해서 군집 수가 최적이라는 보장은 없음
- 특정 군집만 실루엣 계수가 높고 나머지는 낮으면 전체 평균이 왜곡될 수 있음
- 개별 군집의 실루엣 분포 시각화를 통해 평가해야 함
시각화 방식:
X축: 실루엣 계수
Y축: 군집 번호와 개별 데이터
점선: 전체 평균 실루엣 계수
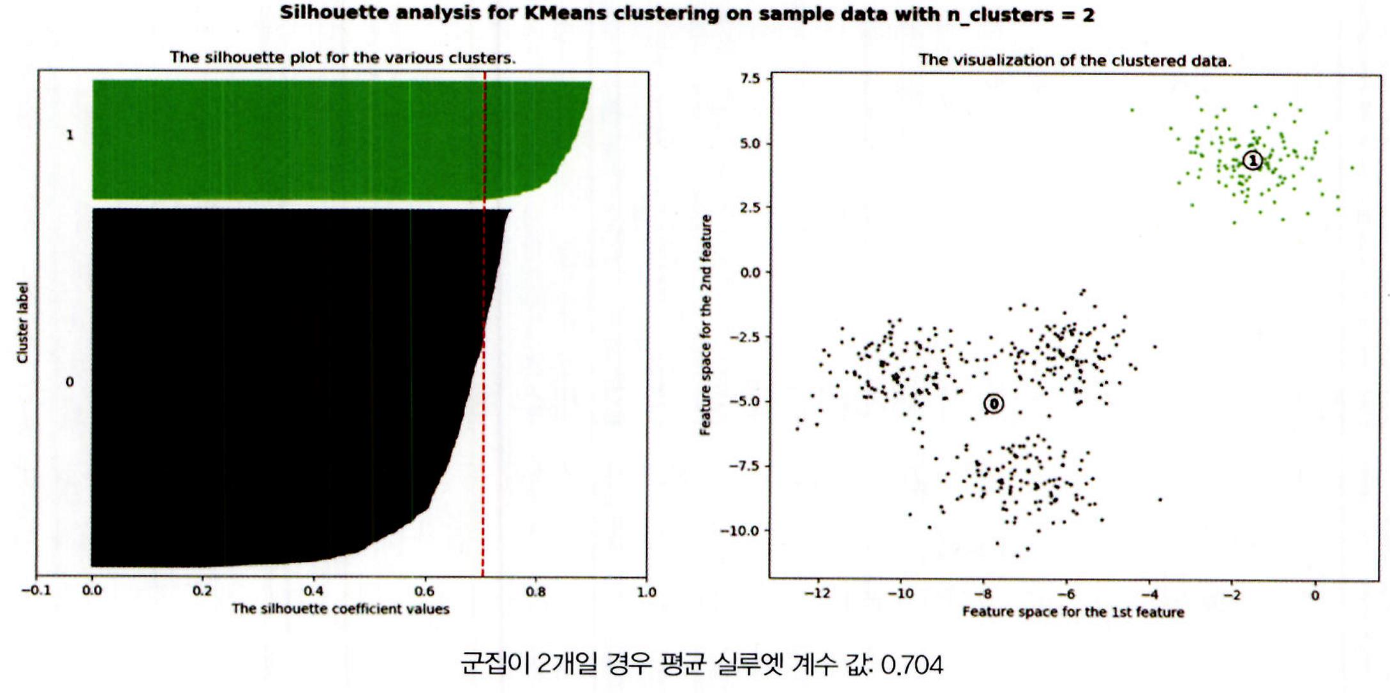
군집 수 = 2
평균 실루엣 계수 ≈ 0.704 → 매우 높지만
군집 1번은 대부분 평균 이상
군집 2번은 많은 데이터가 평균 미만 → 불균형 구조
-
결론: 군집별 실루엣 분포 시각화로 적정 군집 수 판단해야 함.
-
오른쪽에 있는 그림으로 그 이유를 보충해서 설명할 수 있음.
-
1 번 군집의 경우는 0 번 군집과 멀리 떨어져 있고 , 내부 데이터끼리도 잘 뭉쳐 있음
-
하지만 0 번 군집의 경우는 내부 데이터끼리 많이 떨어져 있는 모습임
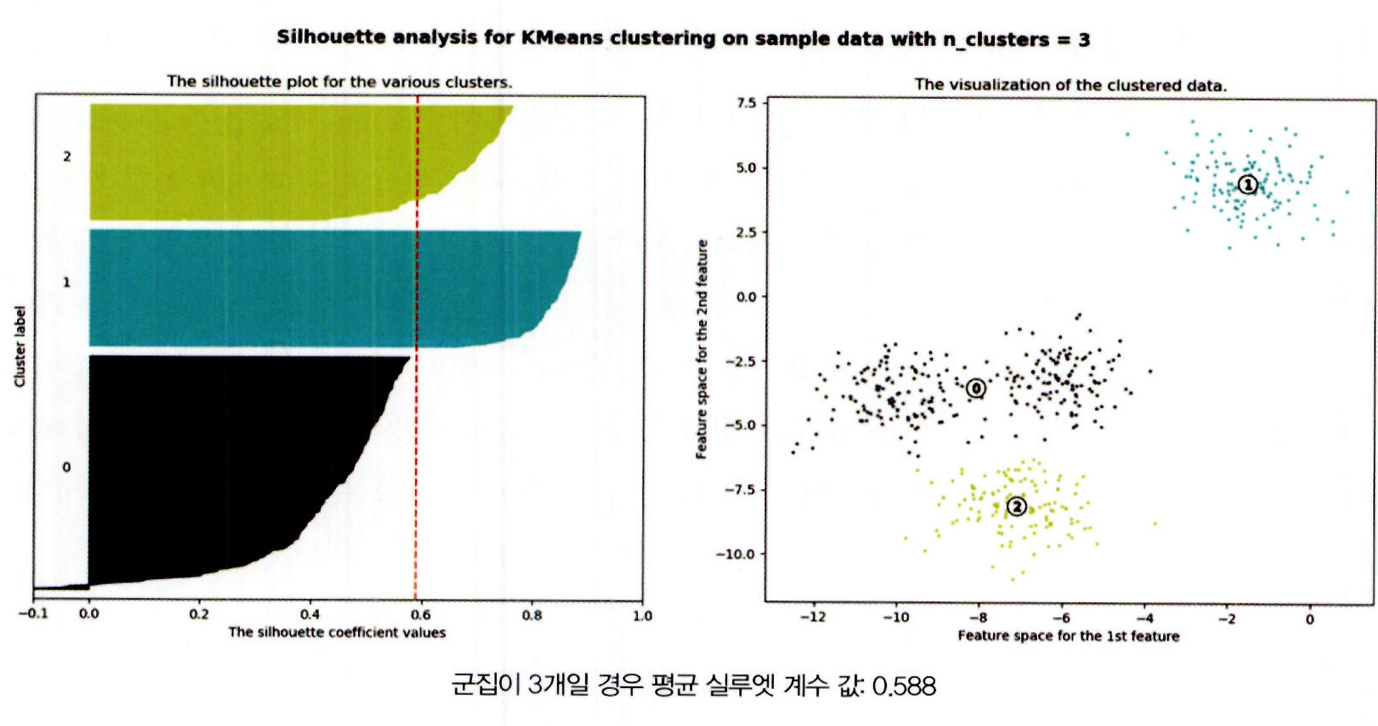
군집 개수 = 3 개
- 전체 데이터의 평균 실루엣 계수 값은 약 0.588
- 1번 , 2 번 군집의 경우 평균보다 높은 실루엣 계수 값을 가지고 있지만 , 0 번의 경우 모두 평균보다 낮음.
- 오른쪽 그림을 보면 0 번의 경우 내부 데이터 간의 거리도 멀지만 , 2 번 군집과도 가깝게 위치하고 있기 때문임
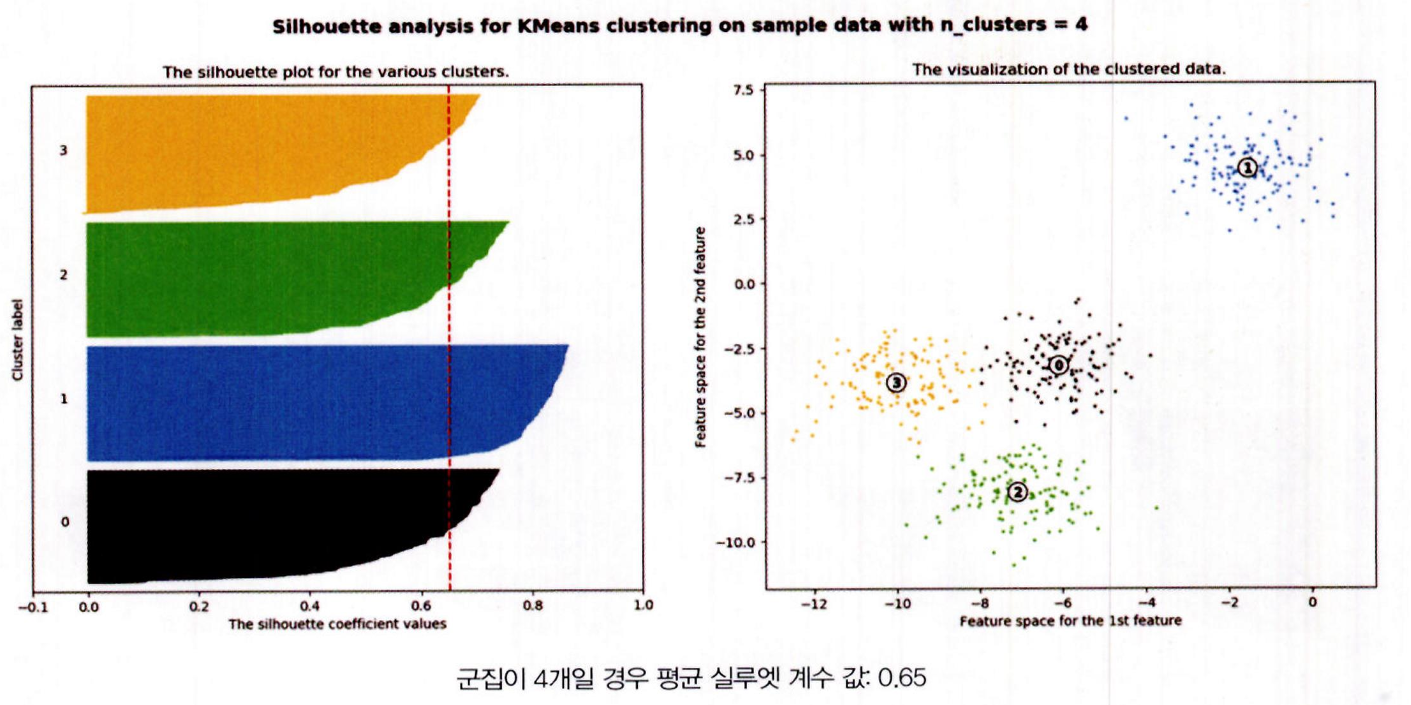
군집 수 = 4일 때
- 평균 실루엣 계수 ≈ 0.65
- 전체적으로 군집별 실루엣 계수 분포가 균일하게 형성됨
1번 군집: 모든 데이터가 평균 이상
0번, 2번 군집: 절반 이상이 평균 이상
3번 군집: 약 1/3 정도만 평균 이상 - 군집 수 2일 때보다 평균 실루엣 계수는 낮지만,
→ 군집별 균형 측면에서 4개 군집이 더 이상적
결론: 군집 간 분포와 내부 응집도가 적절하여 → 4개 군집이 가장 적절한 K로 판단 가능
- visualize_silhouette()은 내부 파라미터로 여러 개의 군집 개수를 리스트로 가지는 첫 번째 파라미터와 피처 데이터 세트인 두 번째 파라미터를 가지고 있음
- 만일 피처 데이터 세트 X_features에 대해서 군집이 2 개일 때와 3 개 , 4 개 , 5 개일 때의 군집별 평균 실루엣 계수 값을 알고 싶다면 다음과 같이
호출
3. 평균 이동
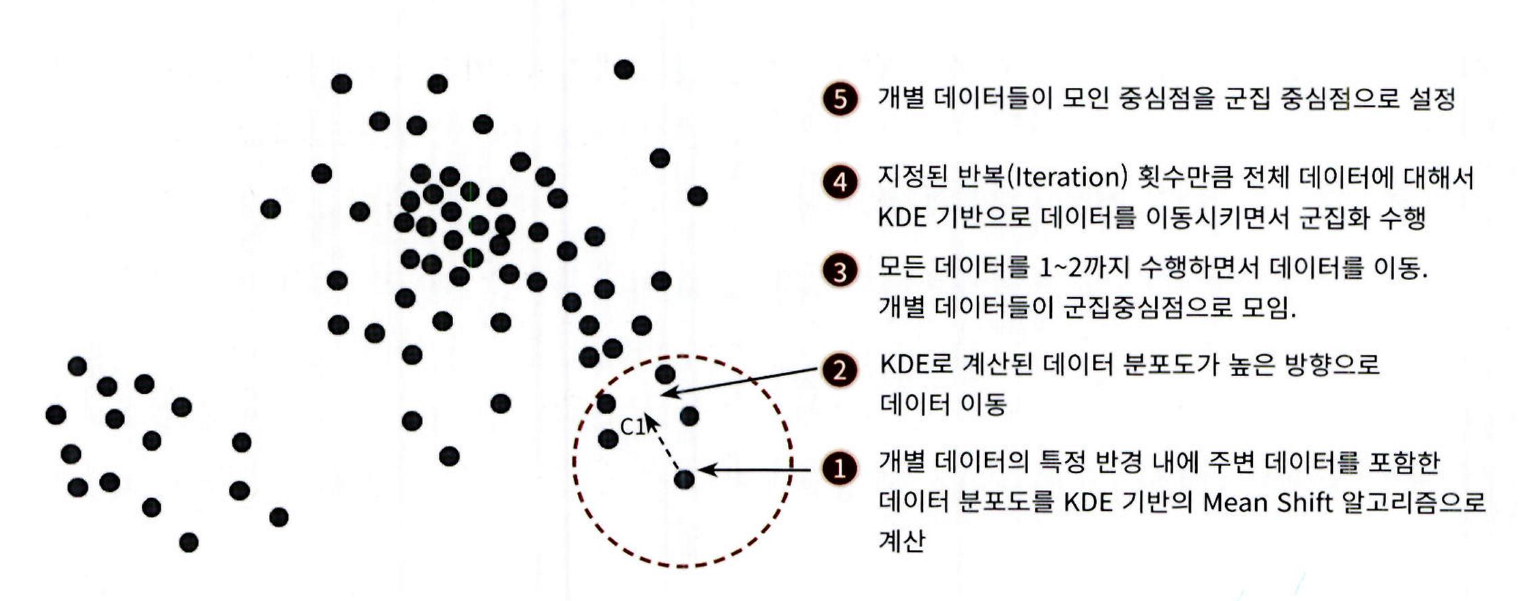
평균 이동 (Mean Shift)의 개요
-
평균 이동(Mean Shift)은 K-평균처럼 중심을 반복 이동하며 군집화 수행
-
그러나 K-평균은 중심점으로부터의 평균 거리에 따라 이동하고,
평균 이동은 데이터 밀도가 가장 높은 곳으로 중심을 이동 -
확률 밀도 함수 (Probability Density Function)를 기반으로 중심점 탐색
-
KDE (Kernel Density Estimation)를 활용해 데이터가 가장 집중된 위치 찾음
-
각 데이터 포인트는 반경 내에서 KDE 값을 계산하여 밀도가 높은 방향으로 이동
-
이 과정을 반복 적용하여 군집 중심점 수렴 및 군집화 수행
-
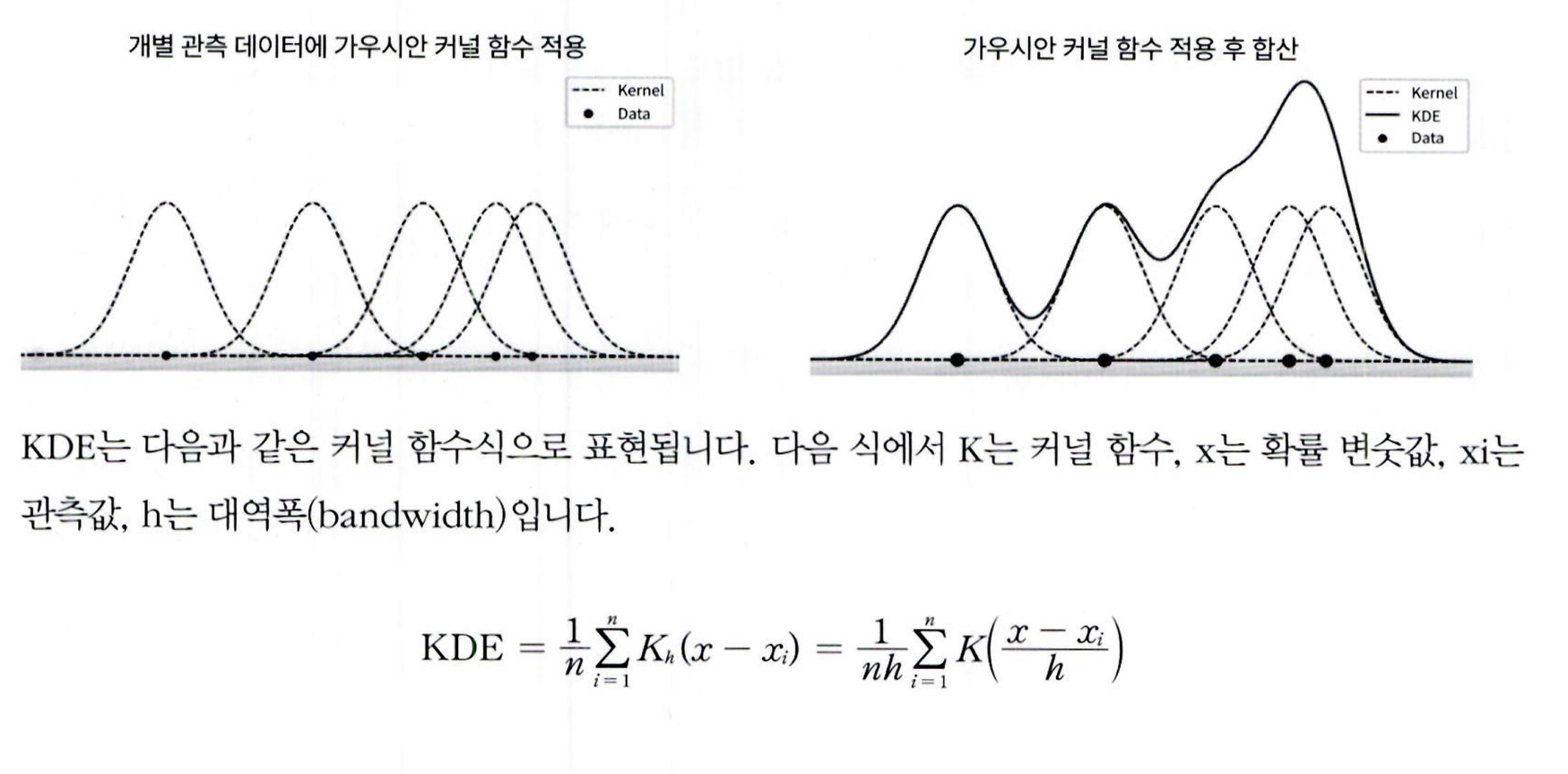
KDE (Kernel Density Estimation): 커널 함수로 확률 밀도 함수(PDF)를 추정하는 방법
-
관측된 각 데이터에 커널 함수 적용, 이 값을 합산 후 데이터 수로 나누어 밀도 추정
-
확률 밀도 함수(PDF)는 변수의 분포와 특성(예: 평균, 분산)을 설명
-
KDE에서 가장 널리 쓰이는 커널 함수는 가우시안(정규 분포) 함수
-
왼쪽 그림: 개별 데이터에 가우시안 커널 적용 결과
-
오른쪽 그림: 적용값을 더해 얻은 KDE 추정 곡선 (부드러운 확률 밀도 곡선)
-
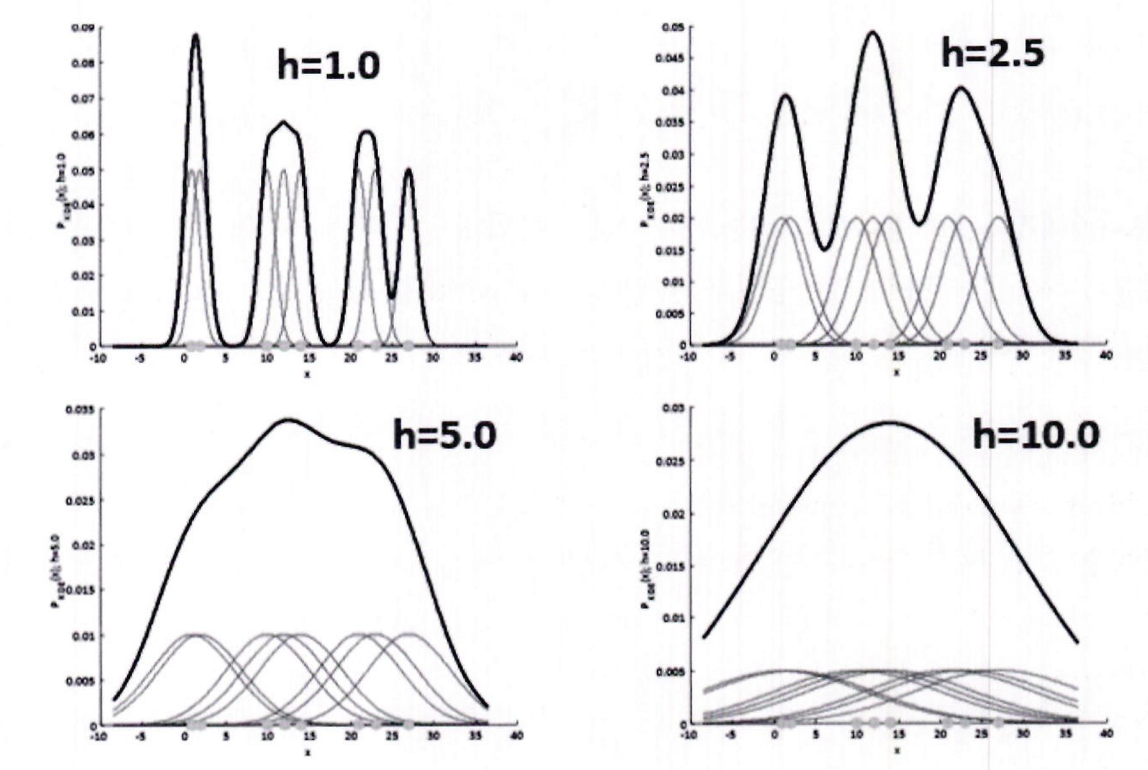
대역폭 h: KDE에서 확률 밀도 함수의 부드러움(smoothing) 정도를 조절
-
작은 h (예: h=1.0):
KDE가 좁고 뾰족함 → 변동성 큼, 과적합(overfitting) 우려 -
큰 h (예: h=10):
KDE가 과도하게 평탄화됨 → 단순화, 과소적합(underfitting) 가능 -
KDE 기반 Mean Shift 군집화의 성능은 ℎ
h 설정에 크게 좌우됨 -
적절한 h 선택이 중요함
-
평균 이동 군집화: 군집 개수 지정 없이 대역폭(bandwidth)에 따라 자동 결정
-
대역폭이 클수록 : 적은 수의 군집 중심점
-
대역폭이 작을수록 : 많은 수의 군집 중심점
-
사이킷런 제공 클래스: MeanShift
-
핵심 파라미터: bandwidth (KDE의 대역폭 h)
-
최적 bandwidth 계산 함수: estimate_bandwidth()
예제: make_blobs(cluster_std=0.7)로 생성한 데이터에 bandwidth=0.8 설정하여 군집화 수행
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import MeanShift
X, y = make_blobs(n_samples=200, n_features=2, centers=3, cluster_std=0.7, random_state=0)
meanshift= MeanShift(bandwidth=0.8)
cluster_labels = meanshift.fit_predict(X)
print('cluster labels 유형:', np.unique(cluster_labels))
- 군집이 0 부터 5 까지 6 개로 분류됐음
- 지나치게 세분화돼 군집화됐음
- 일반적으로 bandwidth 값을 작게 할수록 군집 개수가 많아짐
이번에 bandwidth를 살짝 높인 1.0 으로 해서 MeanShift 수행
meanshift= MeanShift(bandwidth=1)
cluster_labels = meanshift.fit_predict(X)
