
0. Word2Vec 요약
- “같은 문장에서 나타난 단어들은 의미가 유사할 것이다.”를 가정으로 제안된 알고리즘
- NNLM의 느린 학습 속도와 정확도를 개선한 것으로 NNLM은 이전에 등장한 단어들만 참고하지만, word2vec은 전후 단어 모두 참고한다.
- CBOW: 주변 단어들을 입력으로 받아 중간에 위치한 단어를 예측
- Skip-gram: 중간에 있는 단어로 주변 단어들을 예측 ⇒ 둘 다 가중치 행렬을 2번 곱한 후, projection layer, output layer를 거치기 때문에 유사한 매커니즘이다.
- 본 논문은 대용량 데이터셋으로부터 continuous vector representation을 구하는 방법 2가지(CBOW, skip-gram) 방법을 제안했으며, 더 적은 연산량으로 더 높은 성능을 달성했다.
1. Introduction
- 이전까지는 n-gram, BoW(bag of words)처럼 one-hot vector를 사용해 단어를 표현했다. 하지만 이러한 방식을 사용하면 모든 단어간의 거리는 , 코사인 유사도는 0으로 단순히 인덱스의 나열이기 때문에 단어들 간의 유사성(연관성)을 학습하지 못한다.
- 많은 데이터셋을 사용한 간단한 모델의 성능이 적은 데이터셋을 사용한 복잡한 모델의 성능보다 높기 때문에 이전까지는 one-hot vector를 많이 사용했다. 또한 통계 기반 방식에서는 n-gram이 더 효율적이다. 하지만 기계학습 기반 방식으로 바뀌면서 복잡한 모델에 많은 데이터셋을 활용하기 위해 벡터 형식으로 단어를 표현하는 distributed representation 방법을 제안한다. 단어의 의미를 여러 차원에 분산해 표현한다.
1.1 Goals of the Paper
- 본 논문에서는 대량의 데이터셋으로부터 높은 품질의(high-quality) word vector를 학습하는 방법을 제안한다. 단어가 의미적 유사성 뿐만 아니라, multiple degrees of similarity를 학습할 수 있다. 또한 임베딩 벡터를 더하고 빼는 연산을 통해 다른 단어를 도출할 수 있다. ex)
- syntatic and semantic regularities를 모두 측정하기 위해 새로운 test set을 구축했고 사용되는 단어 벡터의 차원에 따라 학습 시간과 정확도가 달라지는 것 또한 확인했다.
multiple degrees of similarity
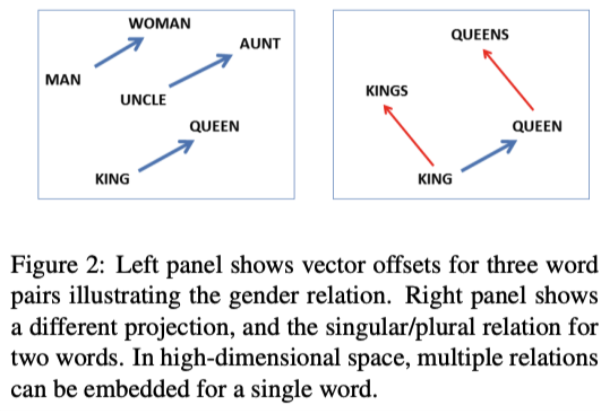
reference 표시된 논문의 예
- 같은 noun이어도 형태의 차이(e.g단수/복수)를 가져도 비슷한 표현으로 볼 수 있는 것
e.g, apple, apples - 한 개의 단어가 여러개의 비슷한 성격을 가지는 단어와도 연결될 수 있는 것(e.g, 성별, 직위) → 왼쪽 그림은 각 단어가 1:1매핑(man → woman, king → queen), 반면 오른쪽 그림은 1개의 단어가 여러개와 연결(king → kings & king → queen)
- 한개의 단어가 여러개의 비슷한 의미 특성을 가진 단어와도 연결될 수 있는 의미. big-bigger-biggest
1.2 Previous Work
n-gram
- 언어 모델링(Language Modeling)은 문장에 확률을 할당하는 것으로, 이전 단어들로부터 다음 단어를 예측한다.
- n-gram 모델은 앞 (n-1)개의 단어를 참고해 다음 단어를 예측한다. 하지만, 이러한 n-gram 언어 모델은 충분한 데이터를 보지 못하면 정확히 모델링하지 못하는 희소 문제(sparsity problem)가 있다.
- 훈련 코퍼스에 ‘boy is spreading smile.’이라는 문장이 있으면 P(smiles | boy is spreading)는 확률을 가지지만, 해당 문장이 없으면 현실적으로는 존재할 수 있는 문장이지만 확률은 0이 된다.

