7편: 메트릭 설계, Grafana 대시보드 구성, 그리고 첫 번째 테스트 결과
알고리즘을 구현했으면 이제 제대로 측정해야 한다.
코드를 짜고 나서 "잘 동작하겠지"로 끝내면 의미가 없다. 로드밸런서에서 진짜 중요한 건 어떤 알고리즘이 어떤 상황에서 얼마나 잘 분산하는가를 수치로 보는 것이다.
이번 편에서는 Prometheus + Grafana 모니터링 스택을 올리고, K6로 첫 번째 부하 테스트를 돌린 결과를 분석한다.
1. 무엇을 측정할 것인가
메트릭을 설계하기 전에 먼저 질문을 정리했다.
- 요청이 잘 분산되고 있는가?
- 응답이 빠른가?
- 에러 없이 처리되는가?
- 서버들이 건강한가?
이 4가지 질문에 답하는 메트릭을 설계했다.
loadbalancer_requests_total (Counter)
알고리즘별, 서버별 총 요청 수다.
Counter를 선택한 이유는 요청은 계속 누적되기 때문이다. 그리고 Counter는 rate() 함수로 초당 요청 수(RPS)를 계산할 수 있다.
rate(loadbalancer_requests_total[1m])loadbalancer_response_time_seconds (Histogram)
응답 시간 분포다. 평균뿐만 아니라 p95, p99를 볼 수 있다.
Histogram을 선택한 이유가 있다. 평균만 보면 실제 사용자 경험을 모른다. 평균 응답시간이 100ms여도 가끔 10초가 나온다면 그 서비스는 문제가 있는 것이다. 분포를 봐야 한다.
알고리즘별로 기대하는 결과가 다르다:
- Least Response Time → 평균 응답시간이 가장 낮아야 함
- Round Robin → 느린 서버 때문에 p99가 높을 수 있음
loadbalancer_active_connections (Gauge)
서버별 현재 활성 연결 수다.
연결 수는 오르락내리락하는 값이므로 Gauge를 쓴다. 현재 상태가 중요한 메트릭이다.
이 메트릭으로 알고리즘이 제대로 동작하는지 검증할 수 있다:
- Least Connections → 연결 수가 서버 간 균등하게 유지되어야 함
- Round Robin → 느린 서버에 연결이 쌓이는 모습이 보임
loadbalancer_errors_total (Counter)
서버별 에러 수. 에러 타입(timeout, connection refused 등)도 함께 기록한다.
에러율은 이렇게 계산한다:
rate(loadbalancer_errors_total[1m]) / rate(loadbalancer_requests_total[1m])loadbalancer_server_health (Gauge)
서버 상태를 0/1로 기록한다. 헬스체크가 제대로 동작하는지 확인하는 용도다.
loadbalancer_server_health # 1 = UP, 0 = DOWNloadbalancer_algorithm_duration_seconds (Timer)
알고리즘 자체 처리 시간이다. 서버를 선택하는 데 얼마나 걸리는지 측정한다.
알고리즘마다 이론적인 시간복잡도가 다르다:
- Round Robin: O(1) → 거의 0ms
- Least Connections: O(n) → 서버 수만큼 순회
- Consistent Hash: O(log n) → 해시 계산 + 링 탐색
트래픽이 늘어날수록 알고리즘 오버헤드 차이가 드러날 것이다.
backend_selection_total (Counter)
알고리즘이 각 서버를 얼마나 자주 선택했는지 기록한다.
loadbalancer_requests_total과 비슷해 보이지만 다르다:
backend_selection_total: 서버 선택 시점loadbalancer_requests_total: 요청 완료 시점
에러로 인한 재시도가 발생하면 둘 사이에 차이가 생긴다. 이 메트릭이 있으면 "Round Robin은 완벽하게 균등 분산, IP Hash는 서버 간 편차 15%" 같은 결론을 낼 수 있다.
loadbalancer_retries_total (Counter)
재시도 횟수다.
에러율은 낮은데 응답이 느리다면 재시도가 많이 발생하고 있는 것이다. Least Response Time처럼 응답시간에 민감한 알고리즘일수록 재시도가 전체 성능에 미치는 영향이 크다.
2. 모니터링 스택 구성
Spring Boot App
│
│ 메트릭 수집 (Micrometer)
▼
MeterRegistry (인메모리)
│
│ /actuator/prometheus 엔드포인트로 노출
▼
Prometheus (Pull 방식으로 수집)
│
│ 시계열 데이터 저장 (TSDB)
▼
Grafana (PromQL로 쿼리 + 시각화)Micrometer는 JVM 기반 애플리케이션의 메트릭 계측 라이브러리다. Prometheus, Datadog, CloudWatch 등 다양한 모니터링 시스템에 연동할 수 있도록 추상화 계층을 제공한다. 수집된 지표는 내부적으로 MeterRegistry에 저장된다.
