8편: Burst 트래픽과 서버 장애 — 알고리즘의 진짜 실력은 위기에서 드러난다
안정적인 환경에서는 다 잘 된다. 중요한 건 트래픽이 폭증하거나 서버가 죽었을 때다.
7편에서 균등 트래픽 조건으로 6가지 알고리즘을 테스트했다. Round Robin은 요청은 균등하게 보냈지만 연결이 쌓였고, Least Response Time은 RPS는 압도적이었지만 사실상 단일 서버 운영이었다.
이번 편에서는 두 가지 시나리오를 추가한다.
- Burst: VU를 10 → 250으로 급격하게 올렸다가 다시 내린다. 트래픽 폭증 상황에서 각 알고리즘이 어떻게 반응하는지 본다.
- Server Failure: 테스트 도중 server-1을 강제로 종료한다. 헬스체크가 감지하기 전까지 얼마나 에러가 나는지, 복구 후 재분배가 잘 되는지 확인한다.
Steady Load에서는 잘 보이지 않던 각 알고리즘의 특성이 여기서 드러난다.
Burst 시나리오
테스트 조건
- 시나리오: Burst (급격한 트래픽 증가)
- VUs: 10 → 250 → 10
- Duration: 2분 20초
- Sleep: 0.1s
- 엔드포인트:
GET /test
import http from 'k6/http';
import { check, sleep } from 'k6';
export const options = {
stages: [
{ duration: '30s', target: 10 }, // 워밍업
{ duration: '10s', target: 250 }, // 급격한 증가
{ duration: '1m', target: 250 }, // 피크 유지
{ duration: '10s', target: 10 }, // 급격한 감소
{ duration: '30s', target: 10 }, // 안정화
],
};
export default function () {
const res = http.get('http://localhost:8080/test');
check(res, {
'status is 200': (r) => r.status === 200,
'response time < 2000ms': (r) => r.timings.duration < 2000,
});
sleep(0.1);
}RoundRobin
█ TOTAL RESULTS
checks_total.......: 102614 730.013546/s
checks_succeeded...: 100.00% 102614 out of 102614
checks_failed......: 0.00% 0 out of 102614
✓ status is 200
✓ response time < 2000ms
HTTP
http_req_duration..............: avg=252.55ms min=50.49ms med=182.26ms max=534.04ms p(90)=502.34ms p(95)=502.95ms
{ expected_response:true }...: avg=252.55ms min=50.49ms med=182.26ms max=534.04ms p(90)=502.34ms p(95)=502.95ms
http_req_failed................: 0.00% 0 out of 51307
http_reqs......................: 51307 365.006773/s
EXECUTION
iteration_duration.............: avg=352.84ms min=150.61ms med=283.35ms max=634.4ms p(90)=602.61ms p(95)=603.31ms
iterations.....................: 51307 365.006773/s
vus............................: 10 min=1 max=250
vus_max........................: 250 min=250 max=250
NETWORK
data_received..................: 7.7 MB 55 kB/s
data_sent......................: 3.8 MB 27 kB/s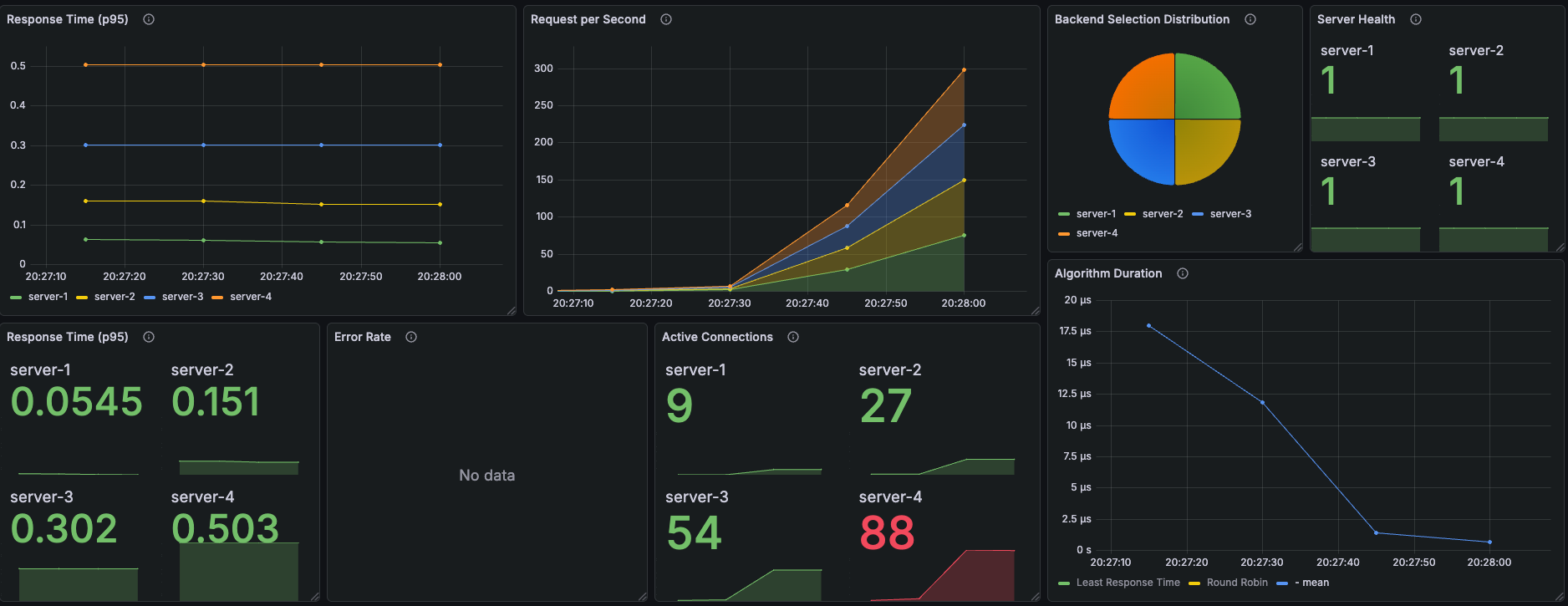
K6 결과
처리량
- 총 요청 수: 51,307건
- RPS: 365.0 req/s
응답시간
- avg: 252.55ms
- med: 182.26ms
- min: 50.49ms
- max: 534.04ms
- p90: 502.34ms
- p95: 502.95ms
안정성
- 에러율: 0.00%
- 모든 체크 통과
Grafana 메트릭
서버 선택 비율: 약 25% 균등 분배
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0545 | 0.151 | 0.302 | 0.503 |
Active Connections (피크 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 9 | 27 | 54 | 88 |
→ Steady(4/11/22/36) 대비 약 2.5배 증가. VU 250이니 당연한 결과
→ server-4에 88개 연결이 쌓임 — burst 시 느린 서버의 부하 집중이 더 심해짐
Algorithm Duration: ~1μs (RR 특성상 일정)
Error Rate: No data (에러 없음)
분석
Steady vs Burst 비교 (Round Robin):
| 지표 | Steady (100 VU) | Burst (10→250→10) |
|---|---|---|
| RPS | 281.9 | 365.0 |
| avg | 253.58ms | 252.55ms |
| med | 253.95ms | 182.26ms |
| Active Conn (server-4) | 36 | 88 |
| 에러율 | 0% | 0% |
- RPS 증가는 VU 증가 때문 — 평균 VU가 높으니 총 처리량도 증가
- avg는 거의 동일 — 알고리즘 특성은 변하지 않음
- 핵심 발견: 느린 서버의 연결 폭증 — server-4 Active Connections가 88까지 치솟음. burst 상황에서 RR의 균등 분배가 느린 서버에 과부하를 가중시키는 문제가 명확히 드러남
Weighted Round Robin
가중치: server-1(6) : server-2(3) : server-3(2) : server-4(1)
█ TOTAL RESULTS
checks_total.......: 140590 1001.475287/s
checks_succeeded...: 100.00% 140590 out of 140590
checks_failed......: 0.00% 0 out of 140590
✓ status is 200
✓ response time < 2000ms
HTTP
