머신러닝
1.[파이썬 머신러닝 완벽 가이드] 1장 정리

머신러닝은 데이터 기반으로 패턴을 학습하고 결과를 예측 분석 (Predictive Analysis)하는 알고리즘 기법을 통칭한다. 일상생활에서 금융 사기 거래 방지, 스팸메일 필터링 같은 응용이 있다. 머신러닝의 분류 1. 지도학습 (Supervised Learnin
2.[파이썬 머신러닝 완벽 가이드] 2장 정리
colab : https://colab.research.google.com/drive/14wzHk55v1fJU9m14VuAjW5DaAiyM7-_M?usp=sharing 1. 사이킷런 (scikit-learn) 특징 머신러닝 라이브러리 -> 가장 쉽고 효율적인 개발 라
3.[파이썬 머신러닝 완벽 가이드] 3장 정리
colab : https://colab.research.google.com/drive/1YOSvu-INmjxNVYTS8-eB4QPyj7Ge1nyZ?usp=sharing github : https://github.com/nalinzip/mlstudy/blob/main/
4.[파이썬 머신러닝 완벽 가이드] 4장 정리
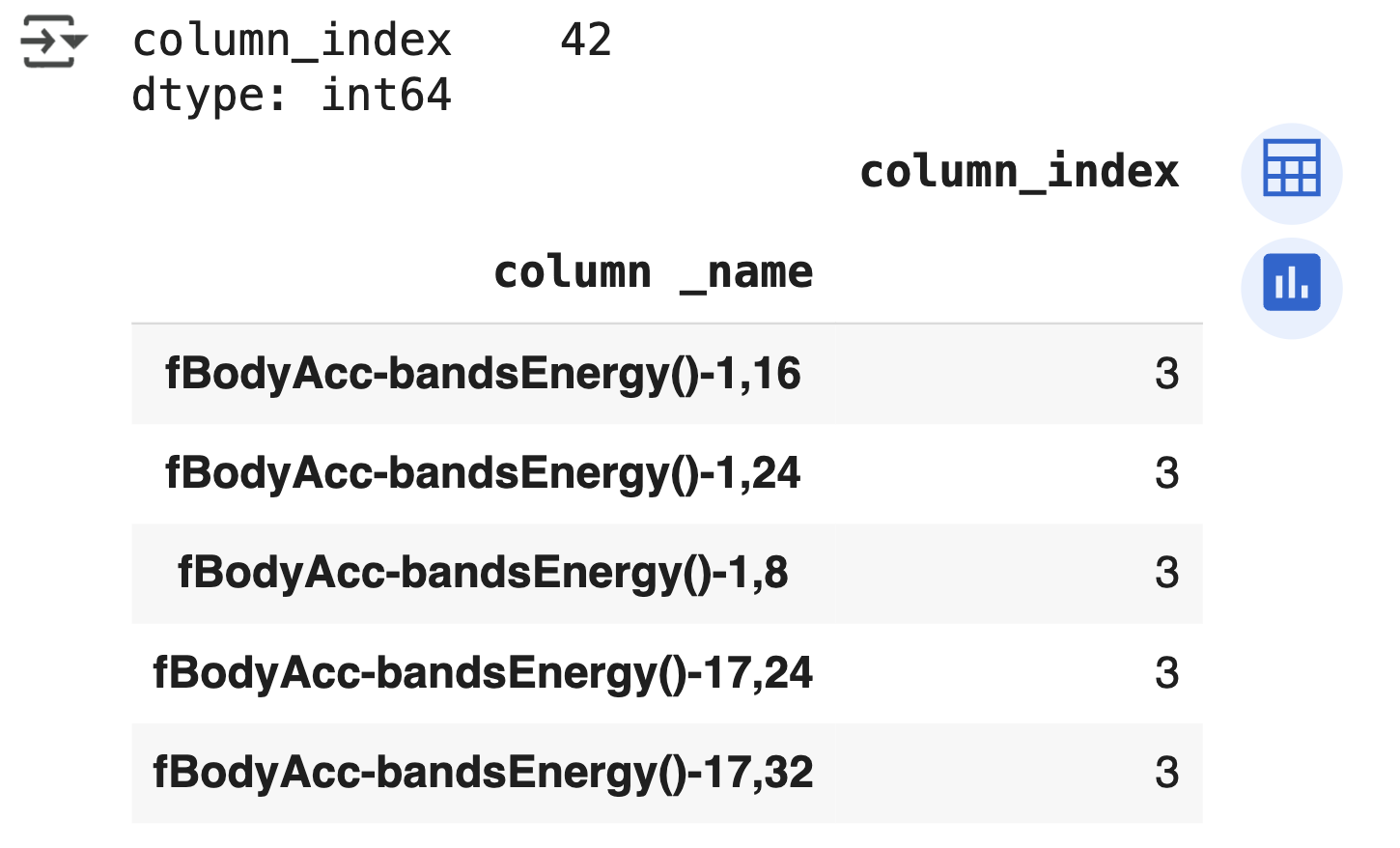
1. 분류(Classification)의 개요 지도학습은 정답(Label)이 있는 데이터를 기반으로 학습하는 머신러닝 방식 대표 유형: 분류(Classification) 피처와 레이블을 이용해 머신러닝 알고리즘이 모델을 학습 학습된 모델은 새로운 데이터의 레이블을 예측
5.[파이썬 머신러닝 완벽 가이드] 5장 정리
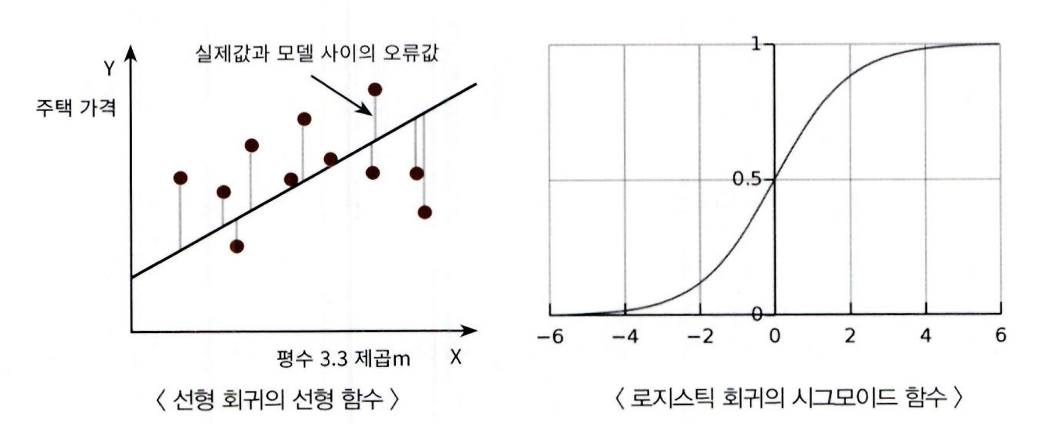
1. 회귀 소개 회귀(regression)는 현대 통계학의 핵심 기법 중 하나임 공학, 의학, 사회과학, 경제학 등 다양한 분야의 