
2023년 7월에 컬럼비아 및 여러 대학교에서 연구한 VLP에 관한 논문이다.
이 논문을 읽게 된 계기는 기존 논문들(CLIP, BLIP, Align 등)은 학습 시 데이터셋의 형식이 단순한 Image-Text pair로 이루어져 있었다는 점이다. 반면 LLaVA는 이미지를 포함한 지시문 데이터 형식인 Visual Instruction-Follwing Data를 새롭게 제안한다. 또한, 학습된 LLM인 Vicuna 모델로 파라미터를 초기화하고 이를 CLIP Vision Encoder와 연결하는데, 그 덕분에 기존 LLM 모델의 언어 능력을 충분히 반영하면서 이미지 정보를 잘 이해하고 대화를 이어가는 모델이 만들어졌다. 이러한 이미지 기반 챗봇 형식의 대화가 가능한 멀티모달 모델 LLaVA가 탄생하였다.
[ Abstract ]
본 논문에서는 Language만을 Input으로 받는 GPT-4를 사용하여 멀티모달 언어-이미지 Instruction-Following 데이터를 생성하고, 이를 이용하여 LLaVA라는 대규모 멀티모달 모델을 만들었다. LLaVA는 시각 인코더와 LLM을 연결하여 시각 및 언어 이해가 가능한 모델이며, GPT-4와 유사하게 이미지-언어 이해 능력에서 85.1%를 달성하였다.
- Instruction Tuning이란, 모델이 다양한 Instruction을 이해하고 따를 수 있도록 데이터를 조정하는 과정이다.
[ Instruction ]
기존의 Vision 모델들은 개별 작업을 독립적으로 수행하고 NLP는 이미지 설명에만 쓰이는데, 이는 상호작용의 제한을 초래한다. 반면 대형 언어 모델(LLM)은 다양한 지침을 명시적으로 표현해 여러 작업을 수행할 수 있는 가능성을 보여준다. 본 논문에서는 비전-언어 멀티모달 Instruction Tuning을 처음으로 시도하며, 데이터 생성, 대규모 멀티모달 모델 개발, 벤치마크 제공 등을 통해 이러한 목표를 달성하고자 한다.
-
멀티모달 Instruction 데이터: 이미지-텍스트 쌍을 Instruction-Following 형식으로 변환하는 데이터 생성 방법 제안.
-
대규모 멀티모달 모델: CLIP의 비전 인코더와 Vicuna의 언어 디코더를 연결하여 새로운 멀티모달 모델 개발.
-
멀티모달 Instruction 벤치마크: LLaVA-Bench라는 새로운 벤치마크와 함께 다양한 이미지, 지침 및 주석 제공.
-
오픈 소스: 생성한 데이터, 코드베이스, 모델 체크포인트 및 비주얼 챗 데모를 공개함.
[ GPT-assisted Visual Instruction Data Generation ]
최근에 공개된 다양한 이미지-텍스트 쌍이 있지만, 이러한 Instruction 데이터를 만드는 과정은 매우 비싼 Cost가 필요하다는 한계가 있다. 그래서 본 논문은 GPT-4와 같은 언어 모델을 활용해 이미지에 대한 질문을 생성하고, 이를 통해 Instruction 데이터를 확장하는 방법을 제안한다. 이때, 특정 Prompt를 ChatGpt-4의 Input으로 사용한다. 이때 주의해야 할 것은 이미지는 Input으로 사용하지 않고, 이미지와 관련된 캡션 및 Bounding Box 값들만 이용해 질문 및 대화셋을 만든다.
- Instruction-tuning:

예를 들면, 위와 같이 이미지, 캡션, Box 정보들이 있을 때, 이를 아래 Prompt의 Content에 넣어준다. 이때 GPT에는 Bounding Box값을 넣는 이유는 이 당시 GPT는 VQA가 안 되는 GPT이기 때문이다. 그래서 ChatGPT 같은 언어 모델은 텍스트 입력만을 이해할 수 있기 때문에 이미지 정보를 직접적으로 처리할 수 없다. 그렇기 때문에 이미지를 설명하기 위해 텍스트로 인코딩된 형태로 바꿔줘야 한다. 이 과정에서 바운딩 박스 정보가 중요한 역할을 한다. 즉, 바운딩 박스와 캡션을 사용하여 이미지를 언어적 특징으로 표현하는 것이다. 캡션은 이미지의 전체적인 내용을 설명해 주고, 이미지를 전반적으로 이해하는 데 도움을 준다.
=> 바운딩 박스의 좌표와 해당 객체의 이름을 텍스트로 표현함으로써, GPT-4가 이미지 내 특정 객체의 위치와 해당 객체의 속성을 인지할 수 있게 되는 것이다.

