
BERT : Bidirectional Encoder Representations from Transformer
BERT를 한국어로 번역해보면, transformer의 encoder구조만 사용해 bidirectional(양방향) 정보를 사용하는 구조이다.
간단히
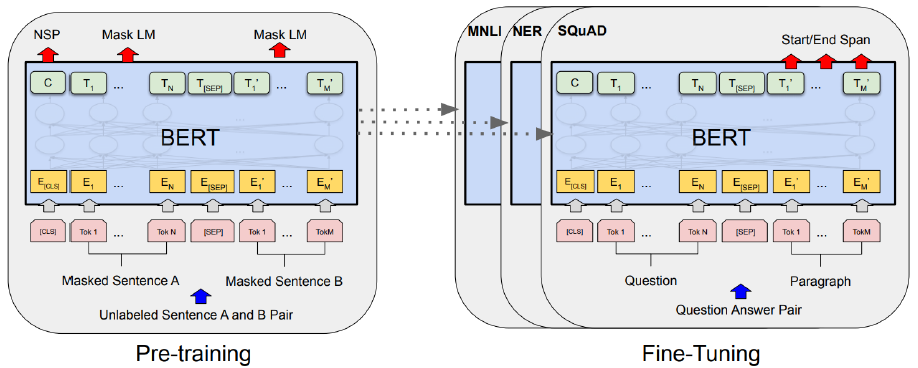
- BERT는 라벨이 없는 데이터를 사용해 pre-train을 하며, 모든 레이어에서 오른쪽으로, 왼쪽으로 양방향 문맥을 고려한다.
- BERT는 2가지 목적으로 모델을 훈련시킨다
1) Masked Language Model(MLM) : 순차적인 데이터를 예측하는 것이 아니라, 특정 위치의 단어에 mask를 씌워 mask에 어떤 단어가 들어가는지 예측
2) Next Sentence Prediction(NSP) : 문맥상 다음에 등장한 문장인지 아닌지를 학습
위의 2가지 목적을 가지고 사전훈련된 BERT에 레이어 1층만 더해 fine-tuning을 거치면 여러가지 NLP task에 사용될 수 있다.
BERT : Model Architecture

- BERT는 이름에서 알 수 있듯이 transformer 모델의 encoder구조(오른쪽 그림)를 사용한다. BERT 모델의 크기를 의미하는 L(레이어의 개수), H(히든 크기), A(attention head의 개수)는 모두 hyper-parameter이다.
- BERT_BASE 모델은 GPT와 성능을 비교하기 위해 동일한 사이즈로 만든 모델이다.
BERT : Input/Output Representations
- 다양한 down-stream task에 활용하기 위해서 BERT는 input representation을 유연하게 구성한다.
- BERT의 입력은 문장 1개 또는 문장 1쌍이다. 여기서 말하는
문장의 정의는 우리가 알고있는(언어학에서의) 정의와 다르다.