print('cluster labels 유형:', np.unique(cluster_labels))
- 3개의 군집으로 잘 군집화됐음
- 데이터의 분포 유형에 따라 bandwidth 값의 변화는 군집화 개수에 큰 영향을 미칠 수 있음
- 따라서 Meanshift 에서는 이 bandwidth 를 최적화 값으로 설정하는
것이 매우 중요함 - 최적화된 bandwidth 값을 찾기 위해서
estimate_bandwidth()
함수 제공 estimate_bandwidth()의 파라미터로 피처 데이터 세트를 입력해주면 최적화된 bandwidth 값을 반환해줌
from sklearn.cluster import estimate_bandwidth
bandwidth = estimate_bandwidth(X)
print('bandwidth 값:', round(bandwidth, 3))
estimate_bandwidth() 로 측정된 bandwidth 를 평균 이동 입력값으로 적용해 동일한 make_blobs() 데이터 세트에 군집화를 수행
import pandas as pd
clusterDF = pd.DataFrame(data=X, columns=['ftr1', 'ftr2'])
clusterDF['target'] = y
# estimate_bandwidth()로 최적의 bandwidth 계산
best_bandwidth = estimate_bandwidth(X)
meanshift= MeanShift(bandwidth=best_bandwidth)
cluster_labels = meanshift.fit_predict(X)
print('cluster labels 유형:',np.unique(cluster_labels))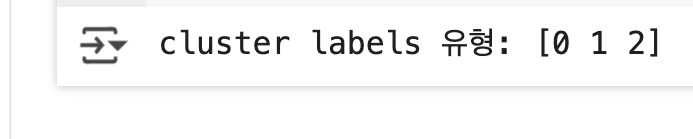
- 3 개의 군집으로 구성
구성된 3 개의 군집을 시각화
평균 이동도 K-평균과 유사하게 중심을 가지고 있으므로 cluster_centers_ 속성으로 군집 중심 좌표를 표시할 수 있음
import matplotlib.pyplot as plt
%matplotlib inline
clusterDF['meanshift_label'] = cluster_labels
centers = meanshift.cluster_centers_
unique_labels = np.unique(cluster_labels)
markers=['o', 's', '^', 'x', '*']
for label in unique_labels:
label_cluster = clusterDF[clusterDF['meanshift_label']==label]
center_x_y = centers[label]
# 군집별로 다른 마커로 산정도 적용
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'], edgecolor='k', marker=markers[label])
# 군집별 중심 표현
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=200, color='gray', alpha=0.9,
marker=markers[label])
plt.scatter(x=center_x_y[1], y=center_x_y[1], s=70, color='k', edgecolor='k', marker='$%d$' % label)
plt.show()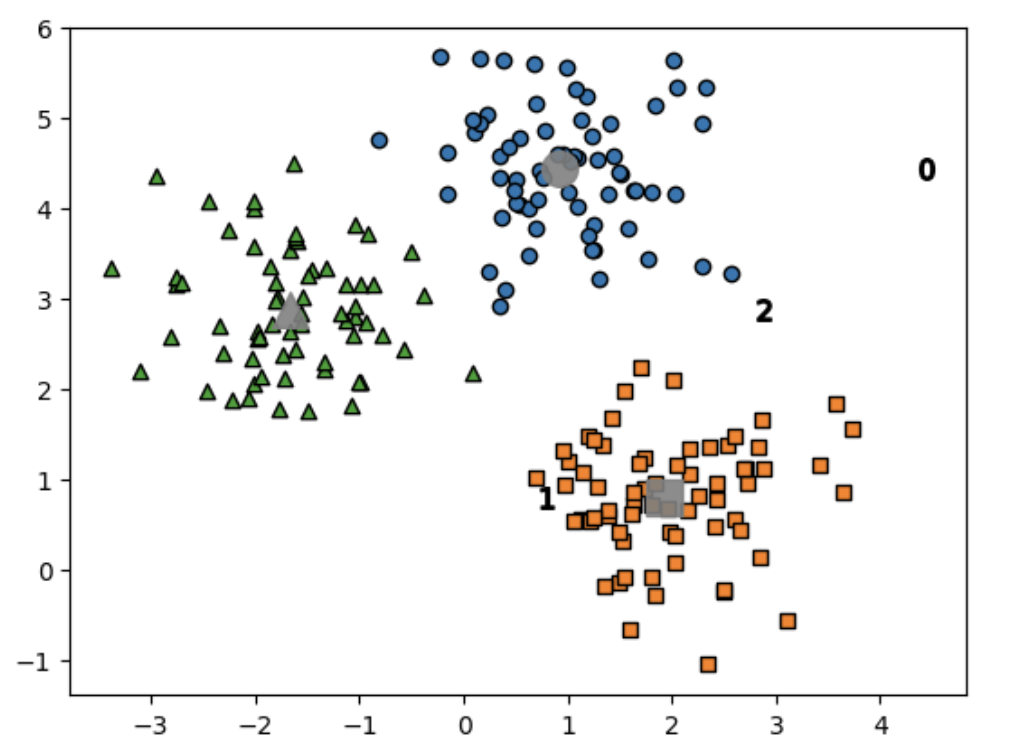
target 값과 군집 label 값을 비교
(Target 값과 군집 label 값이 1:1 로 잘 매칭)
print(clusterDF.groupby('target')['meanshift_label'].value_counts)-
평균 이동의 장점은 데이터 세트의 형태를 특정 형태로 가정한다든가 , 특정 분포도 기반의 모델로 가정하지 않기 때문에 좀 더 유연한 군집화가 가능
-
또한 이상치의 영향력도 크지 않으며 , 미리 군집의 개수를 정할 필요도 없음
-
하지만 알고리즘의 수행 시간이 오래 걸리고 무엇보다도 band-width 의 크기에 따른 군집화 영향도가 매우 큼
-
이 같은 특징 때문에 일반적으로 평균 이동 군집화 기법은 분석 업무 기반의 데이터 세트보다는 컴퓨터 비전 영역에서 더 많이 사용됨
-
이미지나 영상 데이터에서 특정 개체를 구분하거나 움직임을 추적하는 데 뛰어난 역할을 수행하는 알고리즘임
4. GMM(Gaussian Mixture Model)
GMM(Gaussian Mixture Model) 소개
-
GMM 군집화는 군집화를 적용하고자 하는 데이터가 여러 개의 가우시안 분포(Gaussian Distribution)를 가진 데이터 집합들이 섞여서 생성된 것이라는 가정하에 군집화를 수행하는 방식
-
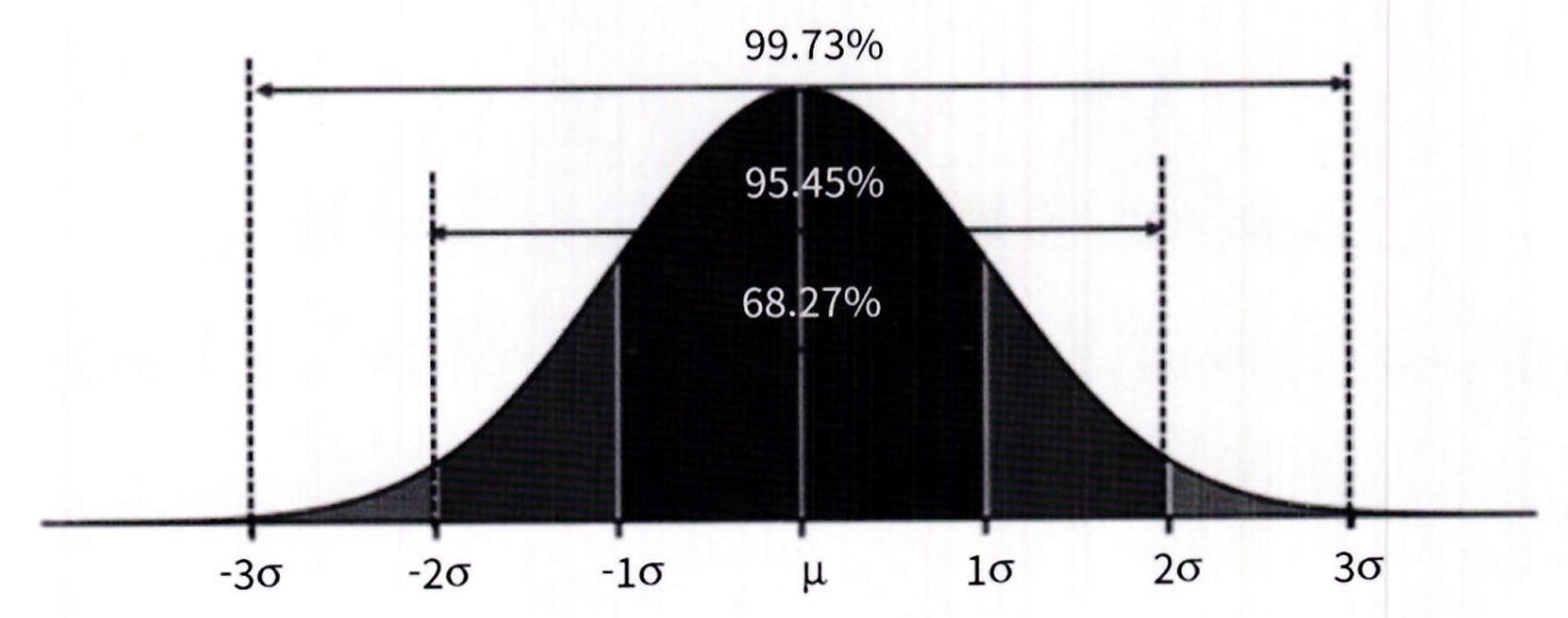
정규 분포 (Normal distribution)로도 알려진 가우시안 분포는 좌우 대칭형의 종(Bell) 형태를 가진 통계학에서 가장 잘 알려진 연속 확률 함수임
-
정규 분포는 평균 를 중심으로 높은 데이터 분포도를 가지고 있음
-
좌우 표준편차 1 에 전체 데이터의 68.27%, 좌우 표준편차 2 에 전체 데이터의 95.45% 를 가지고 있음
-
평균이 0 이고 , 표준편차가 1 인 정규 분포를 표준 정규 분포라고 함
-
GMM(Gaussian Mixture Model) 은 데이터를 여러 개의 가우시안 분포가 섞인 것으로 간주함
-
섞인 데이터 분포에서 개별 유형의 가우시안 분포를 추출합니다. 먼저 다음과 같이 세 개의 가우시안 분포 A, B, C 를 가진 데이터 세트가 있다고 가정
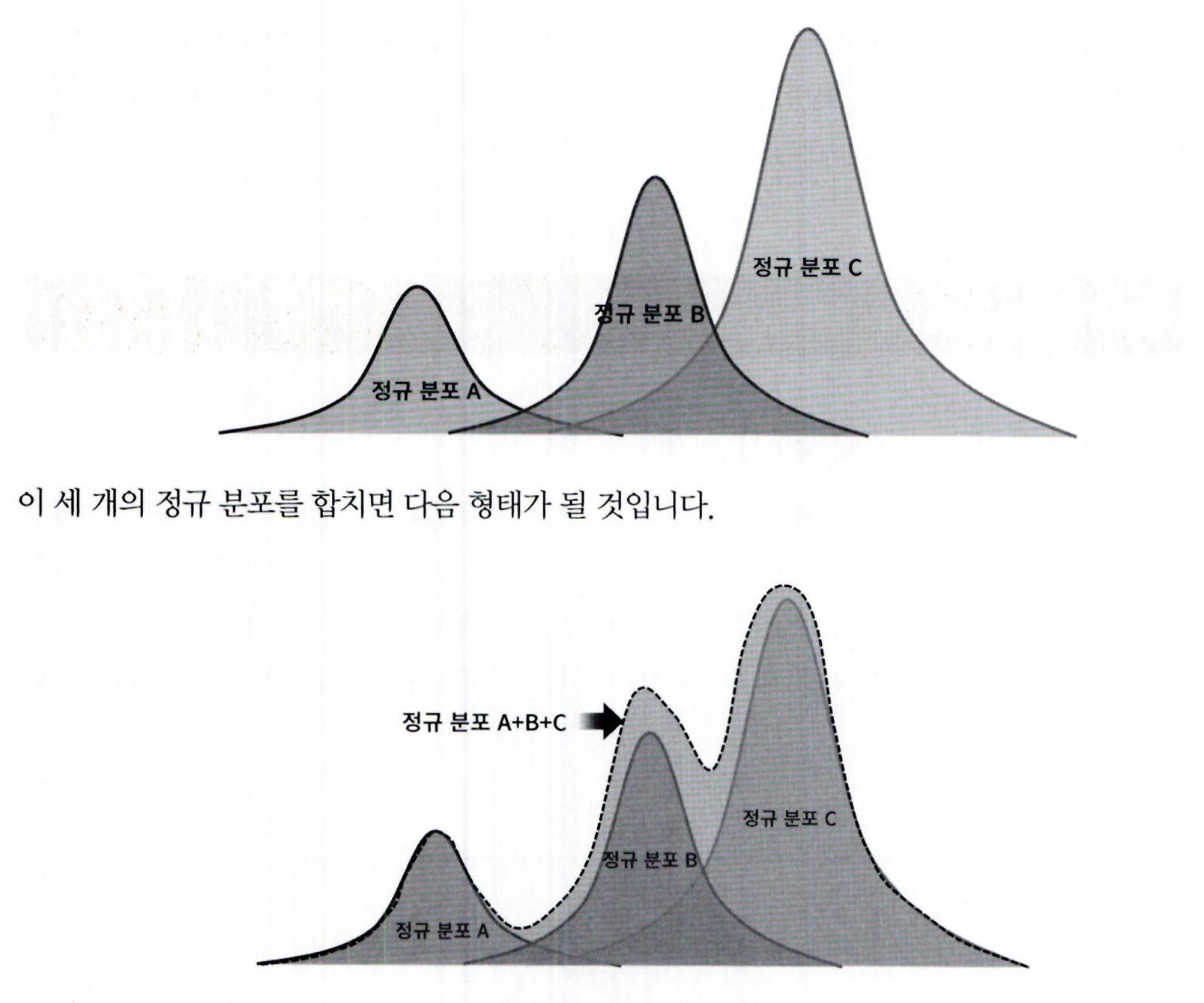
-
군집화를 수행하려는 실제 데이터 세트의 데이터 분포도가 다음과 같다면 쉽게 이 데이터 세트가 정규 분포 A, B, C 가 합쳐서 된 데이터 분포도임을 알 수 있음