Spring Boot Actuator는 MeterRegistry에 저장된 메트릭을 HTTP 엔드포인트로 노출한다. /actuator/prometheus에 접근하면 Prometheus가 이해하는 포맷으로 모든 메트릭이 출력된다.
Prometheus는 Pull 방식으로 동작한다. Spring Actuator 엔드포인트를 주기적으로 호출해서 메트릭을 가져와 시계열 데이터베이스에 저장한다. PromQL로 저장된 데이터를 쿼리할 수 있다.
Grafana는 Prometheus를 데이터 소스로 연결해서 메트릭을 시각화한다.
💡 팁: Micrometer의 Annotation 기반 메트릭 수집도 유용하다.
@Timed: 메서드 실행 시간 + 호출 횟수@Counted: 단순 이벤트 횟수@Gauge: 현재 상태 값 추적
selectServer()같은 핵심 메서드에@Timed를 붙이면 코드 수정 없이 성능 데이터를 얻을 수 있다.
3. 메트릭 수집 흐름
요청 하나가 들어왔을 때 어떤 순서로 메트릭이 기록되는지 보면 이렇다.
// 1. 요청 시작 시점 기록
long requestStartTime = System.currentTimeMillis();
// 2. 현재 알고리즘 & 서버 목록 가져오기
String algorithm = currentStrategy.getStrategyName();
List<Server> servers = serverRegistry.getServers();
// 3. 서버 선택 + 알고리즘 처리 시간 측정
long algoStart = System.nanoTime();
server = currentStrategy.selectServer(...);
long algoDuration = System.nanoTime() - algoStart;
metrics.recordAlgorithmDuration(algorithm, algoDuration); // 알고리즘 처리 시간
metrics.incrementBackendSelection(algorithm, server); // 서버 선택 빈도
metrics.updateActiveConnections(server, +1); // 연결 수 증가
// 4. 실제 백엔드 요청 전송
String response = sendRequest(server, path, request);
// 5. 응답 성공 시
success = true;
currentStrategy.updateServerMetrics(server, responseTime, true);
// 6. 에러 발생 시
metrics.incrementErrorCount(algorithm, server, errorType);
// 7. finally 블록 (성공/실패 상관없이 반드시 실행)
metrics.incrementRequestCount(algorithm, server, success);
metrics.recordResponseTime(algorithm, server, responseTime);
metrics.updateActiveConnections(server, -1); // 연결 수 감소7번 finally 블록이 중요하다. decrementConnections()처럼, 요청이 성공하든 실패하든 반드시 정리가 되어야 한다. 그렇지 않으면 활성 연결 수 메트릭이 계속 누적된다.
4. Grafana 대시보드 구성
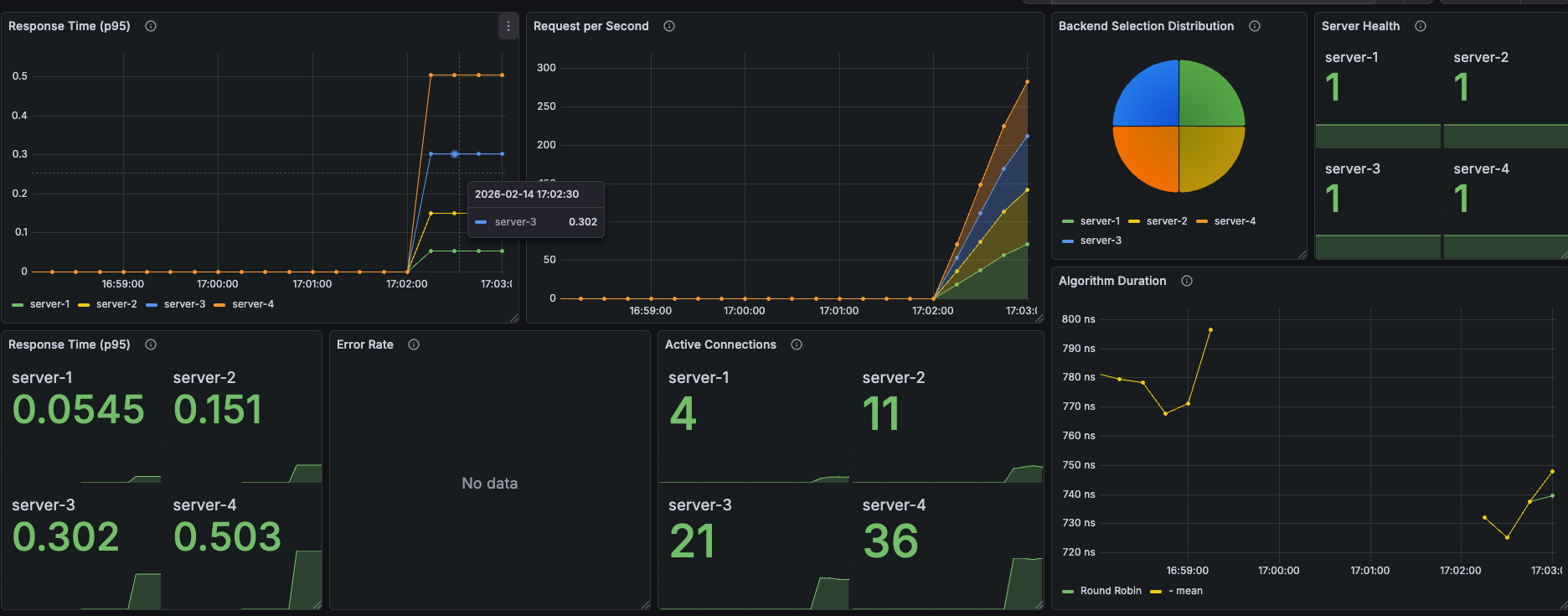
대시보드는 7개 패널로 구성했다.
