https://colab.research.google.com/drive/1fsRtX_z56gkJqEV7hXcEvi8d1hPje5zL?usp=sharing
머신러닝은 데이터 기반으로 패턴을 학습하고 결과를 예측 분석 (Predictive Analysis)하는 알고리즘 기법을 통칭한다. 일상생활에서 금융 사기 거래 방지, 스팸메일 필터링 같은 응용이 있다.
머신러닝의 분류
1. 지도학습 (Supervised Learning)
- 분류
- 회귀
- 추천 시스템
- 시각/음성 인식
- NLP
2. 비지도학습 (Unsupervised Learning)
- Cluetering
- 차원 축소
- 강화 학습
머신러닝에서 중요한 요소들
- 데이터
- 알고리즘
"머신러닝의 가장 큰 단점 : 데이터에 매우 의존적 - Garbage in, Garbage out"
즉, 고품질의 데이터를 갖추지 못한다면 머신러닝의 결과도 좋을 수 없다.
머신러닝에 적합한 프로그래밍언어들
- R
- Python
파이썬을 고르는 이유
- 직관적인 문법
- 객체지향 프로그래밍
- 함수형 프로그래밍
- 널리 사용
- 다양한 라이브러리
파이썬 머신러닝 주요 패키지
- 머신러닝 : 사이킷런 (Scikit-Learn)
- 행렬/선형대수/통계 : Numpy, SciPy
- 데이터 핸들링 : Pandas
- 시각화 : Matplotlib
파이썬을 위한 스프트웨어 설치
파이썬 패키지를 설치하려면 Anaconda 이용하는 것이 좋습니다.
Anaconda는 패키지 및 환경 관리 툴을 제공합니다. 이를 사용해 다양한 파이썬 패키지를 설치하고, 프로젝트마다 독립적인 가상 환경을 설정할 수 있다.
- https://www.anaconda.com/download/success 링크로 Anaconda 설치하기
이메일을 입력한 뒤 아래와 같이 다운로드 화면을 보여줍니다. 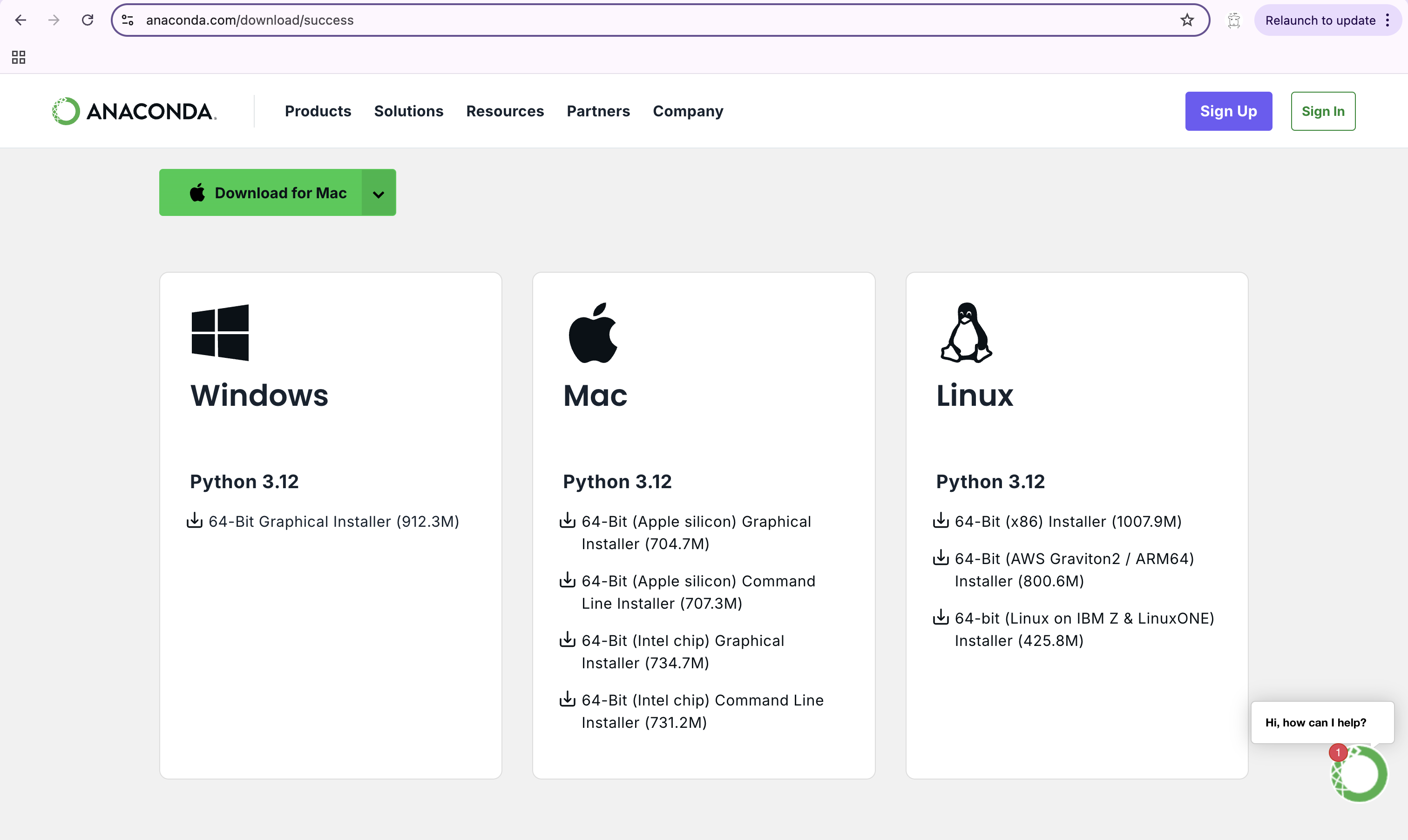
- Mac 이나 Windows 의 Python 3.12 64-Bit Graphical Installer 를 선택하기
- 설치 여부 확인히기 위해서 터미널을 열고 아래와 같이
python이라는 command을 쓰면 설치 상태를 보여준다. 설치가 완료되면 아래와 같이 보여준다.
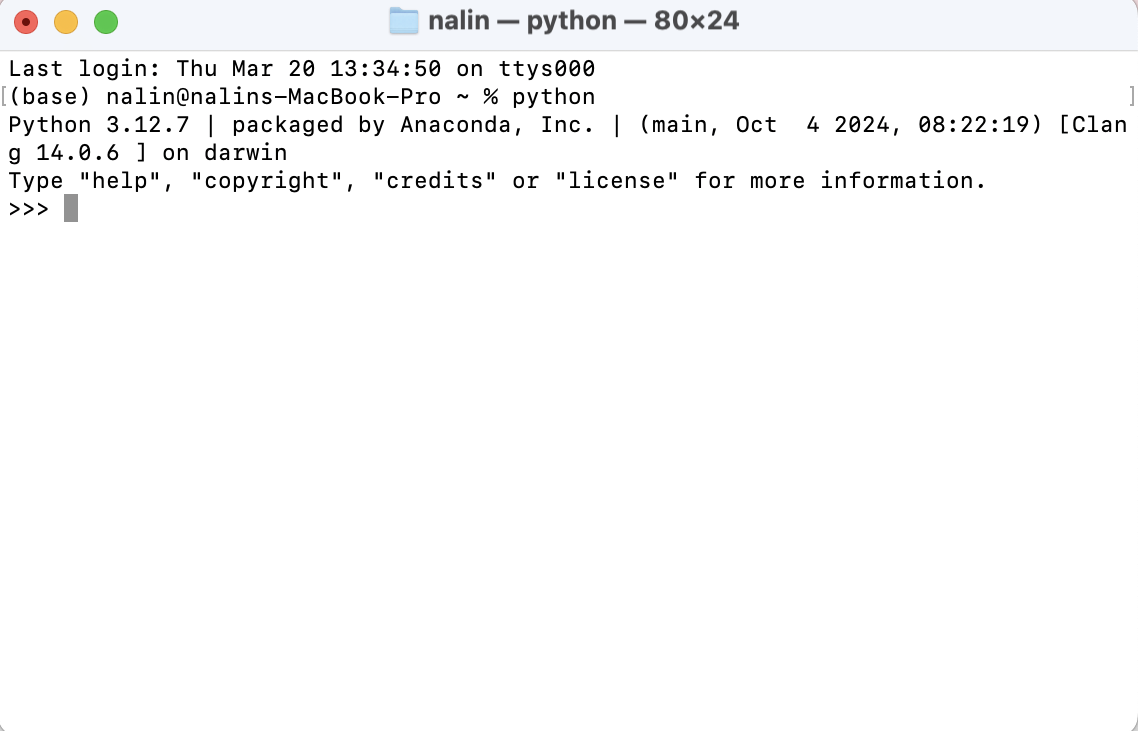
또한, 파이썬 버전 확인 커맨드는
python -V다음, Anaconda.navigator 에 들어가시면 Jupyter Notebook 아이콘을 보실 수 있습니다.
