
3. New Log-linear Models
- 이전에 성능이 좋았던 NNLM을 대용량 데이터셋 학습에 사용하기 위해 시키기 위해서는 연산량을 많이 줄인 distributed representation 모델 2가지 CBOW, Skip-gram 제안한다.
- NNLM에서의 projection layer는 단순히 embedding vector를 concat한 결과이기 때문에 단어간의 연관성 정보는 없고, hidden layer를 거치면서 단어간의 연관성을 학습한다.
- 하지만 가장 많은 연산량이 발생했던 non-linear hidden layer를 제거했기 때문에 projection layer가 단어간의 연관성 정보도 가져야 한다.
3.1 Continuous Bag-of-Words Model(CBOW)
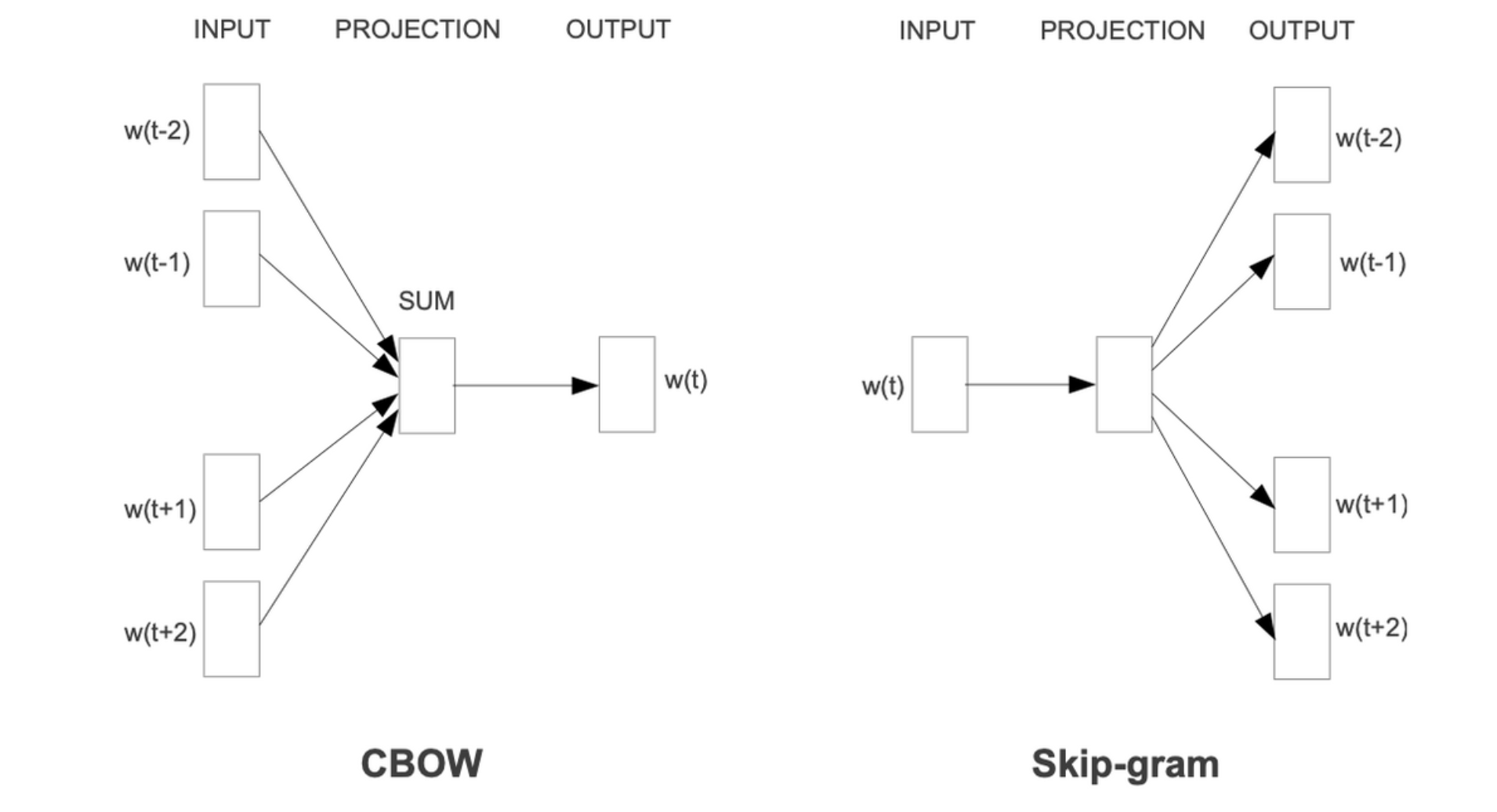
-
주변 단어로 중심 단어 예측
-
NNLM과 비슷하지만 non-linear hidden layer는 없고 projection layer만 존재하며 모든 단어들과 공유된다.