발전에 기여함 영국 통계학자 갈톤(Galton)의 연구에서 유래됨 갈톤은 부모와 자식 간의 키 상관관계를 분석함 부모의 키가 크거나 작아도
6.[파이썬 머신러닝 완벽 가이드] 6장 정리
https://colab.research.google.com/drive/1G1jMN8tJ01jNVXtIO8czPbXICL7cX01G?usp=sharinghttps://colab.research.google.com/drive/1W1zZHWxPY8iQnK
7.[파이썬 머신러닝 완벽 가이드] 7장 정리
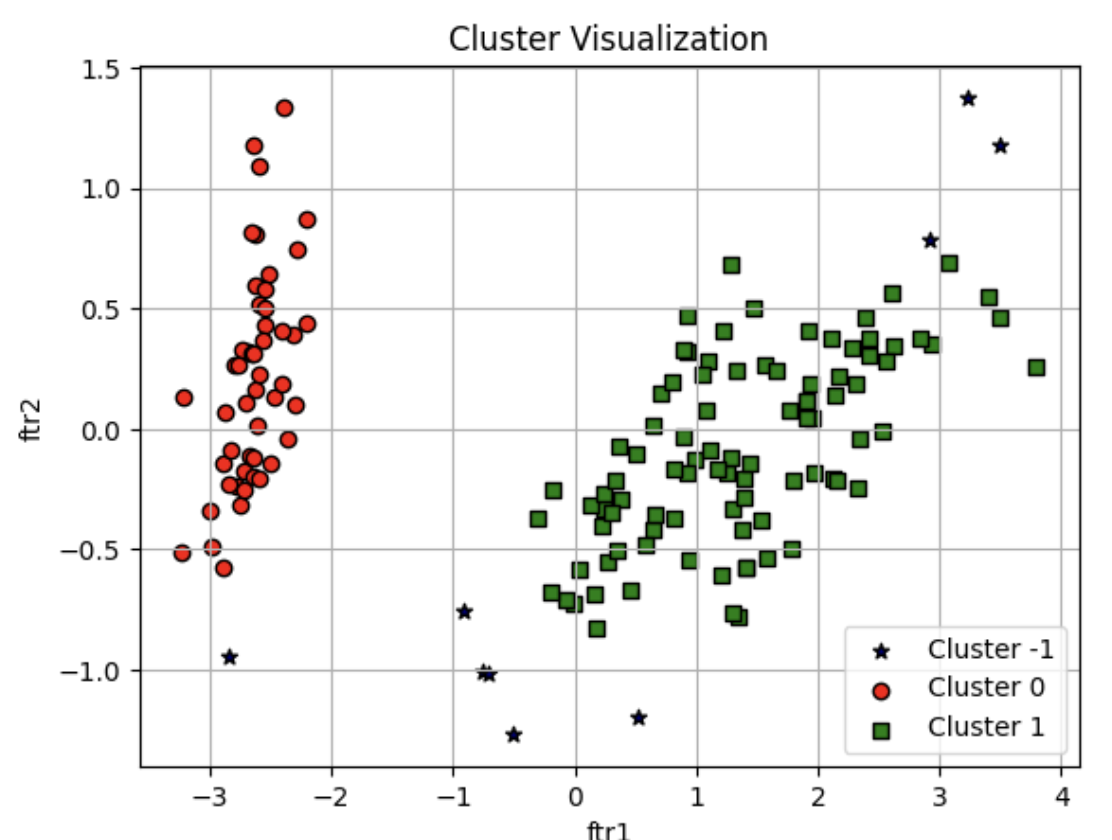
1. K-평균 알고리즘 이해 K-평균은 군집화 (Clustering) 에서 가장 일반적으로 사용되는 알고리즘 K-평균은 군집 중심점 (centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법 군집 중심점은 선택된 포인
