lab
1.로드밸런싱 알고리즘 성능 비교 연구[1]

로드밸런싱 알고리즘서능 비교 연구1 - 연구 동기와 전체 로드맵
2.로드밸런싱 알고리즘 성능 비교 연구[2]
로드밸런싱 개념 정복, 필요한 이유, 수직적 확장 vs 수평적 확장, 로드밸런싱의 개념, 분류, 필요성, 구현계획에 대한 내용을 담고 있습니다
3.로드밸런싱 알고리즘 성능 비교 연구[3]
프로그램 개발시 로컬에서는 돌아가지만 서버에서는 안되는 경우가 빈번하게 발생합니다 개발자의 로컬환경과 운영 서버의 환경이 달라서 발생하는 문제입니다 그렇다면 개발 환경을 통째로 박스에 담아서 가져갈 수 있다면? ⇒ 그 박스가 바로 Docker입니다
4.로드밸런싱 알고리즘 성능 비교 연구[4]

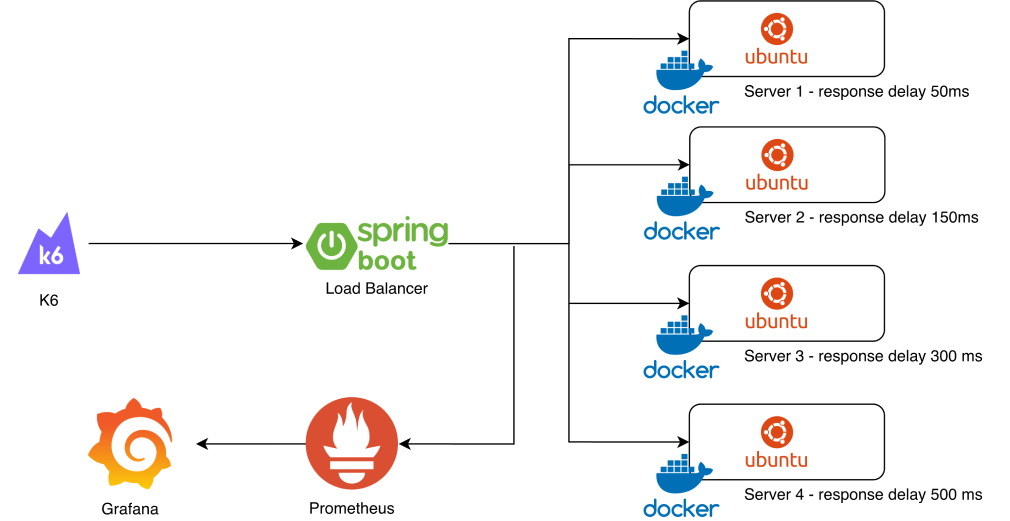
이제 실제로 로드밸런싱 테스트를 위한 4개의 웹서버를 Docker로 구축해보겠습니다각 서버는 서로 다른 성능 특성을 가지도록 설정하여 나중에 로드밸런싱 알고리즘들의 성능을 명확하게 비교할 수 있도록 만들 예정입니다.
5.로드밸런싱 알고리즘 성능 비교 연구[5]
이론은 충분히 했으니, 이제 진짜로 만들어보자.4편에서 Round Robin부터 Least Response Time까지 6가지 알고리즘의 원리를 공부했다.이번 편에서는 Spring Boot로 실제 동작하는 로드밸런서를 구현한다.
6.로드밸런싱 알고리즘 성능 비교 연구[6]
5편에서 Round Robin과 Weighted Round Robin을 구현하면서 동시성 제어의 기본기를 익혔다. 이번 편은 좀 더 복잡한 4가지 알고리즘이다. 각각 동시성을 다루는 방식이 다른데, 그 차이에 집중하면서 읽으면 좋다.
7.로드밸런싱 알고리즘 성능 비교 연구[7]
로드밸런서에서 진짜 중요한 건 **어떤 알고리즘이 어떤 상황에서 얼마나 잘 분산하는가**를 수치로 보는 것이다. 이번 편에서는 Prometheus + Grafana 모니터링 스택을 올리고, K6로 첫 번째 부하 테스트를 돌린 결과를 분석한다.
