github : https://github.com/nalinzip/ml_study
colab pt. 01 : https://colab.research.google.com/github/nalinzip/ml_study/blob/main/ML_week4.ipynb
colab pt.02 : https://colab.research.google.com/drive/1wFMY1_XIRFz8CSYaTwMBqoFksON1NkXK?usp=sharing
1. 분류(Classification)의 개요
- 지도학습은 정답(Label)이 있는 데이터를 기반으로 학습하는 머신러닝 방식
- 대표 유형: 분류(Classification)
- 피처와 레이블을 이용해 머신러닝 알고리즘이 모델을 학습
- 학습된 모델은 새로운 데이터의 레이블을 예측
- 기존 데이터의 레이블 패턴을 인식하고, 이를 바탕으로 새 데이터의 레이블을 판별
분류는 다양한 머신러닝 알고리즘으로 구현 가능
- 베이즈 (Bayes) 통계와 생성 모델에 기반한 나이브 베이즈 (Naive Bayes)
- 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀 (Logistic Regression)
- 데이터 균일도에 따른 규칙 기반의 결정 트리 (Decision Tree)
- 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신 (Support Vector Machine)
- 근접 거리를 기준으로 하는 최소 근접 (Nearest Neighbor) 알고리즘
- 심층 연결 기반의 신경망 (Neural Network)
- 서로 다른 ( 또는 같은 ) 머신러닝 알고리즘을 결합한 앙상블(Ensemble) 이 알고리즘 위주로 공부
앙상블(Ensemble)
-
앙상블은 분류 문제에서 높은 예측 성능으로 각광받는 방식
-
딥러닝을 제외한 정형 데이터 예측 분석에서는 앙상블이 널리 활용됨
앙상블은 크게 배깅(Bagging)과 부스팅(Boosting)으로 구분 -
배깅 대표: 랜덤 포레스트(Random Forest)
- 빠른 수행, 유연성, 높은 예측 성능
-
부스팅 대표: 그래디언트 부스팅(Gradient Boosting)
- 예측 성능 우수하지만 수행 시간이 길고 튜닝 어려움 -
이를 개선한 최신 부스팅 계열:
XGBoost, LightGBM → 빠르고 정확도 높음 -
최신 기법으로 스태킹(Stacking)도 함께 다룸
앙상블은 보통 동일한 알고리즘(결정 트리)을 여러 개 결합
- 결정 트리는:
적용이 쉽고, 데이터 전처리 영향이 적음
하지만 복잡한 구조로 인해 과적합 발생 가능 -> 여러 개의 약한 학습기를 결합해 오류 보완 및 성능 향상
2. 결정 트리 (Decision Tree)
- 데이터에 존재하는 규칙을 학습해 트리 구조의 분류 규칙을 자동 생성
- if/else 구조로 표현 가능하며, 스무고개 게임과 유사
- 룰 기반 프로그램의 if/else 조건을 자동으로 생성하는 알고리즘
- 핵심: 어떤 기준으로 규칙을 만들어야 효율적인 분류가 가능한가 → 이 기준 선택이 결정 트리 성능에 큰 영향
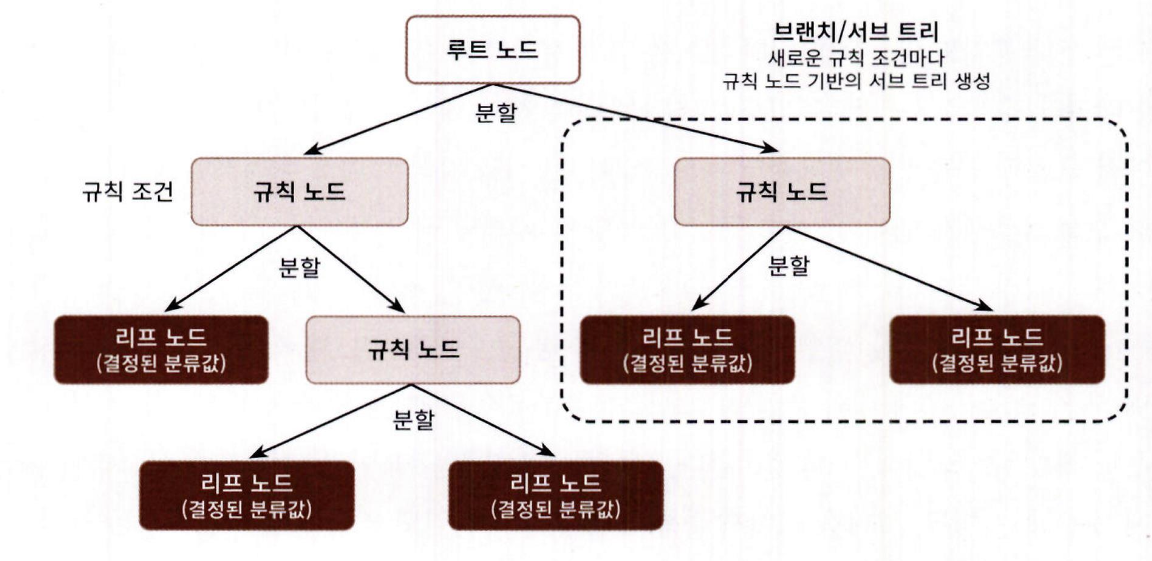
트리 구성 요소:
규칙 노드(Decision Node): 조건 판단
리프 노드(Leaf Node): 최종 분류 결과
서브 트리(Sub Tree): 새로운 규칙 조건에 따른 분기 구조-
많은 규칙 → 복잡한 분류 구조 → 과적합(overfitting) 위험 증가
-
트리 깊이(depth)가 깊을수록 예측 성능 저하 가능성 높아짐
-
가능한 한 적은 결정 노드로 높은 예측 정확도를 가지려면 데이터를 분류할 때 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 함. → 어떻게 트리를 분할 (Split) 할 것인가가 중요한데 최대한 균일한 데이터 세트를 구성할 수 있도록 분할하는 것이 필요함.
균일한 데이터 세트
가장 균일한 데이터 세트부터 순서대로 나열

- C가 가장 균일도가 높고, 그다음 B, 마지막으로 A 순
- C는 모두 검은 공으로 구성되어 데이터가 모두 균일
- B는 일부 하얀 공이 있지만 대부분 검은 공으로 구성
- A는 검은 공과 하얀 공 비율이 비슷하여 균일도가 가장 낮음
- 데이터 세트의 균일도는 데이터를 구분하는 데 필요한 정보의 양에 영향을 줌
- C는 별다른 정보 없이도 예측 가능하지만, A는 더 많은 정보가 필요함
- 결정 노드는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건을 만듦
- 정보 균일도가 높은 방향으로 데이터 세트를 쪼개면서 예측 수행
- 자식 트리로 내려가며 반복적으로 균일도 높은 자식 데이터 세트를 생성
- 예) 박스 안 30개 레고 블록 → 속성: 형태(동그라미, 네모, 세모), 색깔(노랑, 빨강, 파랑)
노랑 블록은 모두 동그라미 → 첫 번째 조건은 if 색깔 == '노란색'
노란색은 쉽게 예측 가능하므로 첫 규칙으로 적합 - 이후 나머지 블록에 대해 다시 균일도 기준으로 분류 진행
이러한 정보의 균일도를 측정하는 대표적인 방법은 엔트로피를 이용한 정보 이득(Information Gain) 지수와 지니 계수가 있음.
정보 이득은 엔트로피
- 주어진 데이터 집합의 혼잡도를 의미하는데 , 서로 다른 값
이 섞여 있으면 엔트로피가 높고 , 같은 값이 섞여 있으면 엔트로피가 낮음. - 정보 이득 지수는 1 에서 엔트로피 지수를 뺀 값임.
- 즉 ,
1-엔트로피지수입니다. - 결정 트리는 이 정보 이득 지수로 분할 기준을 정합니다. 즉 , 정보 이득이 높은 속성을 기준으로 분할함.
지니 계수
- 원래 경제학에서 불평등 지수를 나타낼 때 사용하는 계수임.
- 경제학자인 코라도 지니 (Corrado Gini) 의
이름에서 딴 계수로서 0 이 가장 평등하고 1 로 갈수록 불평등함. - 머신러닝에 적용될 때는 지니 계수가 낮을수록 데이터 균일도가 높은 것으로 해석해 지니 계수가 낮은 속성을 기준으로 분할함.
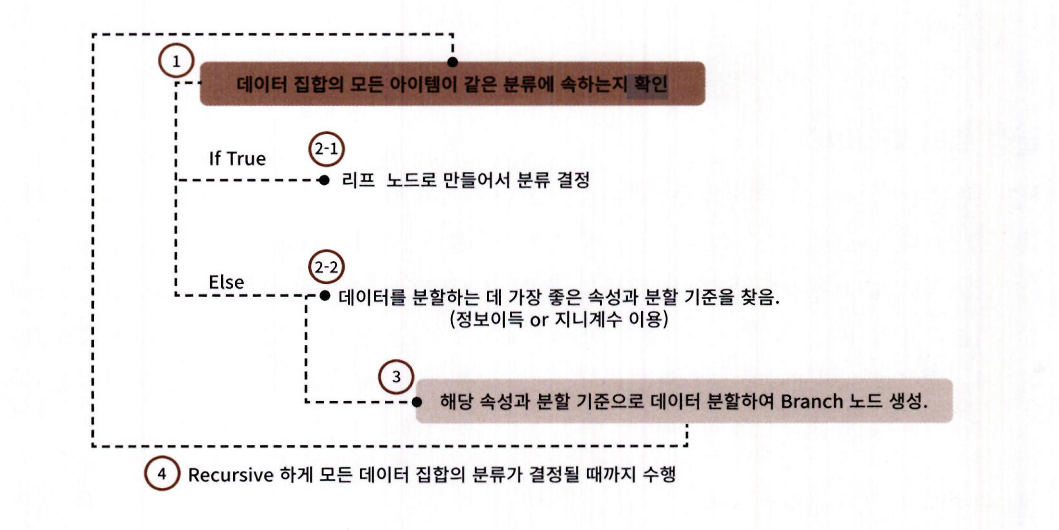
DecisionTreeClassifier는 기본적으로 지니 계수를 이용해 데이터 세트를 분할- 결정 트리 알고리즘은 정보 이득이 높거나 지니 계수가 낮은 조건을 찾아 반복적으로 분할
- 모든 데이터가 특정 분류에 속하면 분할을 멈추고 분류를 결정
결정 트리 모델의 특징
- 결정 트리는 정보의 '균일도'를 기반으로 해 알고리즘이 쉽고 직관적임
- 규칙 노드와 리프 노드 생성 과정이 명확하며 시각화가 가능
- 정보의 균일도만 신경 쓰면 되므로 피처의 스케일링과 정규화 같은 전처리 작업이 필요 없음
- 단점은 과적합으로 정확도가 떨어진다는 점
- 피처가 많고 균일도가 다양할수록 트리의 깊이가 커지고 복잡해짐
- 모든 데이터 상황을 만족하는 완벽한 규칙은 만들지 못하는 경우가 많음에도 불구하고
- 결정 트리는 학습 데이터의 정확도를 높이기 위해 계속 조건을 추가하게 됨
- 이로 인해 복잡한 학습 모델이 되고 테스트 데이터에 유연하게 대처하지 못해 예측 성능 저하
- 차라리 모든 데이터 상황을 만족하는 완벽한 규칙은 만들 수 없다고 인정하는 것이 더 나은 성능을 보장
- 트리의 크기를 사전에 제한하는 것이 오히려 성능 튜닝에 도움이 됨
| 결정 트리 장점 | 결정 트리 단점 |
|---|---|
| 쉽다. 직관적이다 | 과적합으로 알고리즘 성능이 떨어진다. -> 트리의 크기를 사전에 제한하는 튜닝 필요 |
| 피처의 스케일링이나 정규화 등의 사전 가공 영향도가 크지 않음. |
결정 트리 파라미터
- 결정 트리 알고리즘을 구현한
DecisionTreeClassifier(분류용)와DecisionTreeRegressor(회귀용)클래스 - 결정 트리 구현은 CART (Classification And Regression Trees) 알고리즘 기반
CART는 분류와 회귀 모두에 사용 가능 - 여기서는 분류용 DecisionTreeClassifier 클래스만 다룸
min_samples_split
- 노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는 데 사용됨.
- 디폴트는 2 이고 작게 설정할수록 분할되는 노드가 많아져서 과적합 가능성 증가
min_samples_leaf
- 분할이 될 경우 왼쪽과 오른쪽의 브랜치 노드에서 가져야 할 최소한의 샘플 데이터 수
- 큰 값으로 설정될수록 , 분할될 경우 왼쪽과 오른쪽의 브랜치 노드에서 가져야 할 최소한의
샘플 데이터 수 조건을 만족시키기가 어려우므로 노드 분할을 상대적으로 덜 수행함.- minsamples_spli 와 유사하게 과적합 제어 용도 , 그러나 비대칭적 (imbalanced) 데이터의
경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 이 경우는 작게 설정 필요.
max_features
- 최적의 분할을 위해 고려할 최대 피처 개수. 디폴트는 None 으로 데이터 세트의 모든 피처
를 사용해 분할 수행.- int 형으로 지정하면 대상 피처의 개수 , float 형으로 지정하면 전체 피처 중 대상 피처의 퍼
센트임- 'sqrt'는 만큼 선정
- 'auto 로 지정하면 sqrt 와 동일
- 'log' 는 전체 피처 중 log2(전체 피처 개수) 선정
- 'None' 은 전체 피처 선정
max_depth
- 트리의 최대 깊이를 규정.
- 디폴트는 None. None 으로 설정하면 완벽하게 클래스 결정 값이 될 때까지 깊이를 계속 키
우며 분할하거나 노드가 가지는 데이터 개수가 min_samples_split 보다 작아질 때까지 계속
깊이를 증가시킴.- 깊이가 깊어지면 min_samples_split 설정대로 최대 분할하여 과적합할 수 있으므로 적절한
값으로 제어 필요
max_leat_nodes
• 말단 노드 (Leat) 의 최대 개수
결정 트리 모델의 시각화
- 결정 트리 알고리즘의 규칙 구조를 시각화할 수 있는 방법은 Graphviz 패키지 사용
- Graphviz는 dot 파일 형식의 그래프를 이미지로 시각화하는 도구
- 사이킷런은 Graphviz와 연동 가능한
export_graphviz()API 제공 - 인자: 학습된 Estimator, 피처 이름 리스트, 레이블 이름 리스트
- 결과: 학습된 결정 트리 규칙을 트리 형태로 시각화
- 결정 트리의 규칙을 시각화하면 알고리즘 구조 이해가 쉬워짐
- Graphviz는 파이썬 기반이 아닌 C/C++로 개발된 패키지
꽃 데이터 세트에 결정 트리를 적용할 때 어떻게 서브 트리가 구성되고 만들어지는지 시각화
- 새로운 코랩 노트북을 생성
- 사이킷런은 결정 트리 알고리즘을 구현한
DecisionTreeClassifer를 제공해 결정 트리 모델의 학습과 예측을 수행 가능 - 붓꽃 데이터 세트를 이 DecisionTreeClassifer 를 이용해 학습한 뒤 어떠한 형태로 규칙 트리가 만들어지는지 확인해 볼 것임.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고 , 학습과 테스트 데이터 세트로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=11)
# DecisionTreeclassifer 학습.
dt_clf.fit(X_train, y_train)
- 사이킷런의 트리 모듈은 Graphviz 를 이용하기 위해 export graphviz( ) 함수를 제공
export_graphviz()는 Graphviz 가 읽어 들여서 그래프 형태로 시각화할 수 있는 출력 파일을 생성함
- export_graphviz() 에 인자로 학습이 완료된 estimator, output 파일 명 , 결정 클래스의 명칭.
피처의 명칭을 입력해주면 됨.
from sklearn.tree import export_graphviz
#export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함.
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names, \
feature_names = iris_data.feature_names, impurity=True, filled=True)생성된 출력 파일 'tree.dot'을 다음과 같이 Graphviz의 파이썬 래퍼 모듈을 호출해 결정 트리의 규칙을 시각적으로 표현 가능
import graphviz
with open ("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)-
출력된 시각화 결과를 보면 브랜치 노드와 리프 노드 구성이 한눈에 알 수 있음
-
리프 노드: 더 이상 자식 노드가 없고, 최종 클래스(레이블) 값이 결정되는 노드
-
하나의 클래스 값으로 구성되거나, 리프 노드 조건을 만족해야 함
-
브랜치 노드: 자식 노드를 가지며, 분할 규칙 조건을 포함
-
각 노드 내부에는 여러 지표가 표시되어 있음
petal length(cm) `
-
<=` 2.45 와 같이 피처의 조건이 있는 것은 자식 노드를 만들기 위한 규칙 조건임
-
이 조건이 없으면 리프 노드임.
gini
- 다음의 value=[]로 주어진 데이터 분포에서의 지니 계수임.
samples
- 현 규칙에 해당하는 데이터 건수임.
value []
- 클래스 값 기반의 데이터 건수임. 붓꽃 데이터 세트는 클래스 값으로 0, 1, 2 를 가지고 있음
- 0:Setosa, 1: Versicolor, 2: Virginica 품종을 가리킴.
- 만일 Value = [41, 40, 39] 라면 클래스 값의 순서로 Setosa 41 개, Versicolor 40 개 , Virginica 39 개로 데이터가 구성돼 있다는 의미임.
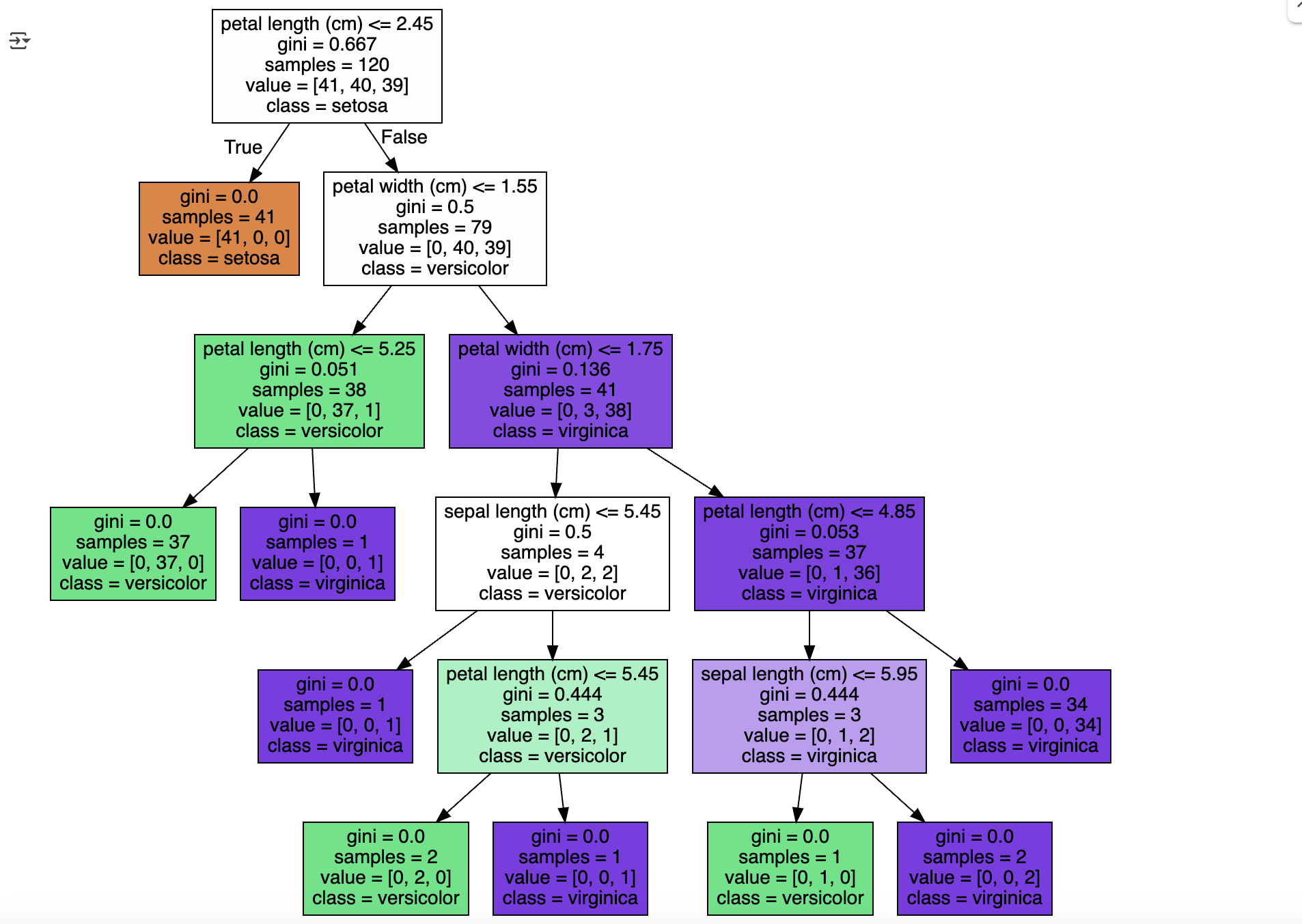
맨 위에 있는 노드를 설명해보자면
- samples = 120 개는 전체 데이터가 120 개라는 의미
- value= [41, 40, 39] 는 Setosa 41 개, Versicolor 40 개, Virginica 39 개로 데이터 구성
- sample 120 개가 value= [41, 40, 39] 분포도로 되어 있으므로 지니 계수는 0.667
- petal length (cm) <= 2.45 규칙으로 자식 노드 생성
- class= setosa 는 하위 노드를 가질 경우에 setosa 의 개수가 41 개로 제일 많다는 의미임.
- Petal length (cm) <= 2.45 규칙이
True또는False로 분기하게 되면 2번 , 3번 노드가 만들어짐. - 2번 노드는 모든 데이터가 Setosa로 결정되므로 클래스가 결정된 리프 노드
- 더 이상 2번 노드에서 분할 규칙 생성 필요 없음
- 2번 노드는 petal length (cm) <= 2.45 조건이
True일 때 도달하는 리프 노드 - 의미: petal length가 2.45 이하이면 해당 샘플은 Setosa로 예측됨
• 41개의 샘플 데이터 모두 Setosa 이므로 예측 클래스는 Setosa로 결정
• 지니 계수는 0 임.
3번 노드는 Petal length (cm) <= 2.45 가 False 인 규칙 노드
- 79개의 샘플 데이터 중 Versicolor 40 개 , Virginica 39 개로 여전히 지니 계수는 0.5 로 높으므로 다음 자식 브랜치 노드로
분기할 규칙 필요- petal width (cm) <= 1.55 규칙으로 자식 노드 생성.