-
-
전체 단어의 one-hot vector에 가중치 행렬 W를 곱하고, 그 결과값을 모두 모아 평균을 구하면 Projection Layer를 만들 수 있다. 단어의 순서가 Projection에 영향을 주지 않는다.
3.2 Continuous Skip-gram Model(Skip-gram)
-
중심 단어로 주변 단어를 예측
-
input vector → projection vector를 거친 후에 여러 개의 가중치 행렬을 만들어 여러 개의 output vector를 만드는 것으로 이해했다.
-
-
빨간색 박스는 CBOW에서 N=1일 때의 수식과 동일
-
C: maximum distance of the words
-
주변 C개의 단어를 예측할 때 주변 단어 범위를 늘리면 word vector의 quality가 증가하고 계산 복잡도도 증가한다. (예측하는 단어 수가 늘어나기 때문) 또한, 중심 단어에서 멀리있는 단어는 의미적 유사성이 작기 때문에, 멀리 있는 단어는 가중치를 작게 부여했다.
-
C를 결정한 후에 [1, C) 범위에서 R을 랜덤하게 뽑아 이전 R개, 이후 R개 단어를 예측한다. R을 뽑을 확률은 이기 때문에 , 기대값은 C번 수행된다. C개 단어에 대해 진행하기 때문.
4. Results
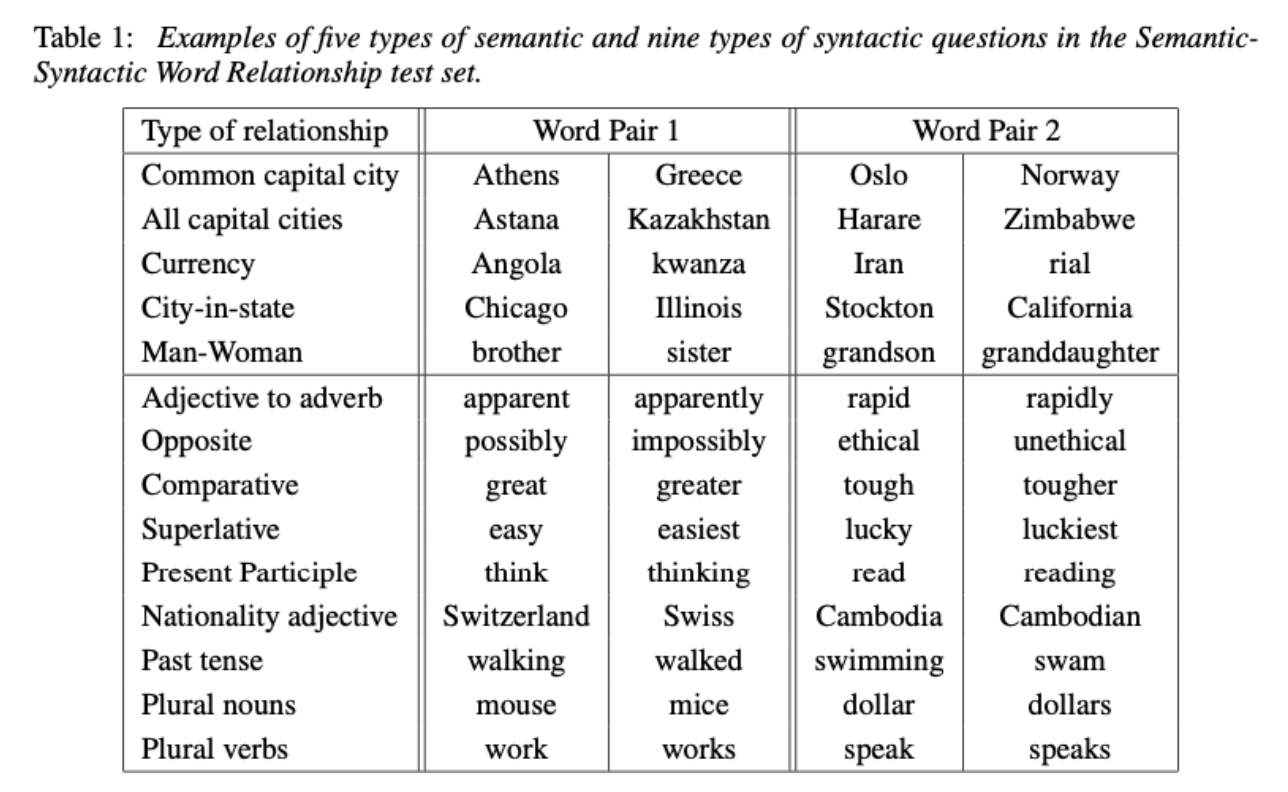
word embedding vector의 syntax, semantic 성능을 측정할 수 있는 새로운 Test set을 제시했다.
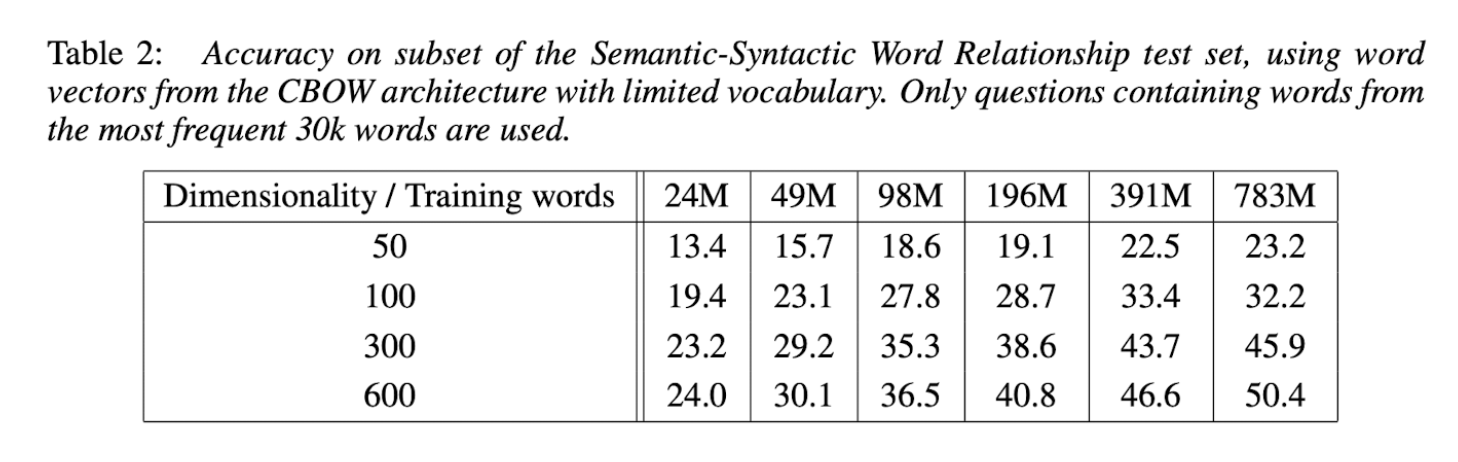
- 데이터셋과 word vector 차원을 동시에 늘렸을 때 성능이 향상되었다.