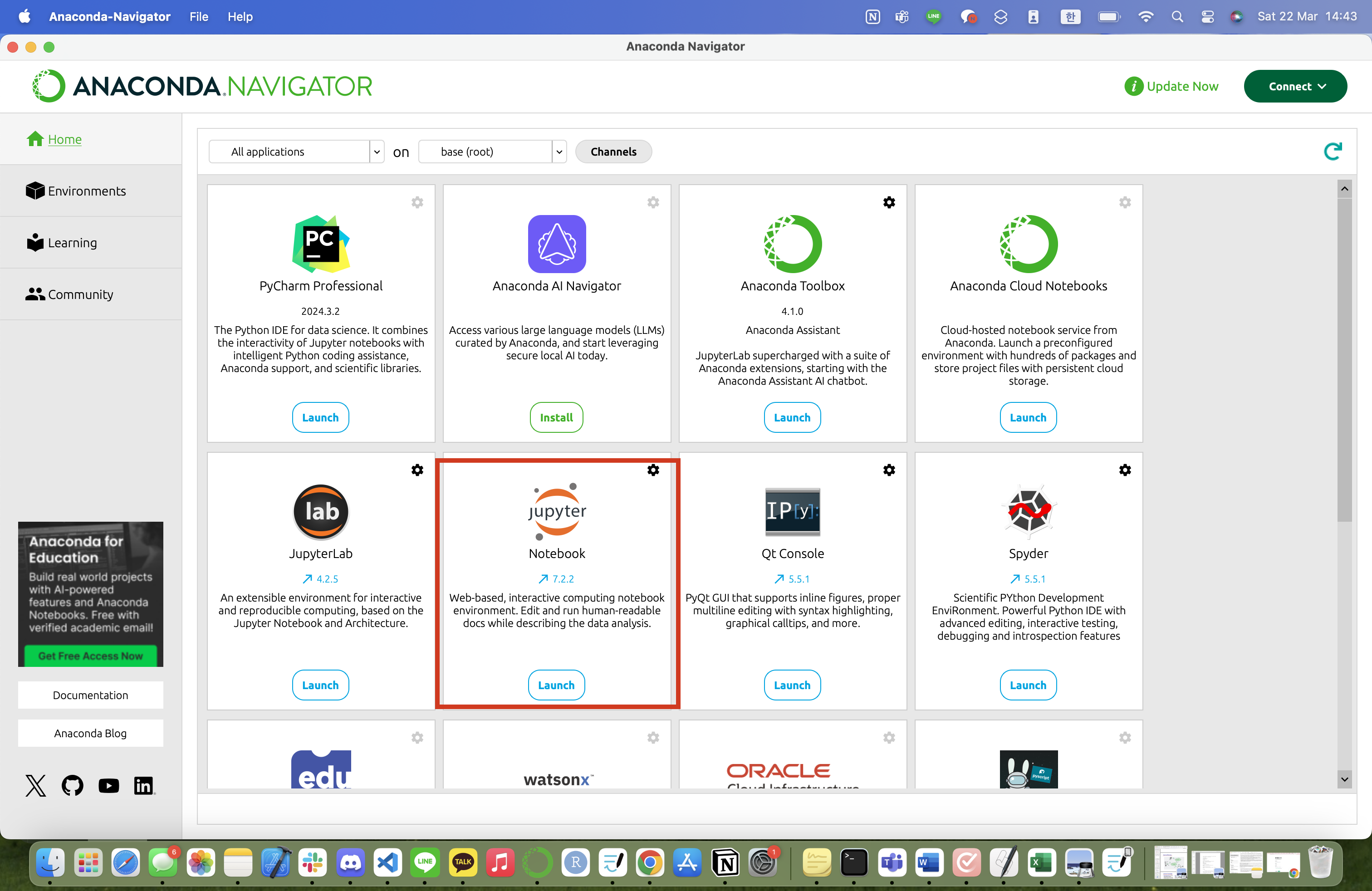
Launch (실행) 을 클릭한 후 콘솔창이 뜨면서 주피터 노트북을 구동하기 위한 서버 프로그램이 실행한다. http://localhost:8888에 접속하면 사용할 수 있습니다.
Anaconda 사용하고 싶지 않다면 Google Colab 사용하실 수 있습니다.
NumPy ndarray 개요
넘파이 모듈 임포트해서 약어로 표현하기
맨 위에 셀 [1] 에
import numpy as np입력해서 return+shift (맥북 기준) 동시 누르기
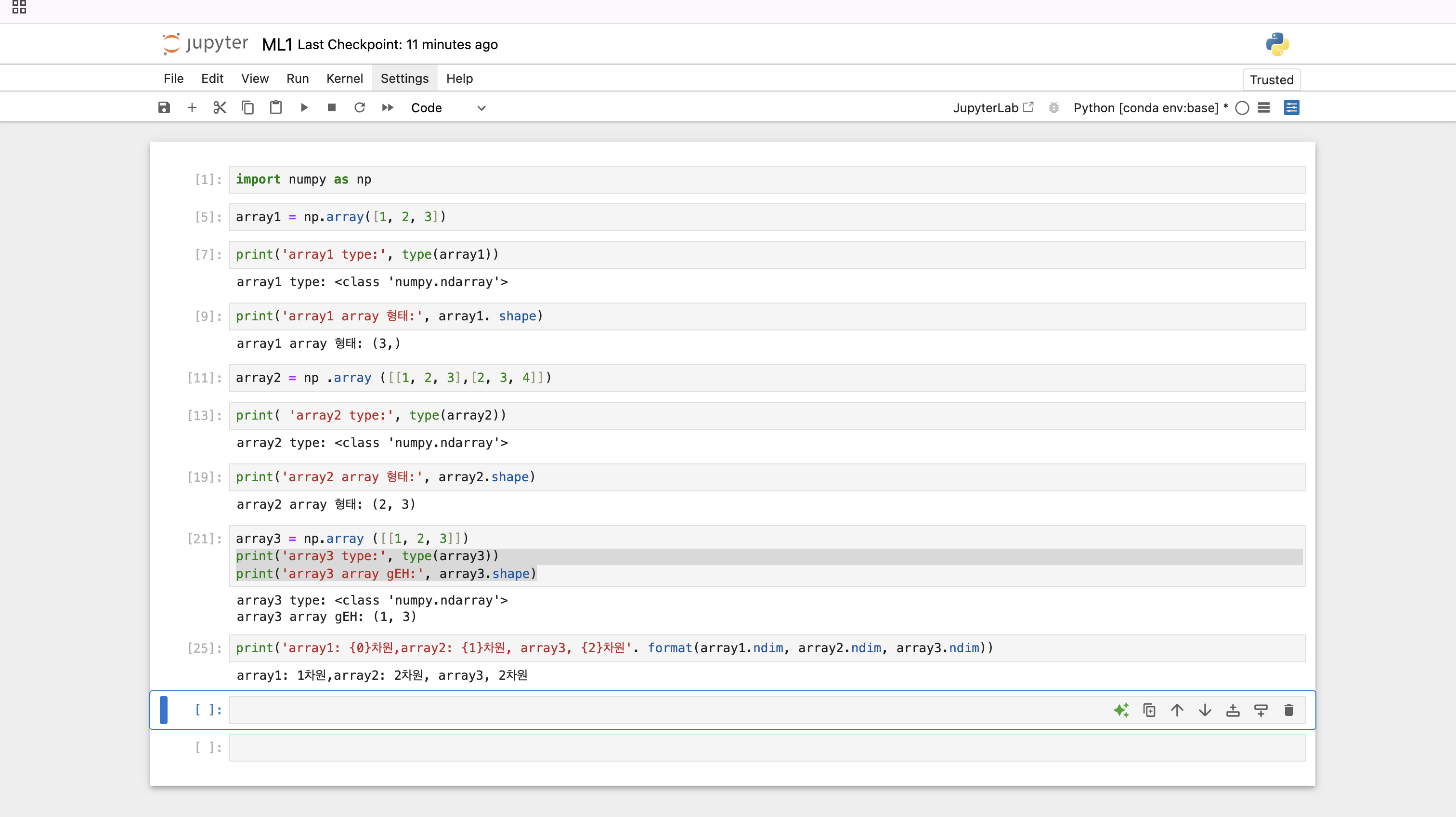
- ndarray 는 넘파이의 기반 데이터 타입임.