- BERT 논문에서 정의한 Sentence와 Sequence의 정의이다.
- 주어+동사로 이루어진 문장이 아니더라도, BERT에서는 연속적인 단어들의 나열을 하나의 "문장"이라고 정의했다. 단순히 단어들의 나열이기 때문에, 우리가 알고있는 문장 1개보다 짧을수도 있고 길 수도 있다.
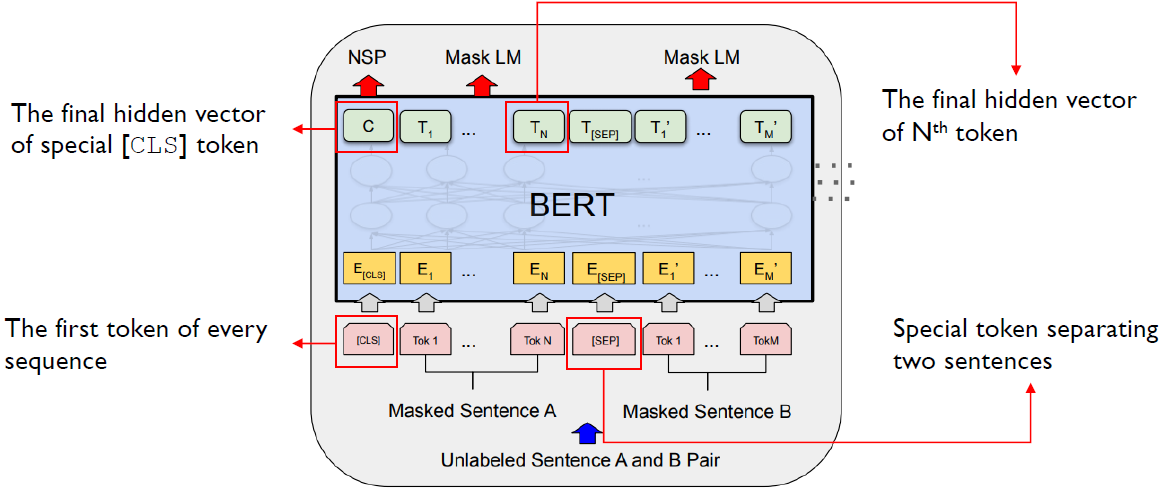
- BERT의 내부 구조는 위의 이미지와 같다.
- BERT를 사전훈련 할 때는 입력으로 unlabeled sentence가 들어가는데, unsupervised learning 방식으로 학습한다.
입력 데이터에 적혀있는 Masked Sentence A는 N개의 토큰(1~N)에서 일정 비율로 토큰을 masking해 입력으로 넣는다. Masked Sentence B도 동일하게 일정 비율로 토큰을 masking해 입력으로 넣는다. - 분홍색 박스에 있는
[CLS],[SEP]토큰은 각각 sequence의 시작, 두번째 문장을 분리하는 기준을 의미하는 토큰이다. 문장 1개만 입력으로 들어오는 경우에는[CLS]토큰만 있고,[SEP]토큰은 존재하지 않는다. - 초록색 박스는 encoder를 여러 번 거친 최종 hidden vector를 의미한다.
- BERT는 pre-train 단계에서 NSP, 첫번째 문장의 Mask LM, 두번째 문장의 Mask LM을 동시에 학습한다.
1) NSP는 문장B가 문장A 뒤에 오는 문장인지 여부(0/1 classification 문제)
2) Mask LM은 입력에서 masking한 단어가 무엇인지 예측하는 문제
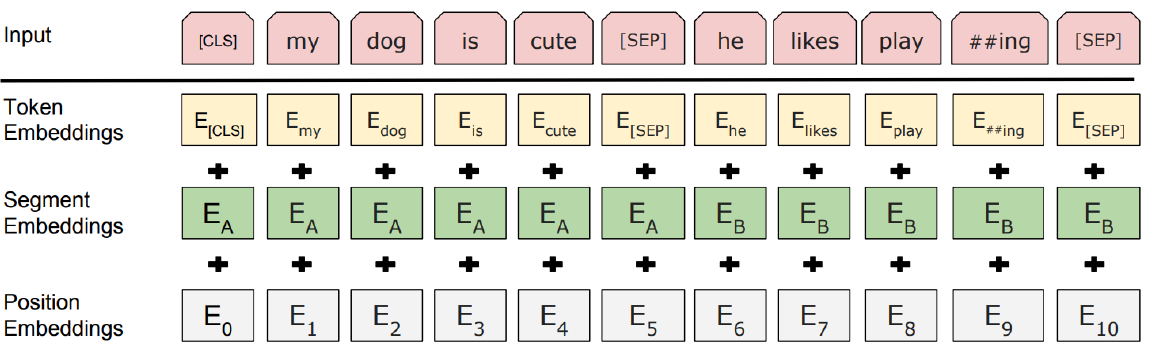
- BERT의 input representation은 3가지 임베딩 벡터의 합으로 표현된다. 3가지 임베딩인 token embedding, segment embedding, position embedding은 모두 차원이 같아 각각 구한 후 선형결합하면 된다.
1) Token embedding

WordPiece 임베딩에서 제공하는 30000개의 토큰으로 이루어진 vector값을 가져온다. Token embedding은 단어를 고정된 크기의 벡터로 변환하기 위해 필요하며, BERT에서는 각 단어(토큰)을 768차원의 벡터로 표현한다.
I like strawberries라는 문장에 token embedding을 수행하면[CLS],I,like,straw,##berries,[SEP]6개의 토큰으로 나뉘며 각각 768차원이 된다.
2) Segment embedding