- 증가한 데이터양을 수용할만한 차원이 필요하다(하나만 늘렸을 때는 성능이 내려가는 경우도 있음)
- 논문이 나올 당시에는 데이터셋은 늘려도 벡터 차원을 늘리는 아이디어는 사용하지 않아 새로운 실험이었다.
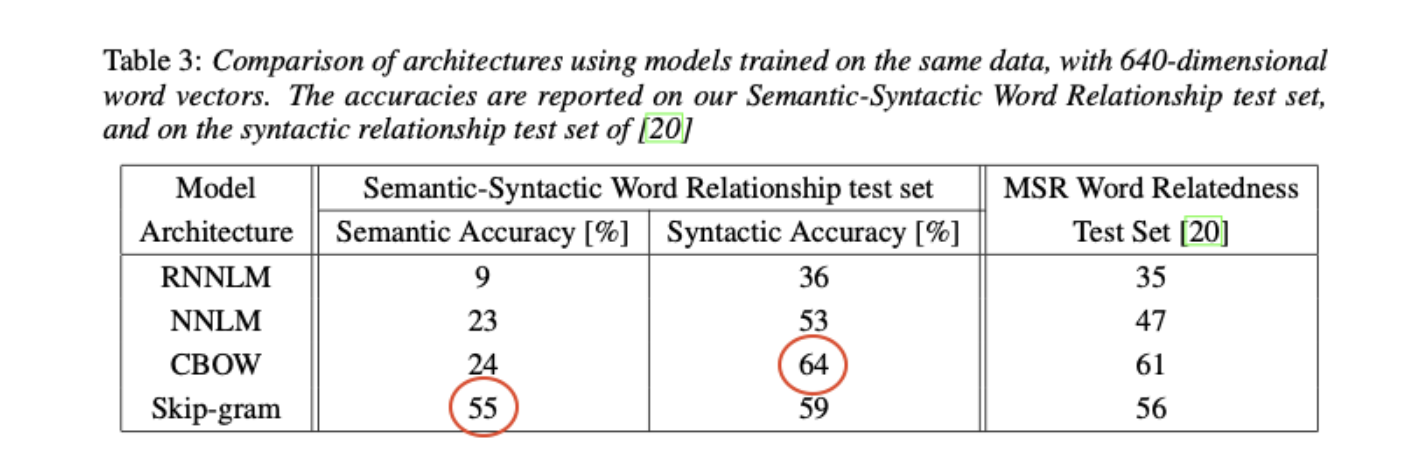
- CBOW의 syntatic accuracy가 높은 이유: 문법이 동일한 것은 한 문장에서 볼 수 없기 때문에 skip-gram이 더 성능이 낮을 것이다.
- Skip-gram의 semantic accuracy가 높은 이유: 한 단어를 중심으로 문장 안의 모든 단어를 예측해 단어들간의 연관성을 학습하지 않을까?
- NNLM보다 RNNLM의 성능이 떨어지는 이유: RNNLM의 vector들은 projection layer와 같은 중간 단계없이 non-linear hidden layer에 연결되기 때문이다.
