batch
1. 핵심 요약 정리
배치 정규화의 장점
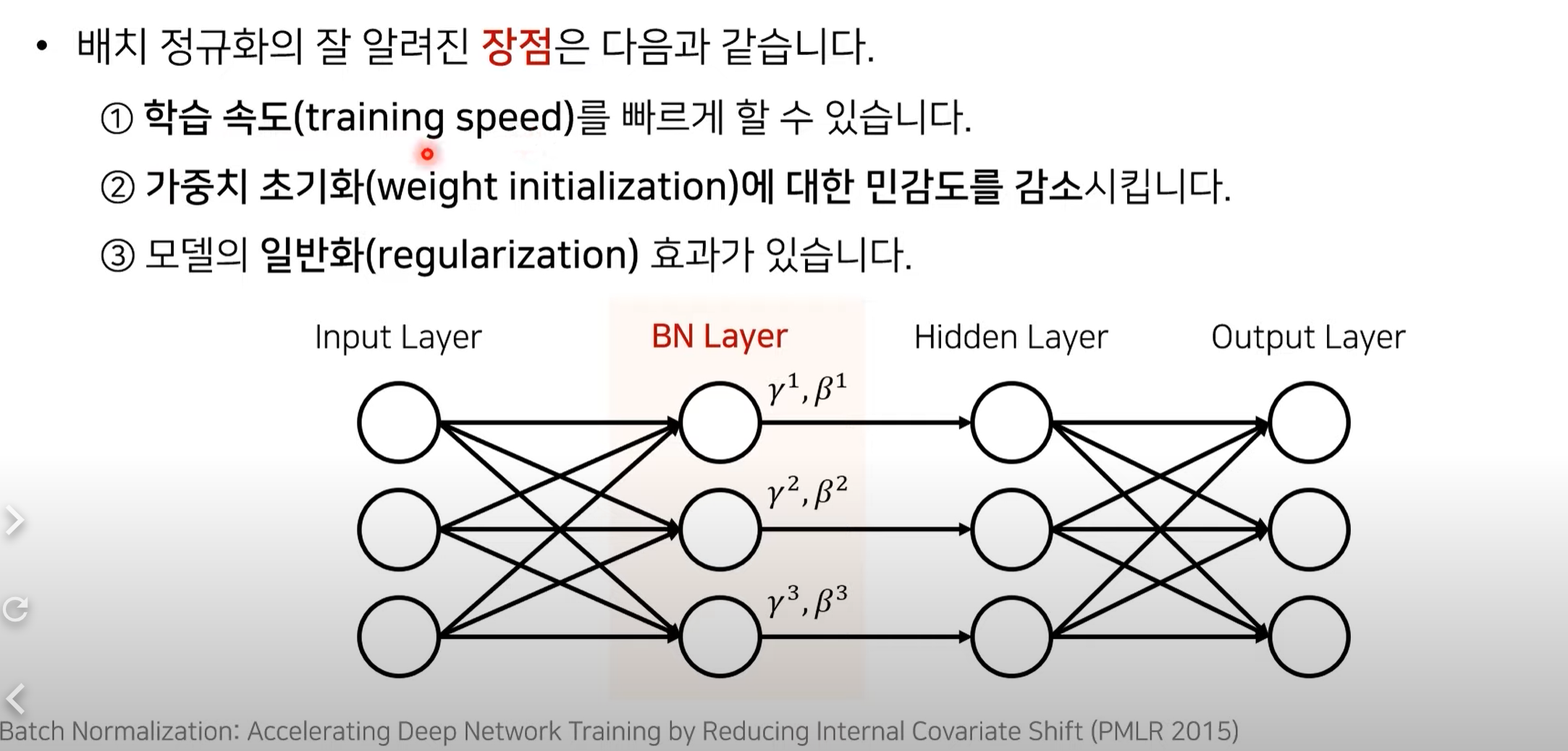
각각 차원에 따른 input을 control하게 해줌.
parameter의 개수도 적음 -> 약간의 연산만 추가하여 성능을 비약적으로 올릴 수 있음
연구 배경
입력 정규화(Normalization)
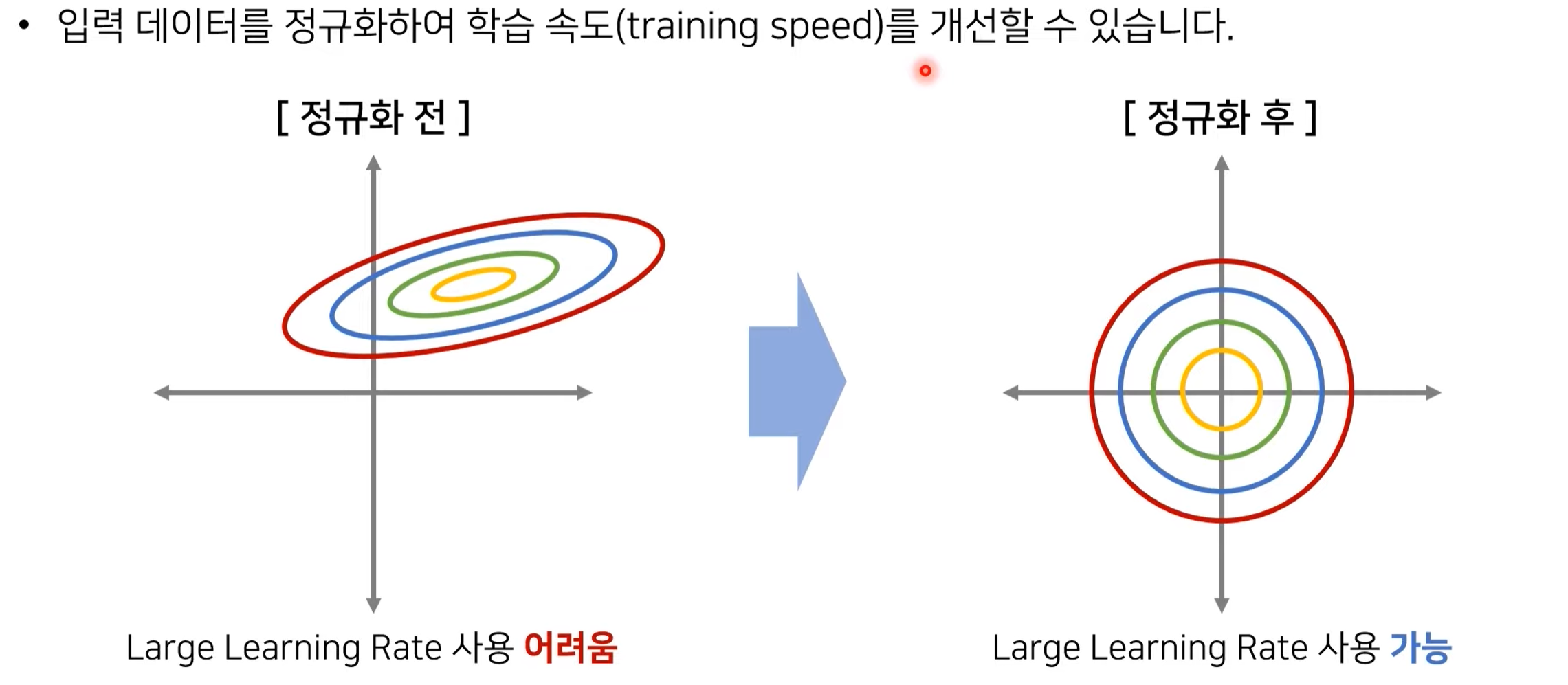
정규화를 하였을 때 학습의 속도가 빨라진다. 2차원의 데이터를 학습한다고 가정하자.