패널 1 — Error Rate (에러율)
rate(load_balancer_errors_total[1m])Legend: {{server}}
패널 2 — RPS (초당 요청 수)
rate(loadbalancer_requests_total[1m])Legend: {{algorithm}} - {{server}}
패널 3 — 서버별 요청 분포 (Pie Chart)
increase(loadbalancer_backend_selection_total[5m])Legend: {{server}}
패널 4 — 알고리즘 선택 시간
rate(loadbalancer_algorithm_duration_seconds_count[1m])Legend: {{algorithm}}
패널 5 — 활성 연결 수
loadbalancer_active_connectionsLegend: {{server}}
패널 6 — 서버 헬스 (Stat, 1 = UP / 0 = DOWN)
loadbalancer_server_healthLegend: {{server}}
5. 테스트 시나리오 3가지
알고리즘을 비교하기 위해 3가지 시나리오를 설계했다.
시나리오 1 — 균등 트래픽 (Steady Load)
모든 서버가 안정적으로 동작하는 일반적인 상황. 각 알고리즘의 평균 성능 비교가 목적이다.
- K6 구성: 3~5분 동안 VU 일정하게 유지
- 이 시나리오가 실서비스 환경과 가장 유사하다
시나리오 2 — 버스트 트래픽 (Sudden Spike)
순간적으로 요청이 폭증하는 상황. 알고리즘이 트래픽 급증에 어떻게 대응하는지 확인한다.
- K6 구성: VU를 10 → 100 → 10으로 급격하게 변화
- RPS, 응답시간, 에러율 변화를 관찰한다
시나리오 3 — 서버 장애 (Mid-Test Server Down)
테스트 중간에 서버를 의도적으로 종료한다. Failover가 제대로 동작하는지 확인한다.
- K6 구성: 트래픽이 진행 중인 상태에서 서버 1개 종료
- 알고리즘이 대체 서버로 얼마나 빠르게 전환하는지 평가한다
균등 트래픽
테스트 조건
- 시나리오 - Steady Load(균등 트래픽)
- Server별 Response Delay (50/150/300/500 ms)
- VUs: 100 고정
- Duration: 3분
- Sleep: 0.1s
- 엔드포인트
GET /test
import http from 'k6/http';
import { check, sleep } from 'k6';
export const options = {
vus: 100,
duration: '3m',
};
export default function () {
const res = http.get('http://localhost:8080/test');
check(res, {
'status is 200': (r) => r.status === 200,
'response time < 1000ms': (r) => r.timings.duration < 1000,
});
sleep(0.1);
}Round Robin
█ TOTAL RESULTS
checks_total.......: 101996 564.739518/s
checks_succeeded...: 100.00% 101996 out of 101996
checks_failed......: 0.00% 0 out of 101996
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=253.04ms min=50.67ms med=245.14ms max=538.68ms p(90)=503.02ms p(95)=503.91ms
{ expected_response:true }...: avg=253.04ms min=50.67ms med=245.14ms max=538.68ms p(90)=503.02ms p(95)=503.91ms
http_req_failed................: 0.00% 0 out of 50998
http_reqs......................: 50998 282.369759/s
EXECUTION
iteration_duration.............: avg=353.37ms min=150.78ms med=346.09ms max=644.01ms p(90)=603.43ms p(95)=604.36ms
iterations.....................: 50998 282.369759/s
vus............................: 100 min=100 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 7.6 MB 42 kB/s
data_sent......................: 3.8 MB 21 kB/s
K6 결과
-
처리량
- 총 요청 수: 50,911건
- RPS: 281.9 req/s
-
응답시간
- avg: 253.58ms
- med: 253.95ms
- min: 50.94ms
- max: 598.78ms
- p90: 503.4ms
- p95: 504.34ms
-
안정성
- 에러율: 0.00% (50,911건 전부 성공)
- status 200 체크: 100% 통과
- response time < 1000ms 체크: 100% 통과
Grafana 메트릭
서버 선택 비율 (Backend Selection Distribution)