- 이를 사용해서 다차원 (Multi-dimensional) 배열 생성과 연산 수행 가능
- array() 함수는 리스트와 같은 인자를 입력 받아서 ndarray로 변환해줌
- ndarray.ndim 이용해서 배열의 차원 확인 가능
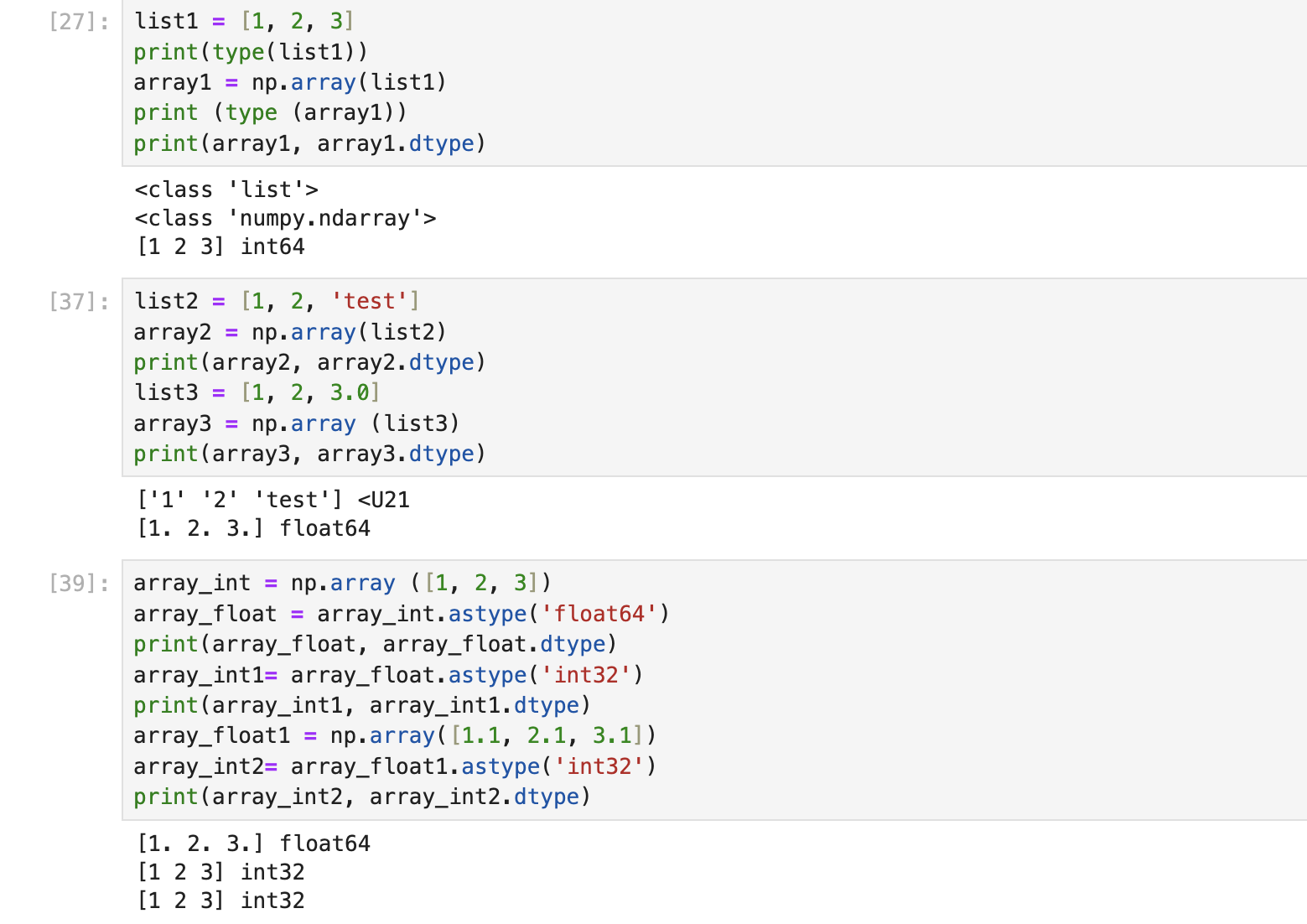
ndarrray의 데이터 타입
- ndarray 내의 숫자 값 , 문자열 값 , 불 값 등이 모두 가능
- 이 보다 더 큰 숫자 값이나 정밀도를 위해 complex 타입도 제공합니다.
- ndarray 내의 데이터 타입은 dtype 속성으로 확인할 수 있습니다.
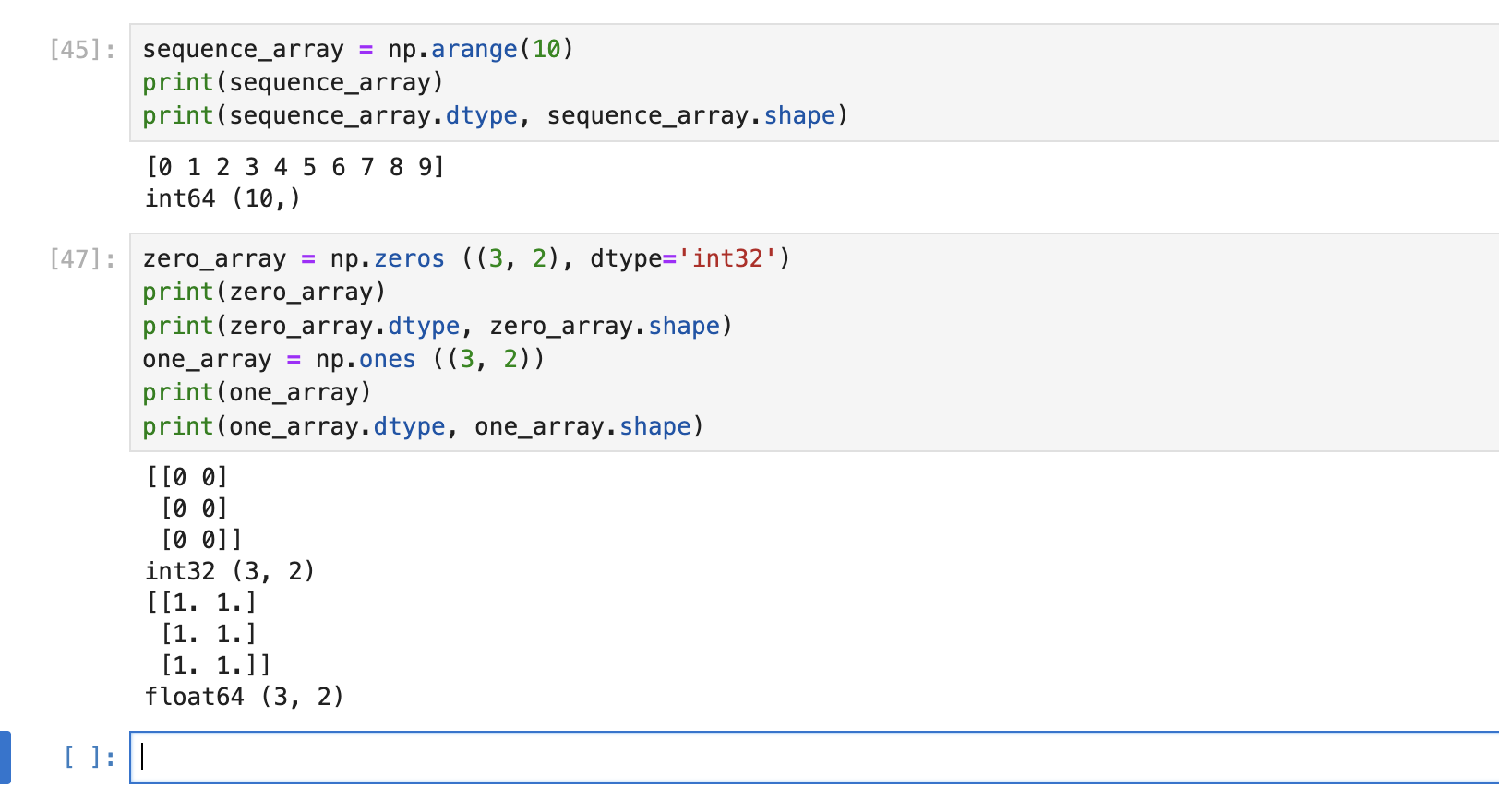
ndarray 생성 방법
range(),zeros(),ones()를 이용arange()는 함수 이름에서 알 수 있듯이 파이썬 표준 함수인 range()와 유사한 기능을 합니다. 쉽게 생각하면 array 를 range()로 표현하는 것입니다. 0 부터 함수 인자 값 1 까지의 값을 순차적으로 ndarray 의 데이터값으로 변환해 줍니다.