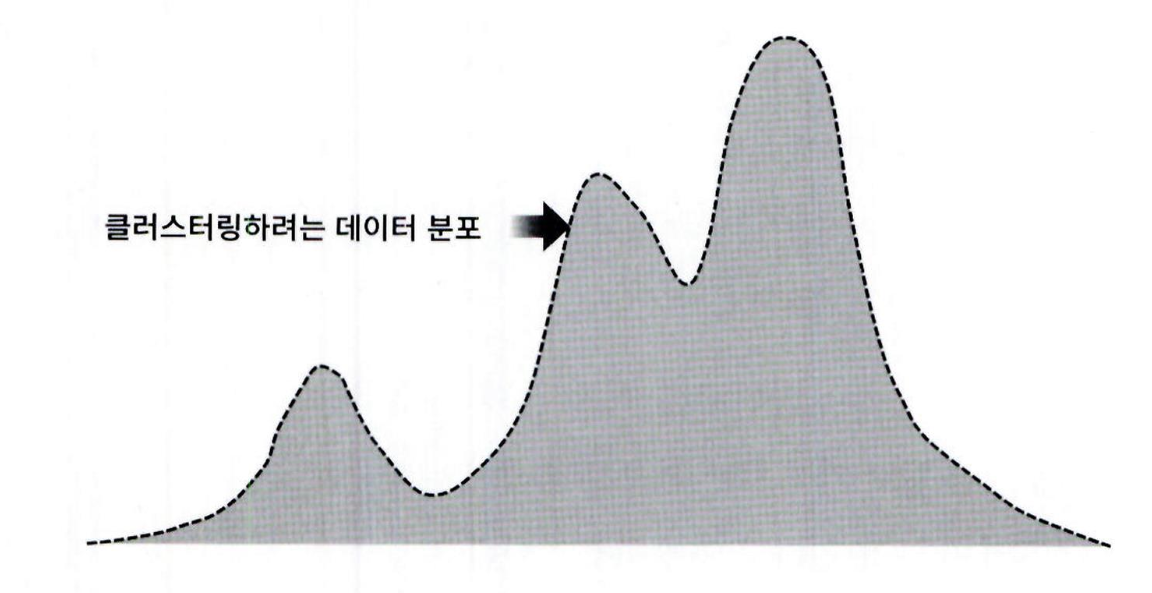
- 전체 데이터 세트는 서로 다른 정규 분포 형태를 가진 여러 가지 확률 분포 곡선으로 구성될 수 있으며 , 이러한 서로 다른 정규 분포에 기반해 군집화을 수행하는 것이 GMM 군집화 방식임
- 가령 1000 개의 데이터 세트가 있다면 이를 구성하는 여러 개의 정규 분포 곡선을 추출하고 , 개별 데이터가 이 중 어떤 정규 분포에 속하는지 결정하는 방식임
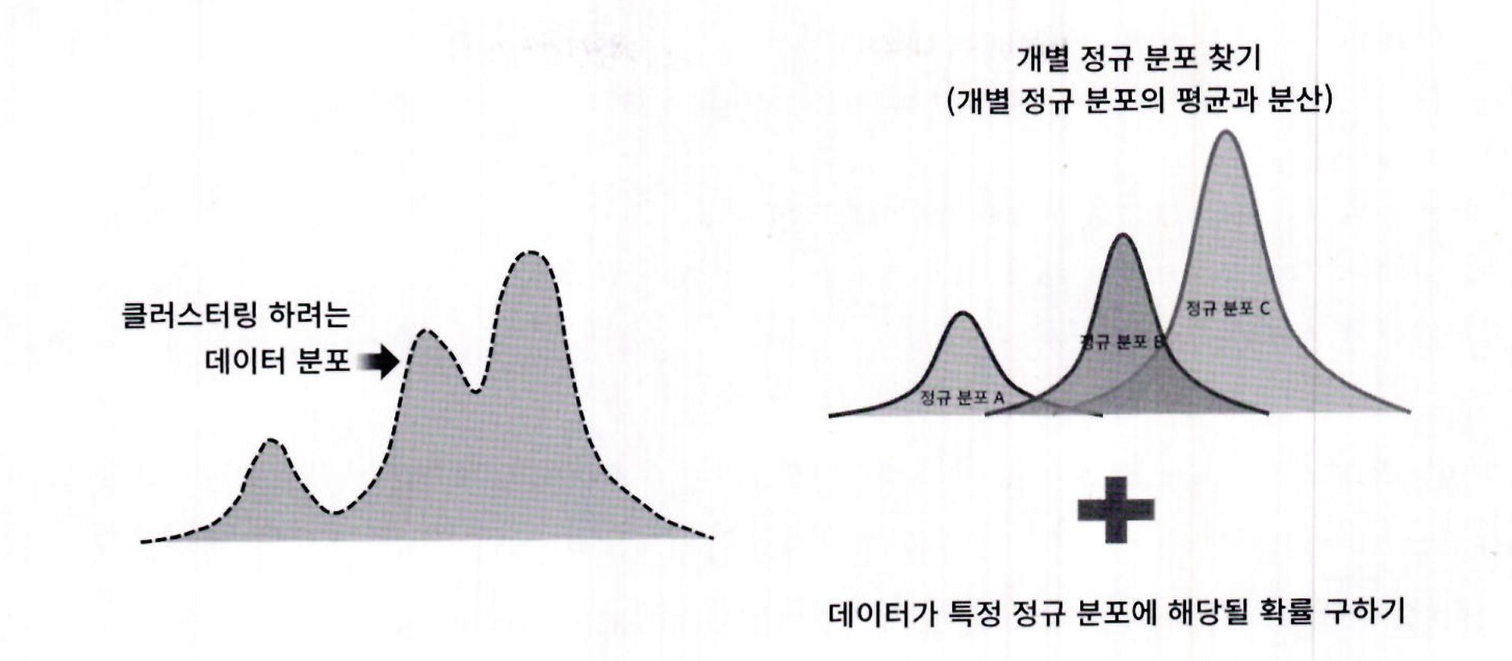
이와 같은 방식은 GMM 에서는 모수 추정이라고 하는데 , 모수 추정은 대표적으로 2 가지를 추정하는 것임
- 개별 정규 분포의 평균과 분산
- 각 데이터가 어떤 정규 분포에 해당되는지의 확률
- 이러한 모수 추정을 위해 GMM 은 EM(Expectation and Maximization) 방법을 적용
-사이킷런은 이러한 GMM 의 EM 방식을 통한 모수 추정 군집화를 지원하기 위해 GaussianMixture 클래스를 지원
GMM 을 이용한 붓꽃 데이터 세트 군집화
- GMM 은 확률 기반 군집화이고 K- 평균은 거리 기반 군집화
- 붓꽃 데이터 세트로 이 두 가지 방식을 이용해 군집화를 수행한 뒤 양쪽 방식을 비교
DataFrame으로 로드
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
feature_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
# 좀 더 편리한 데이터 Handling을 위해 Dataframe 으로 변환
irisDF = pd.DataFrame(data=iris.data, columns=feature_names)
irisDF['target'] = iris.target- GaussianMixture 객체의 가장 중요한 초기화 파라미터는 n_components
- n_components 는 gaussian mixture 의 모델의 총 개수
- K- 평균의 n_clusters와 같이 군집의 개수를 정하는 데 중요한 역할을 수행함 - n_components 를 3 으로 설정하고 GaussianMixture 로 군집화를 수행
GaussianMixture 클래스는 skleamn.mixture 패키지에 위치해 있음에 유의
- GaussianMixture 객체의 fit(피처 데이터 세트) 와 predict(피처 데이터 세트)를 수행해 군집을 결정한 뒤 irisDF DataFrame에
gmm_cluster칼럼명으로 저장하고 나서 타깃별로 군집이 어떻게 매핑됐는지 확인
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=3, random_state=0).fit(iris.data)
gmm_cluster_labels = gmm.predict(iris.data)
# 군집화 결과를 irisDF의 'gm_cluster' 칼럼명으로 저장
irisDF ['gmm_cluster'] = gmm_cluster_labels
irisDF['target'] = iris.target
# target 값에 따라 gmm_cluster 값이 어떻게 매핑됐는지 확인.
iris_result = irisDF.groupby(['target'])['gmm_cluster'].value_counts()
print(iris_result)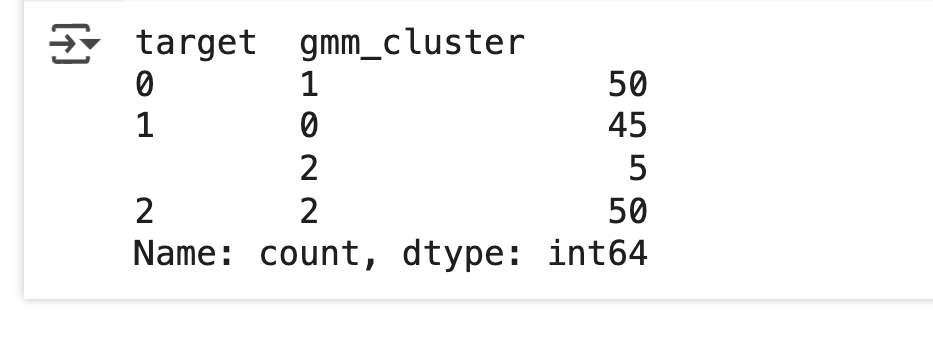
- Target 0 은 cluster 0 으로 , Target 2 는 cluster 1 로 모두 잘 매핑
- Target 1 만 cluster 2 로 45개 (90%), cluster 1 로 5 개 (10%) 매핑됐음
- 앞 절의 붓꽃 데이터 세트의 K- 평균 군집화 결과보다
더 효과적인 분류 결과가 도출됐음
붓꽃 데이터 세트의 K- 평균 군집화를 수행한 결과
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300, random_state=0).fit(iris.data)
kmeans_cluster_labels = kmeans.predict(iris.data)
irisDF['kmeans_cluster'] = kmeans_cluster_labels
iris_result = irisDF.groupby(['target'])['kmeans_cluster'].value_counts()
print(iris_result)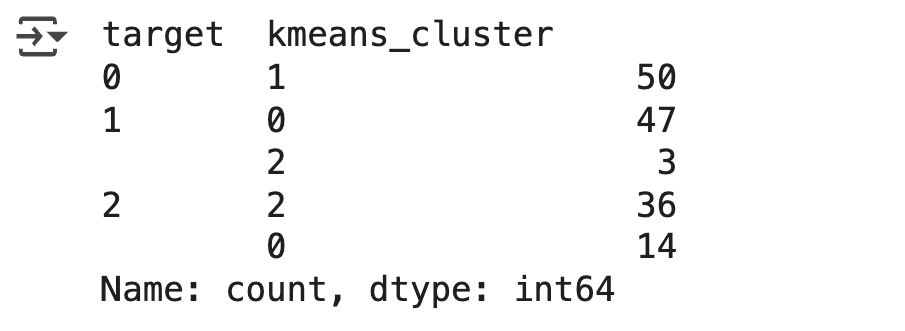
- 이는 어떤 알고리즘에 더 뛰어나다는 의미가 아니라 붓꽃 데이터 세트가 GMM 군집화에 더 효과적이라는 의미임
- K- 평균은 평균 거리 중심으로 중심을 이동하면서 군집화를 수행하는 방식이므로 개별 군집 내의 데이터가 원형으로 흩어져 있는 경우에 매우 효과적으로 군집화가 수행될 수 있음
GMM 과 K-평균의 비교
-
KMeans 는 원형의 범위에서 군집화를 수행합니다. 데이터 세트가 원형의 범위를 가질수록 KMeans 의군집화 효율은 더욱 높아짐
-
다음은 make blobs() 의 군집의 수를 3 개로 하되 , cluster_std 를 0.5 로 설정해 군집 내의 데이터를 뭉치게 유도한 데이터 세트에 KMeans를 적용한 결과임
-
이렇게 cluster_std 를 작게 설정하면 데이터가 원형 형태로 분산될 수 있습니다. 결과를 보면 KMeans 로 효과적으로 군집화됨
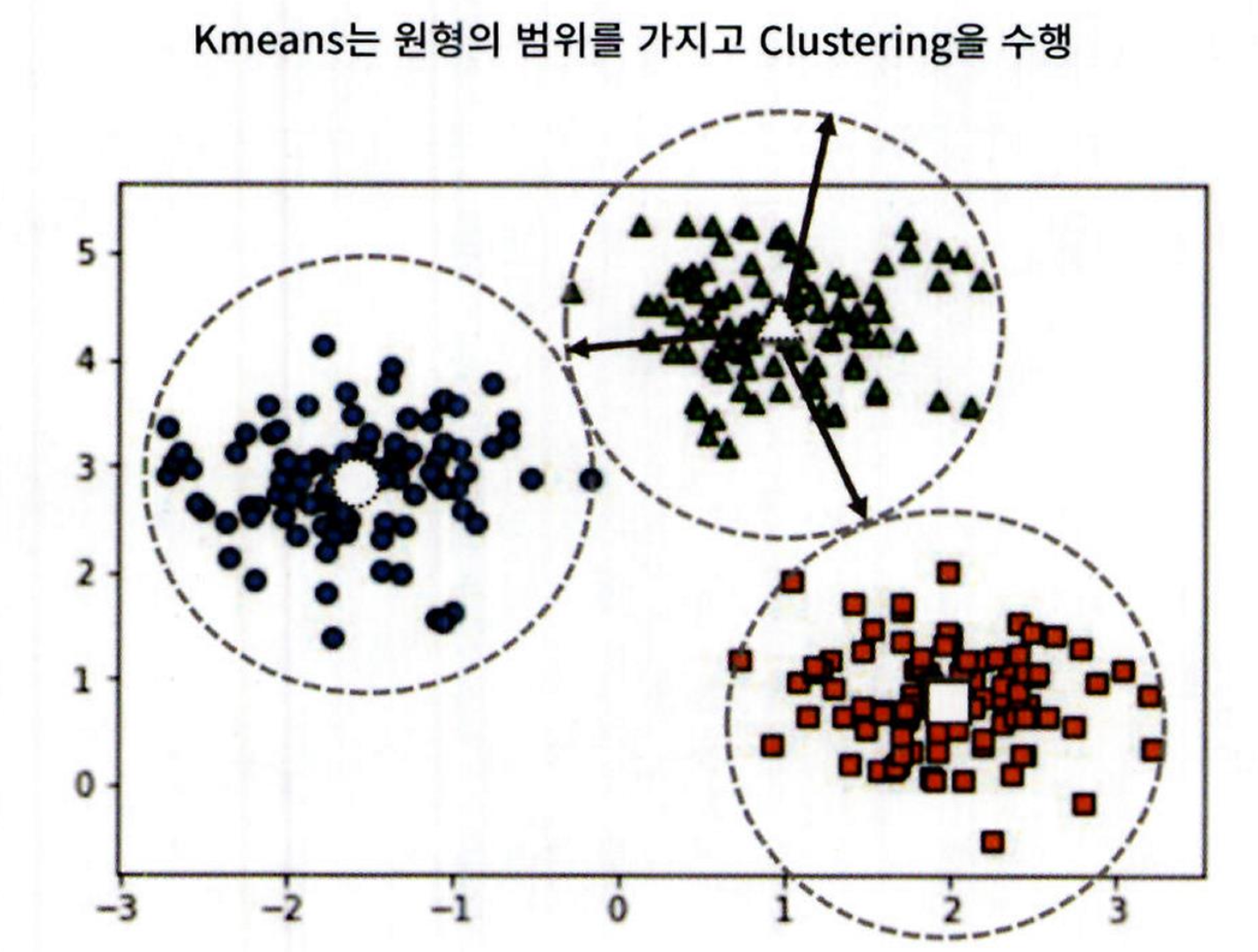
-
KMeans 군집화는 개별 군집의 중심에서 원형의 범위로 데이터를 군집화했음
-
하지만 데이터가 원형의 범위로 퍼져 있지 않는 경우에는 KMeans는 대표적으로 데이터가 길쭉한 타원형으로 늘어선 경우에 군집화를 잘 수행하지 못함.