- server-1 ~ server-4: 각 25% 균등 분배
- Round Robin 특성대로 완벽한 균등 분산 확인
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0545 | 0.151 | 0.302 | 0.503 |
→ 각 서버의 설정된 RESPONSE_DELAY(50/150/300/500ms)와 거의 일치
Active Connections (테스트 종료 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 4 | 11 | 22 | 36 |
→ 균등 분배임에도 활성 연결 수는 불균등. 느린 서버일수록 요청 처리가 오래 걸려 연결이 쌓임
Algorithm Duration
- 평균: ~600ns (나노초)
- Round Robin의 서버 선택 로직 자체는 거의 무시할 수 있는 수준의 오버헤드
Error Rate: No data (에러 없음)
Server Health: 4개 서버 모두 정상 (1)
분석
Round Robin의 특성이 명확히 드러난 결과:
- 균등 분배의 장점과 한계
- 선택 비율은 정확히 25%씩 균등하지만, 서버 성능 차이를 전혀 고려하지 않음
- server-4(500ms)에도 동일한 비율로 요청을 보내기 때문에 전체 평균 응답시간이 253ms로 상승
- 이론적 평균: (50+150+300+500)/4 = 250ms → 실측 253ms와 거의 일치
- 활성 연결 불균형 문제
- 요청은 균등하게 보내지만, 느린 서버는 처리가 오래 걸려 연결이 누적됨
- server-4의 활성 연결(36)이 server-1(4)의 9배
- 이는 느린 서버에 과부하가 걸릴 수 있는 구조적 문제
- 알고리즘 오버헤드
- 선택 시간 600ns는 응답시간(253ms) 대비 무시 가능한 수준
- 단순한 인덱스 순환이라 계산 비용이 거의 없음
Weighted Round Robin
가중치 : server1 - 6, server2 - 3, server3 - 2 , server4 - 1
█ TOTAL RESULTS
checks_total.......: 139930 774.890285/s
checks_succeeded...: 100.00% 139930 out of 139930
checks_failed......: 0.00% 0 out of 139930
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=157.1ms min=50.53ms med=129.32ms max=578.76ms p(90)=304.39ms p(95)=502.5ms
{ expected_response:true }...: avg=157.1ms min=50.53ms med=129.32ms max=578.76ms p(90)=304.39ms p(95)=502.5ms
http_req_failed................: 0.00% 0 out of 69965
http_reqs......................: 69965 387.445143/s
EXECUTION
iteration_duration.............: avg=257.47ms min=150.66ms med=230.71ms max=680.41ms p(90)=404.83ms p(95)=602.99ms
iterations.....................: 69965 387.445143/s
vus............................: 100 min=100 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 11 MB 58 kB/s
data_sent......................: 5.2 MB 29 kB/s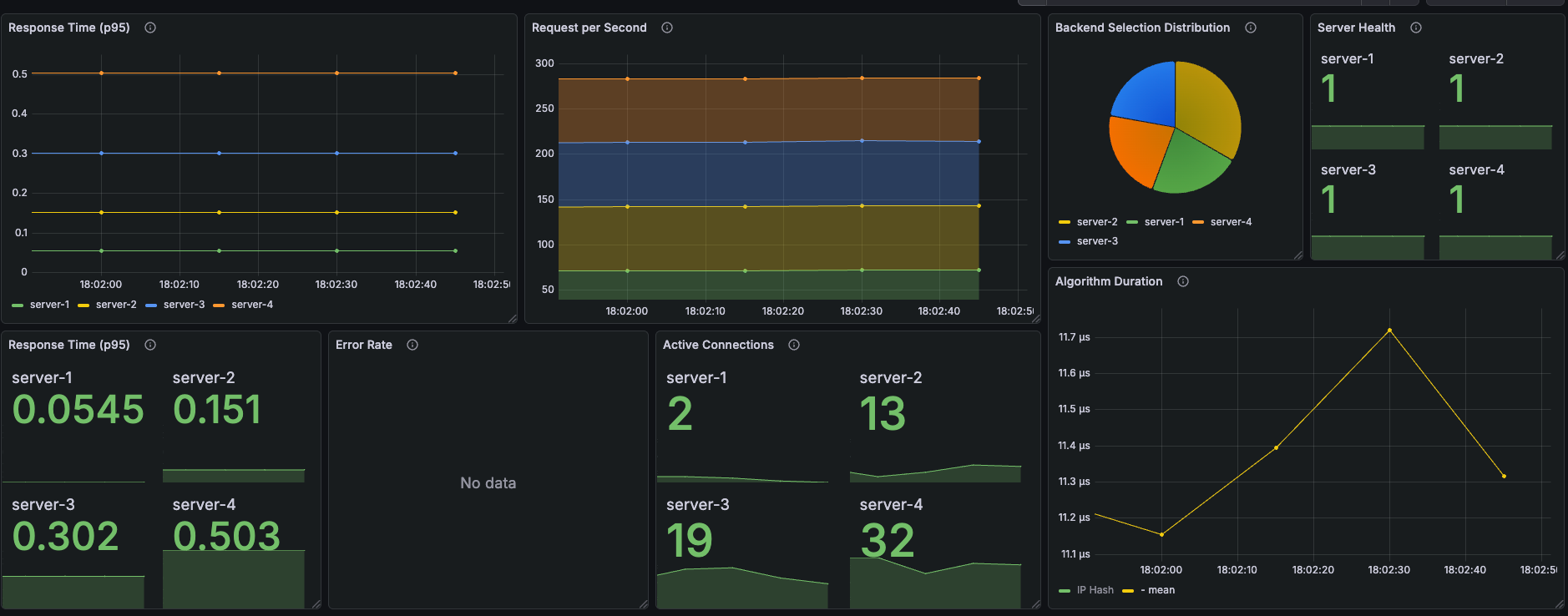
K6 결과
- 처리량
- 총 요청 수: 69,965건
- RPS: 387.4 req/s
- 응답시간
- avg: 157.1ms
- med: 129.32ms
- min: 50.53ms
- max: 578.76ms
- p90: 304.39ms
- p95: 502.5ms
- 에러율: 0.00% (69,965건 전부 성공)
- status 200 체크: 100% 통과
- response time < 1000ms 체크: 100% 통과
Grafana 메트릭
서버 선택 비율 (Backend Selection Distribution)
- server-1: 약 50% (가중치 6/12)
- server-2: 약 25% (가중치 3/12)
- server-3: 약 16.7% (가중치 2/12)
- server-4: 약 8.3% (가중치 1/12)
- 파이차트에서 가중치 비율대로 분배 확인
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0545 | 0.151 | 0.302 | 0.503 |
→ 서버별 응답시간은 RR과 동일 (서버 자체 성능은 변하지 않음)
Active Connections (테스트 종료 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 6 | 14 | 18 | 16 |
→ RR(4/11/22/36) 대비 훨씬 균등해짐. 빠른 서버에 더 많이 보내니 활성 연결이 분산됨
Algorithm Duration
- 평균: ~4.5μs (마이크로초)