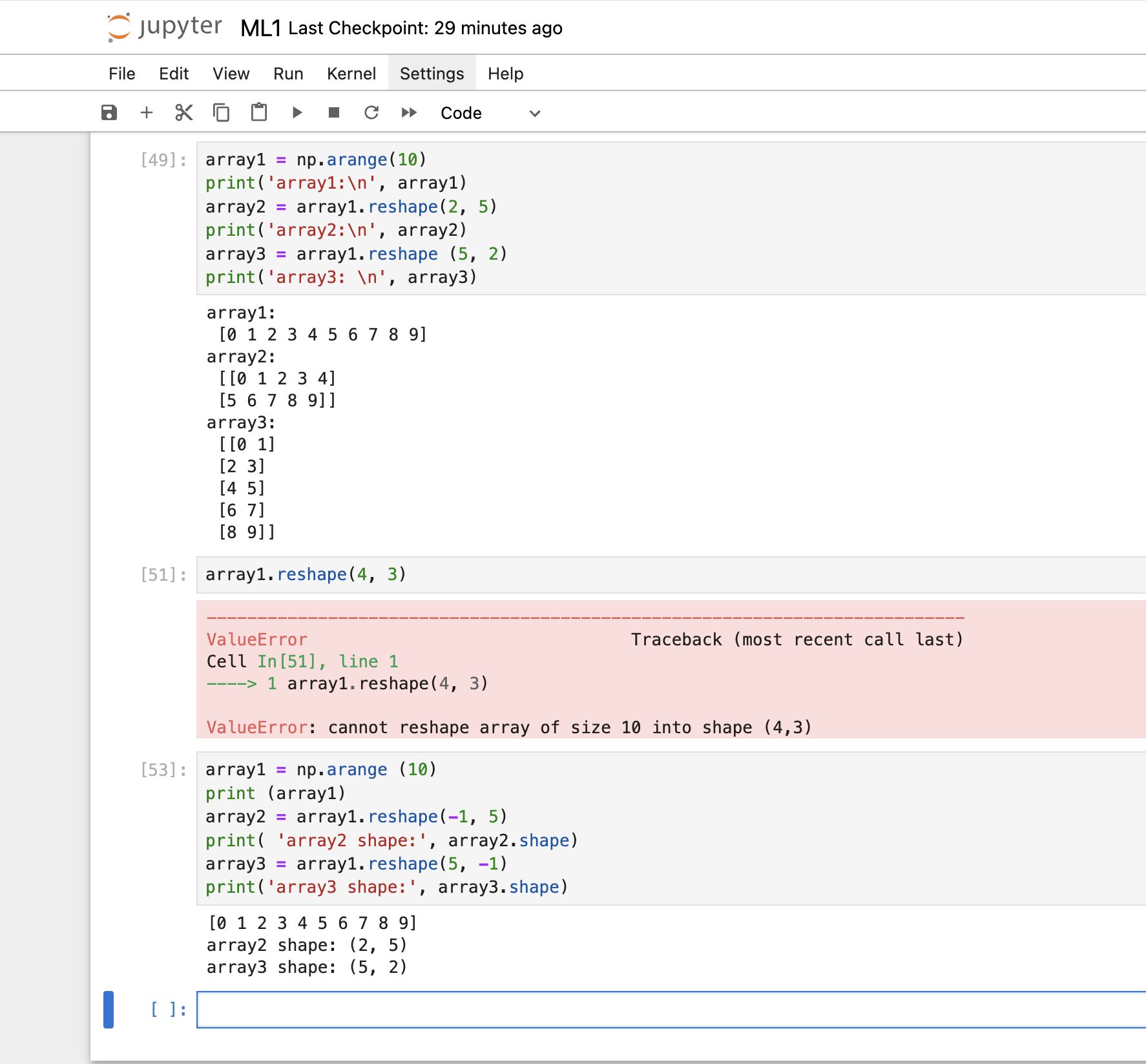
reshape( ) 메서드: ndarray의 차원과 크기를 변경
-
변환을 원하는 크기를 함수 인자로 부여하면 됨
-
reshape()는 지정된 사이즈로 변경이 불가능하면 오류를 발생 -
가령 (10,) 데이터를 (4,3) Shape 형태로 변경할 수는 없습니다.
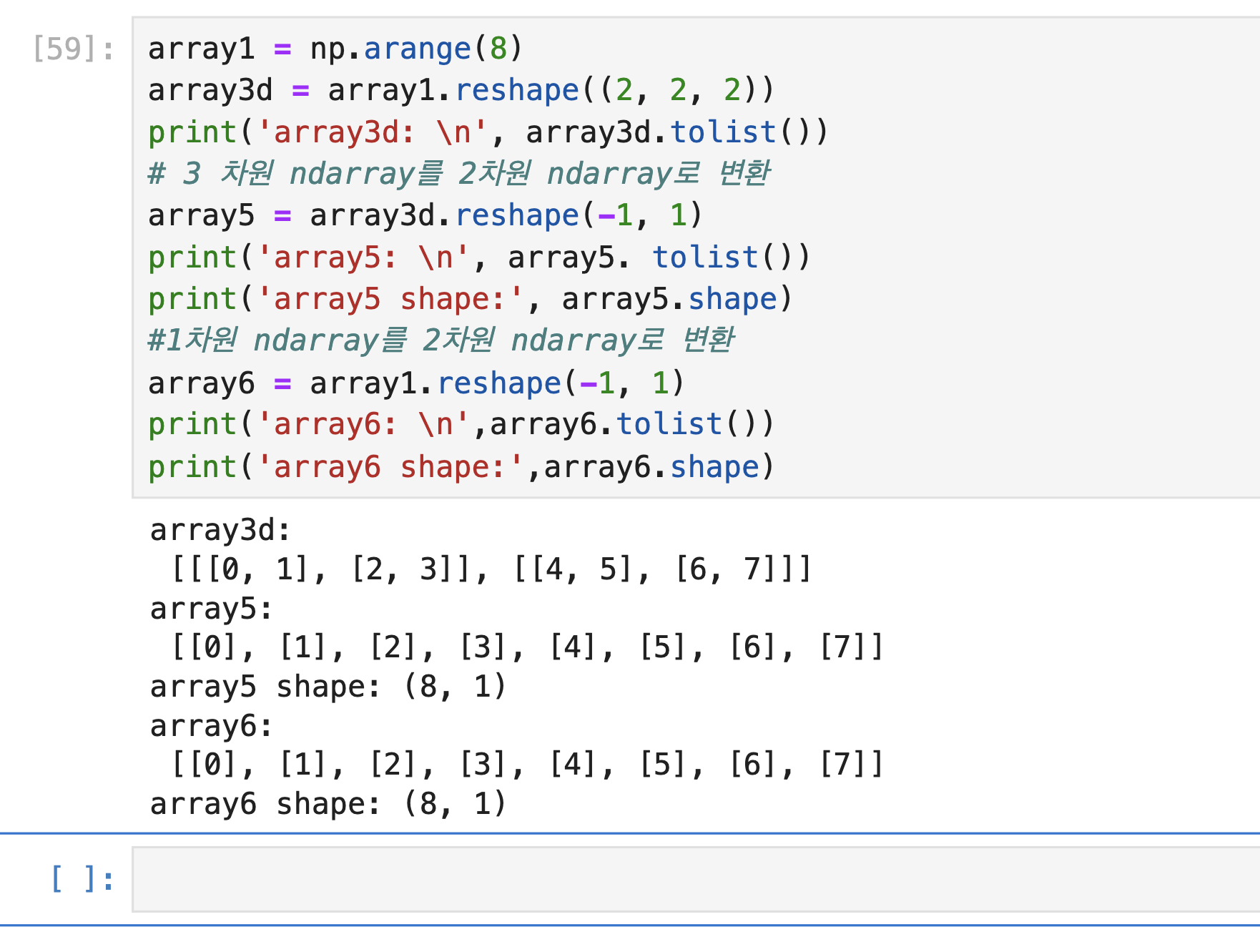
-
tolist() 메서드를 이용해 리스트 자료형으로 변환 가능
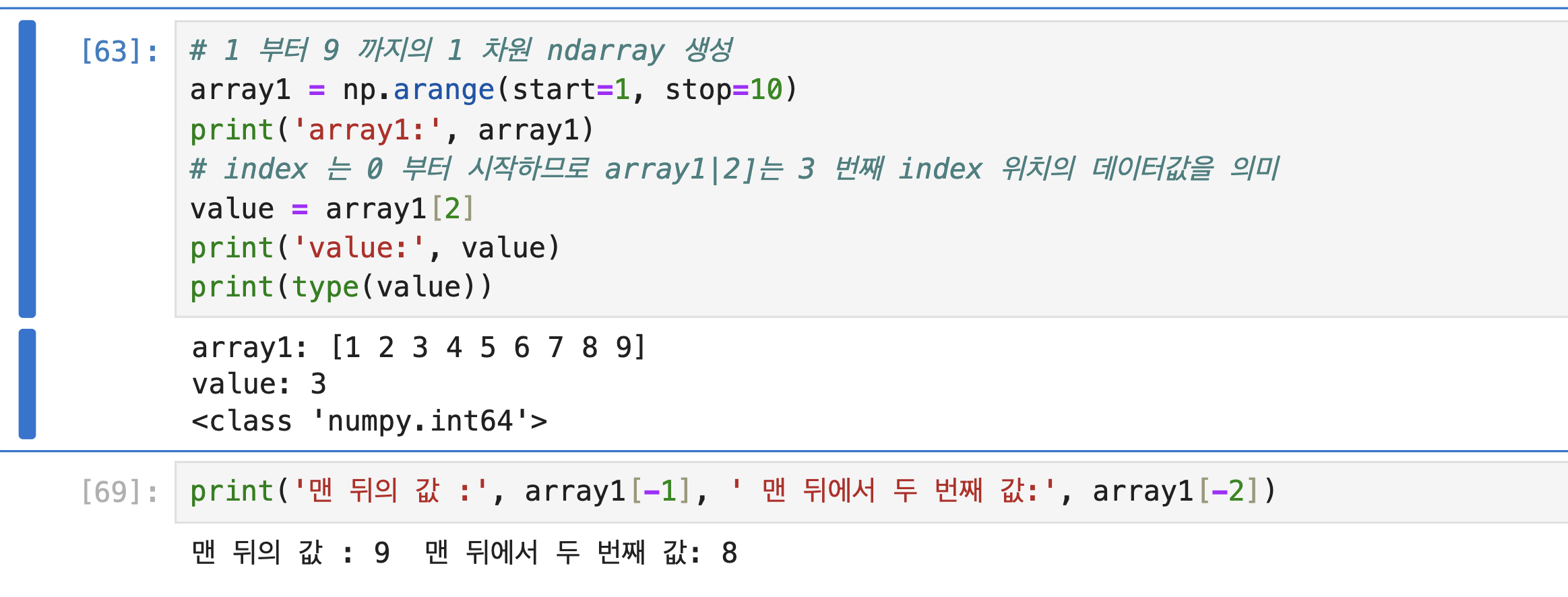
넘파이의 ndarray의 데이터 세트 선택하기 - 인덱싱 (Indexing)
인덱싱
1. 단일 값 추출
ndarray 내의 데이터값도 간단히 수정 가능합니다.

