9편: 6가지 로드밸런싱 알고리즘 — 3가지 시나리오 결과 종합
이론, 구현, 테스트까지 끝났다. 이제 데이터로 정리하자.
지금까지 6가지 알고리즘을 구현하고 3가지 시나리오로 테스트했다. 이번 편에서는 모든 결과를 한곳에 모아서 알고리즘별 특성을 정리하고, 어떤 상황에 어떤 알고리즘을 써야 하는지 결론을 낸다.
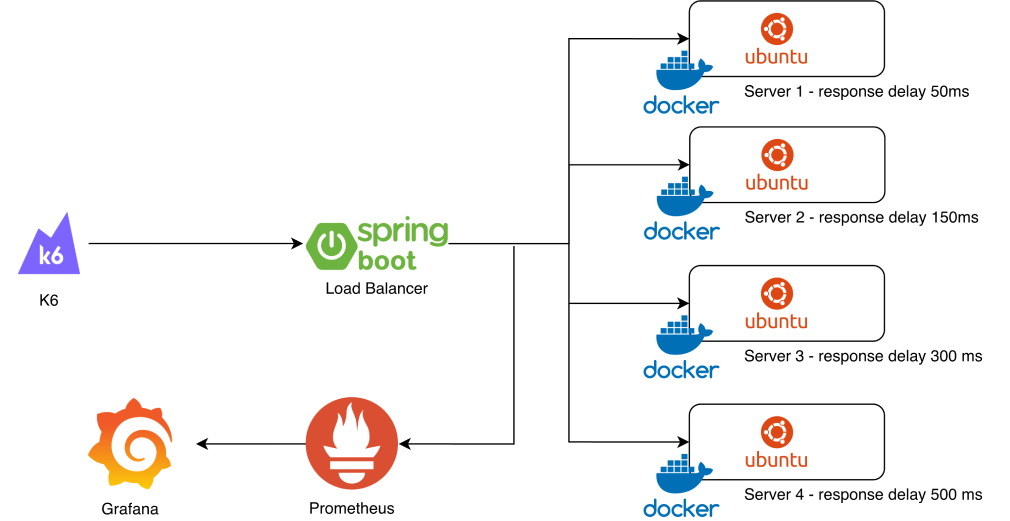
테스트 환경
- 로드밸런서: Spring Boot (로컬, 포트 8080)
- 백엔드 서버: Docker 컨테이너 4대 (포트 5001~5004)
- 서버 응답 지연: server-1(50ms) / server-2(150ms) / server-3(300ms) / server-4(500ms)
- 모니터링: Prometheus + Grafana (커스텀 메트릭 8개)
- 부하 테스트: K6
1. 시나리오 요약
Steady Load: VU 100 고정, 3분. 알고리즘의 기본 성능과 분산 패턴을 측정한다.
Burst: VU 10 → 250 → 10 (2분 20초). 급격한 부하 변화에 대한 대응력을 본다.
Server Failure: VU 100 고정, 3분 중 1분 시점에 server-1을 강제 종료한다. 헬스체크 주기는 5초로 설정했다.