이때 정규화 전의 데이터를 사용할 때는, lr을 크게 사용할 수 없다. ∵ 가중치 값이 많이 바뀐다고 할 때, 세로축의 경우 feature들이 오밀조밀하게 있다. 따라서 큰 폭으로 이동하면 feature값에 많은 변화들이 있게 된다. 하지만 가로축은 이와 반대다.
이러한 이유로 우리는 정규화를 하여 학습에 수월한 데이터 분포를 가지게 한다. -> Learning rate 크게 사용 가능 -> 학습 속도 빨라짐
입력 표준화
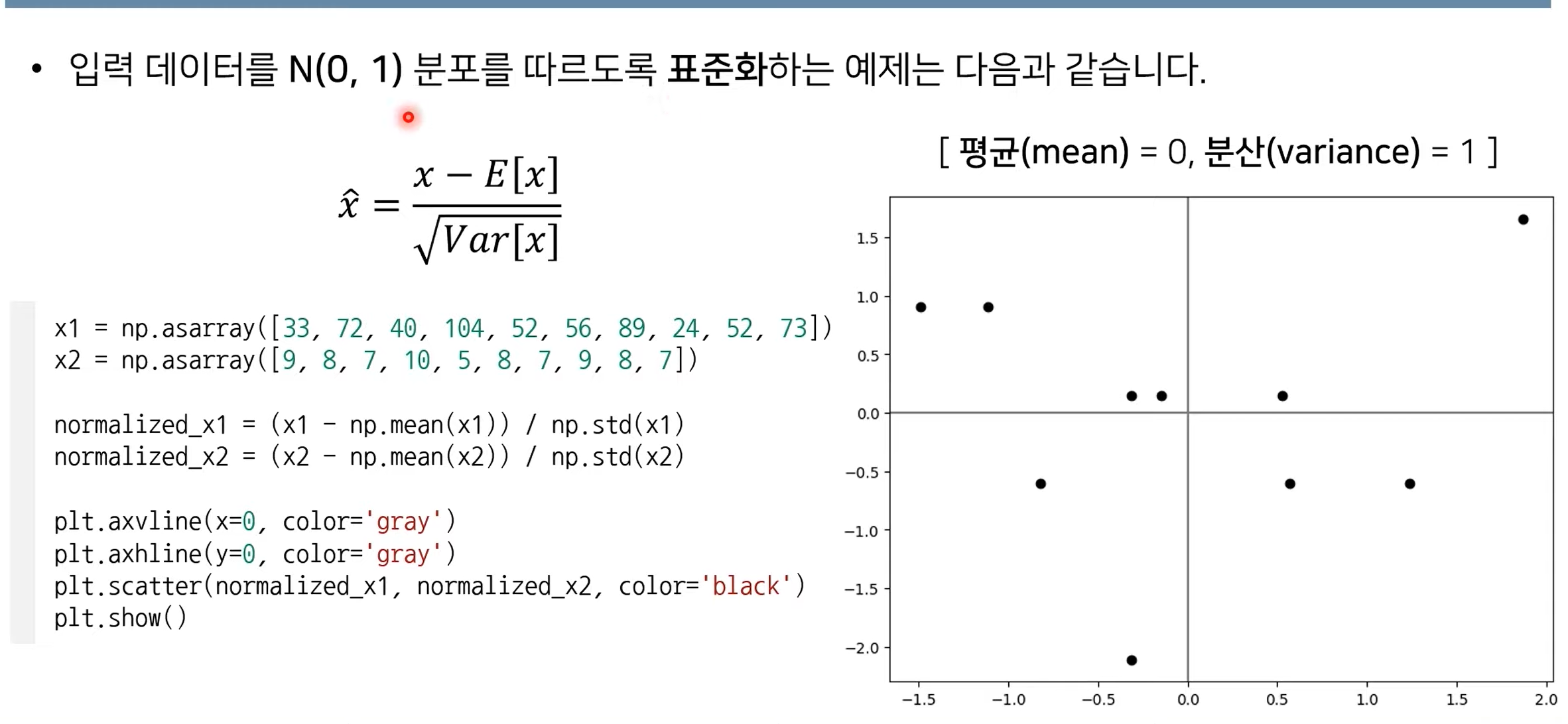
입력 데이터가 표준 정규분포를 따르게 한다.