1차원과 2차원 ndarray 에서의 데이터 접근의 차이는 2 차원의 경우 콤마로 (,) 로 분리된 row와 column 위치의 인덱스를 통해 접근하
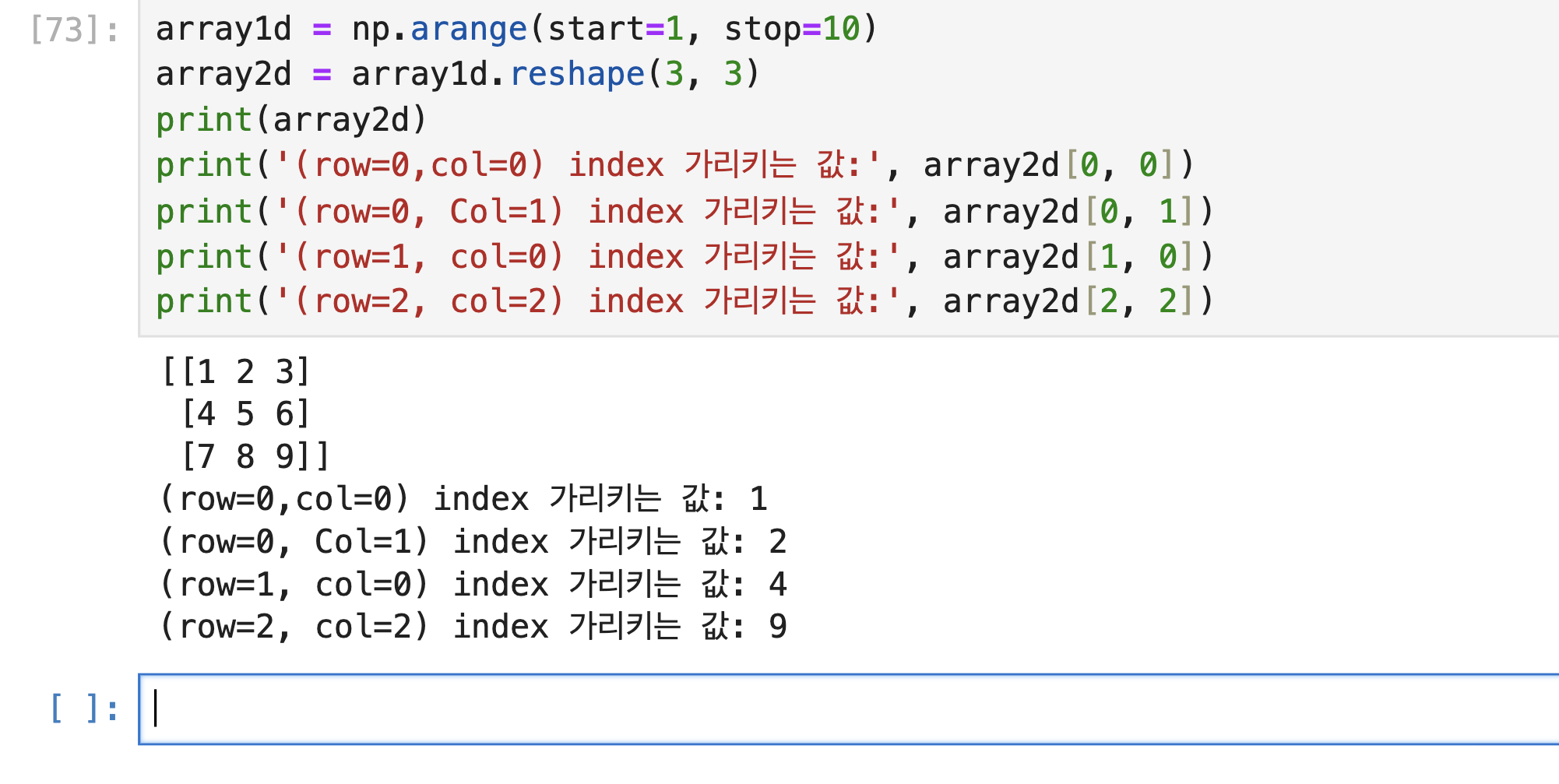
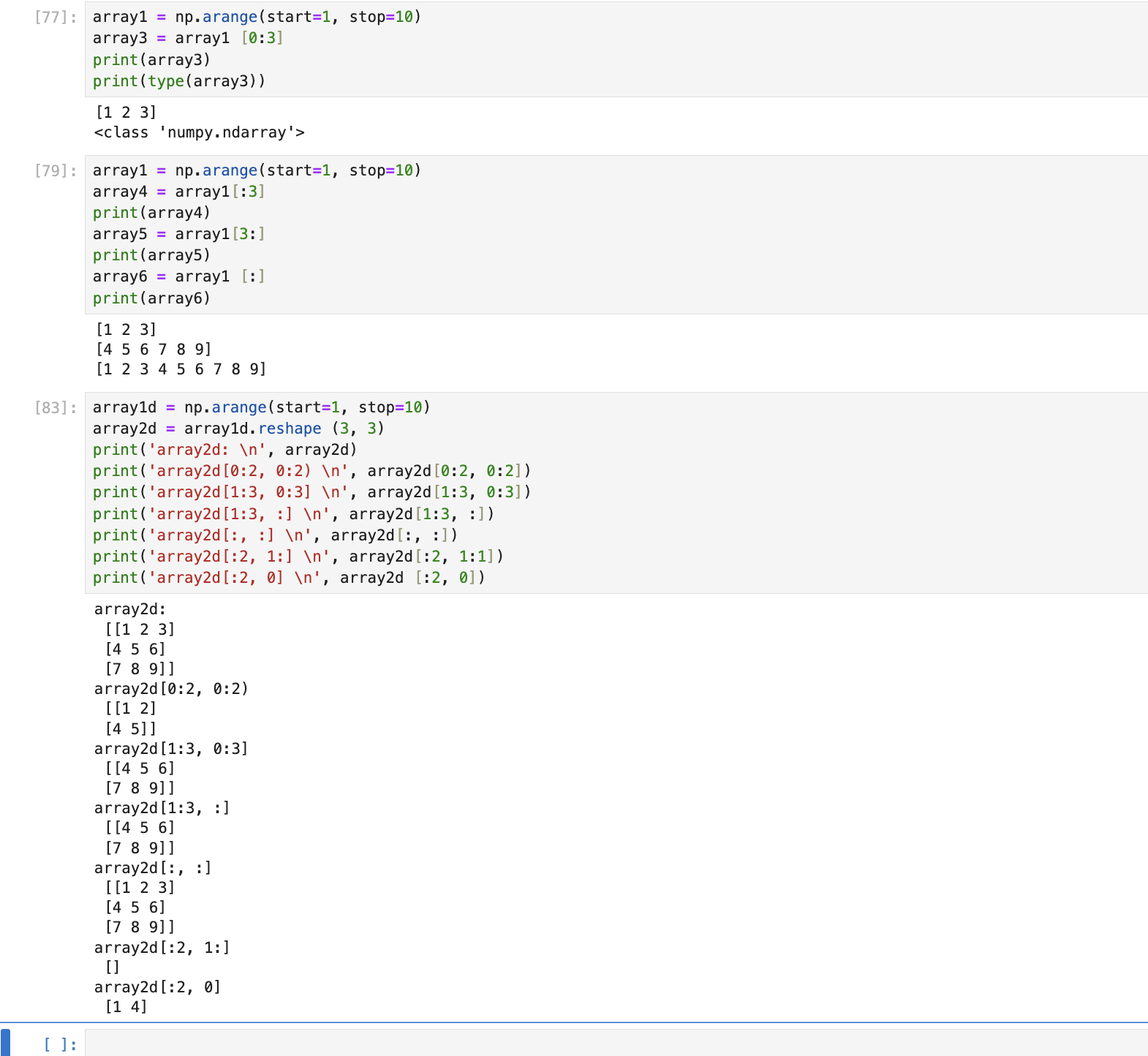
2. 슬라이싱 (Slicing): 슬라이싱은 연속된 인덱스상의 ndarray를 추출하는 방식입니다. : 기호 사이에 시작 인덱스와
종료 인덱스를 표시하면 시작 인덱스에서 종료 인덱스 -1 위치에 있는 데이터의 ndarray를 반환합니다.
- 슬라이싱 기호인 사이의 시작 , 종료 인덱스는 생략이 가능합니다.
- : 기호 앞에 시작 인덱스를 생략하면 자동으로 맨 처음 인덱스인 0 으로 간주합니다.
- : 기호 뒤에 종료 인덱스를 생략하면 자동으로 맨 마지막 인덱스로 간주합니다.