http_req_duration..............: avg=157.09ms min=50.48ms med=150.83ms max=627.57ms p(90)=303.93ms p(95)=502.01ms
{ expected_response:true }...: avg=157.09ms min=50.48ms med=150.83ms max=627.57ms p(90)=303.93ms p(95)=502.01ms
http_req_failed................: 0.00% 0 out of 70295
http_reqs......................: 70295 500.737643/s
EXECUTION
iteration_duration.............: avg=257.37ms min=150.58ms med=250.96ms max=727.84ms p(90)=404.31ms p(95)=602.22ms
iterations.....................: 70295 500.737643/s
vus............................: 10 min=1 max=250
vus_max........................: 250 min=250 max=250
NETWORK
data_received..................: 11 MB 75 kB/s
data_sent......................: 5.2 MB 37 kB/s
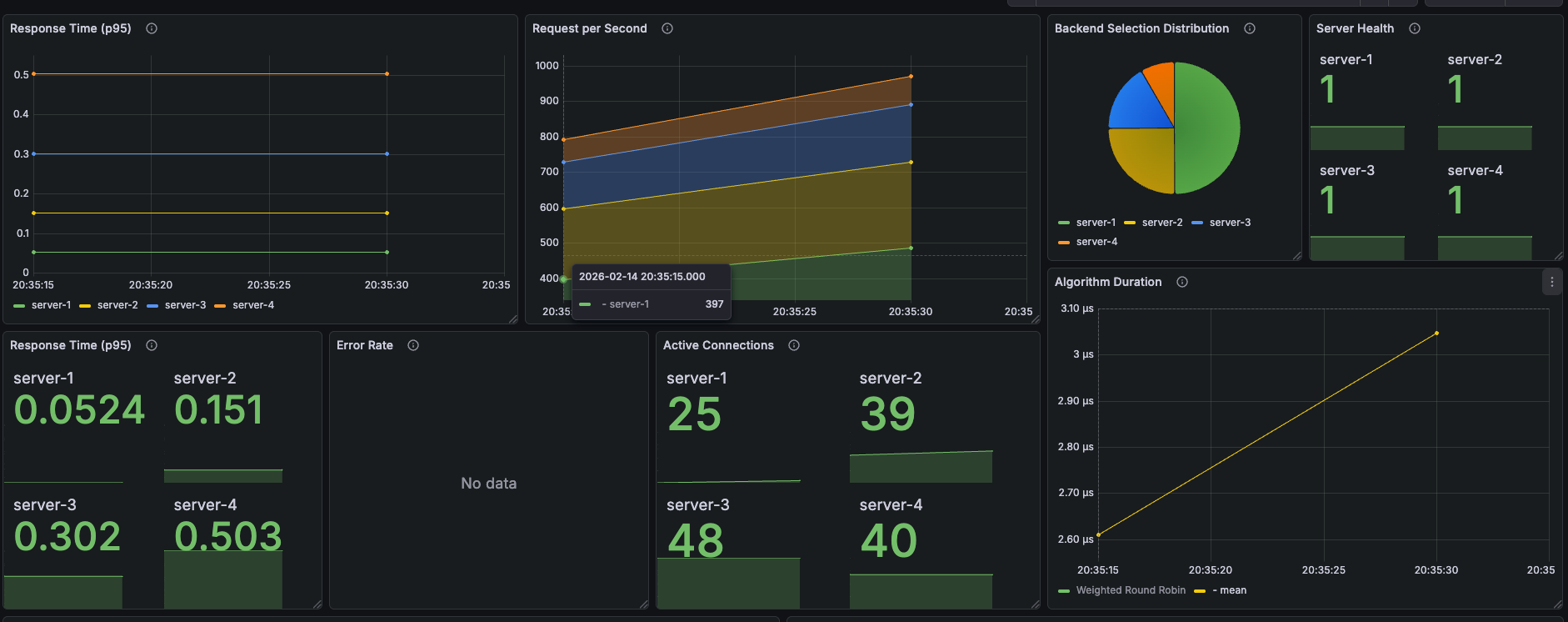
K6 결과
- 처리량
- 총 요청 수: 70,295건
- RPS: 500.7 req/s
- 응답시간
- avg: 157.09ms
- med: 150.83ms
- min: 50.48ms
- max: 627.57ms
- p90: 303.93ms
- p95: 502.01ms
- 안정성
- 에러율: 0.00%
- 모든 체크 통과
Grafana 메트릭
서버 선택 비율: 가중치 비율대로 분배 (6:3:2:1)
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0524 | 0.151 | 0.302 | 0.503 |
Active Connections (피크 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 25 | 39 | 48 | 40 |
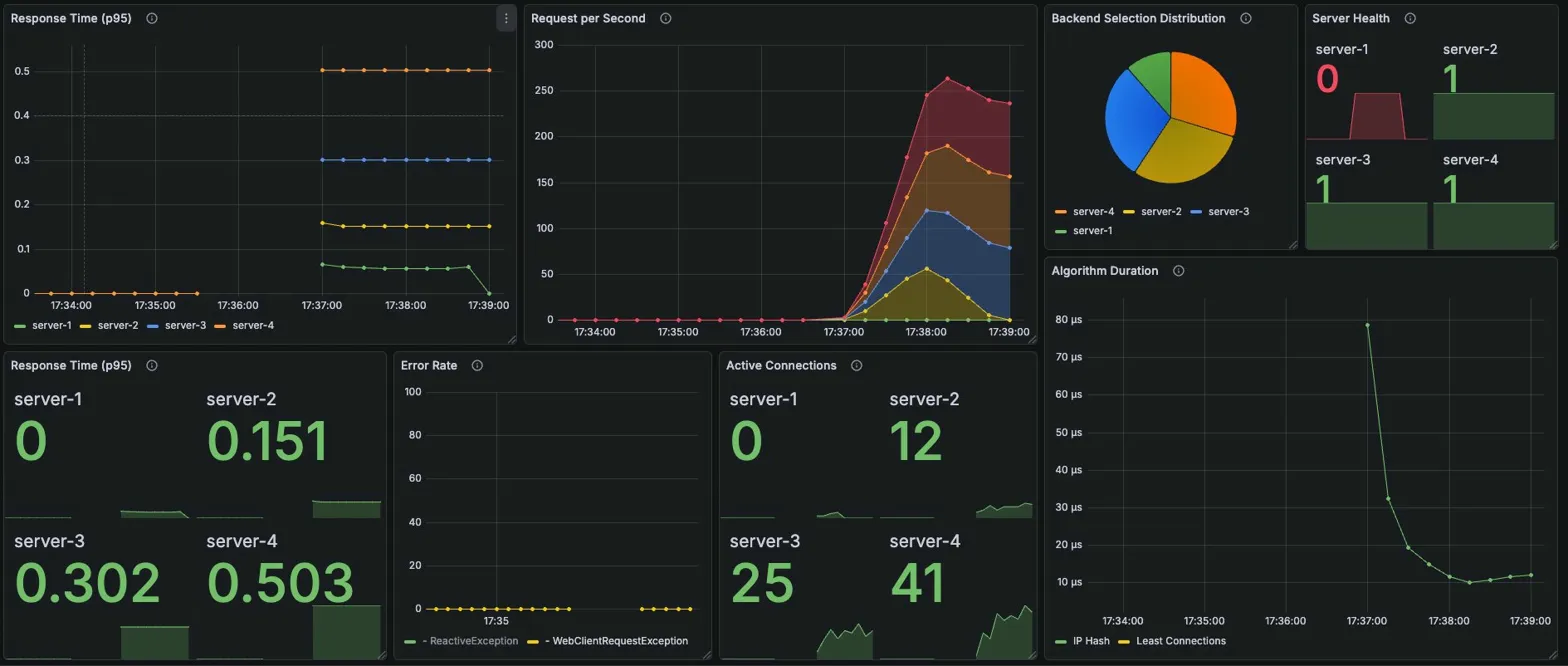
Algorithm Duration: ~2.8μs
Error Rate: No data (에러 없음)
분석
WRR Steady vs Burst 비교:
| 지표 | Steady (100 VU) | Burst (10→250→10) |
|---|---|---|
| RPS | 387.4 | 500.7 |
| avg | 157.1ms | 157.09ms |
| Active Conn | 6/14/18/16 | 25/39/48/40 |
| 에러율 | 0% | 0% |
-
avg가 완전히 동일 — WRR의 가중치 분배가 부하 증가에도 일관성 유지
-
Active Connections 비율도 유사
Steady(6/14/18/16) → Burst(25/39/48/40), 비율 패턴이 거의 동일하게 스케일링
-
RR Burst 대비 확실한 개선 — RR은 server-4에 88개 쌓였지만 WRR은 40개로 억제
Burst 비교표 (현재까지):
| 지표 | RR | WRR |
|---|---|---|
| RPS | 365.0 | 500.7 |
| avg (ms) | 252.55 | 157.09 |
| Active Conn (server-4) | 88 | 40 |
| 에러율 | 0% | 0% |
Least Connection
█ TOTAL RESULTS
checks_total.......: 152568 1087.790019/s
checks_succeeded...: 100.00% 152568 out of 152568
checks_failed......: 0.00% 0 out of 152568
✓ status is 200
✓ response time < 2000ms
HTTP
http_req_duration..............: avg=136.8ms min=182µs med=53.24ms max=561.89ms p(90)=302.9ms p(95)=501.88ms
{ expected_response:true }...: avg=136.8ms min=182µs med=53.24ms max=561.89ms p(90)=302.9ms p(95)=501.88ms
http_req_failed................: 0.00% 0 out of 76284
http_reqs......................: 76284 543.89501/s
EXECUTION
iteration_duration.............: avg=237.09ms min=150.57ms med=153.58ms max=662.15ms p(90)=403.22ms p(95)=602.09ms
iterations.....................: 76284 543.89501/s
vus............................: 10 min=1 max=250
vus_max........................: 250 min=250 max=250
NETWORK
data_received..................: 11 MB 81 kB/s
data_sent......................: 5.6 MB 40 kB/s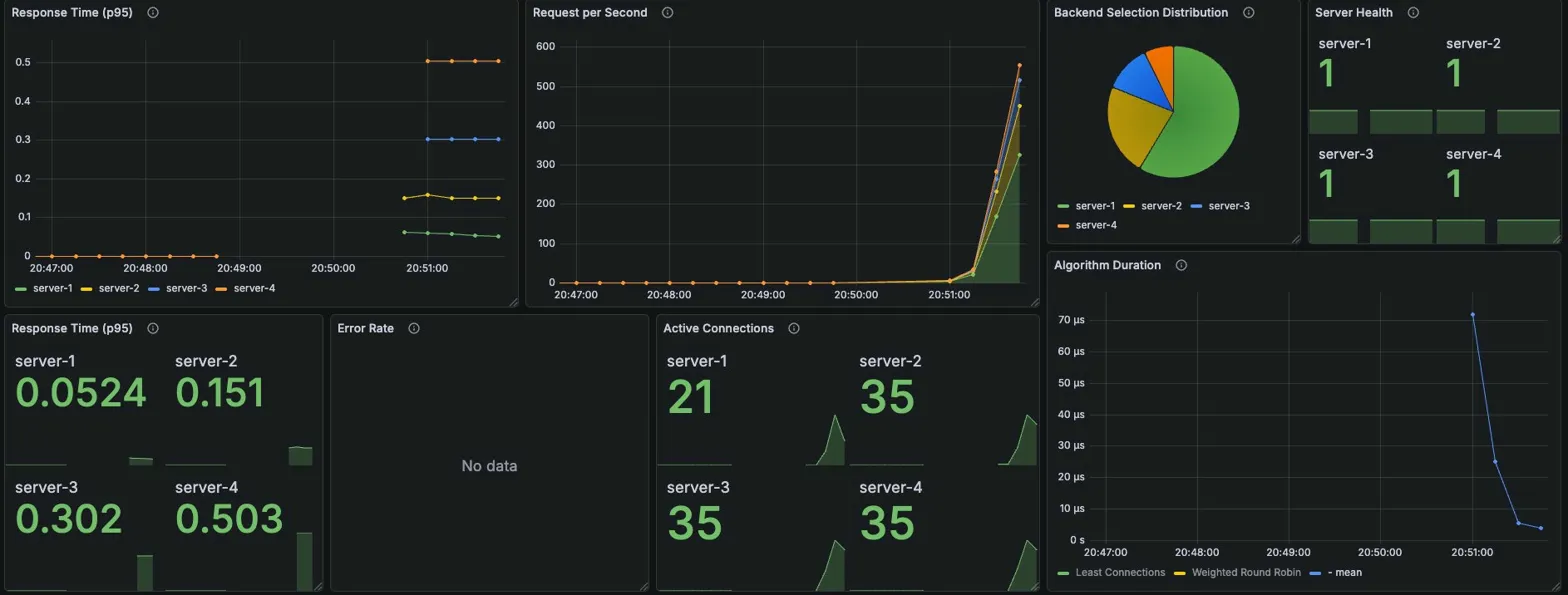
K6 결과
- 처리량
- 총 요청 수: 76,284건
- RPS: 543.9 req/s
- 응답시간
- avg: 136.8ms
- med: 53.24ms
- min: 0.182ms
- max: 561.89ms
- p90: 302.9ms
- p95: 501.88ms
- 안정성
- 에러율: 0.00%
- 모든 체크 통과
Grafana 메트릭
서버 선택 비율: server-1이 가장 큰 비율 (빠른 서버 우선 선택)
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0524 | 0.151 | 0.302 | 0.503 |
Active Connections (피크 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 21 | 35 | 35 | 35 |
→ Steady 때의 완벽한 14/14/14/14는 아니지만 여전히 균등에 가까움
Algorithm Duration: 초반 ~70μs에서 안정화 후 ~15μs로 감소
Error Rate: No data (에러 없음)
분석
LC가 burst에서도 우수한 성능을 유지:
- 초반 VU 10 구간에서 server-1 집중은 정상