4번 노드는 Petal width (cm) <= 1.55 가 True
- 38개의 샘플 데이터 중 Versicolor 37 개 , Virginica 가 1 개로 대부분이 versicolor임.
- 지니 계수는 0.051 로 매우 낮으나 여전히 Versicolor와 Virginica가 혼재돼 있으므로 petal length(cm)= 5.25 라는 새로운 규칙으로 다시 자식 노드 생성
5번 노드는 Petal width (cm) <= 1.55 가 False
- 41개의 샘플 데이터 중 Versicolor 3 개 , Virginica 가 38개 대부분이 virginica임.
- 지니 계수는 0.136 으로 낮으나 여전히 Versicolor 와 Virginica 가 혼재되어 있으므로 petal width(cm) 《 = 1.75 라는 새로운
규칙으로 다시 자식 노드 생성
노드 색깔은 붓꽃 데이터의 레이블 값을 의미
-
주황색: 0 (Setosa)
-
초록색: 1 (Versicolor)
-
보라색: 2 (Virginica)
-
색이 짙을수록: 지니 계수가 낮고, 해당 레이블 샘플 데이터가 많음
-
Graphviz를 통해 결정 트리의 규칙 생성 트리 구조를 시각적으로 이해 가능
-
예: 4번 노드 → 38개 샘플 중 1개는 Virginica, 37개는 Versicolor
-
하지만 완벽한 구분을 위해 자식 노드 생성
-
이처럼 규칙을 제어하지 않으면 계속해서 분할 → 복잡한 트리 생성 → 과적합 발생
-
결정 트리는 과적합 위험이 높은 ML 알고리즘
-
대부분의 결정 트리 하이퍼 파라미터는 과적합 방지를 위한 목적
-
예: max_depth → 트리의 최대 깊이 제한
-
제한 없음에서 3으로 설정 시, 트리 구조가 더 단순해짐
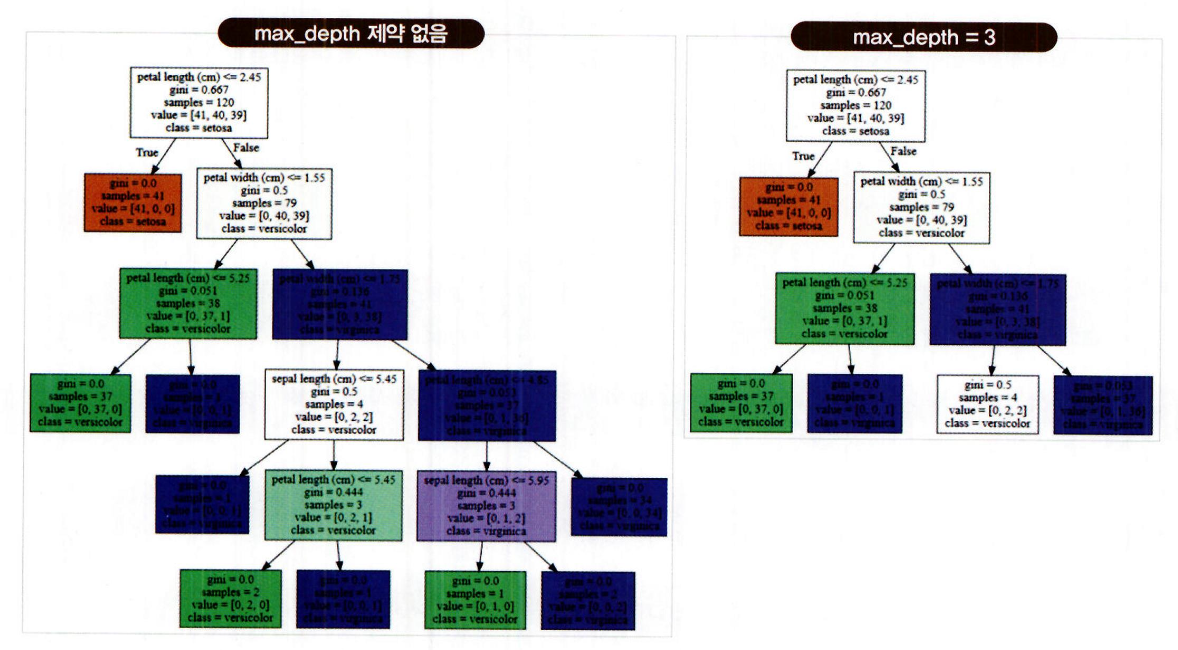
-
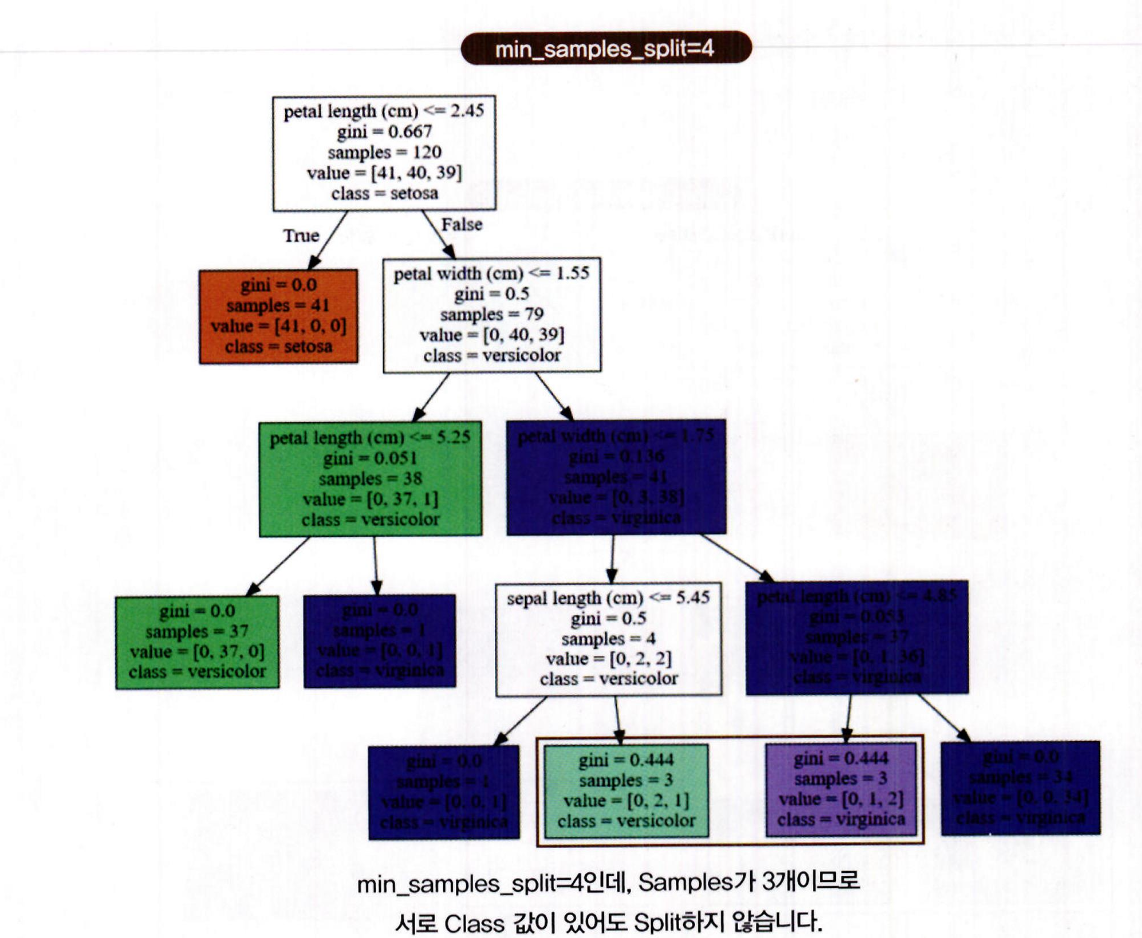
min_samples_split은 자식 규칙 노드를 분할하기 위한 최소 샘플 개수를 지정하는 하이퍼 파라미터 -
예: min_samples_split=4로 설정 시, 샘플이 4개 이상일 때만 분할 가능
-
그림에서 사선 박스로 표시된 리프 노드는 샘플 수가 3개
-
클래스 값이 [0, 2, 1], [0, 1, 2]처럼 혼합된 상태여도
-
샘플 수가 4 미만이므로 더 이상 분할하지 않고 리프 노드로 종료
-
이 설정 덕분에 트리의 깊이도 자연스럽게 감소
-
결과적으로 더 간결한 결정 트리가 생성됨
-
즉, min_samples_split은 복잡도 조절과 과적합 방지에 효과적
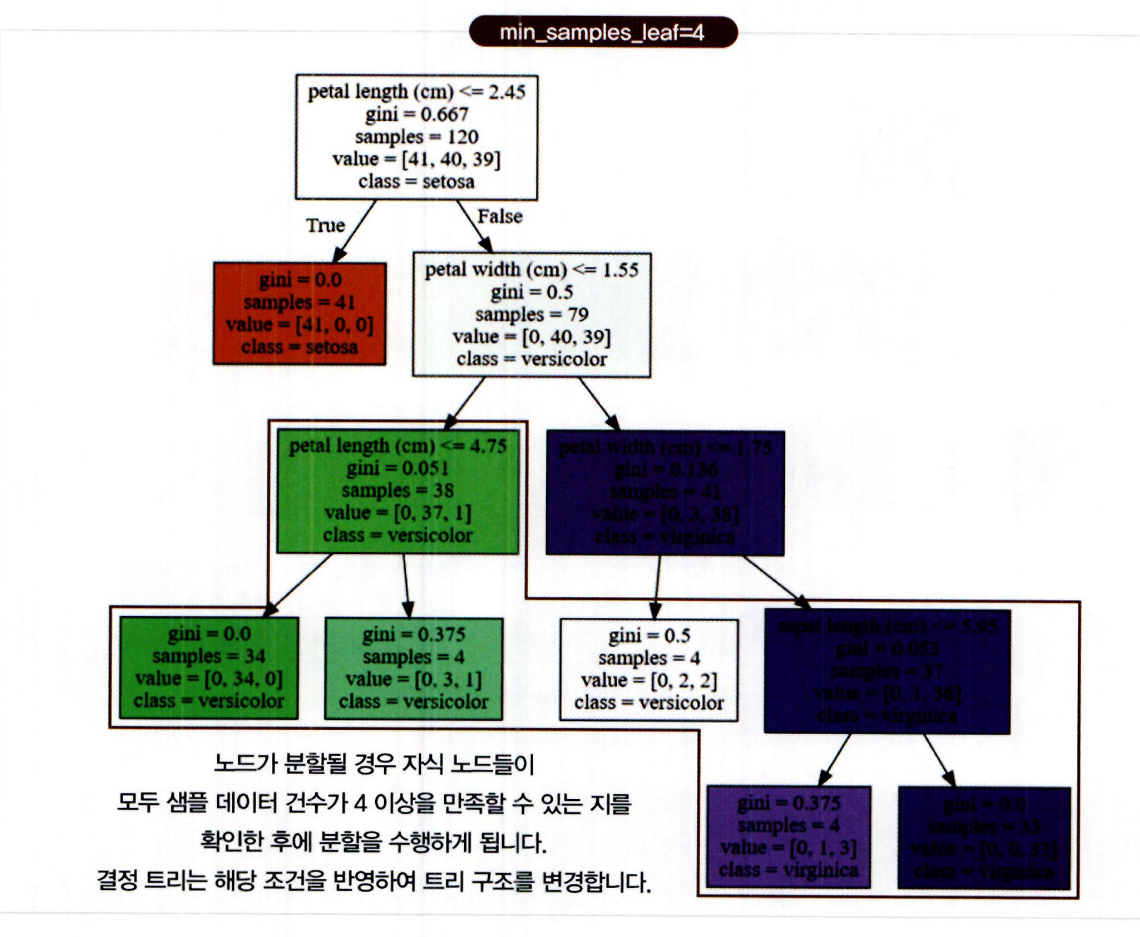
min_samples_leaf는 리프 노드가 되기 위한 자식 노드의 최소 샘플 수를 지정하는 하이퍼 파라미터- 분할 시 왼쪽과 오른쪽 자식 노드 모두
min_samples_leaf이상의 샘플을 가져야 함 - 둘 중 하나라도 조건을 만족하지 못하면 분할 없이 리프 노드로 결정됨
min_samples_leaf 값을 크게 설정할수록
분할 조건이 까다로워짐
리프 노드가 되기 쉬워짐
트리의 브랜치 노드 수 감소 → 구조 간결화
-
예: 기본값 1에서 4로 변경 시,
분할 조건이 강화되어 분할 횟수 감소
자연스럽게 결정 트리가 간결해지고 과적합 위험도 낮아짐
-
결정 트리는 균일도를 기반으로 어떤 속성(피처)을 규칙 조건으로 선택하느냐가 중요
-
몇 개의 중요한 피처가 명확한 규칙 트리를 만들어
-
모델을 좀 더 간결하고 이상치 (Outlier)
에 강한 모델을 만들 수 있기 때문임 -
사이킷런은 학습된 결정 트리에서 피처의 중요도를
feature_importances_속성으로 제공 (DecisionTreeClassifier 객체) -
feature_importances_는 ndarray 형태로 반환되며,
각 피처 순서대로 정규화된 중요도 값이 매핑됨 -
예: [0.01667014, 0.02500521, 0.03200643, 0.92631822]
→ 네 번째 피처가 가장 중요 -
이 값은 각 피처가 정보 이득 또는 지니 계수 개선에 얼마나 기여했는지를 나타냄
-
일반적으로 값이 높을수록 해당 피처의 중요도도 높음
-
학습된
DecisionTreeClassifier객체df_clf에서feature_importances_속성을 가져와 피처별 중요도 표현(막대그래프) 가능
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importances: \n{0}".format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names, dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
# feature importance를 colum 별로 시각화하기
sns.barplot(x=dt_clf.feature_importances_, y=iris_data.feature_names)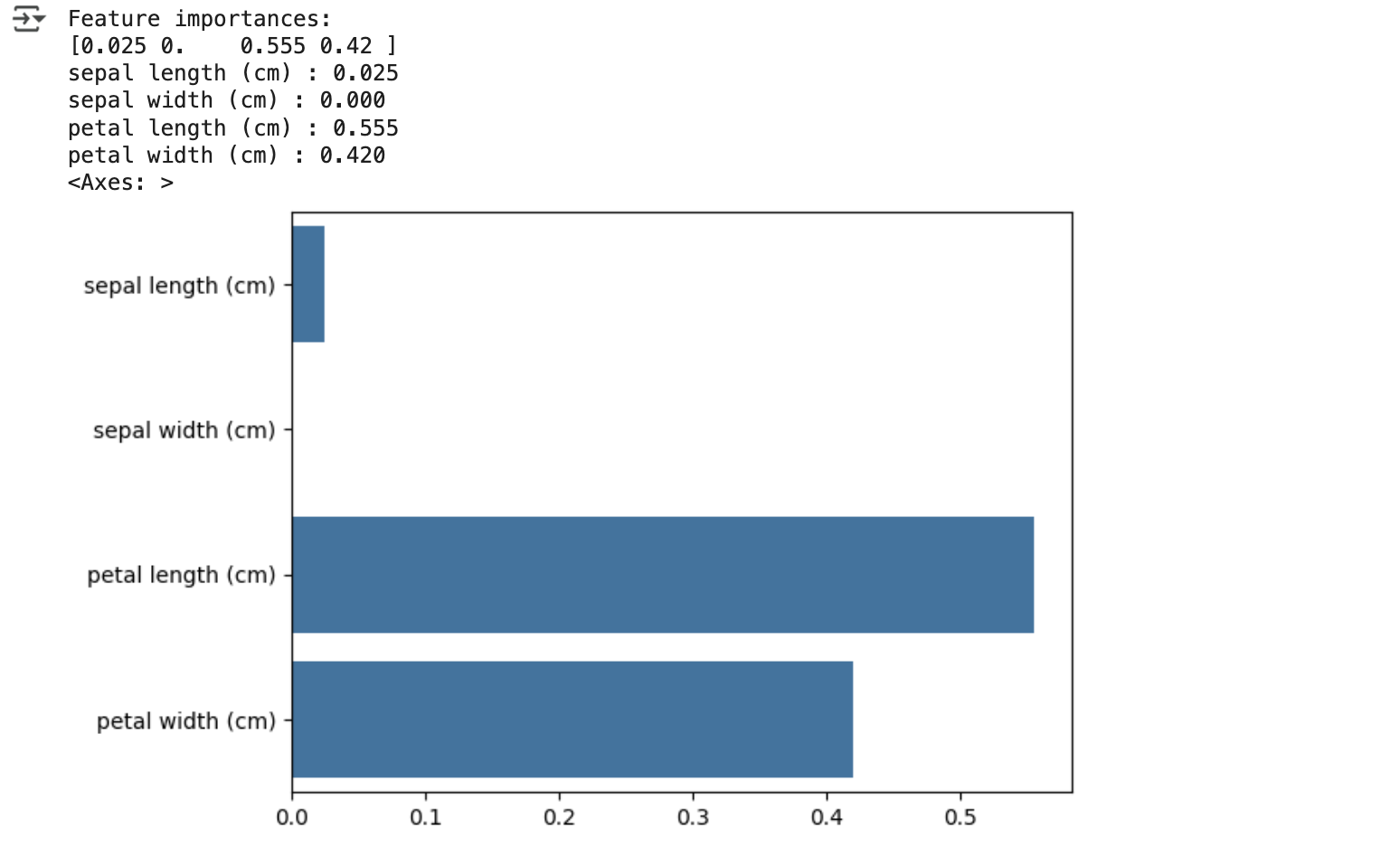
- 여러 피처 중 petal length가 가장 높은 피처 중요도를 가짐
- 다른 알고리즘들은 블랙박스처럼 내부 동작 원리가 복잡- 하지만, 결정 트리는 직관적인 구조를 가짐
- 따라서 결정 트리는 알고리즘과 관련된 요소를 시각적으로 표현할 수 있는 방법이 다양함
- 예: 규칙 트리 시각화, featureimportances 속성
- 이러한 시각화는 결정 트리의 동작 방식을 직관적으로 이해하는 데 도움됨
결정 트리 과적합(Overfitting)
- 결정 트리가 학습 데이터를 어떻게 분할하고 예측을 수행하는지를 시각화해 확인 (결정 트리의 과적합 문제도 함께 이해할 수 있음)
make_classification()함수 사용- 2개의 피처, 3개의 클래스 값을 가지는 분류용 테스트 데이터 세트 생성
make_classification()은 피처 데이터 세트(X)와 클래스 레이블 데이터 세트(y)를 반환- 생성된 데이터를 그래프로 시각화해 결정 트리의 분할 방식 및 학습 경향 확인 가능
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
plt.title("3 Class values with 2 Features Sample data creation")
# 2 차원 시각화를 위해서 피처는 2 개 , 클래스는 3 가지 유형의 분류 샘플 데이터 생성.
X_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2,
n_classes=3, n_clusters_per_class=1, random_state=0)
# 그래프 형태로 2 개의 피처로 2 차원 좌표 시각화 , 각 클래스 값은 다른 색갈로 표시됨.
plt.scatter(X_features[:, 0], X_features[:, 1], marker='o', c=y_labels, s=25, edgecolor='k')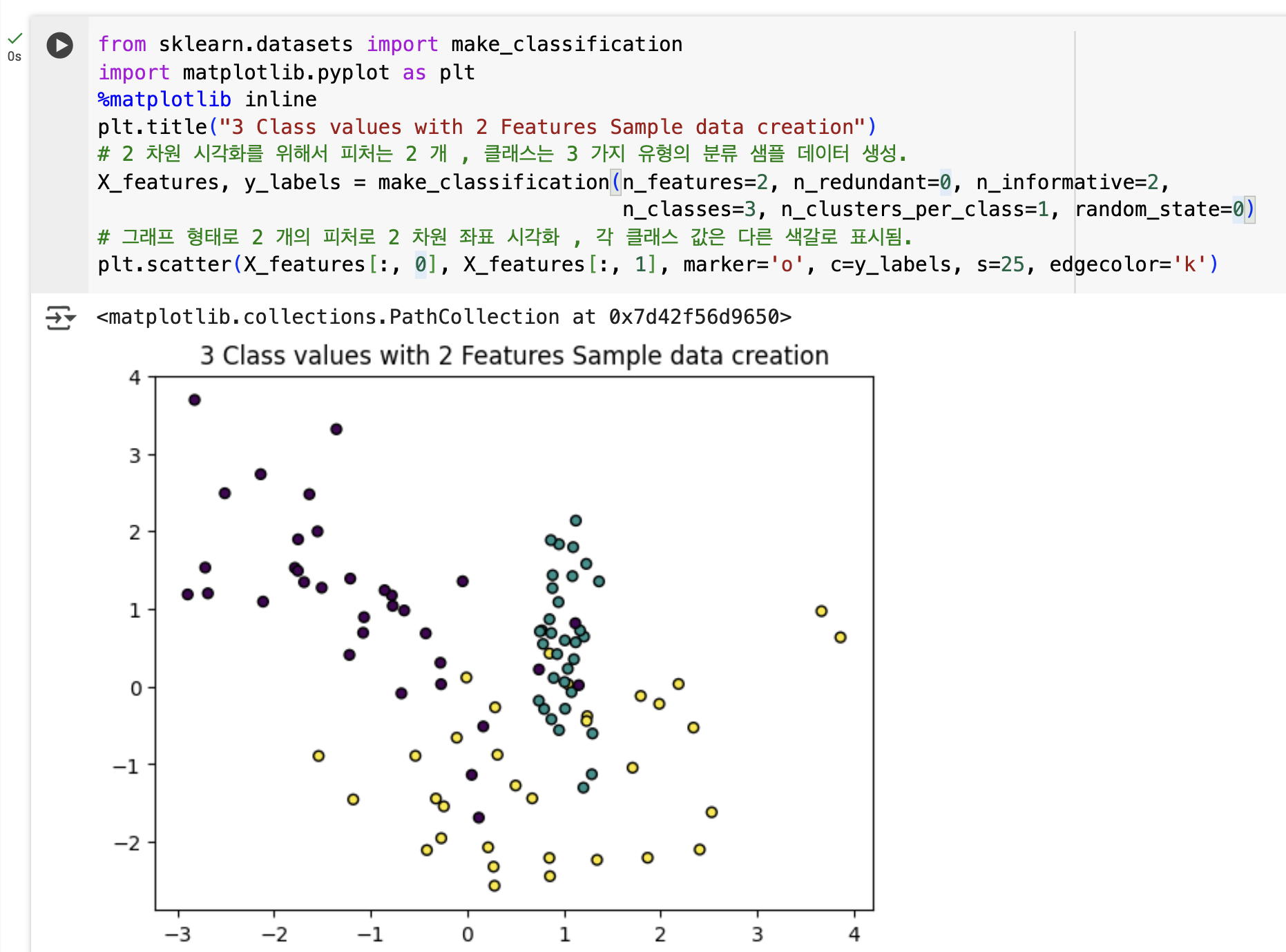