그 후, GPT를 이용해 질문하고 답하는 대화 형식(Type1)의 데이터를 생성한다. 이와 유사하지만 다른 Prompt를 사용해 더 자세한 설명(Type2), 복잡한 추론(Type3) 데이터를 생성한다.

이때, Content로 주는 두 가지 타입의 Symbolic Representation인 캡션과 Bounding Box는 다음과 같은 역할을 한다.
- 1) Symbolic Representation인 캡션은 일반적으로 다양한 관점에서 이미지의 시각적 장면을 설명한다.
- 2) Bounding Box는 보통 장면 내 객체를 Localize하고, 각 객체의 개념과 Spatial Location(공간상 위치)의 정보를 인코딩 한다.
=> 즉, 이러한 Symbolic Representation을 통해 이미지를 LLM이 인식 가능한 시퀀스로 인코딩 할 수 있게 된다.
그래서 본 연구의 저자들은 COCO 데이터셋을 총 3가지 타입의 Instruction-Following Data를 만들었다. 각 타입에 대해 먼저 몇 가지 예시를 사람이 직접 설계한 후 이 예제를 GPT-4의 In-Contexte Learning에 사용하였다.
-
1) Conversation: 질문하는 대화이다. 답변은 AI가 이미지를 보고 있는 것처럼 작성된다. 다양한 질문이 이미지의 시각적 내용에 대해 제기되며, 여기에는 물체의 종류, 개수 세기, 물체의 행동, 위치, 물체 간의 상대적 위치가 포함된다. 명확한 답변이 가능한 질문만 고려된다.
-
2) Detailed Description: 이미지에 대한 풍부하고 포괄적인 설명을 포함하기 위해, 그런 의도를 가진 질문 리스트를 생성한다. GPT-4에 요청한 후, 리스트를 선별한다. 각 이미지에 대해 리스트에서 무작위로 하나의 질문을 샘플링하여 GPT-4에 요청해 상세 설명을 생성한다.
-
3) Complex Reasoning: 위의 두 유형은 시각적 내용에 초점을 맞추고, 이를 바탕으로 심층 추론 질문을 생성합니다. 답변은 일반적으로 단계별 추론 과정을 요구한다.
- In-Context Learning이란, 모델이 특정 작업을 수행할 때, 제공된 예시를 기반으로 즉각적으로 학습하는 방법이다.
[ Visual Instruction Tuning ]
(1) Architecture
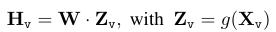
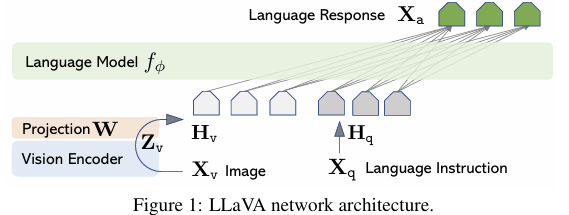
위 그림에서 보이는 LLM에 해당하는 f는 LLaMA를 기반으로 Finetuning한 Vicuna를 사용한다. 그리고 이미지를 입력으로 받는 Vision Encoder는 CLIP의 VIT를 사용한다. 이때 기존 마지막 Layer를 제거하고, 이미지 Feature를 Word Embeddingd 공간에 연결하기 위한 Projection W(Linear Layer)를 추가하여 Linear Layer의 Output Dim이 LM의 Word Embedding 공간과 같게 설정하였다.
이때, Hv는 Sequenece of Visual Token이다.
(2) Training
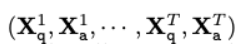
각 이미지에 대해 위와 같은 Multi-Turn Conversation Data를 생성하였다. 이때 T는 전체 Turn의 횟수이다.
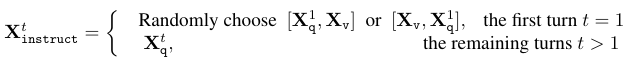
첫 번째 Turn의 경우 이미지 Feauture를 질문 앞에 둘 것인지 뒤에 둘 것인지 랜덤하게 결정한다. 이를 통해 다양한 맥락에서 모델이 질문과 이미지를 결합하는 방식을 학습할 수 있도록 돕는다.
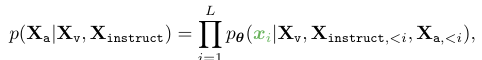
그리고 기존 LLM들과 동일하게 Auto-Regressive Training 목적함수를 사용한다. 즉, 다음에 나올 단어 알아맞추기를 이용해 학습한다. 이때 다른 점은 이미지 Feature를 함께 사용한다는 차이다.

