https://colab.research.google.com/drive/10Fpzn42B1kBYQE1yI6RhCF1wEY7vTABL?usp=sharing
https://colab.research.google.com/drive/1ecn0Idt-lLd9igAFUBDjE2nQwn6Xfd3q?usp=sharing
https://colab.research.google.com/drive/1qH3A6YH_npZ_t95mWZuPi2jilp-nJg9T?usp=sharing
1. 회귀 소개
-
회귀(regression)는 현대 통계학의 핵심 기법 중 하나임
-
공학, 의학, 사회과학, 경제학 등 다양한 분야의 발전에 기여함
-
영국 통계학자 갈톤(Galton)의 연구에서 유래됨
-
갈톤은 부모와 자식 간의 키 상관관계를 분석함
-
부모의 키가 크거나 작아도 자식의 키는 평균에 수렴하려는 경향이 있음
-
데이터가 평균적인 값으로 회귀하려는 성질을 활용함
-
회귀 분석은 이러한 경향을 수학적으로 모델링하는 통계 기법임
-
회귀는 여러 독립변수 와 하나의 종속변수 간의 상관관계를 모델링하는 기법임
-
예시: 방 개수, 방 크기, 학군 등의 독립변수 → 아파트 가격이라는 종속변수 예측
선형 회귀식
Y: 종속변수 (예: 아파트 가격)
X: 독립변수 (예: 방 개수, 방 크기 등)
Z: 회귀 계수 (각 피처의 영향력)
머신러닝 관점:
- 독립변수 → 피처(feature)
- 종속변수 → 결정 값(label)
- 목표: 학습을 통해 최적의 회귀 계수를 찾는 것
회귀는 다음 기준에 따라 분류됨:
- 회귀 계수가 선형인지 → 선형 회귀 / 비선형 회귀
- 독립변수의 개수 → 단일 회귀 / 다중 회귀
회귀 유형 구분
| 독립변수 개수 | 회귀 계수의 결합 |
|---|---|
| 1 개 : 단일 회귀 | 선형 : 선형 회귀 |
| 여러 개 : 다중 회귀 | 비선형 : 비선형 회귀 |
지도학습 유형
| 분류 (Classification) | 회귀 (Regression) |
|---|---|
| 예측 값: 카테고리 값 | 예측 값: 숫자값 |
| ( 이산형 클래스값 ) | ( 연속형 숫자값 ) |
- 선형 회귀는 가장 많이 사용되는 회귀 기법임
- 실제 값과 예측값의 차이(오차 제곱)를 최소화하는 직선을 찾음
- 선형 회귀 모델은 규제(Regularization) 방식에 따라 나뉜다
- 규제는 과적합을 방지하기 위해 회귀 계수에 페널티를 적용하는 방식임
대표적인 선형 회귀 모델
- 일반 선형 회귀 : 예측값과 실제 값의 RSS(Residual Sum of Squares)를 최소화할 수 있도록 회귀 계수를 최적화하며, 규
제(Regularization)를 적용하지 않은 모델 - 릿지 (Ridge): 릿지 회귀는 선형 회귀에 L2 규제를 추가한 회귀 모델입니다. 릿지 회귀는 L2 규제를 적용하는데 , L2 규제
는 상대적으로 큰 회귀 계수 값의 예측 영향도를 감소시키기 위해서 회귀 계수값을 더 작게 만드는 규제 모델. - 라쏘 (Lasso): 라쏘 회귀는 선형 회귀에 L 규제를 적용한 방식입니다. L2 규제가 회귀 계수 값의 크기를 줄이는 데 반해 ,
L1 규제는 예측 영향력이 작은 피처의 회귀 계수를 0 으로 만들어 회귀 예측 시 피처가 선택되지 않게 하는 것입니다. 이러한 특성 때문에 L1 규제는 피처 선택 기능 으로도 불립니다. - 엘라스틱넷 (ElasticNet): L2, L1 규제를 함께 결합한 모델입니다. 주로 피처가 많은 데이터 세트에서 적용되며 , L1 피처의 개수를 줄임과 동시에 L2 규제로 계수 값의 크기를 조정합니다. L1 규제로 피처의 개수를 줄임과 동시에 L2규제로 계수 값의 크기를 조정
- 로지스틱 회귀 (Logistic Regression): 로지스틱 회귀는 회귀라는 이름이 붙어 있지만 , 사실은 분류에 사용되는 선형 모델
입니다. 로지스틱 회귀는 매우 강력한 분류 알고리즘입니다. 일반적으로 이진 분류뿐만 아니라 희소 영역의 분류 , 예를 들어 텍스트 분류와 같은 영역에서 뛰어난 예측 성능을 보입니다.
2. 단순 선형 회귀를 통한 회귀 이해
= 단순 선형 회귀는 독립변수 하나, 종속변수 하나를 사용하는 가장 단순한 형태의 선형 회귀
- 예시: 주택 가격이 주택 크기로만 결정된다고 가정, 주택 크기와 가격 간에는 선형(직선) 관계가 있다고 가정 (일반적으로 주택의 크기가 크면 가격이 높아지는 경향이 있기)
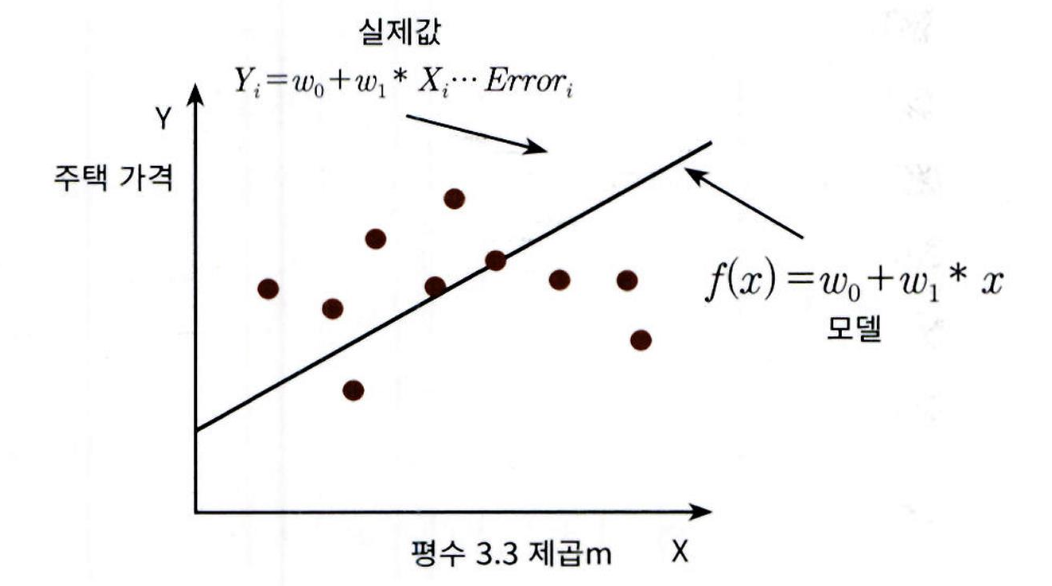
- 오류 값은 + 나 - 가능
- 오류 합을 계산
- 절댓값을 취해서 더하기 (Mean Absolute Error),
- 오류 값의 제곱을 구해서 더하는 방식 (RSS, Residual Sum of Square) 을 취함.
- 일반적으로 RSS 방식으로 오류 합을 구함.
- 즉 ,
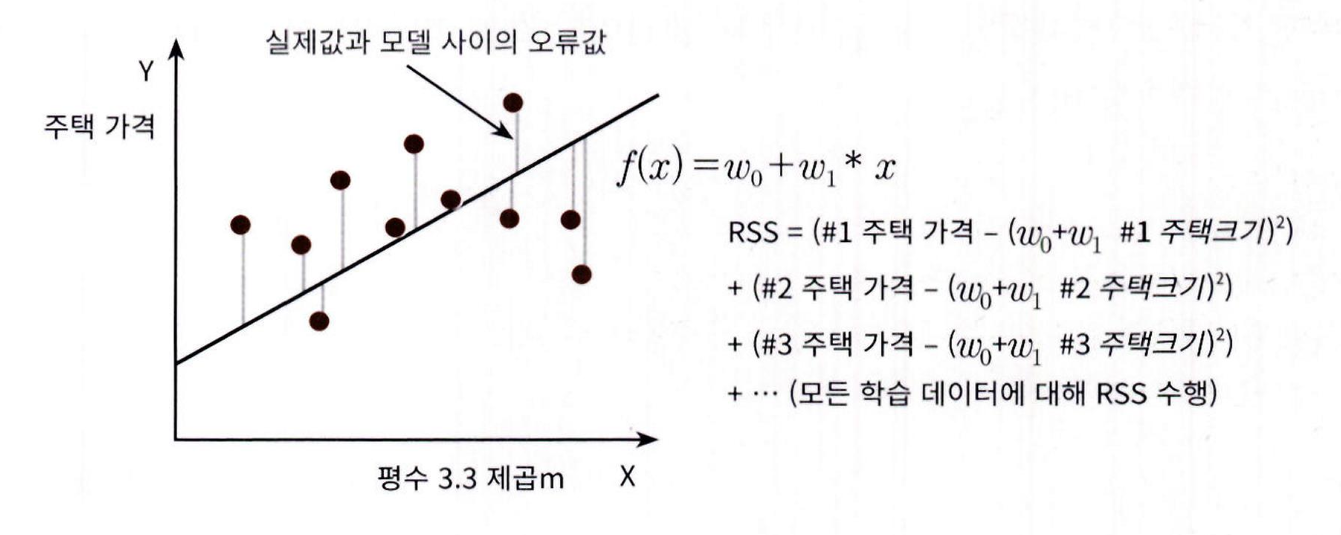
RSS(Residual Sum of Squares)는 회귀 계수
𝑤0,𝑤1 을 변수로 하여 표현
- RSS 는 회귀식의 독립변수 X, 종속변수 Y 가 중심 변수가 아니라 w변수 (회귀 계수) 가 중심 변수임을 인지하는 것이 매우 중요함 - 학습 데이터로 입력되는 독립변수와 종속변수는 RSS 에서 모두 상수로 간주함
- RSS 는 학습 데이터의 건수로 나누어서 다음과 같이 정규화된 식으로 표현
i 는 1 부터 학습 데이터의 총 건수 N 까지
- 회귀에서 RSS는 비용(Cost)으로 간주되며,
- w 변수(회귀 계수)로 구성된 RSS를 비용 함수(Cost Function)라고 함
- 머신러닝 회귀는 학습을 통해 비용 함수의 값을 최소화하는 것이 목표
- 비용 함수는 손실 함수(Loss Function)라고도 불림
3. 비용 최소화하기 - 경사 하강법(Gradient Descent) 소개
비용 함수가 최소가 되는 W 파라미터를 구하기
- W 파라미터가 적을 경우, 고차원 방정식으로도 최소값 계산 가능
- W 파라미터가 많아지면 고차원 방정식으로 해결이 어려움
- 경사 하강법(Gradient Descent)은 이러한 고차원 방정식 같은 문제를 해결할 수 있는 방법임
- 경사 하강법은 비용 함수(RSS)를 점진적으로 줄이면서 최적의 W 파라미터를 찾음
- 경사 하강법은 핵심적인 학습 기법이며, 반복적인 계산을 통해 W 값을 업데이트함 (오류 값이 최소가 되는 W 파라미터를 구하는 방식임)
- 경사 하강법은 비용 함수의 최솟값을 찾기 위해 반복적으로 W 값을 보정하는 방법 --> 마치 깜깜한 밤에 산 아래로 내려가는 것처럼, 현재보다 낮은 방향(오차가 줄어드는 방향)으로 이동
경사 하강법은 복잡한 고차원 방정식을 풀지 않고도 직관적이고 빠르게 최적 W 값을 찾을 수 있음 - 예측값과 실제 값의 차이(오류)를 줄이는 방향으로 W 값을 반복적으로 조정
예: 오류가 100 → 90 → 80 → … 점점 감소
-
더 이상 오류가 줄어들지 않으면 현재 오류를 최소 비용으로 판단하고 해당 W 값을 반환
-
즉, 오류 최소화 방향으로 W를 업데이트하면서 최적의 W를 찾는 방식
-
경사 하강법의 핵심은 오류가 작아지는 방향으로 W(가중치)를 보정하는 것
-
예: 야구공을 던지면 속도가 증가하다가 점차 감소하며 땅에 떨어지듯,
처음엔 가속도(속도의 미분값) 가 양수 → 속도 증가
가속도 = 0일 때 최고 속도 도달
이후 가속도 < 0 (마이너스) 가 되며 속도는 감소 → 결국 떨어짐 -
비용 함수가 포물선 형태일 때, 기울기(미분값) 를 계산해
기울기가 양수면 W를 감소시키고
기울기가 음수면 W를 증가시켜 비용이 최소가 되는 방향으로 이동
- 기울기 = 0인 지점(미분값이 0)이 최소 비용 지점, 그때의 W가 최적 파라미터임
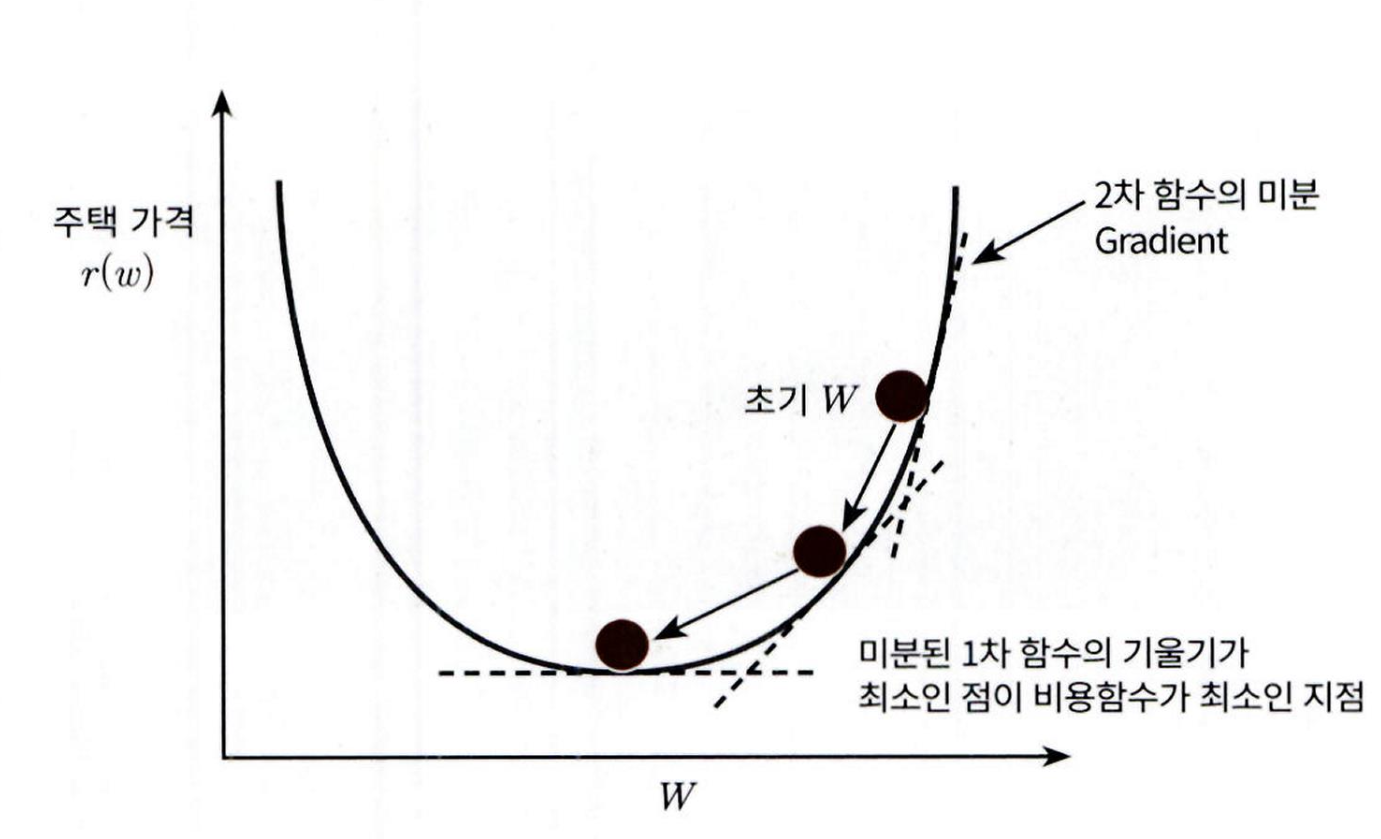
비용 함수 RSS(W0,W1) 를 편의상 R(w) 로 지칭
- R(w) 는 변수가 w 파라미터로 이뤄진 함수
- 두 개의 w 파라미터 가지고 있으며 각 변수에 편미분을 적용

- 결과를 반복적으로 보정하면서 , 값을 업데이트하면 비용 함수 R(w) 가 최소가 되는 ,를 구할 수 있음
- 업데이트는 새로운 을 이전 에서 편미분 결괏값을 마이너스 (-) 하면서 적용
-편미분 값이 너무 클 수 있기 때문에 보정 계수 를 곱함 ('학습률')
경사 하강법의 일반적인 프로세스
Step 1 : , 를 임의의 값으로 설정하고 첫 비용 함수의 값을 계산합니다.
Step 2 :
을
을
으로 업데이트한 후 다시 비용 함수의 값을 계산합니다.
Step 3 : 비용 함수가 감소하는 방향성으로 주어진 횟수만큼 Step 2 를 반복하면서 , 과 를 계속 업데이트합니다.
실습
간단한 회귀식인 y= 4X + 6 을 근사하기 위한 100 개의 데이터 세트를 만들고, 여기에 경사 하강법을 이용해 회귀 계수(, 과 )를 도출하는 것
- 단순 선형 회귀로 예측할 만한 데이터 세트를 먼저 만들어
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(0)
# y = 4x + 6 에 노이즈 추가
X = 2 * np.random.rand(100, 1)
y = 6 + 4 * X + np.random.randn(100, 1)
#X,y 데이터 세트 산점도로 시각화
plt.scatter(X, y)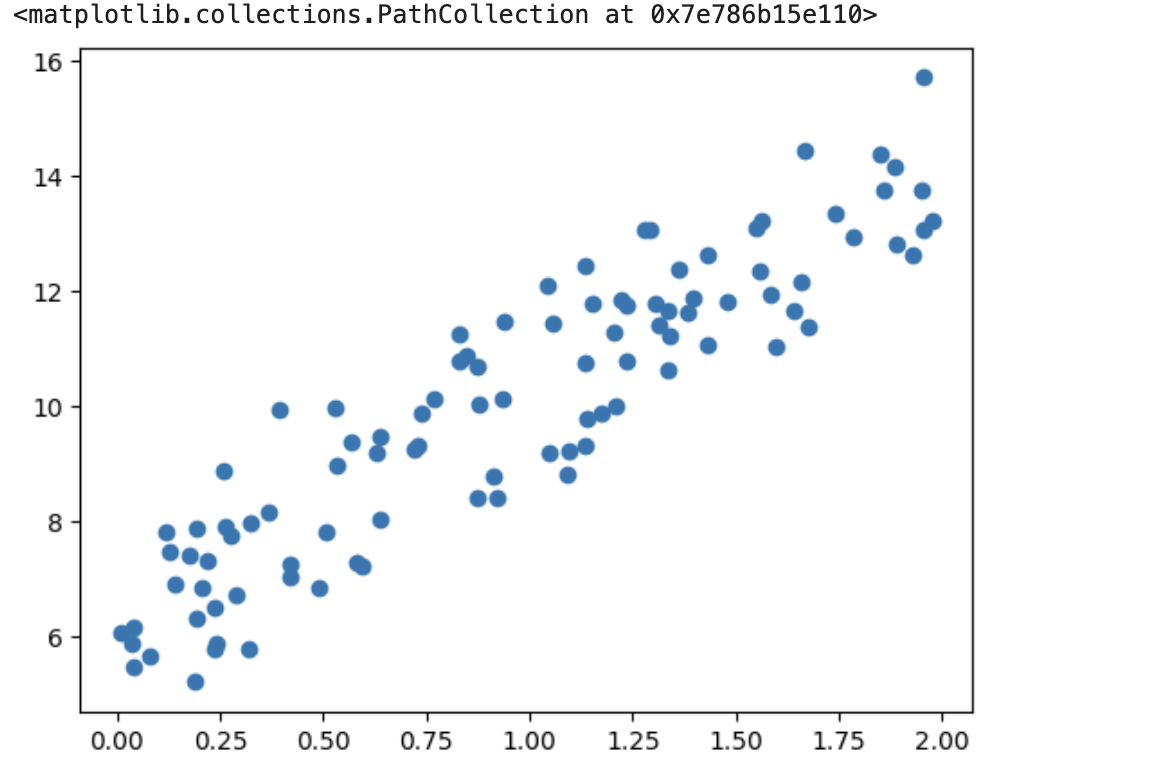
- 데이터는 y=4X+6 을 중심으로 무작위로 퍼져 있음
- 비용 함수
get_cost()는 실제 y 값과 예측된 y 값을 인자로 받아서
을 계산해 반환
N = len(y)
cost = np.sum(np.square(y - y_pred))/N
return cost- 경사 하강법을
gradient_descent() - gradient_descent()
는 , 과 을 모두 0 으로 초기화한 뒤 iters 개수만큼 반복하면서 , 과 을 업데이트 - gradient_descent()는 위에서 무작위로
생성한 X 와 y 를 입력받는데 , X 와 y 모두 넘파이 ndarray.
넘파이 행렬에 W 를 업데이트하려면 약간의 선형 대수 지식이 필요함
-
get_weight_updates()
입력 배열 X 값에 대한 예측 배열 y pred 는 np.dot(X, w1.T) + w0 으로 구함 -
100 개의 데이터 X(1,2,••,100)이 있다면 예측값은 W0 + X(1)W1 + X(2)W1
+..+ X(100)*w1 임 -
dot()를 이용해 y_pred=np.dot(X, w1.T) + w0 로 예측 배열값을 계산
-
get_weight_update()는w1_update로
를 , w0_update 로
값을 넘파이의 dot 행렬 연산으로 계산한 뒤 이를 반환
#w1 과 w0 를 업데이트할 1_update, wo_update 를 반환.
def get_weight_updates(w1, w0, X, y, learning_rate=0.01):
N = len(y)
# 먼저 w1_update, wo_update 를 각각 w1, w 의 shape 와 동일한 크기를 가진 0 값으로 초기화
w1_update = np.zeros_like(w1)
wO_update = np.zeros_like(w0)
# 예측 배열 계산하고 예측과 실제 값의 차이 계산
y_pred = np.dot(X, w1.T) + w0
diff = y-y_pred
# w0_update 를 dot 행렬 연산으로 구하기 위해 모두 1 값을 가진 행렬 생성
w0_factors = np.ones((N, 1))
# W1 과 w0 을 업데이트할 W1_update 와 wo_update 계산
w1_update = -(2/N)*learning_rate*(np.dot(X.T, diff))
w0_update = -(2/N)*learning_rate*(np.dot(w0_factors.T, diff))
return wi_update, w0_updateget_weight_updates() 을 경사 하강 방식으로 반복적으로 수행하여 w1 과 w0 를 업데이트하
는 함수인 gradient_descent_steps() 함수를 생성
# 입력 인자 iters로 주어진 횟수만큼 반복적으로 w1 과 wO 를 업데이트 적용함.
def gradient_descent_steps(X, y, iters=10000):
#wO 와 w 을 모두 0 으로 초기화.
w0 = np.zeros((1, 1))
w1 = np.zeros((1, 1))
# 인자로 주어진 iters 만큼 반복적으로 get_weight_updates() 호출해 w1, w0 업데이트 수행.
for ind in range(iters):
w1_update, wo_update = get_weight_updates(w1, w0, X, y, learning_rate=0.01)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0
gradient_descent_steps() 를 호출해 w1 과 w0 을 구해 보겠습니다.