- VU 10이면 server-1(50ms)이 빠르게 연결을 해제 → 항상 최소 연결 → 집중
- VU가 올라가면서 자연스럽게 분산됨
- Active Connections 비교 (피크 시점)
- RR: 9/27/54/88 → server-4 과부하
- WRR: 25/39/48/40 → 개선됨
- LC: 21/35/35/35 → 가장 균등
- Algorithm Duration 스파이크
- burst 시작 시 70μs까지 치솟았다가 안정화
- VU 급증 시 동시 접근으로 인한 일시적 경합 → 이후 안정
Ip Hash
█ TOTAL RESULTS
checks_total.......: 102426 729.490639/s
checks_succeeded...: 100.00% 102426 out of 102426
checks_failed......: 0.00% 0 out of 102426
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=253.21ms min=50.71ms med=301.06ms max=537.31ms p(90)=502.3ms p(95)=502.89ms
{ expected_response:true }...: avg=253.21ms min=50.71ms med=301.06ms max=537.31ms p(90)=502.3ms p(95)=502.89ms
http_req_failed................: 0.00% 0 out of 51213
http_reqs......................: 51213 364.74532/s
EXECUTION
iteration_duration.............: avg=353.52ms min=150.87ms med=401.22ms max=637.5ms p(90)=602.6ms p(95)=603.23ms
iterations.....................: 51213 364.74532/s
vus............................: 10 min=1 max=250
vus_max........................: 250 min=250 max=250
NETWORK
data_received..................: 7.7 MB 55 kB/s
data_sent......................: 5.5 MB 39 kB/s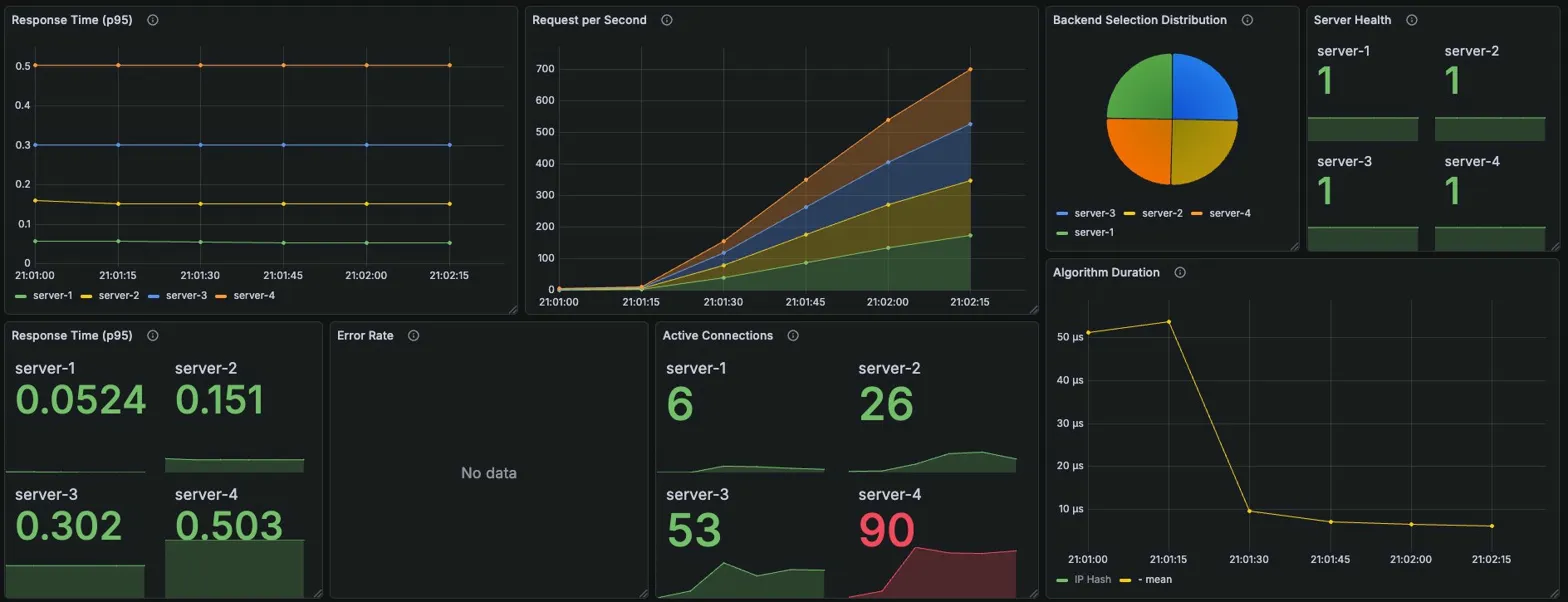
K6 결과
- 처리량
- 총 요청 수: 51,213건
- RPS: 364.7 req/s
- 응답시간
- avg: 253.21ms
- med: 301.06ms
- min: 50.71ms
- max: 537.31ms
- p90: 502.3ms
- p95: 502.89ms
- 안정성
- 에러율: 0.00%
- 모든 체크 통과
Grafana 메트릭
서버 선택 비율: 대략 균등 (해시 분포)
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0.0524 | 0.151 | 0.302 | 0.503 |
Active Connections (피크 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 6 | 26 | 53 | 90 |
→ RR(9/27/54/88)과 거의 동일. server-4에 90개로 전체 테스트 중 최악
Algorithm Duration: 초반 ~50μs에서 안정화 후 ~10μs
Error Rate: No data (에러 없음)
분석
IP Hash는 burst에서도 RR과 동일한 패턴:
- RR과 거의 모든 수치가 일치 — 랜덤 IP 해시가 균등 분배를 만들어 RR과 사실상 같은 결과
- server-4 Active Connections 90 — 전체 테스트 중 최고. burst + 균등 분배 + 느린 서버 조합이 최악의 연결 누적을 만듦
- Algorithm Duration 초반 스파이크(50μs) — burst 시작 시 대량의 새 IP에 대한 해시 계산 + 캐시 저장 비용
Consistent Hashing
█ TOTAL RESULTS
checks_total.......: 102210 727.511259/s
checks_succeeded...: 100.00% 102210 out of 102210
checks_failed......: 0.00% 0 out of 102210
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=253.92ms min=50.53ms med=301.28ms max=545.7ms p(90)=502.26ms p(95)=502.87ms
{ expected_response:true }...: avg=253.92ms min=50.53ms med=301.28ms max=545.7ms p(90)=502.26ms p(95)=502.87ms
http_req_failed................: 0.00% 0 out of 51105
http_reqs......................: 51105 363.75563/s
EXECUTION
iteration_duration.............: avg=354.22ms min=150.68ms med=401.47ms max=650.56ms p(90)=602.53ms p(95)=603.22ms
iterations.....................: 51105 363.75563/s
vus............................: 10 min=1 max=250
vus_max........................: 250 min=250 max=250
NETWORK
data_received..................: 7.7 MB 55 kB/s
data_sent......................: 5.5 MB 39 kB/s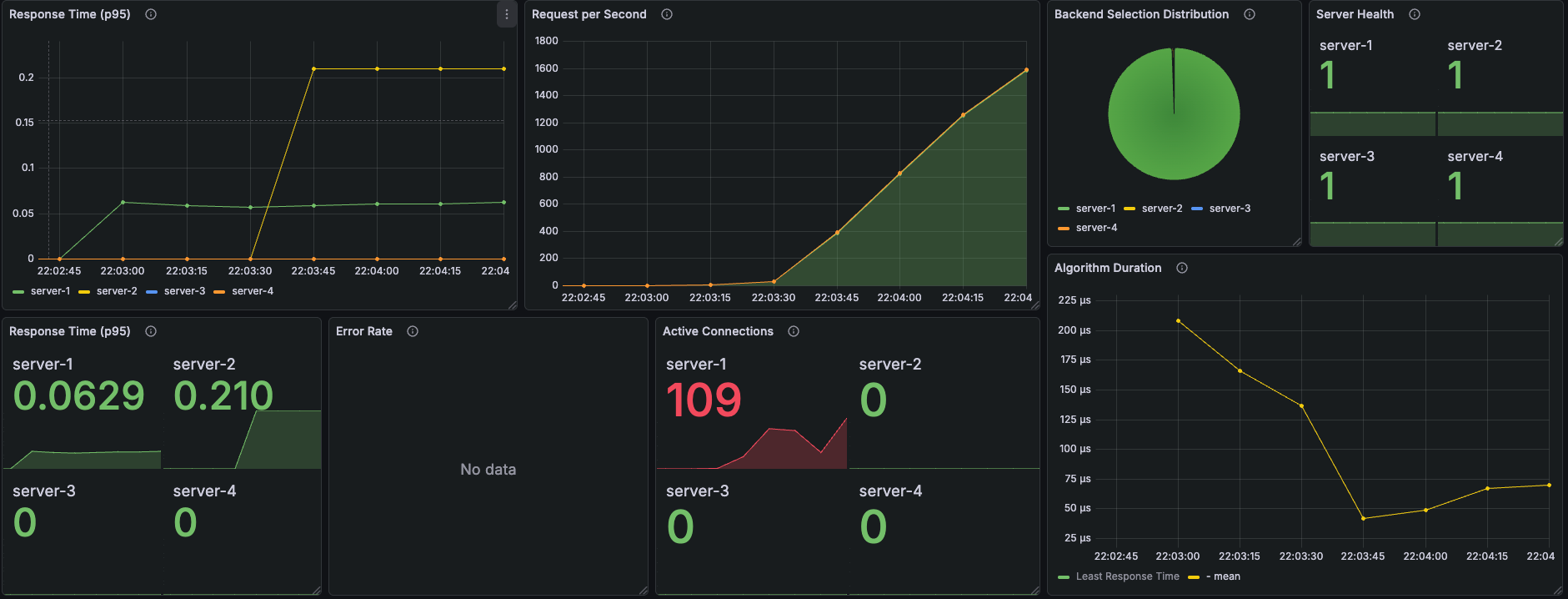
K6 결과
처리량
- 총 요청 수: 51,105건
- RPS: 363.8 req/s
응답시간
- avg: 253.92ms
- med: 301.28ms
- min: 50.53ms
- max: 545.7ms
- p90: 502.26ms
- p95: 502.87ms
안정성
- 에러율: 0.00%
- 모든 체크 통과
Grafana 메트릭
서버 선택 비율: 대략 균등 (해시 링 분포)
Active Connections (피크 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 8 | 32 | 58 | 83 |
Algorithm Duration: 초반 ~45μs에서 안정화 후 ~20μs
분석
RR, IP Hash와 거의 동일한 결과. 해시 기반 균등 분배의 한계가 동일하게 나타남.