입력 정규화 vs 화이트닝
-
입력 정규화
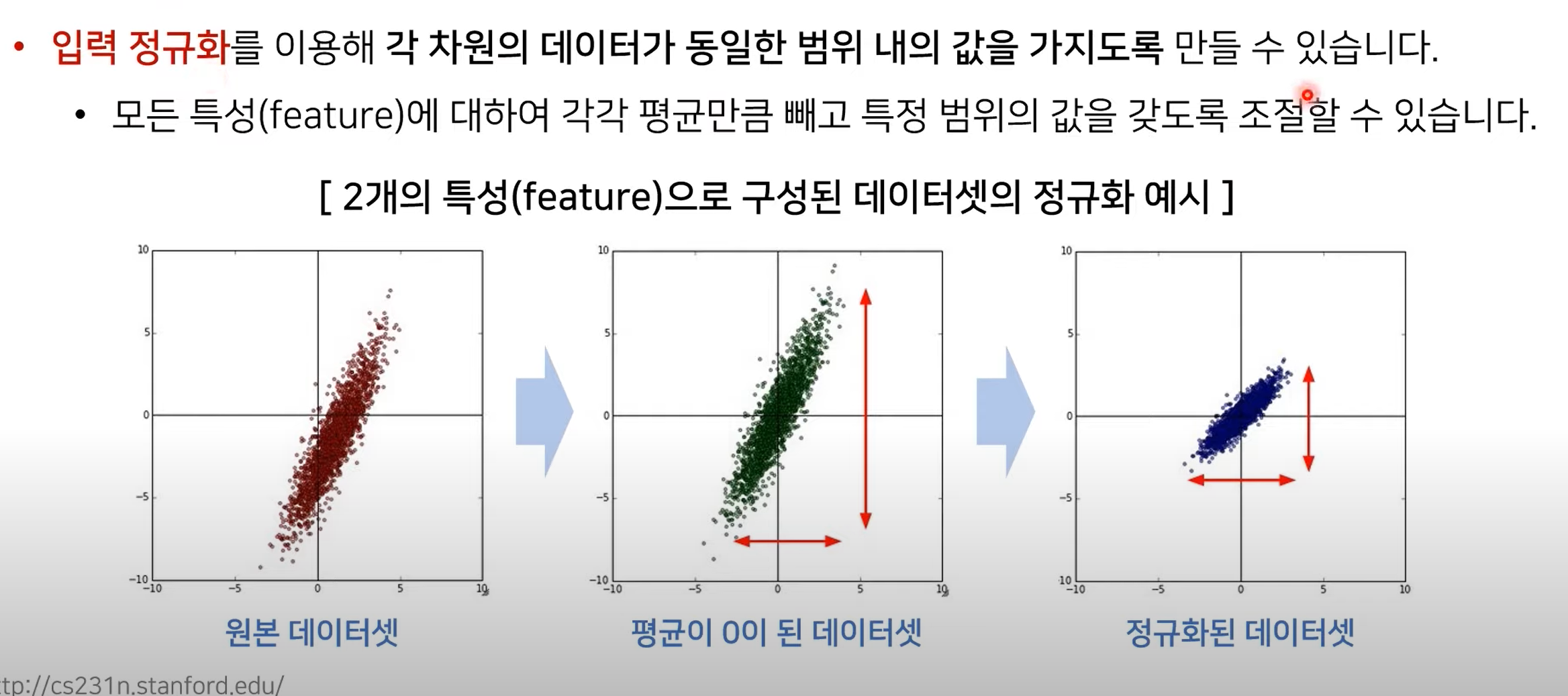
-
화이트닝
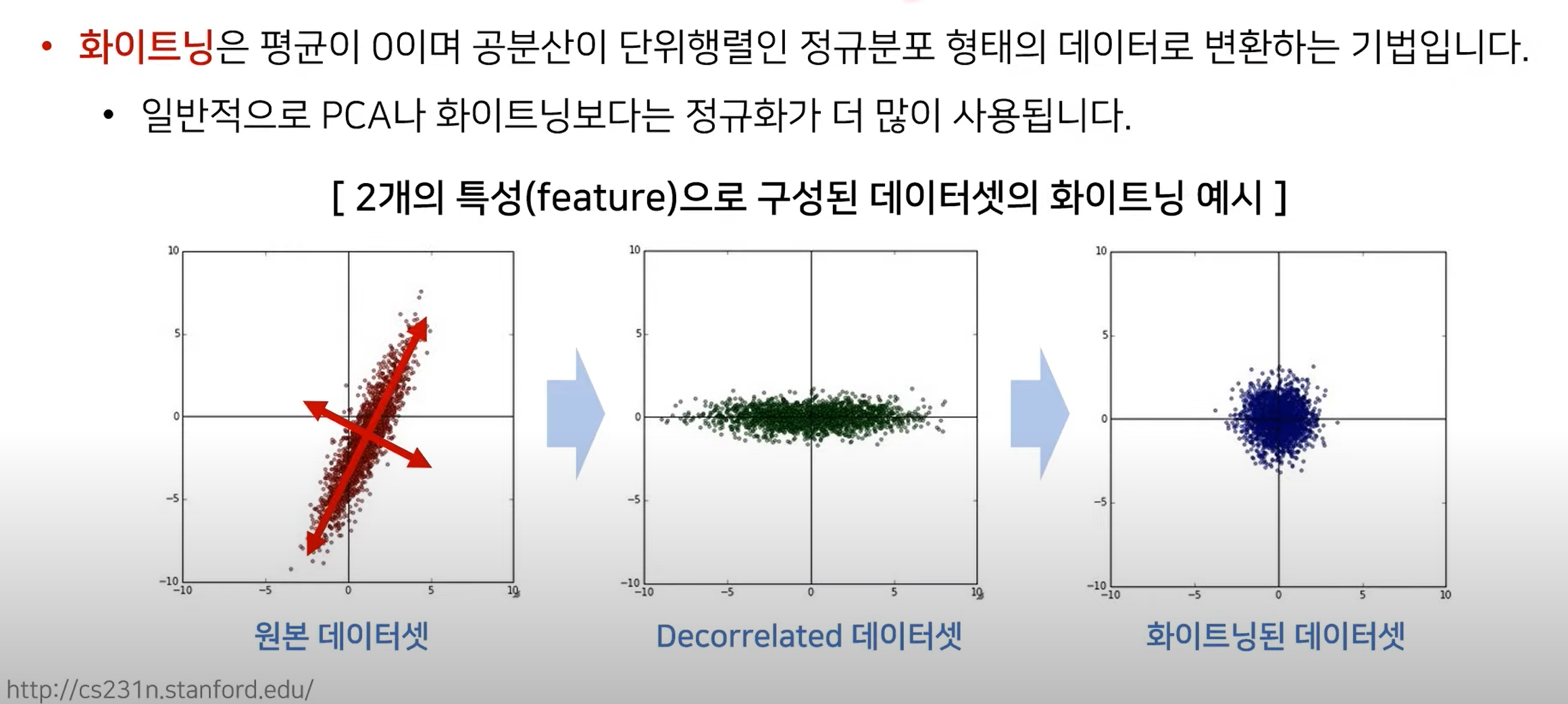
- 이때 공분산이 단위행렬을 가진다는 것은 서로 다른 feature간의 연관성이 없도록 데이터를 처리한다는 것이다.