- 그리고 최종적으로 예측값 과 실제값의 RSS 차이를계산하는
get_cost()함수를 생성하고 이를 이용해 경사 하강법의 예측 오류도 계산해 보겠습니다.
def get_cost(y, y_pred):
N = len(y)
cost = np.sum(np.square(y - y_pred)) / N
return cost
w1, w0 = gradient_descent_steps(X, y, iters=1000)
print("w1: {0: 3f} w0: {1:.3f}".format(w1[0, 0], w0[0, 0]))
y_pred = w1[0, 0] * X + w0
print('Gradient Descent Total Cost: {0:.4f}'.format(get_cost(y, y_pred)))
결과
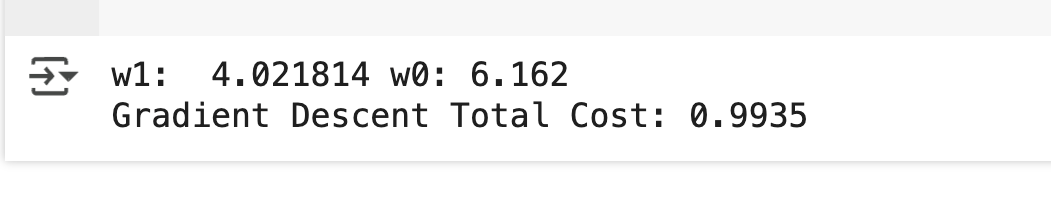
- 실제 선형식인 y= 4X + 6 과 유사하게 w1 은 4.022, wO 는 6.162 가 도출
- 예측 오류 비용은 약 0.9935
y_pred에 기반해 회귀선
plt.scatter (X, y)
plt.plot(X, y_pred)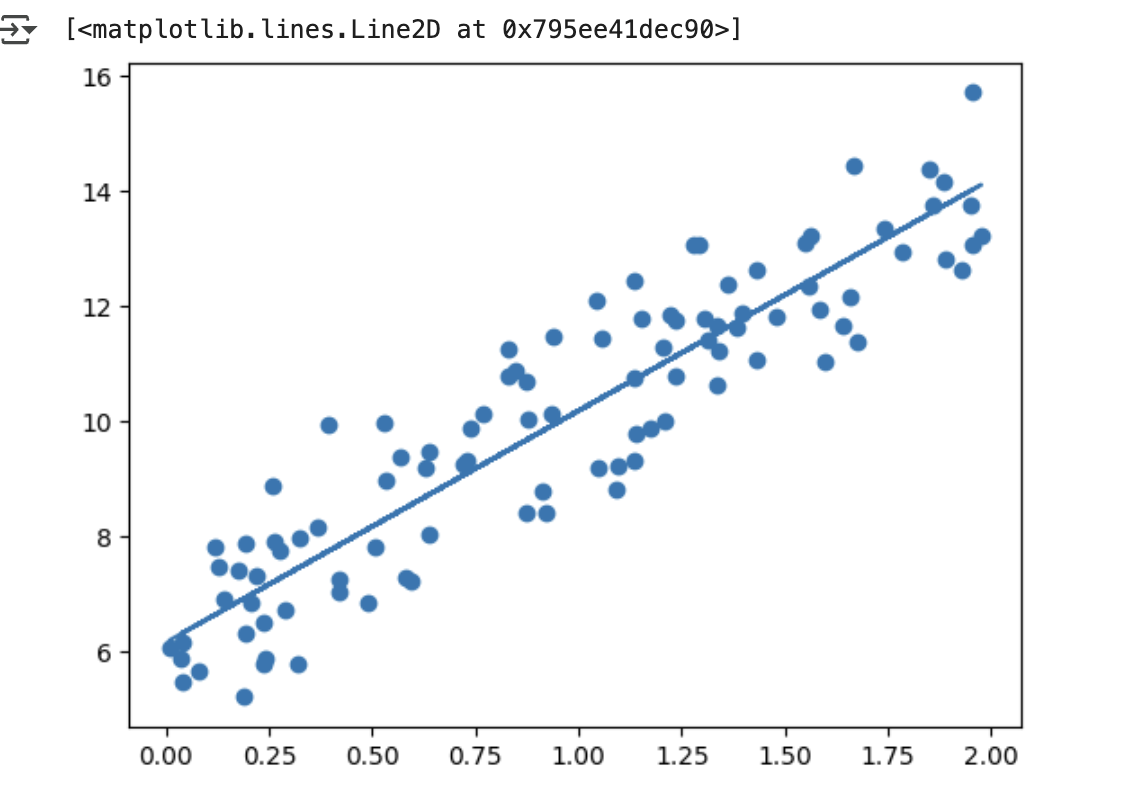
- 경사 하강법은 전체 데이터를 반복적으로 사용해 비용 함수 최소화를 수행하지만, 수행 시간이 오래 걸림
- 실무에서는 일반적으로 확률적 경사 하강법( (Stochastic Gradient
Descent) 사용 - 전체 데이터가 아닌 일부(batch_size) 데이터만 이용해 W를 업데이트
- 이로 인해 속도가 빠르며 대용량 데이터에 적합
- 또 다른 변형으로 미니 배치 확률적 경사 하강법(Mini-batch SGD) 도 존재
stochastic_gradient_descent_steps()함수는 기존gradient_descent_steps()와 구조는 유사- 차이점: 전체 데이터 대신 일부 샘플을 랜덤 추출하여 업데이트 수행
def stochastic_gradient_descent_steps(X, y, batch_size=10, iters=1000):
w0 = np.zeros((1, 1))
w1 = np.zeros((1, 1))
for ind in range(iters):
np.random.seed(ind)
# 전체 X, y 데이터에서 랜덤하게 batch_size만큼 데이터를 추출해 sample X, Sample y 로 저장
stochastic_random_index = np.random.permutation(X.shape[0])
sample_X = X[stochastic_random_index[0:batch_size]]
sample_y = y[stochastic_random_index[0:batch_size]]
# 랜덤하게 batch_size 만큼 추출된 데이터 기반으로 w1_update, wo_update 계산 후 업데이트
w1_update, w0_update = get_weight_updates(w1, w0, sample_X, sample_y, learning_rate=0.01)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0stochastic_gradient_descent_steps() 를 이용해 w1, w0 및 예측 오류 비용을 계산
w1, w0 = stochastic_gradient_descent_steps(X, y, iters=1000)
print("w1:", round (w1[0, 0], 3), "w0:", round(w0[0, 0], 3))
y_pred = w1[0, 0] * X + w0
print( 'Stochastic Gradient Descent Total Cost: {0: .4f}'.format(get_cost(y, y_pred)))
- (미니 배치) 확률적 경사 하강법으로 구한 w0, w1 결과는 경사 하강법으로 구한 w1, w0 와 큰 차이가
없으며, 예측 오류 비용 또한 0.9937 로 경사 하강법으로 구한 예측 오류 비용 0.9935 보다 아주 조금
높을 뿐으로 큰 예측 성능상의 차이가 없음을 알 수 있음 - 따라서 큰 데이터를 처리할 경우에는 경
사 하강법은 매우 시간이 오래 걸리므로 일반적으로 확률적 경사 하강법을 이용함
같이 예측 회귀식을 만들 수 있음
- 계수가 많아지더라도 선형대수를 이용해 간단하게 예측값을 도출할 수 있음
- 앞의 예제에서 입력 행렬 X 에 대해서 예측 행렬 y pred 는 굳이 개별적으로 X 의 개별 원소와 w1 의 값을 곱하지 않고 np.dot(X, w1.T) + w0 을 이용해 계산했습니다. 마찬가지로 데이터의 개수가 N 이고 피처 M 개의 입력 행렬을 , 회귀 계수 를 W 배열로 표기하면 예측 행렬
로 구할 수 있습니다.
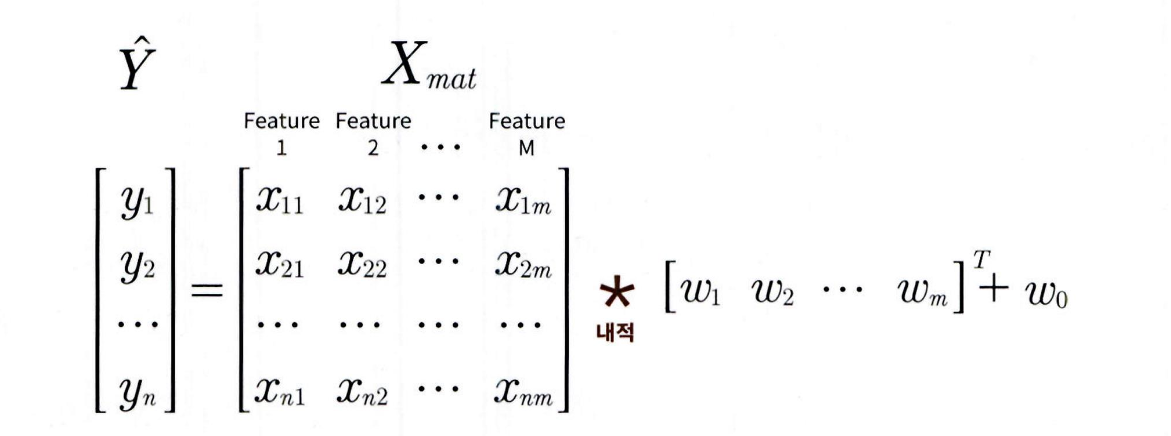
- w0 를 Weight 의 배열인 W 안에 포함시키기 위해서 Xmat 의 맨 처음 열에 모든 데이터의 값이 1 인 피처 Feat 0 을 추가
-->
회귀 예측값은
와 같이 도출할 수 있음

4. 사이킷런 LinearRegression을 이용한 보스턴 주택 가격 예측
-
사이킷런의 linear_models 모듈은 매우 다양한 종류의 선형 기반 회귀를 클래스로 구현해 제공
-
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.linear_model 에서
사이킷런이 지원하는 다양한 선형 모듈을 확인 가능 -
이들 선형 모델 중 규제가 적용되지 않
은 선형 회귀를 사이킷런에서 구현한 클래스인 LinearRegression을 이용해 보스턴 주택 가격 예측 회귀를 구현 가능
LinearRegression 클래스 - Ordinary Least Squares
- LinearRegression 클래스는 예측값과 실제 값의 RSS(Residual Sum o f Squares) 를 최소화해
OLS(Ordinary Least Squares) 추정 방식으로 구현한 클래스 - LinearRegression 클래스는
fit() 메서드로 X, y 배열을 입력받으면 회귀 계수 (Coefficients) 인 W 를 coef_ 속성에 저장
입력 파라미터
- fit_intercept: 불린 값으로 , 디폴트는 True 입니다. Intercept(절편) 값을 계산할 것인지 말지를 지정
- 만일 False 로 지정하면 intercept 가 사용되지 않고 0 으로 지정
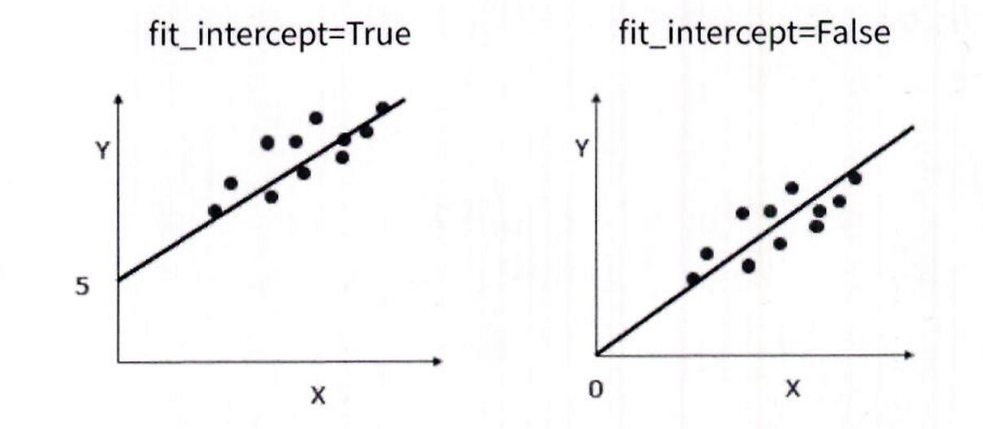
- normalize: 불린 값으로 디폴트는 False fit_intercept 가 False 인 경우에는 이 파라미터가 무시됨. 만일 True면 회귀를 수행하기 전에 입력 데이터 세트를 정규화함
속성
coef: fit() 메서드를 수행했을 때 회귀 계수가 배열 형태로 저장하는 속성. Shape 는 (Target 값 개수 ,피처 개수 ).
intercept: intercept값
-OLS (Ordinary Least Squares) 기반 회귀는 입력 피처 간 독립성에 크게 의존함
다중 공선성(Multicollinearity):
- 피처들 간 상관관계가 높을 때 발생
- 회귀 계수의 분산이 커지고, 모델이 오류에 민감해짐
해결 방법:
- 상관관계가 높은 피처 제거
- 정규화(규제, Regularization) 적용 (예: Ridge, Lasso)
- PCA 같은 차원 축소 기법 적용
회귀 평가 지표
일반적으로 회귀의 성능을 평가하는 지표

- 이 밖에 MSE 나 RMSE 에 로그를 적용한 MSLE(Mean Squared Log Error)와 RMSLE(Root Mean Squared Log Error)도 사용
- 사이킷런은 아쉽게도 RMSE 를 제공하지 않음
각 평가 방법에 대한 사이킷런의 API 및 cross_val_score 나 GridSearchCV에서 평가 시 사용되는 scoring 파라미터의 적용 값

- 회귀 지표를 cross_val_score나 GridSearchCV 같은 함수에 적용할 때는 scoring이라는 파라미터를 사용함
- 사이킷런의 scoring 함수는 점수 값이 클수록 좋은 평가 결과라고 간주함
- 평균 절대 오차(Mean Absolute Error), 평균 제곱 오차(Mean Squared Error) 등은 값이 작을수록 좋은 평가 지표임
- 따라서 이와 같은 회귀 지표를 scoring 파라미터로 사용할 때는 음수로 변환된 값을 사용
- 예를 들어 'negmean_absolute_error', 'neg_mean_squared_error'와 같이 neg 접두어가 붙음
- 이는 실제 평가 지표 값에 -1을 곱해서 음수로 만들어 점수가 작을수록 나쁜 성능으로 처리하지 않도록 하기 위함
0 예를 들어, 평균 절대 오차가 10이면 -10으로 변환되어 작은 오차일수록 더 큰 점수로 간주됩니다. - metrics.mean_absolute_error()와 같은 사이킷런의 평가 함수는 원래의 양수 값을 반환함
- 따라서 scoring 파라미터로 사용할 때와 평가 함수로 사용할 때는 해석 방식이 다르므로 주의해야 함
LinearRegression을 이용해 보스턴 주택 가격 회귀 구현
- Linear Regression 클래스를 이용해 선형 회귀 모델을 만들기
- 이킷런에 내장된 데이터 세트인 보스턴 주택 가격 데이터를 이용함

- 사이킷런은 보스턴 주택 가격 데이터 세트를 --
load_boston()을 통해 제공 - 해당 데이터 세트를 로드하고 DataFrame으로 변경
사이킷런 버전 문제로 인해 내장된 데이터를 사용할 수 없게 되어서 수동 로드 방식으로 해결할 수 있음
# 보스턴 데이터 수동 로드
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 데이터프레임 구성
bostonDF = pd.DataFrame(data, columns=[
'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE',
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'
])
bostonDF['PRICE'] = target
print('Boston 데이터 세트 크기 :', bostonDF.shape)
bostonDF.head()- 데이터 세트 피처의 Null 값은 없으며 모두 float 형임 → bostonDF.info()로 확인 가능
- RM, ZN, INDUS, NOX, AGE, PTRATIO, LSTAT, RAD의 8개 칼럼에 대해 값 증가에 따라 PRICE가 어떻게 변하는지 확인
- seaborn의 regplot() 함수: X, Y 산점도 + 선형 회귀선 제공
- matplotlib.subplots() 사용: 여러 그래프를 한 번에 표현
ncols: 열 방향 그래프 개수
nrows: 행 방향 그래프 개수
ncols=4, nrows=2이면 총 8개 그래프를 행·열 방향으로 표현 가능
import matplotlib.pyplot as plt
import seaborn as sns
# 2x4 서브플롯 생성
fig, axs = plt.subplots(figsize=(16, 8), ncols=4, nrows=2)
lm_features = ['RM', 'ZN', 'INDUS', 'NOX', 'AGE', 'PTRATIO', 'LSTAT', 'RAD']
for i, feature in enumerate(lm_features):
row = i // 4 # 행 번호 계산
col = i % 4 # 열 번호 계산
sns.regplot(x=feature, y='PRICE', data=bostonDF, ax=axs[row][col])
axs[row][col].set_title(f'{feature} vs PRICE')
plt.tight_layout()
plt.show()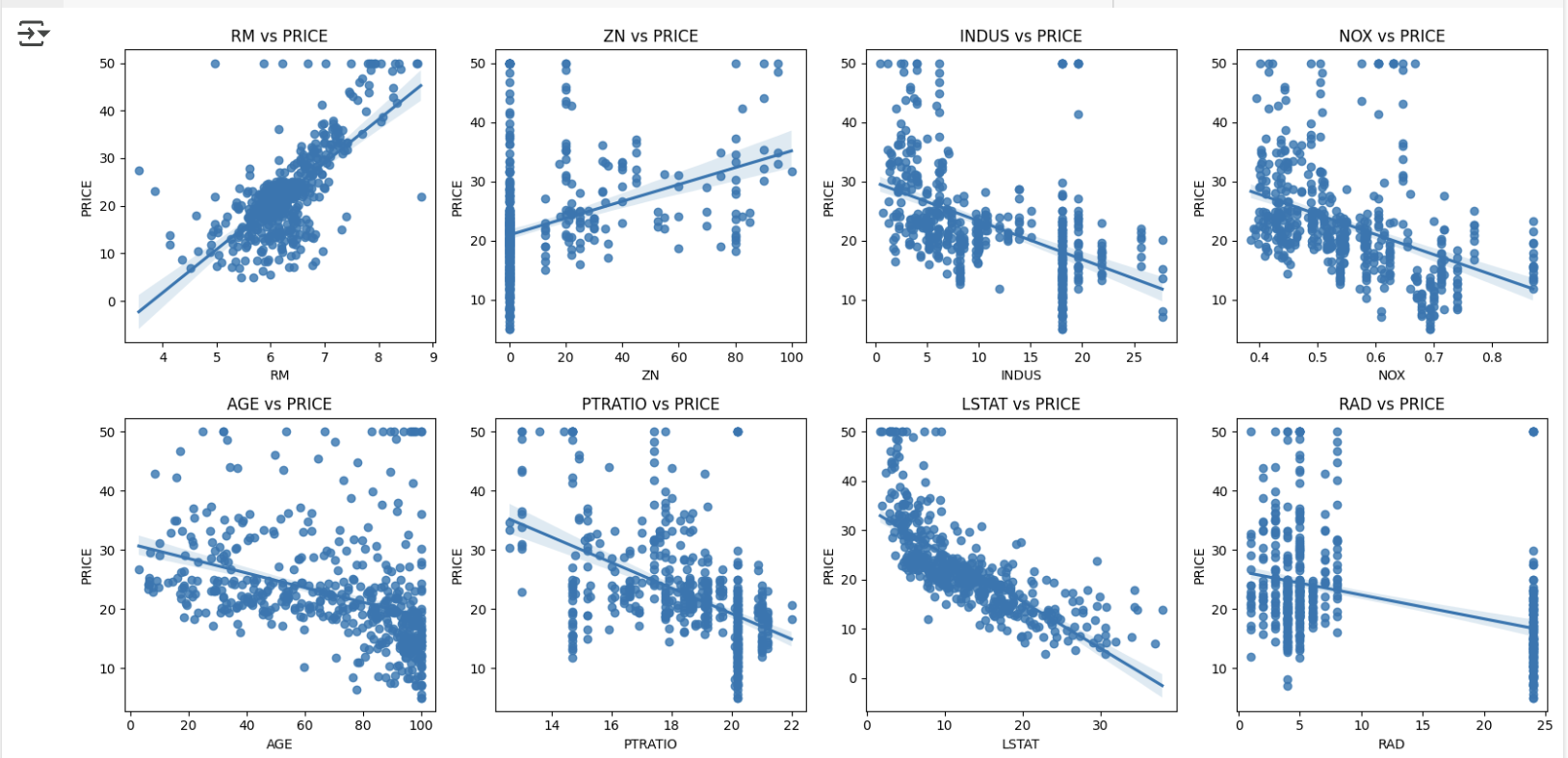
- RM과 LSTAT 칼럼이 PRICE에 가장 큰 영향
- RM(방 개수): 양의 선형성 → 방 수 증가 시 가격도 증가
- LSTAT(하위 계층 비율): 음의 선형성 → 비율 낮을수록 가격 증가
- LinearRegression 클래스를 이용해 보스턴 주택 가격 회귀 모델 생성
- train_test_split() 함수로 학습/테스트 데이터 분리
- metrics 모듈의 mean_squared_error()와 r2_score()로 MSE, R2 점수 측정
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'], axis=1, inplace=False)
# Correct the assignment order of y_train and y_test
X_train, X_test, y_train, y_test = train_test_split(X_data, y_target, test_size=0.3, random_state=156)
# Continue with training the model
lr = LinearRegression()
lr.fit(X_train, y_train)
y_preds = lr.predict(X_test)
mse = mean_squared_error(y_test, y_preds)
rmse = np.sqrt(mse)
print('MSE : {0:.3f}, RMSE : {1:.3F}'.format(mse, rmse))
print('Variance score : {0:.3f}'.format(r2_score(y_test, y_preds)))
- LinearRegression으로 생성한 주택가격 모델의 intercept(절편)과 coefficients(회귀 계수) 값을 보겠
습니다. - 절편은 LinearRegression 객체의 intercept 속성에 , 회귀 계수는 coef 속성에 값이 저장되어 있음
print('절편 값:', lr.intercept_)
print('회귀 계수값 :', np.round(lr.coef_, 1))
- coef_ 속성은 회귀 계수 값만 가지고 있으므로 이를 피처별 회귀 계수 값으로 다시 매핑하고 , 높은 값
순으로 출력해 보겠습니다. - 이를 위해 판다스 Series 의 sort_values() 함수를 이용
# 회귀 계수를 큰 값 순으로 정렬하기 위해 Series로 생성. 인덱스 칼럼명에 유의
coeff = pd.Series(data=np.round(lr.coef_, 1), index=X_data.columns )
coeff.sort_values(ascending=False)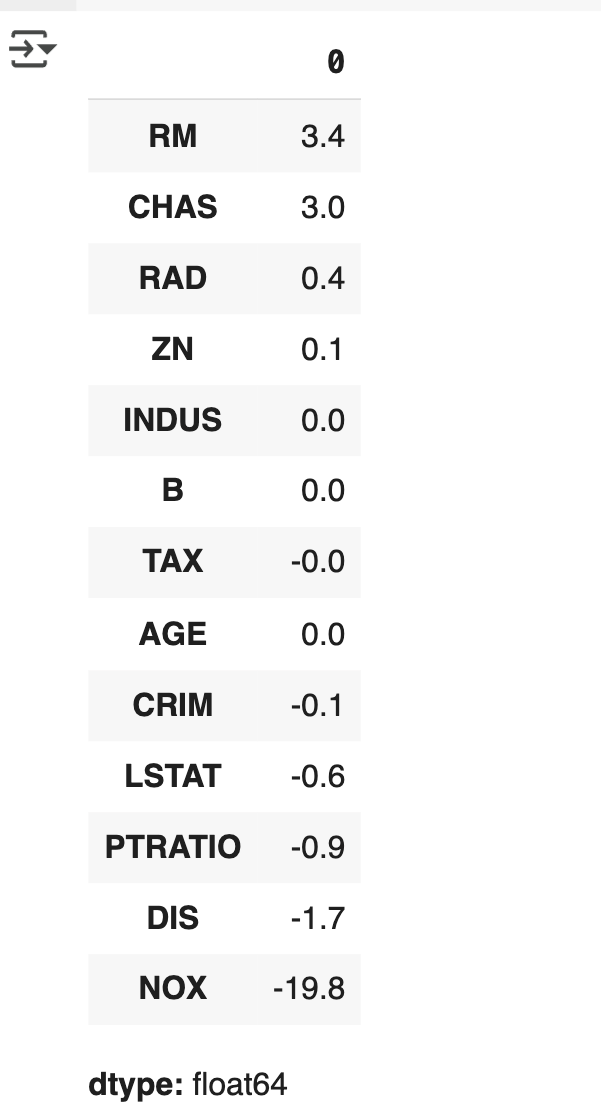
- RM 피처는 양의 회귀 계수로 가장 큰 영향
- NOX 피처는 음의 회귀 계수를 가짐
- 회귀 수행 시 피처의 계수 변화도 함께 확인
- cross_val_score()로 5개의 폴드 세트에 대한 교차 검증 수행
- scoring='neg_mean_squared_error' 지정 시 음수로 반환
- 반환된 음수에 (-1을 곱해서 MSE로 복원, 이후 np.sqrt()로 RMSE 계산
from sklearn.model_selection import cross_val_score
y_target = bostonDF ['PRICE']
X_data = bostonDF .drop([ 'PRICE'], axis=1, inplace=False)
lr = LinearRegression()
#Cross_val_score()로 5 폴드 세트로 MSE 를 구한 뒤 이를 기반으로 다시 RMSE 구함.
neg_mse_scores = cross_val_score(lr, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean (rmse_scores)
# cross_val_score(scoring="neg_mean_squared_error")로 반환된 값은 모두 음수
print(' 5 folds 의 개별 Negative MSE scores: ', np.round (neg_mse_scores, 2))
print(' 5 folds 의 개별 RMSE scores :' , np.round(rmse_scores, 2))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
5 개 폴드 세트에 대해서 교차 검증을 수행한 결과 , 평균 RMSE 는 약 5.829 가 나왔습니다. cross_val_score (scoring="neg_mean_squared_error")로 반환된 값을 확인해 보면 모두 음수임을 알 수 있음
5. 다항 회귀와 과 ( 대 ) 적합 / 과소적합 이해
다항 회귀 이해
- 회귀가 독립변수의 단항식이 아닌 2 차 , 3 차 방정식과 같은 다항식으로 표현되는 것을 다항 (Polynomial) 회귀라고 함
- 다항 회귀는 선형 회귀라는 점에 주의해야 함
- 회귀에서 선형 회귀 / 비선형 회귀를 나누는 기준은 회귀 계수가 선형 / 비선형인지에 따른 것이지 독
립변수의 선형 / 비선형 여부와는 무관
식을 새로운 변수인 Z 를 로 한다면
같이 표현할 수 있기에 여전히 선형 회귀임
아래 그림을 보면 데이터 세트에 대해서 피처 X 에 대해 Target Y 값의 관계를 단순 선형 회귀 직선형으로 표현한 것보다 다항 회귀 곡선형으로 표현한 것이 더 예측 성능이 높음
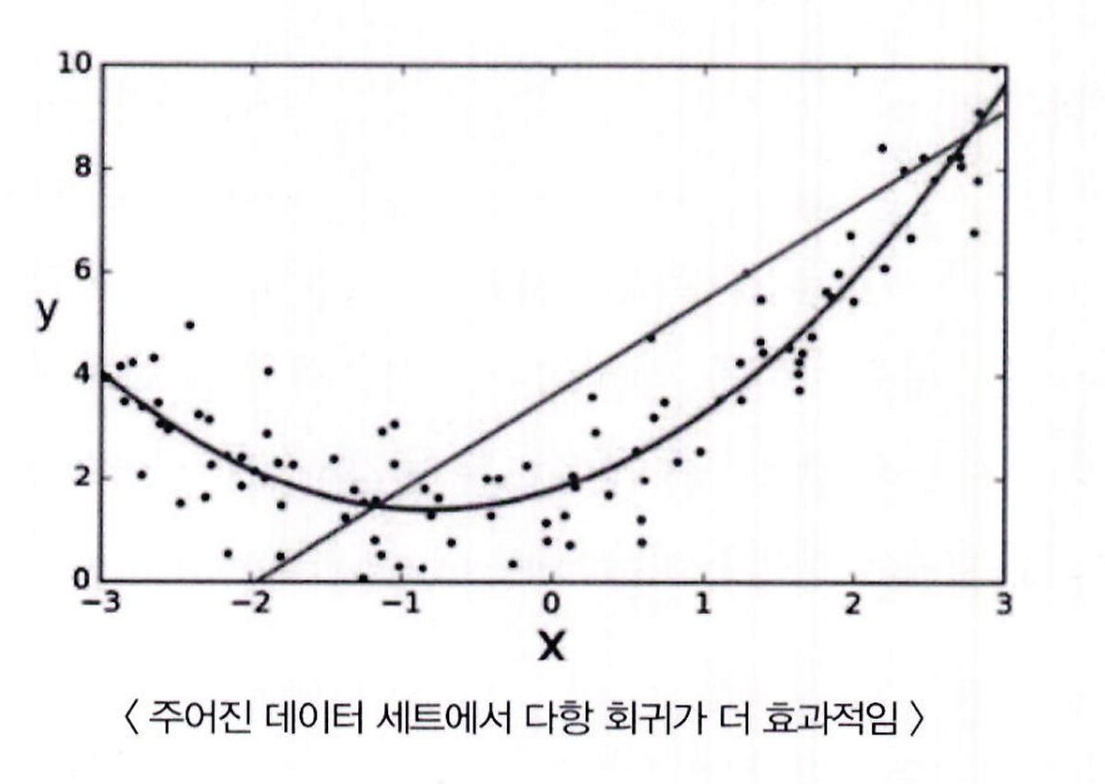
BUT 이킷런은 다항 회귀를 위한 클래스를 명시적으로 제공하지 않음
- 대신 다항 회귀 역시 선형 회귀이기 때문에 비선형 함수를 선형 모델에 적용시키는 방법을 사용해 구현
- 사이킷런은 PolynomialFeatures 클래스를 통해 피처를 Polynomial(다항식) 피처로 변환
- PolynomialFeatures 클래스는 degree 파라미터를 통해 입력받은 단항식 피처를 degree 에 해당하는 다항식 피처로 변환
- 다른 전처리 변환 클래스와 마찬가지로 PolynomialFeatures 클래스는 fit(),
transform() 메서드를 통해 이 같은 변환 작업을 수행
PolynomialFeatures
를 2 차 다항값으로
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
# 다항식으로 변환한 단식 생성 , [[0, 11, [2, 3] 의 2X2 행렬 생성
X = np.arange(4).reshape(2, 2)
print('일차 단항식 계수 피처 :1\n', X )
# degree = 2 인 2차 다항식으로 변환하기 위해 PolynomialFeatures를 이용해 변환
poly = PolynomialFeatures (degree=2)
poly.fit (X)
poly_ftr = poly.transform(X)
print('변환된 2 차 다항식 계수 피처 :\n', poly_ftr)
def polynomial_func(X):
y = 1 + 2*X[:,0] + 3*X[:,0]**2 + 4*X[:,1]**3
return y
X = np.arange(4).reshape(2, 2)
print('일차 단항식 계수 feature: \n', X)
y = polynomial_func(X)
print('삼차 다항식 결정값 : \n', y)

- 이제 일차 단항식 계수를 삼차 다항식 계수로 변환하고 , 이를 선형 회귀에 적용하면 다항 회귀로 구현됨.
