PaperReview
1.Sequence to Sequence Learning with Neural Networks

Sequence to Sequence Learning with Neural Networks(NIPS 2014)
2022년 3월 6일
2.Efficient Estimation of Word Representations in Vector Space 상편

Efficient Estimation of Word Representations in Vector Space 상편
2022년 6월 1일
3.Efficient Estimation of Word Representations in Vector Space 하편

Efficient Estimation of Word Representations in Vector Space 하편
2022년 6월 1일
4.Transformer: Attention is all you need

Attention is all you need (NIPS 2017)
2022년 6월 26일
5.ResNet
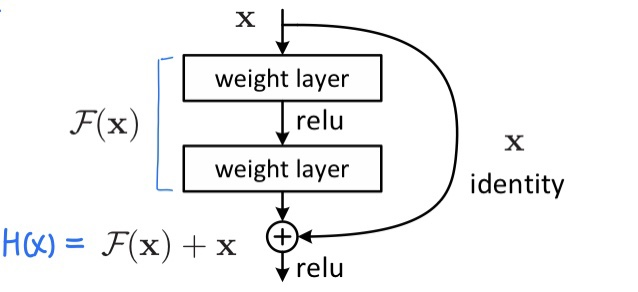
Deep Resiaual Learning for Image Recognition
2021년 9월 13일
6.BERT : Bidirectional Encoder Representations from Transformer

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2021년 6월 1일