8.로드밸런싱 알고리즘 성능 비교 연구[8]
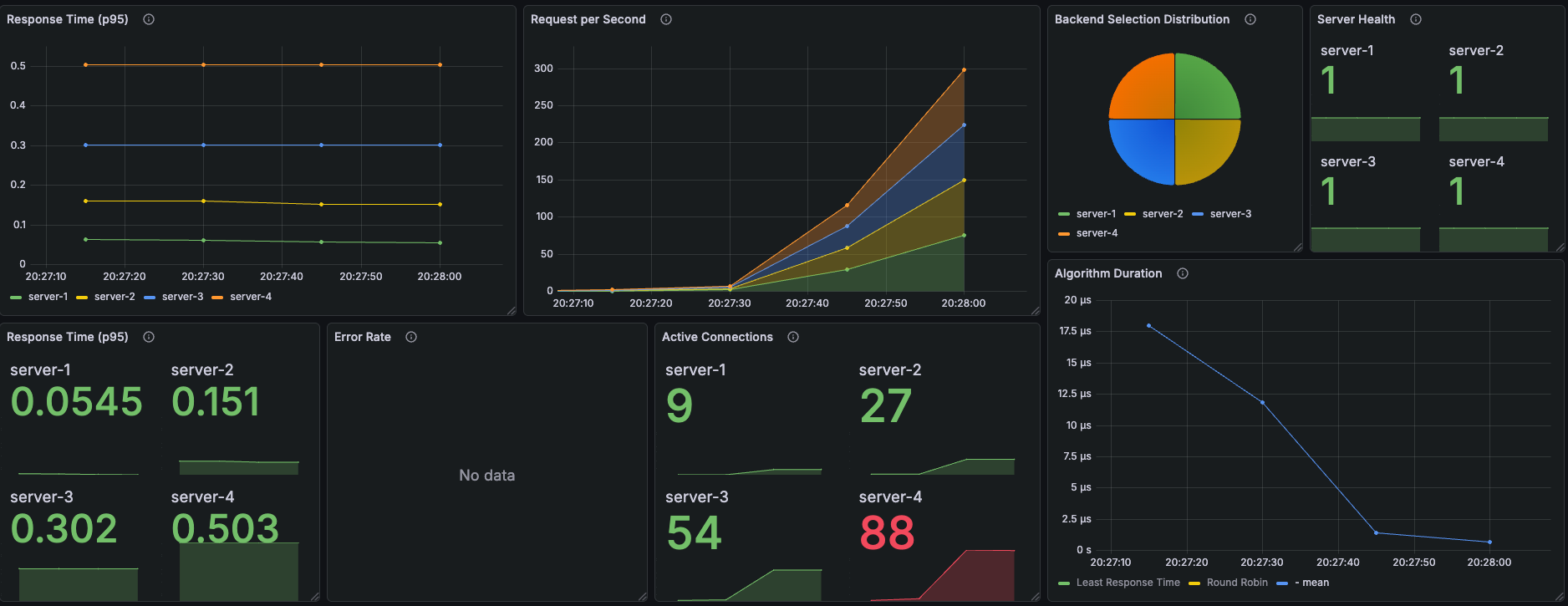
Burst: VU를 10 → 250으로 급격하게 올렸다가 다시 내린다. 트래픽 폭증 상황에서 각 알고리즘이 어떻게 반응하는지 본다. Server Failure: 테스트 도중 server-1을 강제로 종료한다. 헬스체크가 감지하기 전까지 얼마나 에러가 나는지, 확인한다.
9.로드밸런싱 알고리즘 성능 비교 연구[9]
이론, 구현, 테스트까지 끝났다. 이제 데이터로 정리하자.지금까지 6가지 알고리즘을 구현하고 3가지 시나리오로 테스트했다. 이번 편에서는 모든 결과를 한곳에 모아서 알고리즘별 특성을 정리하고, 어떤 상황에 어떤 알고리즘을 써야 하는지 결론을 낸다.
10.로드밸런싱 알고리즘 성능 비교 연구[10] -Adaptive Load Balancer
"최적 알고리즘은 하나가 아니다"는 걸 데이터로 확인했다. 그럼 상황에 따라 자동으로 바꾸면 되지 않을까?지난 편에서 6가지 알고리즘을 실측 벤치마크했을 때 얻은 결론은 이거였다.
11.로드밸런싱 알고리즘 성능 비교 연구[11] - Adaptive Load Balancer
GPT-4o가 벤치마크 데이터를 보고 rule을 자동으로 만들면, 과연 성능이 좋아질까?8편에서 Runtime 설계를 끝냈다. 이번 편은 AI Feedback Loop가 실제로 어떻게 동작하는지, 그리고 결과가 어땠는지다.