- Segment embedding은 해당 토큰이 첫 번째 문장에 속하는지 두 번째 문장에 속하는지 알려준다.
[SEP]토큰을 기준으로 입력 토큰을 2개로 나눈다. E_A는 문장 A의 토큰, E_B는 문장 B의 토큰을 의미한다. 어떤 문장인지에 대한 토큰도 입력데이터에 라벨링 되어있지 않고, 학습시켜야 한다.- Segment embedding이 수행되는 과정은 다음과 같다.
[SEP]토큰을 기준으로 2개의 문장으로 구분된다. BERT_BASE 모델에서 hidden vector size를 768로 정의했기 때문에
첫번째 segment, 두번째 segment 각각 768차원이기 때문에 segment embedding에서만 1536(768x2)개의 파라미터를 학습시켜야 한다.
3) Position embedding
Transformer에서 사용된 임베딩과 동일한 방식으로 주기함수를 사용해 각 단어의 상대적인 위치 정보를 가져온다. Positional Encoding을 PyTorch로 구현한 Positional-Encoding 구현을 참고한다.
Pre-training BERT
Task 1 : Masked Language Model (MLM)
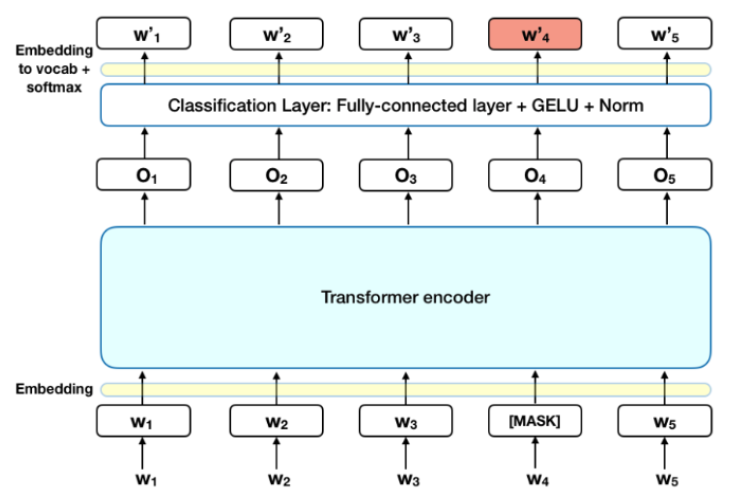
- 다시 한번 언급하자면 MLM은 masking된 단어가 무엇인지 예측하는 task이다. 위의 그림에서 예측한 토큰 W'4가 W4가 되도록 학습시킨다.
- MLM task를 학습시키기 위해 전체 입력 토큰의 15%를
[MASK]토큰으로 가렸다. - BERT에서는 ReLU 대신에 GELU 활성화 함수(activation function)을 사용했다.
- Pre-trained 모델 중 하나인 ELMo는 순방향(forward), 역방향(backward)을 따로 학습시킨 후에 해당 토큰의 representation을 선형결합하지만, BERT는 순방향, 역방향을 순차적으로 학습하지 않고 동시에 학습한다.

- 본 논문에서는
[MASK]토큰이 pre-training에서만 등장하고, fine-tuning에서는 등장하지 않기 때문에 mismatch가 발생할 수 있다고 했다.(왜쥬???) - 이 문제점에 대한 해결방법으로 본 논문은 masking해야할 단어를 모두 masking하는 대신 80% 확률로 masking, 10%의 확률로 masking할 단어를 다른 단어로 대체, 10%의 확률로 masking알 단어를 masking하지 않았다.
 > 80 : 10 : 10 의 비율은 다양한 조합으로 실험을 통해 얻은 결과이다.
> 80 : 10 : 10 의 비율은 다양한 조합으로 실험을 통해 얻은 결과이다.
Task 2 : Next Sentence Prediction (NSP)
- 자연어처리의 중요한 task인 QA(Question Answering), NLI(Natural Language Inference)는 두 문장간의 관계를 이해해야 가능하며, language modeling만으로는 어렵다.
- {문장 A, 문장 B}가 입력으로 들어왔을 때 문장 B가 문장 A 다음에 오는 문장인지 예측(binarized next sentence prediction)만을 통해 두 문장간의 관계에 대한 정보를 얻을 수 있다. 문장 A ~ 문장 B가 이어진 경우 50%, 이어지지 않은 경우 50%로 구성해 NSP를 학습시켰다.