- PolynomialFeatures(degree=3) 은 단항 계수 피처 를 3 차 다항 계수 10 개의 다항 계수로 변환
# 3 차 다항식 변환
from sklearn.linear_model import LinearRegression # Import LinearRegression
poly_ftr = PolynomialFeatures (degree=3).fit_transform(X)
print('3차 다항식 계수 feature: \n',poly_ftr)
# Linear Regression 에 3 차 다항식 계수 feature와 3 차 다항식 결정값으로 학습 후 회귀 계수 확인
model = LinearRegression()
model.fit(poly_ftr,y)
print('Polynomial 회귀 계수 In' , np.round(model.coef_, 2))
print('Polynomial 회귀 Shape :' , model.coef_.shape)
- 일차 단항식의 피처 수는 2개였으나,
→ 3차 다항식 Polynomial 변환 후 피처 수는 10개로 증가 - LinearRegression을 적용한 결과,
→ 회귀 계수 10개: [1.0, 0.18, 0.18, 0.36, 0.54, 0.72, 0.72, 1.08, 1.62, 2.34] - 원래 다항식 1 + 2x + 3x² + 4x³의 계수 [1, 2, 0, 3, 0, 0, 0, 0, 0, 4] 와는 차이가 있음
→ 하지만 다항 회귀로 근사하고 있음을 알 수 있음 - 사이킷런은 PolynomialFeatures로 피처 확장 후 LinearRegression으로 다항 회귀 구현
- 별도로 적용하는 것보다, Pipeline 객체를 이용하면 코드가 더 명료하게 작성 가능
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
def polynomial_func(X):
y = 1 + 2*X[:,0] + 3*X[:,0]**2 + 4*X[:,1]**3
return y
# Pipeline 객체로 Streamline하게 Polynomial Feature 변환과 Linear Regression을 연결
model = Pipeline([('poly', PolynomialFeatures (degree=3)),
('linear', LinearRegression())])
X = np.arange(4).reshape (2,2)
y = polynomial_func(X)
model = model. fit(X, y)
print('Polynomial 회귀 횟수 \n', np.round(model.named_steps['linear'].coef_, 2))
다항 회귀를 이용한 과소적합 및 과적합 이해
- 다항 회귀는 직선적 관계가 아닌 복잡한 다항 관계를 모델링할 수 있음
- 차수가 높을수록 더 복잡한 관계까지 모델링 가능하지만,
→ 과적합(overfitting) 문제 발생 가능 - 학습 데이터에 과도하게 맞춰져 테스트 데이터의 예측 정확도 저하
학습 데이터는 30 개의 임의의 데이터인 X, 그리고 X 의 코사인 값에서 약간의 잡음 변동 값을 더한 target 인 y 로 구성됨
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn. linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
%matplotlib inline
# 임의의 값으로 구성된 X 값에 대해 코사인 변환 값을 반환.
def true_fun(X):
return np.cos (1.5 * np.pi * X)
# X 는 0 부터 1 까지 30 개의 임의의 값을 순서대로 샘플링한 데이터입니다.
np.random.seed (0)
n_samples = 30
X = np.sort(np.random.rand(n_samples))
#y 값은 코사인 기반의 true_fun()에서 약간의 노이즈 변동 값을 더한 값입니다.
y = true_fun(X) + np.random.randn(n_samples) * 0.1- 예측 결과를 비교할 다항식 차수를 각 1, 4, 15 로 변경하면서 예측 결과를 비교
- 다항식 차수별로 학습을 수행한 뒤 cross_val_score()로 MSE 값을 구해 차수별 예측 성능을 평가
- 0 부터 1 까지 균일하게 구성된 100 개의 테스트용 데이터 세트를 이용해 차수별 회귀 예측 곡선
plt.figure(figsize=(14, 5))
degrees = [1, 4, 15]
# 다항 회귀의 차수를 1, 4, 15로 변화시키며 비교
for i in range(len(degrees)):
ax = plt.subplot(1, len(degrees), i + 1)
plt.setp(ax, xticks=(), yticks=())
# 개별 degree 별로 Polynomial 변환
polynomial_features = PolynomialFeatures(degree=degrees[i], include_bias=False)
linear_regression = LinearRegression()
pipeline = Pipeline([
("polynomial_features", polynomial_features),
("linear_regression", linear_regression)
])
pipeline.fit(X.reshape(-1, 1), y)
# 교차 검증으로 다항 회귀 평가
scores = cross_val_score(pipeline, X.reshape(-1, 1), y,
scoring="neg_mean_squared_error", cv=10)
# 회귀 계수 출력
coefficients = pipeline.named_steps['linear_regression'].coef_
print('Degree {} 회귀 계수는 {} 입니다.'.format(degrees[i], np.round(coefficients, 2)))
print('Degree {} MSE = {:.4f}'.format(degrees[i], -scores.mean()))
# 예측 시각화
X_test = np.linspace(0, 1, 100)
plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model")
plt.plot(X_test, true_fun(X_test), '-', label="True function")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.xlabel("x"); plt.ylabel("y")
plt.xlim((0, 1)); plt.ylim((-2, 2))
plt.legend(loc="best")
plt.title("Degree {}\nMSE = {:.2e} (+/- {:.2e})".format(
degrees[i], -scores.mean(), scores.std()))
plt.show()
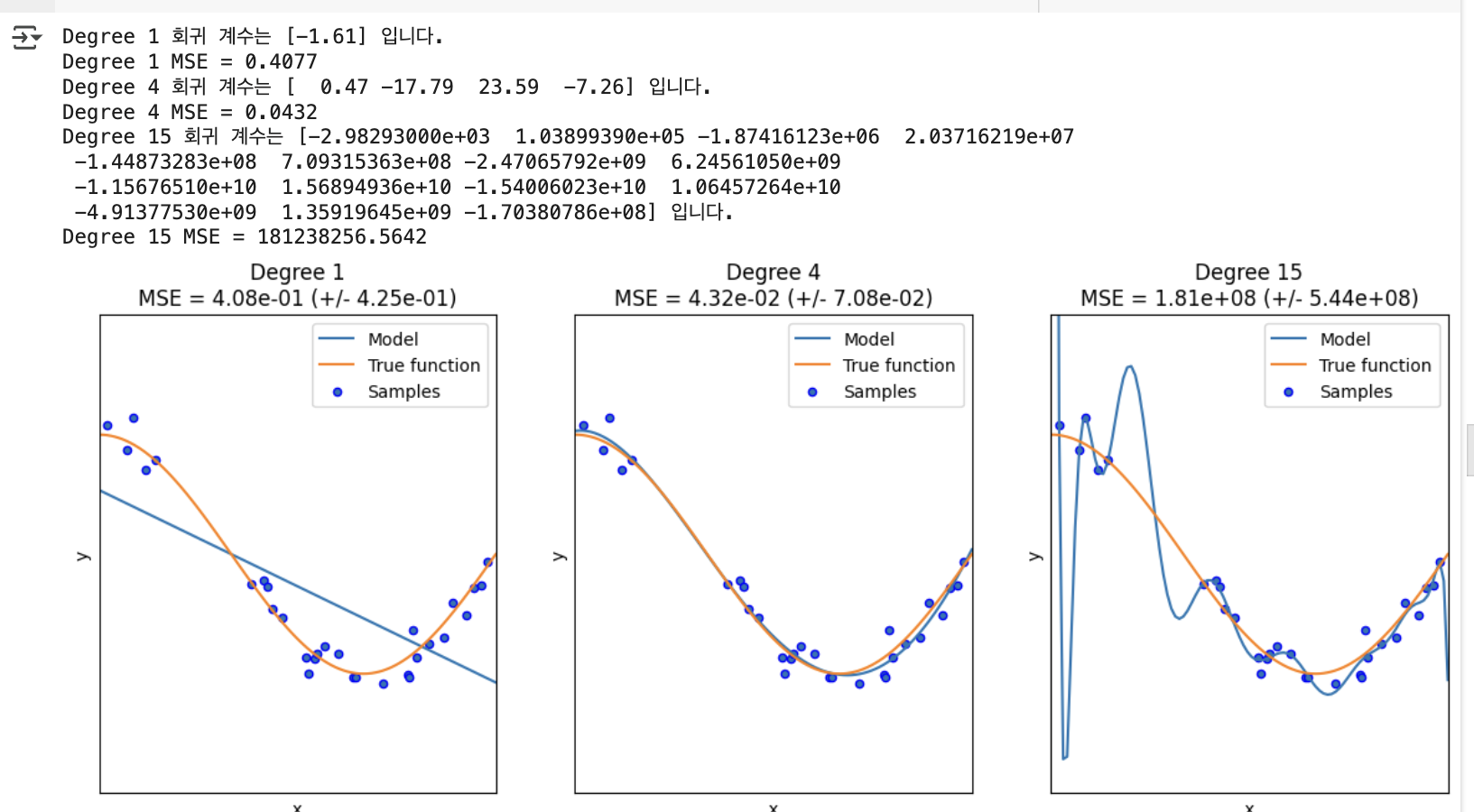
- 실선: 다항 회귀 모델이 예측한 곡선
- 점선: 실제 데이터의 코사인 함수 곡선 (정답 곡선)
학습 데이터 구성:
- X: 0부터 1 사이의 30개 임의 값
- Y: 해당 X에 대한 코사인 값 + 잡음(Noise) 추가
평가 방법:
- MSE (평균 제곱 오차)
- 10개 교차 검증 세트로 나누어 측정 후 평균
Degree 1 (좌측):
- 단순 선형 회귀 형태 (직선)
- 실제 코사인 곡선을 잘 반영하지 못함 → 과소적합
- MSE ≈ 0.41
Degree 4 (중앙):
- 실제 데이터와 유사한 곡선
- 잡음은 반영 못했지만 테스트 데이터까지 잘 예측
- MSE ≈ 0.04 (가장 우수한 성능)
Degree 15 (우측):
- 데이터의 잡음까지 지나치게 반영 → 과적합
- 테스트 곡선과는 동떨어진 곡선
- MSE ≈ 182581084.83 (매우 높은 오류)
Degree 15 회귀 계수:
- [-2.98300000e+03, 1.03900000e+05] 등 매우 큰 값
- 모델이 과하게 복잡한 다항식을 만족시키기 위해 비정상적으로 커진 계수
문제점:
- 현실과 동떨어진 예측 결과
- 학습 데이터의 모든 패턴을 반영하려다 과적합 발생
결론: 좋은 예측 모델은
- Degree 1처럼 과소적합도 아니고 Degree 15처럼 과적합도 아님
- 학습 데이터를 잘 반영하면서 복잡하지 않은 균형 잡힌 모델이 이상적
편향 분산 트레이드오프(Bias-Variance Trade off)
- 편향-분산 트레이드오프는 머신러닝 모델의 일반화 능력에 가장 중요한 이슈 중 하나
- 모델이 너무 단순하면 고편향(High Bias) → 과소적합
- 모델이 너무 복잡하면 고분산(High Variance) → 과적합
Degree 1 모델:
- 고편향 / 저분산
- 학습 데이터의 특성을 반영하지 못하고, 단순한 예측만 수행함
Degree 15 모델:
- 저편향 / 고분산
- 학습 데이터를 지나치게 반영해, 테스트 데이터에서 성능 저하
양궁 과녁 비유:
-
Low Bias / Low Variance (최적): 예측값이 정확하고 분산이 적음
-
Low Bias / High Variance: 정확하지만 예측값이 흩어져 있음
-
High Bias / Low Variance: 부정확하지만 일정한 위치에 예측값이 몰림
-
High Bias / High Variance: 부정확하고 예측값도 퍼져 있음
-
최적 모델은 편향과 분산 사이의 균형(Balanced Trade-off)이 필요함
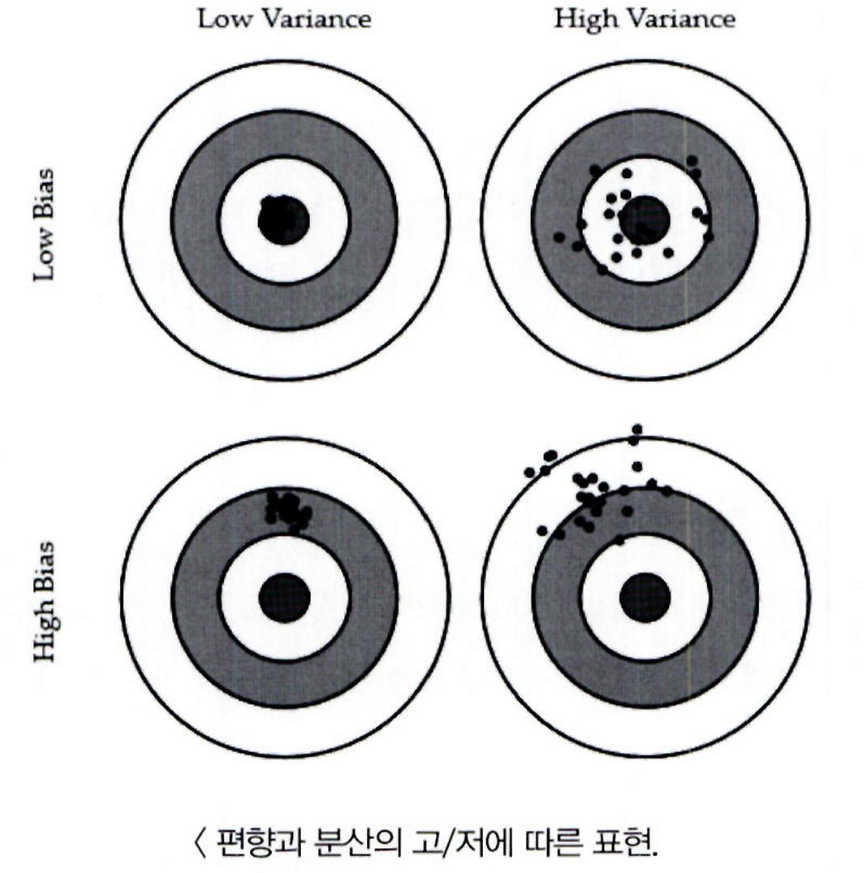
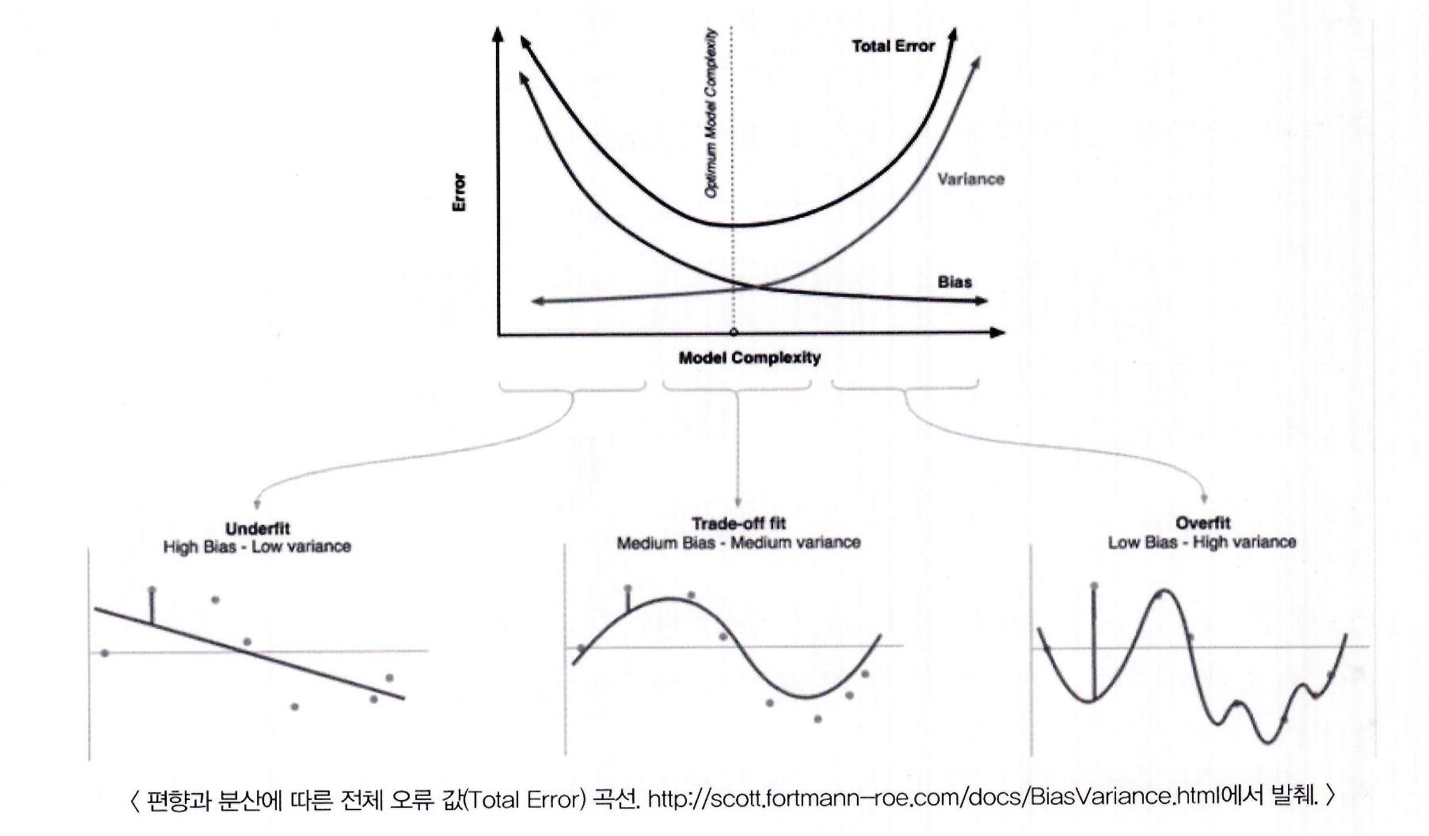
-
높은 편향 / 낮은 분산에서 과소적합되기 쉬우며 낮은 편향 / 높은 분산에서 과적합되기 쉬움
-
편향과 분산이 서로 트레이드오프를 이루면서 오류 Cost 값이 최대로 낮아지는 모델을 구축하는 것이 가장 효율적인 머신러닝 예측 모델을 만드는 방법임.
6. 규제 선형 모델 - 릿지 , 라쏘 , 엘라스틱넷
규제 선형 모델의 개요
좋은 머신러닝 회귀 모델
과소적합을 피해야 함
- 모델이 지나치게 단순하여 데이터의 패턴을 충분히 반영하지 못하면 성능이 낮음
- 예: 다항 회귀에서 Degree가 1인 경우
과적합을 방지해야 함
- 모델이 학습 데이터에 너무 맞춰져 일반화 성능이 떨어짐
- 예: Degree가 15인 경우, 회귀 계수가 과도하게 커짐
적절한 복잡도 유지 - 학습 데이터에 잘 맞추되, 테스트 데이터에서도 예측력이 유지되어야 함
- 이를 위해 회귀 계수의 크기를 제어하는 규제(Regularization)가 필요
좋은 회귀 모델은 다음을 동시에 만족해야 함
- 실제 값과 예측값의 차이를 줄이는 것 (RSS 최소화)
- 회귀 계수가 과도하게 커지지 않도록 제어하는 것 (규제항 포함)
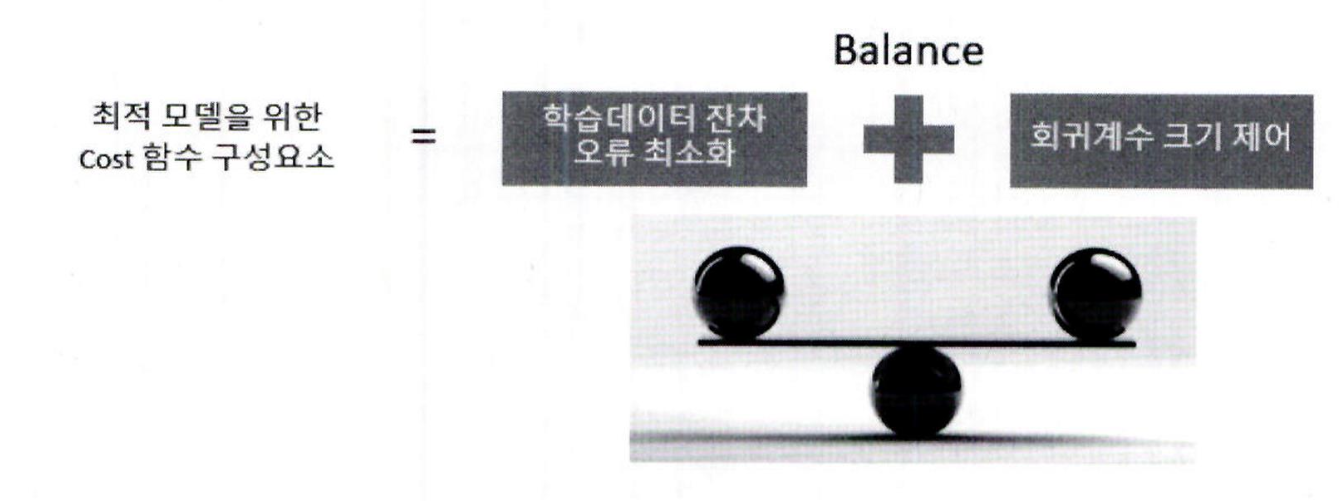
alpha가 0일 때:
- 규제가 없는 기존 선형 회귀와 같음
- 학습 데이터에 더 잘 맞추지만 과적합 위험 증가
alpha가 클 때:
- 회귀 계수 W의 크기를 줄여 모델 복잡도 감소
- 과적합 완화 효과, 하지만 과소적합 가능성 있음
- 적절한 alpha 값 선택은 모델이 학습 데이터에 적절히 적합하면서도,
일반화 성능을 유지하도록 돕는 핵심 요소입니다.

규제(Regularization)는 과적합을 줄이기 위해 회귀 계수(W)의 크기에 페널티를 부여하는 방법입니다.
- alpha 값을 증가시키면 회귀 계수의 크기가 줄어들고, 모델 복잡도는 감소.