- 즉, 각각의 feature에 대해 Decorrelated 되도록 하는 것이다.(Using SVD for example)
각 레이어에 대한 입력 분포 정규화
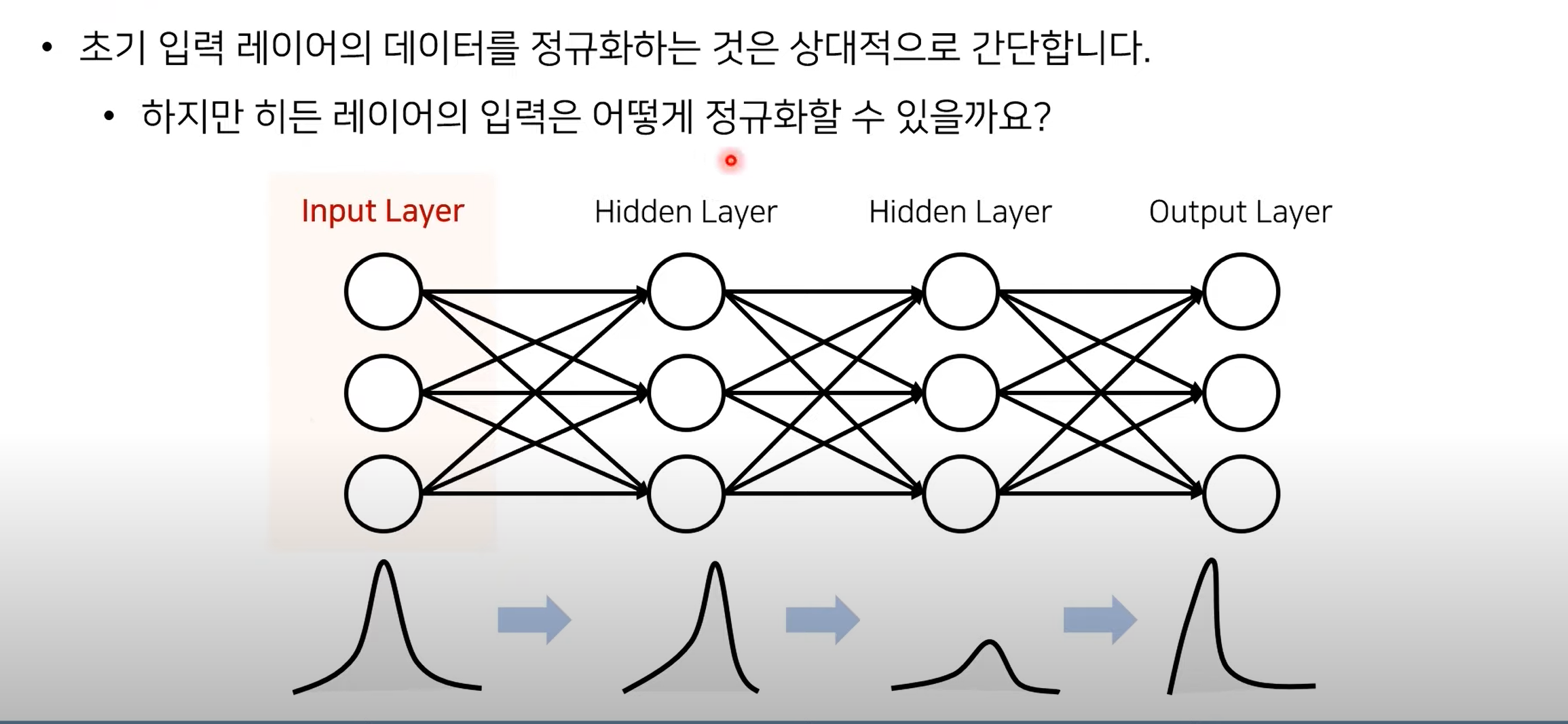
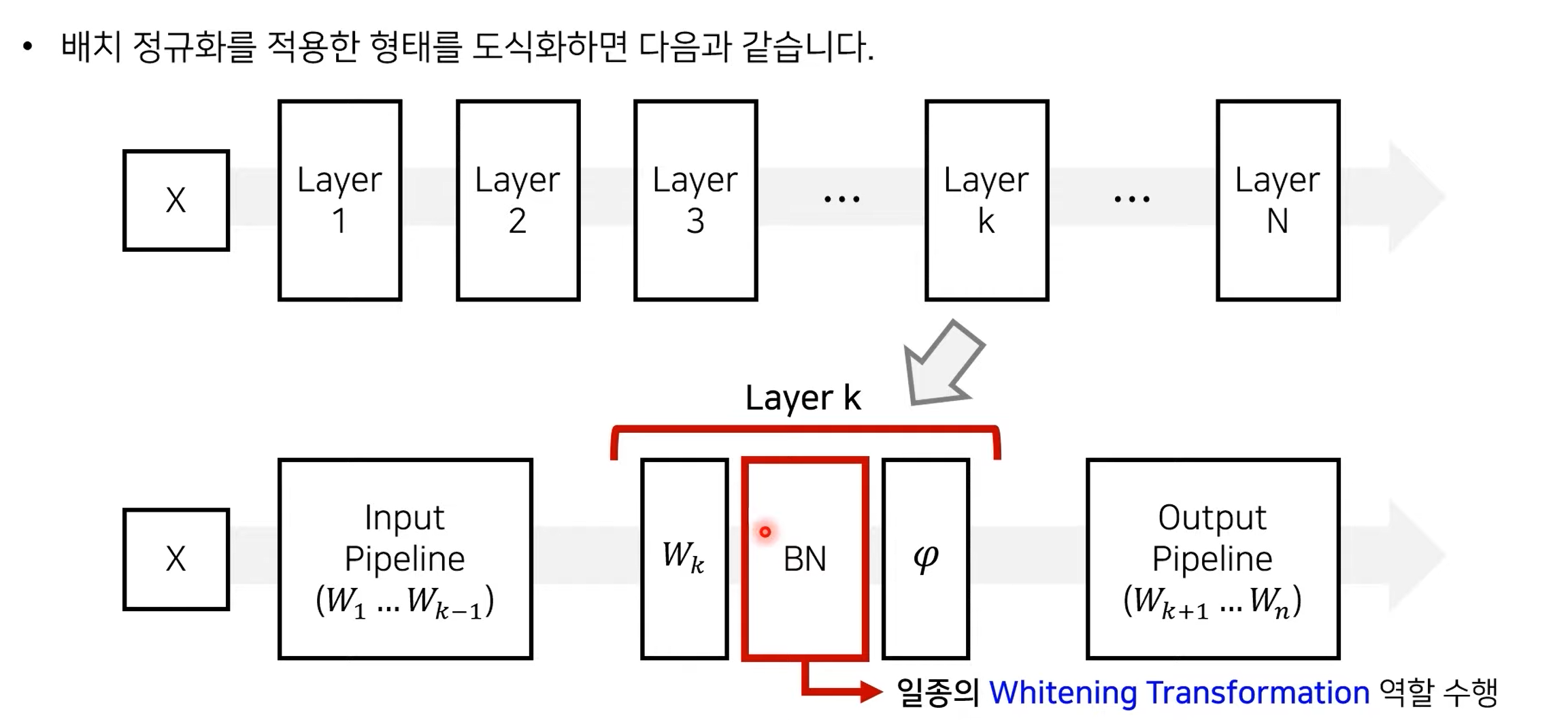
배치 정규화

-
체크: 입력 데이터를 정규화할 때에서 추가된 점이 있다면 네트워크가 성능이 향상되는 방향으로 알아서 추가적인 파라미터 를 학습한다!