2. 성능 비교 종합
Steady Load
| 알고리즘 | RPS | avg (ms) | med (ms) | Active Conn 분포 | Algo Duration |
|---|---|---|---|---|---|
| Round Robin | 281.9 | 253.6 | 254.0 | 4/11/22/36 | 600ns |
| Weighted RR | 387.4 | 157.1 | 129.3 | 6/14/18/16 | 4.5μs |
| Least Connections | 421.0 | 136.6 | 53.4 | 14/14/14/14 | 3.2μs |
| IP Hash | 281.9 | 253.6 | 301.3 | 2/13/19/32 | 11.3μs |
| Consistent Hashing | 279.5 | 256.6 | 302.0 | 유사 패턴 | 30.8μs |
| Least Response Time | 640.4* | 55.7* | 52.0* | 35/0/0/0 | 46μs |
*LRT는 server-1에 트래픽 100% 집중 — 사실상 단일 서버 운영
Burst (VU 10→250→10)
| 알고리즘 | RPS | avg (ms) | server-4 최대 연결 수 |
|---|---|---|---|
| Round Robin | 365.0 | 252.6 | 88 |
| Weighted RR | 500.7 | 157.1 | 40 |
| Least Connections | 543.9 | 136.8 | 35 |
| IP Hash | 364.7 | 253.2 | 90 |
| Consistent Hashing | 363.8 | 253.9 | 83 |
| Least Response Time | 824.1* | 56.2* | 0 (server-1: 109) |
Server Failure (server-1 다운)
| 알고리즘 | RPS | avg (ms) | 에러 건수 | RPS 하락폭 |
|---|---|---|---|---|
| Round Robin | 229.7 | 297.9 | 345건 | -18.5% |
| Weighted RR | 280.7 | 225.4 | 265건 | -27.5% |
| Least Connections | 288.8 | 216.5 | 319건 | -31.4% |
| IP Hash | 228.8 | 299.5 | 3건 | -18.8% |
| Consistent Hashing | 227.0 | 302.5 | 150건 | -18.8% |
| Least Response Time | 422.4* | 116.4* | 23건 | -34.0% |
3. 알고리즘별 분석
Round Robin — 기준점
모든 서버에 25%씩 균등하게 분배한다. 구현이 단순하고 예측 가능하다는 게 장점이다.
문제는 서버 성능을 전혀 고려하지 않는다는 것이다. server-4(500ms)에도 동일한 비율로 요청을 보내기 때문에 Active Connections가 4/11/22/36으로 불균형하게 쌓인다. Burst 시에는 server-4에 88개까지 치솟는다.
장애 대응은 전적으로 헬스체크에 의존한다. 헬스체크 주기(5초) 동안 다운된 서버로 요청을 계속 보내서 345건 에러가 발생했다.
Weighted Round Robin — 정적 최적화
가중치(6:3:2:1)를 통해 빠른 서버에 더 많은 요청을 할당한다. RR 대비 RPS 37% 증가, avg 38% 감소를 달성했다. Burst에서도 Steady와 거의 동일한 avg를 유지했고, Active Connections도 가중치 비율에 맞게 스케일링됐다.
단점은 가중치가 고정이라는 것이다. 서버 상태가 변해도 반응하지 못한다. 그리고 server-1에 50% 의존하고 있었기 때문에 장애 시 RPS 하락폭(27.5%)이 RR(18.5%)보다 크다. 가중치가 높은 서버일수록 단일 장애점이 된다는 점을 고려해야 한다.
Least Connections — 실질적 최고 성능
현재 활성 연결 수가 가장 적은 서버를 선택한다. 빠른 서버가 연결을 빨리 해제하므로 자연스럽게 더 많은 요청을 처리하는 동적 가중치 효과가 생긴다. 수동으로 가중치를 설정하지 않아도 서버 성능에 따라 자동으로 분산 비율이 조정된다.
Steady 기준 RPS 421.0 / avg 136.6ms / Active Connections 14:14:14:14로 세 항목 모두 가장 좋은 결과를 냈다. Burst에서도 server-4 최대 연결 수가 35개로 가장 낮았다.
다만 server-1에 가장 많이 보내고 있었기 때문에 장애 시 RPS 하락폭이 31.4%로 가장 크다. 그래도 남은 3개 서버에서의 분산은 여전히 균등(17/18/27)하게 유지됐다.
IP Hash — 장애 대응 최우수
클라이언트 IP를 해시해서 고정 서버에 매핑한다. 성능은 RR과 동일한 수준이지만, 장애 대응에서 에러 3건으로 사실상 무중단을 달성했다.