규제에는 L2 방식과 L1 방식이 있습니다:
- L2 규제 (Ridge 회귀):
회귀 계수 전체를 작게 만듦 (0은 아님)
- L1 규제 (Lasso 회귀):
영향력이 적은 회귀 계수는 완전히 0으로 만듦 → 특성 선택 효과
릿지 회귀
- Ridge 클래스를 통해 릿지 회귀를 구현
- Ridge 클래스의 주요 생성 파라미터는 alpha 이며 , 이는 릿지 회귀의 alpha L2 규제 계수에 해당합니다. 앞 예제의 보스턴 주택 가격을 Ridge 클래스를 이용해 다시 예측하고 , 예측 성능을 cross_Val_score( ) 로 평가해 보겠습니다.
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# alpha=10 으로 설정해 릿지 회귀 수행.
ridge = Ridge(alpha=10)
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv=5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 3))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores, 3))
print(' 5 folds 의 평균 RMSE : {0:.3f}'.format(avg_rmse))

- 릿지 회귀의 5 폴드 평균 RMSE는 5.518로, 규제 없이 학습한 선형 회귀(RMSE 5.829)보다 성능이 우수함.
- alpha 값을 0, 0.1, 1, 10, 100으로 바꿔가며 RMSE와 회귀 계수의 변화를 관찰함.
결과적으로:
- alpha 값이 커질수록 회귀 계수의 절댓값이 작아짐 → 모델이 단순해지고 과적합 방지
- alpha = 0일 경우는 규제가 없는 선형 회귀와 동일
- alpha에 따른 RMSE와 회귀 계수를 시각화하고 DataFrame에 저장함.
# 릿지에 사용될 alpha 파라미터의 값을 정의
alphas = [0, 0.1, 1, 10, 100]
# alphas list 값을 반복하면서 alpha 에 따른 평균 rmse 를 구함.
for alpha in alphas :
ridge = Ridge (alpha = alpha)
#cross_val_score를 이용해 5 폴드의 평균 RMSE 를 계산
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores))
print('alpha {0} 일 때 5 folds 의 평균 RMSE : {1:.3f} '.format(alpha, avg_rmse))
- alpha = 100일 때 평균 RMSE가 5.330으로 가장 우수한 성능을 보임.
- Ridge 객체의 coef_ 속성을 이용해 피처별 회귀 계수를 추출함.
- 회귀 계수 값을 Series 객체로 변환하여 Seaborn의 가로 막대 그래프로 시각화.
- 각 alpha 값에 따른 회귀 계수를 DataFrame에 저장하여 비교 가능하게 정리함.
# 각 alpha 에 따른 회귀 계수 값을 시각화하기 위해 5 개의 열로 된 맷플롯립 축 생성
fig, axs = plt.subplots(figsize=(18, 6), nrows=1, ncols=5)
# 각 alpha에 따른 회귀 계수 값을 데이터로 저장하기 위한 Dataframe 생성
coeff_df = pd.DataFrame()
# alphas 리스트 값을 차례로 입력해 회귀 계수 값 시각화 및 데이터 저장. pos 는 axis의 위치 지정
for pos, alpha in enumerate(alphas) :
ridge = Ridge(alpha = alpha)
ridge.fit(X_data, y_target)
# alpha에 따른 피처별로 회귀 계수를 Series로 변환하고 이를 DataFrame 의 칼럼으로 추가.
coeff = pd.Series(data=ridge.coef_, index=X_data.columns )
colname='alpha: '+str(alpha)
coeff_df [colname] = coeff
# 막대 그래프로 각 alpha 값에서의 회귀 계수를 시각화. 회귀 계수값이 높은 순으로 표현
coeff = coeff.sort_values(ascending=False)
axs[pos]. set_title(colname)
axs[pos].set_xlim(-3, 6)
sns.barplot(x=coeff.values, y=coeff.index, ax=axs[pos])
# for 문 바깥에서 맷플롯립의 Show 호출 및 alpha 에 따른 피처별 회귀 계수를 DataFrame으로 표시
plt.show()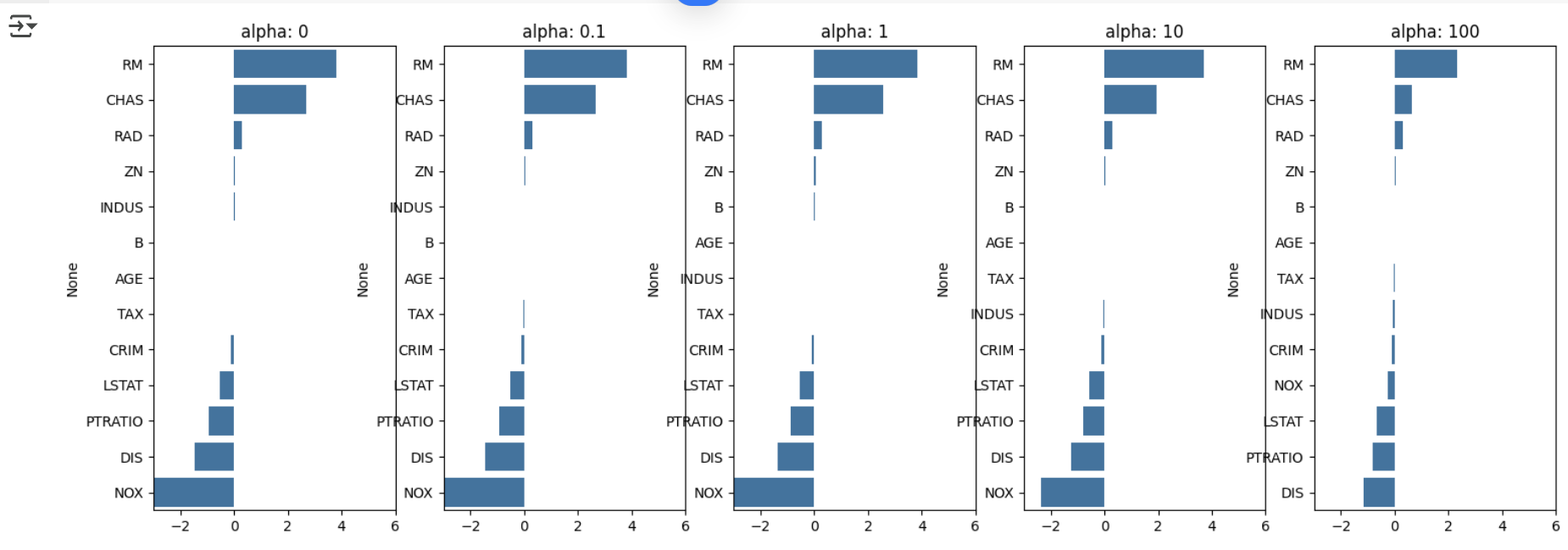
- alpha 값을 계속 증가시킬수록 회귀 계수 값은 지속적으로 작아짐을 알 수 있음
- 특히 NOX 피처의 경우 alpha 값을 계속 증가시킴에 따라 회귀 계수가 크게 작아짐
- DataFrame 에 저장된 alpha 값의 변화에 따른 릿지 회귀 계수 값을 구함
ridge_alphas = [0, 0.1, 1, 10, 100]
sort_column = 'alpha: '+str(ridge_alphas [0])
coeff_df.sort_values(by=sort_column, ascending=False)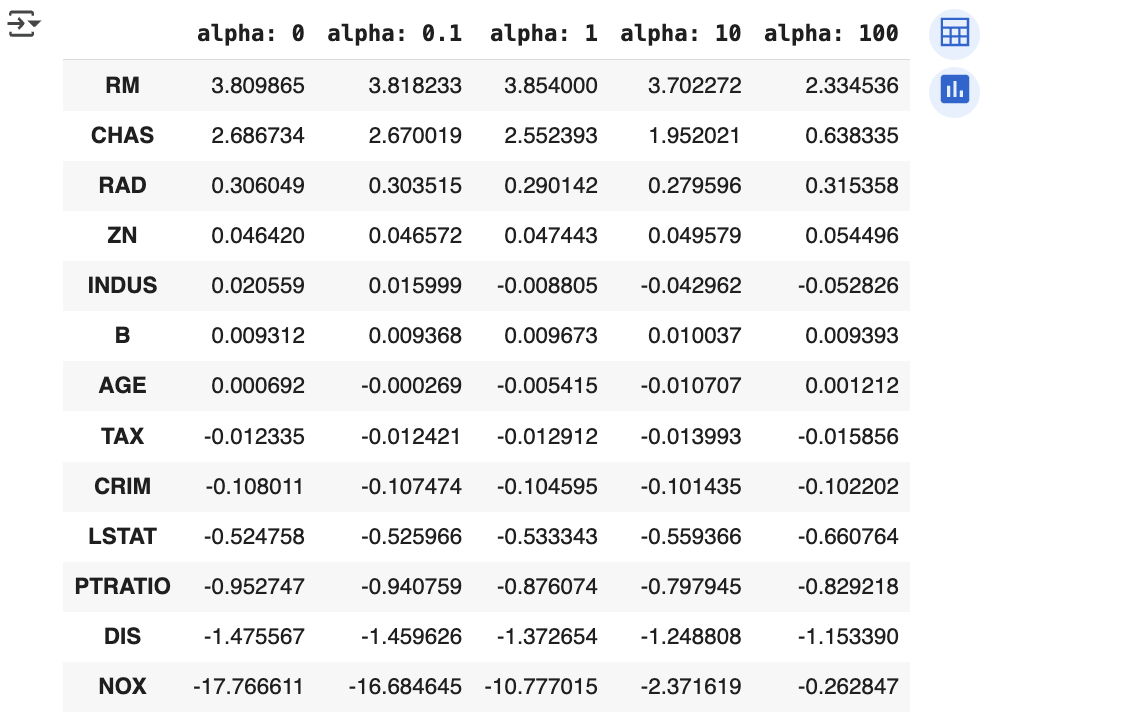
alpha 값이 증가하면서 회귀 계수가 지속적으로 작아지고 있음을 알 수 있습니다. 하지만 릿지 회귀의 경우에는 회귀 계수를 0 으로 만들지는 않음
라쏘 회귀
- W 의 절댓값에 페널티를 부여하는 LI 규제를 선형 회귀에 적용한 것이 라쏘 (Lasso) 회귀
사이킷런의 Lasso 클래스는 L1 규제 기반의 라쏘 회귀를 구현함. - alpha 파라미터는 규제 강도를 결정하는 핵심 하이퍼파라미터임.
- 릿지 회귀와 유사하게 alpha 값을 변화시키며 RMSE와 회귀 계수의 변화를 분석.
- get_linear_reg_eval() 함수는 회귀 모델명, alpha 리스트, 피처 및 타깃 데이터를 인자로 받아,
- 각 alpha에 따른 폴드 평균 RMSE를 출력하고, 회귀 계수들을 DataFrame으로 반환함.
# 라쏘에 사용될 alpha 파라미터의 값을 정의하고 get_linear_reg_eval() 함수 호출
lasso_alphas = [0.07, 0.1, 0.5, 1, 3]
coeff_lasso_df = get_linear_reg_eval(
'Lasso',
params=lasso_alphas,
X_data_n=X_data,
_target_n=y_target # ← 여기 이름 맞춰야 함
)
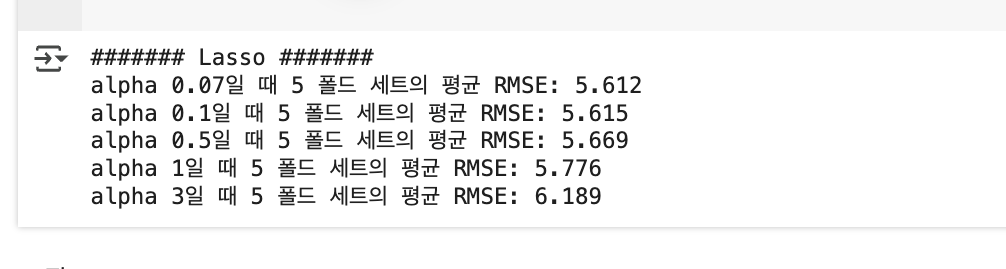
- alpha 가 0.07 일 때 5.612 로 가장 좋은 평균 RMSE 를 보여줍니다. 앞의 릿지 평균 5.518 보다는 약간 떨어지는 수치지만 , LinearRegression 평균인 5.829 보다는 향상됐습니다.
alpha 값에 따른 피처별 회귀 계수
# 반환된 coeff_lasso_df를 첫 번째 칼럼순으로 내림차순 정렬해 회귀계수 DataFrame 출력
sort_column = 'alpha: '+str(lasso_alphas[0])
coeff_lasso_df. sort_values(by=sort_column, ascending=False)- alpha 의 크기가 증가함에 따라 일부 피처의 회귀 계수는 아예 0 으로 바뀌고 있음.
- NOX 속성은 alpha 가 0.07 일 때부터 회귀 계수가 0 이며 , alpha 를 증가시키면서 INDUS, CHAS 와 같은 속성의 회귀 계수가 0 으로 바뀝니다. 회귀 계수가 0 인 피처는 회귀 식에서 제외되면서 피처 선택의 효과를 얻을 수 있음
엘라스틱넷 회귀
- 사이킷런의 Lasso 클래스는 L1 규제 기반의 라쏘 회귀를 구현함.
- alpha 파라미터는 규제 강도를 결정하는 핵심 하이퍼파라미터임.
- 릿지 회귀와 유사하게 alpha 값을 변화시키며 RMSE와 회귀 계수의 변화를 분석.
- get_linear_reg_eval() 함수는 회귀 모델명, alpha 리스트, 피처 및 타깃 데이터를 인자로 받아,
- 각 alpha에 따른 폴드 평균 RMSE를 출력하고, 회귀 계수들을 DataFrame으로 반환함.
# ElasticNet에 사용될 alpha 파라미터 값들을 정의하고 get_linear_reg_eval() 함수 호출
# l1_ratio는 0.7로 고정
elastic_alphas = [0.07, 0.1, 0.5, 1, 3]
coeff_elastic_df = get_linear_reg_eval('ElasticNet',
params=elastic_alphas,
X_data_n=X_data, _target_n=y_target) 
# 반환된 coeff_elastic_df를 첫 번째 칼럼순으로 내림차순 정렬해 회귀계수 DataFrame 출력
sort_column = 'alpha: '+str(elastic_alphas[0])
coeff_elastic_df.sort_values(by=sort_column, ascending=False)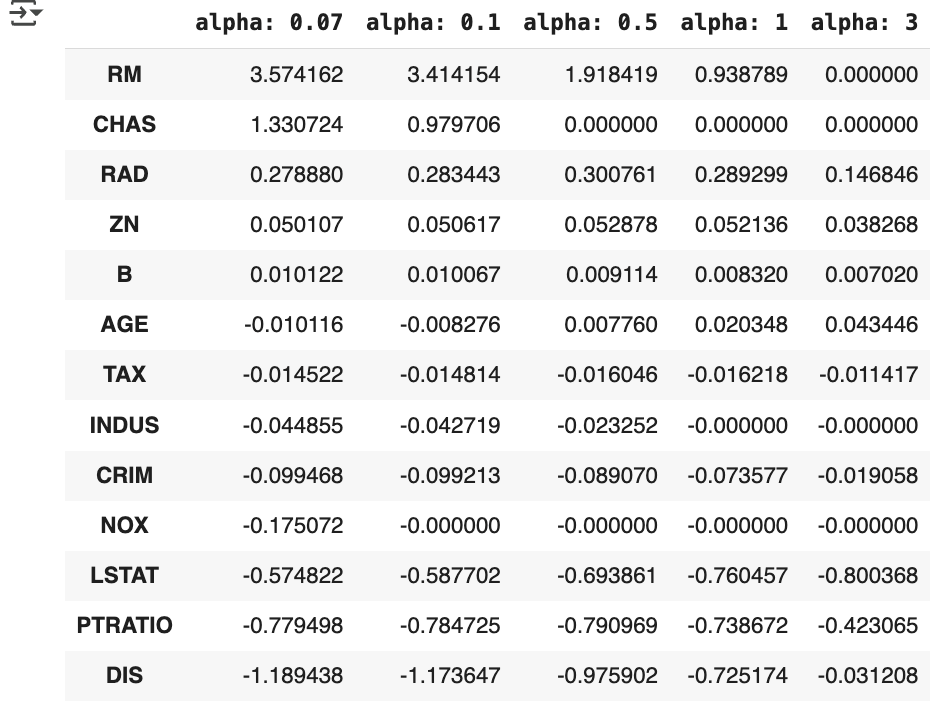
- Lasso 회귀에서 alpha = 0.5일 때 RMSE = 5.467로 가장 좋은 예측 성능을 보임.
- Lasso보다 ElasticNet은 회귀 계수가 0이 되는 피처가 적음.
- Ridge, Lasso, ElasticNet은 상황에 따라 성능이 다르므로, 각 하이퍼파라미터를 조정해 최적의 성능을 찾아야 함.
- 특히 선형 회귀에서는 하이퍼파라미터 조정 외에도, 데이터 정규화와 인코딩 방법이 예측 성능에 중요한 영향을 미침.
선형 회귀 모델을 위한 데이터 변환
- 선형 회귀 모델은 선형 관계 및 정규 분포 가정에 기반함.
- 특히 타깃값이 왜곡된 분포(skewed distribution)일 경우 예측 성능 저하 가능성 큼.
- 피처값이 왜곡되어 있어도 예측 성능에 부정적 영향 가능.
- 따라서 스케일링 / 정규화 작업이 중요하며, 일반적으로 다음 경우에 수행:
타깃값의 분포가 심하게 왜곡되었을 때
중요 피처들이 비정규 분포를 가질 때 - 모든 경우에 변환이 필요한 것은 아님 — 효과는 데이터에 따라 다름.
- StandardScaler 클래스를 이용해 평균이 0, 분산이 1 인 표준 정규 분포를 가진 데이터 세트로 변환하거나 MinMaxScaler 클래스를 이용해 최솟값이 0 이고 최댓값이 1 인 값으로 정규화를 수행합니다.
- 스케일링 / 정규화를 수행한 데이터 세트에 다시 다항 특성을 적용하여 변환하는 방법입니다. 보통 1 번 방법을 통해 예측 성능에 향상이 없을 경우 이와 같은 방법을 적용합니다.
- 원래 값에 1og 함수를 적용하면 보다 정규 분포에 가까운 형태로 값이 분포됩니다. 이러한 변환을 로그 변환 (Log Transformation) 이라고 부릅니다. 로그 변환은 매우 유용한 변환이며 , 실제로 선형 회귀에서는 앞에서 소개한 1, 2
번 방법보다 로그 변환이 훨씬 많이 사용되는 변환 방법입니다. 왜냐하면 1 번 방법의 경우 예측 성능 향상을 크게기대하기 어려운 경우가 많으며 2 번 방법의 경우 피처의 개수가 매우 많을 경우에는 다항 변환으로 생성되는 피처의 개수가 기하급수로 늘어나서 과적합의 이슈가 발생할 수 있기 때문입니다.
타깃값(log 변환):
- 타깃값이 왜곡된 분포를 가질 경우 로그 변환(log1p)을 적용하면 예측 성능이 향상되는 경우가 많음.
- log 변환은 정규 분포에 가깝게 변환함으로써 모델 성능 향상 기대 가능.
- log 함수 대신 np.log1p() 사용: log(x+1) 형태로, 0 값 처리 및 언더플로우 방지.
피처 변환 방법 3가지 (get_scaled_data() 함수 사용):
- Standard (표준 정규 분포 변환): 평균 0, 표준편차 1로 변환.
- MinMax (최댓값/최솟값 정규화): 모든 값이 0~1 범위 내에 위치하도록 조정.
- Log (로그 변환): 왜곡된 분포를 정규 분포에 가깝게 함.
- 다항식 차수는 2까지 제한하며, 과적합 방지를 위해 높은 차수는 피함.
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
import numpy as np
def get_scaled_data(method='None', P_degree=None, input_data=None):
if method == 'Standard':
scaled_data = StandardScaler().fit_transform(input_data)
elif method == 'MinMax':
scaled_data = MinMaxScaler().fit_transform(input_data)
elif method == 'Log':
scaled_data = np.log1p(input_data)
else:
scaled_data = input_data
if P_degree != None:
scaled_data = PolynomialFeatures(degree=P_degree, include_bias=False).fit_transform(scaled_data)
return scaled_data
- 다양한 피처 변환 방식(표준화, 정규화, 로그변환, 다항 변환 등)을 적용한 후
- Ridge 회귀 모델에 여러 alpha 값을 설정하여 예측 성능(RMSE)의 변화를 비교 분석함
- 목표: 변환 방식 + alpha 조합에 따라 Ridge 회귀 성능이 어떻게 달라지는지 확인
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
import numpy as np
import pandas as pd
# 스케일링 및 다항식 변환 함수
def get_scaled_data(method='None', P_degree=None, input_data=None):
if method == 'Standard':
scaled_data = StandardScaler().fit_transform(input_data)
elif method == 'MinMax':
scaled_data = MinMaxScaler().fit_transform(input_data)
elif method == 'Log':
scaled_data = np.log1p(input_data)
else:
scaled_data = input_data
if P_degree is not None:
scaled_data = PolynomialFeatures(degree=P_degree, include_bias=False).fit_transform(scaled_data)
return scaled_data
# 회귀 평가 함수
def get_linear_reg_eval(model_name, params, X_data_n, y_target, verbose=True, return_coeff=False):
results = []
for alpha in params:
if model_name == 'Ridge':
model = Ridge(alpha=alpha)
else:
raise ValueError("지원되지 않는 모델입니다.")
model.fit(X_data_n, y_target)
pred = model.predict(X_data_n)
rmse = np.sqrt(mean_squared_error(y_target, pred))
if verbose:
print(f'[Model: {model_name}] alpha: {alpha}, RMSE: {rmse:.4f}')
if return_coeff:
results.append((alpha, model.coef_))
if return_coeff:
return results
# 예시용 데이터 (원래는 X_data, y_target을 정의해야 함)
# 예시로 sklearn의 보스턴 주택 데이터 사용
from sklearn.datasets import load_diabetes
X_data, y_target = load_diabetes(return_X_y=True)
# Ridge의 alpha 값을 다르게 적용하고 다양한 데이터 변환 방법에 따른 RMSE 추출
alphas = [0.1, 1, 10, 100]
# 6개 방식으로 변환: 원본, 표준정규, 표준정규+다항식, MinMax, MinMax+다항식, 로그
scale_methods = [
(None, None),
('Standard', None),
('Standard', 2),
('MinMax', None),
('MinMax', 2),
('Log', None)
]
for scale_method in scale_methods:
X_data_scaled = get_scaled_data(method=scale_method[0], P_degree=scale_method[1],
input_data=X_data)
print('\n### Method: {}, Polynomial Degree: {}'.format(scale_method[0], scale_method[1]))
get_linear_reg_eval('Ridge',
params=alphas,
X_data_n=X_data_scaled,
y_target=y_target,
verbose=True,
return_coeff=False)
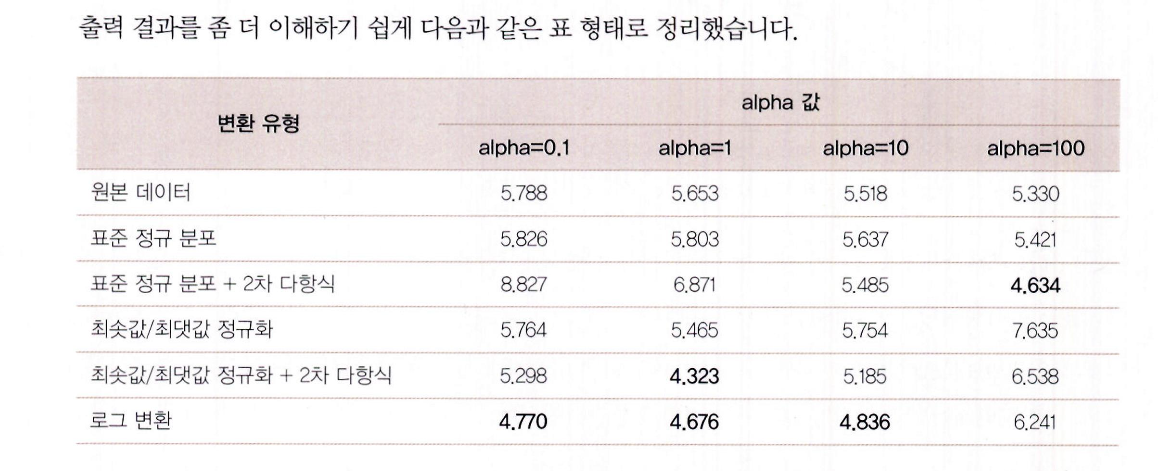
- 표준 정규 분포, 최소-최대 정규화만 적용했을 때는 성능 개선이 거의 없음
- 표준화 + 2차 다항 변환: alpha=100일 때 RMSE 4.634
- 정규화 + 2차 다항 변환: alpha=1일 때 RMSE 4.323 → 가장 좋은 성능
- 단점: 다항 변환은 피처가 많거나 데이터가 많으면 계산 부담 큼
- 로그 변환: alpha=0.1, 1, 10 모두 안정적이고 성능 향상
- 결론: 왜곡된 분포일수록 로그 변환이 효과적
7. 로지스틱 회귀
-
로지스틱 회귀는 선형 회귀 방식을 분류에 적용한 알고리즘 (따라서 회귀라는 이름과 달리 실제로는 분류 알고리즘임)
-
로지스틱 회귀는 선형 회귀 계열에 속함.
-
회귀가 선형인지 비선형인지는 독립변수가 아니라 가중치 변수(Weight)가 선형이냐 비선형이냐에 따라 구분함
-
로지스틱 회귀는 선형 함수의 회귀 최적선을 찾는 것이 아니라, 시그모이드 함수(Sigmoid Function)의 최적선을 찾음
-
시그모이드 함수의 반환 값은 0에서 1 사이의 확률로 간주함.