❔ 감마, 베타를 사용하는 이유?
❕ 정규화 이후에 사용하는 감마와 베타는 비선형성을 유지할 수 있도록 해준다!
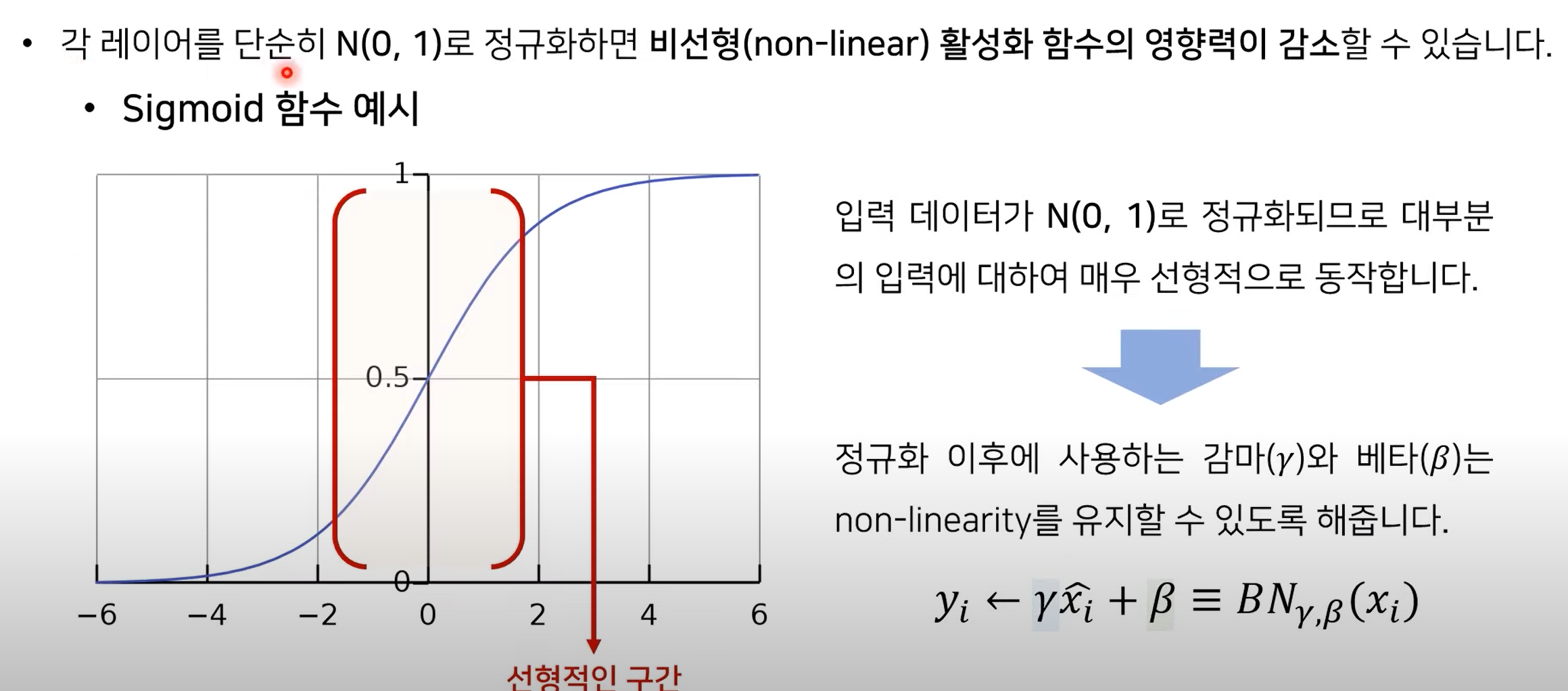
배치 정규화의 성능 향상
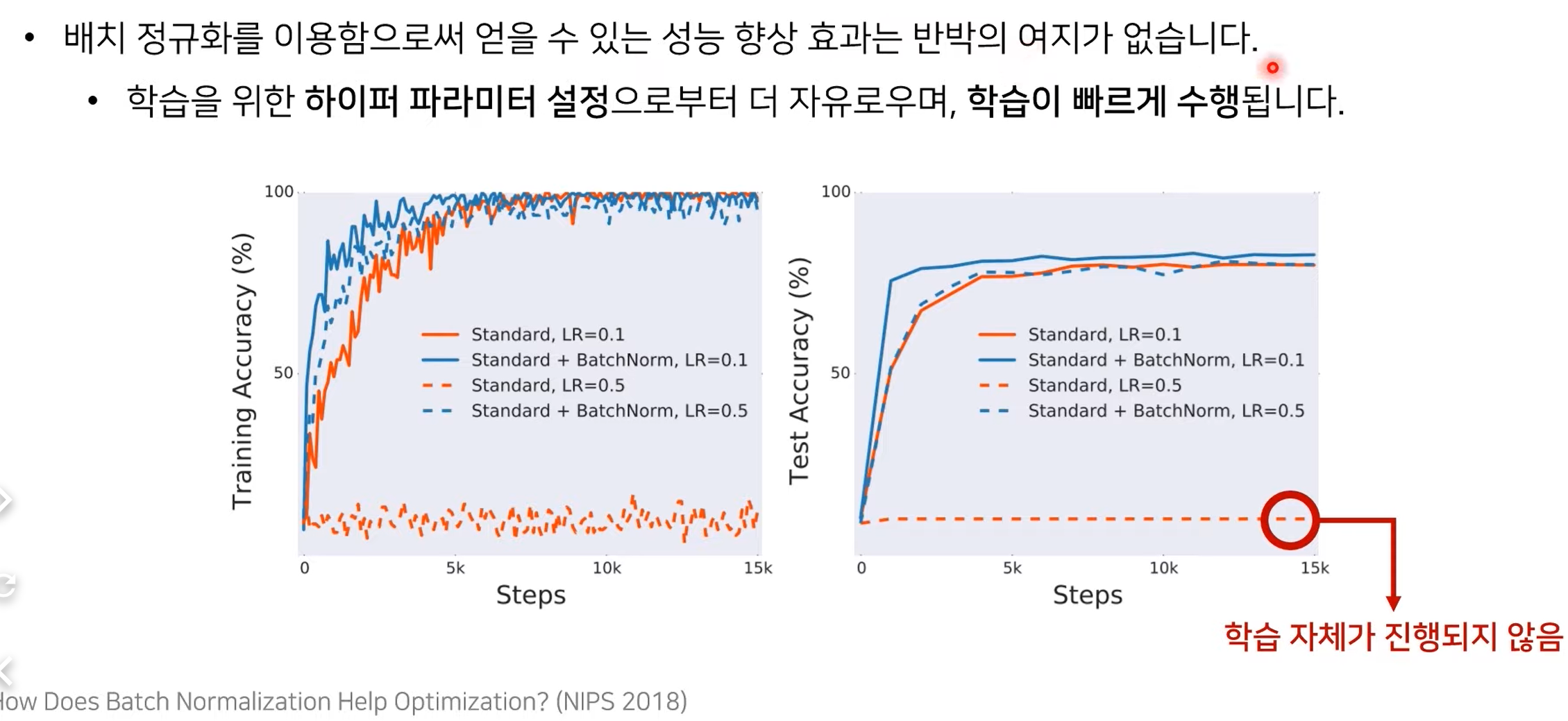
- 훨씬 빠른 학습이 진행됨을 확인할 수 있음!
- Batch Norm을 사용하지 않을 경우, lr을 크게 잡으면 학습이 제대로 진행되지 않는다!
