Lab 5: Logistic Classification
Reminder: Logistic Regression
Hypothesis
Cost
- If , cost is near 0.
- If , cost is high.
❓ 왜 이전에 배운 MSE를 cost function으로 쓰면 안 되는가?
❗ 이제 가설식은 이다. 이 가설식에 MSE로 cost function을 정의하게 되어 미분하게 된다면, 선형 회귀 때와 달리 심한 비볼록(non-convex) 그래프가 나올 것이다.
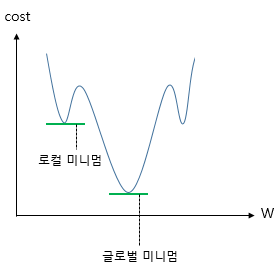
이렇게 된다면 local minimum에 빠지기 쉽다. 이는 cost가 최소가 되는 가중치 W를 찾겠다는 비용 함수의 목적에 맞지 않게 된다.
Weight Update via Gradient Descent
- : Learning rate
Imports
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim# For reproducibility
torch.manual_seed(1)<torch._C.Generator at 0x106951ed0>Training Data
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]]
y_data = [[0], [0], [0], [1], [1], [1]]Consider the following classification problem: given the number of hours each student spent watching the lecture and working in the code lab, predict whether the student passed or failed a course. For example, the first (index 0) student watched the lecture for 1 hour and spent 2 hours in the lab session ([1, 2]), and ended up failing the course ([0]).
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)As always, we need these data to be in torch.Tensor format, so we convert them.
print(x_train.shape)
print(y_train.shape)torch.Size([6, 2])
torch.Size([6, 1])Computing the Hypothesis
PyTorch has a torch.exp() function that resembles the exponential function.
print('e^1 equals: ', torch.exp(torch.FloatTensor([1])))e^1 equals: tensor([2.7183])We can use it to compute the hypothesis function conveniently.
W = torch.zeros((2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)hypothesis = 1 / (1 + torch.exp(-(x_train.matmul(W) + b)))print(hypothesis)
print(hypothesis.shape)tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<MulBackward>)
torch.Size([6, 1])Or, we could use torch.sigmoid() function! This resembles the sigmoid function:
print('1/(1+e^{-1}) equals: ', torch.sigmoid(torch.FloatTensor([1])))1/(1+e^{-1}) equals: tensor([0.7311])Now, the code for hypothesis function is cleaner.
hypothesis = torch.sigmoid(x_train.matmul(W) + b)print(hypothesis)
print(hypothesis.shape)tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<SigmoidBackward>)
torch.Size([6, 1])Computing the Cost Function (Low-level)
We want to measure the difference between hypothesis and y_train.
print(hypothesis)
print(y_train)tensor([[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000],
[0.5000]], grad_fn=<SigmoidBackward>)
tensor([[0.],
[0.],
[0.],
[1.],
[1.],
[1.]])For one element, the loss can be computed as follows:
-(y_train[0] * torch.log(hypothesis[0]) +
(1 - y_train[0]) * torch.log(1 - hypothesis[0]))tensor([0.6931], grad_fn=<NegBackward>)To compute the losses for the entire batch, we can simply input the entire vector.
losses = -(y_train * torch.log(hypothesis) +
(1 - y_train) * torch.log(1 - hypothesis))
print(losses)tensor([[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931],
[0.6931]], grad_fn=<NegBackward>)Then, we just .mean() to take the mean of these individual losses.
cost = losses.mean()
print(cost)tensor(0.6931, grad_fn=<MeanBackward1>)Computing the Cost Function with F.binary_cross_entropy
In reality, binary classification is used so often that PyTorch has a simple function called F.binary_cross_entropy implemented to lighten the burden.
F.binary_cross_entropy(hypothesis, y_train)tensor(0.6931, grad_fn=<BinaryCrossEntropyBackward>)Training with Low-level Binary Cross Entropy Loss
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]]
y_data = [[0], [0], [0], [1], [1], [1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)# 모델 초기화
W = torch.zeros((2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# Cost 계산
hypothesis = torch.sigmoid(x_train.matmul(W) + b) # or .mm or @
cost = -(y_train * torch.log(hypothesis) +
(1 - y_train) * torch.log(1 - hypothesis)).mean()
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))Epoch 0/1000 Cost: 0.693147
Epoch 100/1000 Cost: 0.134722
Epoch 200/1000 Cost: 0.080643
Epoch 300/1000 Cost: 0.057900
Epoch 400/1000 Cost: 0.045300
Epoch 500/1000 Cost: 0.037261
Epoch 600/1000 Cost: 0.031673
Epoch 700/1000 Cost: 0.027556
Epoch 800/1000 Cost: 0.024394
Epoch 900/1000 Cost: 0.021888
Epoch 1000/1000 Cost: 0.019852Training with F.binary_cross_entropy
# 모델 초기화
W = torch.zeros((2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# Cost 계산
hypothesis = torch.sigmoid(x_train.matmul(W) + b) # or .mm or @
cost = F.binary_cross_entropy(hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))Epoch 0/1000 Cost: 0.693147
Epoch 100/1000 Cost: 0.134722
Epoch 200/1000 Cost: 0.080643
Epoch 300/1000 Cost: 0.057900
Epoch 400/1000 Cost: 0.045300
Epoch 500/1000 Cost: 0.037261
Epoch 600/1000 Cost: 0.031672
Epoch 700/1000 Cost: 0.027556