- : 기호 앞 / 뒤에 시작 / 종료 인덱스를 생략하면 자동으로 맨 처음 / 맨 마지막 인덱스로 간주합니다.
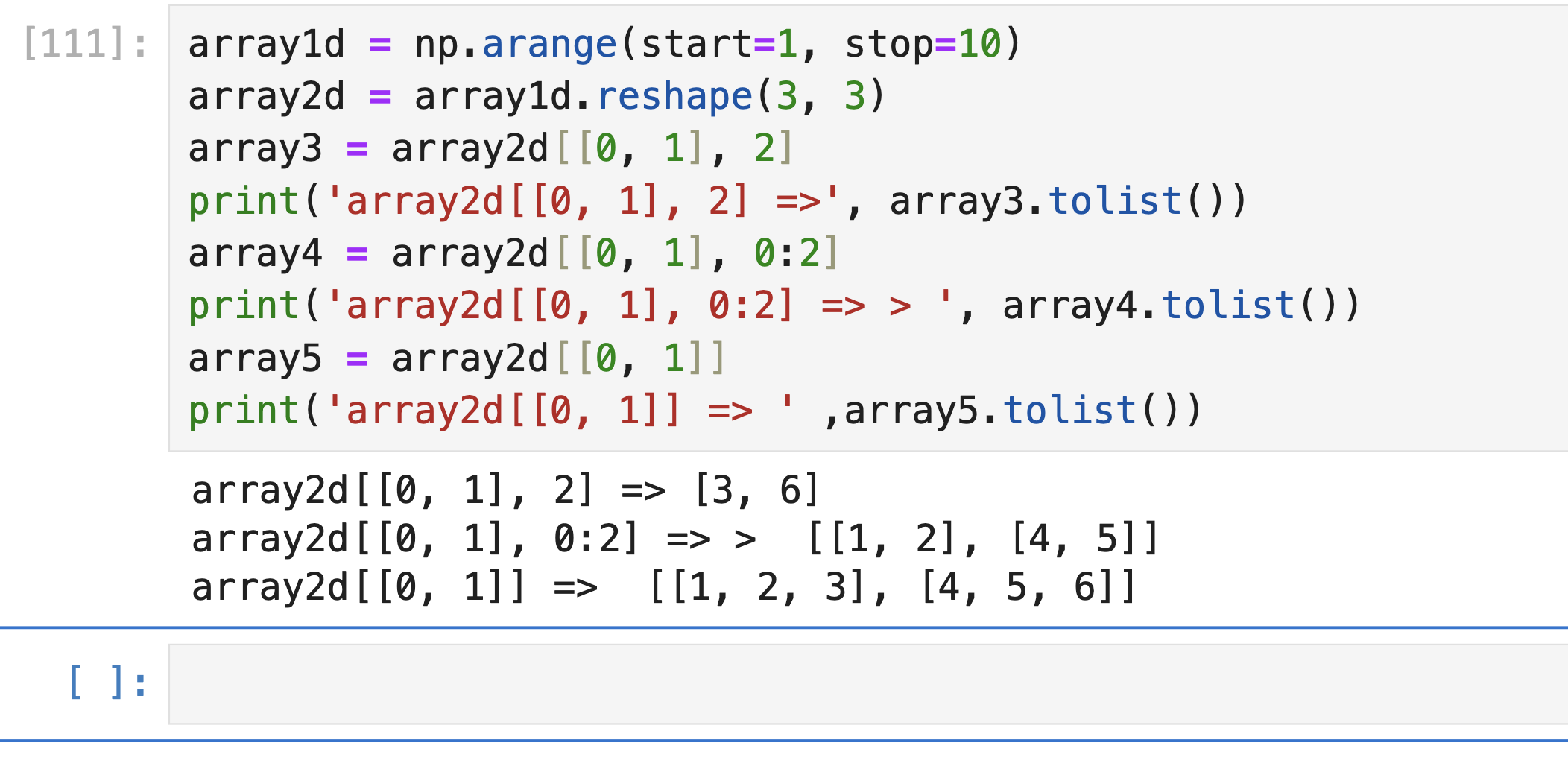
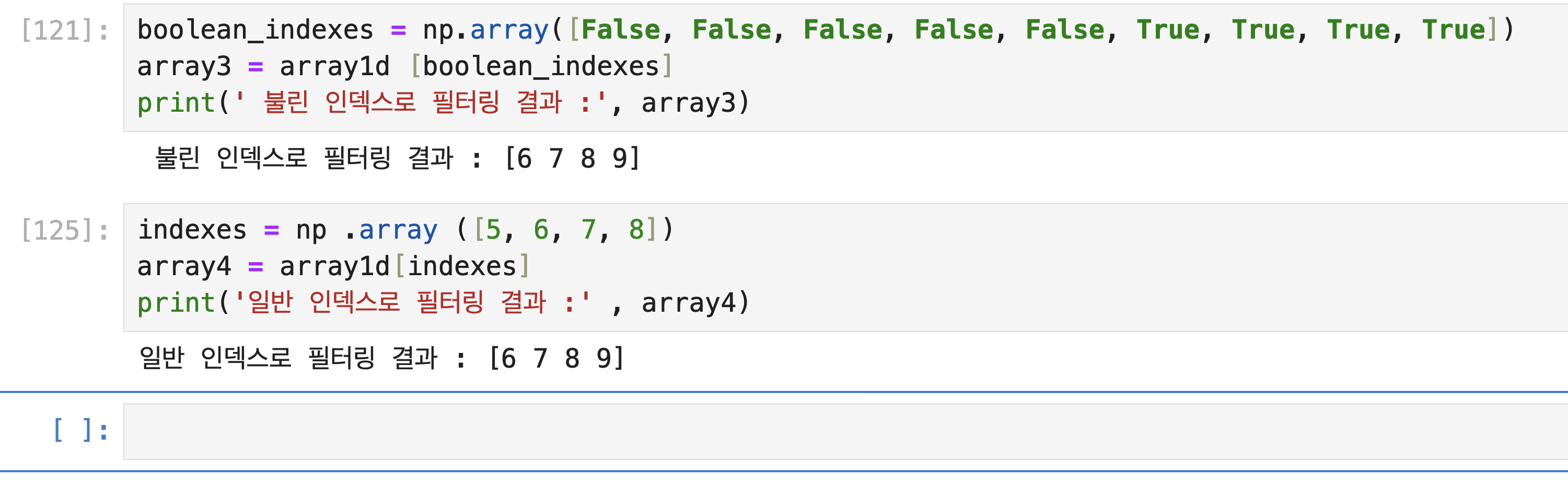
- 팬시 인덱싱 (Fancy Indexing): 일정한 인덱싱 집합을 리스트 또는 ndarray 형태로 지정해 해당 위치에 있는 데이터의 ndarray를 반환합니다.
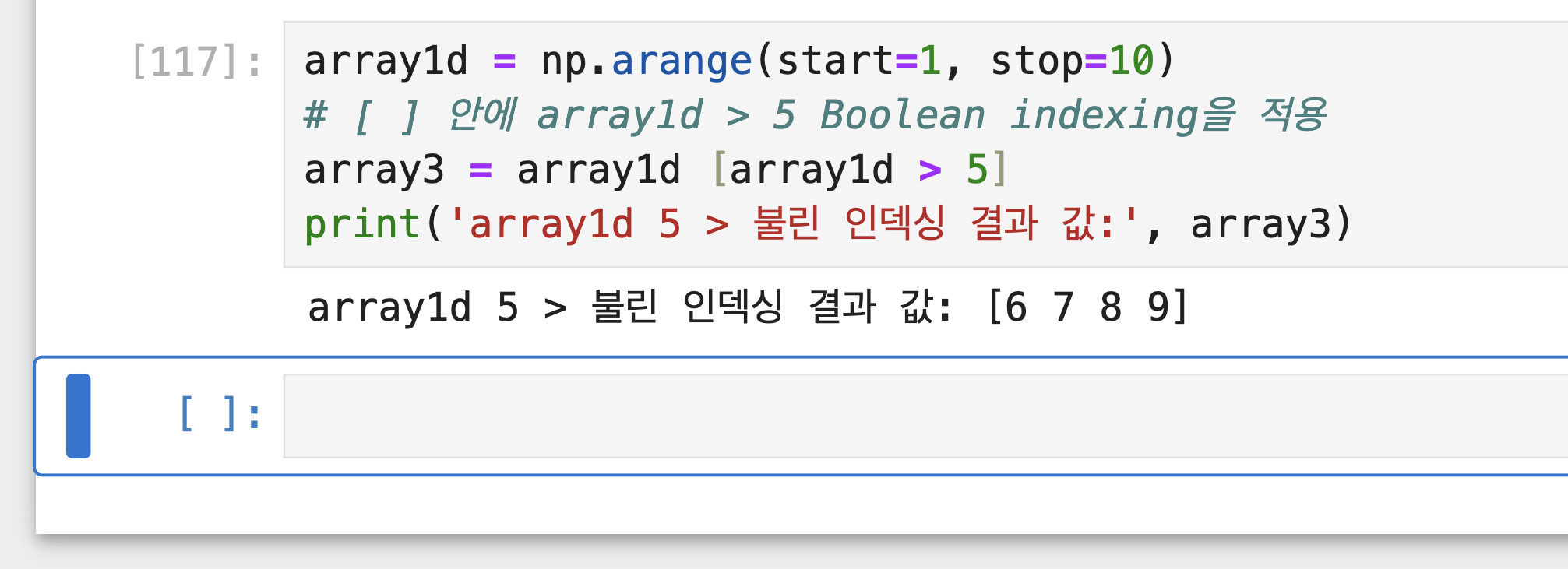
- 불린 인덱싱 (Boolean Indexing): 특정 조건에 해당하는지 여부인 True/False 값 인덱싱 집합을 기반으로 True
에 해당하는 인덱스 위치에 있는 데이터의 ndarray를 반환합니다.