- 각 피처는 X, Y 축에 배치된 2차원 그래프로 표현되며,
3개의 클래스 값은 색깔로 구분 - 이 데이터 세트를 기반으로 결정 트리 모델을 학습
- 첫 번째 학습은 하이퍼 파라미터 제약 없이 디폴트 설정으로 진행
- 결정 트리가 어떤 기준으로 데이터를 분할해 분류하는지 확인 ->
visualize_boundary()함수 사용 - 머신러닝 모델이 예측하는 클래스 구분 경계와 결정 기준을 색상과 경계선으로 시각화
- 모델이 데이터를 어떻게 분류하는지 시각적으로 이해 가능
- 먼저 결정 트리 생성에 별다른 제약이 없도록 하이퍼 파라미터가 디폴트인 Classifier를 학습하고 결정
기준 경계를 시각화해 보기
from sklearn.tree import DecisionTreeClassifier
# 특정한 트리 생성 제약 없는 결정 트리의 학습과 결정 경계 시각화.
dt_clf = DecisionTreeClassifier(random_state=156).fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)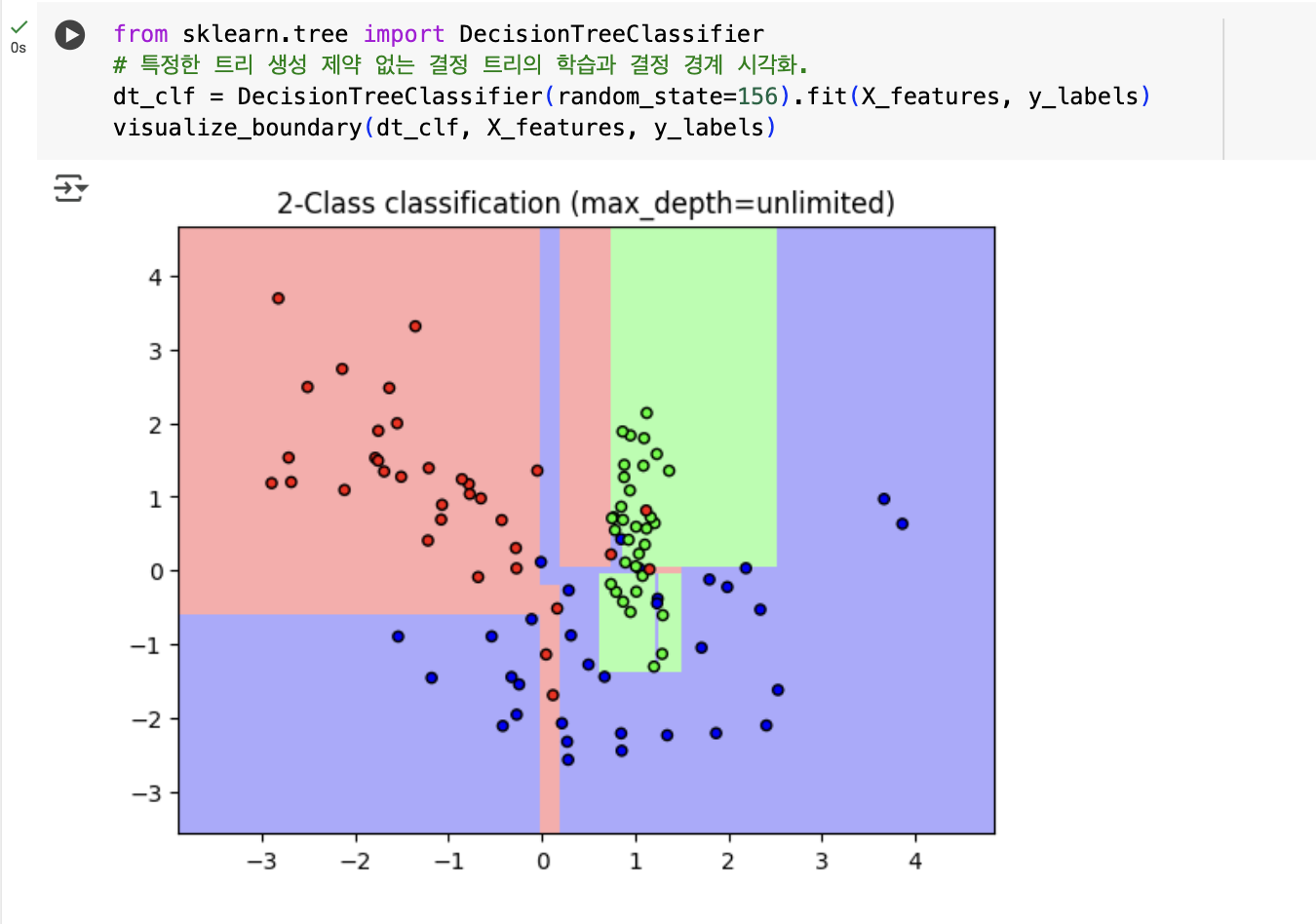
- 기본 설정의 결정 트리는 이상치(Outlier)까지 분류하려고 하여 분할이 자주 발생 -> 결정 기준 경계가 많고 복잡해짐
- 리프 노드에 데이터가 모두 균일하거나 하나만 있어야 하는 엄격한 분할 기준 때문임.
- 다른 형태의 데이터에 대해 예측 정확도가 떨어질 수 있음 (과적합)
min_samples_leaf=6 으로 설정 (6개 이하의 데이터는 리프 노드로 분할하지 않음)
- 리프 노드 생성 조건을 완화하여 결정 기준 경계가 어떻게 변하는지 시각적으로 확인할 예정
# min_samples_leaf=으로 트리 생성 조건을 제약한 결정 경계 시각화
dt_clf = DecisionTreeClassifier(min_samples_leaf=6, random_state=156).fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)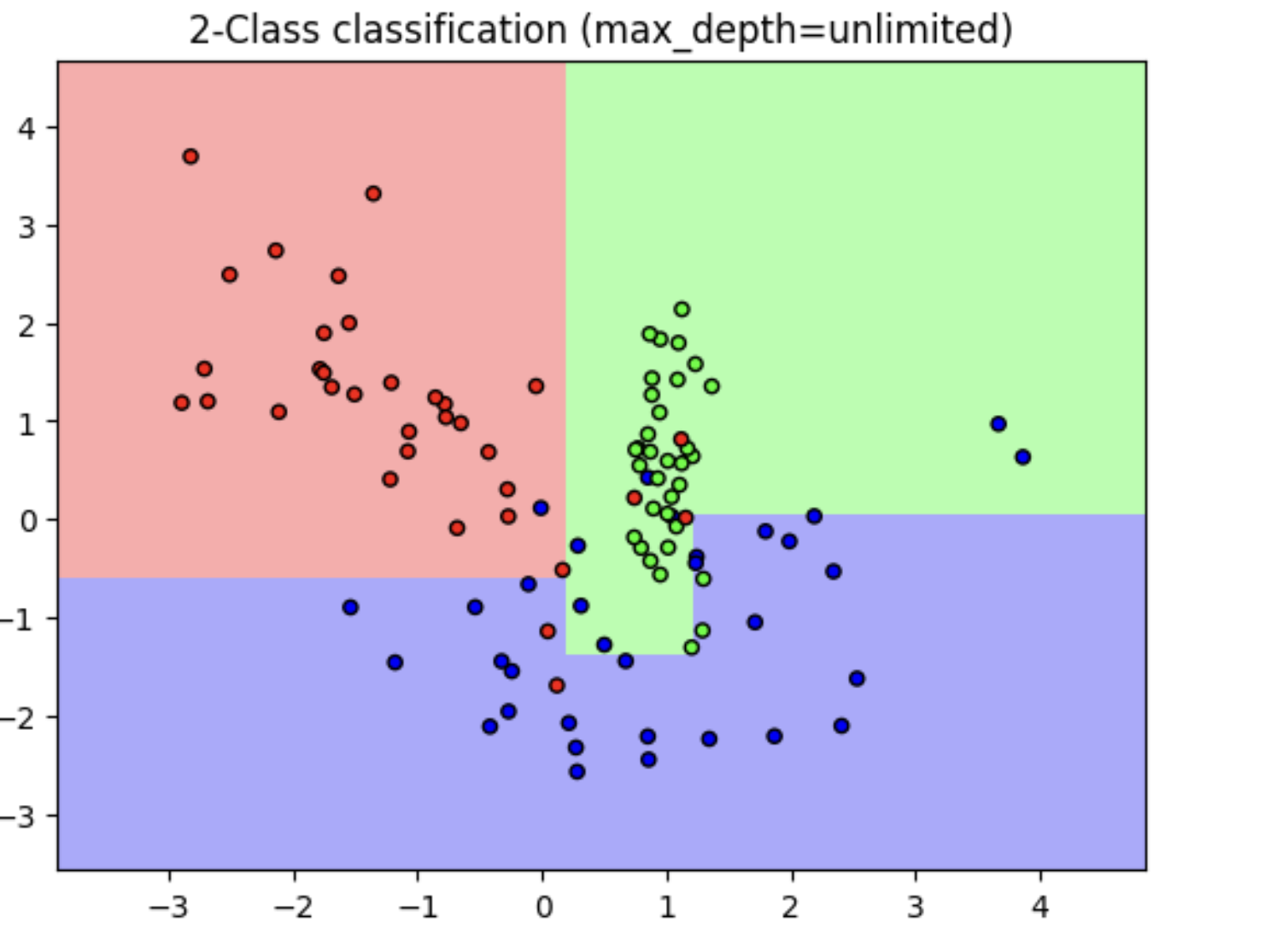
- 이상치에 덜 민감하게 반응하며, 더 일반화된 분류 규칙으로 분류됨
- 다양한 테스트 데이터 세트에서의 예측 성능은
첫 번째 모델보다min_samples_leaf=6으로 조건을 제약한 모델이 더 뛰어날 가능성 높음 - 이유: 테스트 데이터는 학습 데이터와 다르므로,
학습 데이터에만 과하게 최적화된 모델은 오히려 정확도 저하를 초래할 수 있음
결정 트리 실습 - 사용자 행동 인식 데이터 세트
- UCI 머신러닝 리포지토리
(Machine Learning Repository) 에서 제공하는 사용자 행동 인식 (Human Activity Recognition) 데이터 세트에 대한 예측 분류를 수행 - 30 명에게 스마트폰 센서를 장착한 뒤 사람의 동작과 관련된 여러 가지 피처를 수집한 데이터임
- 수집된 피처 세트를 기반으로 결정 트리 를 이용해 어떠한 동작인지 예측
- https://archive.ics.uci.edu/dataset/240/human+activity+recognition+using+smartphones 에 접속해서 데이터를 다운받기
- UCI HAR Dataset.zip을 클릭하기
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# features.txt 파일에는 피처 이름 index 와 피처명이 공백으로 분리되어 있음. 이를 Dataframe으로 로드 .
feature_name_df = pd.read_csv('/features.txt', sep='\s+',
header=None, names=[ 'column_index', 'column _name' ])
# 피처명 index 를 제거하고 , 피처명만 리스트 객체로 생성한 뒤 샘플로 10 개만 추출
feature_name = feature_name_df.iloc[:, 1].values.tolist()
print('전체 피처명에서 10 개만 추출 :', feature_name[:10])출력
전체 피처명에서 10 개만 추출 : ['tBodyAcc-mean()-X', 'tBodyAcc-mean()-Y', 'tBodyAcc-mean()-Z', 'tBodyAcc-std()-X', 'tBodyAcc-std()-Y', 'tBodyAcc-std()-Z', 'tBodyAcc-mad()-X', 'tBodyAcc-mad()-Y', 'tBodyAcc-mad()-Z', 'tBodyAcc-max()-X']-
피처명을 보면 인체 움직임 관련 속성의 평균/표준편차가 X, Y, Z 축 값으로 구성된 것을 유추 가능
-
피처명을 가지는 features.txt 파일을 DataFrame으로 로딩하기 전에 주의할 점 있음:
→ 중복된 피처명 존재 -
중복된 피처명을 그대로 사용해 데이터 파일을 DataFrame에 로딩하면 오류 발생
-
과거 판다스 버전에서는 허용되었지만, 현재는 허용되지 않음
-
따라서 중복 피처명에는 숫자(예: 1, 2 등)를 붙여 고유하게 이름 변경 필요
-
이후 수정된 피처명을 사용해 데이터 파일을 DataFrame에 로딩
-
먼저 중복된 피처명이 몇 개인지 확인할 예정
feature_dup_df = feature_name_df.groupby('column _name').count()
print(feature_dup_df[feature_dup_df['column_index'] > 1]. count())
feature_dup_df[feature_dup_df['column_index'] > 1].head()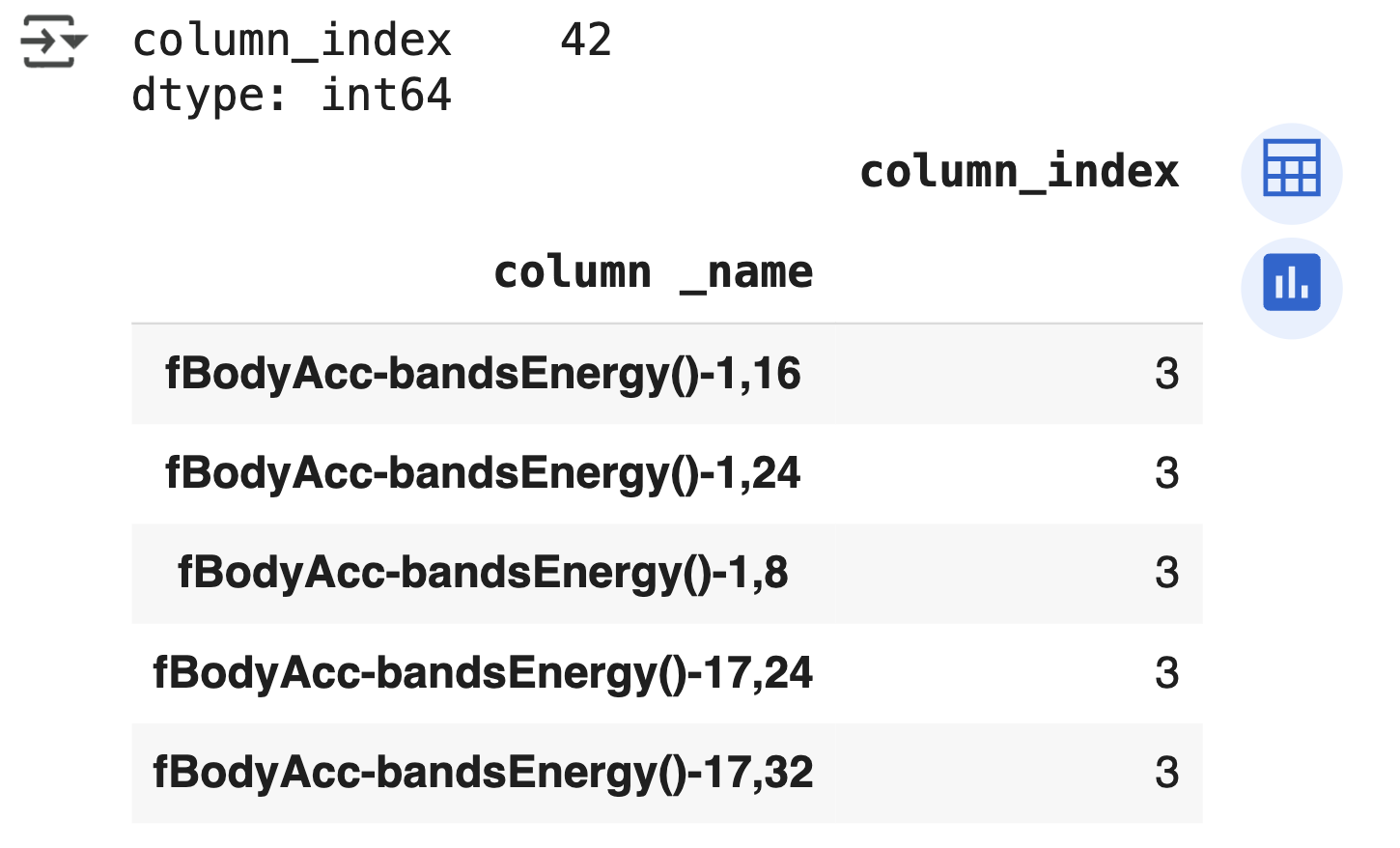
- 총 42 개의 피처명이 중복돼 있음
- 이 중복된 피처명에 대해서는 원본 피처명에 1또는 2를 추가로 부여해 새로운 피처명을 가지는 DataFrame을 반환하는 함수인
get_new_feature_name_df()를 생성하겠습니다.
- train 디렉터리: 학습용 피처 데이터 세트 + 레이블 데이터 세트
- test 디렉터리: 테스트용 피처 데이터 세트 + 레이블 데이터 세트
- 각 파일은 공백으로 구분되어 있으므로, read_csv()의 sep 인자로 공백 문자 지정
- 레이블 컬럼 이름은 "action"으로 명명
- 함수명: get_human_dataset()
- 이전에 만든 get_new_feature_name_df() 함수는 get_human_dataset() 함수 내에서 호출되어 중복된 피처명을 수정한 새로운 피처명을 사용해 데이터 로딩 진행
import pandas as pd
def get_human_dataset():
#각 데이터 파일은 공백으로 분리되어 있으므로 read_csv 에서 공백 문자를 sep 으로 할당.
feature_name_df = pd.read_csv('/features.txt', sep='\s+',
header=None, names=['column_index', 'column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용 , 신규 피처명 DataFrame 생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 칼럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터세트와 테스트 피처 데이터를 Dataframe 으로 로딩. 칼럼명은 feature_name 적용
X_train = pd.read_csv('/X_train.txt' ,sep='\s+', names=feature_name)
X_test = pd.read_csv('/X_test.txt', sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터를 Datarrame으로 로딩하고 칼럼명은 action으로 부여
y_train = pd.read_csv('/y_train.txt', sep='\s+', header=None, names=['action'])
y_test = pd.read_csv('/y_test.txt',sep='\s+',header=None, names=['action'])
# 로드된 학습 / 테스트용 Dataframe을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()print('\ 학습 피처 데이터셋 info()')
print(X_train.info())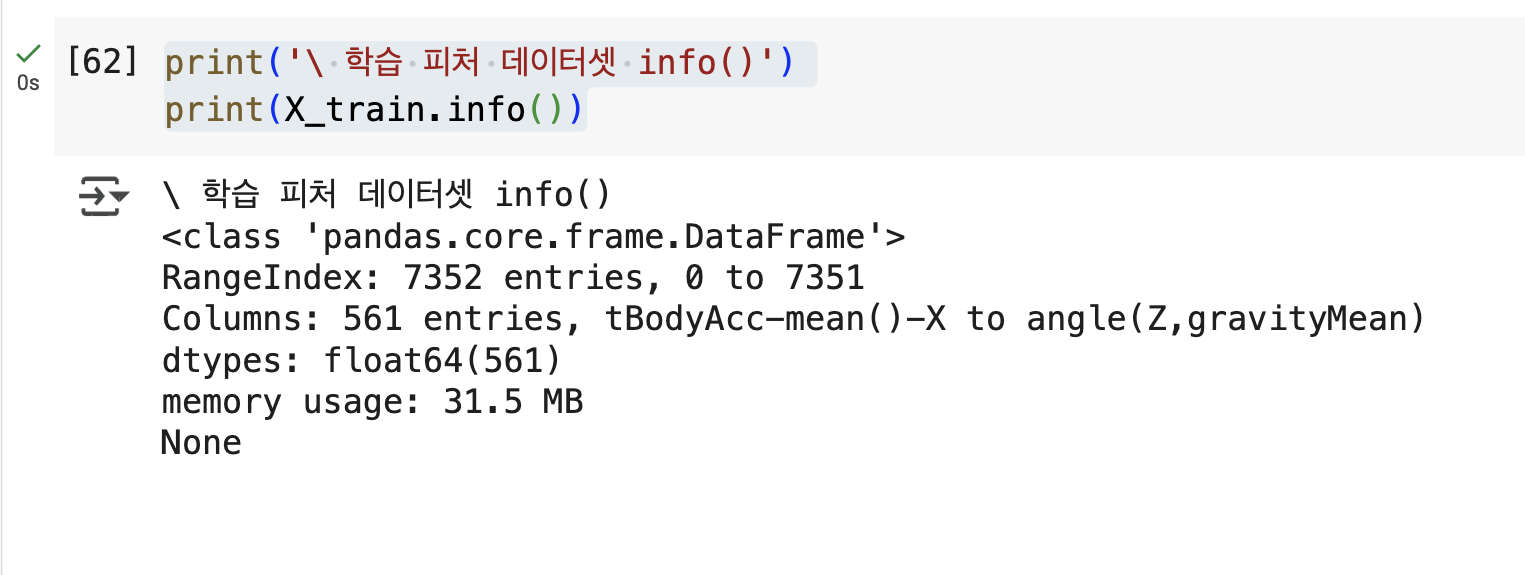
print(y_train['action'].value_counts())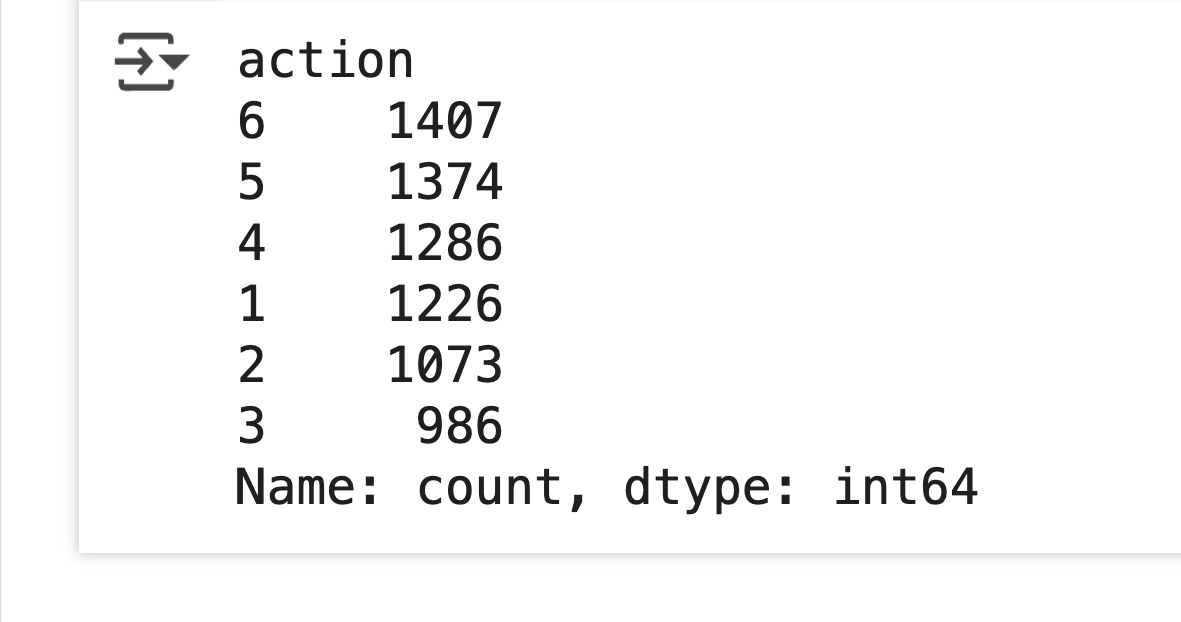
DecisionTreeClassifier 를 이용해 동작 예측 분류를 수행해 보기
- 먼저 DecisionTreeClassifier 의 하이퍼 파라미터는 모두 디폴트 값으로 설정해 수행하고 , 이때의 하이퍼 파라미터 값을 모두 추출
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 예제 반복 시마다 동일한 예측 결과 도출을 위해 random_state 설정
dt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('결정 트리 예측 정확도 : {0: .4f}'.format(accuracy))
# DecisionTreeClassifier의 하이퍼 파라미터 추출
print('DecisionTreeclassifier 기본 하이퍼 파라미터 :\n', dt_clf.get_params())출력
결정 트리 예측 정확도 : 0.8548
DecisionTreeclassifier 기본 하이퍼 파라미터 :
{'ccp_alpha': 0.0, 'class_weight': None, 'criterion': 'gini', 'max_depth': None, 'max_features': None, 'max_leaf_nodes': None, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'monotonic_cst': None, 'random_state': 156, 'splitter': 'best'}- 현재 모델은 약 85.48%의 정확도를 보임
- 이번에는 결정 트리의 깊이(Tree Depth)가 예측 정확도에 미치는 영향을 분석
- 결정 트리는 적절한 리프 노드가 될 때까지 트리 분할을 반복하므로 → 트리 깊이가 깊어질수록 과적합 위험 증가
- GridSearchCV를 활용해 max_depth 하이퍼 파라미터 조정
- 7가지 max_depth에 대해 5개 폴드 교차 검증(CV=5) 수행
- 목적: max_depth 변화에 따라 예측 성능이 어떻게 달라지는지 확인
from sklearn.model_selection import GridSearchCV
params = {
'max_depth': [ 6, 8 ,10, 12, 16 ,20, 24],
'min_samples_split': [16]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, verbose=1)
grid_cv.fit(X_train, y_train)
print('GridsearchCV 최고 평균 정확도 수치 : {0:.4f}'.format(grid_cv.best_score_))
print('GridsearchCV 최적 하이퍼 파라미터 :', grid_cv.best_params_)