- RR(600ns) 대비 약 7.5배 느리지만, 응답시간(157ms) 대비 여전히 무시 가능한 수준
Error Rate: No data (에러 없음)
Server Health: 4개 서버 모두 정상
분석
- 처리량 37.5% 향상
- RR: 281.9 RPS → WRR: 387.4 RPS
- 빠른 서버(server-1)에 50% 요청을 보내면서 전체 처리 속도 향상
- 평균 응답시간 38% 감소
- RR: 253.58ms → WRR: 157.1ms
- 가중치를 통해 빠른 서버 활용을 극대화한 효과
- 활성 연결 균등화
- RR: 4/11/22/36 (편차 큼) → WRR: 6/14/18/16 (편차 감소)
- 빠른 서버에 많이 보내고 느린 서버에 적게 보내니, 처리 속도와 요청 비율이 상쇄되어 연결이 균등해짐
- 알고리즘 오버헤드 증가는 미미
- RR: 600ns → WRR: 4.5μs
- 가중치 계산 로직이 추가되었지만 응답시간 대비 무시 가능
한계점
- 가중치가 정적이라 서버 상태가 변해도 적응 불가
- 최적 가중치를 사전에 알아야 함 (현재는 응답시간 기반으로 수동 설정)
- Least Connections, Least Response Time 같은 동적 알고리즘과의 비교가 필요
Least Connections
█ TOTAL RESULTS
checks_total.......: 152058 842.045993/s
checks_succeeded...: 100.00% 152058 out of 152058
checks_failed......: 0.00% 0 out of 152058
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=136.58ms min=50.57ms med=53.4ms max=574.65ms p(90)=303.16ms p(95)=502.15ms
{ expected_response:true }...: avg=136.58ms min=50.57ms med=53.4ms max=574.65ms p(90)=303.16ms p(95)=502.15ms
http_req_failed................: 0.00% 0 out of 76029
http_reqs......................: 76029 421.022996/s
EXECUTION
iteration_duration.............: avg=236.93ms min=150.71ms med=153.85ms max=677.32ms p(90)=403.59ms p(95)=602.47ms
iterations.....................: 76029 421.022996/s
vus............................: 100 min=100 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 11 MB 63 kB/s
data_sent......................: 5.6 MB 31 kB/sK6 결과
- 처리량
- 총 요청 수: 76,029건
- RPS: 421.0 req/s
- 응답시간
- avg: 136.58ms
- med: 53.4ms
- min: 50.57ms
- max: 574.65ms
- p90: 303.16ms
- p95: 502.15ms
- 안정성
- 에러율: 0.00% (76,029건 전부 성공)
- status 200 체크: 100% 통과
- response time < 1000ms 체크: 100% 통과
Grafana 메트릭
서버 선택 비율 (Backend Selection Distribution)
- server-1이 가장 큰 비율 (파이차트에서 약 50%+)
- server-2, server-3, server-4는 상대적으로 적은 비율
- 빠른 서버가 연결을 빨리 해제하므로 자연스럽게 더 많은 요청을 받음
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0524 | 0.151 | 0.302 | 0.503 |
→ 서버 자체 성능은 동일
Active Connections (테스트 종료 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 14 | 14 | 14 | 14 |
→ 완벽한 연결 균등화! Least Connections의 핵심 특성이 명확히 드러남
Algorithm Duration
- 평균: ~3.2μs (마이크로초)
- WRR(4.5μs)보다 오히려 빠름
Error Rate: No data (에러 없음)
Server Health: 4개 서버 모두 정상 (1)
분석
- 처리량
- RR: 281.9 → WRR: 387.4 → LC: 421.0 RPS
- RR 대비 49.3% 향상, WRR 대비 8.7% 향상
- 평균 응답시간 현재 최저
- RR: 253.58ms → WRR: 157.1ms → LC: 136.58ms
- 중앙값(med)이 53.4ms로 매우 낮음 → 대부분의 요청이 server-1(빠른 서버)로 향함
- 활성 연결 완벽 균등화 (핵심 발견)
- RR: 4/11/22/36 (극심한 불균형)
- WRR: 6/14/18/16 (개선됨)
- LC: 14/14/14/14 (완벽한 균등)
- 연결 수 기반으로 선택하니 당연한 결과이지만, 시각적으로 매우 인상적
- 자동 가중치 효과
- WRR처럼 수동으로 가중치를 설정하지 않아도, 빠른 서버가 연결을 빨리 해제 → 자연스럽게 더 많은 요청을 받음