- 다음에서 해당 데이터 세트를 make_blobs()의 데이터를 변환해 만듦
- 앞으로도 군집을 자주 시각화하므로 이를 위한 별도의 함수
를 만들어 이용함 - 함수명은 visualize_cluster plot(clusterobi, dataframe, label_name,iscluster=True)
- clusterobj: 사이킷런의 군집 수행 객체. KMeans 나 GaussianMixture의 fi( ) 와 predict()로 군집화를 완료한 객체. 만
약 군집화 결과 시각화가 아니고 make_blobs( ) 로 생성한 데이터의 시각화일 경우 None 입력- dataframe: 피처 데이터 세트와 label 값을 가진 DataFrame
- label_name: 군집화 결과 시각화일 경우 datatrame 내의 군집화 label 칼럼명 , make_blobs( ) 결과 시각화일 경우는
dataframe 내의 target 칼럼명- iscenter: 사이킷런 Cluster 객체가 군집 중심 좌표를 제공하면 True, 그렇지 않으면 False
visualize_cluster_plot
import matplotlib.pyplot as plt
import numpy as np
def visualize_cluster_plot(kmeans_model, dataframe, label='target', iscenter=False):
if iscenter:
centers = kmeans_model.cluster_centers_
unique_labels = np.unique(dataframe[label].values)
# Match marker and color as seen in the image
markers = ['o', 's', '^'] # Circle, Square, Triangle
colors = ['navy', 'red', 'green']
for i, cluster_label in enumerate(unique_labels):
label_cluster = dataframe[dataframe[label] == cluster_label]
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'],
c=colors[i], marker=markers[i], edgecolor='k', label=f'Cluster {cluster_label}')
if iscenter:
center_x_y = centers[i]
plt.scatter(x=center_x_y[0], y=center_x_y[1],
s=200, color='white', alpha=0.9, edgecolor='k', marker=markers[i])
plt.scatter(x=center_x_y[0], y=center_x_y[1],
s=70, color='black', edgecolor='k', marker=f"${cluster_label}$")
plt.legend()
plt.xlabel("ftr1")
plt.ylabel("ftr2")
plt.title("Cluster Visualization")
plt.grid(True)
plt.show()
from sklearn.datasets import make_blobs
# make_blobs()로 300 개의 데이터 세트 , 3 개의 군집 세트 , cluster_Std=0.5를 만듦.
X, y = make_blobs(n_samples=300, n_features=2, centers=3, cluster_std=0.5, random_state=0)
# 길게 늘어난 타원형의 데이터 세트를 생성하기 위해 변환함.
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
X_aniso = np.dot(X, transformation)
# feature 데이터 세트와 make_blobs( ) 의 y 결값을 Dataframe 으로 저장
clusterDF = pd.DataFrame(data=X_aniso, columns=['ftr1', 'ftr2'])
clusterDF['target'] = y
# 생성된 데이터 세트를 target 별로 다른 마커로 표시해 시각화함
visualize_cluster_plot(None, clusterDF, 'target', iscenter=False)
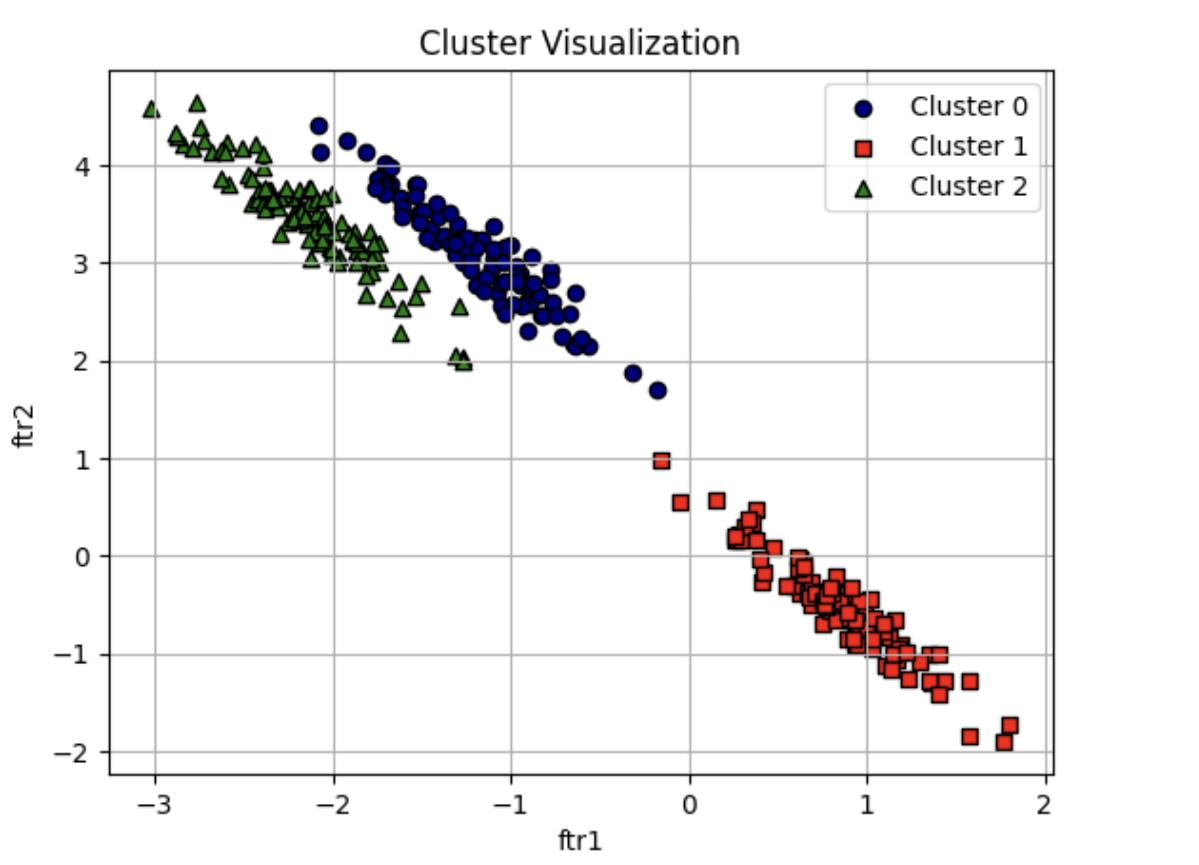
위와 같이 만들어진 데이터 세트에서는 KMeans 의 군집화 정확성이 떨어지게 됩니다. KMeans 가 위 데이터 세트를 어떻게 군집화하는지 확인
# 3 개의 군집 기반 Kmeans 를 X_aniso 데이터 세트에 적용
kmeans = KMeans (3, random_state=0)
kmeans_label = kmeans.fit_predict(X_aniso)
clusterDF['kmeans_label'] = kmeans_label
visualize_cluster_plot(kmeans, clusterDF, 'kmeans_label', iscenter=True)- KMeans 로 군집화를 수행할 경우 , 주로 원형 영역 위치로 개별 군집화가 되면서 원하는 방향으로 구성되지 않음
- KMeans 가 평균 거리 기반으로 군집화를 수행하므로 같은 거리상 원형으로 군집을 구성하면서 위와 같이 길쭉한 방향으로 데이터가 밀접해 있을 경우에는 최적의 군집화가 어려움
GMM 으로 군집화를 수행
# 3 개의 n_components 기반 GMM 을 X_aniso 데이터 세트에 적용
gmm = GaussianMixture(n_components=3, random_state=0)
gmm_label = gmm.fit(X_aniso).predict(X_aniso)
clusterDF ['gmm_label'] = gmm_label
# GaussianMixture는 cluster_centers_ 속성이 없으므로 iscenter를 False로 설정.
visualize_cluster_plot(gmm, clusterDF, 'gmm_label', iscenter=False)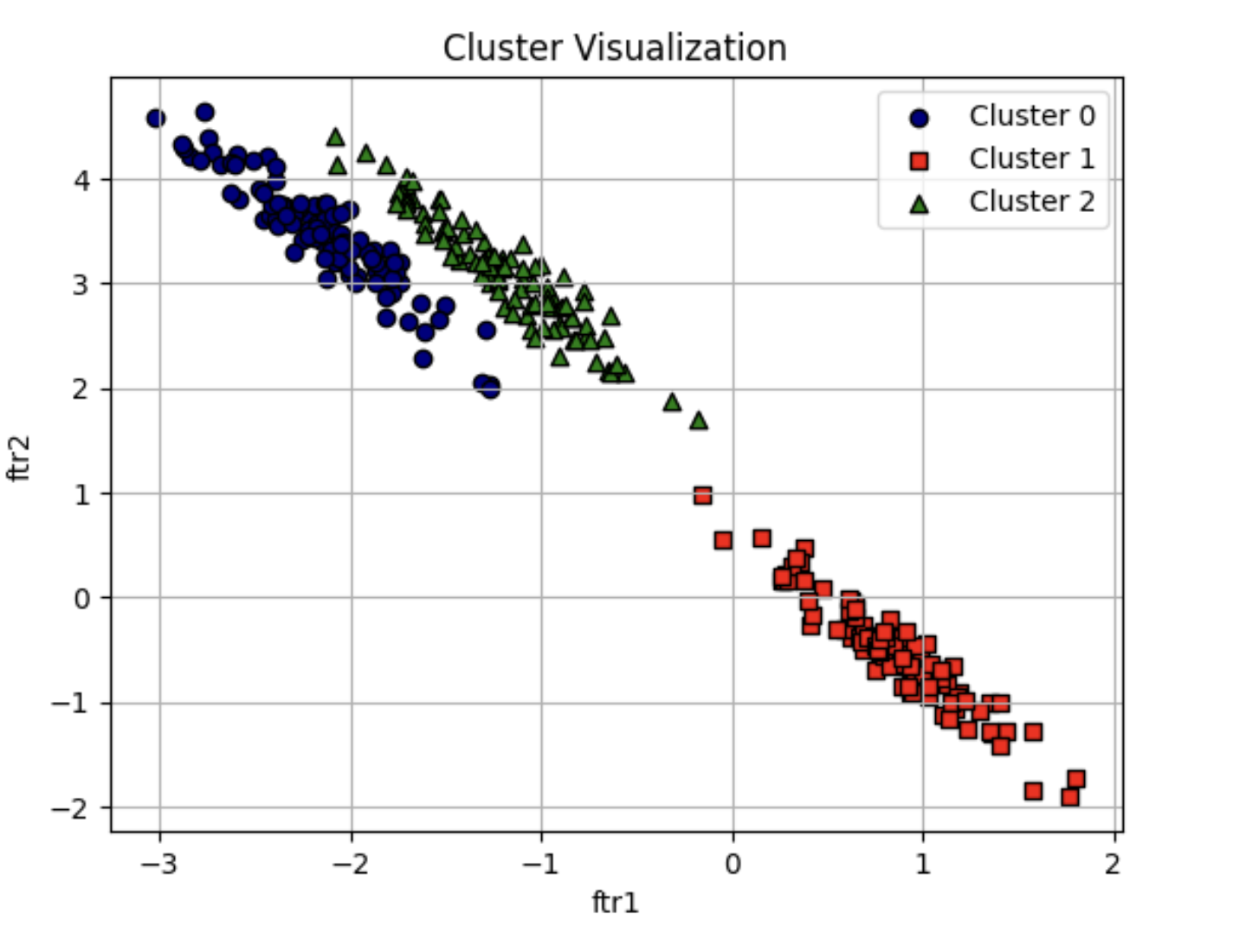
- 데이터가 분포된 방향에 따라 정확하게 군집화됐음
- GMM 은 K-평균과 다르게 군집의 중심 좌표를 구할 수 없기 때문에 군집 중심 표현이 visualize_cluster_plot()에서 시각화되지 않음
make_blobs()의 target 값과 KMeans, GMM 의 군집 Label 값을 서로 비교해 위와 같은 데이터 세트에서 얼만큼의 군집화 효율 차이가 발생하는지 확인
print('### KMeans Clustering ###')
print(clusterDF.groupby ('target')['kmeans_label'].value_counts())
print('\n### Gaussian Mixture Clustering ###')
print(clusterDF.groupby('target')['gmm_label'].value_counts())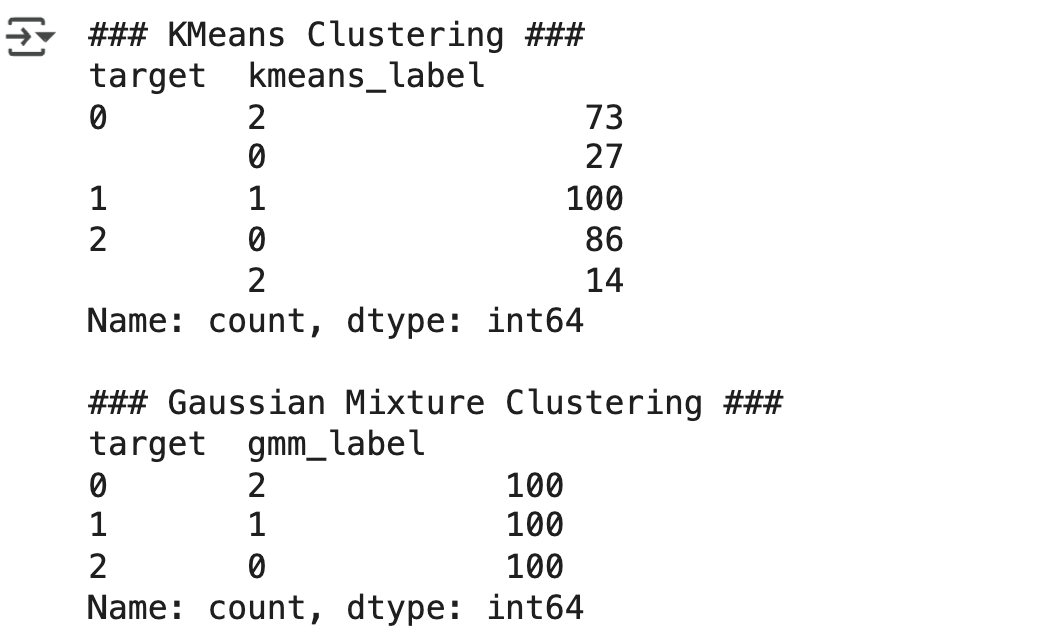
- KMeans 의 경우 군집 1 번만 정확히 매핑됐지만 , 나머지 군집의 경우 target 값과 어긋나는 경우가 발생하고 있음.
- 하지만 GMM 의 경우는 군집이 target 값과 잘 매핑돼 있음
- 이처럼 GMM 의 경우는 KMeans 보다 유연하게 다양한 데이터 세트에 잘 적용될 수 있다는 장점이 있음
- 하지만 군집화를 위한 수행 시간이 오래 걸린다는 단점이 있음
5. DBSCAN
DBSCAN (Density Based Spatial Clustering of Applications with Noise) 개요
- 밀도 기반 군집화의 대표적인 알고리즘
- DBSCAN 은 간단하고 직관적인 알고리즘으로 돼있음에도 데이터의 분포가 기하학적으로 복잡한 데이터 세트에도 효과적인 군집화가 가능
- 다음과 같이 내부의 원 모양과 외부의 원 모양 형태의 분포를 가진 데이터 세트를 군집화한다고 가정할 때 앞에서 소개한 K 평균 , 평균 이동 , GMM 으로는 효과적인 군집화를 수행하기가 어려움.
- 특정 공간 내에 데이터 밀도 차이를 기반 알고리즘으로 하고 있어서 복잡한 기하학적 분포도를 가진 데이터 세트에 대해서도 군집화를 잘 수행함
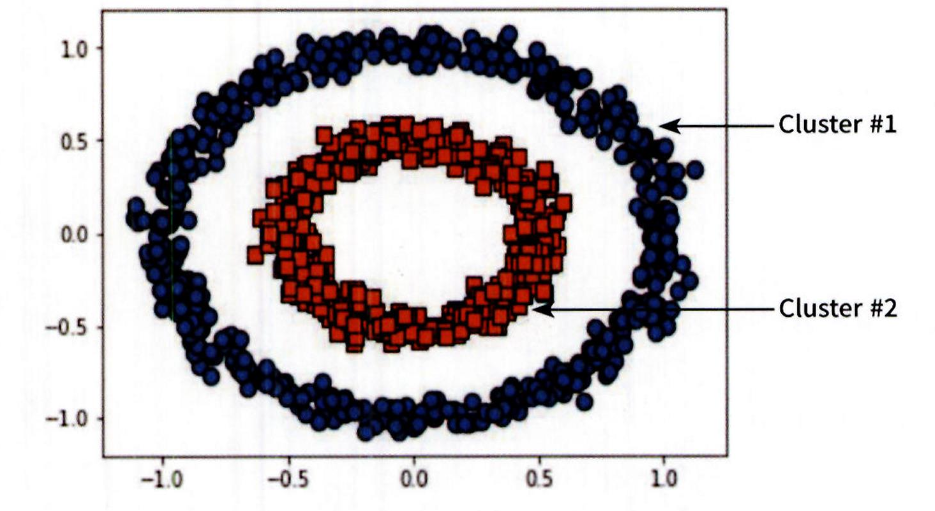
- DBSCAN 을 구성하는 가장 중요한 두 가지 파라미터는 입실론 (epsilon) 으로 표기하는 주변 영역과 이 입실론 주변 영역에 포함되는 최소 데이터의 개수 min points 임
입실론 주변 영역 (epsilon): 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역입니다.최소 데이터 개수 (min points): 개별 데이터의 입실론 주변 영역에 포함되는 타 데이터의 개수입니다.
입실론 주변 영역 내에 포함되는 최소 데이터 개수를 충족시키는가 아닌가에 따라 데이터 포인트를 다음과 같이 정의
핵심 포인트 (Core Point): 주변 영역 내에 최소 데이터 개수 이상의 타 데이터를 가지고 있을 경우 해당 데이터를 핵심 포
인트라고 합니다.이웃 포인트 (Neighbor Point): 주변 영역 내에 위치한 타 데이터를 이웃 포인트라고 합니다.경계 포인트 (Border Point): 주변 영역 내에 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않지만 핵심 포인트를
이웃 포인트로 가지고 있는 데이터를 경계 포인트라고 합니다.잡음 포인트 (Noise Point): 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않으며 , 핵심 포인트도 이웃 포인트로 가
지고 있지 않는 데이터를 잡음 포인트라고 합니다.