학습 데이터(corpus) 안에 10개의 문장(S1, S2, S3, … S10)이 있을 때, S1와 S2는 이어지기 때문에 NSP 라벨이 1이 되고, S5와 S1은 이어지지 않기 때문에 NSP 라벨이 0이 된다.

- 미국 시트콤 friends의 대사로 NSP 라벨을 만들면 다음과 같다.
(friends에 푹 빠져서 요즘 지하철에서 매일 프렌즈 보고 있는데 여기서 만나다니 너무 반갑다 ㅎㅎ 아직 프렌즈 정주행을 완료하지는 않았지만 위의 사진은 프렌즈 마지막화!! 극중에서 피비는 엉뚱하면서도 예언?을 하는 역할인데, 웃긴 얘기지만 피비가 할만할 말을 예측하는 것도 재밌을 것 같다.)
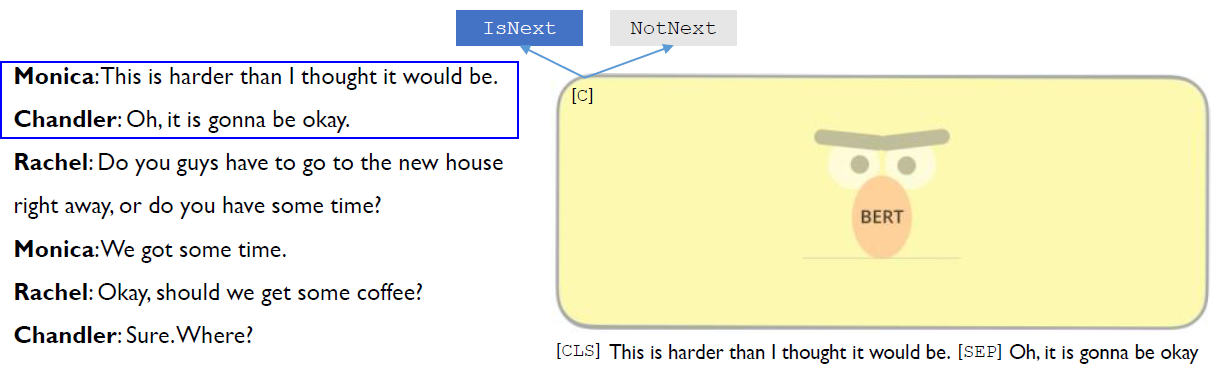
첫 번째 Monica와 Chandler의 대화는 연속되기 때문에 "IsNext"
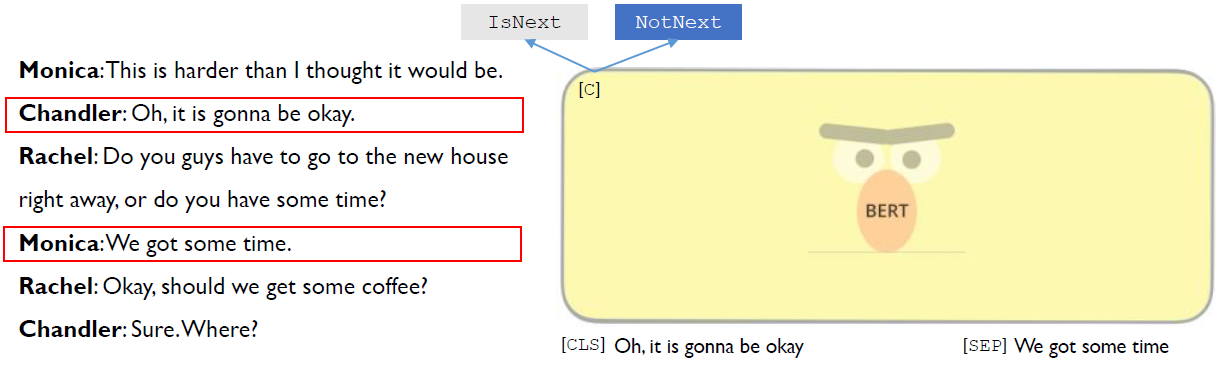
바로 다음 문장이 아닌 빨간색 박스의 Chandler와 Monica대화는 "NotNext"
BERT vs. GPT vs. ELMo
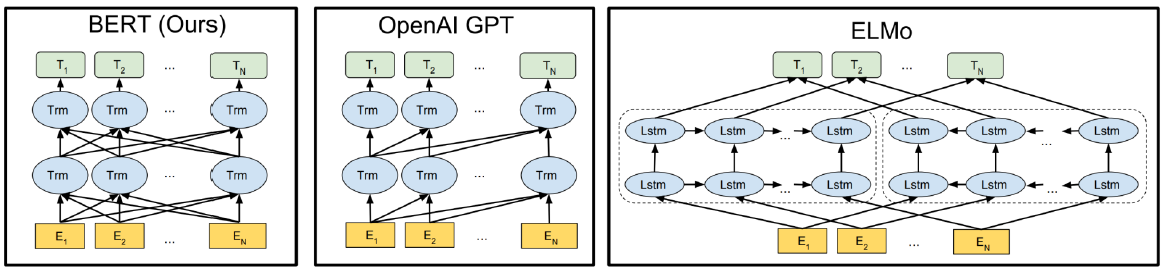
- BERT : transformer의 encoder를 사용해 동일한 sequence에 대하여 양쪽방향으로 동시에 학습
- GPT : transformer의 decoder를 사용해 forward 방향으로 만 학습
- ELMo : 동일한 sequence에 대하여 forward LSTM, backward LSTM을 여러 단계 학습시킨 후 각각 해당하는 hidden state를 선형결합
Dataset
- BookCorpus (https://github.com/soskek/bookcorpus)
-BERT를 pre-train할 때 사용한 데이터인 800M 단어로 구성된 BooksCorpus은 다음 사이트에서 구할 수 있다. - WikiExtractor (https://github.com/attardi/wikiextractor)
-2500M 단어로 구성된 영어 위키피디아 데이터셋도 다음 사이트에서 구할 수 있다.
Pre-training BERT