- ‘발표 자료를 살펴보다'라는 시퀀스는 존재하지만 ‘발표 자료를 톺아보다’라는 시퀀스가 존재하지 않는 코퍼스로 학습한 모델: 위의 두 경우 중 ‘톺아보다'를 선택해야 하지만, ‘톺아보다'가 코퍼스에 없기 때문에 모델은 P(톺아보다|발표 자료를) 확률을 0으로 계산한다. → 훈련 코퍼스에 없는 단어는 예측하지 못한다.
- 또한, 앞에서 단어 몇개를 볼 지 n을 정할 때 trade-off가 존재한다. n이 크면 더 긴 단어 시퀀스를 보고 예측해 정확해지지만, 해당 시퀀스를 코퍼스에서 count하기 어려워진다.
- 언어 모델이 단어의 의미적 유사성을 학습할 수 있다면, 훈련 코퍼스에 없는 단어 시퀀스에 대한 예측도 가능할 것이다. 이러한 아이디어가 반영된 모델이 NNLM, word embedding이다.
Sparse representation
- 단어를 컴퓨터에게 가르치려면 컴퓨터가 읽을 수 있는 형태로 변환해야 한다. 그 방법 중 하나가 one-hot encoding
- [코끼리, 사자, 뱀] 3개의 단어로 이루어진 vocab을 one-hot encoding을 사용해 각 단어를 one-hot vector로 표현하면 아래와 같다.

- one-hot vector는 간단하고 직관적인 표현 방법이지만 vocab이 커질수록 차원수도 증가해 계산복잡성이 늘어나고, 자기 자신만 1이고 나머지 요소는 0의 값을 가지는 sparse vector 형태를 갖는다.
- 코끼리와 사자 one-hot vector를 내적하면 내적값은 0으로 두 벡터가 서로 직교해 one-hot vector로 표현된 모든 단어가 독립적이라는 의미지만, 현실에서 단어들 사이에는 관련성이 있으며 유사어/반의어 관계가 있다.
- 이러한 문제를 해결한 것이 distributed representation이다.
2. Model Architectures
2.1 NNLM
- 다음 단어를 예측할 때 앞에 등장한 모든 단어를 참고하지 않고, n-gram처럼 정해진 n개의 단어만 참고한다. NNLM에서는 참고하는 단어의 개수(범위)를 window라고 한다.
- 예시 - 아래의 훈련 코퍼스에서 “sit”을 예측 하는 경우


- 위의 그림과 같이 NNLM은 4개의 layer로 이루어진다(input, projection, hidden, output layer)
- 입력 단어를 one-hot vector로 인코딩한다. 전체 vocab에는 7개의 단어가 있으므로 각 단어는 7차원의 벡터로 표현된다. 위의 예시는 window=4이므로 “sit”을 예측할 때 4개의 단어 “will the fat cat”만 참고한다.
- input layer는 단어 4개의 one-hot vector, output layer는 예측해야하는 단어 “sit”의 one-hot vector이다. output layer의 vector는 모델이 예측한 값의 오차를 구하기 위한 레이블로 사용되고, 인공 신경망은 오차로부터 손실 함수를 사용해 학습한다.
- NNLM은 input layer를 거쳐 projection layer를 거치는데, 가중치 행렬과 곱셈 연산은 있지만 일반 은닉층과는 달리 활성화 함수가 존재하지 않는다.
projection layer
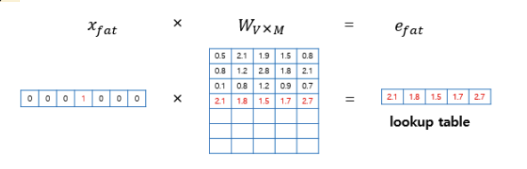
- Projection layer에서는 V차원 input vector 에 크기가 인 가중치행렬 W를 곱해 차원의 embedding vector**를 얻는다. 위 그림에서 input vector 은 7차원 one-hot vector로 7x5 가중치 행렬 W와 행렬곱을 통해 5차원 embedding vector 을 얻는다.

- projection layer 안에서 이루어지는 연산을 살펴보면 위의 그림과 같으며, 해당 layer를 거치면 0이었던 요소들이 값으로 채워져 dense vector가 된다.
- one-hot vector는 i번째 인덱스 값만 1이기 때문에 i번째 행을 그대로 읽어오는 것과 동일해 이 과정을 lookup이라 하고, 수행 결과 얻은 벡터를 lookup table이라고 한다.
- 각 단어는 lookup table을 통해 임베딩 벡터(가운데 노란색)로 변환되고, 4개의 임베딩 벡터를 concat해 하나의 벡터로 연결한다. 5차원의 임베딩 벡터 4개를 연결한 20차원의 벡터를 얻는다.