8.[파이썬 머신러닝 완벽 가이드] 8장 정리
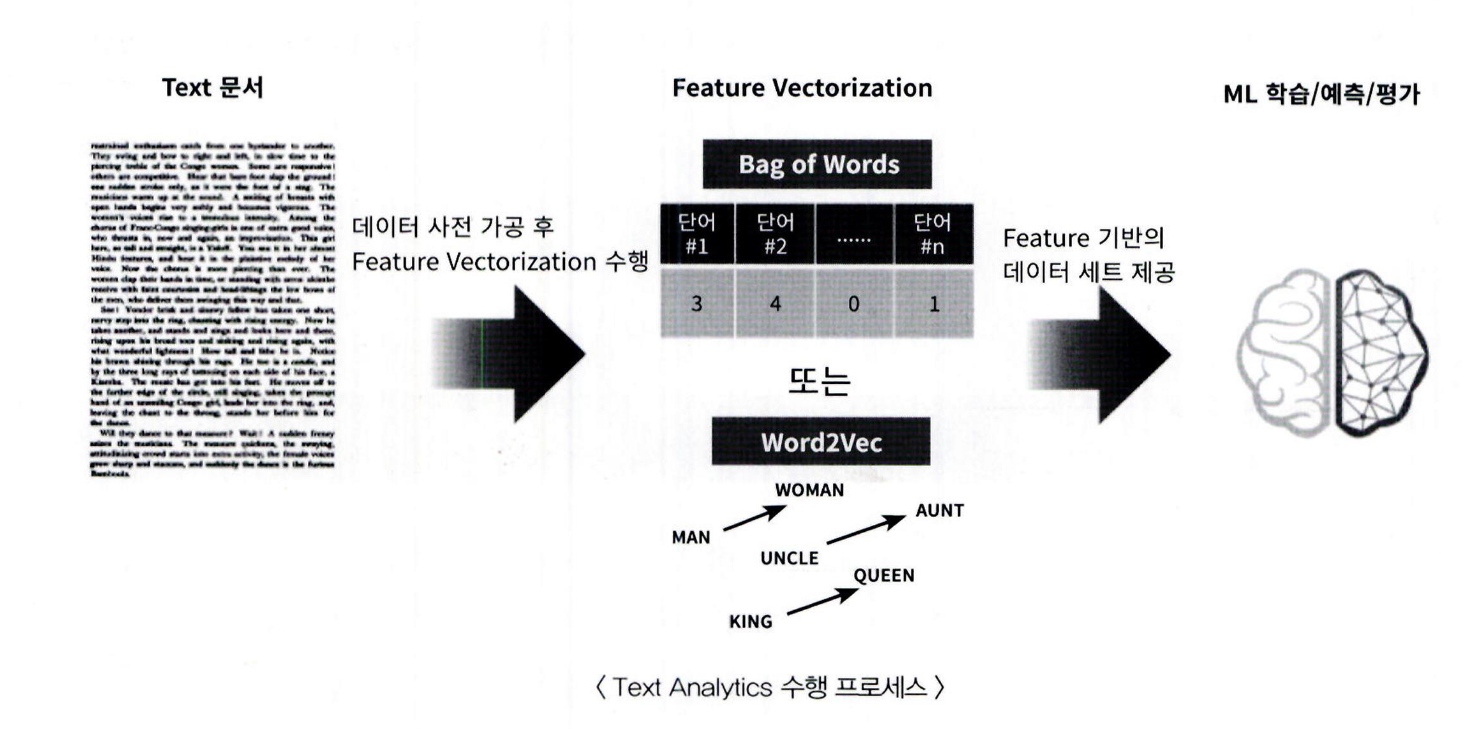
NLP 는 머신이 인간의 언어를 이해하고 해석하는 데 더 중점을 두고 기술이 발전해 왔음 텍스트 마이닝 (Text Mining) 이라고도 불리는 텍스트 분석 (Text Analytics, 이하 TA) 은 비정형 텍스트에서 의미 있는 정보를 추출하는 것에 좀 더 중점
9.[파이썬 머신러닝 완벽 가이드] 9장 정리
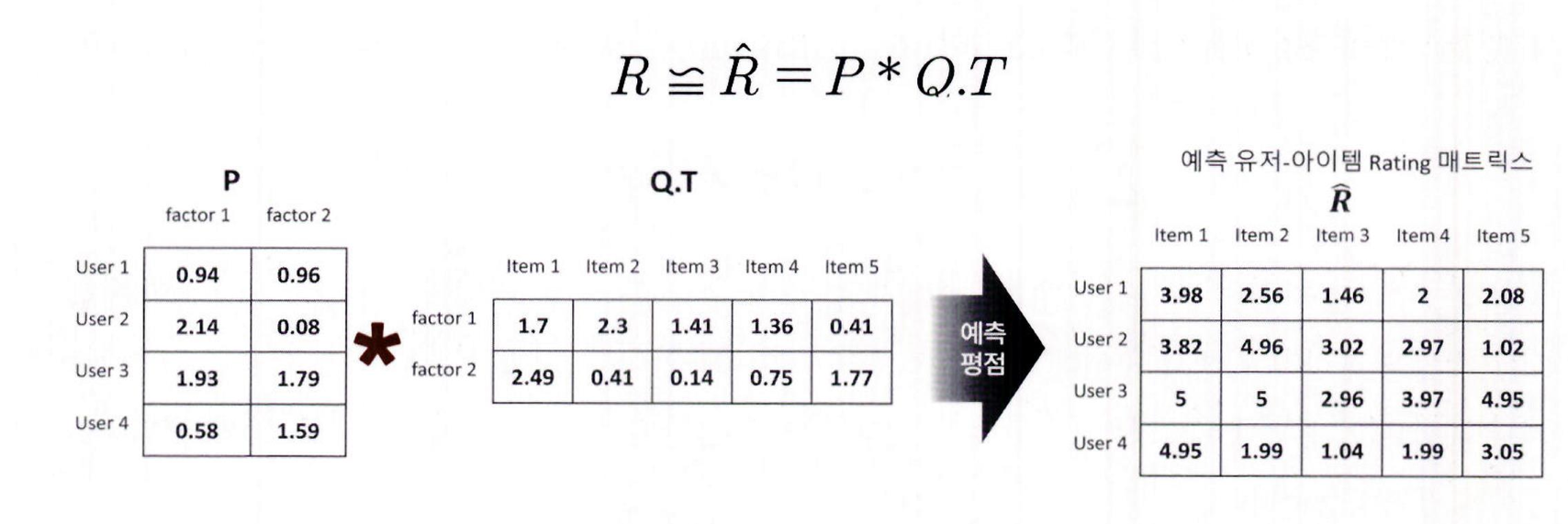
1. 추천 시스템의 개요와 배경 바야흐로 지금은 추천 시스템(Recommendations) 전성시대입니다. 아마존 등과 같은 전자상거래 업체부터 유튜브, 애플 뮤직 등 콘텐츠 포털까지 추천 시스템을 통해 사용자의 취향을 이해하고 맞춤 상품과 콘텐츠를 제공해 조금이라도