Least Response Time
█ TOTAL RESULTS
checks_total.......: 230802 1648.251308/s
checks_succeeded...: 100.00% 230802 out of 230802
checks_failed......: 0.00% 0 out of 230802
✓ status is 200
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=56.23ms min=50.49ms med=53.67ms max=359.51ms p(90)=60.13ms p(95)=65.52ms
{ expected_response:true }...: avg=56.23ms min=50.49ms med=53.67ms max=359.51ms p(90)=60.13ms p(95)=65.52ms
http_req_failed................: 0.00% 0 out of 115401
http_reqs......................: 115401 824.125654/s
EXECUTION
iteration_duration.............: avg=156.55ms min=150.67ms med=153.98ms max=459.7ms p(90)=160.6ms p(95)=165.86ms
iterations.....................: 115401 824.125654/s
vus............................: 10 min=1 max=250
vus_max........................: 250 min=250 max=250
NETWORK
data_received..................: 17 MB 123 kB/s
data_sent......................: 12 MB 88 kB/s
K6 결과
처리량
- 총 요청 수: 115,401건
- RPS: 824.1 req/s
응답시간
- avg: 56.23ms
- med: 53.67ms
- min: 50.49ms
- max: 359.51ms
- p90: 60.13ms
- p95: 65.52ms
안정성
- 에러율: 0.00%
- 모든 체크 통과
Grafana 메트릭
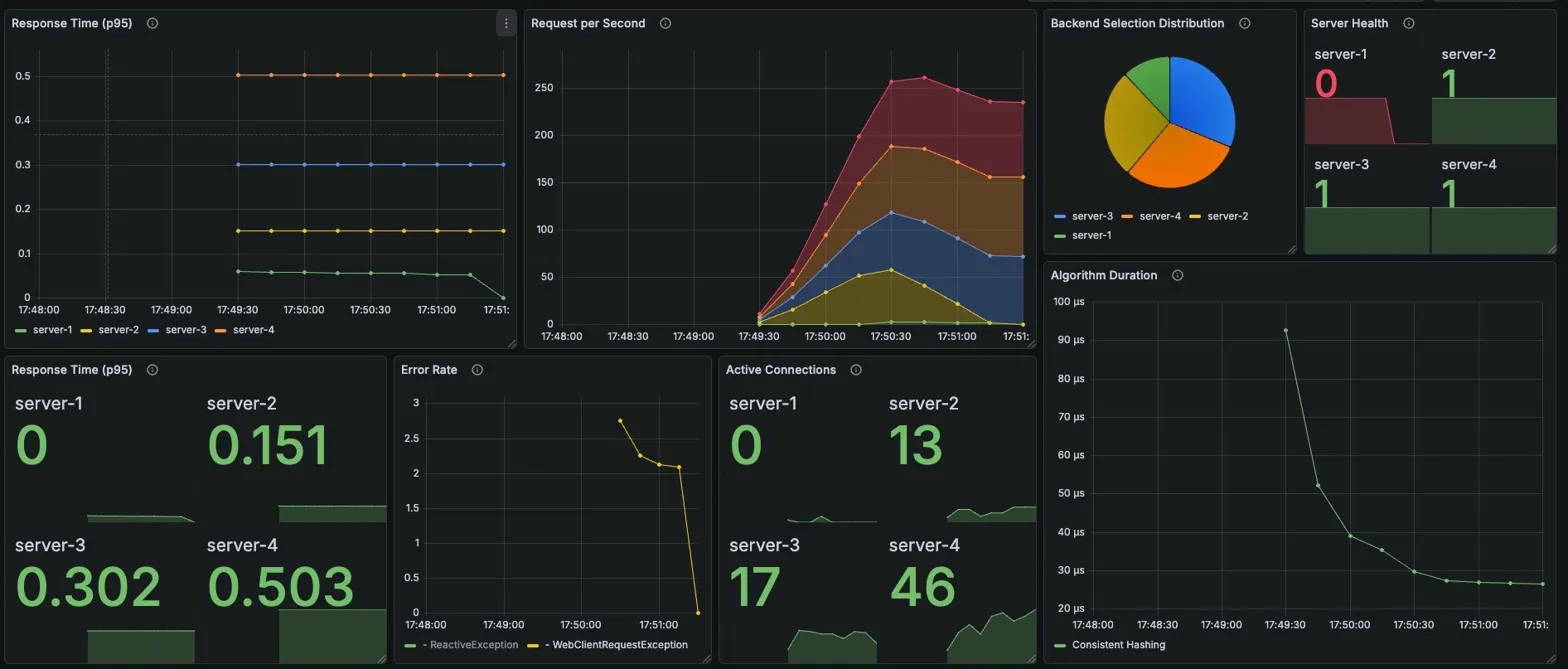
서버 선택 비율: server-1 거의 100%, server-2, server-3 약간
Active Connections (피크 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 109 | 0 | 0 | 0 |
Algorithm Duration: 초반 ~200μs에서 안정화 후 ~50μs
흥미로운 점: server-2의 p95가 0.210초 — VU가 올라가면서 잠깐 server-2로 분산된 흔적
분석
Steady보다 스노우볼 효과가 더 심해진 결과:
- VU 250에서 server-1에 109개 연결 — 단일 서버에 대한 극심한 쏠림
- server-2에 잠깐 분산된 흔적 — VU 급증 시 server-1 응답시간이 일시적으로 올라가서 server-2로 일부 전환, 하지만 곧 다시 server-1로 복귀
- Algorithm Duration 200μs — burst 시 전체 알고리즘 중 최고. 응답시간 계산 비용이 부하에 비례해서 증가
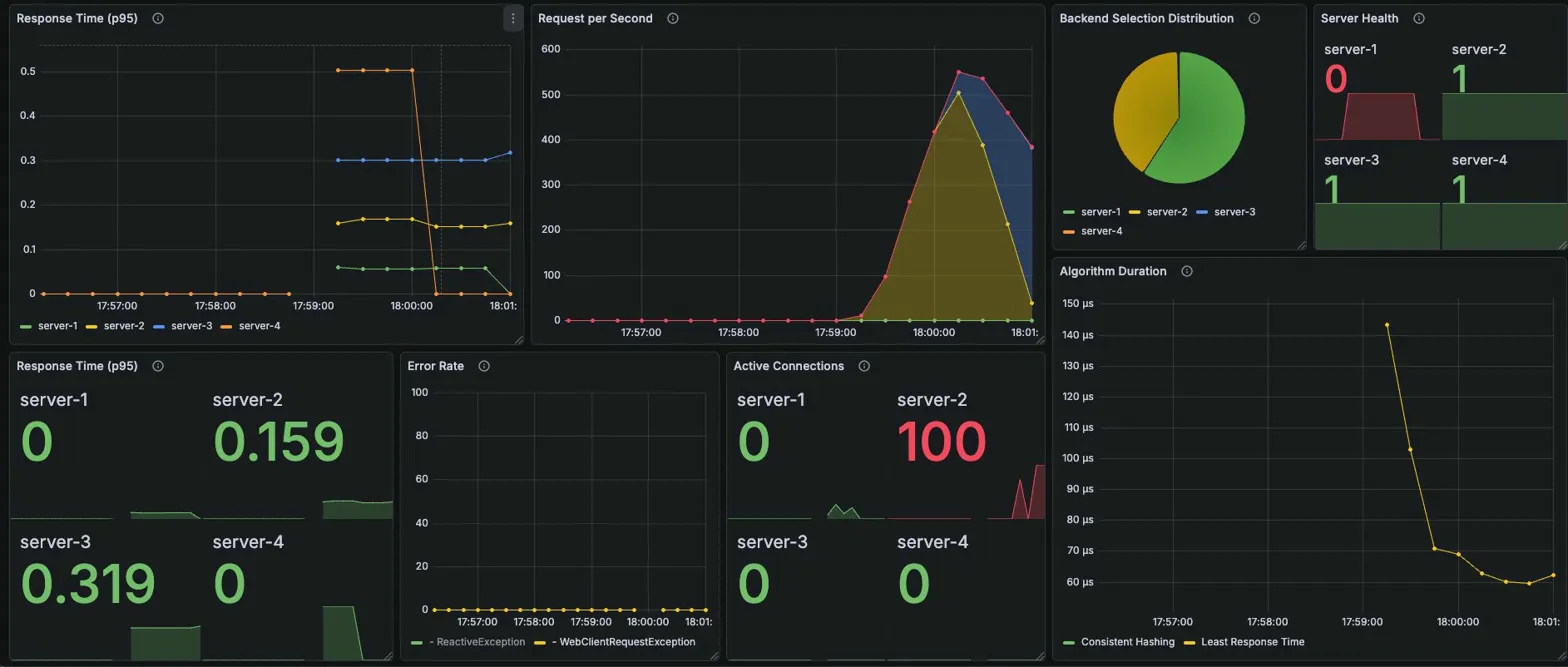
Server Failure 시나리오
테스트 조건
- 시나리오: Server Failure (server-1 다운)
- VUs: 100 (고정)
- Duration: 3분
- 장애 시점: 테스트 시작 ~1분 후
docker stop web-server-1 - Sleep: 0.1s
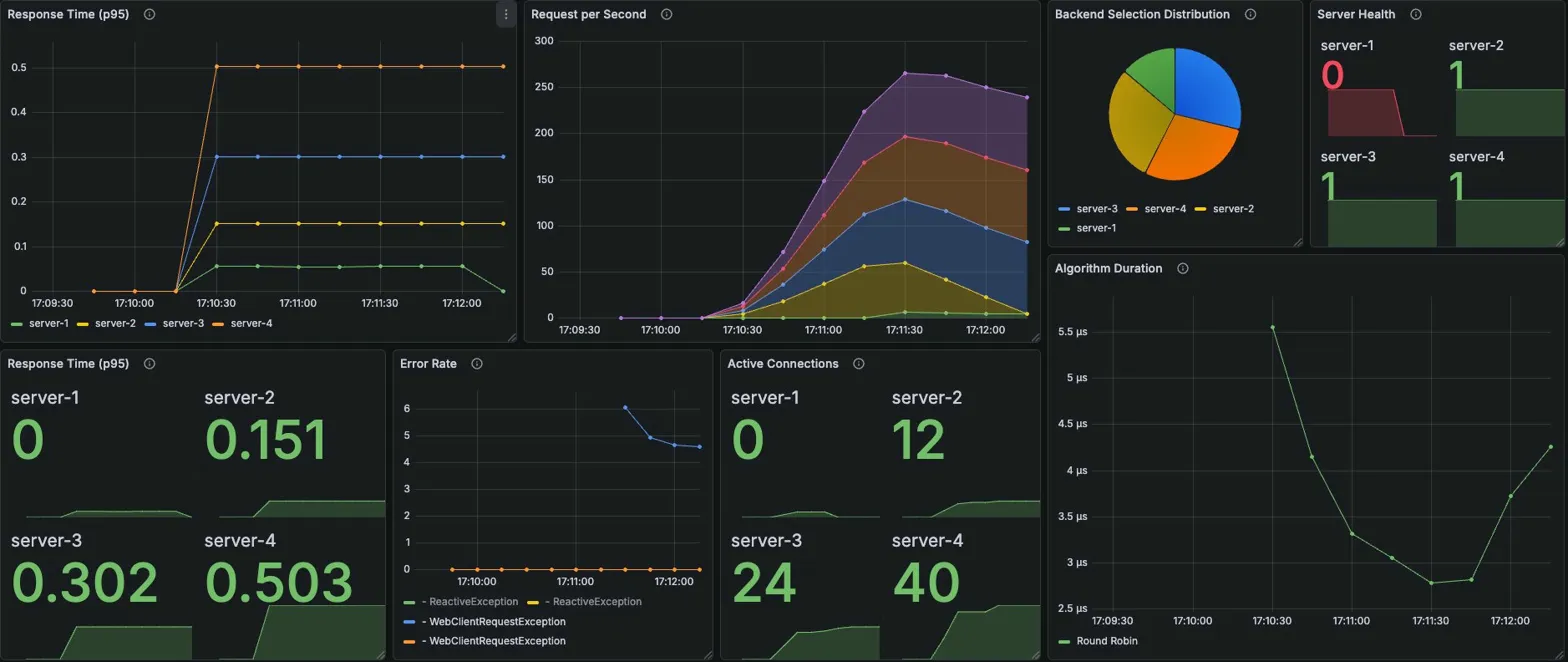
Round Robin
█ TOTAL RESULTS
checks_total.......: 82956 459.330197/s
checks_succeeded...: 99.57% 82607 out of 82956
checks_failed......: 0.42% 349 out of 82956
✗ status is 200
↳ 99% — ✓ 41133 / ✗ 345
✗ response time < 1000ms
↳ 99% — ✓ 41474 / ✗ 4
HTTP
http_req_duration..............: avg=297.94ms min=504µs med=303.28ms max=10s p(90)=505.71ms p(95)=507.46ms
{ expected_response:true }...: avg=299.45ms min=50.89ms med=303.33ms max=540.63ms p(90)=505.73ms p(95)=507.47ms
http_req_failed................: 0.83% 345 out of 41478
http_reqs......................: 41478 229.665098/s
EXECUTION
iteration_duration.............: avg=398.35ms min=100.65ms med=403.66ms max=10.1s p(90)=606.22ms p(95)=608.02ms
iterations.....................: 41478 229.665098/s
vus............................: 100 min=4 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 6.2 MB 35 kB/s
data_sent......................: 4.4 MB 25 kB/s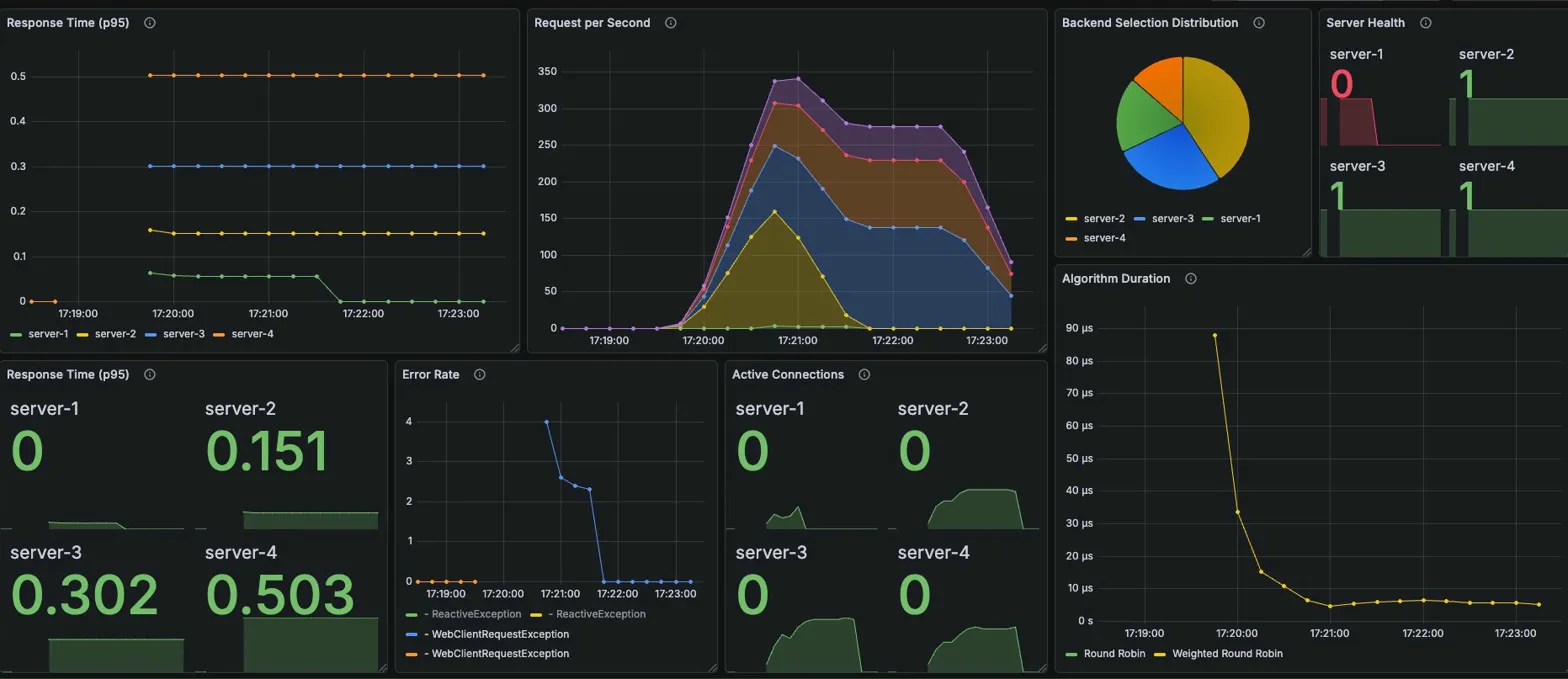
K6 결과
처리량
- 총 요청 수: 41,478건
- RPS: 229.7 req/s
응답시간
- avg: 297.94ms
- med: 303.28ms
- min: 0.504ms
- max: 10s (타임아웃)
- p90: 505.71ms
- p95: 507.46ms
안정성
- 에러율: 0.83% (345건 실패)