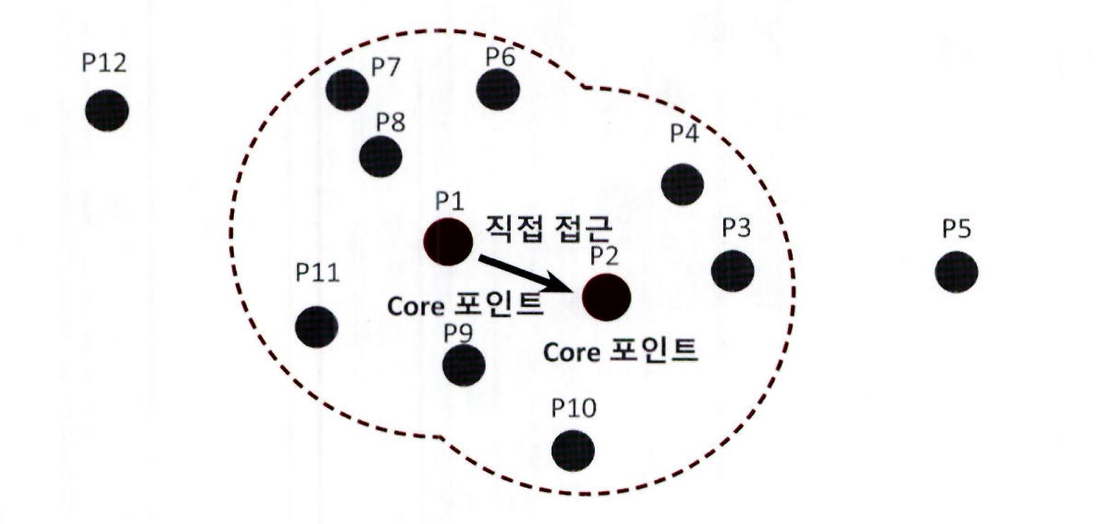
- 다음 그림과 같이 P1 에서 P12 까지 12 개의 데이터 세트에 대해서 DBSCAN 군집화를 적용하면서 주요 개념을 설명
특정 입실론 반경 내에 포함될 최소 데이터 세트를 6 개로 (자기 자신의 데이터를 포함) 가정
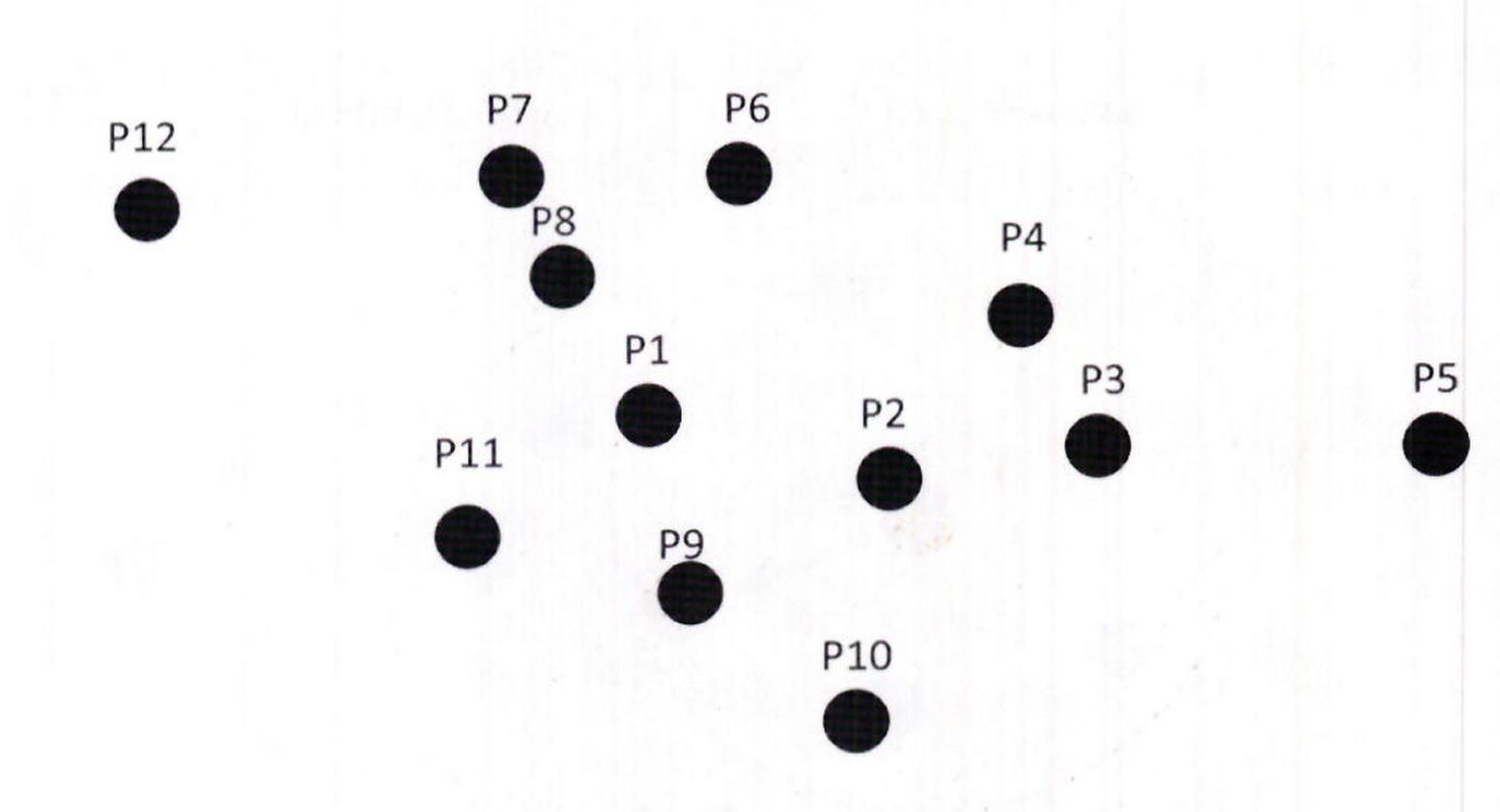
2. P1 데이터를 기준으로 입실론 반경 내에 포함된 데이터가 7 개 ( 자신은 P1, 이웃 데이터 P2, P6, P7, P8, P9, P11) 로 최소 데이터 5 개 이상을 만족하므로 P1 데이터는 핵심 포인트 (Core Point)
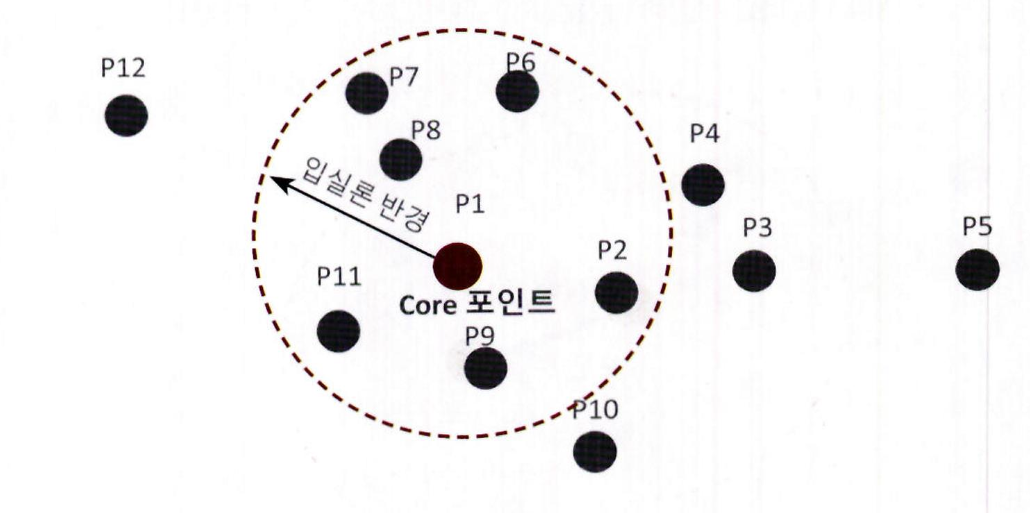
3. 다음으로 P2 데이터 포인트를 살펴보겠습니다. P2 역시 반경 내에 6 개의 데이터 ( 자신은 P2, 이웃 데이터 P1, P3, P4, P9, P10) 를 가지고 있으므로 핵심 포인트임
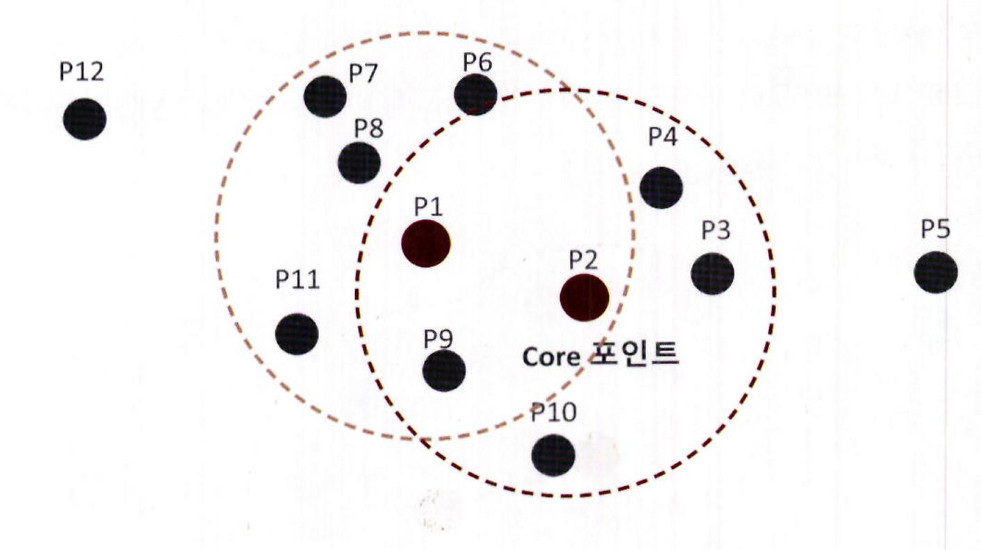
4. 핵심 포인트 P1 의 이웃 데이터 포인트 P2 역시 핵심 포인트일 경우 P1 에서 P2 로 연결해 직접 접근이 가능
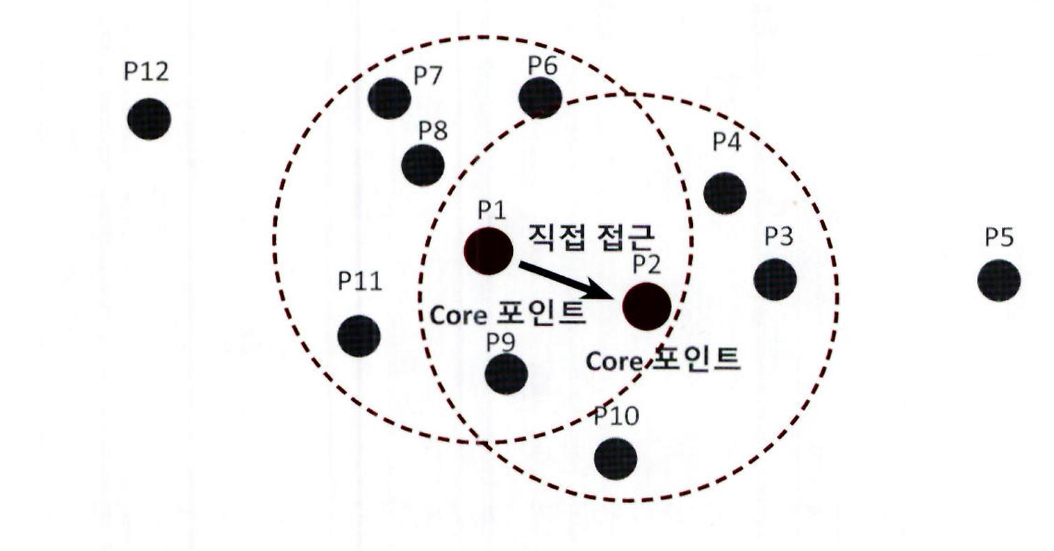
5. 특정 핵심 포인트에서 직접 접근이 가능한 다른 핵심 포인트를 서로 연결하면서 군집화를 구성함
이러한 방식으로 점차적으로 군집 (Cluster) 영역을 확장해 나가는 것이 DBSCAN 군집화 방식임
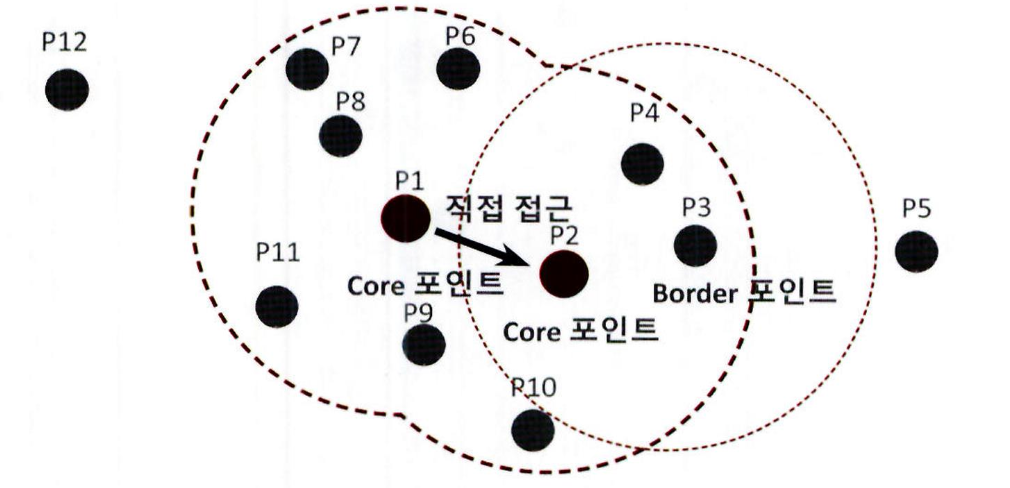
- P3 데이터의 경우 반경 내에 포함되는 이웃 데이터는 P2, P4 로 2 개이므로 군집으로 구분할 수 있는 핵심 포인트가 될 수 없음
- 하지만 이웃 데이터 중에 핵심 포인트인 P2 를 가지고 있습니다. 이처럼 자신은 핵심 포인트가 아니지만 , 이웃 데이터로 핵심 포인트를 가지고 있는 데이터를 경계 포인트 (Border Point) 라고 함 (경계 포인트:군집의 외곽을 형성함)
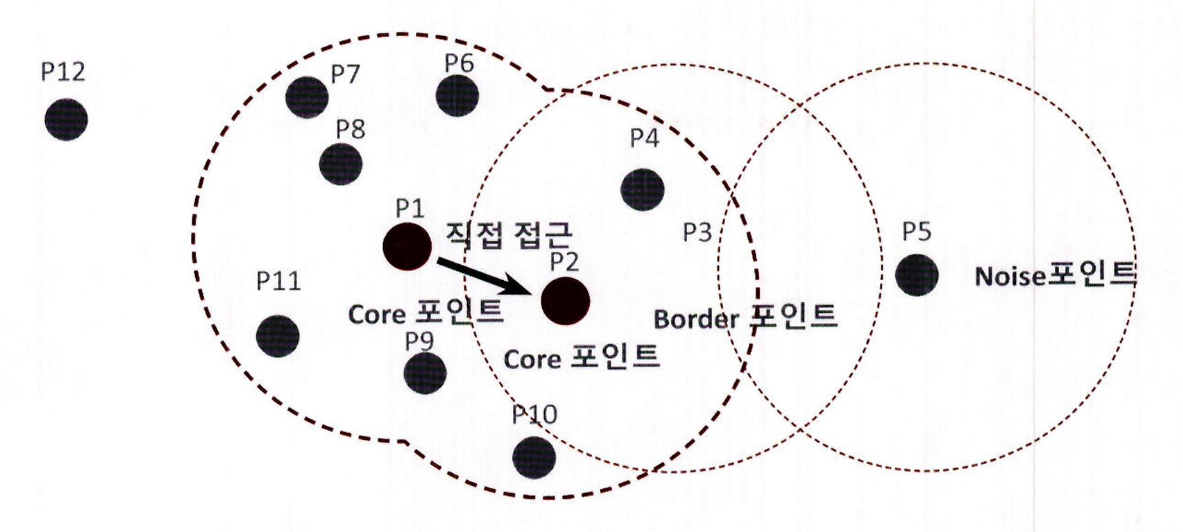
- 다음 그림의 P5 와 같이 반경 내에 최소 데이터를 가지고 있지도 않고 , 핵심 포인트 또한 이웃 데이터로 가지고 있지 않는 데이터를 잡음 포인트 (Noise Point) 라고 함
-
DBSCAN 은 이처럼 입실론 주변 영역의 최소 데이터 개수를 포함하는 밀도 기준을 충족시키는 데이터인 핵심 포인트를 연결하면서 군집화를 구성하는 방식임.
-
사이킷런은 DBSCAN 클래스를 통해 DBSCAN 알고리즘을 지원합니다. DBSCAN 클래스는 다음과 같은 주요한 초기화 파라미터를 가지고 있음
-
eps: 입실론 주변 영역의 반경을 의미
-
min_samples: 핵심 포인트가 되기 위해 입실론 주변 영역 내에 포함돼야 할 데이터의 최소 개수를 의미합니다 ( 자신의 데이터를 포함합니다. 위에서 설명한 min points + 1).
DBSCAN 적용하기 - 붓꽃 데이터 세트
-먼저 새로운 주피터 노트북을 생성 하고 붓꽃 데이터 세트를 DataFrame 으로 로딩
DBSCAN 클래스를 이용해 붓꽃 데이터 세트를 군집화
(eps=0.6, min_samples=8 ; 일반적으로 eps 값으로는 1 이하의 값을 설정합니다.)