-
이 확률 값을 기준으로 이진 분류 등의 분류 결과를 결정함
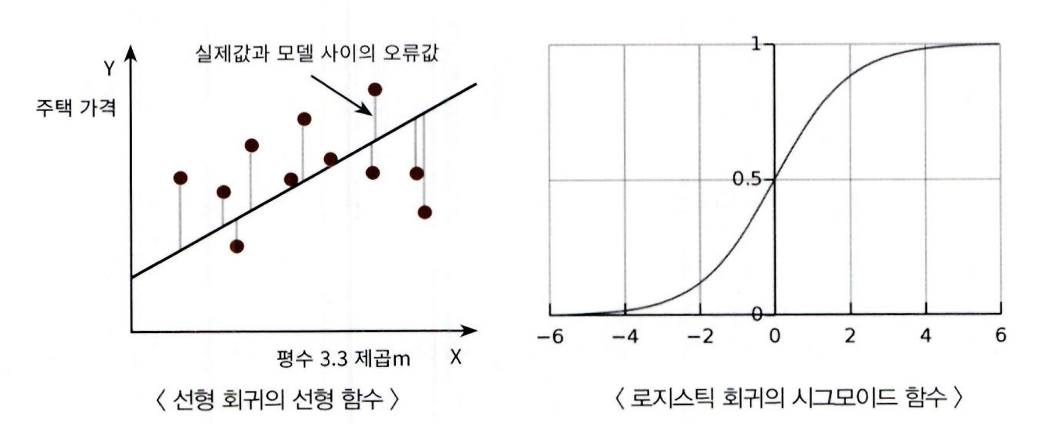
-
많은 자연 , 사회 현상에서 특정 변수의 확률 값은 선형이 아니라 위의 시그모이드 함수와 같이 S 자 커
브 형태를 가짐 -
시그모이드 함수의 정의
-
x 값이 +, - 로 아무리 커지거나 작아져도 y 값은 항상 0 과 1 사이 값을 반환
-
x 값이 커지면 1 에 근사하며 x 값이 작아지면 0 에 근사함
-
x 가 0 일 때는 0.5 임
-
지금까지는 회귀를 부동산 가격과 같은 연속형 값 예측에 사용했습니다.
-
이번에는 회귀 문제를 분류 문제에 적용해보는 접근임
-
예시: 종양의 크기에 따라 악성 종양 여부(Yes=1, No=0)를 예측하는 문제임
-
종양 크기를 X축, 악성 여부를 Y축에 표시하면 데이터가 선형 회귀선으로는 명확히 분류되지 않음을 알 수 있음
-
선형 회귀선은 분류를 시도할 수 있지만, 정확도가 낮음
-
시그모이드 함수(S자 커브 형태)를 이용하면 확률적으로 0과 1을 잘 구분할 수 있음
-
로지스틱 회귀는 선형 회귀 방식을 기반으로 하되,
시그모이드 함수를 이용해 이진 분류를 수행하는 회귀 기법임
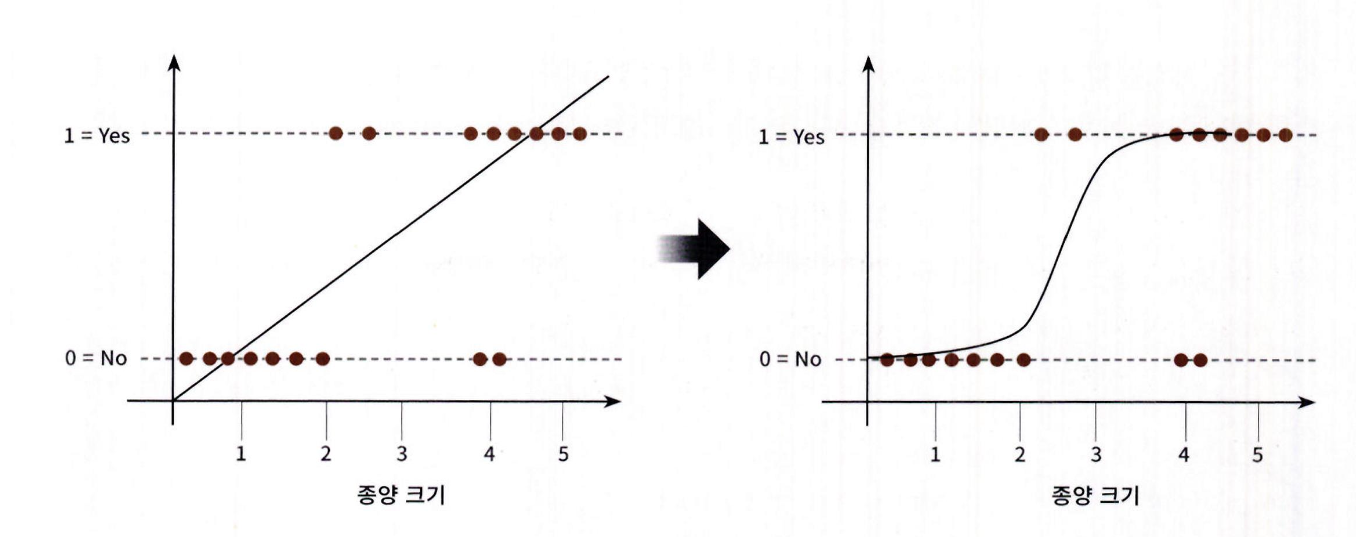
-
사이킷런은 로지스틱 회귀를 위해서 LogisticRegression 클래스를 제공함
-
LogisticRegression클래스의 회귀 계수 최적화는 본 장의 초반부에 소개해 드린 경사 하강법 외에 다양한 최적화 방안을 선택 가능
-
LogisticRegression 클래스에서 Solver 파라미터의 'lbfgs', liblinear,
'newton-cg, sag', saga' 값을 적용해서 최적화를 선택할 수 있음
- lbfgs: 사이킷런 버전 0.22 부터 solver 의 기본 설정값입니다. 메모리 공간을 절약할 수 있고 , CPU 코어 수가 많다면 최적화를 병렬로 수행 가능
- liblinear: 사이킷런 버전 0.21 까지에서 solver의 기본 설정값입니다. 다차원이고 작은 데이터 세트에서 효과적으로 동작하지만 국소 최적화 (Local Minimum) 에 이슈가 있고 , 병렬로 최적화 불가
- newon-cg: 좀 더 정교한 최적화를 가능하게 하지만 , 대용량의 데이터에서 속도가 많이 느려짐
- sag: Stochastic Average Gradient로서 경사 하강법 기반의 최적화를 적용합니다. 대용량의 데이터에서 빠르게 최적화함
- saga: sag 와 유사한 최적화 방식이며 L1 정규화를 가능하게 해줌
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
cancer = load_breast_cancer()- 선형 회귀 계열의 로지스틱 회귀는 데이터의 정규 분포도에 따라 예측 성능 영향을 받을 수 있으므로
데이터에 먼저 정규 분포 형태의 표준 스케일링을 적용한 뒤에 train_test_Split()을 이용해 데이터 세
트를 분리하겠습니다.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# StandardScaler()로 평균이 0, 분산 1 로 데이터 분포도 변환
scaler = StandardScaler()
data_scaled = scaler.fit_transform(cancer.data)
X_train, X_test, y_train, y_test = train_test_split(data_scaled, cancer.target, test_size=0.3,
random_state=0)- 이제 로지스틱 회귀를 이용해 학습 및 예측을 수행하고 , 정확도와 ROC-AUC 값을 구해 보겠습니다.
먼저 solver 값을 'lbfgs' 로 설정하고 성능을 확인해 보겠습니다. - 기본 solver 값은 'lbfgs 이므로 solver
인자값을 LogisticRegression() 생성자로 입력하지 않으면 자동으로 solver=1bfgs' 로 할당
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score
# 로지스틱 회귀를 이용하여 학습 및 예측 수행.
# solver 인자값을 생성자로 입력하지 않으면 solver='lbfgs'
lr_clf = LogisticRegression()
lr_clf.fit(X_train, y_train) # Make sure to train before predict
lr_preds = lr_clf.predict(X_test)
lr_preds_proba = lr_clf.predict_proba(X_test)[:, 1]
# accuracy와 roc_auc 측정
print('accuracy: {0:.3f}, roc_auc: {1:.3f}'.format(
accuracy_score(y_test, lr_preds),
roc_auc_score(y_test, lr_preds_proba)))
-
solver가 ‘lbfgs’인 경우: 정확도는 0.977 ROC-AUC는 0.995로 나타났음
-
이번에는 서로 다른 solver 값을 지정하여 LogisticRegression 모델을 학습하고 성능을 평가함
-
일부 solver는 최적화에 더 많은 반복 횟수가 필요할 수 있으므로, max_iter 값을 600으로 설정함
-
max_iter=600은 최적화 알고리즘이 수렴할 때까지 최대 600번 반복하여 회귀 계수를 조정하도록 함
solvers = ['lbfgs', 'liblinear', 'newton-cg', 'sag', 'saga']
# 여러 개의 Solver 값별로 LogisticRegression 학습 후 성능 평가
for solver in solvers:
lr_clf = LogisticRegression(solver=solver, max_iter=600)
lr_clf.fit(X_train, y_train)
lr_preds = lr_clf .predict(X_test)
lr_preds_proba = lr_clf.predict_proba(X_test)[:, 1]
#accuracy와 roc_auc 측정
print('solver:{0}, accuracy: {1:.3f}, roc_auc: {2:.3f}'.format(solver,
accuracy_score(y_test, lr_preds),
roc_auc_score(y_test, lr_preds_proba)))
- liblinear, sag, saga 사용 시:
정확도는 0.982, ROC-AUC는 0.995 - lbfgs나 newton-cg에 비해 상대적으로 성능 수치가 약간 높음
- 그러나 데이터 세트가 작기 때문에 큰 의미 있는 차이는 아님
- 여러 데이터 세트에 적용해도 solver 간 성능 차이는 크지 않음
- 예제에서는 일반적으로 liblinear가 약간 더 나은 성능을 보여 자주 사용됨
LogisticRegression 클래스의 주요 하이퍼파라미터:
- solver: 최적화 알고리즘 선택
- max_iter: 반복 최대 횟수
- penalty:
규제 유형 지정
- 'l2': L2 규제 (기본값)
- 'l1': L1 규제
C: 규제 강도 조절
- C = 1 / alpha, C 값이 작을수록 규제 강도는 큼
- L1, L2 규제 가능 여부 (solver에 따라 다름):
- liblinear, saga: L1과 L2 모두 가능
- lbfgs, newton-cg, sag: L2 규제만 가능
GridSearchCV 를 이용해 위스콘신 데이터 세트에서 solver, penalty, C 를 최적화해보기
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
params={'solver':['liblinear', 'lbfgs'],
'penalty' :['l2', 'l1'],
'C': [0.01, 0.1, 1, 5, 10]}
lr_clf = LogisticRegression()
grid_clf = GridSearchCV(lr_clf, param_grid=params, scoring='accuracy', cv=3 )
grid_clf.fit(data_scaled, cancer.target)
print('최적 하이퍼 파라미터 :{0}, 최적 평균 정확도:{1:.3f}'.format(grid_clf.best_params_,
grid_clf.best_score_))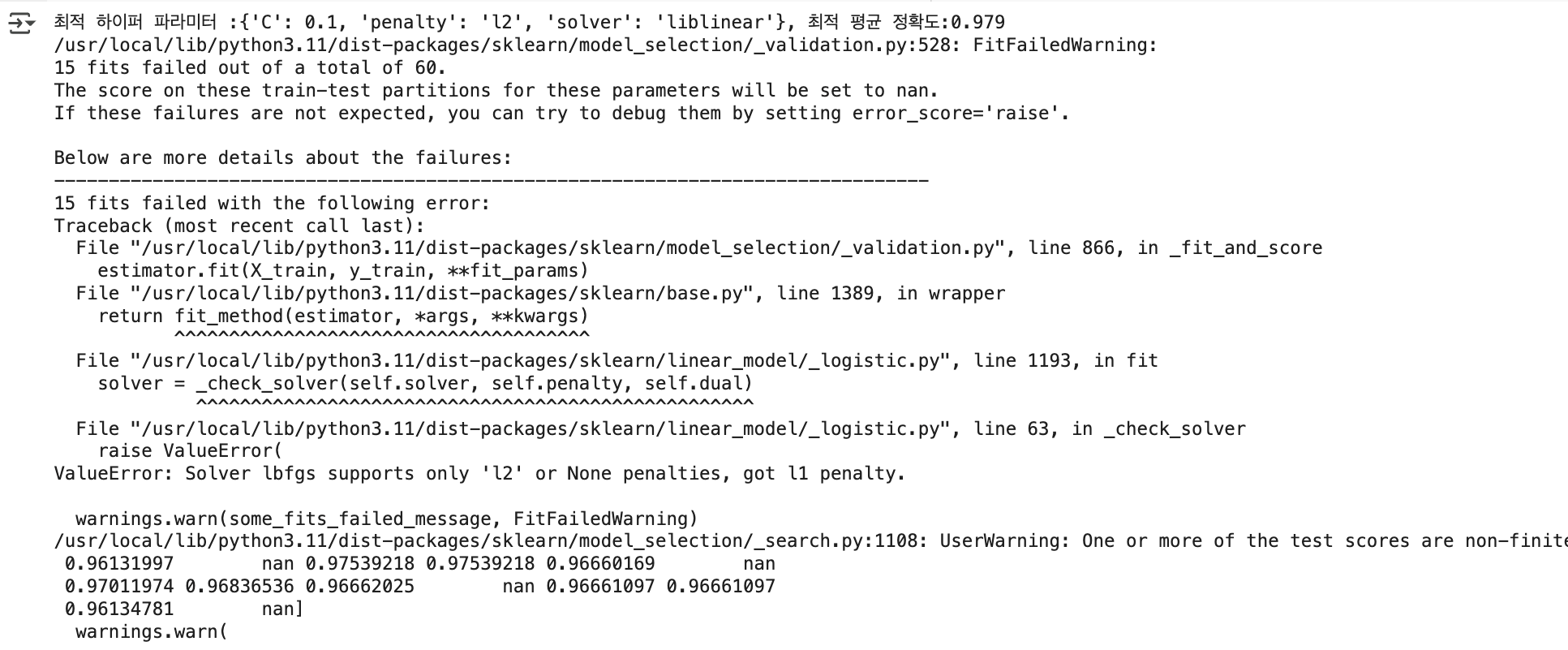
- solver가 liblinear, Penalty가 L2 규제, C 값이 0.1일 때 → 평균 정확도는 0.979로 가장 우수한 성능을 보임
FitFailedWarning 메시지 발생 원인:
- solver가 lbfgs일 때는 L1 규제를 지원하지 않음
- 그런데 GridSearchCV에 L1 규제를 함께 입력했기 때문에 경고 발생
로지스틱 회귀의 특징:
- 계산이 가볍고 빠름
- 이진 분류 예측 성능이 뛰어나 기본 모델로 많이 사용됨
- 희소한 데이터에도 강하여 텍스트 분류 문제에서 자주 활용됨
8. 회귀 트리
- 선형 회귀는 모든 회귀 계수 간의 관계를 선형으로 가정함
→ 회귀 계수의 선형 결합으로 이루어진 회귀 함수를 기반으로 예측 수행 - 비선형 회귀는 회귀 계수 간의 결합이 비선형일 뿐, 역시 회귀 함수 기반으로 예측 수행
- 머신러닝 기반 회귀의 핵심 목표는 최적의 회귀 함수(선형이든 비선형이든)를 학습을 통해 도출하는 것
- 이 절에서는 함수 기반 회귀가 아닌 방식인 트리 기반 회귀를 소개
-회귀 트리는 회귀를 위한 결정 트리 구조를 사용
→ 기본 구조는 분류 트리와 유사하지만, 예측 방식에서 차이가 있음 - 분류 트리는 리프 노드에서 클래스 레이블을 예측
→ 반면 회귀 트리는 리프 노드에 속한 데이터의 평균값을 예측값으로 사용 - 매우 간단한 데이터 세트를 이용해 회귀 트리가
어떻게 동작하는지 살펴보겠습니다. 피처가 단
하나인 X 피처 데이터 세트와 결정값 Y 가 2 차원 3
평면상에 다음 그림과 같이 있다고 가정
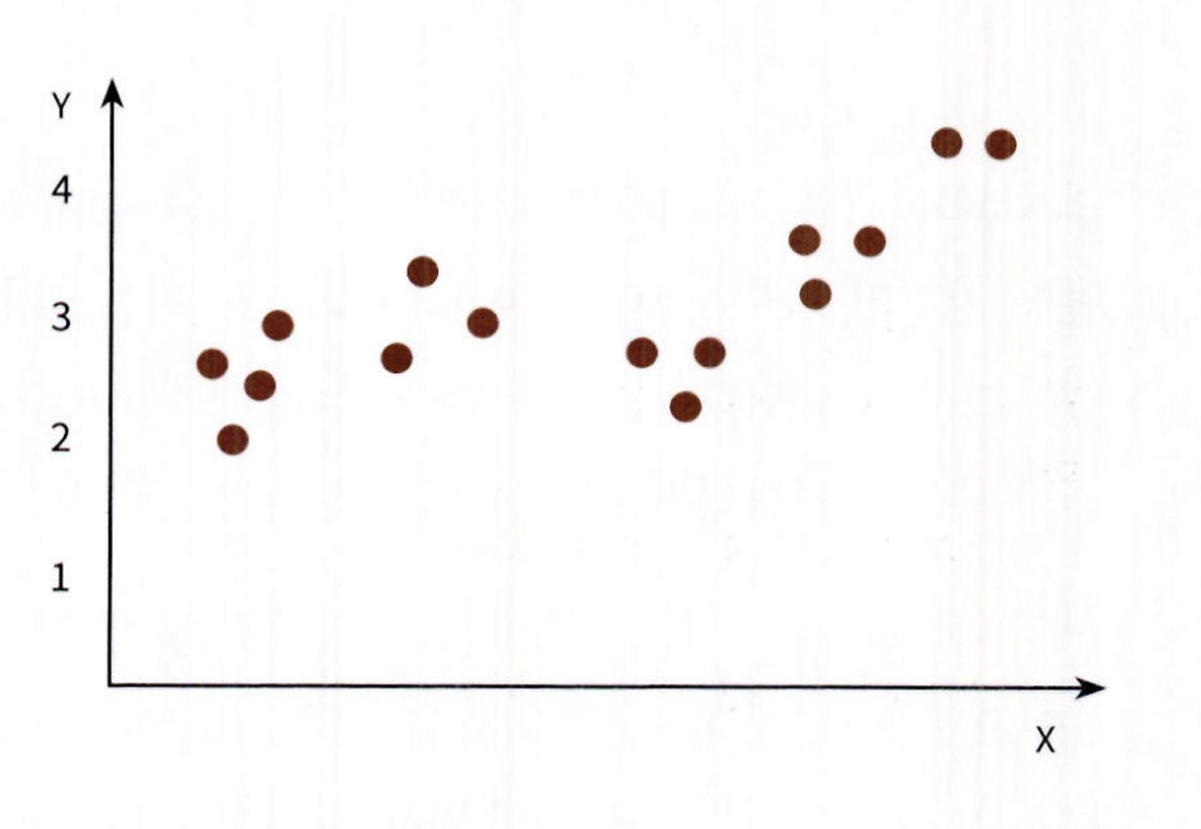
- 이 데이터 세트의 X 피처를 결정 트리 기반으로 분할하면 X 값의 균일도를 반영한 지니 계수에 따라 다
음 그림의 왼쪽과 같이 분할할 수 있음 - 루트 노드를 Split 0 기준으로 분할하고 이렇게 분할된 규칙 노드에서 다시 Split 1 과 Split 2 규칙 노드로 분할할 수 이ㅆ음
- 그리고 Split 2 는 다시 재귀적으로 Split 3 규칙 노드로 다음 그림의 오른쪽과 같이 트리 규칙으로 변환될 수 있음
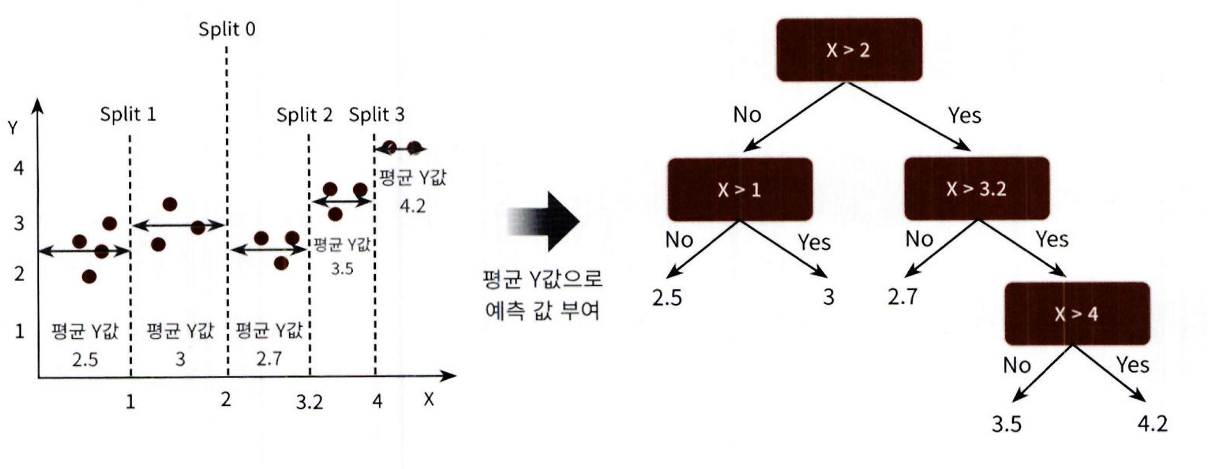
리프 노드 생성 기준에 부합하는 트리 분할이 완료됐다면 리프 노드에 소속된 데이터 값의 평균값을 구
해서 최종적으로 리프 노드에 결정 값으로 할당
- 결정 트리, 랜덤 포레스트, GBM, XGBoost, LightGBM은 모두 분류와 회귀에 사용 가능
- 이는 모두 CART (Classification and Regression Tree) 알고리즘 기반이기 때문
- 사이킷런은 각각의 알고리즘에 대해 분류용과 회귀용 Estimator 클래스를 따로 제공함
- 예: DecisionTreeClassifier / DecisionTreeRegressor
- XGBoost, LightGBM도 사이킷런 래퍼 클래스로 회귀 지원함
사이킷런의 트리 기반 회귀와 분류의 Estimator 클래스를 표
| Algorithm | Classification Estimator | Regression Estimator |
|---|---|---|
| Decision Tree | DecisionTreeClassifier | DecisionTreeRegressor |
| Gradient Boosting | GradientBoostingClassifier | GradientBoostingRegressor |
| XGBoost | XGBClassifier (wrapper) | XGBRegressor (wrapper) |
| LightGBM | LGBMClassifier (wrapper) | LGBMRegressor (wrapper) |
import pandas as pd
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
# 보스턴 데이터 수동 로드
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 데이터프레임 구성
bostonDF = pd.DataFrame(data, columns=[
'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE',
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'
])
bostonDF['PRICE'] = target
# 학습용 데이터 분리
X_data = bostonDF.drop(['PRICE'], axis=1)
y_target = bostonDF['PRICE']
# 랜덤 포레스트 회귀 모델 학습 및 평가
rf = RandomForestRegressor(random_state=0, n_estimators=1000)
neg_mse_scores = cross_val_score(rf, X_data, y_target, scoring="neg_mean_squared_error", cv=5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
# 결과 출력
print('5 교차 검증의 개별 Negative MSE scores:', np.round(neg_mse_scores, 2))
print('5 교차 검증의 개별 RMSE scores:', np.round(rmse_scores, 2))
print('5 교차 검증의 평균 RMSE: {:.3f}'.format(avg_rmse))
- 이번에는 랜덤 포레스트뿐만 아니라 결정 트리 , GBM, XGBoost, LightG BM 의 Regressor 를 모두 이용해 보스턴 주택 가격 예측을 수행
- 이를 위해 get_model_cv prediction() 함수를 만듦. - get_model_cv_prediction()은 입력 모델과 데이터 세트를 입력받아 교차 검증으로 평균
RMSB 를 계산해주는 함수
def get_model_cv_prediction(model, X_data, y_target):
neg_mse_scores=cross_val_score(model, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean (rmse_scores)
print('#####' , model.__class__name__, ' #####')
print(' 5 교차 검증의 평균 RMSE : {0:.3f}' .format(avg_rmse))다양한 유형의 회귀 트리를 생성하고 , 이를 이용해 보스턴 주택 가격을 예측해 보겠습니다.