- 사실상 서버 성능에 따른 동적 가중치가 자동 적용되는 셈
- med vs avg 차이가 큰 점
- avg: 136.58ms인데 med: 53.4ms
- 절반 이상의 요청이 server-1으로 가서 50ms대에 처리됨
- 느린 서버(server-3, 4)로 가는 소수 요청이 평균을 올리는 구조
IP Hash
- IP 시뮬레이션:
X-Forwarded-For헤더로 랜덤 IP 생성
█ TOTAL RESULTS
checks_total.......: 101812 563.728164/s
checks_succeeded...: 100.00% 101812 out of 101812
checks_failed......: 0.00% 0 out of 101812
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=253.61ms min=50.76ms med=301.25ms max=547ms p(90)=503.11ms p(95)=504.15ms
{ expected_response:true }...: avg=253.61ms min=50.76ms med=301.25ms max=547ms p(90)=503.11ms p(95)=504.15ms
http_req_failed................: 0.00% 0 out of 50906
http_reqs......................: 50906 281.864082/s
EXECUTION
iteration_duration.............: avg=354.01ms min=150.91ms med=401.44ms max=653.76ms p(90)=603.61ms p(95)=604.72ms
iterations.....................: 50906 281.864082/s
vus............................: 100 min=100 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 7.6 MB 42 kB/s
data_sent......................: 5.5 MB 30 kB/s
K6 결과
- 처리량
- 총 요청 수: 50,906건
- RPS: 281.9 req/s
- 응답시간
- avg: 253.61ms
- med: 301.25ms
- min: 50.76ms
- max: 547ms
- p90: 503.11ms
- p95: 504.15ms
- 안정성
- 에러율: 0.00% (50,906건 전부 성공)
- status 200 체크: 100% 통과
- response time < 1000ms 체크: 100% 통과
Grafana 메트릭
서버 선택 비율 (Backend Selection Distribution)
- 4개 서버에 대략 균등하게 분배 (파이차트 기준 각 ~25%)
- 랜덤 IP의 해시 분포가 균등하기 때문
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0545 | 0.151 | 0.302 | 0.503 |
Active Connections (테스트 종료 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 2 | 13 | 19 | 32 |
→ RR과 거의 동일한 패턴. 균등 분배이므로 느린 서버에 연결이 쌓임
Algorithm Duration
- 평균: ~11.3μs (마이크로초)
- 해시 계산 + 캐시 조회(
ConcurrentHashMap.compute) 비용이 반영됨 - RR(600ns), WRR(4.5μs), LC(3.2μs) 대비 가장 높음
Error Rate: No data (에러 없음)
Server Health: 4개 서버 모두 정상 (1)
분석
IP Hash가 Round Robin과 거의 동일한 성능을 보인 결과:
- RR과 사실상 동일한 수치
- RPS: RR 281.9 ≈ IP Hash 281.9
- avg: RR 253.58ms ≈ IP Hash 253.61ms
- 랜덤 IP로 테스트했기 때문에 해시 분포가 균등 → 결과적으로 RR과 같은 25% 균등 분배
- med(중앙값)가 RR보다 높음
- RR med: 253.95ms vs IP Hash med: 301.25ms
- 해시 분포의 미세한 불균등으로 server-3(300ms)쪽에 약간 더 몰린 것으로 추정
- Algorithm Duration이 가장 높음 (11.3μs)
- 해시 계산 + ConcurrentHashMap.compute + 캐시 조회 비용
- RR(600ns)의 약 19배이지만, 응답시간(253ms) 대비 여전히 무시 가능
- IP Hash의 진짜 가치는 성능이 아닌 세션 지속성
- 같은 IP → 항상 같은 서버로 보장
- 이 테스트에서는 랜덤 IP라 세션 지속성 이점이 드러나지 않음
- 성능만 보면 RR과 동일하지만, 세션이 필요한 환경에서는 의미 있는 선택
Consistent Hash
- IP 시뮬레이션 -
X-Forwarded-For헤더로 랜덤 IP 생성 - 가상 노드: 150개
█ TOTAL RESULTS
checks_total.......: 100946 559.003459/s
checks_succeeded...: 100.00% 100946 out of 100946
checks_failed......: 0.00% 0 out of 100946
