[논문 리뷰] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Multi-Modal 논문 리뷰

2022년 1월에 공개한 논문이다.
[ Abstract ]
Vision-Language Pre-training (VLP) 방법론에 관한 내용을 다룬다. 기존 모델들은 Understanding-based Task나 Generation-based Task 중 하나에만 뛰어난 경우가 많다. 그리고 성능 향상도 주로 웹에서 수집한 노이즈가 많은 이미지-텍스트 데이터를 대규모로 활용해 얻은 것이다. 본 논문에서는 BLIP라는 새로운 VLP 프레임워크를 제안하며, 이해와 생성 작업 모두에 유연하게 적용될 수 있다. BLIP는 웹 데이터를 더 효과적으로 사용하기 위해 캡셔너를 이용해 합성 캡션을 생성하고, 필터로 노이즈가 많은 캡션을 제거한다. 이를 통해 이미지-텍스트 검색, 이미지 캡션 생성, VQA 같은 다양한 비전-언어 작업에서 최첨단 성능을 달성한다.
[ Introduction ]
기존 방법에는 두 가지 한계가 있다.
-
1) 모델 관점에서 Encoder 기반 모델은 Text Generation Task(ex. image caption generation)에는 적합하지 않고, Encoder-Decoder 모델은 Text 생성에만 집중하다보니 Image-Text 상호 Modality간의 Understanding이 필요한 Task의 성능이 그리 좋지 않았다.
-
2) 데이터 관점에서 많은 최신 방법들이 웹에서 수집한 이미지-텍스트 쌍을 사용해 사전 학습을 진행하지만, 노이즈가 많은 웹 데이터는 비전-언어 학습에 최적의 데이터가 아니다.
이 문제를 해결하기 위해 본 논문에서는 BLIP(Bootstrapping Language-Image Pre-training)라는 새로운 VLP 프레임워크를 제안한다. BLIP는 이해와 생성 작업 모두에 유연하게 적용될 수 있으며, 모델과 데이터 측면에서 두 가지 기여를 한다.
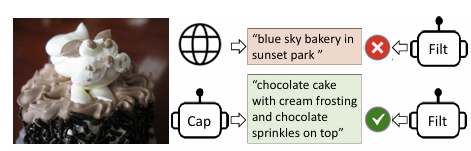
-
1) 멀티모달 인코더-디코더(MED)라는 새로운 모델 구조를 도입해, 다양한 작업에 효과적으로 적용할 수 있게 했다. 즉, 위에서 제기된 서로 다른 Modality 간의 상호작용을 고려하기 어려웠던 문제점을 다양한 모드에서 동작할 수 있는 MED 블록으로 학습시키면서 해결하였다.
-
2) 캡션 생성 및 필터링(CapFilt) 방법을 통해 노이즈가 많은 이미지-텍스트 쌍에서 학습할 수 있도록 했다. 위 그림의 예시처럼, 케이크 사진에 잘못된 Caption을 Filter를 통해 제거하였다.
이 프레임워크는 이미지-텍스트 검색, 이미지 캡션 생성, VQA(Visual Question Answering) 등 다양한 작업에서 최첨단 성능을 기록했으며, 제로샷 방식으로 비디오-언어 작업에서도 우수한 성과를 보여준다.