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.6, min_samples=8, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
irisDF['dbscan_cluster'] = dbscan_labels
irisDF['target'] = iris.target
iris_result = irisDF .groupby(['target'])['dbscan_cluster'].value_counts()
print(iris_result)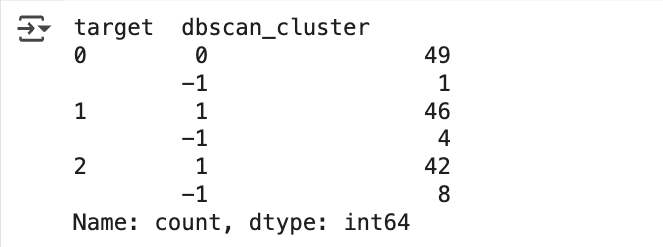
- dbscan_cluster 값 0 과 1 외에 특이하게 1 이 군집 레이블로 있음
- 군집 레이블이 -1 인 것은 노이즈에 속하는 군집을 의미
- 따라서 위 붓꽃 데이터 세트는 DBSCAN 에서 0 과 1 두 개의 군집으로 군집화됐음 Target 값의 유형이 3 가지인데 , 군집이 2 개가 됐다고 군집화 효율이 떨어진다는 의미는 아님
- DBSCAN 은 군집의 개수를 알고리즘에 따라 자동으로 지정하므로 DBSCAN 에서 군집의 개수를 지정하는 것은 무의미하다고 할 수 있음
- 특히 붓꽃 데이터 세트는 군집을 3 개로 하는 것보다는 2 개로 하는 것이 군집화의 효율로서 더 좋은 면이 있음
- DBSCAN 으로 군집화 데이터 세트를 2 차원 평면에서 표현하기 위해 PCA 를 이용해 2 개의 피처로 압죽 변환한 뒤 , 앞 예제에서 사용한 visualize_cluster_plot() 함수를 이용해 시각화
- visualize_custer_plot() 함수 인자로 사용하기 위해 irisDF 의 frl', 'fr2' 칼럼에 PCA 로 변환된 피처 데이터 세트를 입력
import matplotlib.pyplot as plt
import numpy as np
def visualize_cluster_plot(kmeans_model, dataframe, label='target', iscenter=False):
if iscenter:
centers = kmeans_model.cluster_centers_
unique_labels = np.unique(dataframe[label].values)
# Match marker and color as seen in the image
markers = ['*', 'o', 's'] # Circle, Square, Triangle
colors = ['navy', 'red', 'green']
for i, cluster_label in enumerate(unique_labels):
label_cluster = dataframe[dataframe[label] == cluster_label]
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'],
c=colors[i], marker=markers[i], edgecolor='k', label=f'Cluster {cluster_label}')
if iscenter:
center_x_y = centers[i]
plt.scatter(x=center_x_y[0], y=center_x_y[1],
s=200, color='white', alpha=0.9, edgecolor='k', marker=markers[i])
plt.scatter(x=center_x_y[0], y=center_x_y[1],
s=70, color='black', edgecolor='k', marker=f"${cluster_label}$")
plt.legend()
plt.xlabel("ftr1")
plt.ylabel("ftr2")
plt.title("Cluster Visualization")
plt.grid(True)
plt.show()
from sklearn.decomposition import PCA
# 2 차원으로 시각화하기 위해 PCA n_componets=2 로 피처 데이터 세트 변환
pca = PCA(n_components=2, random_state=0)
pca_transformed = pca.fit_transform(iris.data)
# visualize_cluster plot() 함수는 ftr1, ftr2 칼럼을 좌표에 표현하므로 PCA 변환값을 해당 칼럼으로 생성
irisDF['ftr1'] = pca_transformed [:, 0]
irisDF['ftr2'] = pca_transformed[:, 1]
visualize_cluster_plot(dbscan, irisDF, 'dbscan_cluster', iscenter=False)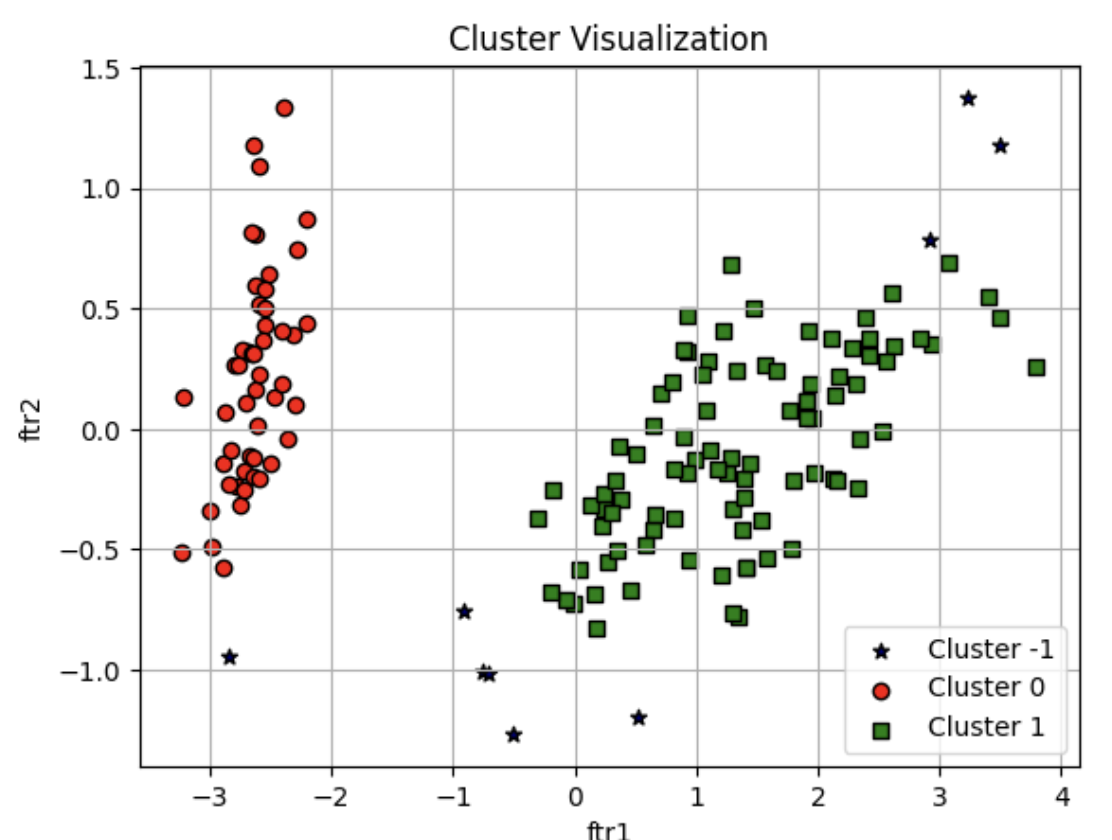
- 별표 (*) = 모두 노이즈
- PCA 로 2 차원으로 표현하면 이상치인 노이즈 데이터가 명확히 드러남
- DBSCAN 을 적용할 때는 특정 군집 개수로 군집을 강제하지 않는 것이 좋음
- DBSCAN 알고리즘에 적절한 eps 와 min_Samples 파라미터를 통해 최적의 군집을 찾는 게 중요함
- 일반적으로 cps 의 값을 크게 하면 반경이 커져 포함하는 데이터가 많아지므로 노이즈 데이터 개수가 작아짐
- min_samples를 크게 하면 주어진 반경 내에서 더 많은 데이터를 포함시켜야 하므로 노이즈 데이터 개수가 커짐
- 데이터 밀도가 더 커져야 하는데 , 매우 촘촘한 데이터 분포가 아
닌 경우 노이즈로 인식하기 때문임 - eps 를 기존의 0.6 에서 0.8 로 증가시키면 노이즈 데이터 수가 줄어듦
import matplotlib.pyplot as plt
def visualize_cluster_2d(df, cluster_col, centers=None, legend=True):
unique_labels = df[cluster_col].unique()
markers = ['o', 's', '^', 'P', '*', 'X', 'D']
for label in unique_labels:
label_data = df[df[cluster_col] == label]
if label == -1:
# Noise
plt.scatter(label_data['ftr1'], label_data['ftr2'],
c='k', marker='*', label='Noise')
else:
plt.scatter(label_data['ftr1'], label_data['ftr2'],
marker=markers[label % len(markers)],
label=f'Cluster {label}')
if centers is not None:
plt.scatter(centers[:, 0], centers[:, 1], s=250, marker='+', c='white', edgecolors='black', label='Centers')
if legend:
plt.legend()
plt.xlabel('ftr1')
plt.ylabel('ftr2')
plt.title(f'2D Cluster Visualization: {cluster_col}')
plt.show()
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.8, min_samples=8, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
irisDF['dbscan_cluster'] = dbscan_labels
irisDF['target'] = iris.target
iris_result = irisDF .groupby(['target'])['dbscan_cluster'].value_counts()
print(iris_result)
visualize_cluster_2d(irisDF, 'dbscan_cluster', centers=None, legend=True)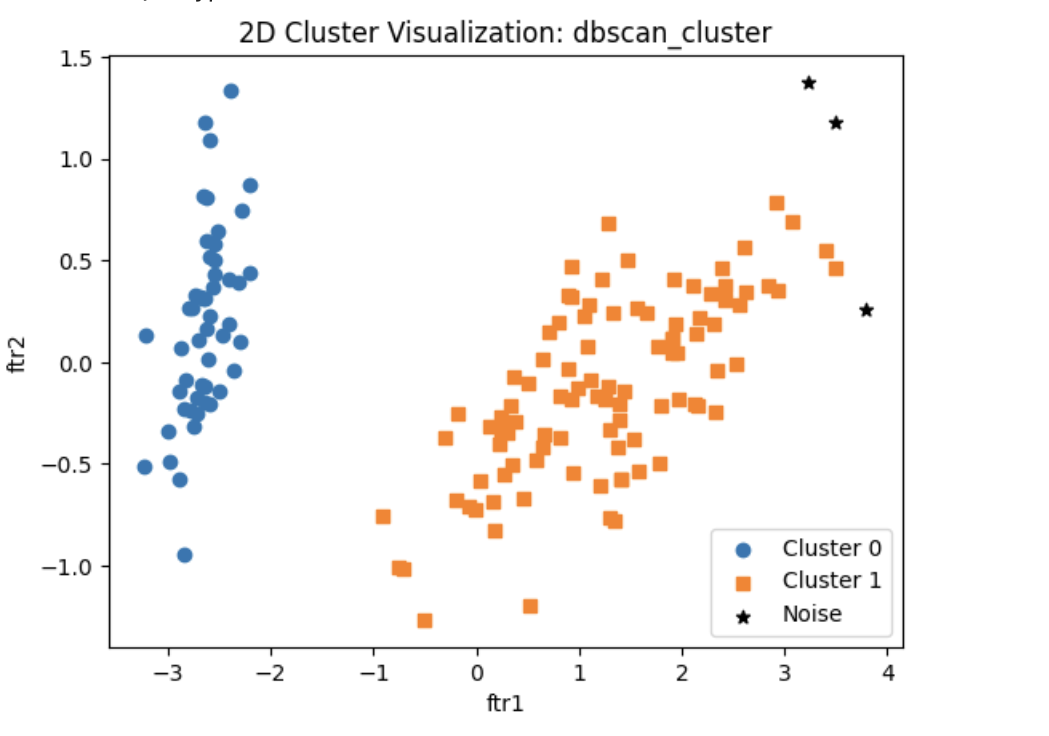
- 노이즈 군집인 1 이 3 개밖에 없음
- 기존에 eps가 0.6 일 때 노이즈로 분류된 데이터 세트는 eps 반경이 커지면서 Cluster 1 에 소속됐음
- 이번에는 eps 를 기존 0.6 으로 유지하고 min_Samples 를 16 으로 늚
- 바로 위 예제 코드에서 DBSCAN 의 초기화 파라미터 값만 다음과 같이 변경
하면 됨
from sklearn.cluster import DBSCAN
dbscan = DBSCAN (eps=0.6, min_samples=16, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
irisDF['dbscan_cluster'] = dbscan_labels
irisDF['target'] = iris.target
iris_result = irisDF .groupby(['target'])['dbscan_cluster'].value_counts()
print(iris_result)
visualize_cluster_2d(irisDF, 'dbscan_cluster', centers=None, legend=True)
노이즈 데이터가 기존보다 많이 증가함을 알 수 있음
DBSCAN 적용하기 - make_circles() 데이터 세트
-
복잡한 기하학적 분포를 가지는 데이터 세트에서 DBSCAN 과 타 알고리즘을 비교
-
먼저 make_circles() 함수를 이용해 내부 원과 외부 원 형태로 돼 있는 2 차원 데이터 세트를 만듦
-
make_circles() 함수는 오직 2 개의 피처만을 생성하므로 별도의 피처 개수를 지정할 필요가 없음.
-
파라미터 noise 는 노이즈 데이터 세트의 비율이며 , factor 는 외부 원과 내부 원의 scale 비율임.
from sklearn.datasets import make_circles
X, y = make_circles(n_samples=1000, shuffle=True, noise=0.05, random_state=0, factor=0.5)
clusterDF = pd.DataFrame(data=X, columns=['ftr1', 'ftr2'])
clusterDF ['target'] = y
visualize_cluster_plot(None, clusterDF, 'target', iscenter=False)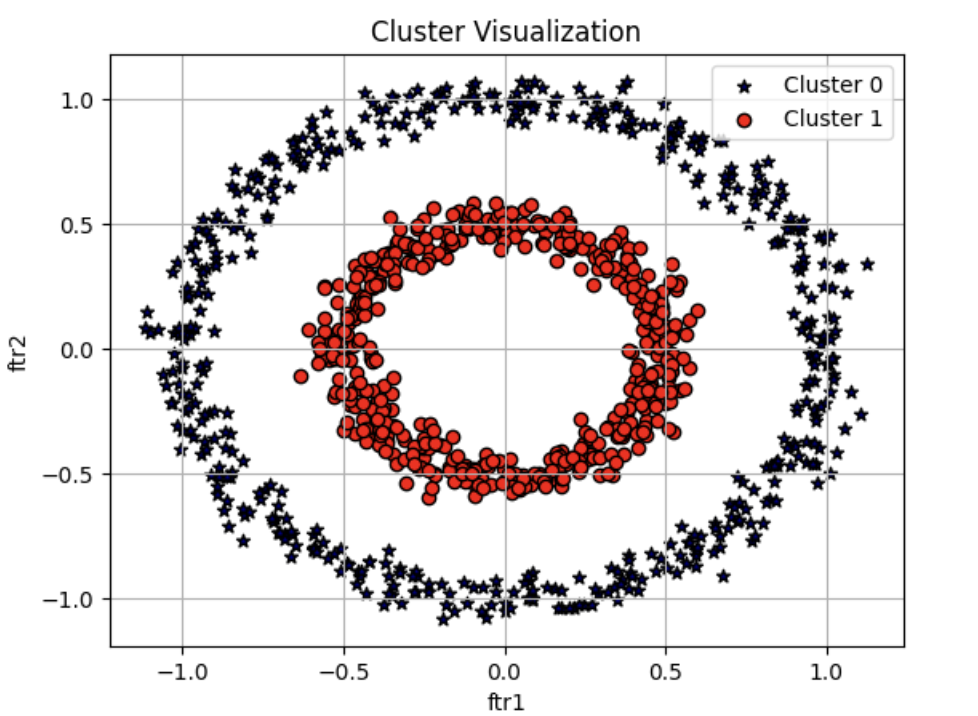
make_circles()는 내부 원과 외부 원으로 구분되는 데이터 세트를 생성함을 알 수 있습니다.- DBSCAN 이 이 데이터 세트를 군집화한 결과를 보기 전에 먼저 K- 평균과 GMM 은 어떻게 이 데이터 세트를 군집화하는지 확인해 보겠습니다.
- 먼저 K- 평균으로 make_circles() 데이터 세트를 군집화해 보겠습니다.
# KMeans 로 make_circles( ) 데이터 세트를 군집화 수행.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, max_iter=1000, random_state=0)
kmeans_labels = kmeans.fit_predict(X)
clusterDF ['kmeans_cluster'] = kmeans_labels
visualize_cluster_plot(kmeans, clusterDF, 'kmeans_cluster', iscenter=True)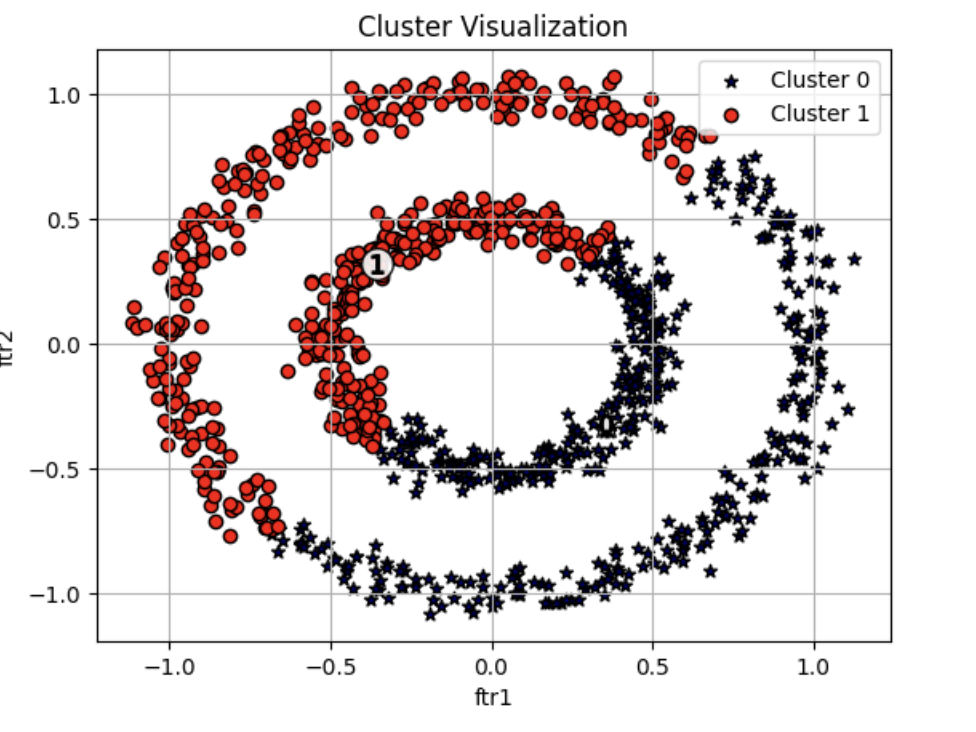
- 위 , 아래 군집 중심을 기반으로 위와 아래 절반으로 군집화됐음.
- 데이터가 특정한 형태로 지속해서 이어지는 부분을 찾아내기 어려움
다음으로는 GMM 을 적용해 보겠습니다.
# GMN 으로 make_circles( ) 데이터 세트를 군집화 수행.
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=2, random_state=0)
gmm_label = gmm.fit(X).predict(X)
clusterDF['gmm_cluster'] = gmm_label
visualize_cluster_plot(gmm, clusterDF, 'gmm_cluster', iscenter=False)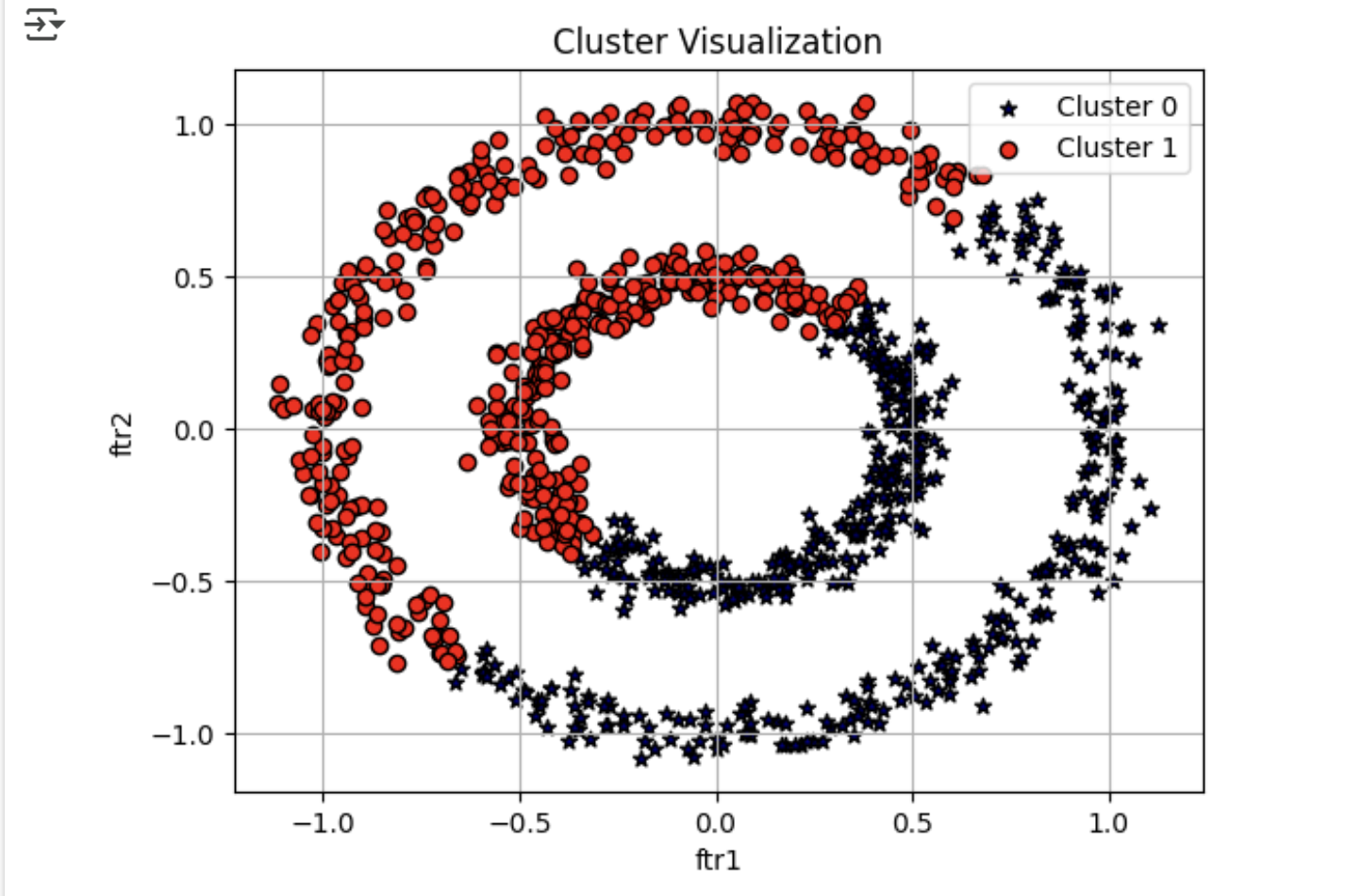
- GMM 도 앞 절의 일렬로 늘어선 데이터 세트에서는 효과적으로 군집화 적용이 가능했으나, 내부와 외부의 원형으로 구성된 더 복잡한 형태의 데이터 세트에서는 군집화가 원하는 방향으로 되지 않았음
- 이제 DBSCAN 으로 군집화를 적용해 보겠습니다.