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
# 모델 정의
dt_reg = DecisionTreeRegressor(random_state=0, max_depth=4)
rf_reg = RandomForestRegressor(random_state=0, n_estimators=1000)
gb_reg = GradientBoostingRegressor(random_state=0, n_estimators=1000)
xgb_reg = XGBRegressor(n_estimators=1000)
lgb_reg = LGBMRegressor(n_estimators=1000, min_child_samples=5)
models = [dt_reg, rf_reg, gb_reg, xgb_reg, lgb_reg]
# 모델 평가 루프
for model in models:
get_model_cv_prediction(model, X_data, y_target)
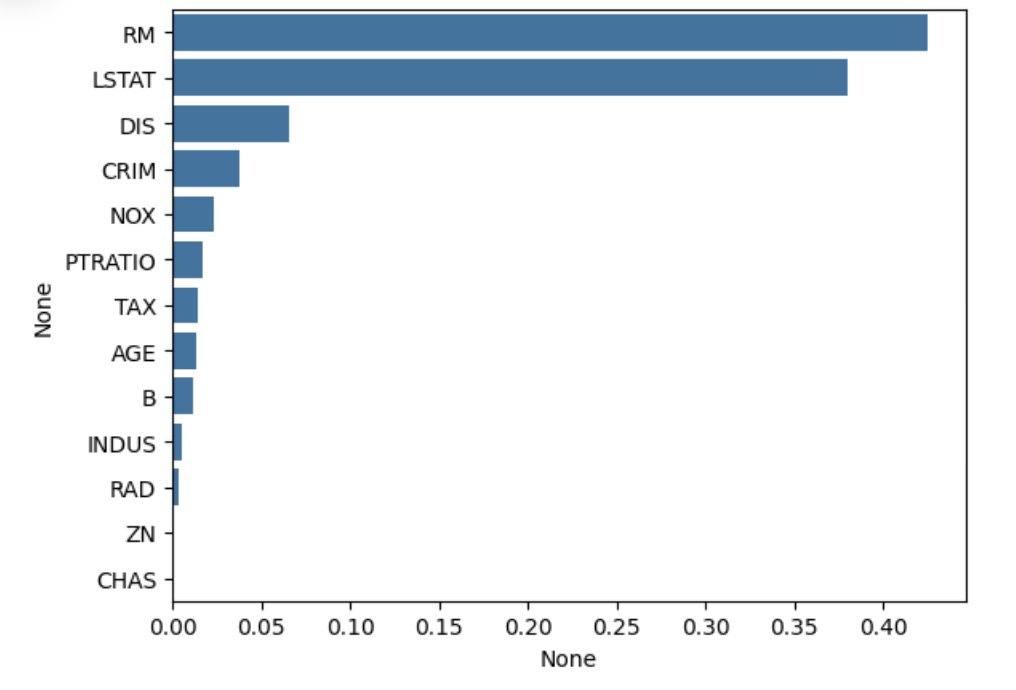
- 회귀 트리 Regressor 클래스는 선형 회귀와 다른 처리 방식이므로 회귀 계수를 제공하는 coef_ 속성이 없음.
- 대신 featureimportances를 이용해 피처별 중요도를 알 수 있음.
- featureimportances를 이용해 보스턴 주택 가격 모델의 피처별 중요도를 시각화해 보겠습니다.
import seaborn as sns
%matplotlib inline
rf_reg = RandomForestRegressor(n_estimators=1000)
# 앞 예제에서 만들어진 X_data, y_target 데이터 세트를 적용해 학습합니다.
rf_reg.fit(X_data, y_target)
feature_series = pd.Series(data=rf_reg.feature_importances_, index=X_data.columns )
feature_series = feature_series.sort_values(ascending=False)
sns.barplot(x= feature_series, y=feature_series.index)
- 사이킷런의 회귀 트리(DecisionTreeRegressor)는 분류 트리(Classifier)와 하이퍼 파라미터가 거의 동일
- max_depth 하이퍼 파라미터를 바꾸어 예측 결과의 변화를 시각화
- 보스턴 주택 데이터에서 RM (방 개수) 칼럼만 추출하여 2차원 회귀선 시각화
- 선형 회귀와 결정 트리 회귀의 예측 선을 RM vs PRICE로 비교
- 직관적 시각화를 위해 데이터 100개만 샘플링하여 사용
bostonDF_sample = bostonDF [['RM', 'PRICE']]
bostonD_sample = bostonDF_sample.sample(n=100, random_state=0)
print(bostonDF_sample.shape)
plt.figure()
plt.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")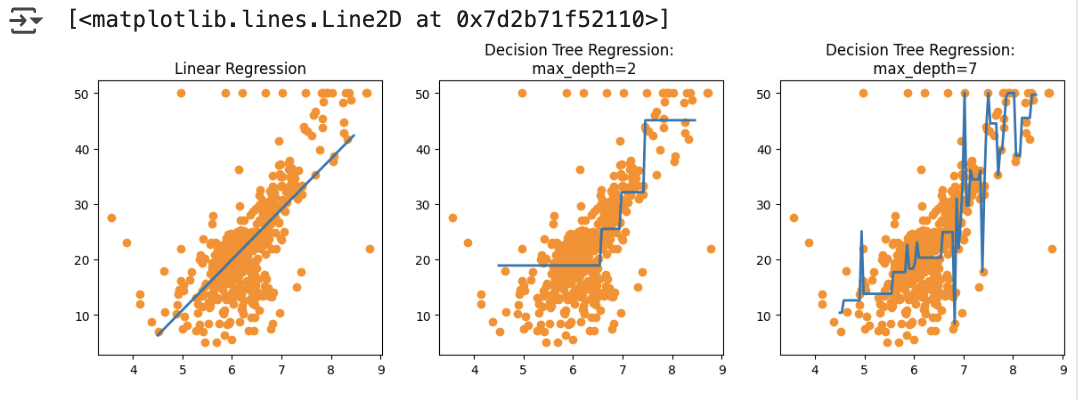
- 다음으로 보스턴 데이터 세트에 대해 LinearRegression DecisionTreeRegressor를 max_depth를
각 2, 7 로 해서 학습해 보겠습니다. - 이렇게 학습된 Regressor 에 RM 값을 4.5~8.5 까지의 100 개의 테스트 데이터 세트로 제공했을 때 예측값을 구하겠습니다.
import numpy as np
from sklearn.linear_model import LinearRegression
# 선형 회귀와 결정 트리 기반의 Regressor 생성. DecisionTreeRegressor 의 max_depth 는 각 2, 7
lr_reg = LinearRegression()
rf_reg2 = DecisionTreeRegressor(max_depth=2)
rf_reg7 = DecisionTreeRegressor(max_depth=7)
# 실제 예측을 적용할 테스트용 데이터 세트를 4.5~8.5 까지의 100 개 데이터 세트로 생성.
X_test = np.arange(4.5, 8.5, 0.04) .reshape(-1, 1)
# 보스턴 주택 가격 데이터에서 시각화를 위해 피처는 RM 만 , 그리고 결정 데이터인 PRICE 추출
X_feature = bostonDF_sample['RM'].values.reshape(-1, 1)
y_target = bostonDF_sample['PRICE'].values.reshape(-1, 1)
# 학습과 예측 수행.
lr_reg.fit(X_feature, y_target)
rf_reg2.fit(X_feature, y_target)
rf_reg7.fit(X_feature, y_target)
pred_lr = lr_reg.predict(X_test)
pred_rf2 = rf_reg2.predict(X_test)
pred_rf7 = rf_reg7.predict(X_test)fig, (ax1, ax2, ax3) = plt.subplots(figsize=(14, 4), ncols=3)
# X 축 값을 4.5 ~ 8.5로 변환하며 입력했을 때 선형 회귀와 결정 트리 회귀 예측선 시각화
# 선형 회귀로 학습된 모델 회귀 예측선
ax1.set_title('Linear Regression')
ax1.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
ax1.plot(X_test, pred_lr, label="linear", linewidth=2 )
# DecisionTreeRegressor의 max_depth 를 2로 했을 때 회귀 예측선
ax2.set_title('Decision Tree Regression: \n max_depth=2' )
ax2.scatter (bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
ax2.plot(X_test, pred_rf2, label="max_depth:3", linewidth=2 )
# DecisionTreeRegressor의 max_depth를 7 로 했을 때 회귀 예측선
ax3.set_title('Decision Tree Regression: \n max_depth=7')
ax3.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
ax3.plot(X_test, pred_rf7, label="max_depth:7", linewidth=2)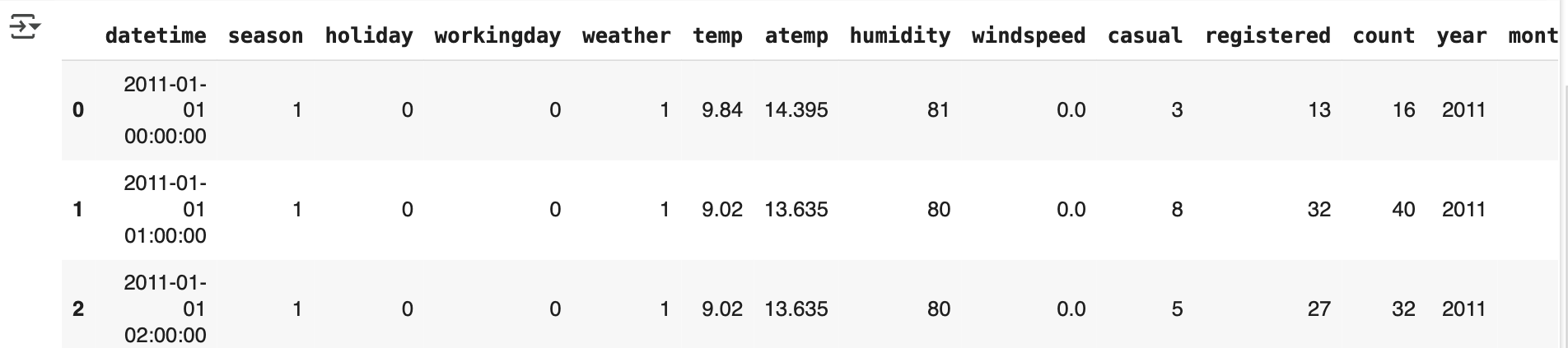
- 선형 회귀는 예측 값을 직선으로 표현함
- 회귀 트리(DecisionTreeRegressor)는 데이터 분할 기준에 따라 계단 형태의 회귀선을 생성
- max_depth=7로 설정한 경우, 이상치(outlier)까지 학습하여 과적합(overfitting)이 발생할 수 있음
9. 회귀 실습 - 자전거 대여 수요 예측
• datetime: hourly date + timestamp
• season: 1= 봄. 2 = 여름 , 3= 가을 , 4 = 겨울
• holiday: 1= 토 , 일요일의 주말을 제외한 국경일 등의 휴일 , 0= 휴일이 아닌 날
• workingday: 1= 토 , 일요일의 주말 및 휴일이 아닌 주중 , 0= 주말 및 휴일
• w e a t h e r :
• 1= 맑음 , 약간 구름 낀 흐림
• 2= 안개 , 안개 + 흐림
• 3= 가벼운 눈 , 가벼운 비 + 천둥
• 4= 심한 눈 / 비 , 천둥 / 번개
• temp: 온도 ( 섭씨 )
• atemp: 체감온도 ( 섭씨 )
• humidity: 상대습도
• windspeed: 풍속
• casual: 사전에 등록되지 않는 사용자가 대여한 횟수
• registered: 사전에 등록된 사용자가 대여한 횟수
• count: 대여 횟수
데이터 클렌징 및 가공과 데이터 시각화
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore", category=RuntimeWarning)
bike_df = pd.read_csv('/content/sample_data/bike_train.csv')
print(bike_df.shape)
bike_df.head()데이터 칼럼의 타입을 살펴보기
bike_df.info()- 전체 데이터는 10,886개이며 Null 값은 없음
- 대부분의 칼럼은 int 또는 float형이며 datetime 칼럼만 object 형
- datetime은 문자열 형태로 "년-월-일 시:분:초" 구조
- 이를 년도, 월, 일, 시간 4개의 속성으로 분리하기 위해 pd.to_datetime을 사용
- apply(pd.to_datetime)으로 datetime 칼럼을 datetime 타입으로 변환한 후 각각의 속성을 추출함
# 문자열을 datetime 타입으로 변경.
bike_df ['datetime'] = bike_df.datetime.apply(pd.to_datetime)
# datetime 타입에서 년 , 월 , 일 , 시간 추출
bike_df[ 'year'] = bike_df.datetime.apply(lambda x : x.year )
bike_df['month'] = bike_df.datetime.apply(lambda x : x.month)
bike_df['day'] = bike_df.datetime.apply(lambda x : x.day)
bike_df['hour'] = bike_df.datetime.apply(lambda x: x.hour)
bike_df.head (3)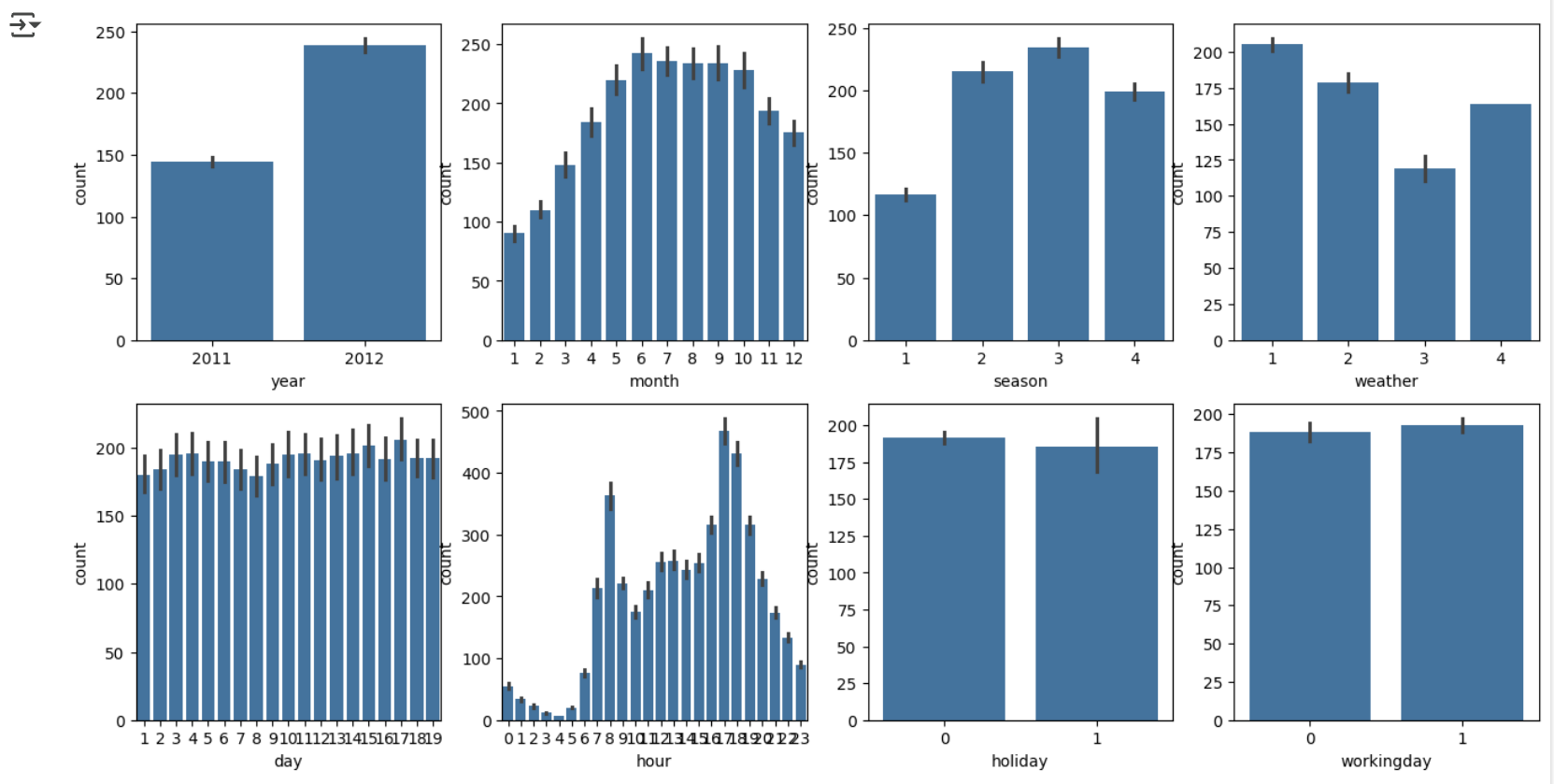
- year, month, day, hour 칼럼이 새롭게 추가됨
- 기존의 datetime 칼럼은 더 이상 필요 없으므로 삭제
- casual은 비등록 사용자, registered는 등록 사용자 대여 횟수
- count = casual + registered 관계이므로 casual과 registered는 예측에 불필요하고
높은 상관도로 인해 예측을 저해할 수 있어 둘 다 삭제함
drop_columns = ['datetime', 'casual', 'registered']
bike_df.drop(drop_columns, axis=1, inplace=True)- count(자전거 대여 횟수)의 분포를 주요 범주형 칼럼 8개별로 시각화
- 대상 칼럼: 'year', 'month', 'season', 'weather', 'day', 'hour', 'holiday', 'workingday'
- 시본(Seaborn)의 barplot() 사용해 각 칼럼 값별로 count 합계를 표시
- matplotlib.pyplot.subplots(ncols=4, nrows=2)를 사용해 2행 4열 구성으로 시각화
fig, axs = plt.subplots(figsize=(16, 8), ncols=4, nrows=2)
cat_features = ['year', 'month', 'season', 'weather', 'day', 'hour', 'holiday', 'workingday'] # Fixed: Added missing comma between 'month' and 'season'
# Cat_features에 있는 모든 칼럼별로 개별 칼럼값에 따른 count의 합을 barplot으로 시각화
for i, feature in enumerate(cat_features):
row = int(i/4)
col = i % 4
# 시본의 barplot을 이용해 칼럼값에 따른 count 의 합을 표현
sns.barplot(x=feature, y='count', data=bike_df, ax=axs[row, col]) 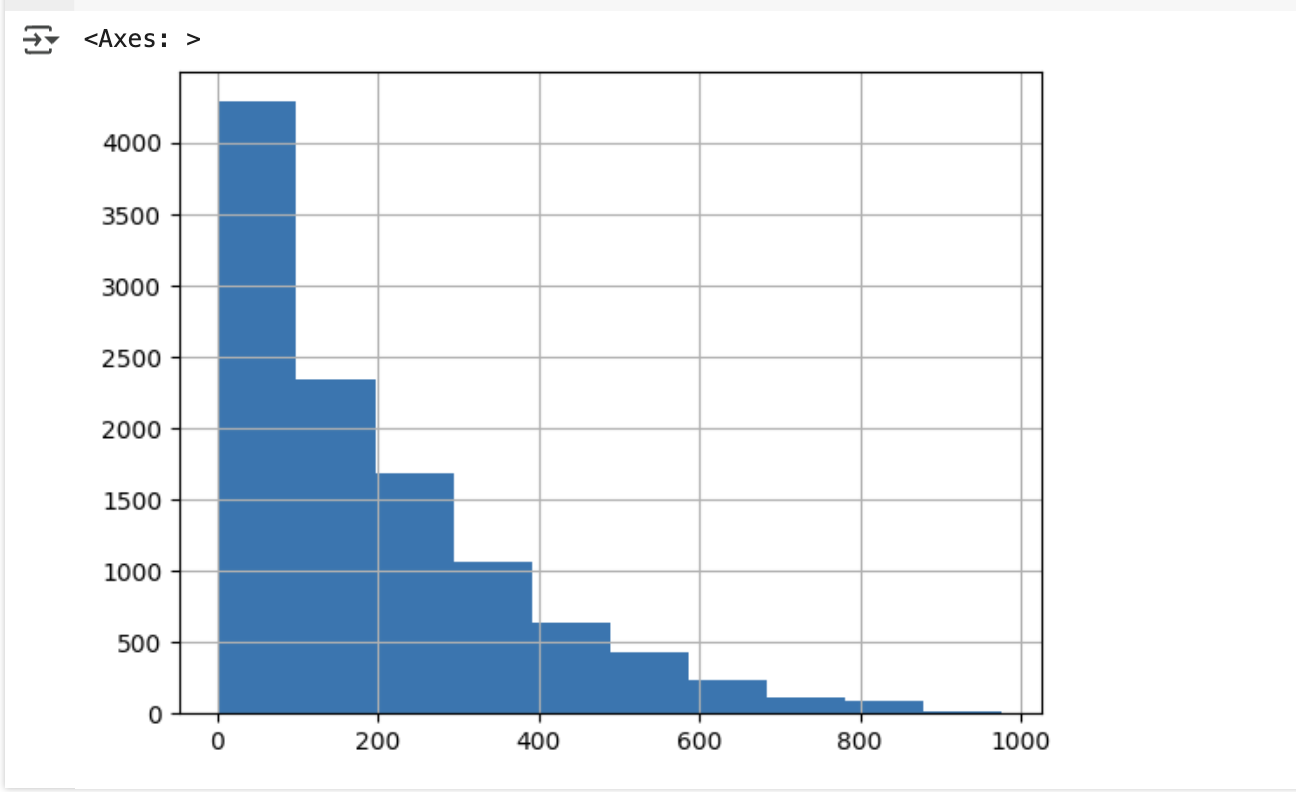
from sklearn.metrics import mean_squared_error, mean_absolute_error
def rmsle(y, pred):
log_y = np.log1p(y)
log_pred = np.log1p(pred)
squared_error = (log_y - log_pred) ** 2
rmsle = np.sqrt(np.mean(squared_error))
return rmsle
# 사이킷런의 mean_square_error()를 이용해 RMSE 계산
def rmse(y, pred):
return np.sqrt(mean_squared_error (y, pred))
# MAE, RNSE, RMSLE 를 모두 계산
def evaluate_regr(y, pred):
rmsle_val = rmsle(y, pred)
rmse_val = rmse(y, pred)
# MAE 는 사이킷런의 mean_absolute_error()로 계산
mae_val = mean_absolute_error (y, pred)
print('RMSLE: {0:.3f}, RMSE: {1:3F}, MAE: {2:3}'. format(rmsle_val, rmse_val, mae_val))- 위의 rmsle() 함수를 만들 때 한 가지 주의해야 할 점이 있습니다. rmsle 를 구할 때 넘파이의 log()
함수를 이용하거나 사이킷런의mean_squared_log_error()를 이용할 수도 있지만 데이터 값의 크기에 따라 오버플로 / 언더플로 (overflow/underflow) 오류가 발생하기 쉽습니다. 예를 들어 rmsle()를 다음과 같이 정의했을 때 쉽게 오류가 발생할 수 있습니다.
# 다음과 같은 rmsle 구현은 오버플로나 언더플로 오류를 발생하기 쉽습니다.
def rmsle(y, pred):
msle = mean_squared_log_error(y, pred)
rmsle = np.sqrt(mse)
return rmsle- 따라서 log() 보다는 log1p() 를 이용하는데 , log1p(x) 의 경우는 1og(1+x) 로 변환되므로 x 값이 0 이 되더라도 log(O) 인 무한대가 되지 않고 , log(1) 인 0 이 되므로 오버플로 / 언더플로 문제를 해결해 줍니
다. - 그리고 loglp()로 변환된 값은 다시 넘파이의 expml() 함수로 쉽게 원래의 스케일로 복원될 수
있습니다.
로그 변환 , 피처 인코딩과 모델 학습 / 예측 / 평가
사이킷런의 LinearRegression 객체를 이용해 회귀 예측
- 회귀 모델 적용 전 데이터 전처리 과정이 중요함
- 타깃 값(count)의 정규 분포 여부를 확인하여 필요 시 로그 변환 수행
- 범주형 변수는 회귀 모델에 직접 사용하기 어려우므로 원-핫 인코딩 필요
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge, Lasso
y_target = bike_df[ 'count']
X_features = bike_df.drop(['count'], axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3,
random_state=0)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
pred = lr_reg.predict(X_test)
evaluate_regr(y_test, pred)- RMSLE: 1.165, RMSE: 140.900. MAE: 105.924 는 실제 Target 데이터 값인 대여 횟수 (Count)를 감안하면 예측 오류로서는 비교적 큰 값
- 실제 값과 예측값이 어느 정도 차이가 나는지 DataFrame 의 칼럼으로 만들어서 오류 값이 가장 큰 순으로 5 개만 확인해 보겠습니다.
def get_top_error_data(y_test, pred, n_tops = 5):
# DataFrame의 칼럼으로 실제 대여 횟수(count)와 예측값을 서로 비교할 수 있도록 생성.
result_df = pd.DataFrame(y_test.values, columns=['real_count'])
result_df[ 'predicted_count' ]= np.round (pred)
result_df['diff'] = np.abs(result_df['real_count'] - result_df[ 'predicted_count'])
# 예측값과 실제 값이 가장 큰 데이터 순으로 출력.
print(result_df.sort_values('diff', ascending=False)[:n_tops])
get_top_error_data(y_test, pred, n_tops=5)= 예측 오류가 큰 경우, 가장 먼저 타깃 값(Target)의 분포를 점검해야 함
- 타깃 값은 정규 분포 형태일 때 회귀 예측 성능이 가장 우수함
= 반대로 왜곡된 분포(편향된 형태)를 가지면 회귀 모델이 제대로 학습하지 못해 예측 오류가 커짐
= 따라서 타깃 값의 분포를 정규화(예: 로그 변환 등)하는 것이 필요할 수 있음
y_target.hist()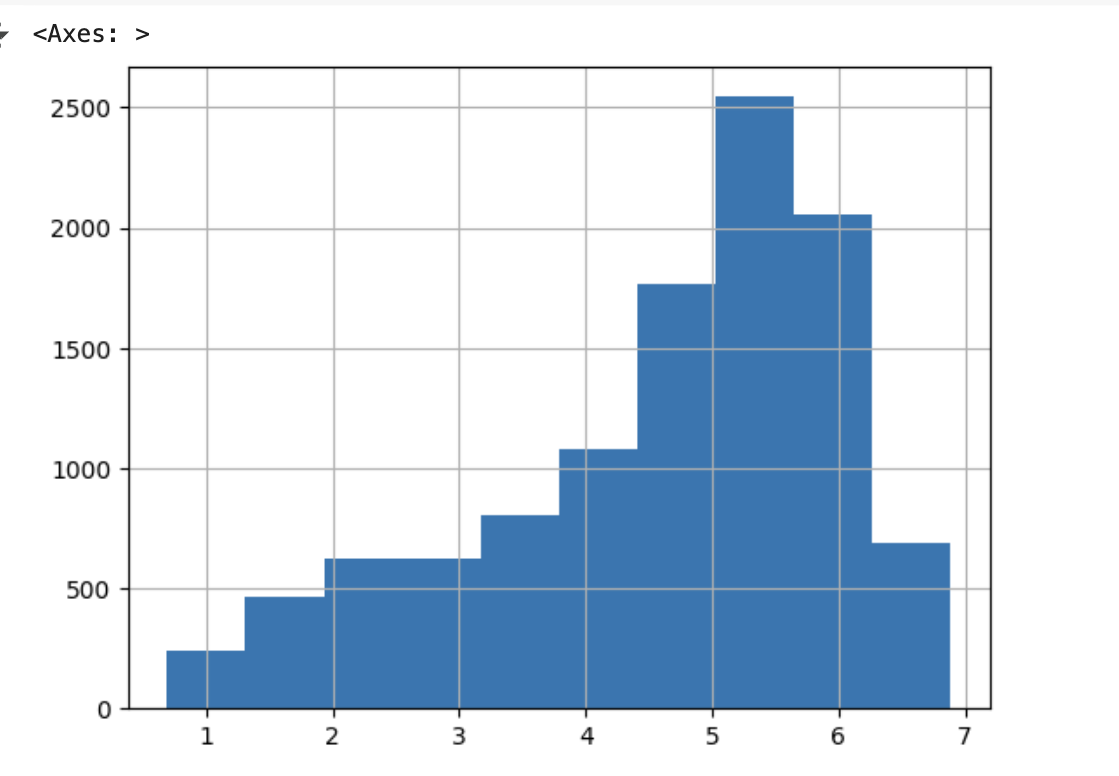
y_log_transform = np.log1p(y_target)
y_log_transform.hist()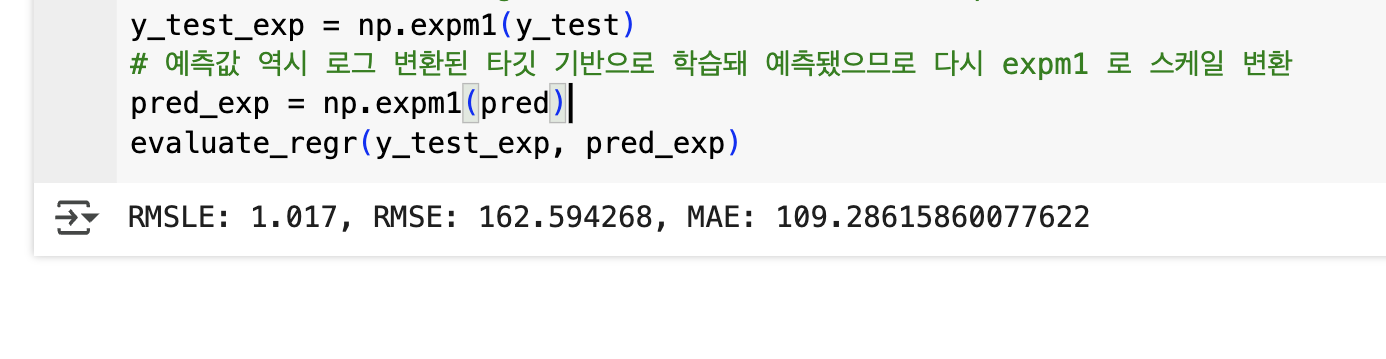
- 로그로 Target 값을 변환한 후에 원하는 정규 분포 형태는 아니지만 변환하기 전보다는 왜곡 정도가 많이 향상됐음
- 이를 이용해 다시 학습한 후 평가를 수행해 보겠습니다.