Method Model Architecture & Pre-training Objectives
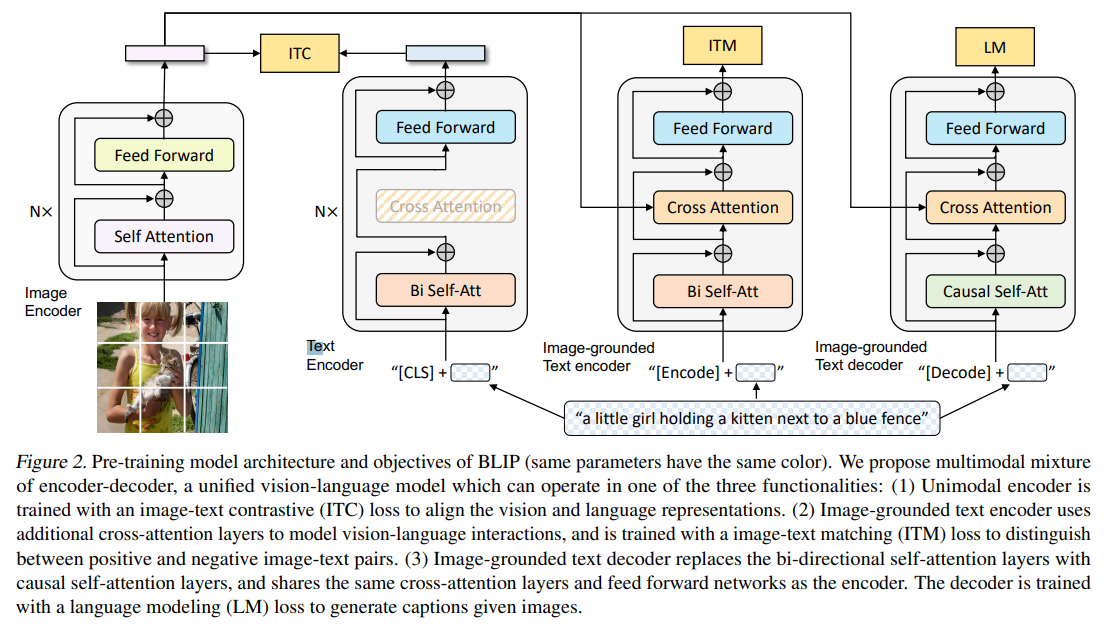
-
전반적인 학습 과정은 그림 왼쪽의 이미지 인코더가 이미지를 입력으로 받고, 텍스트 인코더가 텍스트를 처리한다. 그런 다음, 3가지 pre-Training Objective(Image-Text Contrastive Loss, Image-Text Matching Loss, Language Modeling Loss)를 통해서 Jointly Training된다.즉, BLIP의 architecture는 아래 세 가지 task를 수행하여 pretrain된다. Image-Text Contrastive(ITC) Learning, Image-Text Matching (ITM), Image-conditioned Language Model (LM)이다. 따라서 모델의 전체 loss function의 경우 세 가지 task의 loss를 모두 더한 것을 사용하게 된다. 이러한 MED 구조를 통해서 여러 Downstream Task에 Flexible하게 대응할 수 있게 된다.
-
- ITC (Image-Text Contrastive)
단일 모드 인코더(Unimodal Encoder)는 이미지와 텍스트 각각에 대한 인코더가 있고, 이 인코더는 같은 {image, text} pair에 있는 positive pair의 경우에는 cosine similarity가 높아지고 다른 {image, text} pair에 있는 negative pair의 경우에는 cosine similarity가 낮아지도록 학습되는 Contrastive Learning으로 학습된다. 이 과정에서는 이미지와 텍스트의 표현을 맞추는 작업이 이루어져, 서로 대응하는 이미지-텍스트 쌍을 식별할 수 있게 한다.
- ITC (Image-Text Contrastive)
-
- ITM (Image-Text Matching)
ITM 모델의 인코더(=Image-Grounded Text Encoder)에 Text를 넣어서 얻은 임베딩을 Image Encoder의 임베딩과 Cross Attention을 시킨 후, 해당 Text와 Image가 잘 Matching이 됐는지 예측하도록 학습시키는 Loss를 의미한다. 즉, 특정 이미지에 대해 올바른 텍스트 설명을 찾는 과정에서 활용된다.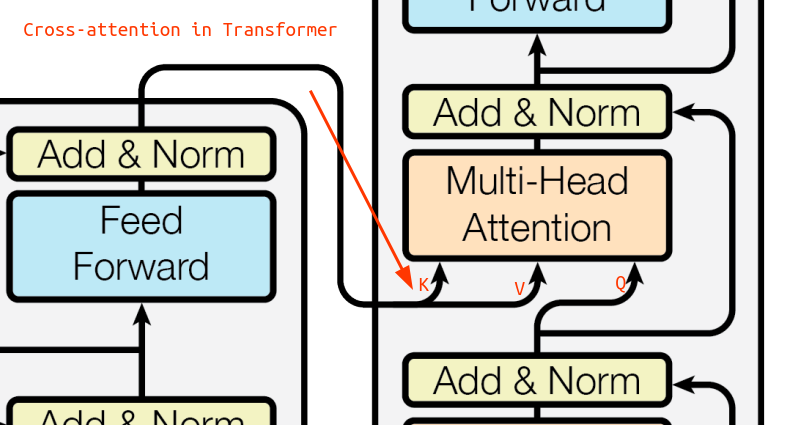 Cross-attention이란, 트렌스포머 구조에서 두 개의 다른 임베딩 시퀀스를 섞는 것을 말한다.