2. 배치 정규화 파라미터 미분해보고 기울기 계산해보기
정규화 흐름
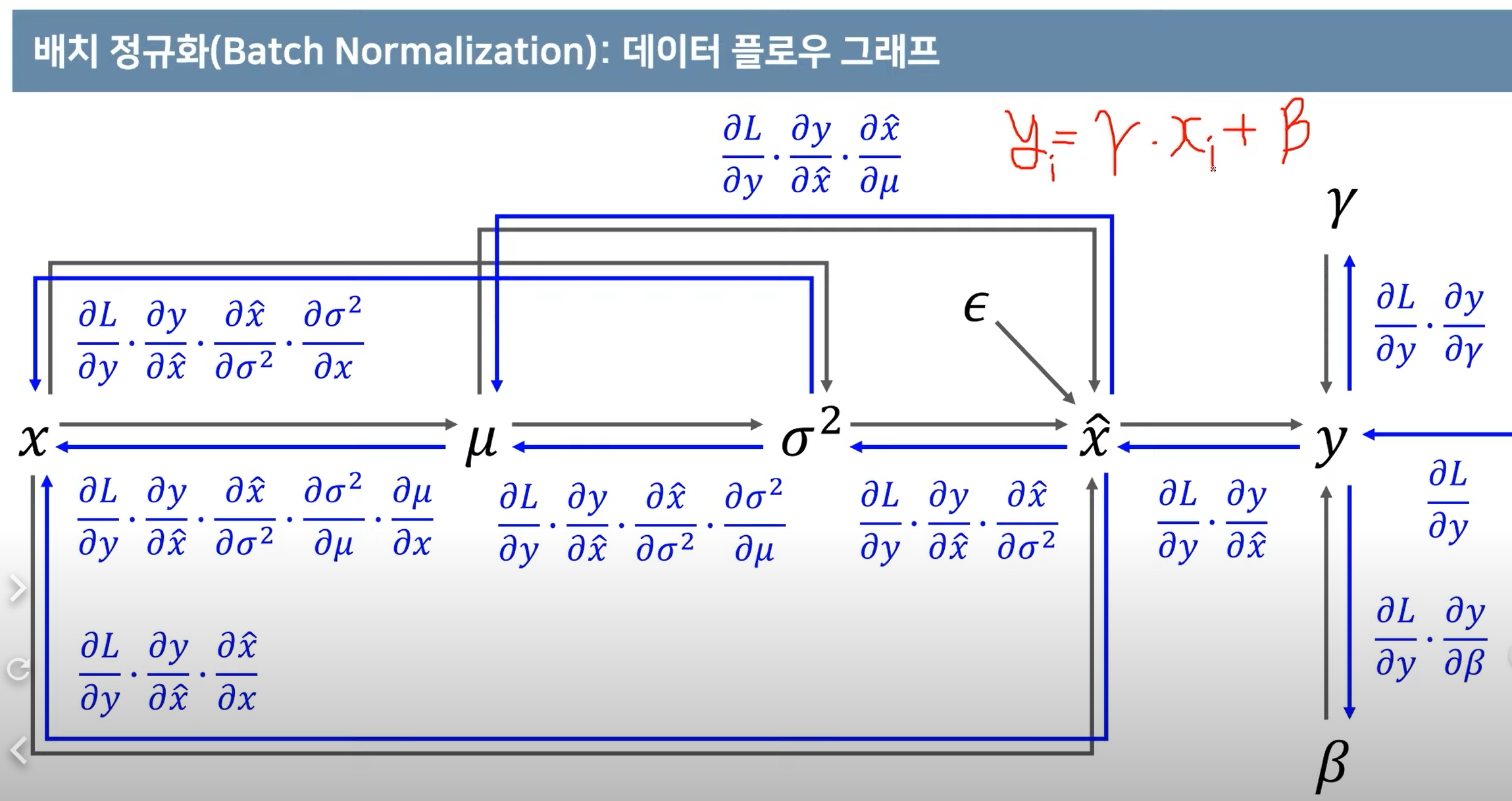

정규화 학습 및 추론

가장 기본적인 네트워크를 Training mode로 설정한다. 이후 batch normalization을 추가한다. 이후 학습이 끝나면 파라미터를 고정한 이후 inference mode(frozen parameters)로 학습을 진행한다.