# DBSCAN 으로 make_circles( ) 데이터 세트 군집화 수행.
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.2, min_samples=10, metric='euclidean')
dbscan_labels = dbscan.fit_predict(X)
clusterDF['dbscan_cluster'] = dbscan_labels
visualize_cluster_plot(dbscan, clusterDF, 'dbscan_cluster', iscenter=False)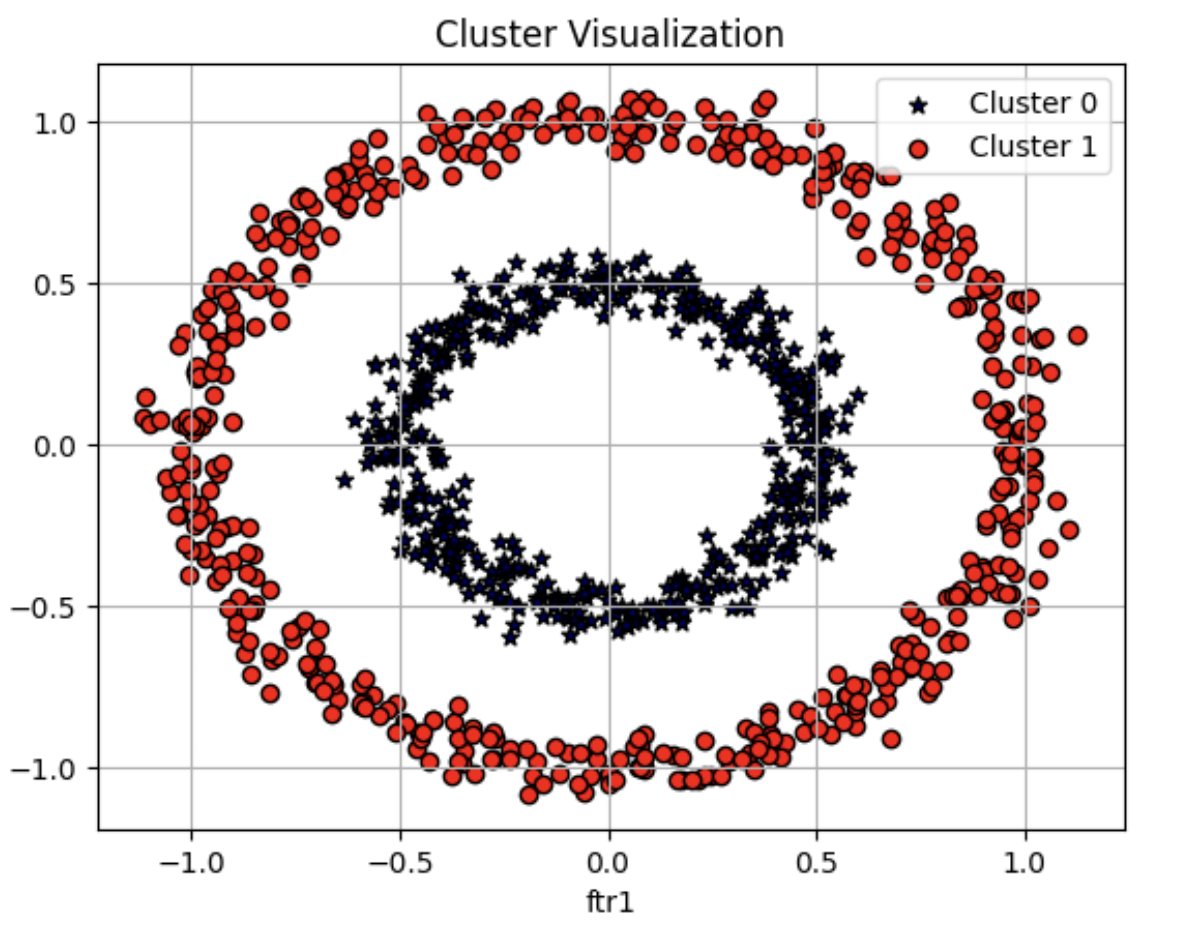
DBSCAN 으로 군집화를 적용해 원하는 방향으로 정확히 군집화가 됐음을 알 수 있음
6. 군집화 실습 - 고객 세그먼테이션
고객 세그먼테이션의 정의와 기법
- 고객 세그먼테이션 (Customer Segmentation)은 다양한 기준으로 고객을 분류하는 기법을 지칭함
고객 세그먼테이션은 CRM 이나 마케팅의 중요 기반 요소입니다.
고객을 분류하는 요소
-
지역 / 결혼 여부 / 성별 / 소득과 같이 개인의 신상 데이터
가 이를 위해 사용될 수도 있습니다만, 고객 분류가 사용되는 대부분의 비즈니스가 상품 판매에 중점을 두고 있기 때문에 더 중요한 분류 요소는 어떤 상품을 얼마나 많은 비용을 써서 얼마나 자주 사용하는 가에 기반한 정보로 분류하는 것이 보통임 -
기업 입장에서는 얼마나 많은 매출을 발생하느냐가 고객 기준을 정하는 중요한 요소임
-
고객 세그먼테이션의 주요 목표는 타깃 마케팅입니다. 타깃 마케팅이란 고객을 여러 특성에 맞게 세분화해서 그 유형에 따라 맞춤형 마케팅이나 서비스를 제공하는 것임
-
평소에 많은 돈을 지불해 서비스를 이용하고 있다면 VIP 전용 상품의 가입을 권유하는 전화나 이메일을 많이 받아봤을 것임
-
새로운 상품이나 서비스를 적극적으로 이용해왔다면 프로모션 상품이 출시될 때마다 권유를 받았을 것임
-
이처럼 기업의 마케팅은 고객의 상품 구매 이력에서 출발합니다.
-
고객 세그먼테이션은 고객의 어떤 요소를 기반으로 군집화할 것인가를 결정하는 것이 중요한데, 여기서는 기본적인 고객 분석 요소인 RFM 기법을 이용
-
RFM 기법은 Recency(R), Frequency(F), Monetary Value(M) 의 각 앞글자를 합한 것으로서 각 단어의 의미
• RECENCY (R): 가장 최근 상품 구입 일에서 오늘까지의 기간
• FREQUENCY (F): 상품 구매 횟수
• MONETARY VALUE (M): 총 구매 금액
데이터 세트 로딩과 데이터 클렌징
import pandas as pd
import datetime
import math
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
retail_df = pd.read_excel(io='/content/sample_data/Online Retail.xlsx')
retail_df.head(3)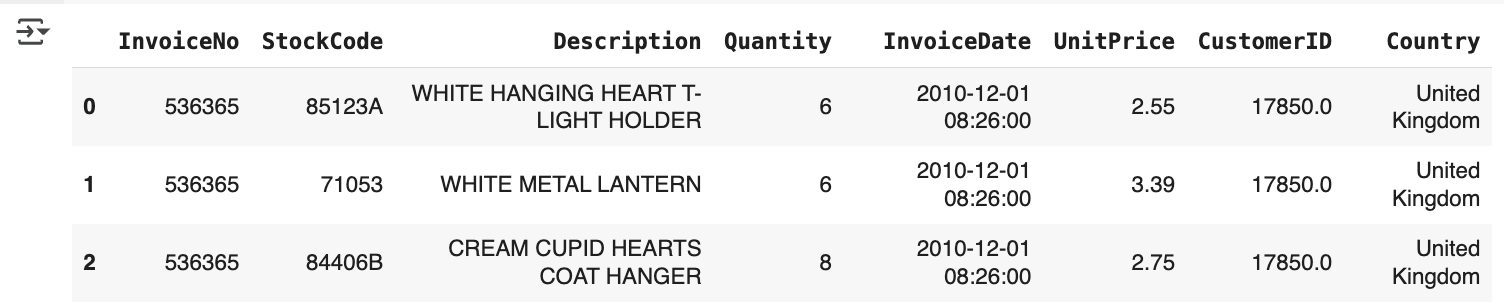
데이터 세트의 전체 건수 , 칼럼 타입 , Null 개수를 확인
retail_df.info()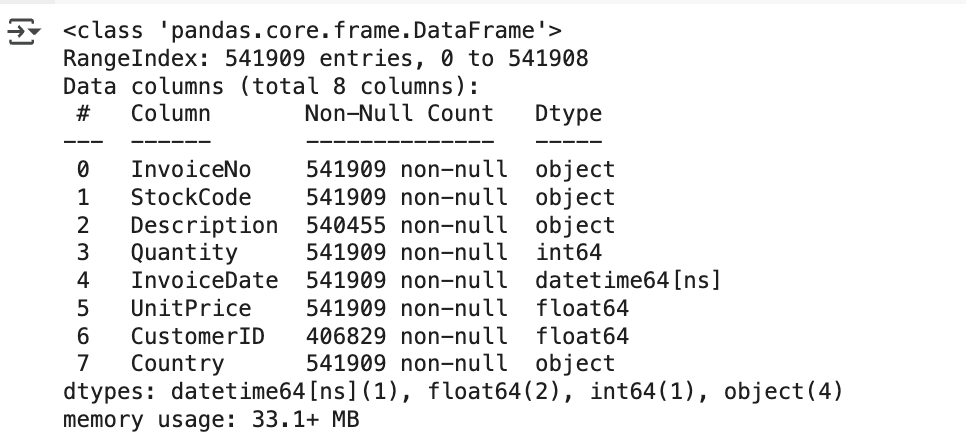
- 전체 데이터는 541,909 개
- 하지만 CustomerID의 Null 값이 너무 많음
CustomerID가 Not Null 인 데이터 건수는 406,829 개로 무려 13 만 5 천 건의 데이터가 Null 임 - 그 외에 다른 칼럼의 경우도 오류 데이터가 존재함
- 따라서 이 데이터 세트는 먼저 사전 정제 작업이 필요함
- Null 데이터 제거 : 특히 CustomerID 가 Nul 인 데이터가 많습니다. 고객 세그먼테이션을 수행하므로 고객 식별 번호가 없는 데이터는 필요가 없기에 삭제합니다.
- 오류 데이터 삭제 : 대표적인 오류 데이터는 Quantity 또는 UnitPrice 가 0 보다 작은 경우입니다. 사실 Quantity 가 0 보다 작은 경우는 오류 데이터라기보다는 반환을 뜻하는 값입니다. 이 경우 InvoiceNo의 앞자리는 C'로 돼 있습니다. 분석의 효
율성을 위해서 이 데이터는 모두 삭제하겠습니다.
불린 인덱싱을 적용해 Quantity> O, UnitPrice 〉 0 이고 CustomerID 이 Not Nul 인 값만 다시 필터
링하겠습니다.
retail_df = retail_df[retail_df[ 'Quantity'] > 0]
retail_df = retail_df[retail_df[ 'UnitPrice'] > 0]
retail_df = retail_df[retail_df['CustomerID'].notnull()]
print(retail_df.shape)
retail_df.isnull().sum()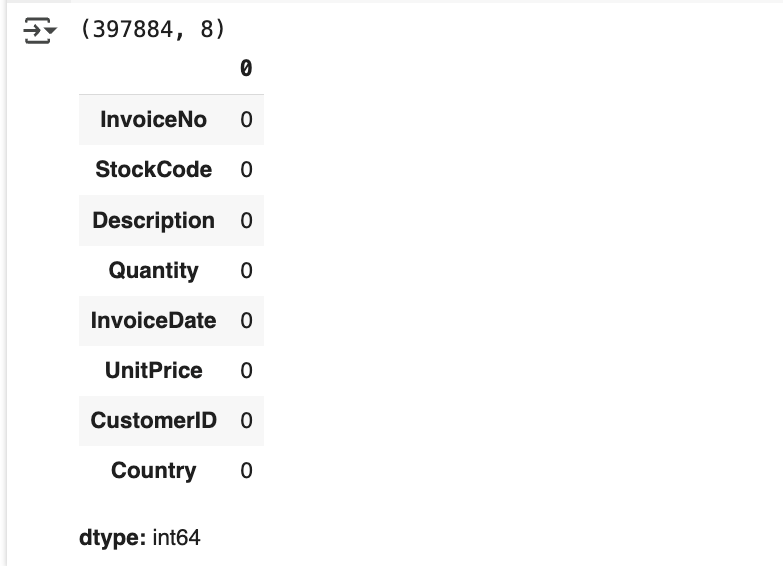
- 전체 데이터가 541,909 에서 397,884 로 줄었음
- 이제 Null 값은 칼럼에 존재하지 않음
- 한 가지 사항만 더 정리하고 간략하게 데이터 사전 정제를 마침
- Country 칼럼은 주문 고객 국가임
- 주요 주문 고객은 영국인데 , 이 외에도 BU 의 여러 나라와 영연방 국가들이 포함돼 있음
retail_df['Country'].value_counts()[:5]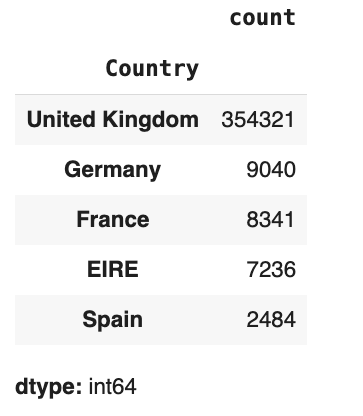
- 영국이 대다수를 차지하므로 다른 국가의 데이터는 모두 제외
retail_df = retail_df[retail_df['Country']=='United Kingdom']
print(retail_df.shape)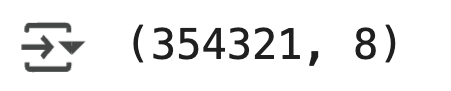
- 최종 데이터는 354,321 건으로 줄었음
RFM 기반 데이터 가공
-
사전 정제된 데이터 기반으로 고객 세그먼테이션 군집화를 RFM 기반으로 수행
-
필요한 데이터를 가공
-
먼저 'UnitPrice' 와 'Quantity' 를 곱해서 주문 금액 데이터를 만듦
-
그리고 CustomerNo 도 더 편리한 식별성을 위해 float 형을 int 형으로 변경
retail_df['sale_amount'] = retail_df['Quantity'] * retail_df ['UnitPrice']
retail_df['CustomerID'] = retail_df['CustomerID'].astype(int)- 해당 온라인 판매 데이터 세트는 주문 횟수와 주문 금액이 압도적으로 특정 고객에게 많은 특성을 가짐
- 개인 고객의 주문과 소매점의 주문이 함께 포함돼 있기 때문임
- Top-5 주문 건수와 주문 금액을 가진 고객 데이터를 추출
print(retail_df['CustomerID'].value_counts().head(5))
print(retail_df.groupby('CustomerID')['sale_amount'].sum().sort_values(ascending=False)[:5])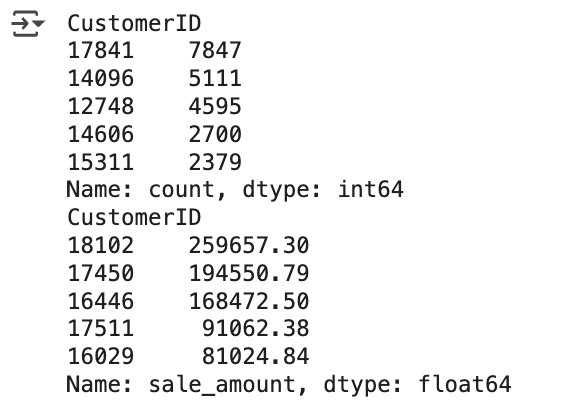
- 위의 결과에서 볼 수 있듯이 몇몇 특정 고객이 많은 주문 건수와 주문 금액을 가지고 있음
- 주어진 온라인 판매 데이터 세트는 전형적인 판매 데이터 세트와 같이 주문번호 (InvoiceNo) + 상품코드
(StockCode) 레벨의 식별자로 돼 있음 - InvoiceNo + StockCode로 Group by 를 수행하면 거의 1 에 가깝게 유일한 식별자 레벨이 됨을 알 수 있음
retail_df.groupby(['InvoiceNo', 'StockCode'])['InvoiceNo'].count().mean ()- 고객 레벨로 Recency, Frequency, Monetary value 데이터로 변경
- retail_df DataFrame에 groupby('CustomerID') 적용
- groupby만 사용하면 여러 aggregation 연산을 동시에 수행하기 어려움
- groupby 후 agg() 이용, 칼럼들과 aggregation 함수명을 딕셔너리 형태로 입력
- Frequency: CustomerID로 groupby → 'InvoiceNo'의 count()
- Monetary value: CustomerID로 groupby → 'sale_amount'의 sum()
- Recency: CustomerID로 groupby → 'InvoiceDate'의 max() → 추후 가공
# Datarrame 의 groupby()의 multiple 연산을 위해 agg() 이용
# Recency 는 InvoiceDate 칼럼의 max() 에서 데이터 가공
# Frequency 는 InvoiceNo 칼럼의 count(), Monetary value 는 sale_amount 칼럼의 sum()
aggregations = {
'InvoiceDate': 'max',
'InvoiceNo': 'count',
'sale_amount': 'sum'
}
cust_df = retail_df.groupby ('CustomerID').agg (aggregations)
# groupby 된 결과 칼럼 값을 Recency, Frequency Monetary 로 변경
cust_df = cust_df.rename(columns = {'InvoiceDate': 'Recency',
'InvoiceNo': 'Frequency',
'sale_amount': 'Monetary'
}
)
cust_df = cust_df.reset_index()
cust_df.head (3)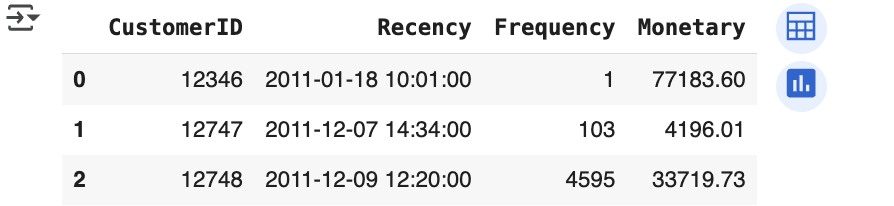
- Recency는 고객별 가장 최근 주문일을 기반으로 계산
- 기준 날짜는 실제 현재 날짜가 아닌 2011년 12월 10일로 설정
- Recency = 2011년 12월 10일 − 고객의 마지막 주문일
- 계산된 날짜 차이에서 일자(days)만 추출해 Recency 칼럼으로 생성
import datetime as dt
cust_df['Recency'] = dt.datetime(2011, 12, 10) - cust_df['Recency']
cust_df['Recency'] = cust_df ['Recency'].apply(lambda x: x.days+1)
print('cust_of 로우와 칼럼 건수는 ', cust_df.shape)
cust_df.head(3)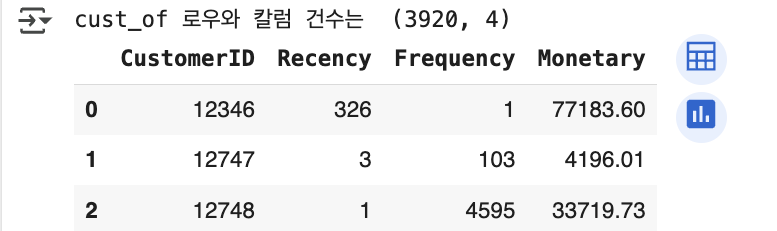
- 이제 고객별로 RFM 분석에 필요한 Recency, Frequency, Monetary 칼럼을 모두 생성
- 생성된 고객 RFM 데이터 세트의 특성을 개괄적으로 알아보고 RFM 기반에서 고객 세그먼테이션을 수행
RFM 기반 고객 세그먼테이션
- 온라인 판매 데이터에는 대규모 주문이 포함되어 있음
- 이로 인해 개인 고객 데이터와의 차이로 데이터 분포가 심하게 왜곡됨
- 왜곡된 분포는 군집화 시 특정 군집으로 과도하게 집중되는 문제를 유발
- 이를 확인하기 위해 Recency, Frequency, Monetary 칼럼에 대해
matplotlib.pyplot.hist()로 히스토그램 시각화 진행
fig, (ax1, ax2, ax3) = plt.subplots(figsize=(12, 4), nrows=1, ncols=3)
ax1.set_title('Recency Histogram')
ax1.hist(cust_df ['Recency'])
ax2. set_title('Frequency Histogram')
ax2.hist(cust_df ['Frequency'])
ax3.set_title( 'Monetary Histogram' )
ax3.hist(cust_df ['Monetary' ])
plt.show()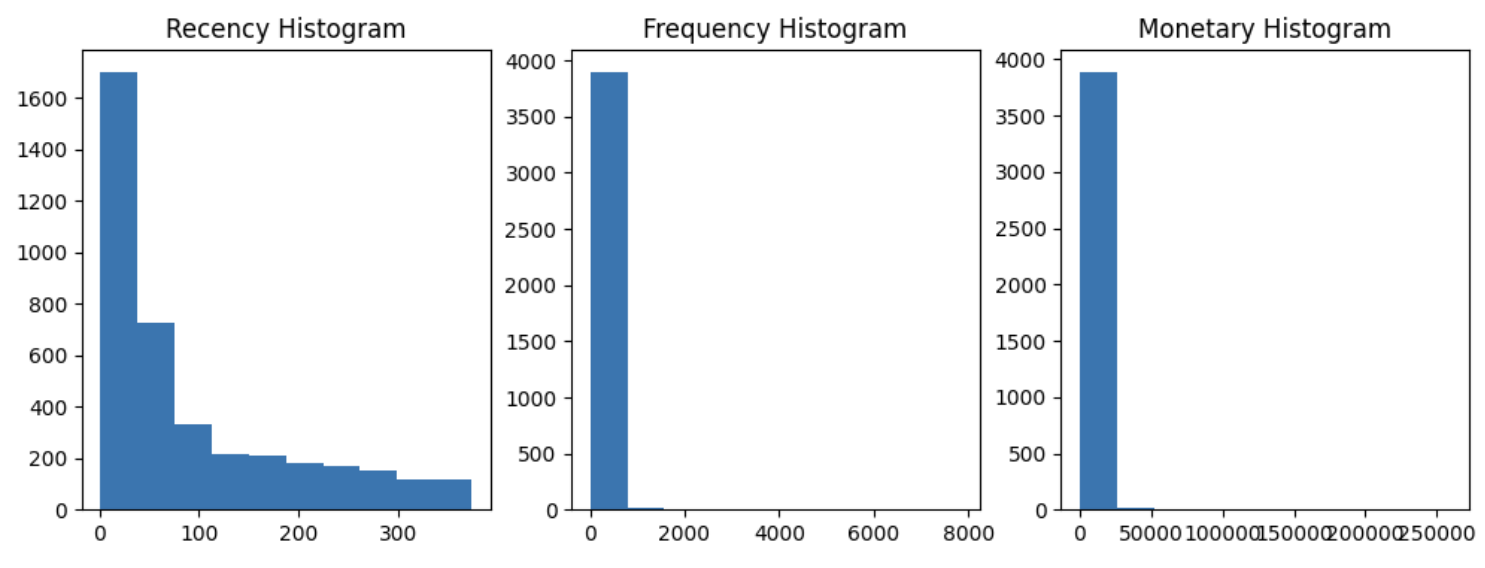
- Recency, Frequency, Monetary 모두 왜곡된 데이터 값 분포도를 가지고 있으며 , 특히 Frequency.