# GridsearchCV 객체의 CV_results_ 속성을 DataFrame 으로 생성.
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
# max_depth 파라미터 값과 그때의 테스트 세트 , 학습 데이터 세트의 정확도 수치 추출
cv_results_df[['param_max_depth', 'mean_test_score']]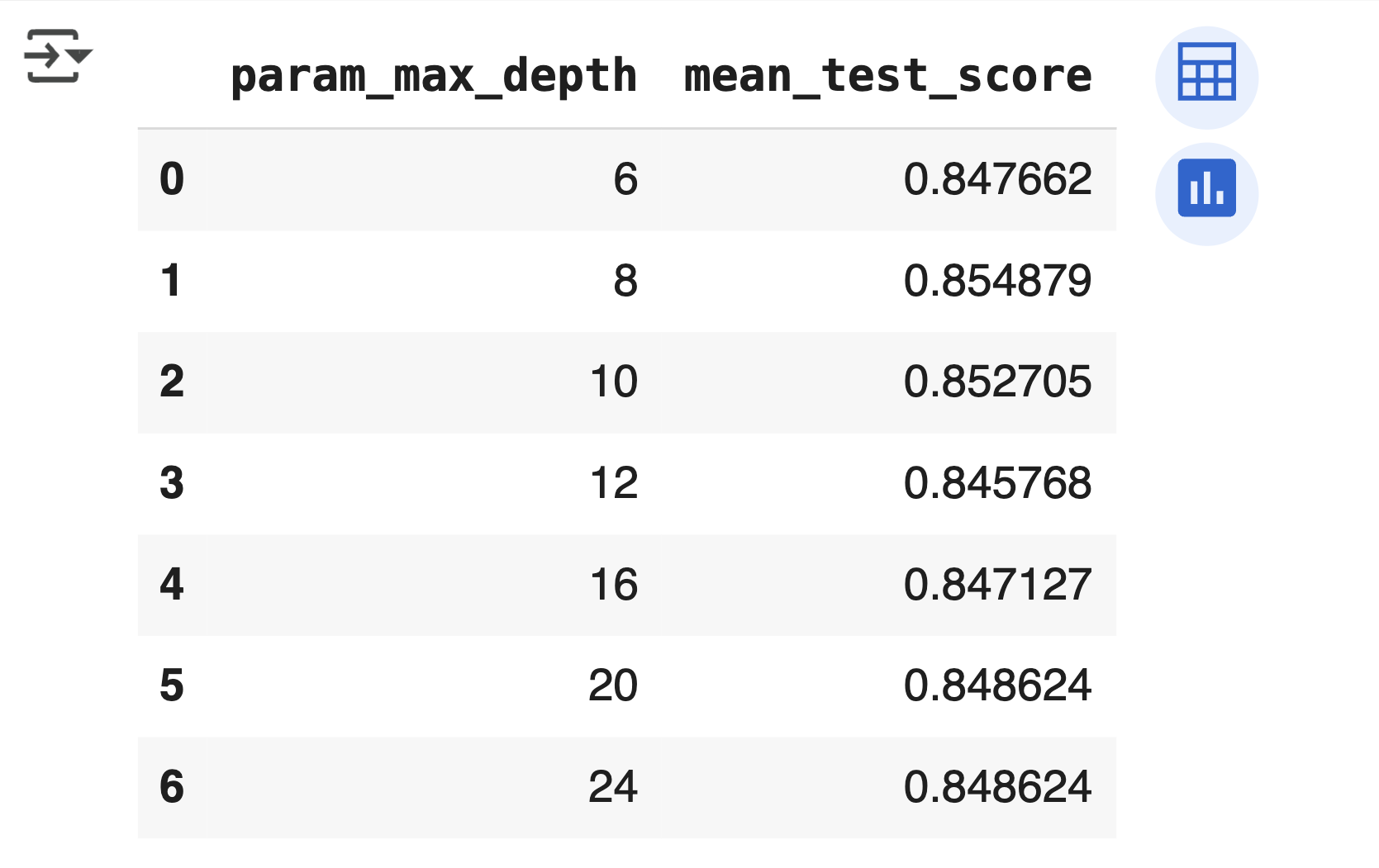
mean_test_score는 5개의 CV 세트에서 검증용 데이터 세트의 평균 정확도max_depth=8일 때 정확도 최고점 (0.854)을 기록
깊이가 깊어질수록 정확도 감소
이유: 결정 트리는 더 완벽한 규칙 학습을 위해 분할을 반복하면서 → 모델 복잡도 증가 → 과적합 발생 → 검증 성능 저하
별도의 테스트 데이터 세트에서 정확도 측정
- min_samples_split=16 고정
- max_depth 변화에 따라 테스트 성능 측정
목표: 검증 데이터에서 최적이었던 max_depth=8이
테스트 데이터에서도 우수한 성능을 유지하는지를 확인
max_depths = [6, 8, 10, 12, 16, 20, 24]
# max_depth 값을 변화시키면서 그때마다 학습과 테스트 세트에서의 예측 성능 측정
for depth in max_depths:
dt_clf = DecisionTreeClassifier(max_depth=depth, min_samples_split=16, random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score (y_test, pred)
print('max_depth = {0} 정확도 : {1:.4f}'.format(depth, accuracy))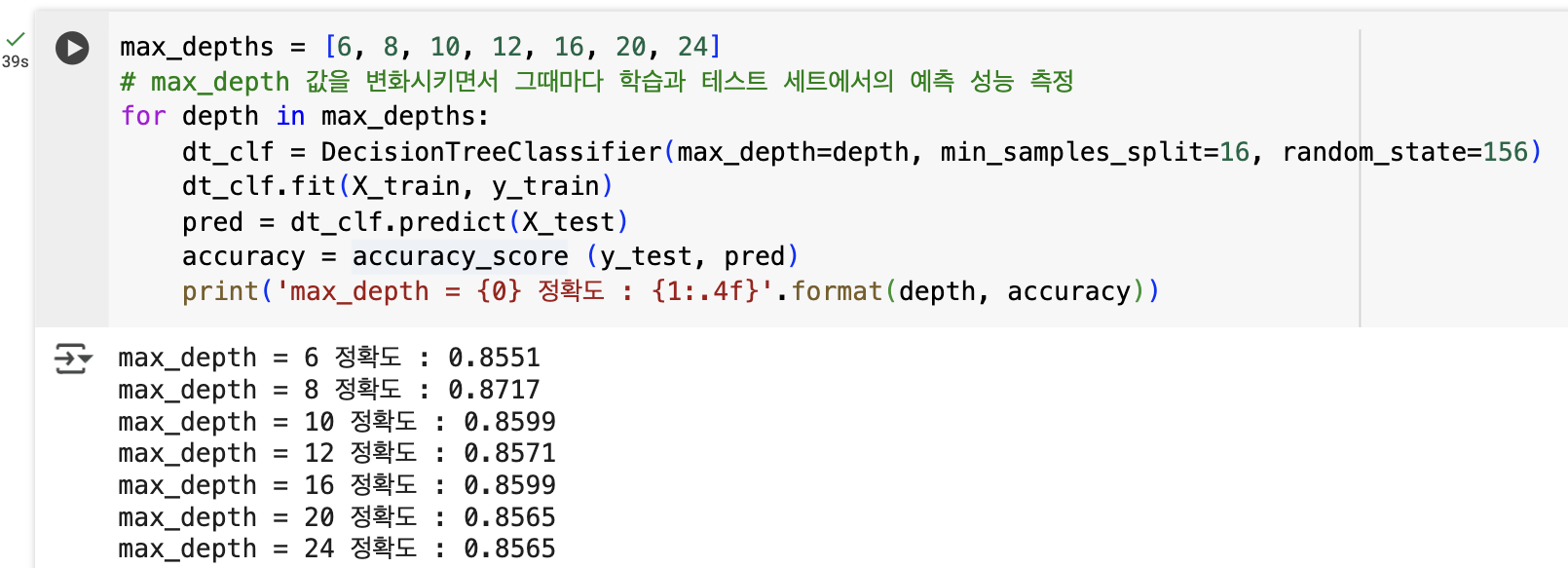
- max_depth=8일 때 약 87.17%로 가장 높은 테스트 정확도를 기록 -> 8을 초과하면 정확도는 점점 감소
- GridSearchCV 결과와 동일하며, 깊이가 깊어질수록 과적합 영향이 커짐
- 따라서, 결정 트리는 트리 깊이를 하이퍼 파라미터로 제어해야 과적합 방지 가능
- 복잡한 모델보다 깊이를 낮춘 단순한 모델이 더 좋은 성능을 보일 수 있음
max_depth와 min_samples_split을 함께 조정하여 예측 정확도 튜닝을 수행할 예정
params = {
'max_depth' : [8, 12, 16, 20],
'min_samples_split' : [16, 24],
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, verbose=1 )
grid_cv.fit(X_train, y_train)
print('GridsearchCV 최고 평균 정확도 수치 : {0:.4f}'.format(grid_cv.best_score_))
print('GridsearchCV 최적 하이퍼 파라미터 :', grid_cv.best_params_)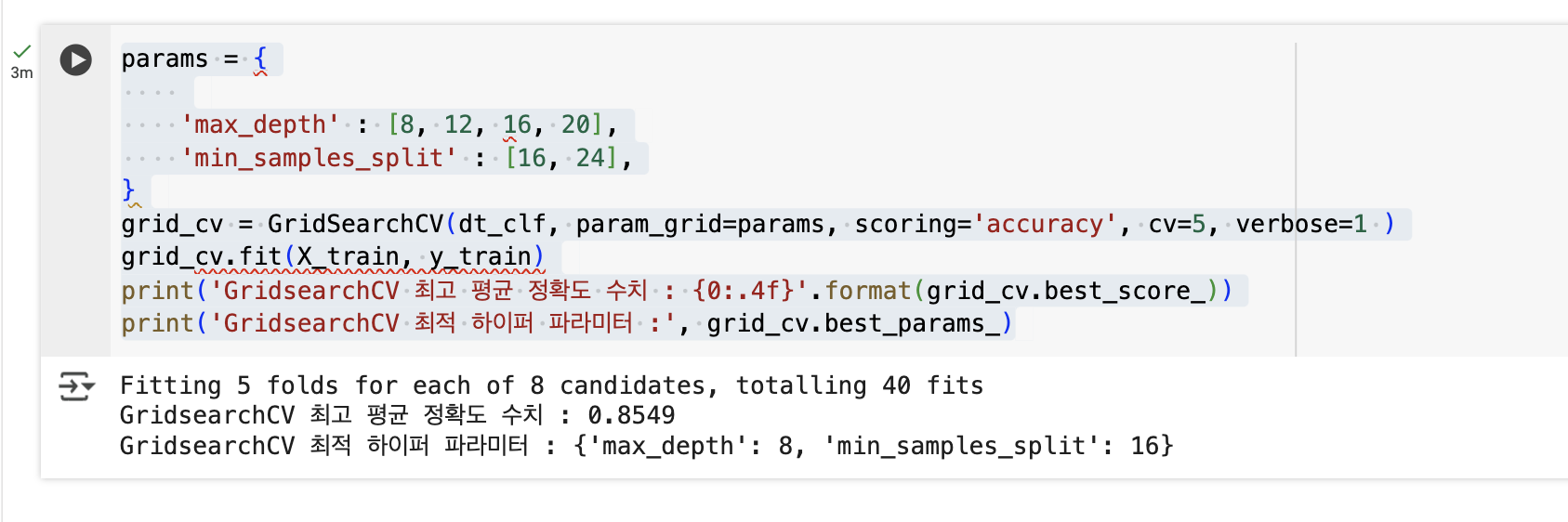
- max_depth=8, min_samples_split=16일 때 가장 높은 정확도(약 85.49%)
best_df_clf = grid_cv.best_estimator_
pred1 = best_df_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred1)
print('결정 트리 예측 정확도:{0:.4f}'.format(accuracy))
- max_depth=8, min_samples_split=16일 때
테스트 데이터 세트 예측 정확도는 약 87.17% - 마지막으로
feature_importances_속성을 이용해
결정 트리 모델이 학습한 후 각 피처의 중요도를 확인 - 중요도가 높은 순으로 Top 20 피처를 막대그래프로 표현
import seaborn as sns
ftr_importances_values = best_df_clf.feature_importances_
# Top 중요도로 정렬을 쉽게 하고 , 시본 (Seaborn) 의 막대그래프로 쉽게 표현하기 위해 Series 변환
ftr_importances = pd.Series(ftr_importances_values, index=X_train.columns )
# 중요도값 순으로 Series를 정렬
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8, 6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20, y = ftr_top20.index)
plt.show()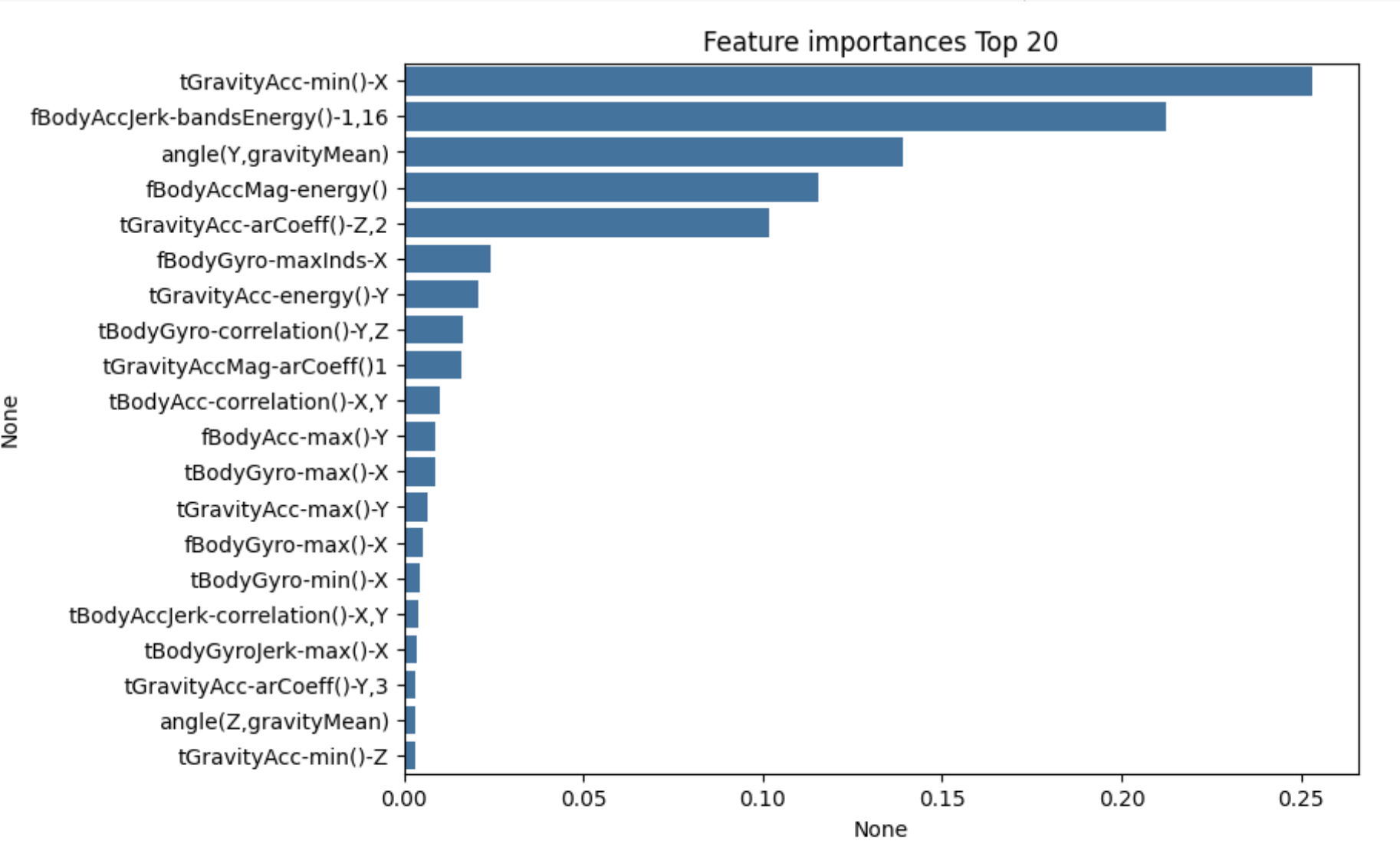
막대 그래프상에서 확인해 보면 이 중 가장 높은 중요도를 가진 Top 5 의 피처들이 매우 중요하게 규칙 생성에 영향을 미치고 있음
3. 앙상블 학습
앙상블 학습 개요
-
앙상블 학습(Ensemble Learning)을 통한 분류는 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법을 말함
-
어려운 문제의 결론을 내기 위해 여러 명의 전문가로 위원회를 구성해 다양한 의견을 수렴하고 결정하는 것처럼
-
앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것임
집단 지성으로 어려운 문제도 쉽게 해결책을 찾을 수 있습니다
-
이미지, 영상, 음성 등의 비정형 데이터의 분류는 딥러닝이 뛰어난 성능을 보이고 있지만, 대부분의 정형 데이터 분류 시에는 앙상블이 뛰어난 성능을 나타내고 있음
-
랜덤 포레스트와 그래디언트 부스팅은 뛰어난 성능, 쉬운 사용, 다양한 활용도로 분석가 및 데이터 과학자들 사이에서 애용됨
부스팅 계열의 강세로 인해 기존 그래디언트 부스팅을 뛰어넘는 새로운 알고리즘 개발이 활발히 진행됨
-
예: 캐글(Kaggle)에서 ‘매력적인 솔루션’이라 불리는 XGBoost
-
XGBoost와 유사한 성능 + 더 빠른 속도를 가진 LightGBM
-
여러 모델의 결과를 기반으로 메타 모델을 수립하는 스태킹(Stacking)
-
XGBoost, LightGBM 등 최신 앙상블 모델 한두 개만 잘 알아도정형 데이터의 분류나 회귀 분야에서 매우 뛰어난 예측 성능의 모델을 쉽게 구현 가능
-
쉽고 편리하면서도 강력한 성능이 앙상블 학습의 특징
앙상블 학습 유형 은 전통적으로
- 보팅(Voting) : 서로 다른 알고리즘 기반의 분류기 조합
- 배깅(Bagging) : 같은 알고리즘 기반이지만, 데이터 샘플링을 다르게 하여 학습 후 보팅 수행
- 대표적인 배깅 방식: 랜덤 포레스트 알고리즘 - 부스팅(Boosting)
로 구분되며, 스태킹(Stacking)을 포함한 다양한 방식 존재함
- 보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결정
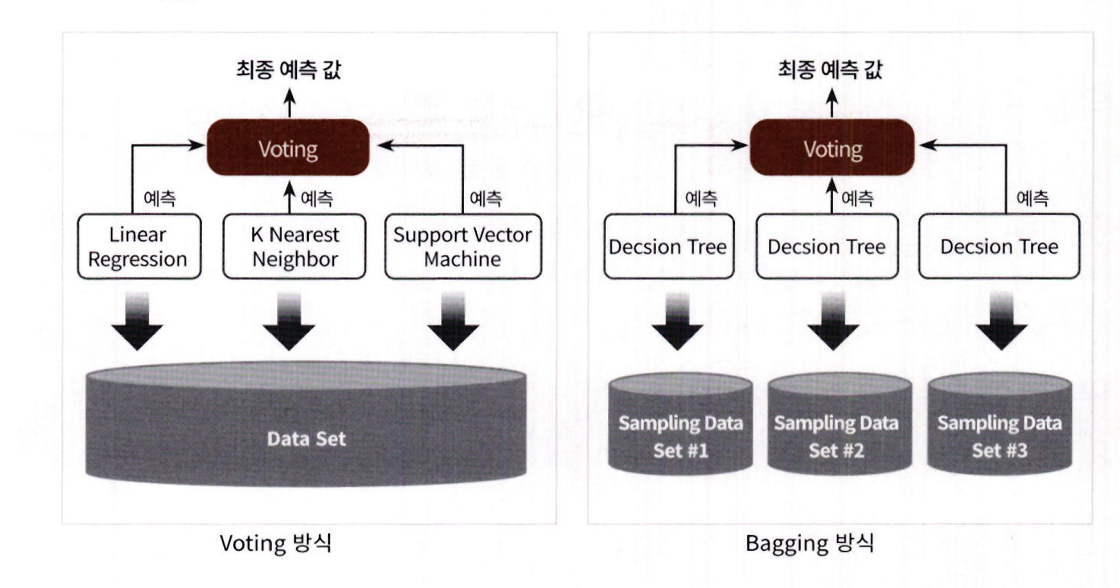
왼쪽 그림 (보팅 분류기):
- 선형 회귀, K 최근접 이웃, 서포트 벡터 머신이라는 3개의 ML 알고리즘이 같은 데이터 세트에 대해 학습과 예측 수행
- 각 모델의 예측 결과를 보팅하여 최종 예측 결과 선정
오른쪽 그림 (배깅 분류기):
- 단일 ML 알고리즘(결정 트리)로 여러 개의 분류기 생성
- 각 분류기는 원본 학습 데이터를 샘플링하여 학습 -> 부트스트래핑(Bootstrapping) 방식
- 각 개별 분류기의 예측 결과를 보팅하여 최종 결과 결정
- 교차 검증과 달리, 배깅은 중복 데이터 허용
부스팅(Boosting):
- 여러 분류기가 순차적으로 학습
0 앞선 분류기가 틀린 데이터에 대해 다음 분류기에게 가중치(weight)를 부여해 학습 - 점진적으로 예측 정확도 향상
- 대표 모듈: 그래디언트 부스트, XGBoost, LightGBM
스태킹(Stacking):