행렬의 정렬 sort()와 argsort()
- 행렬 정렬 ▶︎
p.sort(),ndarray.sort() - 내림차순으로 정렬 : [::-1] 을 적용합니다.
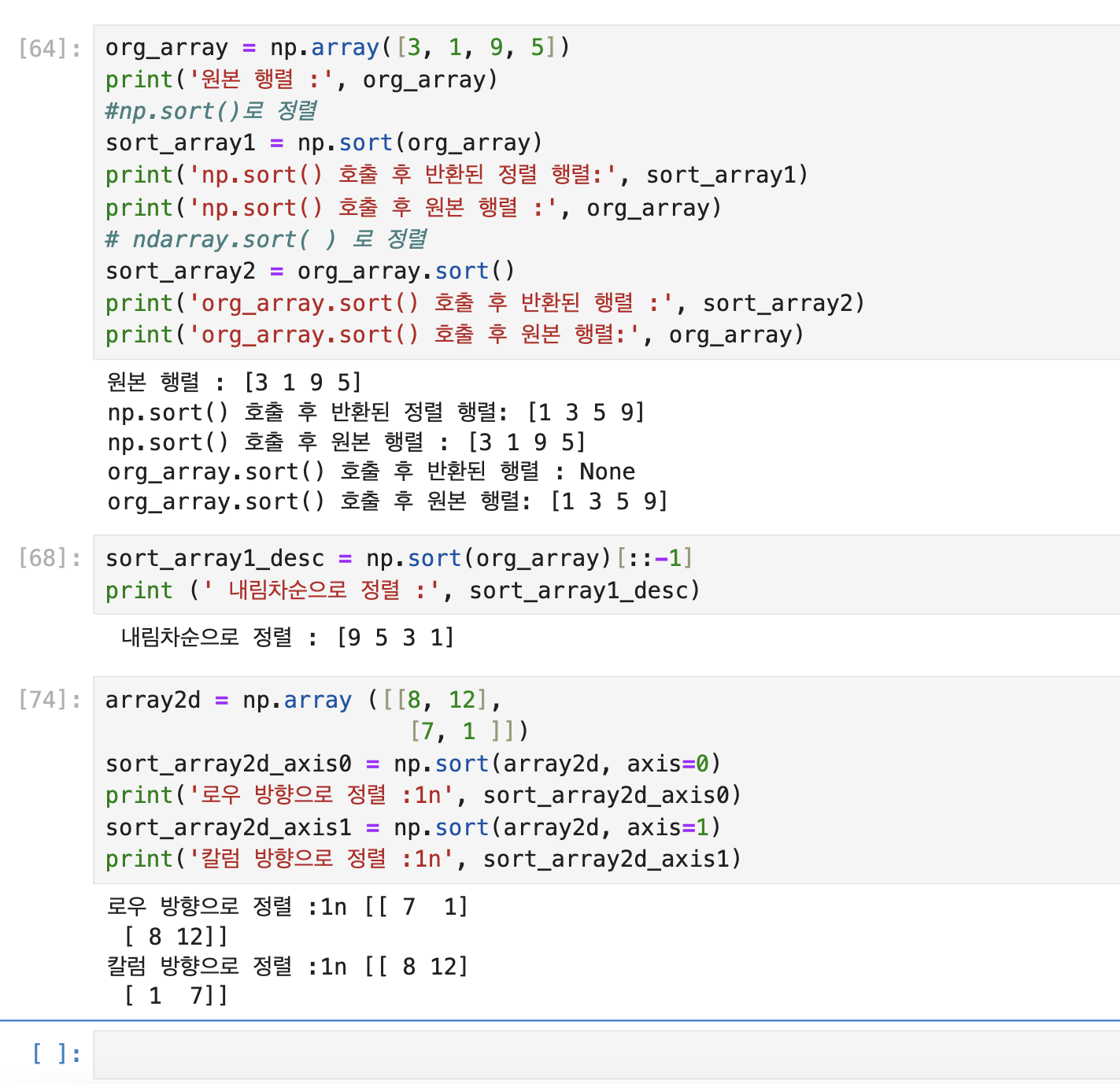
- 정렬된 행렬의 인덱스를 반환 ▶︎ argsort()
- 오름차순이 아닌 내림차순으로 정렬 시에 원본 행렬의 인덱스를 구하는 것도 [:;-1]을 적용하면 됩니다.

name_array = np.array(['John', 'Mike' , 'Sarah', 'Kate', 'Samuel'])
score_array= np.array([78, 95, 84, 98, 88])
sort_indices_asc = np.argsort(score_array)
print('성적 오름차순 정렬 시 Score_array의 인덱스 :', sort_indices_asc)
print('성적 오름차순으로 name_array 의 이름 출력:' , name_array[sort_indices_asc])결과
성적 오름차순 정렬 시 Score_array의 인덱스 : [0 2 4 1 3]
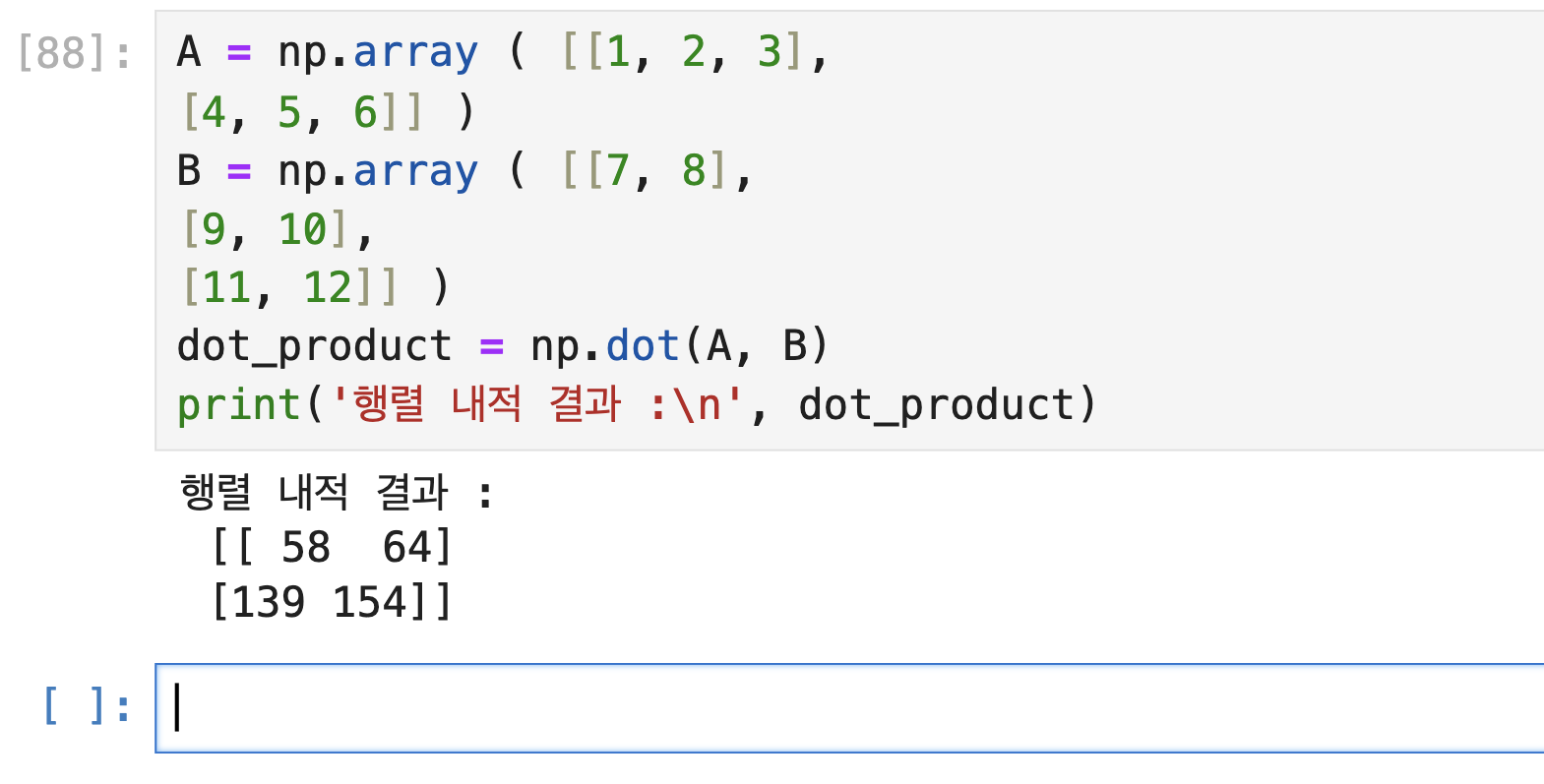
성적 오름차순으로 name_array 의 이름 출력: ['John' 'Sarah' 'Samuel' 'Mike' 'Kate']선형대수 연산 - 행렬 내적과 전치 행렬 구하기