3. Pytorch를 기반으로 결과를 분석하기
4. 배치 정규화의 성능 향상 원인을 분석하는 논문 핵심 요약하기
공변량 변화(Covariate Shift)
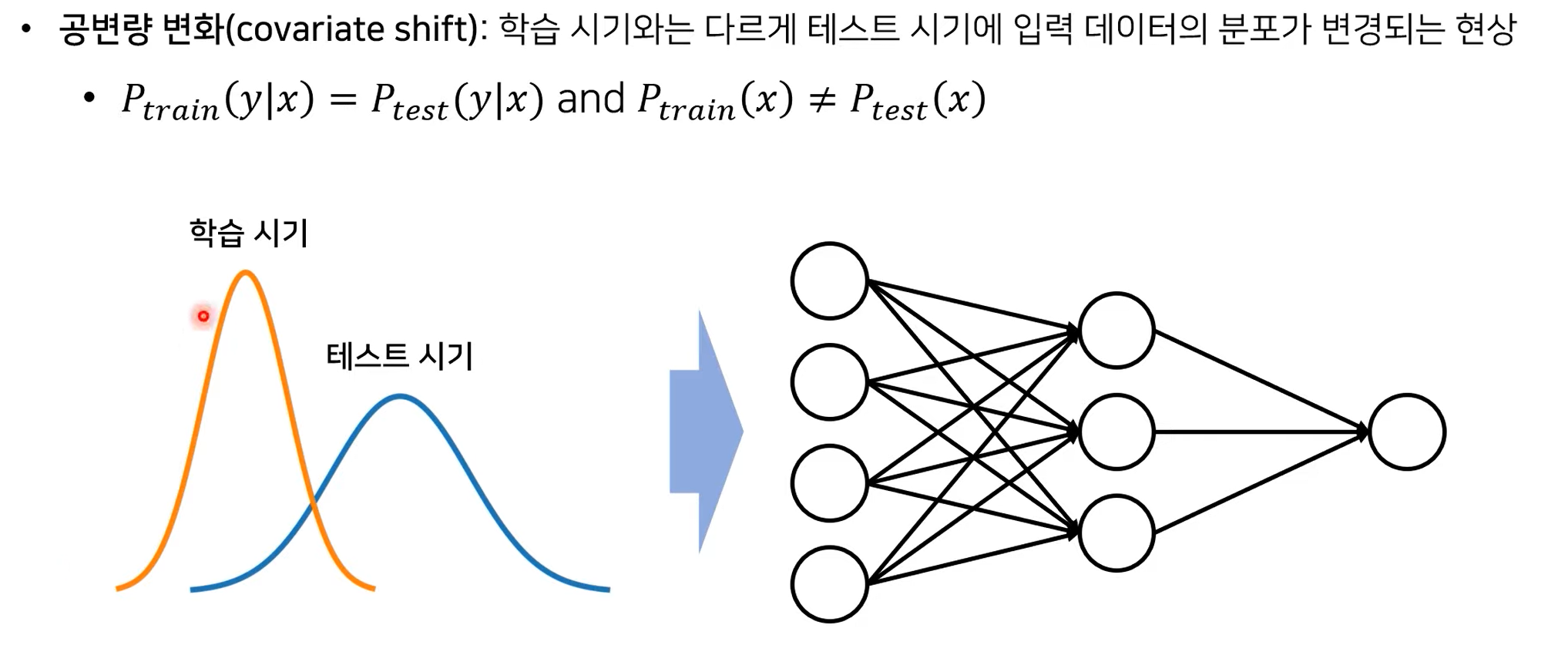
학습 때와 다른 데이터 분포의 테스트 데이터가 input으로 들어오면, 정확도가 감소하는 현상