- BERT를 학습시킬 때 hyper-parameter가 많은데, 위와 같다.
- 첫 번째 maximum token length=512는 BERT에 들어오는 입력 데이터 두 문장을 합쳐서 최대 512개 token까지만 가능하다는 의미이다.
- Learning rate는 10000 step 이후에는 선형적으로 감소하도록 설정했다.
- 맨 아래 2줄은 학습시킬 때의 tip으로, 본 논문에서는 step의 90%는 총 512개의 토큰 중 일부인 128개만 사용해 학습하고, step의 10%에만 512개 토큰 전부를 사용해 학습시켰다.
Fine-tuning BERT
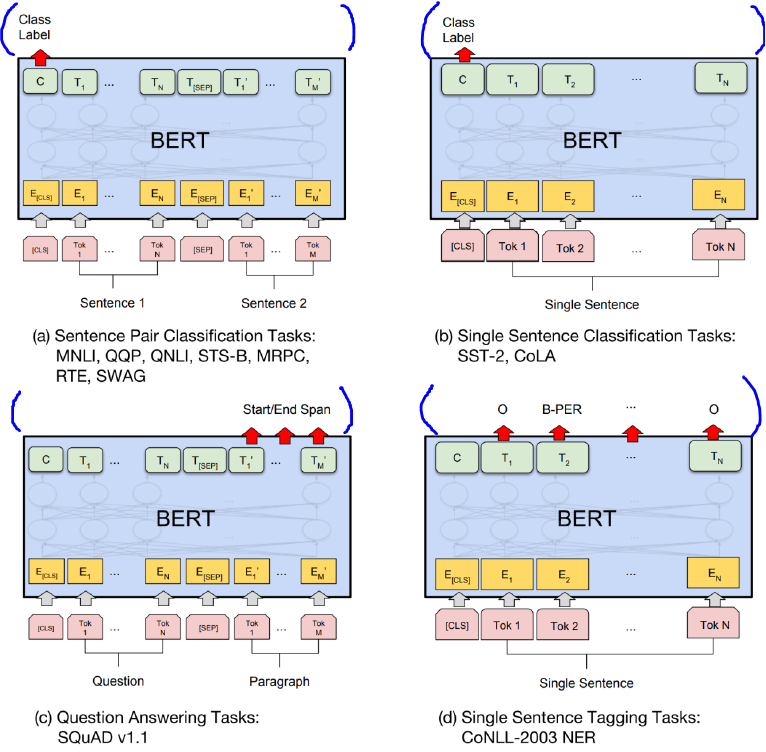
- Pre-training은 corpus 데이터를 사용해 unsupervised 방식으로 MLM, NSP 2가지를 동시에 학습시킨다.
- Pre-trained BERT 모델에 파란색으로 표시한 레이어 1개만 추가하면 다양한 task에 활용 가능한 모델을 만들 수 있다.
- (a) : sequence 2개를 입력으로 받아 특정한 NLP 클래스에 속하는지/안 속하는지를 출력함 (NLI)
- (b) : sequence 1개만 입력으로 받아 레이블을 생성함 (감성 분석)
- (c) : sequence 2개를 입력으로 받아 2번째 sequence에서 정답을 출력함 (QA-질의응답)
- (d) : sequence 1개만 입력으로 받아 토큰마다 정답을 출력함. (형태소 분석, 개체명 인식)
Experiments
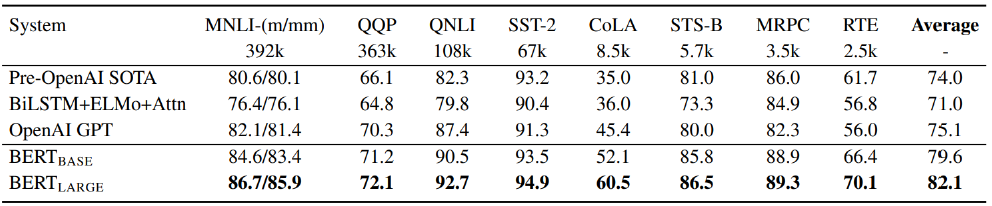
현재 기준으로는 BERT가 leaderboard 상위권에 오를만한 성능이 좋은 모델은 아니지만, 본 논문에 나왔던 시기에는 BERT 모델만으로 SOTA 모델의 성능을 능가했다.
• Ablation Study 1 : Effect of pre-training tasks