- status 200 체크: 99% (345건 실패)
- response time < 1000ms: 99% (4건 초과)
Grafana 메트릭
Server Health
- server-1: 0 (빨간색) — 헬스체크가 정상적으로 장애 감지
- server-2, 3, 4: 1 (정상)
서버 선택 비율 (Backend Selection Distribution)
- server-1 비율 축소, server-2/3/4로 재분배
- 파이차트에서 3개 서버 위주로 변경된 것 확인
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0 | 0.151 | 0.302 | 0.503 |
Active Connections (장애 후 안정화 시점)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0 | 12 | 24 | 40 |
→ server-1 제외 후 3개 서버로 균등 분배. 느린 서버에 연결 쌓이는 패턴 동일
Error Rate
- ReactiveException + WebClientRequestException 발생
- 장애 직후
56건/s 스파이크 후 헬스체크 이후 감소
Algorithm Duration: 35μs (RR 특성상 일정)
분석
server-1 장애의 영향이 명확히 드러난 결과:
- RPS 큰 폭 하락
- Steady: 281.9 → Server Failure: 229.7 RPS
- 가장 빠른 서버(50ms)가 빠지면서 전체 처리량 18.5% 감소
- 남은 서버(150/300/500ms)로만 처리하니 평균 응답시간도 상승
- avg 응답시간 상승
- Steady: 253.58ms → Server Failure: 297.94ms
- 빠른 서버 제거로 평균이 (150+300+500)/3 = 316ms에 수렴
- 에러 345건 = 헬스체크 5초 사이의 손실
- server-1 다운 → 헬스체크가 감지하기까지 최대 5초
- 그 사이 server-1로 간 요청들이 타임아웃(10초) 또는 즉시 실패
- 재시도 로직이 있었다면 이 에러를 줄일 수 있었을 것
- 복구 후 정상적인 3개 서버 분배
- 헬스체크 후 server-1이 제외되면서 나머지 3개 서버로 33%씩 분배
- Error Rate 그래프에서 스파이크 후 0으로 수렴하는 것 확인
Weighted Round Robin
█ TOTAL RESULTS
checks_total.......: 101396 561.458485/s
checks_succeeded...: 99.72% 101119 out of 101396
checks_failed......: 0.27% 277 out of 101396
✗ status is 200
↳ 99% — ✓ 50433 / ✗ 265
✗ response time < 1000ms
↳ 99% — ✓ 50686 / ✗ 12
HTTP
http_req_duration..............: avg=225.44ms min=418µs med=153.74ms max=10s p(90)=502.43ms p(95)=503.58ms
{ expected_response:true }...: avg=224.24ms min=50.61ms med=153.77ms max=611.47ms p(90)=502.43ms p(95)=503.58ms
http_req_failed................: 0.52% 265 out of 50698
http_reqs......................: 50698 280.729243/s
EXECUTION
iteration_duration.............: avg=325.84ms min=100.49ms med=254.21ms max=10.1s p(90)=602.81ms p(95)=604.12ms
iterations.....................: 50698 280.729243/s
vus............................: 100 min=4 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 7.6 MB 42 kB/s
data_sent......................: 5.4 MB 30 kB/s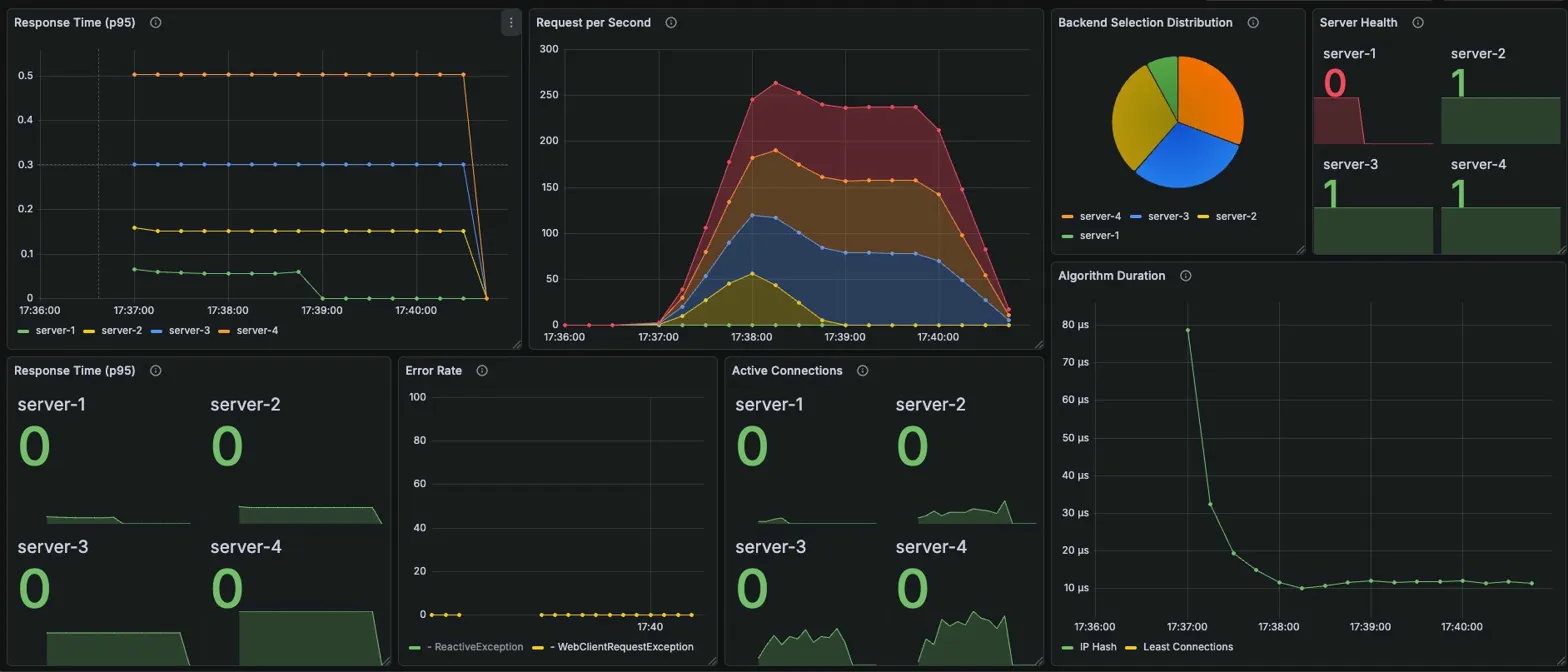
K6 결과
처리량
- 총 요청 수: 50,698건
- RPS: 280.7 req/s
응답시간
- avg: 225.44ms
- med: 153.74ms
- min: 0.418ms
- max: 10s (타임아웃)
- p90: 502.43ms
- p95: 503.58ms
안정성
- 에러율: 0.52% (265건 실패)
- status 200 체크: 99%
- response time < 1000ms: 99%
Grafana 메트릭
Server Health: server-1: 0, server-2/3/4: 1
서버 선택 비율: 장애 후 server-2/3/4로 재분배 (가중치 3:2:1 비율)
Active Connections (장애 후 안정화)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0 | 21 | 28 | 23 |
Error Rate: 장애 직후 ~4건/s 스파이크 후 감소
Algorithm Duration: 장애 직후 ~90μs 스파이크 → 안정화 후 ~30μs
분석
WRR이 RR보다 장애 대응에서 더 큰 영향을 받은 결과:
- 에러율은 RR보다 낮음
- RR: 0.83% (345건) → WRR: 0.52% (265건)
- WRR이 server-1에 50% 보내는데 에러가 적은 건 의외. connection refused가 빠르게 돌아온 덕분
- RPS 하락폭이 RR보다 큼
- RR Steady→Failure: 281.9→229.7 (18.5% 감소)
- WRR Steady→Failure: 387.4→280.7 (27.5% 감소)
- WRR이 server-1에 50% 의존했기 때문에 장애 시 충격이 더 큼
- Algorithm Duration 스파이크 (90μs)
- 장애 후 가중치 재계산 + healthy 서버 필터링 비용
- RR(~5μs)보다 훨씬 높은 일시적 오버헤드