Epoch 800/1000 Cost: 0.024394
Epoch 900/1000 Cost: 0.021888
Epoch 1000/1000 Cost: 0.019852Loading Real Data
import numpy as npxy = np.loadtxt('data-03-diabetes.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)print(x_train[0:5])
print(y_train[0:5])tensor([[-0.2941, 0.4874, 0.1803, -0.2929, 0.0000, 0.0015, -0.5312, -0.0333],
[-0.8824, -0.1457, 0.0820, -0.4141, 0.0000, -0.2072, -0.7669, -0.6667],
[-0.0588, 0.8392, 0.0492, 0.0000, 0.0000, -0.3055, -0.4927, -0.6333],
[-0.8824, -0.1055, 0.0820, -0.5354, -0.7778, -0.1624, -0.9240, 0.0000],
[ 0.0000, 0.3769, -0.3443, -0.2929, -0.6028, 0.2846, 0.8873, -0.6000]])
tensor([[0.],
[1.],
[0.],
[1.],
[0.]])Training with Real Data using low-level Binary Cross Entropy Loss
# 모델 초기화
W = torch.zeros((8, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1)
nb_epochs = 100
for epoch in range(nb_epochs + 1):
# Cost 계산
hypothesis = torch.sigmoid(x_train.matmul(W) + b) # or .mm or @
cost = -(y_train * torch.log(hypothesis) + (1 - y_train) * torch.log(1 - hypothesis)).mean()
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 10번마다 로그 출력
if epoch % 10 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))Epoch 0/100 Cost: 0.693148
Epoch 10/100 Cost: 0.572727
Epoch 20/100 Cost: 0.539493
Epoch 30/100 Cost: 0.519708
Epoch 40/100 Cost: 0.507066
Epoch 50/100 Cost: 0.498539
Epoch 60/100 Cost: 0.492549
Epoch 70/100 Cost: 0.488209
Epoch 80/100 Cost: 0.484985
Epoch 90/100 Cost: 0.482543
Epoch 100/100 Cost: 0.480661Training with Real Data using F.binary_cross_entropy
# 모델 초기화
W = torch.zeros((8, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1)
nb_epochs = 100
for epoch in range(nb_epochs + 1):
# Cost 계산
hypothesis = torch.sigmoid(x_train.matmul(W) + b) # or .mm or @
cost = F.binary_cross_entropy(hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 10번마다 로그 출력
if epoch % 10 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))Epoch 0/100 Cost: 0.693147
Epoch 10/100 Cost: 0.572727
Epoch 20/100 Cost: 0.539494
Epoch 30/100 Cost: 0.519708
Epoch 40/100 Cost: 0.507065
Epoch 50/100 Cost: 0.498539
Epoch 60/100 Cost: 0.492549
Epoch 70/100 Cost: 0.488208
Epoch 80/100 Cost: 0.484985
Epoch 90/100 Cost: 0.482543
Epoch 100/100 Cost: 0.480661Evaluation
After we finish training the model, we want to check how well our model fits the training set.
hypothesis = torch.sigmoid(x_test.matmul(W) + b)
print(hypothesis[:5])tensor([[0.4103],
[0.9242],
[0.2300],
[0.9411],
[0.1772]], grad_fn=<SliceBackward>)We can change hypothesis (real number from 0 to 1) to binary predictions (either 0 or 1) by comparing them to 0.5.
prediction = hypothesis >= torch.FloatTensor([0.5])
print(prediction[:5])tensor([[0],
[1],
[0],
[1],
[0]], dtype=torch.uint8)Then, we compare it with the correct labels y_train.
print(prediction[:5])
print(y_train[:5])tensor([[0],
[1],
[0],
[1],
[0]], dtype=torch.uint8)
tensor([[0.],
[1.],
[0.],
[1.],
[0.]])correct_prediction = prediction.float() == y_train
print(correct_prediction[:5])tensor([[1],
[1],
[1],
[1],
[1]], dtype=torch.uint8)Finally, we can calculate the accuracy by counting the number of correct predictions and dividng by total number of predictions.
accuracy = correct_prediction.sum().item() / len(correct_prediction)
print('The model has an accuracy of {:2.2f}% for the training set.'.format(accuracy * 100))The model has an accuracy of 76.68% for the training set.Optional: High-level Implementation with nn.Module
class BinaryClassifier(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(8, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return self.sigmoid(self.linear(x))model = BinaryClassifier()# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=1) # Returns an iterator over module parameters.(ex. W, b)
nb_epochs = 100
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = model(x_train)
# cost 계산
cost = F.binary_cross_entropy(hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 20번마다 로그 출력
if epoch % 10 == 0:
prediction = hypothesis >= torch.FloatTensor([0.5])
correct_prediction = prediction.float() == y_train
accuracy = correct_prediction.sum().item() / len(correct_prediction)
print('Epoch {:4d}/{} Cost: {:.6f} Accuracy {:2.2f}%'.format(
epoch, nb_epochs, cost.item(), accuracy * 100,
))
Epoch 0/100 Cost: 0.704829 Accuracy 45.72%
Epoch 10/100 Cost: 0.572391 Accuracy 67.59%
Epoch 20/100 Cost: 0.539563 Accuracy 73.25%
Epoch 30/100 Cost: 0.520042 Accuracy 75.89%
Epoch 40/100 Cost: 0.507561 Accuracy 76.15%
Epoch 50/100 Cost: 0.499125 Accuracy 76.42%
Epoch 60/100 Cost: 0.493177 Accuracy 77.21%
Epoch 70/100 Cost: 0.488846 Accuracy 76.81%
Epoch 80/100 Cost: 0.485612 Accuracy 76.28%
Epoch 90/100 Cost: 0.483146 Accuracy 76.55%
Epoch 100/100 Cost: 0.481234 Accuracy 76.81%