BERT_BASE 모델은 LM, NSP 2개를 학습시킨 모델이고, No NSP 모델은 LM만 학습시킨 모델이다.
두 모델은 다른 데이터셋의 경우에는 성능 차이가 거의 없지만, 2개 이상의 문장을 이해해야하는 task의 경우에는 NSP를 pre-training하는게 효과가 있음을 확인할 수 있다.
• Ablation Study 2 : Effect of model size

레이어 개수가 6인 모델이 BERT_BASE, 레이어 개수가 24인 모델이 BERT_LARGE이다.
구조가 커질수록 성능이 좋아지는 모습을 보이며, 어찌 보면 당연한 결과이다. (구조가 너무 깊어 역전파가 제대로 이루어지지 않아 성능이 떨어지는 것을 제외하면)
• Ablation Study 3 : Feature-based approach with BERT

Fine-tuning을 하지 않고 pre-trained된 모델한 사용해 hidden state vector를 결합해 사용했을 때의 성능이 어떻게 될지에 관한 실험이다.
Fine-tuning을 한 경우와 안 한 경우를 비교했을 때 성능이 5% 이상 하락했다.
BERT_BASE의 경우 encoder를 12개 거치는데 첫번째 hidden state vector인 embeddings을 사용했을 때는 성능이 91, 모든 encoder를 거친 결과인 last hidden은 성능이 94.9이다.
레이어마다 출력된 hidden vector를 모두 합쳐서 사용했을 때의 성능은 95 정도로 fine-tuning을 한 경우와 크게 차이가 나지 않았다.
👉 Fine-tuning을 하지 않으면 성능이 하락하지만, hidden state vector 레벨에서 모든 레이어의 값을 합쳐서 사용하면 성능이 크게 하락하지 않았다.
Referenes
BERT paper
Korea University Text Analytics
BERT 톺아보기
How the Embedding Layers in BERT Were Implemented