이유는 ipServerMapping.compute()에 있다. 해당 키에 락을 걸고 캐시 확인 + 재선택을 원자적으로 처리하기 때문에, unhealthy 서버로 한 번 실패하면 즉시 캐시를 무효화하고 다른 서버를 선택한다. 헬스체크 주기를 기다리지 않고 connection refused 시점에 바로 우회한다.
단, 서버 수가 변경되면(% 4 → % 3) 기존 IP 매핑이 전부 깨진다는 한계가 있다. 이 부분이 Consistent Hashing과의 차이다.
Consistent Hashing — 최소 재배치
해시 링 기반으로 클라이언트를 서버에 매핑한다. 성능은 IP Hash와 유사하지만, 장애 시 에러 150건으로 IP Hash(3건)보다 높았다. 해시 링 재구성(needsRebuild → rebuildIfNeeded → buildHashRing) 과정에서 일시적으로 이전 링을 사용하는 구간이 있기 때문이다.
장애 후 Active Connections가 13/17/46으로 server-4에 쏠렸는데, server-1의 가상 노드 150개가 빠지면서 인접 서버에 불균등하게 재배치된 결과다. "최소 재배치"가 "균등 재배치"를 의미하지는 않는다.
CH의 진짜 가치는 이 테스트에서 직접 드러나지 않았다. 서버 추가/제거 시 기존 클라이언트 매핑이 유지된다는 것이 핵심인데, server-2/3/4에 매핑된 클라이언트는 server-1이 죽어도 자신의 서버가 바뀌지 않는다. 대규모 캐시나 세션 환경에서 서버 변동이 자주 일어날 때 빛을 발한다.
Least Response Time — 쏠림 현상 발견
실측 응답시간 기반으로 가장 빠른 서버를 선택한다. 수치는 압도적이었다. Steady 기준 RPS 640.4, avg 55.7ms.
하지만 치명적인 문제가 있다. server-1(50ms)에 트래픽이 100% 집중되어 Active Connections가 35/0/0/0이 됐다. 나머지 서버 3대는 놀고 있는 것이다. 이는 로드밸런싱이 아니라 단일 서버 자동 선택에 불과하다.
이 쏠림 현상의 메커니즘은 이렇다. server-1이 가장 빠르므로 모든 요청이 집중된다 → 부하가 쌓여도 server-1이 여전히 다른 서버(150ms/300ms/500ms)보다 빠르다 → 계속 집중된다 → 반복. 가장 빠른 서버가 서버가 죽을 만큼 느려지지 않는 한 다른 서버로 분산되지 않는다.
Server Failure에서는 이 쏠림이 server-2로 그대로 이전됐다. Active Connections가 0/100/0/0. 알고리즘 특성이 해결된 게 아니라 대상 서버만 바뀐 것이다.
실제로 쓰려면 응답시간 × 활성연결수 복합 점수 도입, 또는 최소 트래픽 보장(floor) 설정이 필요하다.
4. 핵심 발견
"연결 수 균등 = 성능 최적"이었다. LC가 Active Connections를 균등하게 유지하면서 가장 높은 RPS를 달성했다. 응답시간을 직접 측정하지 않아도, 연결 수 기반 분산이 동적 가중치 효과를 자연스럽게 만들어낸다.
p95는 알고리즘 차이를 반영하지 않는다. 모든 알고리즘에서 p95가 ~502ms로 수렴했다. 어떤 알고리즘이든 server-4(500ms)로 가는 요청이 존재하기 때문이다. 알고리즘 간 차이는 avg, med, RPS에서 드러난다.
Burst는 Steady의 특성을 그대로 증폭했다. RR의 느린 서버 연결 누적(36→88), LRT의 쏠림(35→109)이 비례적으로 늘어났다. 새로운 패턴이 발견되지 않고 기존 특성이 확대됐다.
에러율과 성능은 별개 차원이다. IP Hash가 성능에서는 RR과 동일하지만, 장애 에러율에서는 345건 vs 3건으로 극적인 차이를 보였다. 알고리즘을 선택할 때 성능뿐 아니라 장애 복원력을 별도로 평가해야 한다.