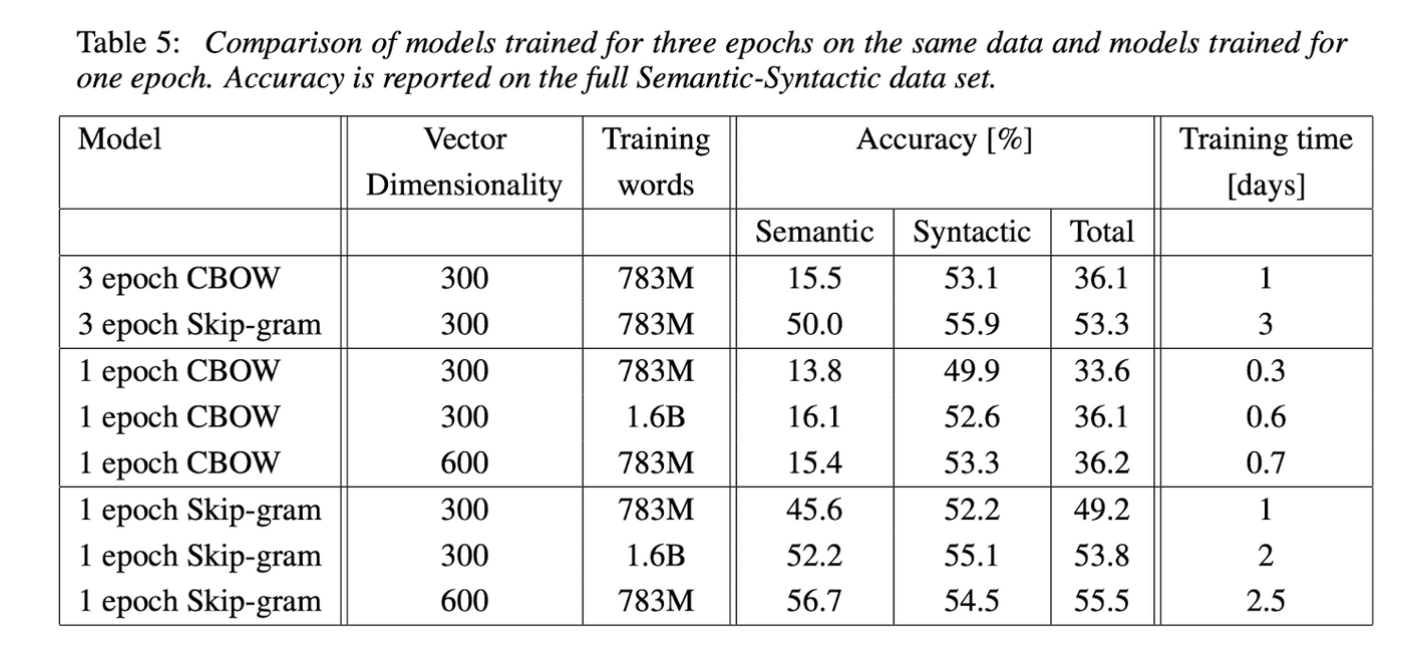
훈련 에폭수를 늘리는 것보다 데이터 크기를 늘리는 것이 성능 향상에 더 좋다.
의문점
- 허프만 코딩: 이진 트리이지만, 높은 확률로 balanced 이진트리가 아님. 자주 등장하는 단어는 비트수를 짧게, 자주 등장하지 않는 비트수는 길게 할당한다. → 허프만 이진 트리를 사용한다고 해서 log_2(v)를 보장할 수 있나? → log_2(v)를 보장하도록 앞뒤단어를 맞춰 허프만 이진 트리를 만들지 않았을까?
- one-hot vector임을 미리 알고 계산하면 lookup table처럼 계산할 수 있지만, 컴퓨터가 미리 알고있지 않는다면 일단 행렬을 다 곱하니까 계산복잡도가 D로 안 줄어들지 않나? → 학습할 때 참고하는 파라미터 기준으로 세면 이해될수도
소감
분명 word2vec 논문인데 NNLM을 공부하는데 더 많은 시간을 쏟았다. 배경 지식이 거의 없어서 많이 검색하면서 읽었지만, 다음 논문을 읽을 때 도움이 되지 않을까 생각한다.
사실 라이브러리 가져다 사용하는 경우가 많아서 임베딩 전후만 확인했었는데 이번 논문을 읽고 내가 얼마나 두루뭉술하게 알고 있었는지 확인할 수 있었다.
어떤 배경으로 제안된 알고리즘인지 알고나니 좀 더 저자의 마음으로 읽을 수 있었고 딥러닝 모델을 더 크게 만들어 성능을 향상시키는 최근 논문과 달라 새로웠다. 논문에서 모델을 학습시킬 때 cpu를 사용했는데 얼마나 오래 걸렸을지 생각만해도 아찔하다. 그 장비로 연구한 분들이 존경스러울 따름이다..!