- 여러 다른 모델의 예측 결과를 입력 데이터로 사용 -> 다시 다른 모델(메타 모델)로 재학습시켜 최종 예측 수행
보팅 유형 - 하드 보팅 (Hard Voting)과 소프트 보팅(Soft Voting)
- 보팅 방법에는 두 가지가 있습니다: 하드 보팅과 소프트 보팅
하드 보팅:
- 다수결 원칙과 유사
- 여러 분류기의 예측값 중 다수가 선택한 클래스를 최종 보팅 결과로 선정
소프트 보팅:
- 각 분류기의 레이블 값 결정 확률을 모두 더하고 평균
- 가장 높은 평균 확률을 가진 레이블 값을 최종 보팅 결과로 선정
- 일반적으로 소프트 보팅이 보팅 방법으로 적용됨
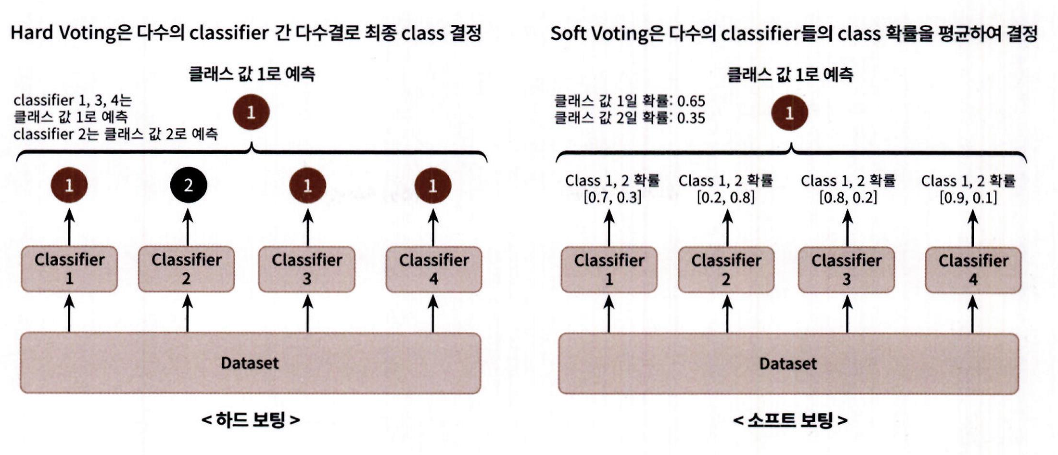
왼쪽 그림: 하드 보팅
- Classifier 1, 2, 3, 4로 구성된 보팅 앙상블에서 분류기 1, 3, 4가 레이블 값 1, 분류기 2가 레이블 값 2 예측
- 다수결 원칙에 따라 최종 예측은 레이블 값 1
오른쪽 그림: 소프트 보팅
각 분류기의 레이블 값 예측 확률 평균을 기반으로 결정
예)
분류기 1: 1→0.7 / 2→0.3
분류기 2: 1→0.2 / 2→0.8
분류기 3: 1→0.8 / 2→0.2
분류기 4: 1→0.9 / 2→0.1
- 레이블 값 1 평균: (0.7 + 0.2 + 0.8 + 0.9) / 4 = 0.65
- 레이블 값 2 평균: (0.3 + 0.8 + 0.2 + 0.1) / 4 = 0.35
- 최종 보팅 결과: 레이블 값 1
- 소프트 보팅이 하드 보팅보다 예측 성능이 좋아 더 많이 사용됨
보팅 분류기 (Voting Classifier)
- 보팅 방식의 앙상블을 구현한
VotingClassifier클래스 - 이를 활용해 위스콘신 유방암 데이터 세트로 이진 분류 예측 분석을 수행
- 위스콘신 유방암 데이터는 악성종양/양성종양 여부를 판별하는 이진 분류 데이터 세트
- 종양의 크기, 모양 등과 관련된 다수의 피처 포함
- 사이킷런의
load_breast_cancer()함수를 통해 바로 로딩 가능
분석 방법:
- 로지스틱 회귀와 K 최근접 이웃(KNN) 알고리즘을 기반으로 보팅 분류기(VotingClassifier) 구성
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
data_df.head(3)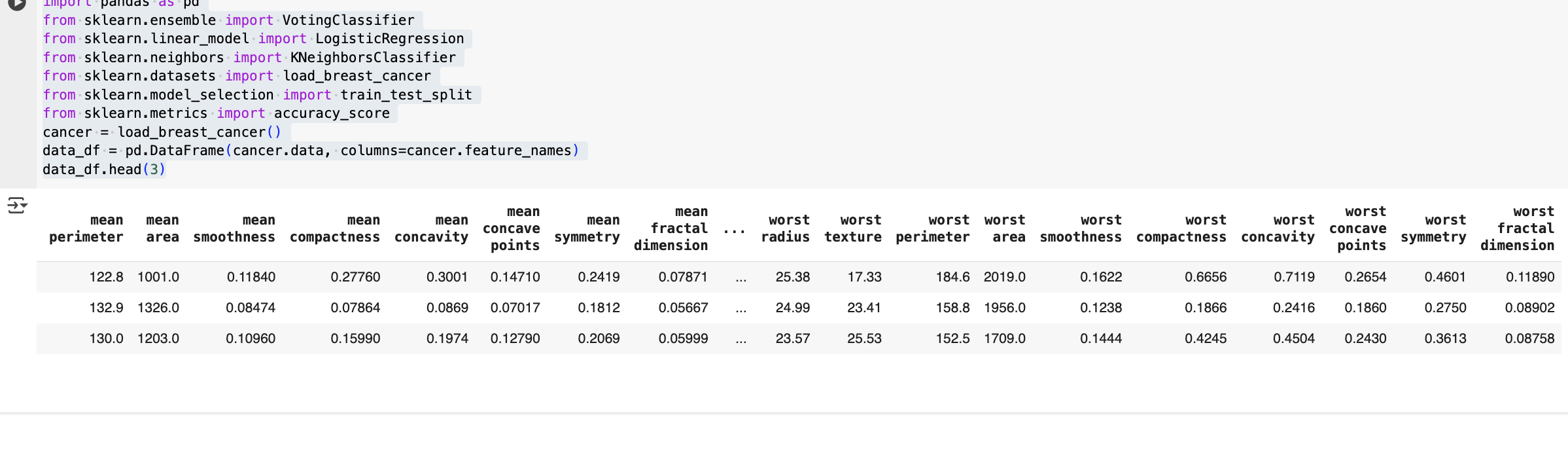
- 로지스틱 회귀와 KNN을 기반으로 소프트 보팅 방식의 보팅 분류기를 생성
- 사이킷런의 VotingClassifier 클래스를 사용하여 구현 가능
- VotingClassifier의 주요 생성 인자:
estimators:
- 보팅에 사용될 여러 개의 Classifier 객체들을
- 튜플 형식의 리스트로 입력
voting:
- 'hard': 하드 보팅
- 'soft': 소프트 보팅 (※ 기본값은 'hard')
- 즉, 소프트 보팅을 사용하려면 voting='soft'를 명시해야 함
# 개별 모델은 로지스틱 회귀와 KNN 임.
lr_clf = LogisticRegression(solver='liblinear')
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier (estimators=[('LR', lr_clf), ('KNN', knn_clf)], voting='soft')
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
test_size=0.2, random_state= 156)
# Votingclassifier 학습 / 예측 / 평가.
vo_clf.fit(X_train, y_train)
pred = vo_clf.predict(X_test)
print('Voting 분류기 정확도 : {0: .4f}'. format(accuracy_score(y_test, pred)))
# 개별 모델의 학습 / 예측 / 평가.
classifiers = [lr_clf, knn_clf]
for classifier in classifiers :
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name= classifier.__class__.__name__
print('{0} 정확도: {1: .4f}'. format(class_name, accuracy_score(y_test, pred)))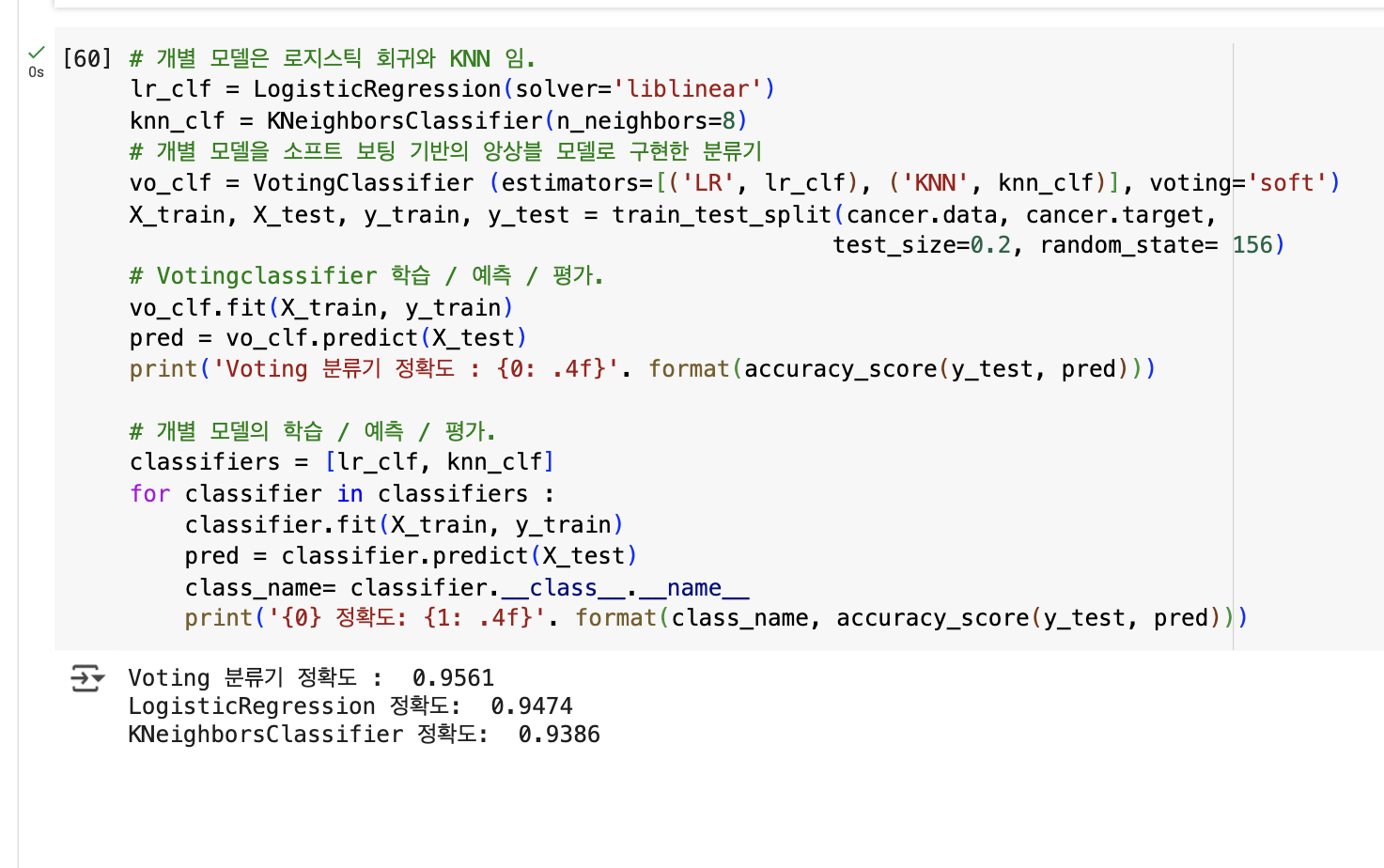
- 보팅 분류기가 정확도가 약간 높게 나타났지만, 항상 기반 분류기보다 성능이 더 뛰어난 것은 아님
- 데이터의 특성, 분포 등에 따라 가장 좋은 개별 분류기가 보팅보다 성능이 더 나을 수도 있음
- 그럼에도 불구하고, 보팅을 포함한 배깅, 부스팅 등의 앙상블 방법은 단일 ML 알고리즘보다 전반적으로 뛰어난 예측 성능을 보이는 경우가 많음
- 현실 세계는 고정된 데이터 세트와는 달리 변수와 예측하기 어려운 규칙으로 구성되어 있음 → 다양한 관점을 가진 알고리즘의 결합이 더 나은 성능을 유도할 수 있음
- 팀워크에도 비유 가능
- 다양한 경험과 배경을 가진 사람들로 구성된 팀이 유연한 문제 해결 능력을 가지고 프로젝트 성공 확률이 높음
- 반면 우수한 인재만 모인 팀은 고정된 관점으로 인해 유연성이 낮을 수 있음
ML 모델 평가에서 중요한 요소:
- 높은 유연성으로 다양한 테스트 데이터에 적응하는 능력 -> 현실에 잘 대응할 수 있음
- 이와 관련된 개념이 편향-분산 트레이드오프
- ML 모델이 극복해야 할 중요 과제
- 보팅, 스태킹은 서로 다른 알고리즘 기반
- 배깅, 부스팅은 대부분 결정 트리 알고리즘 기반
- 결정 트리 알고리즘의 단점:
- 학습 데이터에 과도하게 집착 → 과적합
- 테스트 데이터에서 성능 저하 가능성 있음
- 결정 트리의 장점은 살리고 단점은 보완 (편향-분산 트레이드오프 효과를 극대화 가능)
4. 랜덤 포레스트
랜덤 포레스트의 개요 및 실습
ข 배깅(Bagging)은 보팅과 달리, 같은 알고리즘으로 여러 개의 분류기를 생성 → 이들의 예측 결과를 보팅하여 최종 결정을 내리는 방식
- 배깅의 대표적인 알고리즘은 랜덤 포레스트(Random Forest)
랜덤 포레스트 특징:
- 다재다능한 앙상블 알고리즘
- 빠른 수행 속도
- 다양한 영역에서 높은 예측 성능
- 기반 알고리즘은 결정 트리
- 결정 트리의 쉽고 직관적인 장점 유지
- 실제로, 랜덤 포레스트뿐 아니라 부스팅 계열 앙상블도 대부분 결정 트리 기반 알고리즘을 채택
작동 방식:
- 여러 개의 결정 트리 분류기가 배깅 방식으로 전체 데이터에서 각자 샘플링하여 개별 학습
- 이후, 모든 분류기의 보팅을 통해 최종 예측 결정
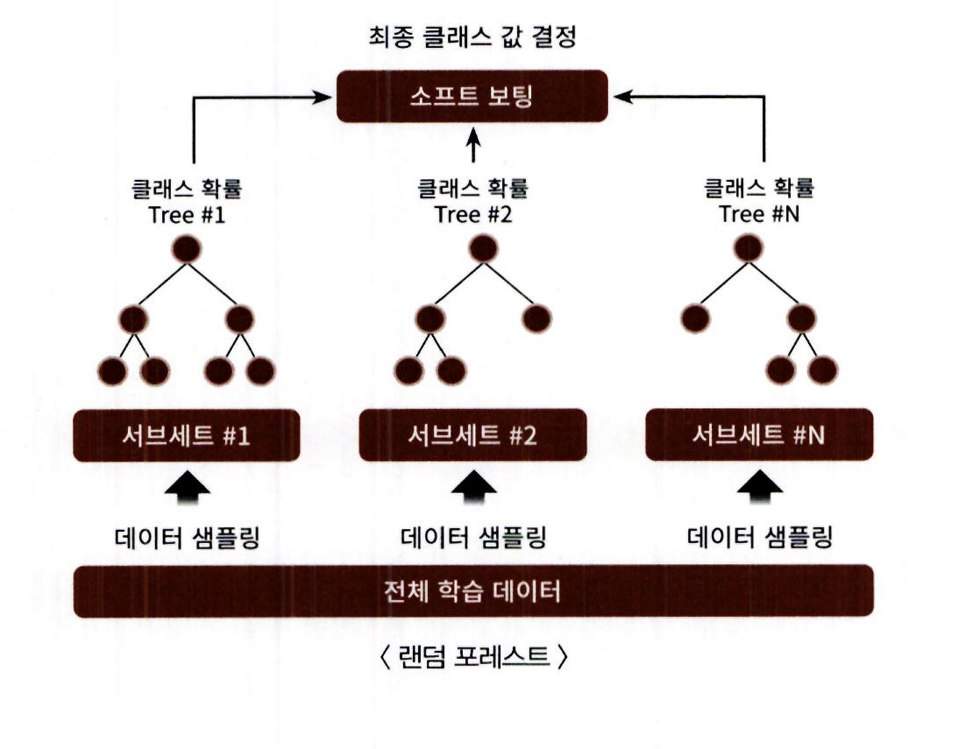
- 랜덤 포레스트는 개별 분류기의 기반 알고리즘은 결정 트리
- 하지만 각 개별 트리는 전체 데이터에서 일부 중첩된 데이터 세트로 학습 -> 부트스트래핑(Bootstrapping) 분할 방식이라 부름
- 그래서 배깅(Bagging)은 Bootstrap Aggregating의 줄임말
- 부트스트랩이란 원래 통계학 용어로, 여러 개의 작은 데이터 세트를 임의로 생성해 개별 평균의 분포도를 측정하는 등의 샘플링 기법
- 랜덤 포레스트의 서브세트 데이터는 부트스트래핑으로 임의 중복 샘플링된 데이터 서브세트의 크기는 원본 데이터와 동일, 하지만 중복된 데이터 포함
예) 원본 데이터의 건수가 10개인 학습 세트
n_estimators=3 이면
→ 3개의 결정 트리마다 각기 다른 부트스트랩 서브세트로 학습 진행
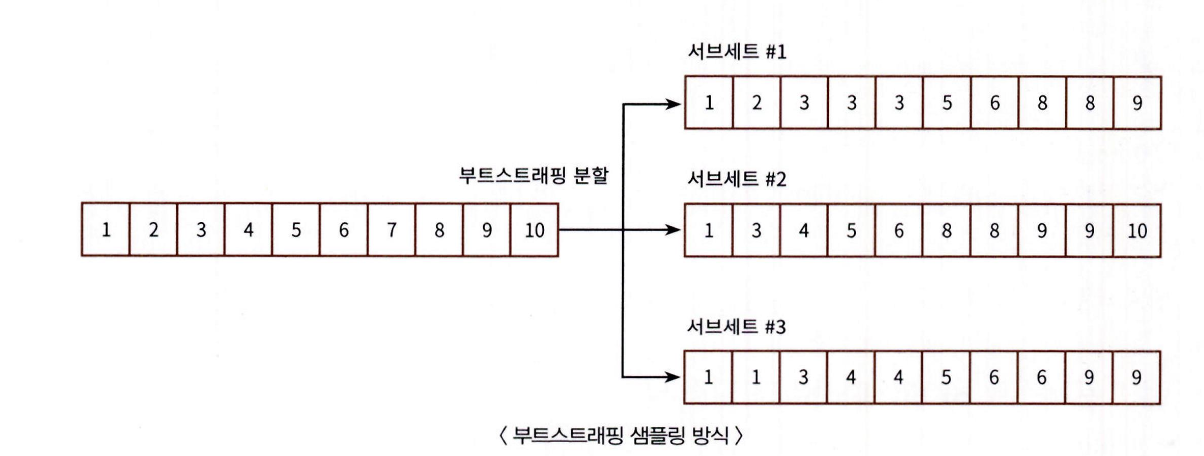
-
이렇게 데이터가 중첩된 개별 데이터 세트에 결정 트리 분류기를 각각 적용하는 것이 랜덤 포레스트임.
-
사이킷런은
RandomForestClassifier클래스를 통해 랜덤 포레스트 기반의 분류를 지원함. -
앞의 사용자 행동 인식 데이터 세트를 RandomForestClassifier 를 이용해 예측해 보겠습니다.