- Active Connections 재분배
- 장애 후 21/28/23으로 분배 — 가중치 3:2:1 비율이 반영됨
- 하지만 연결 수 기준으로는 불균등 (가중치의 한계)
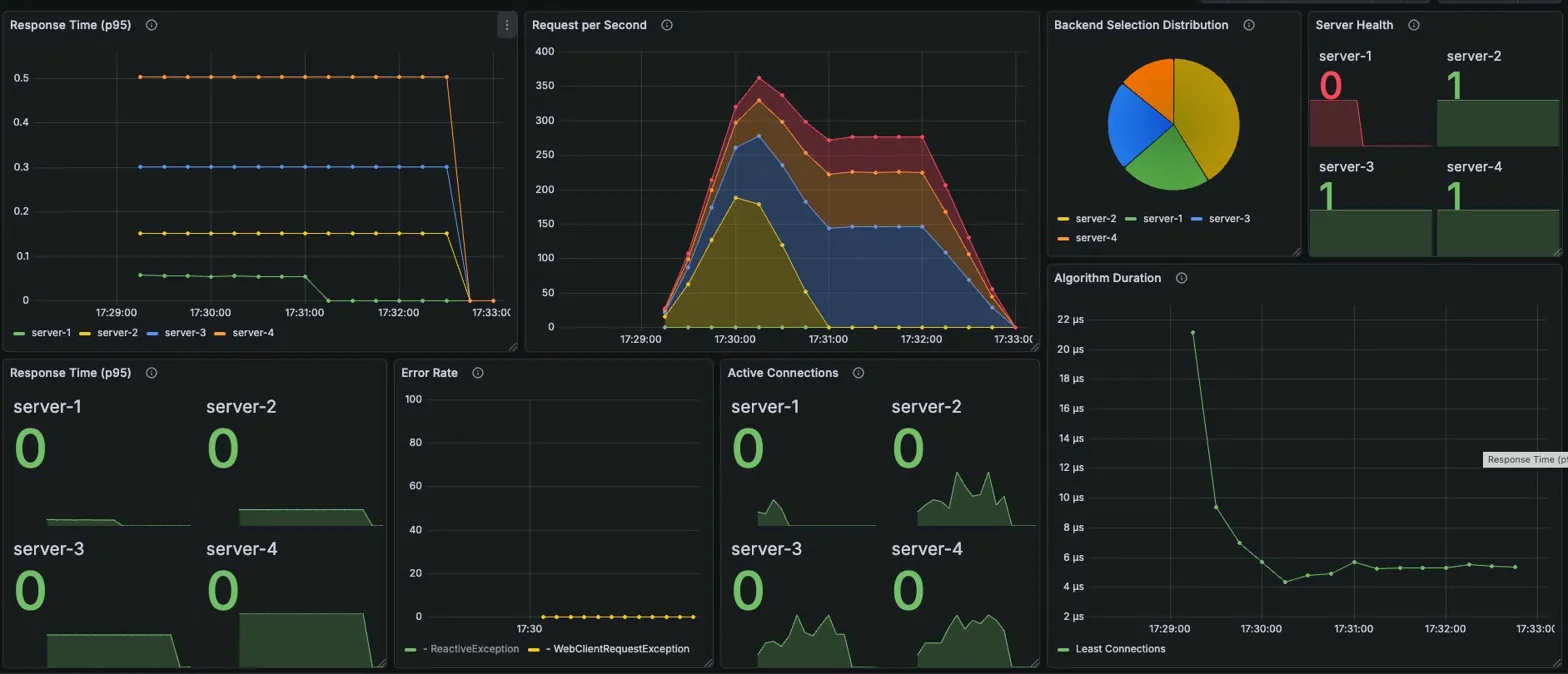
Least Connections
█ TOTAL RESULTS
checks_total.......: 104250 577.60714/s
checks_succeeded...: 99.68% 103917 out of 104250
checks_failed......: 0.31% 333 out of 104250
✗ status is 200
↳ 99% — ✓ 51806 / ✗ 319
✗ response time < 1000ms
↳ 99% — ✓ 52111 / ✗ 14
HTTP
http_req_duration..............: avg=216.46ms min=337µs med=153.58ms max=10s p(90)=502.55ms p(95)=504.02ms
{ expected_response:true }...: avg=215.08ms min=50.66ms med=153.6ms max=626.02ms p(90)=502.55ms p(95)=504.02ms
http_req_failed................: 0.61% 319 out of 52125
http_reqs......................: 52125 288.80357/s
EXECUTION
iteration_duration.............: avg=316.86ms min=100.4ms med=254.06ms max=10.1s p(90)=602.94ms p(95)=604.62ms
iterations.....................: 52125 288.80357/s
vus............................: 100 min=4 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 7.8 MB 43 kB/s
data_sent......................: 5.6 MB 31 kB/s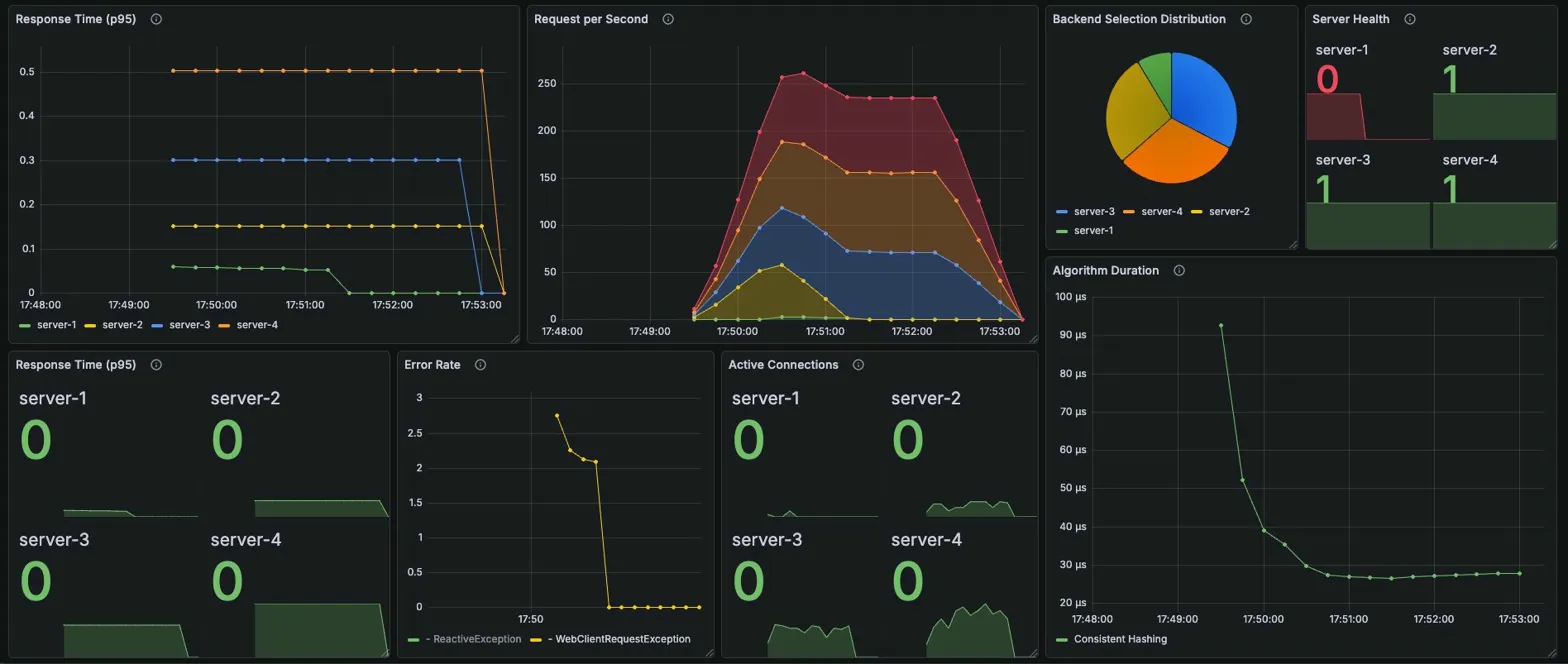
K6 결과
처리량
- 총 요청 수: 52,125건
- RPS: 288.8 req/s
응답시간
- avg: 216.46ms
- med: 153.58ms
- min: 0.337ms
- max: 10s (타임아웃)
- p90: 502.55ms
- p95: 504.02ms
안정성
- 에러율: 0.61% (319건 실패)
Grafana 메트릭
Server Health: server-1: 0, server-2/3/4: 1
Active Connections (장애 후 안정화)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0 | 17 | 18 | 27 |
→ 3개 서버 중에서도 상대적으로 균등 유지
Algorithm Duration: 장애 직후 ~22μs 스파이크 → 안정화 후 ~5μs
분석
LC가 장애 후에도 균등 분산을 유지한 결과:
- RPS 하락폭이 가장 큼
- LC Steady→Failure: 421.0→288.8 (31.4% 감소)
- server-1에 가장 많이 보내고 있었으니 당연한 결과
- 하지만 avg는 여전히 우수
- avg 216.46ms — RR(297.94ms)보다 27% 낮음
- 남은 3개 서버에서도 연결 기반 분산이 작동
- Active Connections 여전히 가장 균등
- RR: 0/12/24/40 → LC: 0/17/18/27
- server-4에 27개로 RR(40)보다 훨씬 적음
- 에러율 중간
- RR: 0.83% → WRR: 0.52% → LC: 0.61%
- LC가 server-1에 많이 보내고 있었으니 장애 시 영향이 클 수 있지만, 연결 실패 후 빠르게 다른 서버로 전환
IP Hash
█ TOTAL RESULTS
checks_total.......: 82640 457.631821/s
checks_succeeded...: 99.99% 82637 out of 82640
checks_failed......: 0.00% 3 out of 82640
✗ status is 200
↳ 99% — ✓ 41317 / ✗ 3
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=299.47ms min=1.86ms med=302.58ms max=560.73ms p(90)=503.89ms p(95)=505.16ms
{ expected_response:true }...: avg=299.49ms min=50.91ms med=302.58ms max=560.73ms p(90)=503.89ms p(95)=505.16ms
http_req_failed................: 0.00% 3 out of 41320
http_reqs......................: 41320 228.815911/s
EXECUTION
iteration_duration.............: avg=399.9ms min=102.27ms med=402.96ms max=661.15ms p(90)=604.46ms p(95)=605.75ms
iterations.....................: 41320 228.815911/s
vus............................: 100 min=4 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 6.2 MB 34 kB/s
data_sent......................: 4.4 MB 25 kB/s
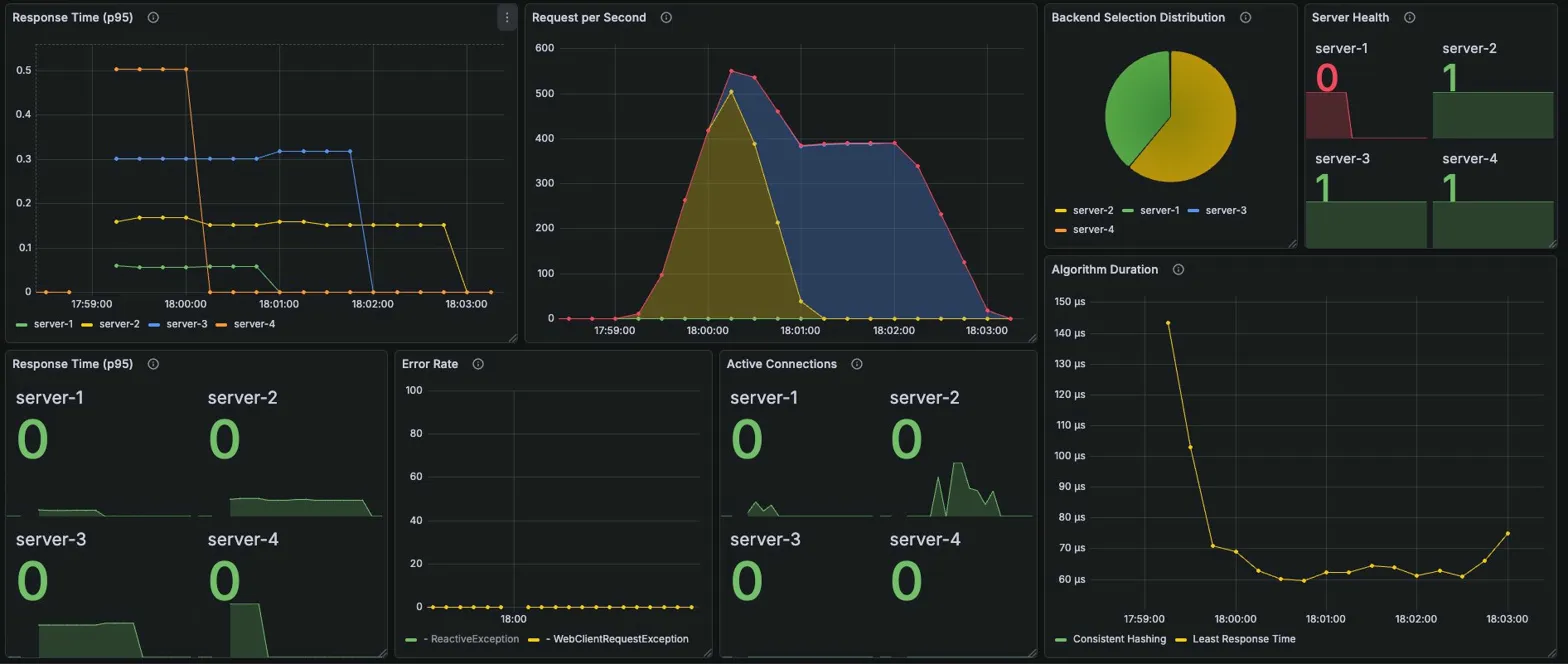
K6 결과
처리량
- 총 요청 수: 41,320건
- RPS: 228.8 req/s
응답시간
- avg: 299.47ms
- med: 302.58ms
- min: 1.86ms
- max: 560.73ms
- p90: 503.89ms
- p95: 505.16ms
안정성
- 에러율: 0.00% (3건 실패 — 사실상 0)