Cross-attention이란, 트렌스포머 구조에서 두 개의 다른 임베딩 시퀀스를 섞는 것을 말한다.
- ITM (Image-Text Matching)
-
- LM (Language Modeling)
이미지 기반 텍스트 디코더(Image-grounded Text Decoder)는 Causal Self-Attention 레이어를 사용해 텍스트를 생성한다. 이 디코더는 이미지와 관련된 텍스트를 생성할 수 있도록 LM Loss를 통해 학습된다. 주어진 이미지를 바탕으로 설명을 생성하는 작업에 사용된다.
- LM (Language Modeling)
(3) CapFilt (Captioner & Filter)
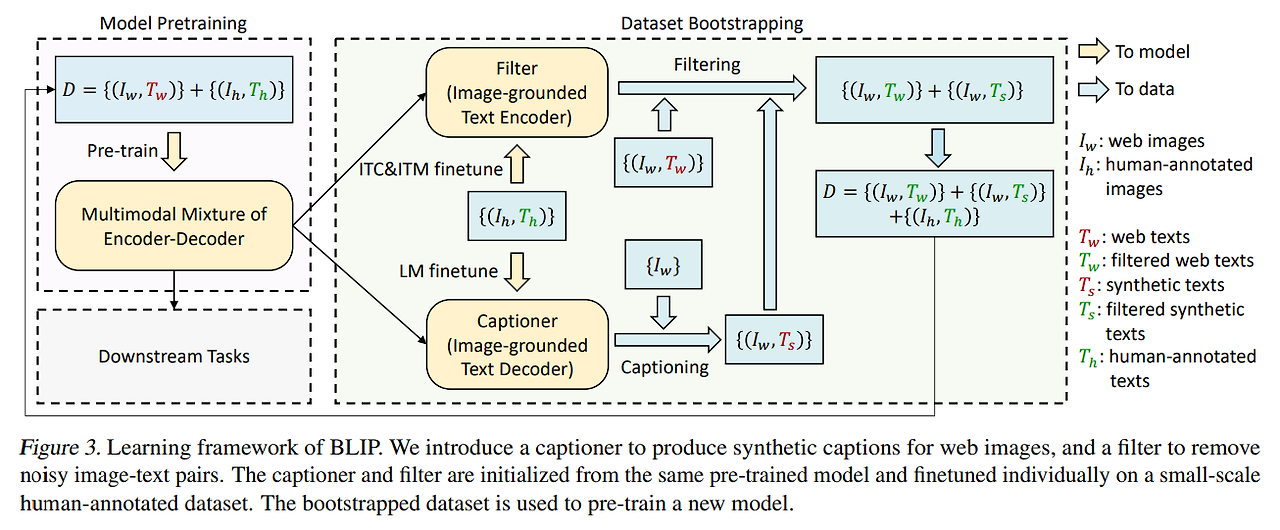
-
Captioner (Image-grounded Text Encoder)
인간이 라벨링한 {Image, Text} 데이터셋으로 LM Loss를 통해 학습된 Captioner는 web에서 수집한 image에 대한 텍스트(캡션)를 생성한다. -
Filter (Image-grounded Text Decoder)

인간이 레이블링한 {Image, Text} Pair 데이터셋으로 ITC와 ITM loss를 통해 학습된 Filter는 web에서 수집한 {Image, Text} Pair들과 Captioner가 생성한 {Image, Text} Pair들을 걸러주는 데에 사용된다. 이 때, {Image, Text} Pair가 서로 맞지 않게 짝지어진 경우를 제거하는 방식으로 Noise를 가질 수 있는 데이터들을 정제하는 역할을 한다.
위 사진은, BLIP 모델의 텍스트 필터링 과정을 설명하는 예시이다. 이미지와 함께 웹에서 수집한 텍스트(텍스트 웹, Tw)와 모델이 생성한 텍스트(텍스트 생성, 𝑇s)가 주어졌고, 모델이 각 텍스트 쌍을 필터링하는 과정을 보여준다.
녹색 텍스트: 이 텍스트들은 필터에 의해 수용된 문장들이다. 이들은 이미지의 내용과 더 잘 일치하는 문장으로, 예를 들어 첫 번째 이미지에서 "a flock of birds flying over a lake at sunset"라는 설명이 적절하게 수용되었다.