- 이렇게 단순히 embedding vector를 concat한 것은 단어간 연관성이 없으며, hidden layer에서 단어간의 연관성을 학습한다.
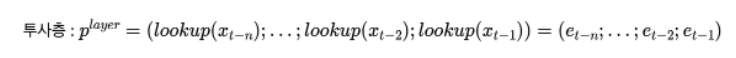
t번째 단어를 예측할 때 n=window size, 세미콜론(;)=concat 기호라고 하면 projection layer를 위와 같은 식으로 표현할 수 있다.
hidden layer
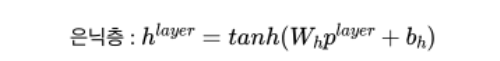
- 은닉층 = 활성화 함수(입력 * 가중치 + 편향) 을 의미한다. 가중치와 편향을 각각 , 라고 표현하고 tanh 활성화 함수를 사용하면 은닉층은 위와 같은 식으로 표현할 수 있다.
- linear 연산 후 tanh함수를 거치기 때문에 nonlinear한 출력값을 가진다.
output layer
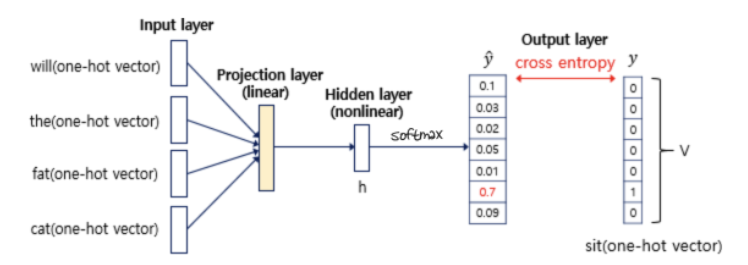
hidden layer를 거친 벡터는 output layer에서 다른 가중치 와 곱해지고 편향 가 더해져 입력과 동일한 V차원의 벡터를 얻는다.

output layer에는 활성화 함수로 softmax를 사용해 벡터의 각 원소는 0-1사이 값을, 총 합은 1이 되는 상태로 바뀐다.
NNLM이 예측한 벡터 y_hat은 다음 단어로 각 인덱스가 올 확률을 의미한다. 예측 벡터 y_hat이 정답 벡터 y에 가까워지게 하기 위해 cross-entropy 손실 함수를 사용한다. V개의 단어 중 정답인 “sit”을 예측할 수 있도록 다중 클래스 분류 문제이다. 역전파가 이루어지면 모든 가중치 행렬들이 학습되는데, projection layer의 가중치 행렬도 포함되므로 embedding vector 값도 학습된다.
training complexity 계산 공식
- E: epoch
- T: training set의 단어 개수
- Q: model architecture에서 정의됨
computational complexity
N개의 입력(이전) 단어가 주어졌을 때, 각 단어는 (1, V) one-hot vector로 표현되며 (V, D) 가중치 행렬과 연산해 (1, D)차원의 embedding vector로 변환된다. 총 N개 단어의 결과를 concat하면 (N, D) 크기의 벡터가 된다.
계산 복잡도는 위의 식처럼 표현할 수 있는데, 각 항은 input → projection, projection → hidden, hidden → output layer로의 계산 복잡도이다. 가장 연산량이 많은 항은 마지막 항이지만, softmax 대신 hierarchical softmax를 사용하면 로 연산량을 줄일 수 있다. → 항이 연산량에 가장 영향을 많이 준다.
Hierarchical Softmax
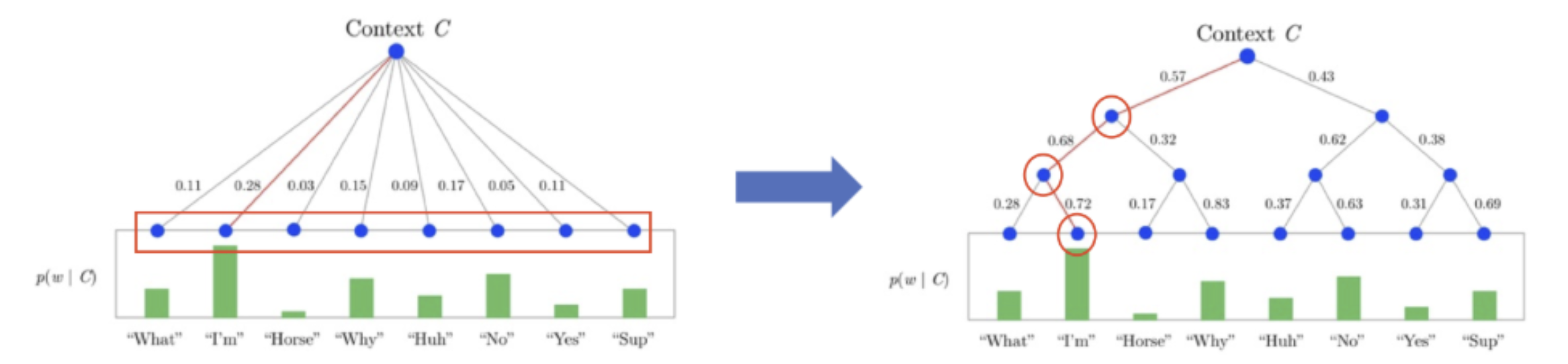
- 이전까지 사용했던 softmax는 1층으로 구성되어 다음 단어의 확률을 구할 때 노드 개의 확률값을 계산해야하지만, hierarchical softmax는 허프만 코딩을 사용해 개의 확률값만 계산하면 된다.