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=256.64ms min=50.79ms med=301.76ms max=576.93ms p(90)=503.24ms p(95)=504.24ms
{ expected_response:true }...: avg=256.64ms min=50.79ms med=301.76ms max=576.93ms p(90)=503.24ms p(95)=504.24ms
http_req_failed................: 0.00% 0 out of 50473
http_reqs......................: 50473 279.501729/s
EXECUTION
iteration_duration.............: avg=357.04ms min=150.9ms med=402ms max=679.57ms p(90)=603.72ms p(95)=604.8ms
iterations.....................: 50473 279.501729/s
vus............................: 100 min=100 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 7.6 MB 42 kB/s
data_sent......................: 5.4 MB 30 kB/sK6 결과
- 처리량
- 총 요청 수: 50,473건
- RPS: 279.5 req/s
- 응답시간
- avg: 256.64ms
- med: 301.76ms
- min: 50.79ms
- max: 576.93ms
- p90: 503.24ms
- p95: 504.24ms
- 안정성
- 에러율: 0.00% (50,473건 전부 성공)
- status 200 체크: 100% 통과
- response time < 1000ms 체크: 100% 통과
Grafana 메트릭
서버 선택 비율 (Backend Selection Distribution)
- 대략 균등하지만 server-3이 약간 많은 비율
- 가상 노드 150개로 분산했지만 완벽한 균등은 아님 (해시 분포 특성)
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0545 | 0.151 | 0.302 | 0.503 |
Active Connections (테스트 종료 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 4 | 11 | 24 | 35 |
→ RR, IP Hash와 유사한 패턴. 균등 분배 계열의 공통 특성
Algorithm Duration
- 평균: ~30.8μs (마이크로초)
- 전체 알고리즘 중 가장 높음. MD5 해시 + ConcurrentSkipListMap.ceilingEntry 비용
Error Rate: No data (에러 없음)
Server Health: 4개 서버 모두 정상 (1)
분석
Consistent Hashing이 Steady Load에서 가장 낮은 성능을 보인 결과:
- 처리량 최하위
- RPS: 279.5 (RR 281.9보다도 낮음)
- Algorithm Duration(30.8μs)이 가장 높아 미세하게 처리량에 영향
- Algorithm Duration이 압도적으로 높음
- RR: 600ns → IP Hash: 11.3μs → CH: 30.8μs
- MD5 해시 계산 + SkipListMap 탐색 비용
- 하지만 응답시간(256ms) 대비 0.012%로 실질적 병목은 아님
- IP Hash와 거의 동일한 결과
- 둘 다 해시 기반 균등 분배라 성능 특성이 유사
- avg: IP Hash 253.61ms ≈ CH 256.64ms
- 차이점은 서버 추가/제거 시 재배치 비율 (CH가 유리)
- Consistent Hashing의 진짜 가치는 이 테스트에서 안 보임
- 서버 추가/제거 시 최소 재배치 → 서버 장애 시나리오에서 평가 필요
- 세션 지속성 → 동일 IP가 같은 서버로 가는지는 별도 검증 필요
Least Response Time
█ TOTAL RESULTS
checks_total.......: 230572 1280.786413/s
checks_succeeded...: 100.00% 230572 out of 230572
checks_failed......: 0.00% 0 out of 230572
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=55.68ms min=18µs med=54.27ms max=586.46ms p(90)=57.58ms p(95)=59.48ms
{ expected_response:true }...: avg=55.68ms min=18µs med=54.27ms max=586.46ms p(90)=57.58ms p(95)=59.48ms
http_req_failed................: 0.00% 0 out of 115286
http_reqs......................: 115286 640.393207/s
EXECUTION
iteration_duration.............: avg=156.17ms min=150.79ms med=154.78ms max=691.13ms p(90)=158.09ms p(95)=160.02ms
iterations.....................: 115286 640.393207/s