빨간색 텍스트: 이 텍스트들은 필터에 의해 거부된 문장들이다. 예를 들어 첫 번째 이미지에서 "from bridge near my house"라는 텍스트는 그 이미지에 명확히 맞지 않아 거부되었다.
따라서 이 이미지의 목적은 웹에서 수집된 텍스트가 모두 정확하지 않기 때문에 필터를 통해 적절한 텍스트를 선택하는 방법을 보여준다.
[ Experiments and Discussions ]

모델의 파라미터 수를 줄이기 위해 layer들의 파라미터를 공유하는 방법을 사용했다. Self-Attention Layer를 제외한 Layer들의 파라미터를 공유하니 성능도 향상하였다. Self-Attention Layer의 경우 Encoder와 Decoder의 작업 자체가 다르기 때문에 충돌이 일어날까봐 공유하지 않았다고 논문에서 언급한다.
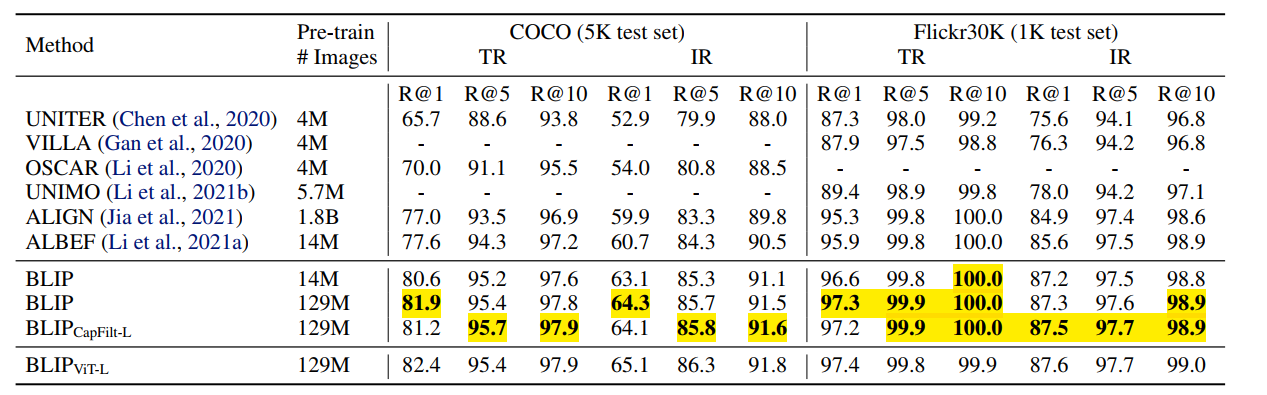
Image-text retrieval 부분에서 SOTA를 달성했다.
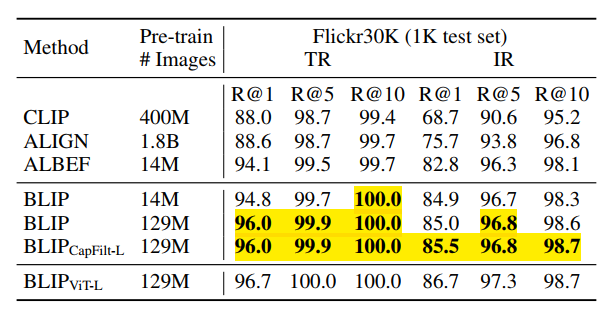
Zero-shot 성능 역시도 기존 방법론들보다 성능이 향상되었음을 알 수 있다.
[ Conclusion ]
BLIP은 다양한 VLP에서 우수한 성능을 발휘하는 새로운 VLP 프레임워크로, Understanding-Based And Generation-Based Tasks 모두에서 우수한 성능을 보여준다. BLIP은 대규모의 노이즈가 포함된 Image-Text 쌍에서 다양한 합성 캡션을 추가하고, 노이즈가 많은 캡션을 제거하는 방식으로 부트스트래핑된 데이터(대규모의 노이즈가 포함된 이미지-텍스트 쌍에서 필요한 정보를 추출하고, 합성 캡션을 추가하여 더 깨끗하고 유용한 데이터를 만드는 과정)를 사용하여 멀티모달 인코더-디코더 모델을 사전 학습한다.
[참고 문헌]
https://arxiv.org/pdf/2201.12086
https://daebaq27.tistory.com/123