행렬 내적 ( 행렬 곱 ) : np.dot()
전치 행렬 : np.transpose()
A = np.array(([1, 2),
[3, 4]])
transpose_mat = np.transpose(A)
print('A의 전치 행렬 :1n', transpose_mat)
데이터 핸들링을 위한 라이브러리 - 판다스 (Pandas)
import pandas as pdKaggle에 로그인해서 Titanic - Machine Learning from Disaster 내려받기
titanic.zip 파일 풀어서
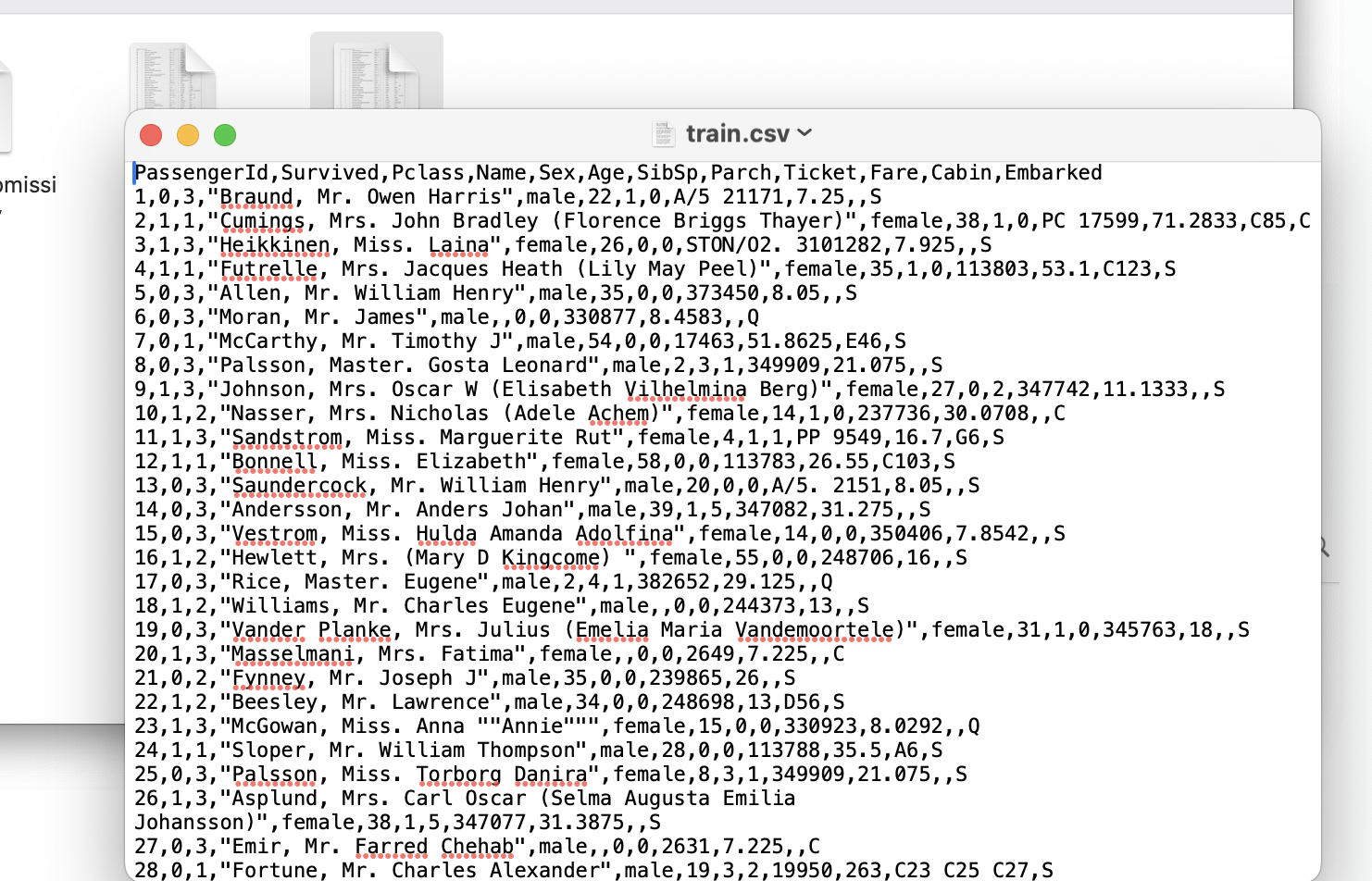
TextEdit로 train.csv 를 열어보시면 아래와 같이 보여줍니다.
pd.read_csv()
파일명 인자로 들어온 파일을 로딩해 Dataframe 객체로 반환
head(3) 은 맨 앞 3 개의 로우를 반환합니다 (Default 는 5개).
titanic_df = pd.read_csv('sample_data/train.csv')
titanic_df.head(3)Dataframe의 크기
print('DataFrame 크기): ', titanic_df.shape)info(), describe()
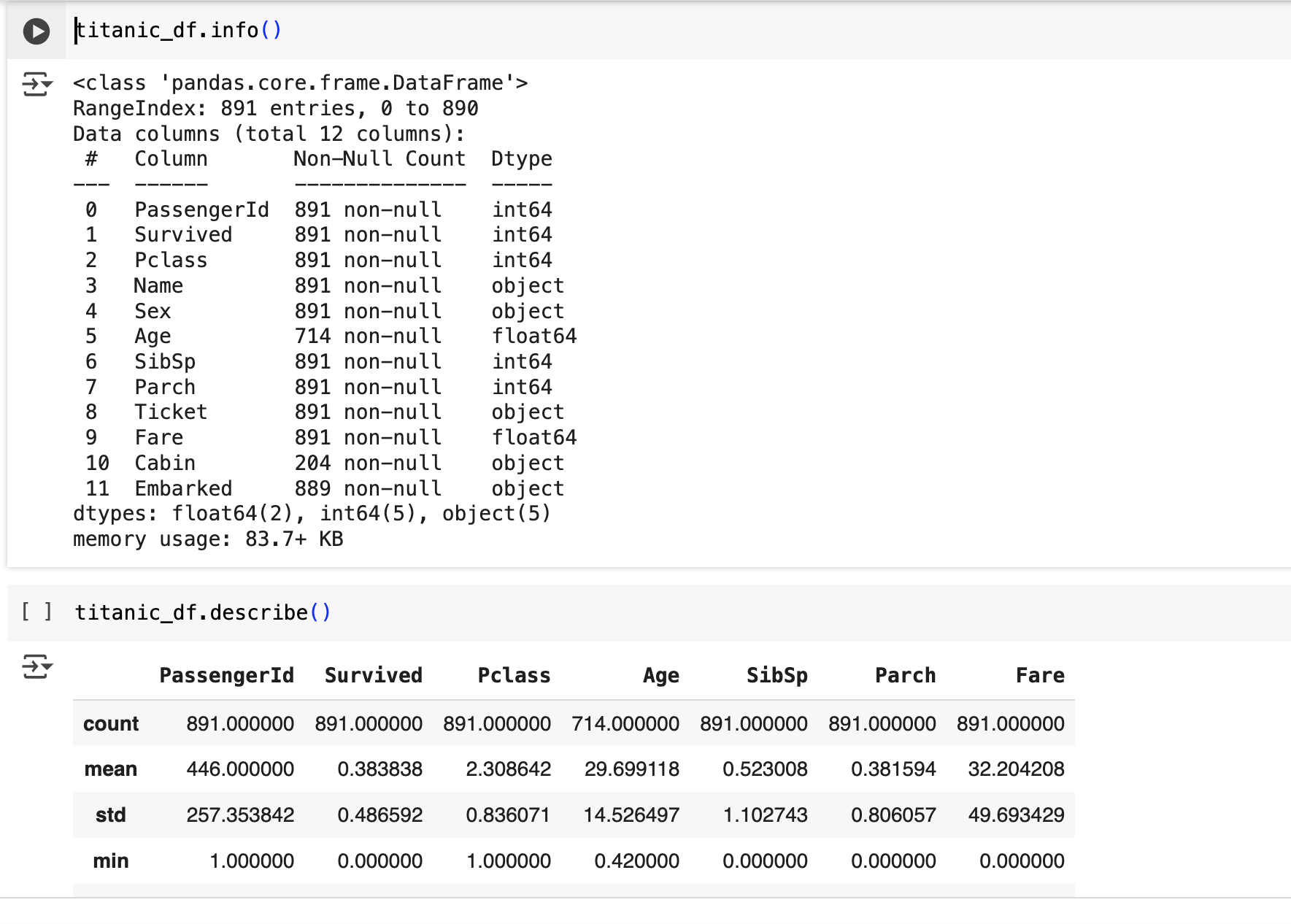
titanic_df.info()
titanic_df.describe()