vus............................: 100 min=100 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 17 MB 96 kB/s
data_sent......................: 12 MB 69 kB/s
K6 결과
- 처리량
- 총 요청 수: 115,286건
- RPS: 640.4 req/s
- 응답시간
- avg: 55.68ms
- med: 54.27ms
- min: 0.018ms
- max: 586.46ms
- p90: 57.58ms
- p95: 59.48ms
- 안정성
- 에러율: 0.00% (115,286건 전부 성공)
- status 200 체크: 100% 통과
- response time < 1000ms 체크: 100% 통과
Grafana 메트릭
서버 선택 비율 (Backend Selection Distribution)
- server-1: 거의 100%
- server-2, 3, 4: 거의 0%
- 사실상 단일 서버 운영 상태
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0587 | 0 | 0 | 0 |
→ server-1만 사용되므로 나머지 서버의 응답시간 데이터 없음
Active Connections (테스트 종료 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 35 | 0 | 0 | 0 |
→ 모든 연결이 server-1에 집중
Algorithm Duration
- 평균: ~46μs (마이크로초)
- 전체 알고리즘 중 가장 높음. 가중평균 + 평균 계산 비용
Error Rate: No data (에러 없음)
Server Health: 4개 서버 모두 정상 (1)
분석
- RPS는 압도적 1위지만 로드밸런싱이 아님
- RPS 640.4는 전체 알고리즘 중 최고
- 하지만 server-1(50ms)만 사용한 결과이므로 단일 서버 성능과 동일
- 나머지 3대의 서버 리소스가 완전히 낭비됨
- 스노우볼 효과 메커니즘
- server-1이 50ms로 가장 빠름 → 모든 요청이 server-1으로 집중
- server-1이 워낙 빨라서 부하가 쌓여도 여전히 다른 서버보다 빠름
- 다른 서버는 요청을 받지 못해 응답시간 데이터가 없거나 초기값 유지
- 결과적으로 영구적인 쏠림 발생
- 단일 장애점 문제 재발생
- server-1이 장애나면 나머지 서버에 응답시간 데이터가 없어 대응 어려움
- 로드밸런싱의 근본 목적인 가용성 확보가 안 됨
- Algorithm Duration 최고치 (46μs)
- 모든 서버의 응답시간을 계산/비교하는 비용
- 그러나 server-1만 데이터가 있어 사실상 의미 없는 비교
마치며
6가지 알고리즘을 동일한 조건으로 테스트한 결과를 정리하면 이렇다.
| 알고리즘 | RPS | avg 응답시간 | 서버 분배 | 알고리즘 오버헤드 |
|---|---|---|---|---|
| Round Robin | 282 | 253ms | 25% 균등 | 600ns |
| Weighted RR | 387 | 157ms | 가중치 비율 | 4.5μs |
| Least Connections | 421 | 137ms | 동적 균등 | 3.2μs |
| IP Hash | 282 | 254ms | ~25% 균등 | 11.3μs |
| Consistent Hash | 280 | 257ms | ~25% 균등 | 30.8μs |
| Least Response Time | 640 | 56ms | server-1 독점 | 46μs |
수치만 보면 Least Response Time이 압도적으로 보이지만, 이건 좋은 결과가 아니다. 서버 4대 중 1대만 쓴 결과다. 나머지 3대는 놀고 있고, server-1이 장애나면 응답시간 데이터가 없는 다른 서버들이 제대로 대응하기 어렵다.
이번 테스트에서 배운 것 몇 가지:
균등하게 분배한다는 게 꼭 좋은 게 아니다. Round Robin은 요청을 25%씩 정확히 나눴지만, 활성 연결 수는 4:11:22:36으로 터무니없이 불균형했다. 서버 성능을 무시하고 요청만 균등하게 보내면 느린 서버에 연결이 쌓인다.
Least Connections의 "완벽한 연결 균등(14:14:14:14)"이 인상적이었다. 따로 가중치를 설정하지 않아도 빠른 서버가 자연스럽게 더 많은 요청을 처리한다. WRR처럼 최적 가중치를 미리 알 필요가 없다는 게 실운영에서 큰 장점이다.
알고리즘 오버헤드는 생각보다 영향이 적다. 가장 무거운 Consistent Hash(30.8μs)도 실제 응답시간(256ms)의 0.012%다. 알고리즘 선택 기준에서 오버헤드는 후순위로 봐도 된다.
IP Hash와 Consistent Hash의 가치는 이 테스트에서 안 드러났다. 둘 다 성능은 Round Robin과 거의 같지만, 진짜 장점은 세션 지속성이다. 같은 클라이언트가 항상 같은 서버로 가는 게 중요한 환경에서 의미 있다. 특히 Consistent Hash는 서버가 추가/제거됐을 때 재배치되는 키가 최소화된다는 점에서, 다음 서버 장애 시나리오에서 차이가 드러날 것이다.
다음 편에서는 버스트 트래픽과 서버 장애 시나리오를 테스트한다. 정적으로 잘 돌아가던 알고리즘들이 갑작스러운 트래픽 폭증과 장애 상황에서 어떻게 다르게 반응하는지 비교해본다.