Grafana 메트릭
Server Health: server-1: 0, server-2/3/4: 1
Active Connections (장애 후 안정화)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0 | 12 | 25 | 41 |
→ 3개 서버로 균등 분배. RR과 유사한 패턴
Algorithm Duration: 장애 직후 ~80μs 스파이크 → 안정화 후 ~10μs
분석
IP Hash가 장애 대응에서 가장 우수한 에러율을 기록:
- 에러 3건 = 사실상 무중단
- RR: 345건, WRR: 265건, LC: 319건 vs IP Hash: 3건
ipServerMapping.compute()에서 캐시된 서버가 unhealthy면 즉시 재선택- 헬스체크 감지 전에도 connection refused → 캐시 무효화 → 재선택이 빠르게 동작한 것으로 추정
- RPS는 RR과 동일 수준
- 228.8 RPS — 3개 서버 균등 분배이므로 RR(229.7)과 거의 동일
- 세션 재배치 발생
- server-1에 매핑되어 있던 IP들이 다른 서버로 재배치
- 하지만
% 3으로 바뀌면서 기존 server-2/3/4 매핑도 일부 변경됨 (IP Hash의 단점)
- Algorithm Duration 스파이크 (80μs)
- 장애 후 대량의 캐시 무효화 + 재해싱 비용
Consistent Hashing
█ TOTAL RESULTS
checks_total.......: 82004 454.042868/s
checks_succeeded...: 99.81% 81852 out of 82004
checks_failed......: 0.18% 152 out of 82004
✗ status is 200
↳ 99% — ✓ 40852 / ✗ 150
✗ response time < 1000ms
↳ 99% — ✓ 41000 / ✗ 2
HTTP
http_req_duration..............: avg=302.49ms min=617µs med=302.61ms max=10s p(90)=503.92ms p(95)=505.16ms
{ expected_response:true }...: avg=303.1ms min=51.05ms med=302.63ms max=568.99ms p(90)=503.92ms p(95)=505.17ms
http_req_failed................: 0.36% 150 out of 41002
http_reqs......................: 41002 227.021434/s
EXECUTION
iteration_duration.............: avg=402.9ms min=100.72ms med=402.97ms max=10.1s p(90)=604.45ms p(95)=605.67ms
iterations.....................: 41002 227.021434/s
vus............................: 100 min=4 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 6.2 MB 34 kB/s
data_sent......................: 4.4 MB 24 kB/sK6 결과
처리량
- 총 요청 수: 41,002건
- RPS: 227.0 req/s
응답시간
- avg: 302.49ms
- med: 302.61ms
- min: 0.617ms
- max: 10s (타임아웃)
- p90: 503.92ms
- p95: 505.16ms
안정성
- 에러율: 0.36% (150건 실패)
Grafana 메트릭
Server Health: server-1: 0, server-2/3/4: 1
Active Connections (장애 후 안정화)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0 | 13 | 17 | 46 |
→ server-4에 쏠림. 해시 링에서 server-1의 가상 노드가 빠지면서 인접 서버(server-4)로 재배치
Algorithm Duration: 장애 직후 ~100μs 스파이크 → 안정화 후 ~30μs
Error Rate: 장애 직후 ~3건/s 피크 → 해시 링 재구성 후 감소
분석
CH가 IP Hash보다 에러율이 높은 의외의 결과:
- 에러 150건 vs IP Hash 3건
- IP Hash는 캐시 매핑에서 unhealthy 체크가 즉각적
- CH는 해시 링 재구성(
buildHashRing)이 필요해서 약간의 지연 발생 needsRebuild()→rebuildIfNeeded()→buildHashRing()과정에서 일시적으로 이전 링 사용
- Active Connections 불균등 (13/17/46)
- 해시 링에서 server-1의 150개 가상 노드가 빠지면서 인접 서버에 불균등하게 재배치
- server-4에 46개 집중 — CH의 이론적 장점(최소 재배치)이 균등 분배를 보장하진 않음
- Algorithm Duration 최고치 (100μs)
- 해시 링 재구성 비용이 반영됨
- 150개 가상 노드 × 3개 서버 = 450개 엔트리 재생성
- CH의 진짜 장점은 다른 곳에
- server-2/3/4에 매핑된 클라이언트들은 서버가 안 바뀜 (최소 재배치)
- IP Hash는
% 3으로 바뀌면서 기존 매핑이 전부 깨짐 - 세션 유지 관점에서는 CH가 우수하지만, 이 테스트에서는 측정 안 됨
Least Response Time
█ TOTAL RESULTS
checks_total.......: 152166 844.848188/s
checks_succeeded...: 99.98% 152143 out of 152166
checks_failed......: 0.01% 23 out of 152166
✗ status is 200
↳ 99% — ✓ 76060 / ✗ 23
✓ response time < 1000ms
HTTP
http_req_duration..............: avg=116.42ms min=17.77ms med=153.26ms max=519.3ms p(90)=156.87ms p(95)=158.39ms