다음 단어는 Assistant 뒤에 있는 Xa들이고 이것들에 대해서만 맞추는 연습을 한다.
-
Stage 1: Pre-training for Feature Alignment: 이미지-텍스트 쌍을 필터링하고, 이를 기반으로 Instruction-Following 데이터를 생성한다. 각 샘플은 단일 턴 대화로 처리되며, 이미지를 위한 질문이 무작위로 샘플링된다. Train 중에는 Visual 인코더와 LLM의 가중치를 고정하고, Projection Matrix 𝑊만 조정하여 이미지 특징을 LLM 단어 임베딩을 정렬한다. 즉, 이 단계에서는 Frozen LLM에 호환되는 Visual Tokenizer를 학습하는 과정이다.
-
Stage 2: Fine-tuning End-to-End: Visual 인코더 가중치를 고정한 채로 Projection 레이어와 LLM의 Pretrained된 가중치를 계속 업데이트한다. 이때, 두 가지 사용 사례를 고려한다. (1) 멀티모달 챗봇: 158K Instruction-Following 데이터를 통해 Train한다. (2) 과학 QA: 자연어 또는 이미지 형태의 맥락을 제공하며, 질문에 대한 답변을 추론과 정답 데이터를 준다.
[ Experiments ]
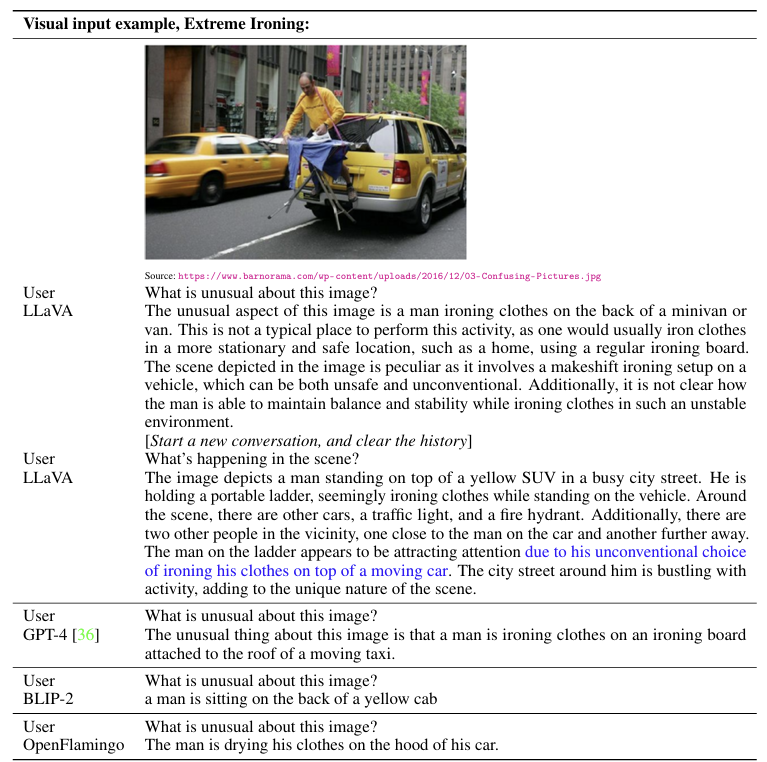
멀티모달 챗봇으로 학습시켰을 때 나오는 결과이다.
-
LLaVA의 응답: 사용자가 이미지에서 이상한 점을 물었을 때, LLaVA는 남자가 미니밴의 뒤에서 옷을 다림질하는 것이 일반적이지 않다고 설명한다. 이 행동이 불안정한 환경에서 균형을 유지하며 이루어진다는 점도 언급한다.
-
LLaVA의 장면 설명: 두 번째 질문에 대해, LLaVA는 남자가 사다리를 사용하고 있으며 주변에 다른 차량과 사람들도 있다는 점을 추가적으로 설명한다.
-
GPT-4와 BLIP-2의 응답: GPT-4는 비슷한 질문에 대해 남자가 이동하는 차량 위에서 다림질하고 있다는 점을 간단히 언급한다. BLIP-2는 남자가 택시의 뒷좌석에 앉아 있다는 설명을 제공한다.


LLaVA가 더 자세한 설명이나 대화, 추론 모든 부문에서 높은 점수를 기록하고 있다.
[ Conclusion ]
LLaVA라는 멀티모달 모델을 Train하여 인간의 의도를 따르고 Visual Task를 수행한다고 한다. 또한, ScienceQA에서 새로운 최고 정확도를 달성했으며, 멀티모달 챗 데이터에 대해 뛰어난 Visual Chat 능력을 보여주었다고 설명한다.