# 타깃 칼럼인 count 값을 10g1p 로 로그 변환
y_target_log = np.log1p(y_target)
# 로그 변환된 y_target_log를 반영해 학습 / 테스트 데이터 세트 분할
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target_log, test_size=0.3,
random_state=0)
lr_reg = LinearRegression()
lr_reg. fit(X_train, y_train)
pred = lr_reg.predict(X_test)
# 테스트 데이터 세트의 Target 값은 로그 변환됐으므로 다시 expm1 을 이용해 원래 스케일로 변환
y_test_exp = np.expm1(y_test)
# 예측값 역시 로그 변환된 타깃 기반으로 학습돼 예측됐으므로 다시 expm1 로 스케일 변환
pred_exp = np.expm1(pred)
evaluate_regr(y_test_exp, pred_exp)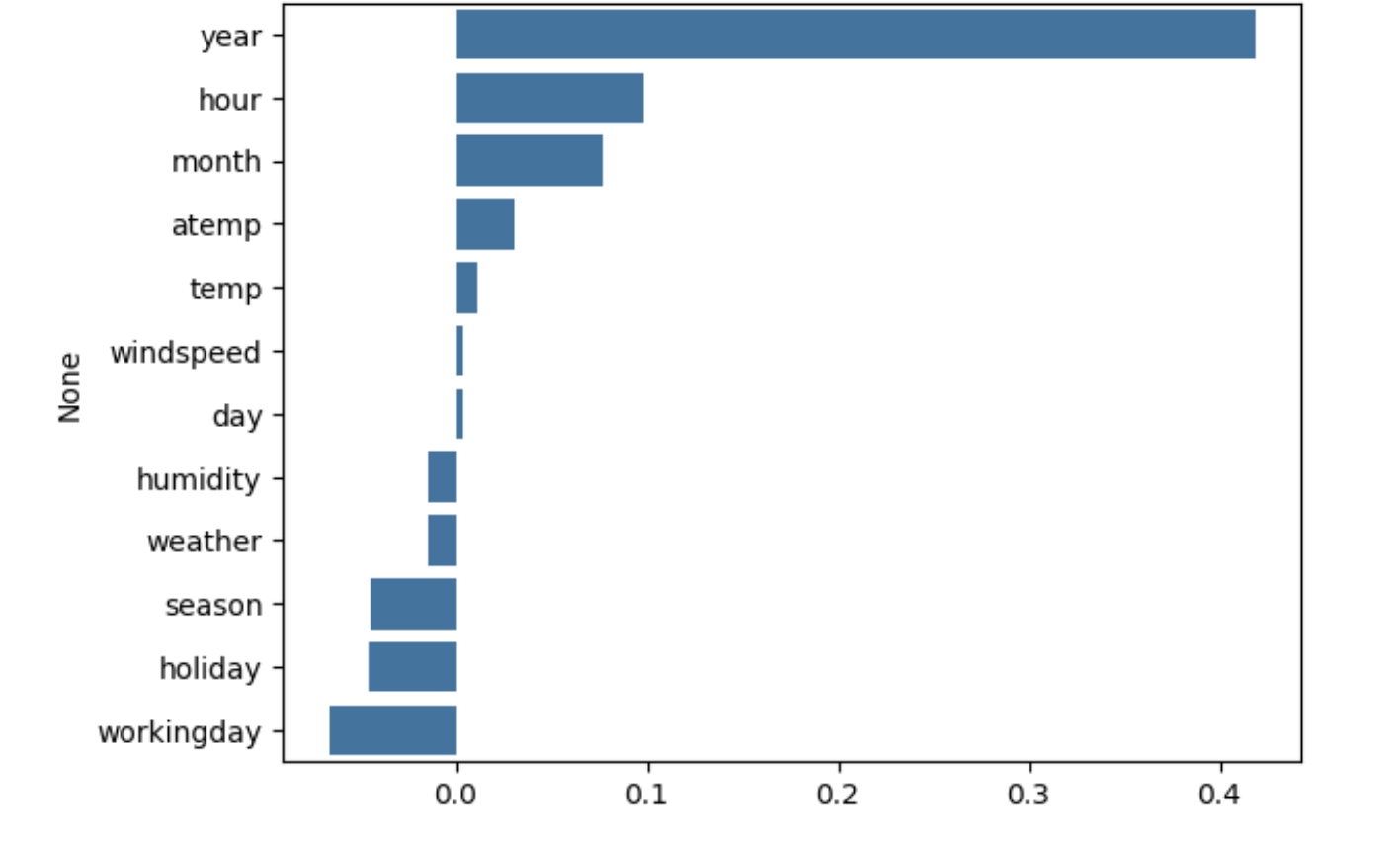
각 피처의 회귀 계숫값을 시각화
coef = pd.Series(lr_reg.coef_, index=X_features.columns)
coef_sort = coef. sort_values(ascending=False)
sns.barplot(x=coef_sort.values, y=coef_sort. index)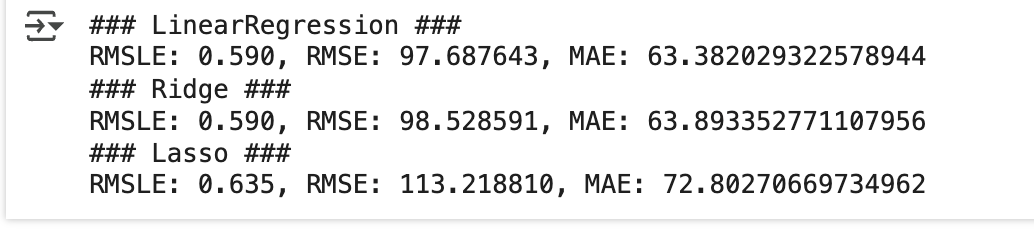
- year, month, hour, season, holiday, workingday 등은 숫자형이지만 본질적으로 범주형 (카테고리형) 피처임
- 이 피처들을 그대로 사용하면 숫자 크기에 따른 잘못된 회귀 계수 해석이 발생할 수 있음
- 선형 회귀 모델은 숫자의 상대적 크기를 민감하게 반영하므로 이런 범주형 피처는 원-핫 인코딩이 필수
- 판다스의 get_dummies()를 사용해 해당 칼럼들을 원-핫 인코딩한 뒤 회귀 모델에 적용하여 성능을 재평가
#'year', month', 'day', hour ' 등의 피처들을 One Hot Encoding
X_features_ohe = pd.get_dummies(X_features, columns=[ 'year', 'month', 'day', 'hour', 'holiday',
'workingday', 'season', 'weather'])모델과 학습 / 테스트 데이터 세트를 입력하면 성능 평가 수치를 반환하는 getmodel
predict() 함수
# 원- 핫 인코딩이 적용된 피처 데이터 세트 기반으로 학습 / 예측 데이터 분할.
X_train, X_test, y_train, y_test = train_test_split(X_features_ohe, y_target_log,
test_size=0.3, random_state=0)
# 모델과 학습 / 테스트 데이터 세트를 입력하면 성능 평가 수치를 반환
def get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=False):
model.fit(X_train, y_train)
pred = model.predict(X_test)
if is_expm1 :
y_test = np.expm1 (y_test)
pred = np.expm1 (pred)
print('###',model.__class__.__name__ ,'###')
evaluate_regr (y_test, pred)
# end of function get_model predict
# 모델별로 평가 수행
lr_reg = LinearRegression()
ridge_reg = Ridge(alpha=10)
lasso_reg = Lasso(alpha=0.01)
for model in [lr_reg, ridge_reg, lasso_reg]:
get_model_predict(model,X_train, X_test, y_train, y_test, is_expm1=True)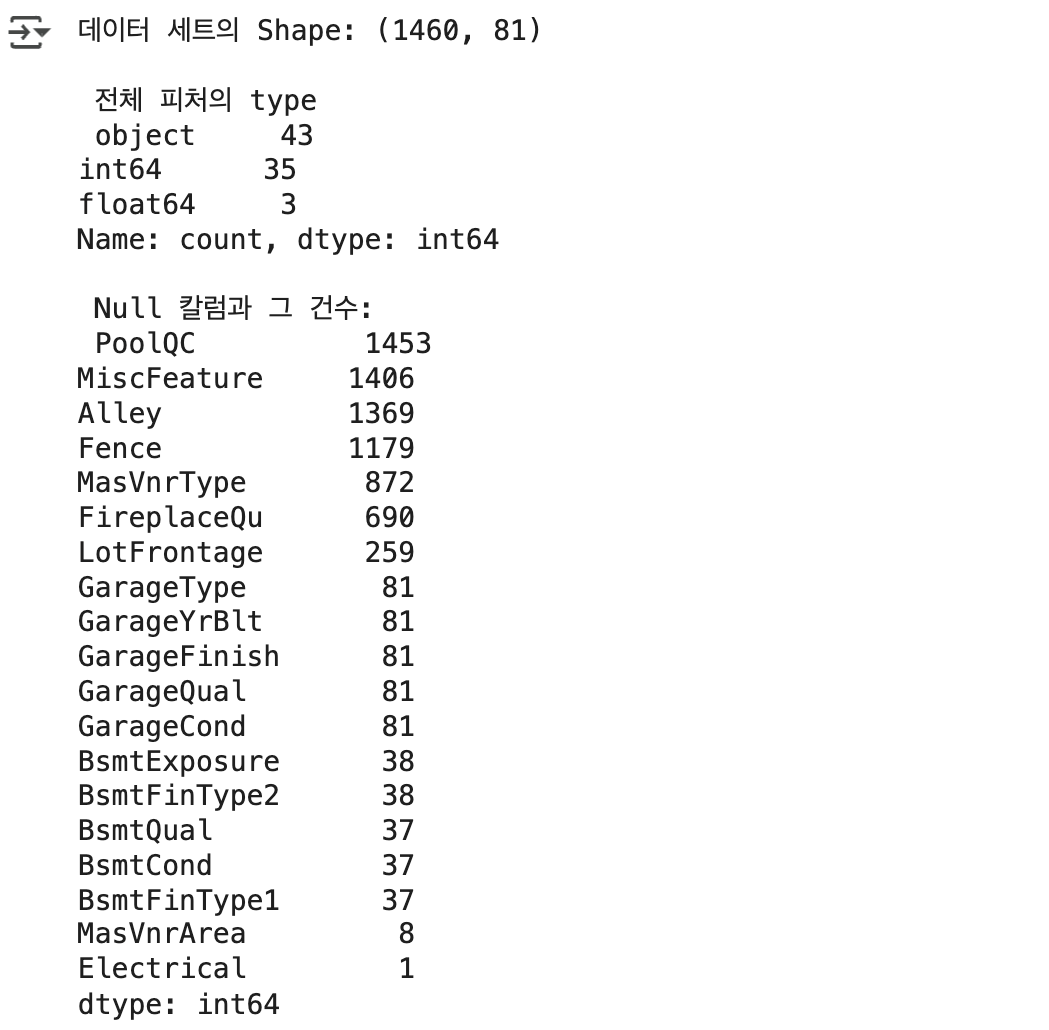
- 원- 핫 인코딩을 적용하고 나서 선형 회귀의 예측 성능이 많이 향상됐습니다. 원- 핫 인코딩된 데이터 세트에서 회귀 계수가 높은 피처를 다시 시각화하겠습니다.
- 원- 핫 인코딩으로 피처가 늘어났으므로 회
귀 계수 상위 20 개 피처를 추출해 보겠습니다.
coef = pd.Series(lr_reg.coef_, index=X_features_ohe.columns)
coef_sort = coef. sort_values(ascending=False)[:20]
sns.barplot(x=coef_sort.values, y=coef_sort.index)from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
# 랜덤 포레스트 , GBM, XGBoost, LightGBM mode] 별로 평가 수행
rf_reg = RandomForestRegressor(n_estimators=500)
gbm_reg = GradientBoostingRegressor(n_estimators=500)
xgb_reg = XGBRegressor(n_estimators=500)
lgbm_reg = LGBMRegressor(n_estimators=500)
for model in [rf_reg, gbm_reg, xgb_reg, lgbm_reg]:
# XGBoost 의 경우 Dataframe 이 입력될 경우 버전에 따라 오류 발생 가능. ndarray 로 변환.
get_model_predict(model,X_train.values, X_test.values, y_train.values,
y_test.values,is_expm1=True)10. 회귀 실습 - 캐글 주택 가격: 고급 회귀 기법
데이터 사전 처리(Preprocessing)
import warnings
warnings. filterwarnings('ignore')
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
house_df_org = pd.read_csv('/content/sample_data/house_price.csv')
house_df = house_df_org.copy()
house_df.head(3)Target 값은 맨 마지막 칼럼인 SalePrice 입니다. 데이터 세트의 전체 크기와 칼럼의 타입 , 그리고 Null 이 있는 칼럼과 그 건수를 내림차순으로 출력해 보겠습니다.
print('데이터 세트의 Shape:', house_df.shape)
print('\n 전체 피처의 type \n', house_df.dtypes. value_counts())
isnull_series = house_df.isnull().sum()
print('\n Null 칼럼과 그 건수:\n', isnull_series[isnull_series > 0].sort_values(ascending=False))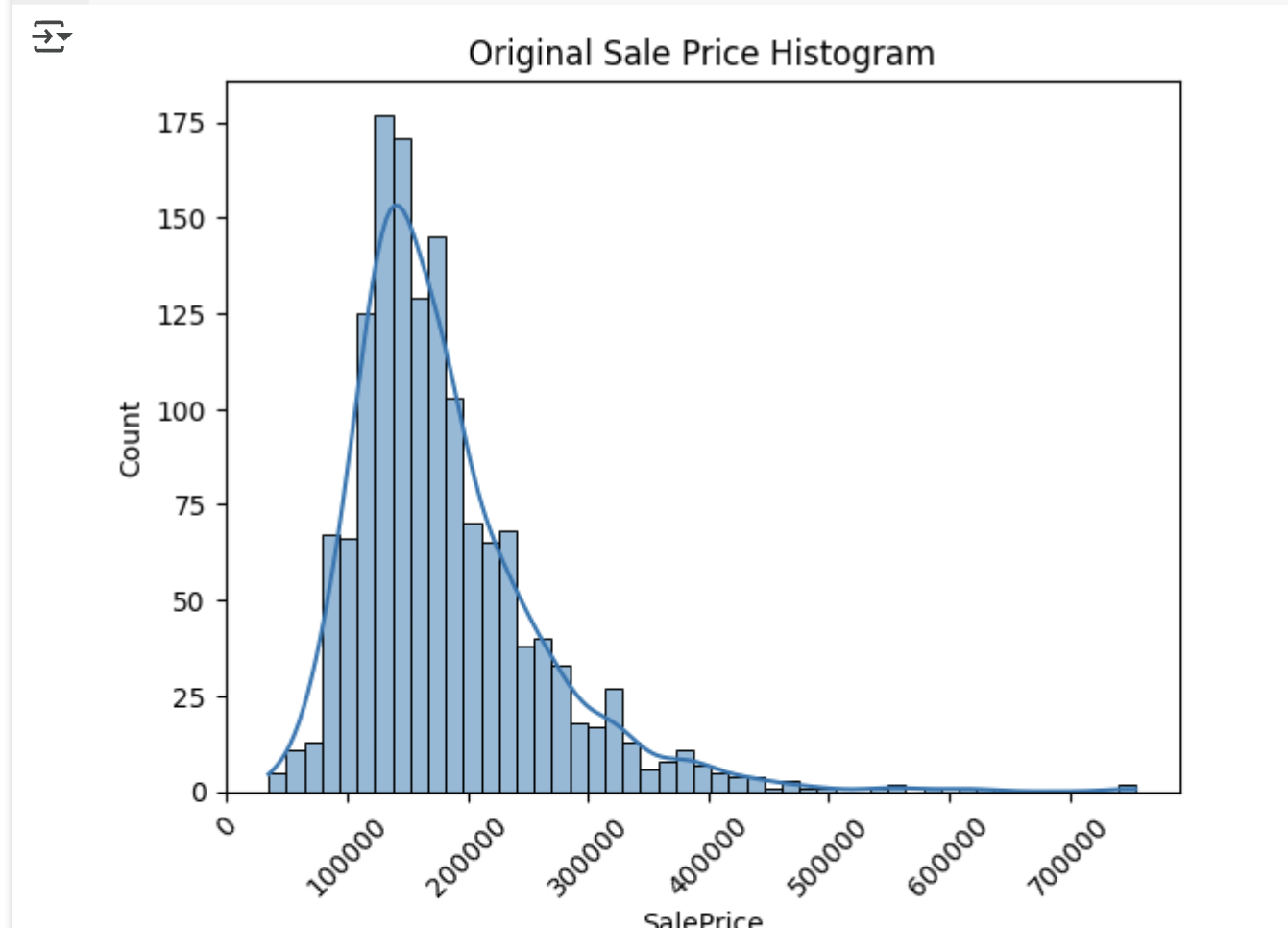
- 전체 1460개 레코드, 81개 피처 중 43개는 문자형, 나머지는 숫자형
- Null 값이 많은 피처들 (PoolQC, MiscFeature, Alley, Fence)는 1000개 이상이 결측치이므로 제거 예정
- 타깃 변수는 정규 분포가 아닌 왼쪽으로 왜곡된 분포를 가짐
- 회귀 모델 적용 전, 타깃 변수 분포를 정규화할필요가 있음 (예: 로그 변환)
plt.title( 'Original Sale Price Histogram')
plt.xticks(rotation=45)
sns.histplot(house_df['SalePrice'], kde=True)
plt.show()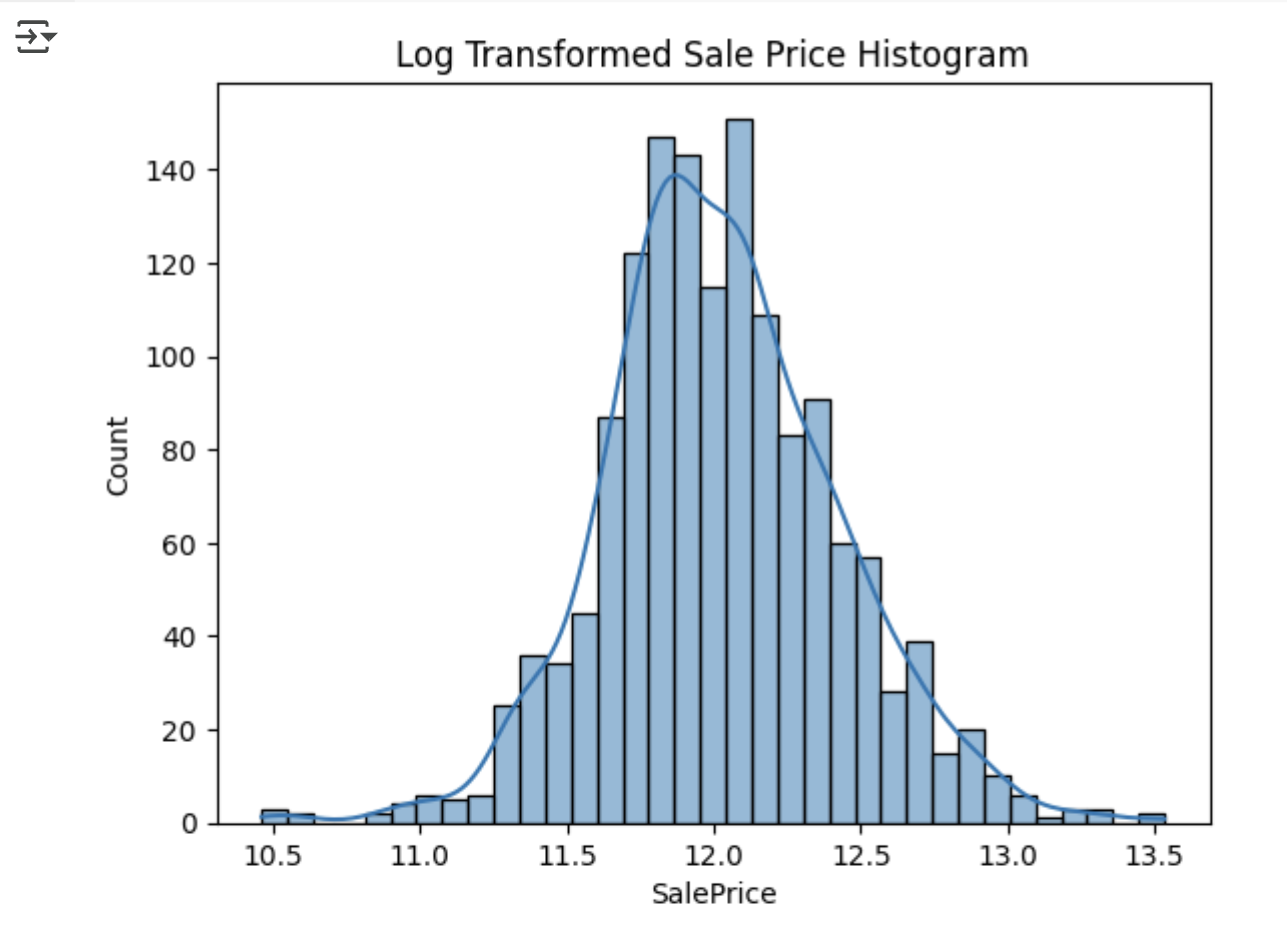
정규 분포가 아닌 결값을 정규 분포 형태로 변환하기 위해 로그 변환 (Log Transformation)을 적용하겠습니다.
plt.title('Log Transformed Sale Price Histogram')
log_SalePrice = np.log1p(house_df['SalePrice'])
sns.histplot(log_SalePrice, kde=True)
plt.show()
print('get_dummies() 수행 전 데이터 Shape:', house_df.shape)
house_df_ohe = pd.get_dummies(house_df)
print('get_dummies() 수행 후 데이터 Shape:', house_df_ohe.shape)
null_column_count = house_df_ohe.isnull().sum()[house_df_ohe.isnull().sum() > 0] # Changed { to (
print('## Null 피처의 Type :\n', house_df_ohe.dtypes[null_column_count.index]) # Changed ( to [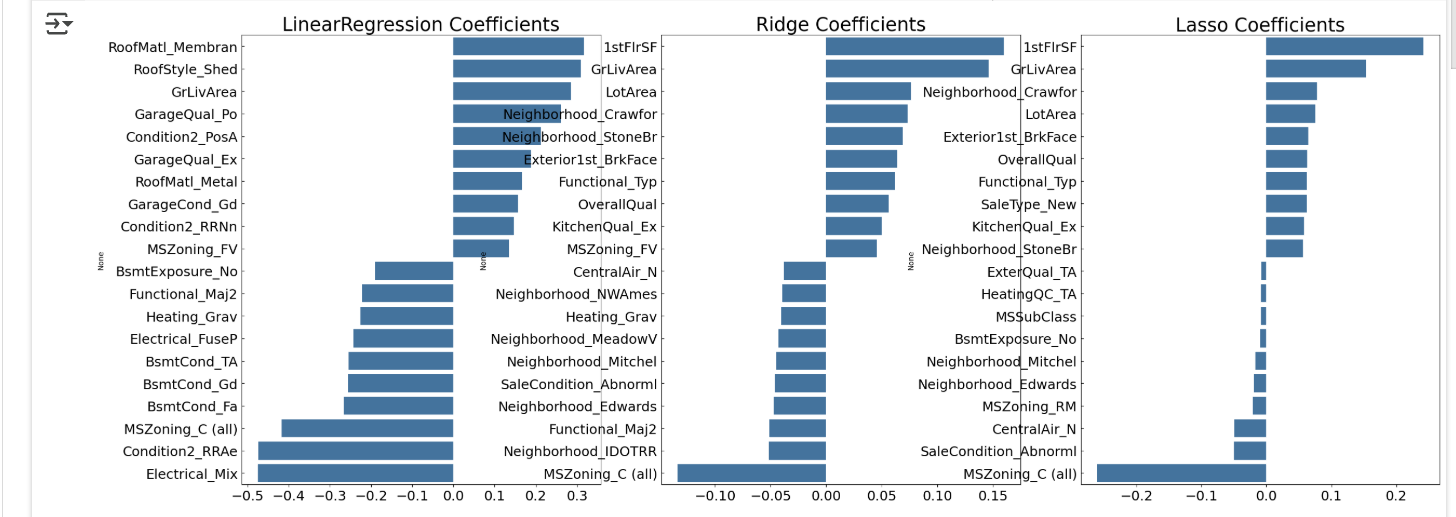
원- 핫 인코딩 후 피처가 75 개에서 271 개로 증가했습니다. 그리고 Null 값을 가진 피처는 이제 존재
하지 않음
선형 회귀 모델 학습 / 예측 / 평가
- SalePrice는 이미 로그 변환되었기 때문에 예측값 역시 로그 변환값을 예측한 결과임
- 따라서 로그 변환된 실제값과 예측값 간의 RMSE를 계산하면 RMSLE 평가가 자동적으로 적용되는 것과 동일
여러 모델의 로그 변환된 RMSE 를 측정할 것이므로 이를 계산하는 함수를 먼저 생성하겠습니다.
def get_rmse(model):
pred = model.predict(X_test)
mse = mean_squared_error (y_test, pred)
rmse = np.sqrt (mse)
print(model.__class__.__name__,'로그 변환된 RMSE:', np.round(tmse, 3 ))
return rmse
def get_rmses(models):
rmses = [ ]
for model in models:
rmse = get_rmse(model)
rmses.append(rmse)
return rmsesget_rmse(model) 은 단일 모델의 RMSE 값을 , get_rmses(models)는 get_rmse()를 이용해 여러 모델의 RMSE 값을 반환합니다. 이제 선형 회귀 모델을 학습하고 예측, 평가해 보겠습니다.