{ expected_response:true }...: avg=116.45ms min=50.61ms med=153.26ms max=519.3ms p(90)=156.87ms p(95)=158.39ms
http_req_failed................: 0.03% 23 out of 76083
http_reqs......................: 76083 422.424094/s
EXECUTION
iteration_duration.............: avg=216.91ms min=118.96ms med=253.75ms max=620.6ms p(90)=257.41ms p(95)=258.9ms
iterations.....................: 76083 422.424094/s
vus............................: 100 min=4 max=100
vus_max........................: 100 min=100 max=100
NETWORK
data_received..................: 11 MB 63 kB/s
data_sent......................: 8.2 MB 45 kB/sK6 결과
처리량
- 총 요청 수: 76,083건
- RPS: 422.4 req/s
응답시간
- avg: 116.42ms
- med: 153.26ms
- min: 17.77ms
- max: 519.3ms
- p90: 156.87ms
- p95: 158.39ms
안정성
- 에러율: 0.03% (23건 실패)
Grafana 메트릭
Server Health: server-1: 0, server-2/3/4: 1
서버 선택 비율: 장애 전 server-1 거의 100% → 장애 후 server-2에 집중
Active Connections (장애 후)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0 | 100 | 0 | 0 |
→ 스노우볼 효과가 server-2로 그대로 이동!
서버별 P95 응답시간 (초)
| server-1 | server-2 | server-3 | server-4 |
|---|---|---|---|
| 0 | 0.159 | 0.319 | 0 |
→ server-2(150ms)가 새로운 "가장 빠른 서버"로 트래픽 독점
Algorithm Duration: 60150μs
분석
예상과 다른 결과 — LRT가 의외로 잘 동작한 것처럼 보이지만 근본 문제는 동일:
- 에러율 0.03% (23건) — IP Hash(3건) 다음으로 우수
- server-1에 100% 집중 → 장애 시 모든 요청 실패할 것으로 예상했지만
- connection refused가 즉시 돌아오면서 빠르게 다른 서버로 전환
- LRT가 응답시간 데이터를 기반으로 server-2를 즉시 선택
- RPS 422.4 — Server Failure 테스트 중 최고!
- 장애 전: server-1(50ms)으로 ~640 RPS
- 장애 후: server-2(150ms)로 ~422 RPS
- 여전히 다른 알고리즘보다 높음 — 단일 서버 집중이 오히려 처리량을 높이는 역설
- 스노우볼 효과가 server-2로 이전
- server-1 → server-2로 "가장 빠른 서버" 타이틀만 바뀜
- Active Connections server-2: 100, 나머지: 0
- 로드밸런싱이 아니라 단일 서버 자동 전환에 불과
- p95가 158ms로 매우 낮은 이유
- server-2(150ms)만 사용하니까 p95도 ~150ms 근처
- 다른 알고리즘은 3개 서버 사용 → server-4(500ms)가 p95를 올림
마치며
Burst와 Server Failure를 돌리고 나서 느낀 것들:
Burst에서 RR, IP Hash, CH는 사실상 동일했다. 셋 다 균등 분배 계열이라 트래픽이 늘어도 패턴이 변하지 않는다. 차이라면 server-4의 연결 누적 정도뿐이고, IP Hash가 burst 초반 캐시 저장 비용으로 오버헤드가 잠깐 치솟는 정도다.
WRR과 LC는 Burst에서도 Steady와 거의 동일한 avg를 유지했다. 부하가 올라가도 알고리즘 특성이 흔들리지 않았다. WRR은 가중치 비율대로 Active Connections도 스케일링됐고, LC는 여전히 균등에 가까운 연결 수를 보여줬다.
Server Failure에서 가장 인상적인 건 IP Hash였다. 에러 3건. 처음에는 의외였는데 이유를 보면 납득이 된다. compute()로 원자적으로 캐시 확인 + 재선택이 이루어지기 때문에 unhealthy 서버로 한 번 실패하면 즉시 캐시를 무효화하고 다른 서버를 선택한다. 헬스체크를 기다리지 않고 스스로 빠르게 우회한 것.
WRR은 서버 의존도가 높은 만큼 장애 충격도 컸다. server-1에 50% 보내는 전략이 정상 상황에서는 최적이지만, 그 서버가 죽으면 그만큼 충격도 크다. 가중치가 높은 서버일수록 단일 장애점이 된다는 점을 고려해야 한다.
Consistent Hashing의 Active Connections 불균등(13/17/46)은 이론과 실제의 차이를 보여준다. 이론적으로 최소 재배치를 보장하지만, "최소 재배치"가 "균등 재배치"를 의미하진 않는다. server-1의 150개 가상 노드가 빠지면서 그 구간을 담당하던 트래픽이 인접 서버(server-4)로 몰렸다. CH의 진짜 장점은 기존에 server-2/3/4에 매핑된 클라이언트는 서버가 바뀌지 않는다는 것인데, 이 테스트에서는 그 부분을 측정하지 못했다.
Least Response Time은 쏠림 현상이 단점이자 장점이었다. Steady에서는 server-1이 모든 연결을 독점하는 문제가 있었지만, Server Failure에서는 server-1이 죽자마자 "다음으로 빠른 서버"인 server-2로 즉시 전환해서 에러가 23건에 그쳤다. 응답시간 데이터를 실시간으로 보고 있기 때문에 적응도 빠르다. 다만 새로운 서버도 결국 독점 상태가 된다는 점은 변하지 않는다.
다음 편에서는 3가지 시나리오 전체 결과를 종합해서 알고리즘별 특성과 적합한 사용 환경을 정리한다.