-
재수행할 때마다 동일한 예측 결과를 출력하기 위해 RandomForestClassifier의 random_state를 0으로 설정
-
사용자 행동 데이터 세트에 DataFrame을 반환하는
get_human_dataset()를 이용하기 위함. -
get_human_dataset()를 이용해 학습 / 테스트용 DataFrame을 가져옵니다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset()를 이용해 학습 / 테스트용 Dataframe 반환
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 세트로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state=0, max_depth=8)
rf_clf.fit(X_train, y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('랜덤 포레스트 정확도 : {0:.4f}'.format(accuracy))
랜덤 포레스트 하이퍼 파라미터 및 튜닝
트리 기반의 앙상블 알고리즘의 단점
-
하이퍼 파라미터가 너무 많음 -> 튜닝을 위한 시간이 많이 소모됨 -> 튜닝 후 예측 성능이 크게 향상되는 경우가 많지 않음.
-
트리 기반 자체의 하이퍼 파라미터가 원래 많은 데다
배깅, 부스팅, 학습, 정규화 등을 위한 하이퍼 파라미터까지 추가되므로 일반적으로 다른 ML 알고리즘에 비해 많을 수밖에 없음 -
그나마 랜덤 포레스트가 적은 편에 속하는데, 결정 트리에서 사용되는
하이퍼 파라미터와 같은 파라미터가 대부분이기 때문임.
n_estimators:
= 랜덤 포레스트에서 결정 트리의 개수를 지정 (디폴트는 10 개)
- 많이 설정할수록 좋은 성능을 기대할 수 있지만 계속 증가시킨다고 성능이 무조건 향상되는 것은 아님
- 늘릴수록 학습 수행 시간이 오래 걸리는 것도 감안해야 함.
max_features
- 결정 트리에 사용된
max_features파라미터와 같음 - 하지만 RandomForestClassifier 의 기본
None이 아니라auto, 즉sqr와 같음 - 따라서 랜덤 포레스트의 트리를 분할하는 피처를 참조할때 전체 피처가 아니라 sqrt(전체 피처 개수) 만큼 참조함. ( 전체 피처가 16 개라면 분할을 위해 4 개 참조).
max_depth 나 min_samples_leaf, min_samples_split
- 결정 트리에서 과적합을 개선하기 위해 사용되는 파라미터가 랜덤 포레스트에도 똑같이 적용될 수 있음.
GridSearchCV를 이용해 랜덤 포레스트의 하이퍼 파라미터를 튜닝.
-
사용자 행동 데이터 세트를 그대로 이용하고 , 튜닝 시간을 절약하기 위해 n_estimators는 100 으로 , CV를 2 로만 설정해 최적 하이퍼 파라미터를 구해 보겠습니다.
-
다음 예제에서 RandomForestClassifier 생성자와 GridSearchCV 생성 시 n_jobs=-1 파라미터를 추가하면 모든 CPU 코어를 이용해 학습할 수 있음.
from sklearn.model_selection import GridSearchCV
params = {
'max_depth': [8, 16, 24],
'min_samples_leaf' : [1, 6, 12],
'min_samples_split' : [2, 8, 16]
}
# RandonForestClassifier 객체 생성 후 GridSearchcV 수행
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터 :\n', grid_cv.best_params_)
print('최고 예측 정확도 : {0:.4f}'.format(grid_cv.best_score_))-
max_depth: 16, min_samples leaf: 6, min_samples_split: 2 일 때 2 개의 CV 세트에서 약
91.65% 의 평균 정확도가 측정됨. -
이렇게 추출된 최적 하이퍼 파라미터로 다시 RandomForest
Classifier 를 학습시킨 뒤에, 별도의 테스트 데이터 세트에서 예측 성능을 측정해 보겠습니다.
rf_clf1 = RandomForestClassifier(n_estimators=100, min_samples_leaf=6, max_depth=16,
min_samples_split=2, random_state=0)
rf_clf1.fit( X_train, y_train)
pred = rf_clf1.predict(X_test)
print('예측 정확도 : {0:.4f}'.format(accuracy_score(y_test , pred)))
-
별도의 테스트 데이터 세트에서 수행한 예측 정확도 수치는 약 92.60%
-
RandomForestClassifier 역시 DecisionTreeClassifier 와 똑같이 featureimportances 속성을 이용해 알고리즘이 선택한 피처의 중요도를 알 수 있음.
이 피처 중요도를 막대그래프로 시각화
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
ftr_importances_values = rf_clf1.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index=X_train.columns)
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20, y=ftr_top20.index)
plt.show()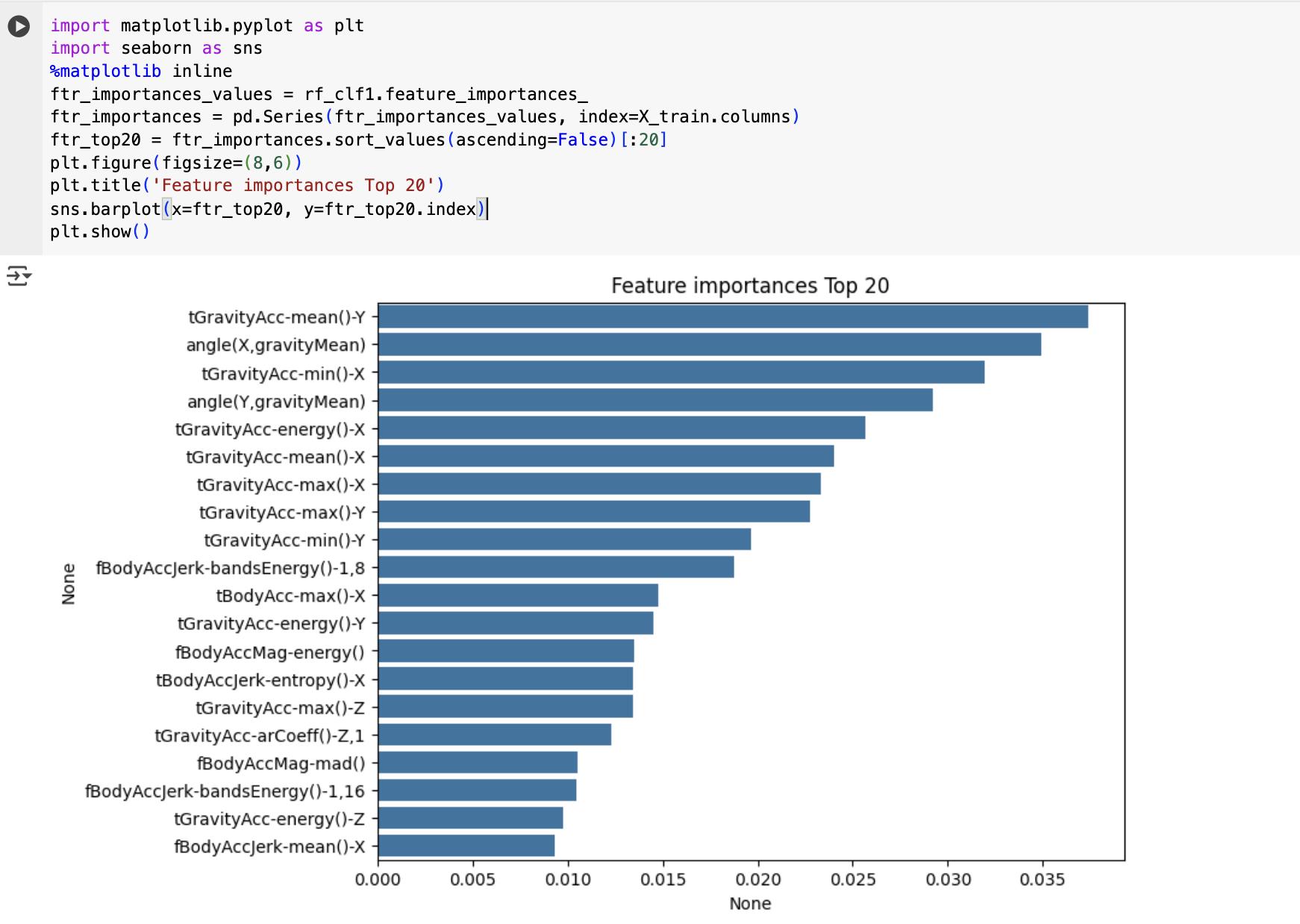
angle(X.gravityMean), tGravityAcc-mean()-Y, tGravityAcc-min()-X 등이 높은 피처 중요도를 가지고 있음.
5. GBM(Gradient Boosting Machine)
GBM 의 개요 및 실습
- 부스팅 알고리즘은 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측
- 잘못 예측한 데이터에 가중치 부여 → 오류를 점점 개선하며 학습 진행
대표적인 부스팅 구현:
- AdaBoost (Adaptive Boosting) : 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표 알고리즘
- 그래디언트 부스트
AdaBoost가 어떻게 학습을 진행 ?
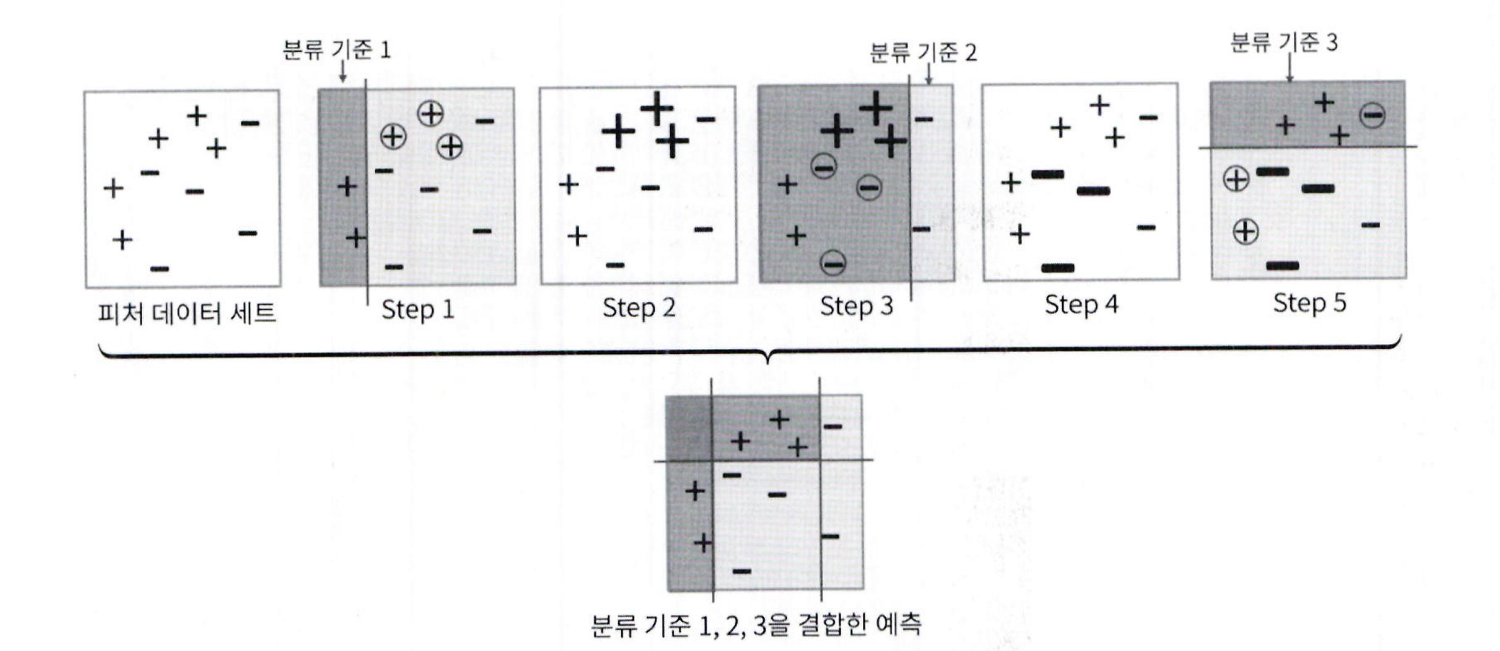
맨 왼쪽 그림과 같이 + 와 - 로 된 피처 데이터 세트가 있다면
- Step 1 은 첫 번째 약한 학습기 (weak learner) 가 분류 기준 1 로 + 와 - 를 분류.
- 동그라미로 표시된
4데이터
는 + 데이터가 잘못 분류된 오류 데이터입니다.
- Step 2 에서는 이 오류 데이터에 대해서 가중치 값을 부여함
- 가중치가 부여된 오류 + 데이터는 다음 약한 학습기가
더 잘 분류할 수 있게 크기가 커졌음.
- Step 3 은 두 번째 약한 학습기가 분류 기준 2 로 + 와 - 를 분류했음.
- 마찬가지로 동그라미로 표시된 - 데이터는 잘못 분류된 오류 데이터임.
- Step 4 에서는 잘못 분류된 이 - 오류 데이터에 대해 다음 약한 학습기가 잘 분류할 수 있게 더 큰 가중치를 부여합니다
( 오류 - 데이터의 크기가 커졌습니다 ).
- Step 5 는 세 번째 약한 학습기가 분류 기준 3 으로 + 와 -를 분류하고 오류 데이터를 찾음. 에이다부스트는 이렇게 약
한 학습기가 순차적으로 오류 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측을 수행합니다.
- 마지막으로 맨 아래에는 첫 번째 , 두 번째 , 세 번째 약한 학습기를 모두 결합한 결과 예측임.
- 개별 약한 학습기보다 훨씬 정확도가 높아졌음.
개별 약한 학습기는 다음 그림과 같이 각각 가중치를 부여해 결합.
예를 들어 첫 번째 학습기에 두 번째 학습기에 가중치 0.5, 세 번째 학습기에 가중치 0.8 을 부여한 후 모두 결합해 예측 가중치 0.3, 을 수행
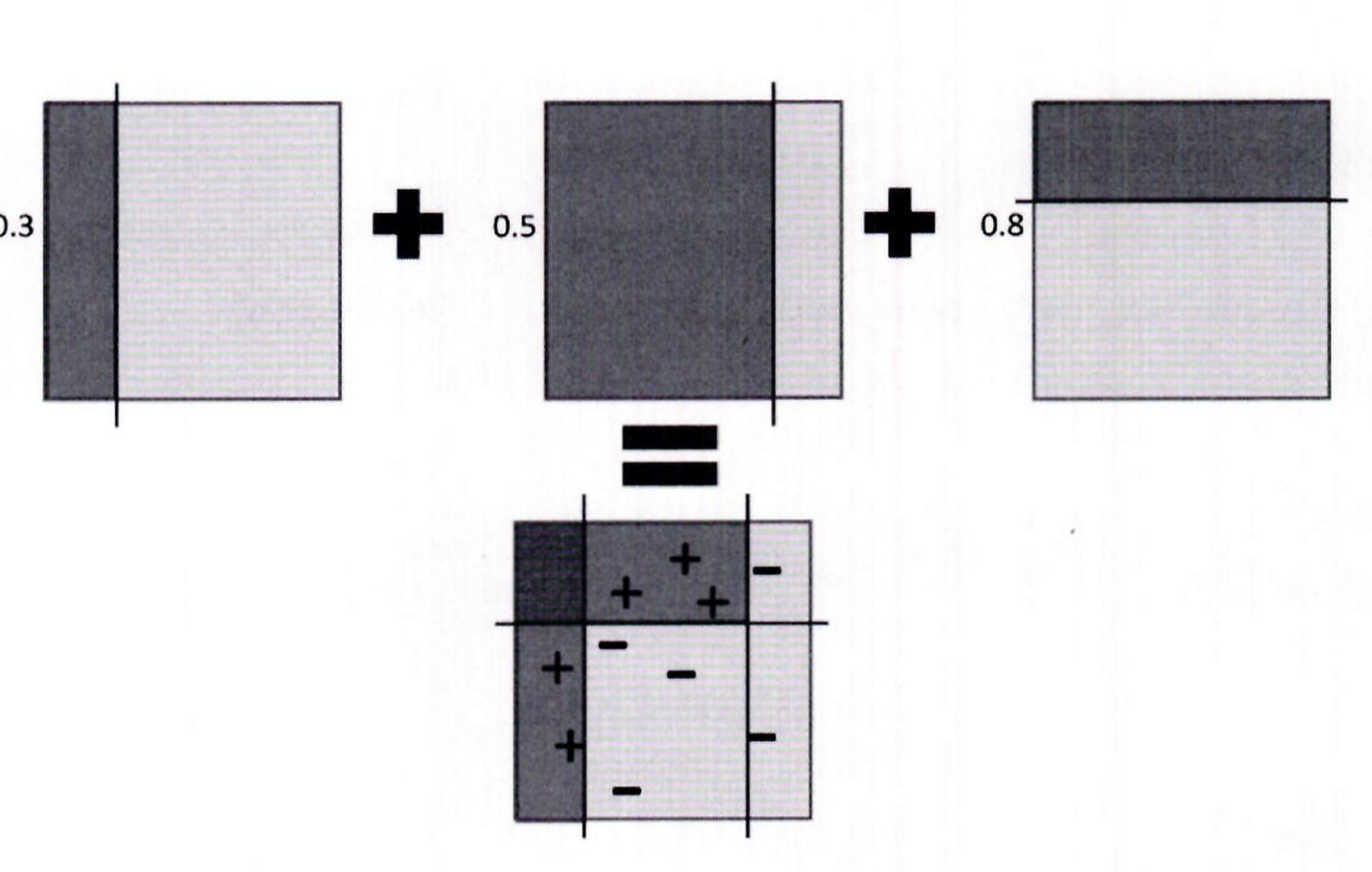
- GBM(Gradient Boost Machine)도 에이다부스트와 유사하나 , 가중치 업데이트를 경사 하강법 (Gradient Descent)을 이용하는 것이 큰 차이임
- 오류 값은 실제 값- 예측값임
- 분류의 실 제 결값을 y, 피처를 X1, X2, ... , Xn, 그리고 이 피처에 기반한 예측 함수를 F(x) 함수
오류식
h(x) = y - F(x)
- 최소화하는 방향성을 가지고 반복적으로 가 중치 값을 업데이트하는 것이 경사 하강법 (Gradient Descent)임
- GBM 은 분류, 회귀도 가능.
- 사이킷런은GBM 기반의 분류를 위해서
GradientBoostingClassifier클래스를 제공 - 사이킷런의 GBM 을 이용해 사용자 행동 데이터 세트를 예측 분류, 또한 GBM 으로 학습 수행 시간 측정
- get_human_dataset() 함수로 데이터 세트를 가져오기
from sklearn.ensemble import GradientBoostingClassifier
import time
import warnings
warnings.filterwarnings('ignore')
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간 : {0:.1f} 초".format(time.time() - start_time))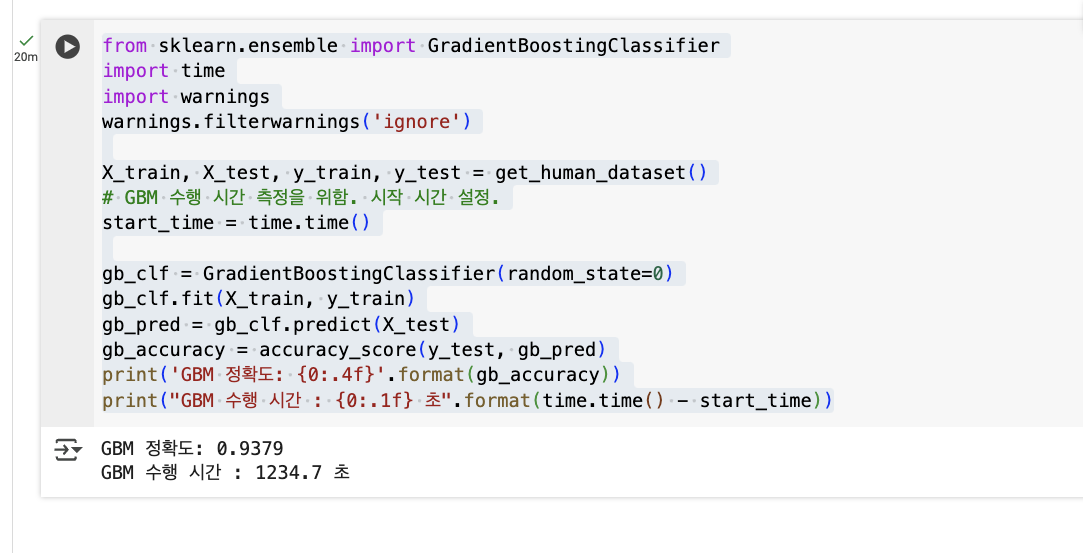
- 기본 하이퍼 파라미터만으로 93.89%의 예측 정확도로 (앞의 랜덤 포레스트보다 나은 예측 성능)
- 물론 항상 그런 것은 아니지만, 일반적으로 GBM이 랜덤 포레스트보다 예측 성능이 조금 뛰어난 경우가 많음
단점:
-
수행 시간이 오래 걸림
-
하이퍼 파라미터 튜닝에 더 많은 노력 필요
-
특히 수행 시간 문제는 GBM이 극복해야 할 중요한 과제
-
예) 위 코드는 필자의 노트북에서 약 537초(약 6분) 소요됨
-
사이킷런의
GradientBoostingClassifier는 약한 학습기의 순차적인 예측 오류 보정 방식으로 학습 -
랜덤 포레스트는 상대적으로 빠른 수행 시간 보장 -> 예측 결과 도출이 더 쉬움
GBM 하이퍼 파라미터 소개
loss :
- 경사 하강법에서 사용할 비용 함수를 지정함
- 특별한 이유가 없으면 기본값인 'deviance'를 그대로 적용함.
learning_rate :
- GBM 이 학습을 진행할 때마다 적용하는 학습률임 Weak learner가 순차적으로 오류 값을 보정해 나가는 데 적용하는 계수임.
- 0~1 사이의 값을 지정 가능 (기본값은 0.1)
- 너무 작은 값을 적용하면 업데이트 되는 값이 작아져서 최소 오류 값을 찾아 예측 성능이 높아질 가능성이 높음.
- 하지만 많은 weak learner 는 순차적인 반복이 필요해서 수행 시간이 오래 걸리고 , 또 너무 작게 설정하면 모든 weak learner의 반복이 완료돼도 최소 오류 값을 찾지 못할 수 있음.
- 반대로 큰 값을 적용하면 최소 오류 값을 찾지 못하고 그냥 지나쳐 버려 예측 성능이 떨어질 가능성이 높아지지만 , 빠른 수행이 가능함.
- 이러한 특성 때문에
learning_rate는n_estimators와 상호 보완적으로 조합해 사용 learning_rate를 작게 하고n_estimators를 크게 하면 더 이상 성능이 좋아지지 않는 한계점까지는 예측 성능이 조금씩 좋아질 수 있음.
n_estimators :
- weak learner의 개수임.
- weak learner가 순차적으로 오류를 보정하므로 개수가 많을수록 예측 성능이 일정 수준까지는 좋아질 수 있음.