- 여기서 허프만 코딩은 이진 트리를 사용해 단어 등장 빈도수에 따라 다른 길이의 코드를 부여하는 압축방식(?) 이라고 생각할 수 있다.
- 위의 그림에서 왼쪽은 일반 softmax, 오른쪽은 hierarchical softmax를 나타낸 모습이다. 다음 단어 "I'm"이 올 확률을 구할 때 softmax 방식에서는 모든 단어 8개의 확률을 구해야 하지만, hierarchical softmax을 사용하면 root node부터 "I'm" leaf node까지의 경로에 위치만 3개 단어에 대한 확률만 필요하다.
- V=8 일 때, 계산 복잡도가 -> 로 감소한 것을 확인할 수 있다.
장점
- train data가 충분하다면 유사한 목적으로 사용된(비슷한 의미로 사용된??) 벡터는 유사한 임베딩 값을 가진다. → train corpus에 없는 단어 시퀀스라도 예측할 수 있다.
- 단어를 표현하기 위해 embedding vector를 사용해 단어의 유사도를 계산 → 희소 문제(sparsity problem) 해결
단점
- 고정된 길이의 입력(input vector)
- 단어를 예측할 때 이전의 모든 단어를 참고하지 않고 한정된 n개의 단어만 참고할 수 있다. (n-gram의 같은 단점)
2.2 RNNLM
- projection layer를 없애고 hidden layer만 사용해 정확도 면에서는 성능이 떨어졌지만, 고정된 입력만 받을 수 있는 NNLM의 한계를 극복한 모델이다. RNN은 이론적으로 더 복잡한 패턴을 다룰 수 있다.
- 또한, RNN을 사용해 바로 이전 단어 뿐만 아니라 이전 단어의 hidden state도 사용하기 때문에 약간의 문맥 정보를 학습할 수 있다.
- RNN에서는 단어를 H차원의 hidden state vector로 표현한다.
- NNLM에서와 마찬가지로 hierarchical softmax를 사용하면 을 로 연산량을 줄일 수 있어 항이 연산량에 가장 많은 영향을 준다.
2.3 Parallel training of Neural Networks
- 구글의 첫 번째 머신러닝 프레임워크 DistBelief를 사용해 실험을 진행했고 mini-batch와 Adagrad 사용했다. (Tensorflow가 구글의 두 번째 프레임워크)
- 병렬화
- 병렬화에는 데이터 병렬화와 모델 병렬화가 있다.
- 데이터 병렬화: 동일한 모델을 각 노드(gpu)마다 보내고, 학습 데이터를 병렬화에 사용하는 노드 갯수만큼 쪼개서 노드에 보내준다. 그리고 각각 계산한 그래디언트를 모아서 모델을 업데이트하고, 그 업데이트된 모델을 다시 각 디바이스에 보내주고요.( 이때 각 디바이스의 그래디언트를 모으고 업데이트를 수행하는 노드를 coordinating node라고 한다)
- 모델 병렬화: 큰 모델을 쪼개서 디바이스에 보내준다. 하나의 디바이스에 한 모델을 다 담기 어려운 메모리 이슈나 모델 구간마다 계산되는 과정을 병렬화하기 위함이다. 여기 multi GPU를 사용하는 방식과 비슷하고, AlexNet 논문에서 모델을 쪼개 2대의 gpu로 학습한 방식이 여기에 해당한다.
- 파이토치 distributeddataparallel 나 dataparallel가 요런 과정이라서 파이토치 공식페이지 참고하셔도 좋을 것 같고.. 당근마켓에 이 분이 올리신 글 도 살짝 봐도 좋을 것 같아요!