- Monetary 의 경우 특정 범위에 값이 몰려 있어서 왜곡 정도가 매우 심함을 알 수 있음
각 칼럼의 데이터 값 백분위로 대략적으로 어떻게 값이 분포돼 있는지 확인
cust_df[['Recency', 'Frequency', 'Monetary']].describe()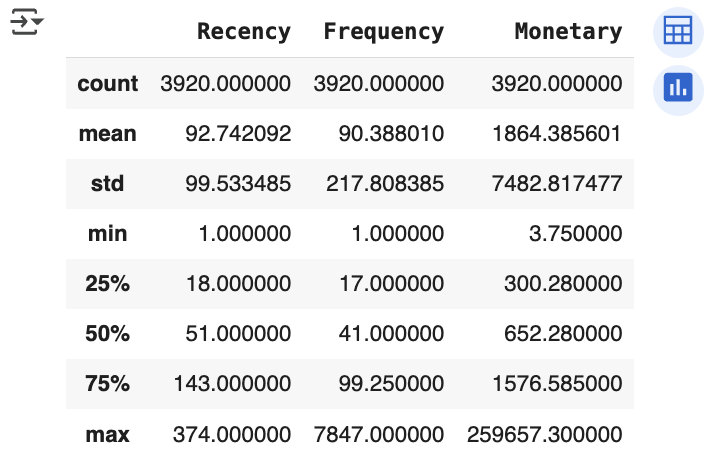
Recency:
- 평균 92.7 vs. 중위값 51 → 왜곡 존재
- 최대값 374, 3/4 분위수 143 → 상위값 영향 큼
Frequency:
- 평균 90.3 ≈ 3/4 분위수 99.25
- 최대값 7847 → 상위 극단값이 평균 왜곡
Monetary:
-
평균 1864.3 vs. 3/4 분위수 1576.5
-
최대값 259657.3 → 상위 몇 개 값이 평균을 끌어올림
-
왜곡된 데이터로는 K-평균 수행 시 군집 간 분별력 약화
-
해결 방법: StandardScaler로 스케일 정규화 후 K-평균 수행
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, silhouette_samples
X_features = cust_df[['Recency', 'Frequency', 'Monetary']].values
X_features_scaled = StandardScaler().fit_transform(X_features)
kmeans = KMeans(n_clusters=3, random_state=0)
labels = kmeans.fit_predict(X_features_scaled)
cust_df['cluster_label'] = labels
print(' 실루엣 스코어는 : {0:.3f}'.format(silhouette_score(X_features_scaled, labels)))from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, silhouette_samples
X_features = cust_df[['Recency', 'Frequency', 'Monetary']].values
X_features_scaled = StandardScaler().fit_transform(X_features)
kmeans = KMeans(n_clusters=3, random_state=0)
labels = kmeans.fit_predict(X_features_scaled)
cust_df['cluster_label'] = labels
print(' 실루엣 스코어는 : {0:.3f}'.format(silhouette_score(X_features_scaled, labels)))- 군집을 3 개로 구성할 경우 전체 군집의 평균 실루엣 계수인 실루엣 스코어는 0.576 로 안정적인 수치가나왔음
- 하지만 각 군집별 실루엣 계수 값은 어떨까요 ? 2 절 군집평가 예제에서 사용한
visualize_silhouette()함수와 군집 개수별로 군집화 구성을 시각화하는visualize_kmeans_plot_multi()함
수 (해당 함수는 부록에서 제공되는 소스 코드에 있습니다)를 새롭게 생성하여 군집 개수를 2~5 개까지
변화시키면서 (함수 인자로 [2,3,4,5] 를 입력합니다 ) 개별 군집의 실루엣 계수 값과 데이터 구성을 함께
알아보겠습니다
def visualize_kmeans_plot_multi(cluster_lists, X_features):
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
# plt.subplots()으로 리스트에 기재된 클러스터링 만큼의 sub figures를 가지는 axs 생성
n_cols = len(cluster_lists)
fig, axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols)
# 입력 데이터의 FEATURE가 여러개일 경우 2차원 데이터 시각화가 어려우므로 PCA 변환하여 2차원 시각화
pca = PCA(n_components=2)
pca_transformed = pca.fit_transform(X_features)
dataframe = pd.DataFrame(pca_transformed, columns=['PCA1','PCA2'])
# 리스트에 기재된 클러스터링 갯수들을 차례로 iteration 수행하면서 KMeans 클러스터링 수행하고 시각화
for ind, n_cluster in enumerate(cluster_lists):
# KMeans 클러스터링으로 클러스터링 결과를 dataframe에 저장.
clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0)
cluster_labels = clusterer.fit_predict(pca_transformed)
dataframe['cluster']=cluster_labels
unique_labels = np.unique(clusterer.labels_)
markers=['o', 's', '^', 'x', '*']
# 클러스터링 결과값 별로 scatter plot 으로 시각화
for label in unique_labels:
label_df = dataframe[dataframe['cluster']==label]
if label == -1:
cluster_legend = 'Noise'
else :
cluster_legend = 'Cluster '+str(label)
axs[ind].scatter(x=label_df['PCA1'], y=label_df['PCA2'], s=70,\
edgecolor='k', marker=markers[label], label=cluster_legend)
axs[ind].set_title('Number of Cluster : '+ str(n_cluster))
axs[ind].legend(loc='upper right')
plt.show()### 여러개의 클러스터링 갯수를 List로 입력 받아 각각의 실루엣 계수를 면적으로 시각화한 함수 작성
def visualize_silhouette(cluster_lists, X_features):
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import math
# 입력값으로 클러스터링 갯수들을 리스트로 받아서, 각 갯수별로 클러스터링을 적용하고 실루엣 개수를 구함
n_cols = len(cluster_lists)
# plt.subplots()으로 리스트에 기재된 클러스터링 만큼의 sub figures를 가지는 axs 생성
fig, axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols)
# 리스트에 기재된 클러스터링 갯수들을 차례로 iteration 수행하면서 실루엣 개수 시각화
for ind, n_cluster in enumerate(cluster_lists):
# KMeans 클러스터링 수행하고, 실루엣 스코어와 개별 데이터의 실루엣 값 계산.
clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0)
cluster_labels = clusterer.fit_predict(X_features)
sil_avg = silhouette_score(X_features, cluster_labels)
sil_values = silhouette_samples(X_features, cluster_labels)
y_lower = 10
axs[ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \
'Silhouette Score :' + str(round(sil_avg,3)) )
axs[ind].set_xlabel("The silhouette coefficient values")
axs[ind].set_ylabel("Cluster label")
axs[ind].set_xlim([-0.1, 1])
axs[ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10])
axs[ind].set_yticks([]) # Clear the yaxis labels / ticks
axs[ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1])
# 클러스터링 갯수별로 fill_betweenx( )형태의 막대 그래프 표현.
for i in range(n_cluster):
ith_cluster_sil_values = sil_values[cluster_labels==i]
ith_cluster_sil_values.sort()
size_cluster_i = ith_cluster_sil_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_cluster)
axs[ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \
facecolor=color, edgecolor=color, alpha=0.7)
axs[ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
axs[ind].axvline(x=sil_avg, color="red", linestyle="--")visualize_silhouette([2, 3, 4, 5], X_features_scaled)
visualize_kmeans_plot_multi([2, 3, 4, 5], X_features_scaled)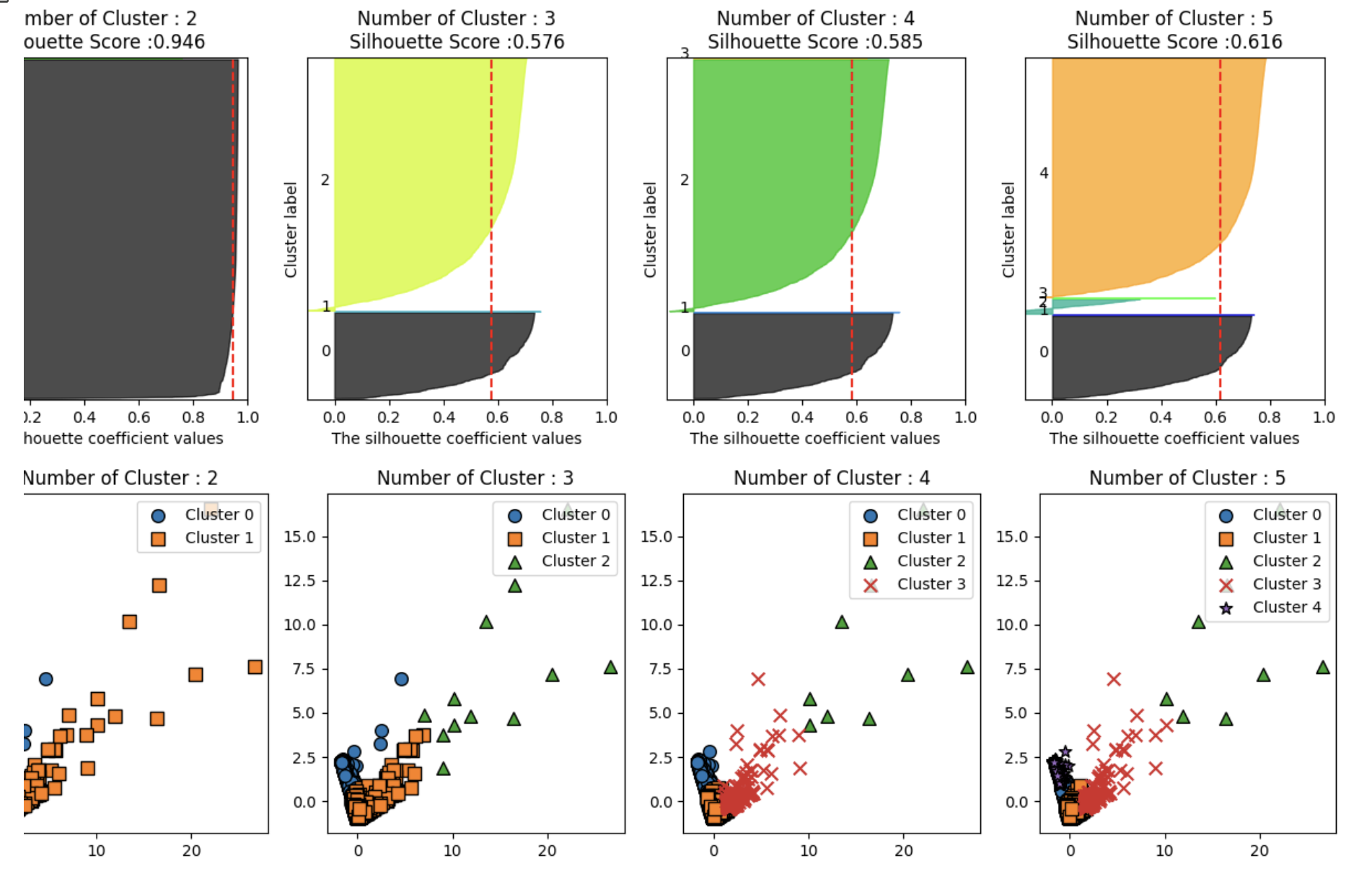
군집 수가 2일 때:
- 군집이 너무 포괄적으로 분류됨 → 개선 필요
군집 수가 3 이상일 때:
-
일부 군집의 데이터 개수 매우 적음
-
실루엣 계수 낮고 군집 내부 분산 큼
-
소수 데이터 = 왜곡된 대량 주문 데이터
-
이러한 데이터는 거리 기반 군집화 (e.g. K-평균)에서는
-
의미 없는 군집 분리 반복
-
군집 수 증가해도 유의미한 개선 없음
결론:
- 왜곡된 데이터는 단순 통계 분석으로도 충분히 분리 가능
- 거리 기반 군집화는 일반화된 군집화 결과만 유도
해결책:
- 로그 변환을 통해 데이터의 왜곡 정도 감소
- 그 후 K-평균 군집화 적용하여 분포 개선 기대
### Log 변환을 통해 데이터 변환
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, silhouette_samples
# Recency, Frequecny, Monetary 컬럼에 np.log1p() 로 Log Transformation
cust_df['Recency_log'] = np.log1p(cust_df['Recency'])
cust_df['Frequency_log'] = np.log1p(cust_df['Frequency'])
cust_df['Monetary_log'] = np.log1p(cust_df['Monetary'])
# Log Transformation 데이터에 StandardScaler 적용
X_features = cust_df[['Recency_log','Frequency_log','Monetary_log']].values
X_features_scaled = StandardScaler().fit_transform(X_features)
kmeans = KMeans(n_clusters=3, random_state=0)
labels = kmeans.fit_predict(X_features_scaled)
cust_df['cluster_label'] = labels
print('실루엣 스코어는 : {0:.3f}'.format(silhouette_score(X_features_scaled,labels)))- 실루엣 스코어는 : 0.303 나왔음
- 실루엣 스코어는 로그 변환하기 전보다 떨어짐
- 하지만 실루엣 스코어의 절대치가 중요한 것이 아님을 앞의 예제에서 잘 알 수 있음
- 어떻게 개별 군집이 더 균일하게 나뉠 수 있는지가 더 중요함
로그 변환한 데이터 세트를 기반으로 실루엣 계수와 군집화 구성을 시각화
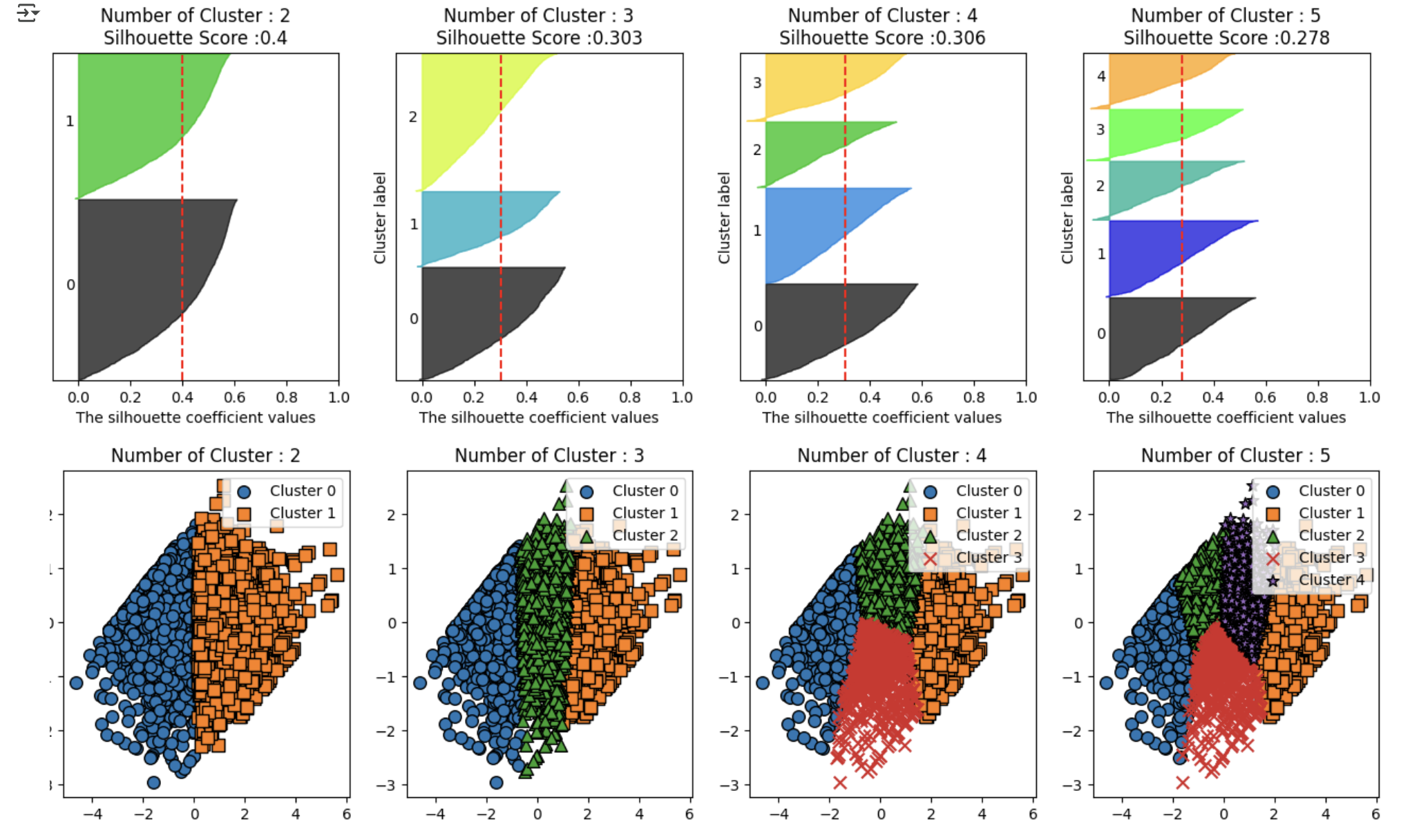
- 실루엣 스코어는 로그 변환하기 전보다 떨어지지만 앞의 경우보다 더 균일하게 군집화가 구성됐음