- 개수가 많을수록 수행 시간 UP.
- 기본값은 100
subsample :
-
weak learner가 학습에 사용하는 데이터의 샘플링 비율임
-
기본값은 1 (전체 학습 데이터를 기반으로 학습한다는 의미)
-
과적이 염려되는 경우 subsample 을 1 보다 작은 값으로 설정
-
GBM 은 과적합에도 강한 뛰어난 예측 성능을 가진 알고리즘임 (수행 시간이 오래)
-
머신러닝 세계에서 가장 각광을 받고 있는 두 개의 그래디언트 부스팅 기반 ML 패키지는 XGBoost 와 LightGBM 임
6. XGBoost(eXtra Gradient Boost)
XGBoost 개요
- XGBoost는 트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나
- 유명한 캐글 경연 대회(Kaggle Contest)에서 상위권 데이터 과학자들이 XGBoost를 사용하면서 널리 알려짐
- 압도적인 차이는 아니지만, 일반적으로 다른 머신러닝 알고리즘보다 분류에서 뛰어난 예측 성능을 보임
- XGBoost는 GBM에 기반하면서도 GBM의 단점인 느린 수행 시간
- 과적합 규제(Regularization) 부재 문제를 해결하여 주목받음
- 특히 병렬 CPU 환경에서 병렬 학습 가능 → 기존 GBM보다 빠른 학습 시간
파이썬 래퍼 XGBoost 하이퍼 파라미터 (유형별로)
- 일반 파라미터 : 일반적으로 실행 시 스레드의 개수나 silent 모드 등의 선택을 위한 파라미터로서 디폴트 파라미터 값을 바꾸는 경우는 거의 없습니다
- 부스터 파라미터 : 트리 최적화 , 부스팅 , regularization 등과 관련 파라미터 등을 지칭합니다.
- 학습 태스크 파라미터 : 학습 수행 시의 객체 함수 , 평가를 위한 지표 등을 설정하는 파라미터입니다.
주요 일반 파라미터
- booster: gbtree(tree based model) 또는 gblinear(linear mode) 선택 , 디폴트는 gbtree 입니다.
- silent: 디폴트는 0 이며 , 출력 메시지를 나타내고 싶지 않을 경우 1 로 설정합니다.
- nthread: CPU 의 실행 스레드 개수를 조정하며 , 디폴트는 CPU 의 전체 스레드를 다 사용하는 것입니다. 멀티 코어 / 스레드 CPU 시스템에서 전체 CPU 를 사용하지 않고 일부 CPU 만 사용해 ML 애플리케이션을 구동하는 경우에 변경합니다.
학습 태스크 파라미터
- objective: 최솟값을 가져야 할 손실 함수를 정의합니다. XGBoost 는 많은 유형의 손실함수를 사용할 수 있습니다. 주로 사용되는 손실함수는 이진 분류인지 다중 분류인지에 따라 달라집니다.
- binary:logistic : 이진 분류일 때 적용합니다.
- multisoftmax. 다중 분류일 때 적용합니다. 손실수가 multisoftmax 일 경우에는 레이블 클래스의 개수인 num_class 파라미터를 지정해야 합니다.
- multi:soprob: multisotimax 와 유사하나 개별 레이블 클래스의 해당되는 예측 확률을 반환합니다.
- eval_metric: 검증에 사용되는 함수를 정의합니다. 기본값은 회귀인 경우는 rmse, 분류일 경우에는 error
rmse: Root Mean Square Error
mae: Mean Absolute Error
logloss: Negative log-likelihood
error: Binary classification error rate (0.5 threshold)
merror: Multiclass classification error rate
mlogloss: Multiclass logloss
auc: Area under the curve
XGBoost 버전 확인
import xgboost
print(xgboost.__version__)파이썬 래퍼 XGBoost 적용 - 위스콘신 유방암 예측
- 이번 절에서는 위스콘신 유방암 데이터 세트를 활용해
파이썬 래퍼 XGBoost API 사용법을 학습 - XGBoost의 파이썬 패키지인 xgboost는 자체적으로: 교차 검증, 성능 평가, 피처 중요도 시각화 (plotting) 기능 포함
- 조기 중단 기능도 내장: 지정된 num_boost_rounds 도달 전이라도 예측 오류가 개선되지 않으면 자동 중지 → 수행 시간 절약
- XGBoost는 GBM과 달리 병렬 처리 및 조기 중단 기능으로 빠른 수행 시간 처리 가능
- 단, CPU 코어가 적은 개인용 PC에서는
성능 향상을 체감하기 어려울 수도 있음 - 위스콘신 유방암 데이터 세트: 종양의 크기, 모양 등 다양한 속성 기반
- 악성 종양 (malignant) vs 양성 종양(benign) 분류
XGBoost를 이용해 종양의 다양한 피처에 따라
악성인지 양성인지 예측 수행
import xgboost as xgb
from xgboost import plot_importance
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
dataset = load_breast_cancer()
features= dataset.data
labels = dataset.target
cancer_df = pd.DataFrame(data=features, columns=dataset.feature_names)
cancer_df['target']= labels
cancer_df.head (3)
- 종양의 크기와 모양에 관련된 많은 속성이 숫자형 값으로 돼 있음
- 타깃 레이블 값의 종류는 악성 인 malignant 가 0 값으로 , 양성인 Denign 이 1 값임
레이블 값의 분포를 확인
print(dataset. target_names)
print(cancer_df['target'].value_counts())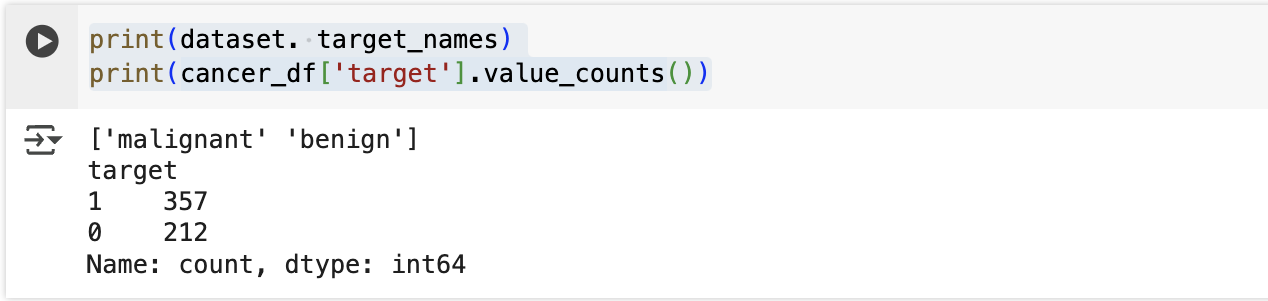
- 1 값인 양성 benign 이 357 개 , 0 값인 악성 malignant 가 212 개로 구성
- 위스콘신 유방암 데이터 세트의 80% 를 학습용으로 , 20% 를 테스트용으로 추출한 뒤 이 80% 의 학습용
데이터에서 90% 를 최종 학습용 , 10% 를 검증용으로 분할하겠습니다. - 여기서 검증용 데이터 세트를 별도로 분할하는 이유는 XGBoost 가 제공하는 기능인 검증 성능 평가와 조기 중단 (early stopping)을 수행해 보기 위함
- cancer_df 의 맨 마지막 칼럼이 레이블이므로 피처용 Dataframe 은 cancer_df 의 첫번째 칼럼에서 맨 마지막 두번째 칼럼까지를 :-1 슬라이싱으로 추출해 볼 예정
# cancer_df에서 feature용 DataFrame 과 Label 용 Series 객체 추출
# 맨 마지막 칼럼이 Label임. Feature 용 Dataframe은 cancer_df 의 첫번째 칼럼에서 맨 마지막 두번째칼럼까지를 : - 1 슬라이싱으로 추출.
X_features = cancer_df.iloc[:, :-1]
y_label = cancer_df.iloc[:, -1]
# 전체 데이터 중 80% 는 학습용 데이터 , 20% 는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(X_features, y_label, test_size=0.2,
random_state=156 )
# 위에서 만든 X_train, y_train 을 다시 쪼개서 90% 는 학습과 10% 는 검증용 데이터로 분리
X_tr, X_val, y_tr, y_val= train_test_split(X_train, y_train, test_size=0.1, random_state=156 )
print(X_train.shape, X_test.shape)
print(X_tr.shape, X_val.shape)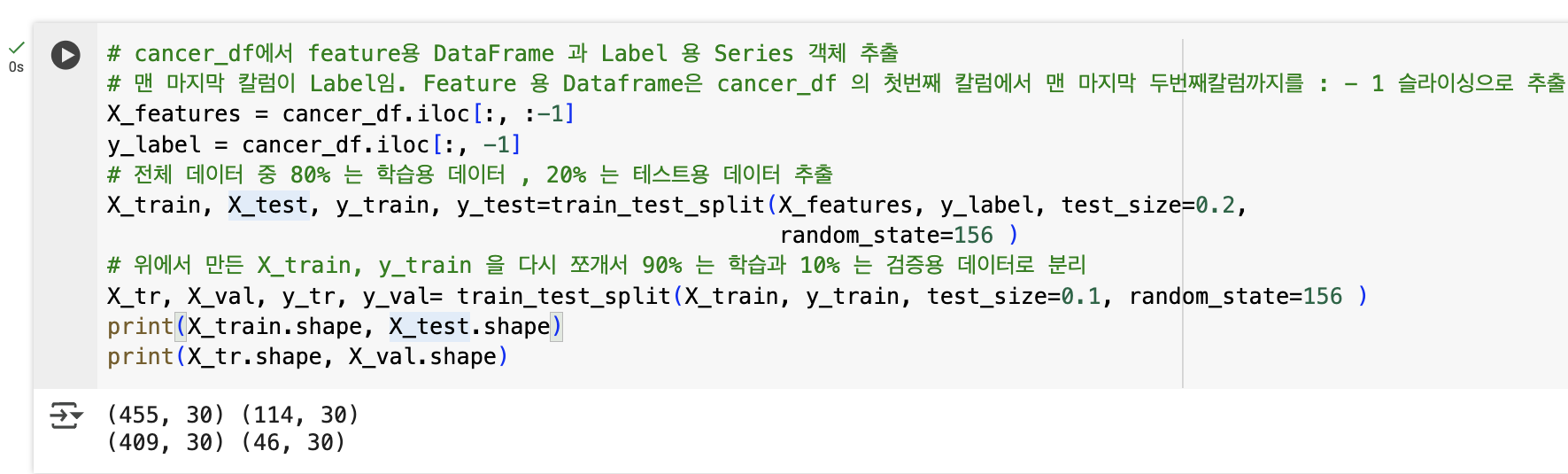
- 전체 569개 데이터 세트 중
- 학습용: 409개, 검증용: 46개, 테스트용: 114개로 분할됨
- 파이썬 래퍼 XGBoost는 사이킷런과의 주요 차이점 중 하나로 → 전용 데이터 객체 DMatrix 사용
- 따라서, Numpy 또는 Pandas로 구성된 학습/검증/테스트 데이터 세트를 모두 DMatrix 객체로 변환해야 XGBoost 모델에 입력 가능
DMatrix 주요 입력 파라미터:
data: 피처 데이터 세트
label: 분류일 경우 레이블 데이터 세트 / 회귀일 경우 숫자형 종속값
DMatrix는 다음과 같은 형식도 지원:
Numpy, DataFrame, Series
libsvm txt 포맷 파일, xgboost 이진 버퍼 파일
# 만약 구버전 XGBoost 에서 DataFrame 으로 DMatrix 생성이 안 될 경우 X_train.values로 넘파이 변환.
# 학습 , 검증 , 테스트용 DMatrix 를 생성.
dtr = xgb.DMatrix(data=X_tr, label=y_tr)
dval = xgb.DMatrix(data=X_val, label=y_val)
dtest = xgb.DMatrix(data=X_test , label=y_test)- 파이썬 래퍼 XGBoost 모듈인 xgboost를 이용해 학습을 수행하기 전에 먼저 XGBoost의 하이퍼 파
라미터를 설정 - XGBoost의 하이퍼 파라미터는 주로 딕셔너리 형태로 입력
- max_depth( 트리 최대 깊이) 는 3.
- 학습률 eta 는 0.1(XGBClassiier 를 사용할 경우 eta가 아니라 learning_rate입니다).
- 예제 데이터가 0 또는 1 이진 분류이므로 목적함수 (objective) 는 이진 로지스틱(binary:logistic).
- 오류 함수의 평가 성능 지표는 logloss.
- num_rounds( 부스팅 반복 횟수 ) 는 400 회
params = { 'max_depth' :3,
'eta': 0.05,
'objective': 'binary:logistic',
'eval_metric': 'logloss'
}
num_rounds = 400- XGBoost 학습은
train()함수에 하이퍼 파라미터 전달 - 조기 중단:
early_stopping_rounds=50설정 → 지표 개선 없으면 중단 - 조기 중단 위해 evals(평가용 데이터 세트), eval_metric(평가지표) 함께 설정 필요
- 매 반복마다 평가 세트로 지표 성능 확인하며 학습 진행
- 평가용 데이터 세트는 학습과 평가용 데이터 세트를 명기하는 개별 튜플을 가지는 리스트 형태로 설정. 가령 dirol 학습용.
dval 이 평가용이라면 ((dtr, train').(dval, eval')]와 같이 , 학습용 DMatrix는 'train 으로 , 평가용 Dmatrix 는 'eval'로 개별
튜플에서 명기하여 설정. 과거 버전 XGBoost 는 학습 데이터 세트와 평가용 데이터 세트를 명기해주어야 했으나 현재 버
전은 평가용 데이터 세트만 명기해 줘도 성능 평가를 수행하므로 ((dval, 'eval')]로 설정해도 무방.eval_metric은 평가 세트에 적용할 성능 평가 방법. 분류일 경우 주로 error( 분류 오류 ), logloss' 를 적용.
- xgboost 모듈의 train() 함수를 호출하여 학습 수행
- 평가용 데이터 세트 설정 예: evals = [(dtr, 'train'), (dval, 'eval')]
- dtr: 학습용 DMatrix
- dval: 검증용 DMatrix
- evals 인자로 평가 세트 전달, eval_metric은 앞서 params 딕셔너리에 지정함
- 학습 반복마다 evals 세트에 대한 평가 지표 결과 출력
- train() 호출 시 학습 완료된 모델 객체 반환
# 학습 데이터 셋은 'train' 또는 평가 데이터 셋은 'eval' 로 명기합니다.
eval_list = [(dtr, 'train'),(dval,'eval')] # 또는 eval list=|(dval, eval')] 만 명기해도 무방.