5. 동시성 제어 설계
알고리즘 구현에서 synchronized 대신 락프리(lock-free) 기반으로 설계했다.
| 구조 | 적용 위치 | 선택 이유 |
|---|---|---|
| AtomicInteger (CAS) | RR/WRR 인덱스 | 단일 카운터 원자적 증가 |
| volatile | 서버 리스트 참조 | 변경 즉시 다른 스레드에 가시 |
| ConcurrentHashMap | IP Hash 캐시 | 키별 독립 락으로 경합 최소화 |
| ConcurrentSkipListMap | CH 해시 링 | 정렬 구조에서 동시 접근 |
| ThreadLocal | MD5 인스턴스 | 스레드별 독립 인스턴스로 경합 제거 |
| Copy-on-Write | 서버 리스트 변경 | 읽기 빈도가 쓰기보다 압도적인 구조 |
성능 검증 결과, VU 400 / 8900 RPS 환경에서 synchronized 버전과 락프리 버전의 성능 차이는 3% 이내(오차 범위)였다. WebClient.block()이 백엔드 응답을 기다리는 동안 네트워크 I/O가 병목이어서, 알고리즘 선택 구간(나노~마이크로초)의 경합이 전체 응답시간(밀리초)에 미치는 영향이 0.01% 미만이기 때문이다.
그럼에도 락프리를 선택한 이유가 있다. Nginx 같은 프로덕션 로드밸런서는 non-blocking 이벤트 루프 기반이라 알고리즘 선택 로직이 실제 병목이 될 수 있다. Spring WebFlux(Netty)로 전환할 경우 락프리 설계의 효과가 유의미하게 드러날 것이다.
6. 상황별 알고리즘 선택 가이드
| 상황 | 추천 | 이유 |
|---|---|---|
| 서버 스펙 동일, 빠른 구현 | Round Robin | 구현 단순, 균등 분배 |
| 서버 성능 차이가 크고 예측 가능 | Weighted RR | 정적 가중치로 처리량 37% 향상 |
| 범용 웹 서비스, 최고 성능 | Least Connections | RPS/응답시간/분산 균등성 모두 우수 |
| 세션 유지 + 장애 에러 최소화 | IP Hash | 에러 3건, 즉각적 장애 우회 |
| 세션 유지 + 서버 자주 변동 | Consistent Hashing | 서버 변경 시 기존 매핑 유지 |
| 응답속도 극한 최적화 | Least Response Time | 쏠림 방지 로직 추가 전제 |
마치며
이 프로젝트를 시작할 때 목표는 단순했다. 6가지 알고리즘을 직접 구현하고 데이터로 비교해보자는 것이었다.
막상 끝내고 보니 코드보다 설계에서 배운 게 더 많았다. 동시성은 제거 대상이 아니라 관리 대상이라는 것, 어떤 레이스를 허용하고 어떤 레이스를 막을지가 설계의 핵심이라는 것. Consistent Hashing에서 ThreadLocal + Copy-on-Write로 읽기 경로를 완전히 락프리로 만들면서 그게 실감됐다.
테스트 결과에서도 의외의 발견이 있었다. LRT가 수치상 압도적이지만 사실상 단일 서버 운영이라는 것, IP Hash가 성능은 평범하지만 장애 에러가 3건이라는 것. "좋은 알고리즘"이 무엇인지는 어떤 상황을 전제로 하느냐에 따라 완전히 달라진다.
결국 로드밸런싱도 트레이드오프의 연속이다. 처리량을 택하면 단일 서버 의존도가 올라가고, 균등 분산을 택하면 느린 서버의 연결이 쌓이고, 세션 지속성을 택하면 장애 시 재배치가 발생한다. 정답은 없고 상황에 맞는 선택이 있을 뿐이다.