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice', axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.2,
random_state=156)
# LinearRegression, Ridge, Lasso 학습 , 예측 , 평가
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
ridge_reg = Ridge()
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso()
lasso_reg.fit(X_train, y_train)
models = [lr_reg, ridge_reg, lasso_reg]
get_rmses(models)- 라쏘 회귀는 다른 회귀 방식에 비해 성능이 낮게 나옴
- alpha 하이퍼파라미터 튜닝이 필요함
def get_top_bottom_coef(model, n=10):
#coef_ 속성을 기반으로 Series 객체를 생성. index 는 칼럼명.
coef = pd.Series(model.coef_, index=X_features.columns)
#+ 상위 10 개 , - 하위 10 개의 회귀 계수를 추출해 반환.
coef_high = coef.sort_values(ascending=False).head(n)
coef_low = coef.sort_values(ascending=False).tail(n)
return coef_high, coef_low- 생성한 getop_bottom_coef(model, n=10) 함수를 이용해 모델별 회귀 계수를 시각화
- 시각화를 위한 함수로 visualize_coefficien (models) 를 생성합니다. 해당 함수는 list 객체로 모델을 입력받아 모델별로 회귀 계수 상위 10 개 , 하위 10 개를 추출해 가로 막대 그래프 형태로 출력
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
def visualize_coefficient(models):
fig, axs = plt.subplots(figsize=(24, 10), nrows=1, ncols=3)
fig.tight_layout(pad=5.0)
for i_num, model in enumerate(models):
coef_high, coef_low = get_top_bottom_coef(model)
coef_concat = pd.concat([coef_high, coef_low])
sns.barplot(x=coef_concat.values, y=coef_concat.index, ax=axs[i_num])
axs[i_num].set_title(f'{model.__class__.__name__} Coefficients', size=25)
axs[i_num].tick_params(axis="y", direction="in", pad=5)
for label in axs[i_num].get_xticklabels() + axs[i_num].get_yticklabels():
label.set_fontsize(18)
plt.show()
# 모델 리스트 전달
models = [lr_reg, ridge_reg, lasso_reg]
visualize_coefficient(models)
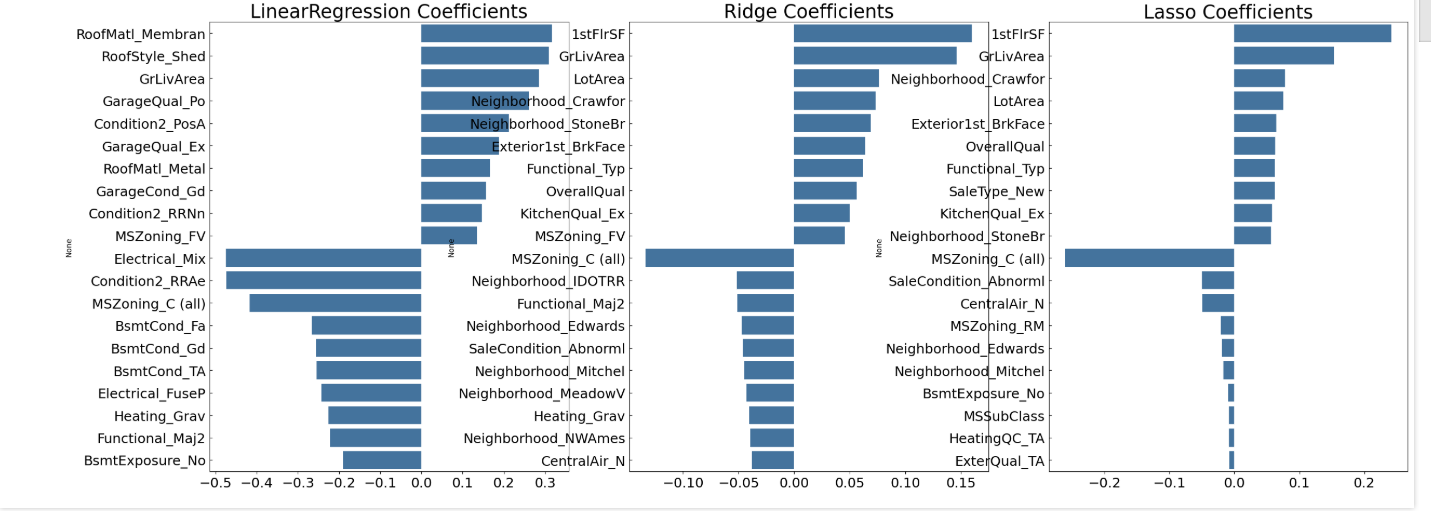
- LinearRegression과 Ridge는 회귀 계수 분포가 유사함
- Lasso는 대부분의 회귀 계수가 매우 작고 YearBuilt 피처만 상대적으로 큼
- Lasso의 회귀 계수 분포가 달라 모델 성능이 떨어진 원인일 가능성 있음
- 각 모델에 대해 평균 RMSE 측정해 모델 간 성능 차이를 공정하게 비교함
from sklearn.model_selection import cross_val_score
import numpy as np
def get_avg_rmse_c(models):
for model in models:
# 분할하지 않고 전체 데이터로 Cross_val_Score) 수행. 모델별 CV RMSE 값과 평균 RMSE 출력
rmse_list = np.sqrt(-cross_val_score(model, X_features, y_target,
scoring="neg_mean_squared_error", cv=5))
rmse_avg = np.mean(rmse_list)
print('\n{0} CV RMSE 값 리스트 : {1}'.format(model.__class__.__name__, np.round(rmse_list, 3)))
print('{0} CV RMSE 평균: {1}'.format(model.__class__.__name__, np.round(rmse_avg, 3)))
# 앞 예제에서 학습한 ridge_reg, Lasso_reg 모델의 CV RMSE 값 출력
models = [ridge_reg, lasso_reg]
get_avg_rmse_c(models)
- 5개의 교차 검증 세트로 학습 후에도 Lasso의 성능은 Ridge보다 낮게 나타남
- 이를 해결하기 위해 하이퍼파라미터 alpha 값을 조정
- 반복 작업을 위해 print_best_params(model, params) 함수 생성
from sklearn.model_selection import GridSearchCV
import numpy as np
def print_best_params(model, params):
grid_model = GridSearchCV(model, param_grid=params,
scoring='neg_mean_squared_error', cv=5)
grid_model.fit(X_features, y_target)
rmse = np.sqrt(-1 * grid_model.best_score_)
print('{0} 5 CV 시 최적 평균 RMSE 값 : {1}, 최적 alpha: {2}'.format(
model.__class__.__name__, np.round(rmse, 4), grid_model.best_params_))
ridge_params = { 'alpha': [0.05, 0.1, 1, 5, 8, 10, 12, 15, 20] }
lasso_params = { 'alpha': [0.001, 0.005, 0.008, 0.05, 0.03, 0.1, 0.5, 1, 5, 10] }
print_best_params(ridge_reg, ridge_params)
print_best_params(lasso_reg, lasso_params)
# 앞의 최적화된 alpha 값으로 모델 학습 및 평가
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
ridge_reg = Ridge(alpha=12)
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso(alpha=0.001)
lasso_reg.fit(X_train, y_train)
# 모든 모델의 RMSE 출력
models = [lr_reg, ridge_reg, lasso_reg]
get_rmses(models)
# 모든 모델의 회귀 계수 시각화
visualize_coefficient(models)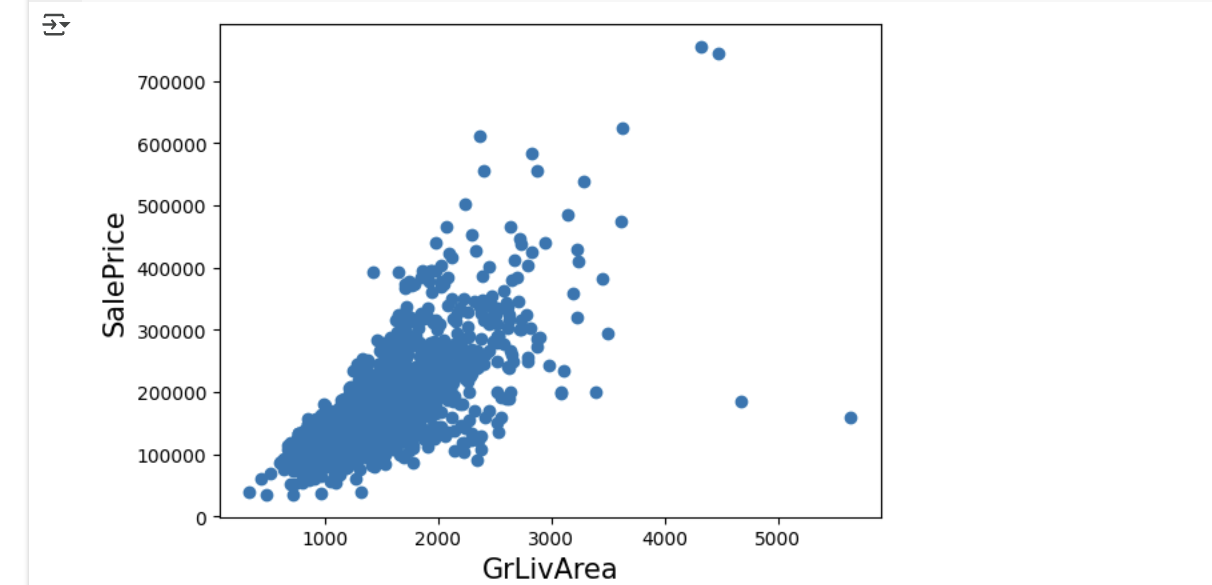
- alpha 최적화 후 릿지와 라쏘 모델의 예측 성능 향상, 특히 라쏘 모델이 큰 개선을 보임
- 회귀 계수 분포: 라쏘는 여전히 릿지에 비해 계수 값이 작지만, 중요 피처는 유사하게 선택됨
- 주의점: 원-핫 인코딩된 카테고리형 피처는 skew 계산 대상에서 제외해야 함 → 왜곡 판단에 적절하지 않기 때문에, 로그 변환은 house_df_ohe가 아닌 house_df 에 적용해야 함
from scipy.stats import skew
# object가 아닌 숫자형 피처의 칼럼 index 객체 추출
features_index = house_df.dtypes[house_df.dtypes != 'object'].index
# 숫자형 칼럼들의 왜도 계산
skew_features = house_df[features_index].apply(lambda x: skew(x))
# Skew(왜도) 정도가 1 이상인 칼럼만 추출
skew_features_top = skew_features[skew_features > 1]
# 출력
print(skew_features_top.sort_values(ascending=False))
house_df[skew_features_top.index] = np.log1p(house_df[skew_features_top.index])- 로그 변환 후에도 일부 피처는 여전히 왜곡이 심하지만, 추가적인 로그 변환은 개선 효과가 없기 때문에 그대로 유지
- 로그 변환이 적용된 house_df를 기반으로 다시 원-핫 인코딩을 수행해 house_df_ohe 생성
이후:
- 피처(X)와 타깃(y) 데이터 세트 재구성
- train_test_split으로 학습/테스트 세트 분리
- print_best_params() 함수 사용하여 릿지, 라쏘 모델의 최적 alpha 및 RMSE 재도출
from sklearn.model_selection import train_test_split
import pandas as pd
# 원-핫 인코딩
house_df_ohe = pd.get_dummies(house_df)
# 타깃/피처 나누기
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice', axis=1, inplace=False)
# 학습/테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.2,
random_state=156)
# 최적 하이퍼파라미터 후보 설정
ridge_params = { 'alpha': [0.05, 0.1, 1, 5, 8, 10, 12, 15, 20] }
lasso_params = { 'alpha': [0.001, 0.005, 0.008, 0.05, 0.03, 0.1, 0.5, 1, 5, 10] }
# 최적 alpha 및 RMSE 출력
print_best_params(Ridge(), ridge_params)
print_best_params(Lasso(), lasso_params)
- 릿지 모델의 최적 alpha 값: 12 → 10
- 5-폴드 평균 RMSE 향상
- 로그 변환 적용 후 모델 성능 전반적으로 개선됨
- 학습/예측/평가 결과에서 GrLivArea(주거 공간 크기)가 가장 높은 회귀 계수를 가짐
→ 주거 면적이 주택 가격에 가장 큰 영향을 준다는 상식적인 결과 도출
주택 가격 데이터가 변환되기 이전의 원본 데이터 세트인 house_df_org 에서 GrLivArea 와 타깃 값인
SalePrice 의 관계를 시각화
plt.scatter(x = house_df_org[ 'GrLivArea'], y = house_df_org['SalePrice'])
plt.ylabel('SalePrice'
, fontsize=15)
plt.xlabel('GrLivArea', fontsize=15)
plt.show()- GrLivArea와 SalePrice는 양의 상관관계가 큼
→ 주거 공간이 클수록 일반적으로 주택 가격도 높음 - GrLivArea > 4000이면서 SalePrice < $500,000인 2개 데이터는 이상치
→ 상관관계에 어긋나는 값으로 제외 필요 - house_df_ohe 데이터프레임에서
로그 변환된 GrLivArea, SalePrice 조건 기반으로 불린 인덱싱 후 drop()으로 이상치 제거
import numpy as np
cond1 = house_df_ohe['GrLivArea'] > np.log1p(4000)
cond2 = house_df_ohe['SalePrice'] < np.log1p(500000)
outlier_index = house_df_ohe[cond1 & cond2].index
print('이상치 레코드 index:', outlier_index.values)
print("이상치 삭제 전 house_df_ohe shape:", house_df_ohe.shape)
house_df_ohe.drop(outlier_index, axis=0, inplace=True)
print('이상치 삭제 후 house_df_ohe shape:', house_df_ohe.shape)
from sklearn.model_selection import train_test_split
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice', axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target,
test_size=0.2, random_state=156)
ridge_params = { 'alpha': [0.05, 0.1, 1, 5, 8, 10, 12, 15, 20] }
lasso_params = { 'alpha': [0.001, 0.005, 0.008, 0.05, 0.03, 0.1, 0.5, 1, 5, 10] }
print_best_params(Ridge(), ridge_params)
print_best_params(Lasso(), lasso_params)
-
단 두 개의 이상치 제거만으로도 모델 성능이 크게 향상됨
-
GrLivArea는 예측에 영향력이 큰 피처이므로
관련된 이상치 제거가 성능 개선에 매우 효과적 -
이상치 탐지와 제거는 중요한 전처리 과정
→ 특히 예측력 높은 피처를 중심으로 분석 필요 -
머신러닝에서는 1차 가공 → 모델링 → 가공 & 튜닝 반복이 반복적 최적화 과정이 중요함
회귀 트리 모델 학습/예측/평가
from xgboost import XGBRegressor
xgb_params = {'n_estimators':[1000]}
xgb_reg = XGBRegressor(n_estimators=1000, learning_rate=0.05, colsample_bytree=0.5, subsample=0.8)
print_best_params(xgb_reg, xgb_params)LightGBM
회귀 트리를 적용
from lightgbm import LGBMRegressor
lgbm_params = {'n_estimators': [1000]}
lgbm_reg = LGBMRegressor(n_estimators=1000, learning_rate=0.05, num_leaves=4,
subsample=0.6, colsample_bytree=0.4, reg_lambda=10, n_jobs=-1)
print_best_params(lgbm_reg, lgbm_params)회귀 모델의 예측 결과 혼합을 통한 최종 예측
- 예측값 혼합(앙상블): 여러 회귀 모델의 예측값을 가중 평균하여 최종 예측값을 계산
- 예: Final = A_pred 0.4 + B_pred 0.6
- 실습 예시: Ridge와 Lasso 모델의 예측값을 혼합하여 최종 예측 수행
- 혼합 모델과 개별 모델의 RMSE 비교를 위한 함수 get_rmse_pred() 구현
- 혼합 비율을 조정하여 개별 모델보다 더 낮은 RMSE 달성 가능
def get_rmse_pred(preds):
for key in preds.keys():
pred_value = preds [key]
mse = mean_squared_error(y_test, pred_value)
rmse = np.sqrt(mse)
print('{0} 모델의 RNSE: {1}'.format(key, rmse))
# 개별 모델의 학습
ridge_reg = Ridge(alpha=8)
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso(alpha=0.001)
lasso_reg.fit(X_train, y_train)
# 개별 모델 예측
ridge_pred = ridge_reg.predict(X_test)
lasso_pred = lasso_reg.predict(X_test)
# 개별 모델 예측값 혼합으로 최종 예측값 도출
pred = 0.4 * ridge_pred + 0.6 * lasso_pred
preds = {' 최종 혼합 ' : pred,
'Ridge': ridge_pred,
'Lasso': lasso_pred}
# 최종 혼합 모델 , 개별 모델의 RNSE 값 출력
get_rmse_pred(preds)- 최종 혼합 모델의 RMSE가 개별 모델보다 성능 면에서 약간 개선됨
- 릿지 모델 예측값에 0.4를 곱하고 라쏘 모델 예측값에 0.6을 곱한 뒤 더함
- 0.4나 0.6을 정하는 특별한 기준은 없음
- 두 개 중 성능이 조금 좋은 쪽에 가중치를 약간 더 둠
xgb_reg = XGBRegressor(n_estimators=1000, learning_rate=0.05,
colsample_bytree=0.5, subsample=0.8)
lgbm_reg = LGBMRegressor(n_estimators=1000, learning_rate=0.05, num_leaves=4,
subsample=0.6, colsample_bytree=0.4, reg_lambda=10, n_jobs=-1)
xgb_reg. fit(X_train, y_train)
lgbm_reg. fit(X_train, y_train)
xgb_pred = xgb_reg.predict(X_test)
lgbm_pred = lgbm_reg.predict(X_test)
pred = 0.5 * xgb_pred + 0.5 * lgbm_pred
preds = {' 최종 혼합': pred,
'XGBM': xgb_pred,
'LGBM': lgbm_pred}
get_rmse_pred(preds)스태킹 앙상블 모델을 통한 회귀 예측
- 최종 메타 모델이 학습할 피처 데이터는 원본 학습 피처 세트로 학습한 개별 모델의 예측값을 스태킹 형태로 결합한 것임
- 개별 모델을 스태킹 모델로 제공하기 위해 데이터 세트를 생성하는 함수는 get_stacking_base_datasets()임
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
import numpy as np
# 개별 기반 모델에서 최종 메타 모델이 사용할 학습 및 테스트용 데이터를 생성하기 위한 함수.
def get_stacking_base_datasets(model, X_train_n, y_train_n, X_test_n, n_folds ):
# 지정된 n_folds 값으로 KFold 생성.
kf = KFold(n_splits=n_folds, shuffle=False)
# 추후에 메타 모델이 사용할 학습 데이터 반환을 위한 넘파이 배열 초기화
train_fold_pred = np.zeros((X_train_n.shape[0], 1))
test_pred = np.zeros((X_test_n.shape[0], n_folds))
print(model.__class__.__name__, ' model 시작 ')
for folder_counter, (train_index, valid_index) in enumerate(kf.split(X_train_n)):
# 입력된 학습 데이터에서 기반 모델이 학습 / 예측할 폴드 데이터 세트 추출
print('lt 폴드 세트 : ', folder_counter, ' 시작 ')
X_tr = X_train_n[train_index]
y_tr = y_train_n[train_index]
X_te = X_train_n[valid_index]
# 폴드 세트 내부에서 다시 만들어진 학습 데이터로 기반 모델의 학습 수행.
model.fit(X_tr, y_tr)
# 폴드 세트 내부에서 다시 만들어진 검증 데이터로 기반 모델 예측 후 데이터 저장.
train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1, 1)
# 입력된 원본 테스트 데이터를 폴드 세트 내 학습된 기반 모델에서 예측 후 데이터 저장.
test_pred[:, folder_counter] = model.predict(X_test_n)
# 폴드 세트 내에서 원본 테스트 데이터를 예측한 데이터를 평균하여 테스트 데이터로 생성
test_pred_mean = np.mean(test_pred, axis=1).reshape(-1, 1)
# train_fold_pred 는 최종 메타 모델이 사용하는 학습 데이터 , test_pred_mean 은 테스트 데이터
return train_fold_pred, test_pred_mean
get_stacking_base_datasets()는 다음과 같은 인자를 받음:
- 개별 기반 모델
- 원본 학습용 피처 데이터
- 원본 학습용 타깃 데이터
- 원본 테스트용 피처 데이터
함수 내부 로직:
- K-폴드 교차 검증을 통해 원본 학습 데이터를 여러 폴드로 분할
- 각 폴드에서 학습/예측을 수행하여 예측 결과를 저장
- 예측 결과는 메타 모델의 학습 피처 세트로 사용됨
- 테스트 데이터에 대해서는 각 폴드에서 예측한 결과를 평균하여 테스트 피처 세트를 생성
적용 모델:
- Ridge
- Lasso
- XGBoost
- LightGBM
# get_stacking_base_datasets()는 넘파이 ndarray를 인자로 사용하므로 Datarame을 넘파이로 변환.
X_train_n = X_train.values
X_test_n = X_test.values
y_train_n = y_train.values
# 각 개별 기반 (Base) 모델이 생성한 학습용 / 테스트용 데이터 반환.
ridge_train, ridge_test = get_stacking_base_datasets(ridge_reg, X_train_n, y_train_n, X_test_n, 5)
lasso_train, lasso_test = get_stacking_base_datasets(lasso_reg, X_train_n, y_train_n, X_test_n, 5)
xgb_train, xgb_test = get_stacking_base_datasets(xgb_reg, X_train_n, y_train_n, X_test_n, 5)
lgbm_train, lgbm_test = get_stacking_base_datasets(lgbm_reg, X_train_n, y_train_n, X_test_n, 5)각 개별 모델이 반환하는 학습용 피처 데이터와 테스트용 피처 데이터 세트를 결합해 최종 메타 모델
에 적용해 보겠습니다. 메타 모델은 별도의 라쏘 모델을 이용하며 , 최종적으로 예측 및 RMSE 를 측정
# 개별 모델이 반환한 학습 및 테스트용 데이터 세트를 스태킹 형태로 결합.
Stack_final_X_train = np.concatenate((ridge_train, lasso_train, xgb_train, lgbm_train), axis=1)
Stack_final_X_test = np.concatenate((ridge_test, lasso_test,xgb_test, lgbm_test), axis=1)
# 최종 메타 모델은 라쏘 모델을 적용.
meta_model_lasso = Lasso(alpha=0.0005)
# 개별 모델 예측값을 기반으로 새롭게 만들어진 학습 / 테스트 데이터로 메타 모델 예측 및 RMSE 측정.
meta_model_lasso. fit(Stack_final_X_train, y_train)
final = meta_model_lasso.predict(Stack_final_X_test)
mse = mean_squared_error (y_test, final)
rmse = np.sqrt (mse)
print(' 스태킹 회귀 모델의 최종 RMSE 값은 :', mse)