# 하이퍼 파라미터와 early stopping 파라미터를 train() 함수의 파라미터로 전달
xgb_model = xgb.train(params = params, dtrain=dtr, num_boost_round=num_rounds , \
early_stopping_rounds=50, evals=eval_list)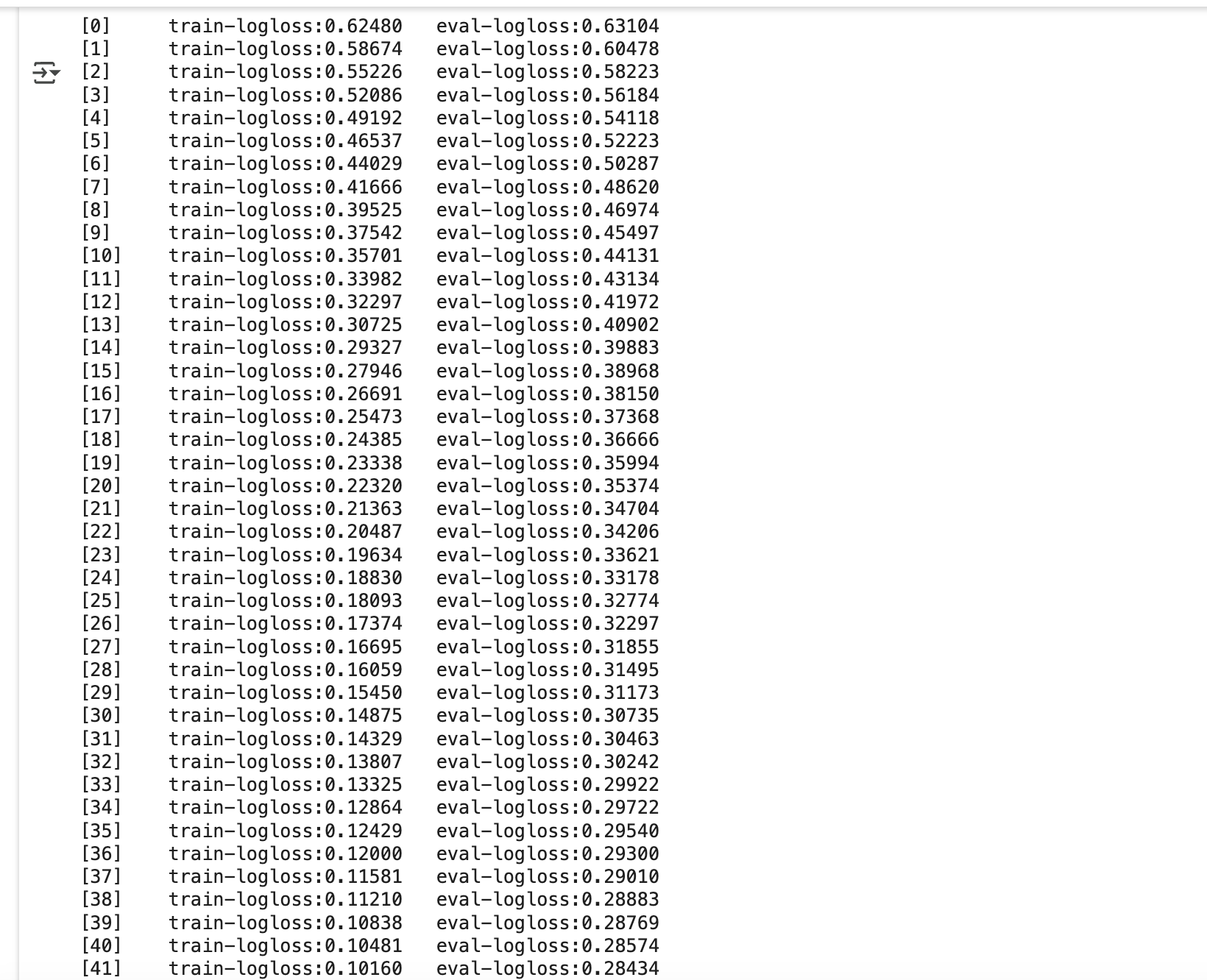
- train() 호출 시 train-logloss와 eval-logloss가 반복마다 감소
- 400회 반복 설정했지만, 126번째 이후 성능 향상 없음 → early_stopping_rounds=50에 따라 176회에서 조기 종료
- 최저 eval-logloss: 0.25587 (126회)
- 이후 50회 동안 개선 없음 → 학습 중단
- 학습 완료된 모델 객체는 predict() 메서드로 예측 수행
주의:
- 사이킷런
predict()→ 클래스 값(0, 1) 반환 - XGBoost
predict()→ 예측 확률값 반환 - 이진 분류이므로 예측 확률이 0.5보다 크면 1, 그렇지 않으면 0으로 변환하는 로직 추가 필요
pred_probs = xgb_model.predict(dtest)
print('predict() 수행 결값을 10 개만 표시 , 예측 확률 값으로 표시됨 ')
print(np.round(pred_probs[:10],3))
# 예측 확률이 0.5보다 크면 1, 그렇지 않으면 0 으로 예측값 결정하여 List 객체인 preds에 저장
preds = [1 if x > 0.5 else 0 for x in pred_probs ]
print('예측값 10 개만 표시:',preds[:10])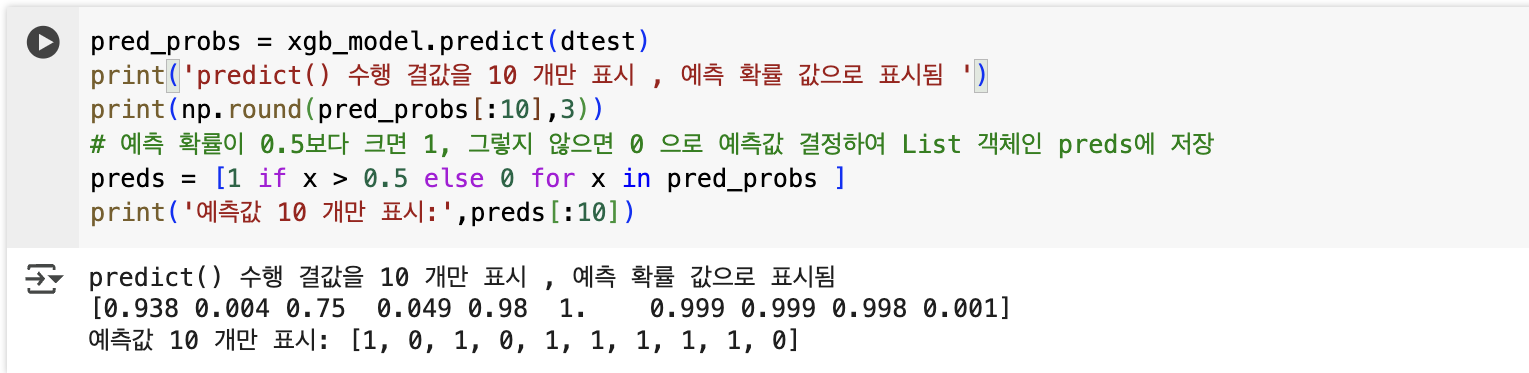
get_clf_eval(y_test, preds, pred_probs)
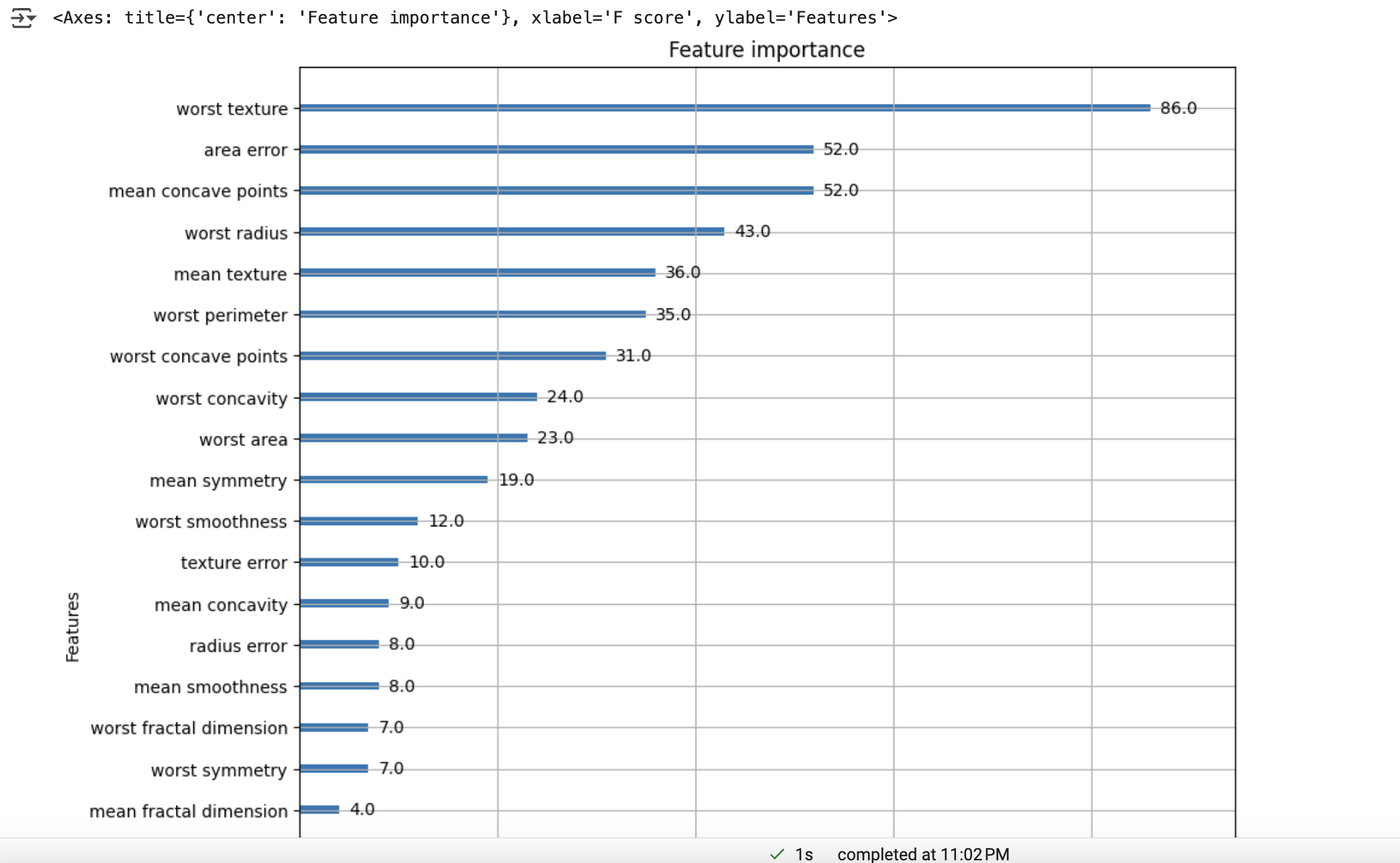
- 다음으로 xgboost 패키지 내장 시각화 기능 수행
plot_importance()API 사용 → 피처 중요도 막대그래프 출력- 기본 기준: f스코어 (트리 분할 시 해당 피처가 사용된 횟수 기반)
- 사이킷런은 직접 시각화 코드 작성 필요(featureimportances), xgboost는 plot_importance()만 호출하면 바로 시각화 가능
사용법:
plot_importance(모델 객체, ax=matplotlib 객체) 형식
유의사항:
- 넘파이 기반 학습 시, 피처명을 알 수 없으므로
Y축에는 f0, f1 형식으로 순서 기반 피처명 출력됨
(예: f0은 첫 번째 피처, f1은 두 번째 피처)
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)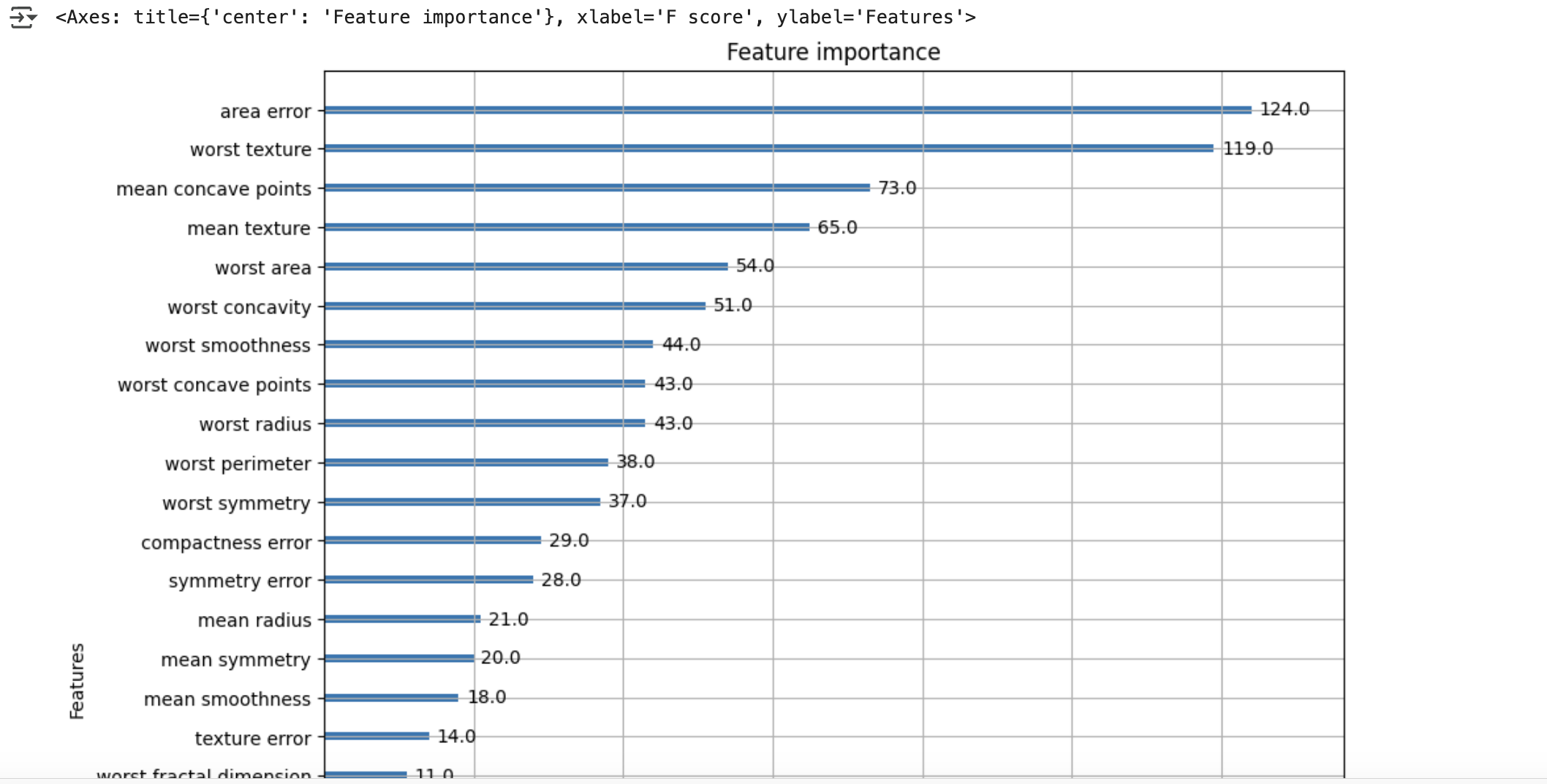
- xgboost에서도 결정 트리와 같은 트리 기반 규칙 구조 시각화 가능
xgboost.to_graphviz()API를 사용하면
주피터 노트북에서 규칙 트리 구조 시각화 가능
조건:
-
Graphviz 프로그램 및 패키지 설치 필요
-
파라미터로는 학습 완료된 모델 객체, 그리고 Graphviz가 참조할 파일명 입력
-
참고: Graphviz 설치 및 설명은 앞의 결정 트리 파트 참고
-
또한, 파이썬 래퍼 XGBoost는
cv()API를 통해
GridSearchCV와 유사한 교차 검증 기반 최적 파라미터 탐색 기능 제공xgboost.cv(params, dtrain, num_boost_round=10, nfold=3, stratified=False, folds=None, metrics=),
obj=None, feval-None, maximize-False, early_stopping_rounds=None, fpreproc=None, as_pandas=True,
verbose_eval-None, show_stdv=True, seed=0, callbacks=None, shuffle=True) -
params (dict): 부스터 파라미터
-
dtrain (DMatrix): 학습 데이터
-
num_boost_round (int): 부스팅 반복 횟수
-
nfold (int):CV 폴드 개수.
-
stratified (bool): CV 수행 시 층화 표본 추출 (stratified sampling) 수행 여부
-
metrics (string or list of strings): CV 수행 시 모니터링할 성능 평가 지표
-
early_stopping_rounds (int): 조기 중단을 활성화시킴. 반복 횟수 지정.
- xgb.cr 의 반환값은 DataFrame 형태임
사이킷런 래퍼 XGBoost의 개요 및 적용
- XGBoost 개발 그룹은 사이킷런 연동을 위해
사이킷런 전용 래퍼 클래스를 개발함 - 이 래퍼 클래스는 사이킷런의 Estimator를 상속하여 fit()과 predict()만으로 학습과 예측 가능
- GridSearchCV, Pipeline 등 사이킷런 유틸리티와 호환
- 따라서 기존 사이킷런 기반 ML 프로그램에서 알고리즘 클래스만 XGBoost 래퍼로 바꾸면 그대로 사용 가능
래퍼 클래스 종류:
- XGBClassifier: 분류용
- XGBRegressor: 회귀용
- 사이킷런 래퍼 XGBoost는 기존 파이썬 래퍼 XGBoost와 일부 하이퍼 파라미터 차이 있음
- 사이킷런과의 호환성을 위해 기존 xgboost 네이티브 파라미터 일부를 변경 적용
eta - learning_rate
sub_sample - subsample
lambda - reg_lambda
alpha - reg_alpha
-
n_estimators(사이킷런용)과num_boost_round(파이썬 래퍼용)은 동일한 의미의 파라미터 -
사용 시 주의점: 파이썬 래퍼 XGBoost API에서는
num_boost_round만 적용되고,
n_estimators는 무시됨 -
반면, XGBClassifier (사이킷런 래퍼)에서는
n_estimators가 적용됨
분류용 사이킷런 래퍼 클래스 XGBClassifier 사용
데이터 세트: 위스콘신 유방암
하이퍼 파라미터 설정:
n_estimators=400, learning_rate=0.1, max_depth=3
학습/테스트 데이터 구성:
학습: X_train, y_train (검증용으로 분할 전 데이터 사용)
테스트: X_test, y_test (그대로 유지)
사용 메서드:
fit(): 학습
predict(): 클래스 예측
predict_proba(): 클래스 확률값 예측
# 사이킷런 래퍼 XGBoost 클래스인 XGBClassifier 임포트
from xgboost import XGBClassifier
# Warning 메시지를 없애기 위해 eval_metric 값을 XGBClassifier 생성 인자로 입력.
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3,
eval_metric='logloss')
xgb_wrapper.fit(X_train, y_train, verbose=True)
w_preds = xgb_wrapper.predict(X_test)
w_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]get_clf_eval(y_test, w_preds, w_pred_proba)- 사이킷런 래퍼 XGBoost (XGBClassifier)가
파이썬 래퍼보다 더 좋은 평가 결과를 보임 - 위스콘신 데이터 세트의 크기가 작기 때문
- 파이썬 래퍼에서는 조기 중단을 위해 학습 데이터를 추가 분리 → 결과적으로 학습 데이터 수 감소 → 성능 저하
- 작은 데이터 세트에서는 검증 데이터 분리나 교차 검증 시 성능 수치의 불안정성 발생 가능성 큼
- 데이터 수가 많을 경우, 학습/검증 데이터 분리 + 적절한 조기 중단 → 과적합 개선 가능 → 모델 성능 향상 기대
- 사이킷런 래퍼 XGBoost에서 조기 중단 적용 방법
fit() 함수에 조기 중단 관련 파라미터 직접 입력 early_stopping_rounds: 향상되지 않아도 반복할 횟수 (예: 50)eval_metric: 평가 지표 (예: 'logloss')eval_set: 평가용 데이터 세트
예: [(X_tr, y_tr), (X_val, y_val)]
→ 별도 문자열(label) 필요 없음, 순서로 자동 인식- 작은 데이터일수록 조기 중단 시 데이터 분할이 성능에 큰 영향, → 큰 데이터에서는 오히려 성능 향상 효과 큼
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3, early_stopping_rounds=50, eval_metric="logloss")
evals = [(X_tr, y_tr), (X_val, y_val)]
xgb_wrapper.fit(X_tr, y_tr, eval_set=evals, verbose=True)
ws50_preds = xgb_wrapper.predict(X_test)
ws50_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]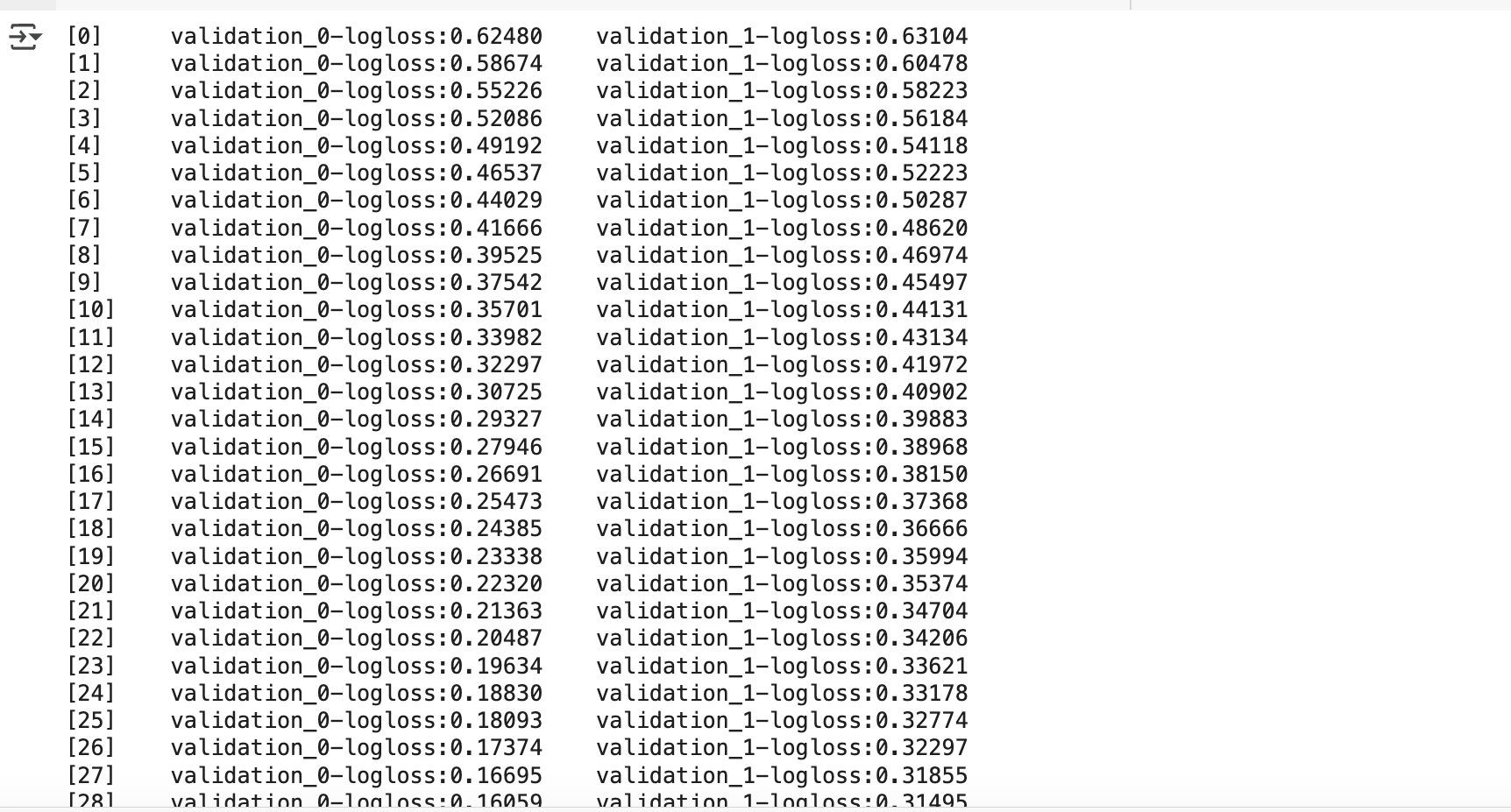
- n_estimators=400으로 설정했지만,
조기 중단으로 인해 176번째 반복에서 학습 종료 - 126번째 반복에서 검증 데이터(validation_1-logloss)가 0.25587로 가장 낮았고
이후 50번 동안 성능 향상 없음 → 조기 종료 - XGBClassifier 의 조기 중단 예측 성능은
파이썬 래퍼와 동일한 수준 - 단, 위스콘신 데이터 세트가 작아,
조기 중단을 위한 검증 데이터 분리 시 성능이 소폭 저하되는 경향 있음 → 학습에 검증 데이터 없이 전체 데이터 사용 시 오히려 성능이 더 좋을 수 있음
get_clf_eval(y_test, ws50_preds, ws50_pred_proba)
- early_stopping_rounds 값을 너무 작게 설정하면
→ 충분한 학습이 이루어지기 전에 조기 종료될 위험 - 예:
early_stopping_rounds=10으로 설정 시
아직 성능이 향상될 여지가 있음에도, 10번 연속 향상이 없으면 반복 중단 → 예측 성능 저하 가능 - 따라서, 지나치게 작은 조기 중단 값은 주의 필요
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3, early_stopping_rounds=10, eval_metric="logloss")
xgb_wrapper.fit(X_tr, y_tr, eval_set=evals, verbose=True)
ws10_preds = xgb_wrapper.predict(X_test)
ws10_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]
get_clf_eval(y_test, ws10_preds, ws10_pred_proba)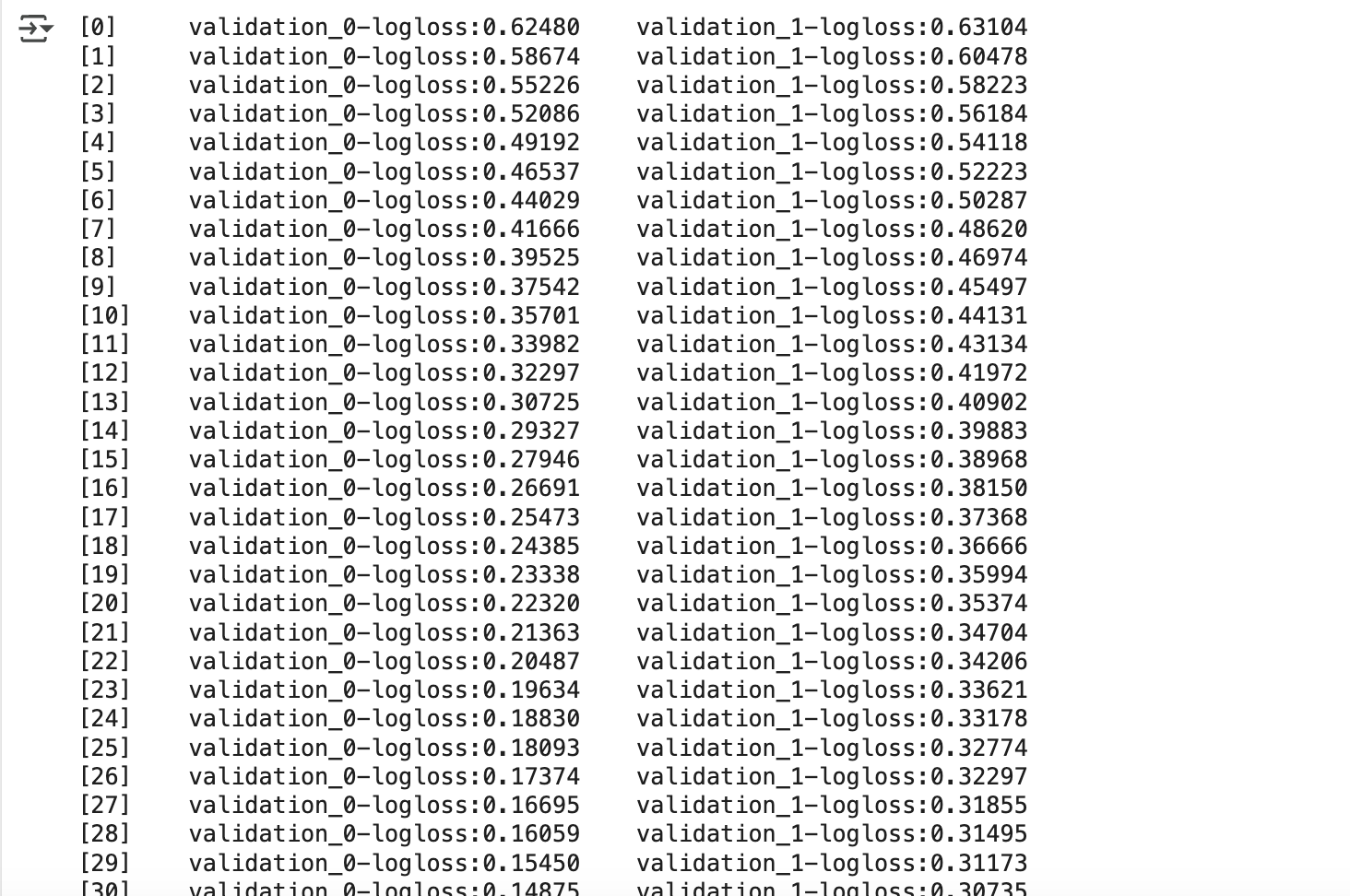
- 103번째 반복에서 학습 종료됨
- 93번째 반복의 logloss: 0.25865
- 103번째 반복의 logloss: 0.25991 → 10번 동안 향상 없음 → 조기 중단
- 조기 중단 후 예측 정확도: 0.9474
- 이는 early_stopping_rounds=50일 때의 0.9561보다 낮음 → 조기 중단 값을 너무 작게 설정하면 성능 저하 가능
- plot_importance() API는 사이킷런 래퍼 클래스(XGBClassifier)에도 사용 가능 → 파이썬 래퍼 클래스와 동일한 시각화 결과 제공
- 해당 시각화 코드는 출력 결과만 제외하고 그대로 실행 가능
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
# 사이킷런 래퍼 클래스를 입력해도 무방.
plot_importance(xgb_wrapper, ax=ax)