Internal Covariate Shift(ICS) 가설
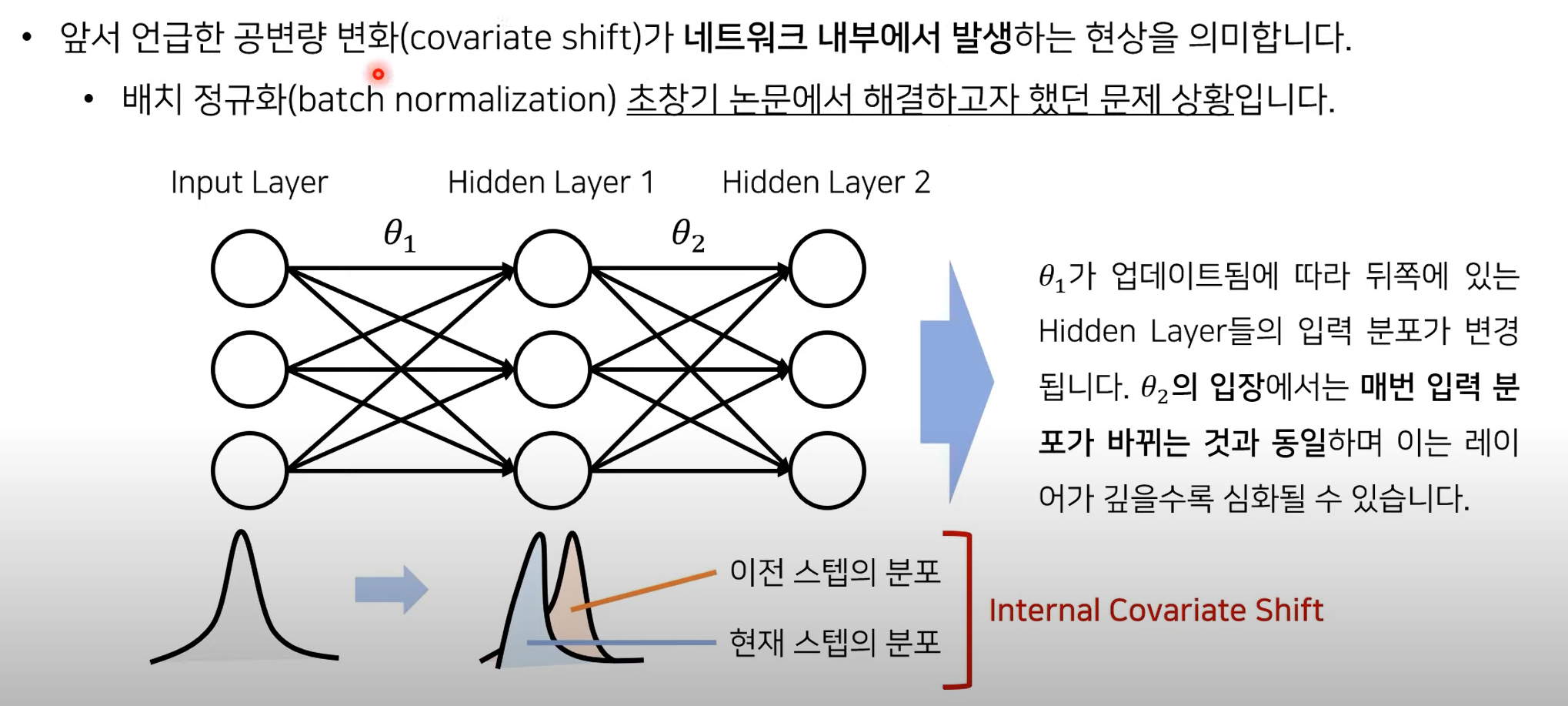
- 이 공변량 변화가 네트워크 내부 전역에서도 일어나지 않을까? 하는 의문 발생 = ICS
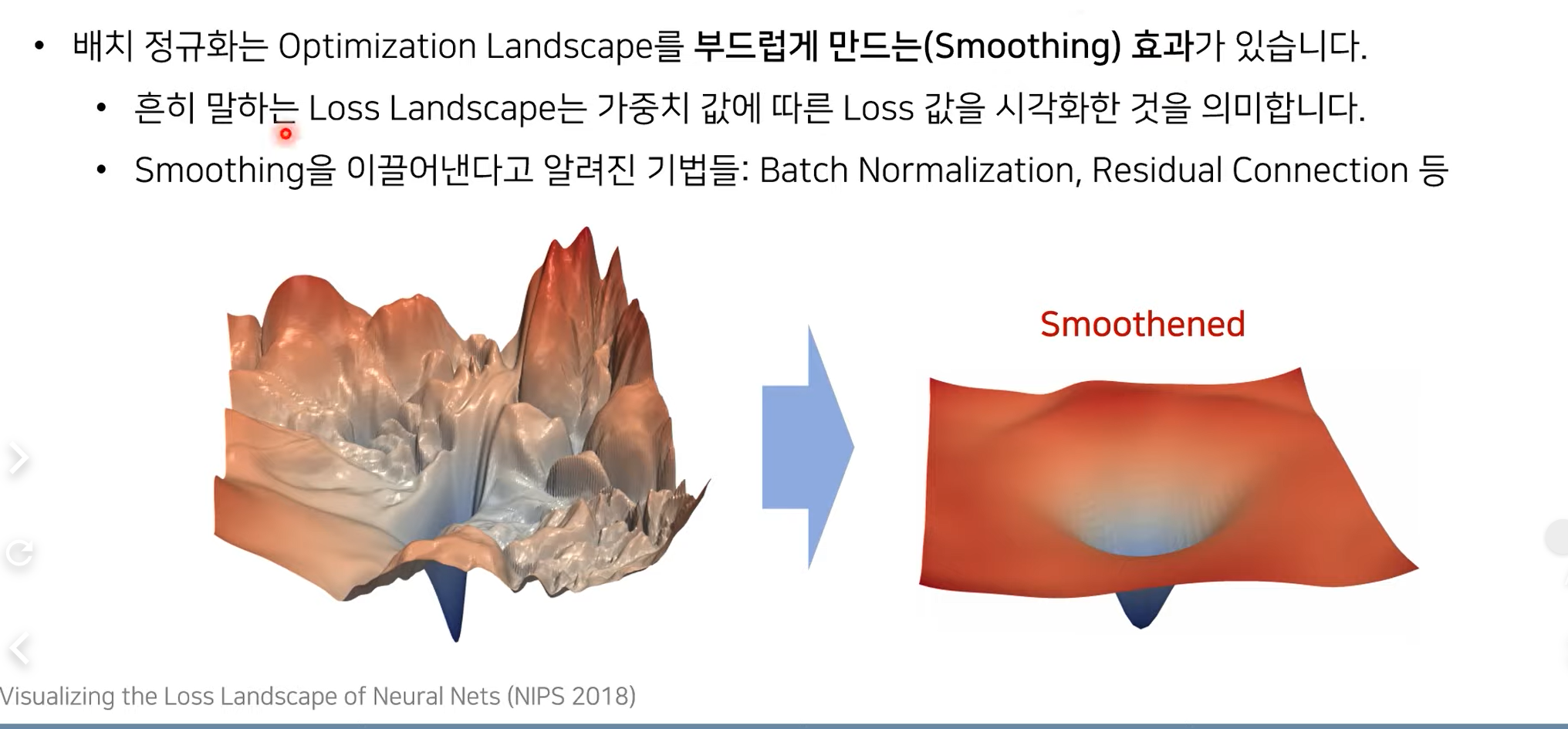
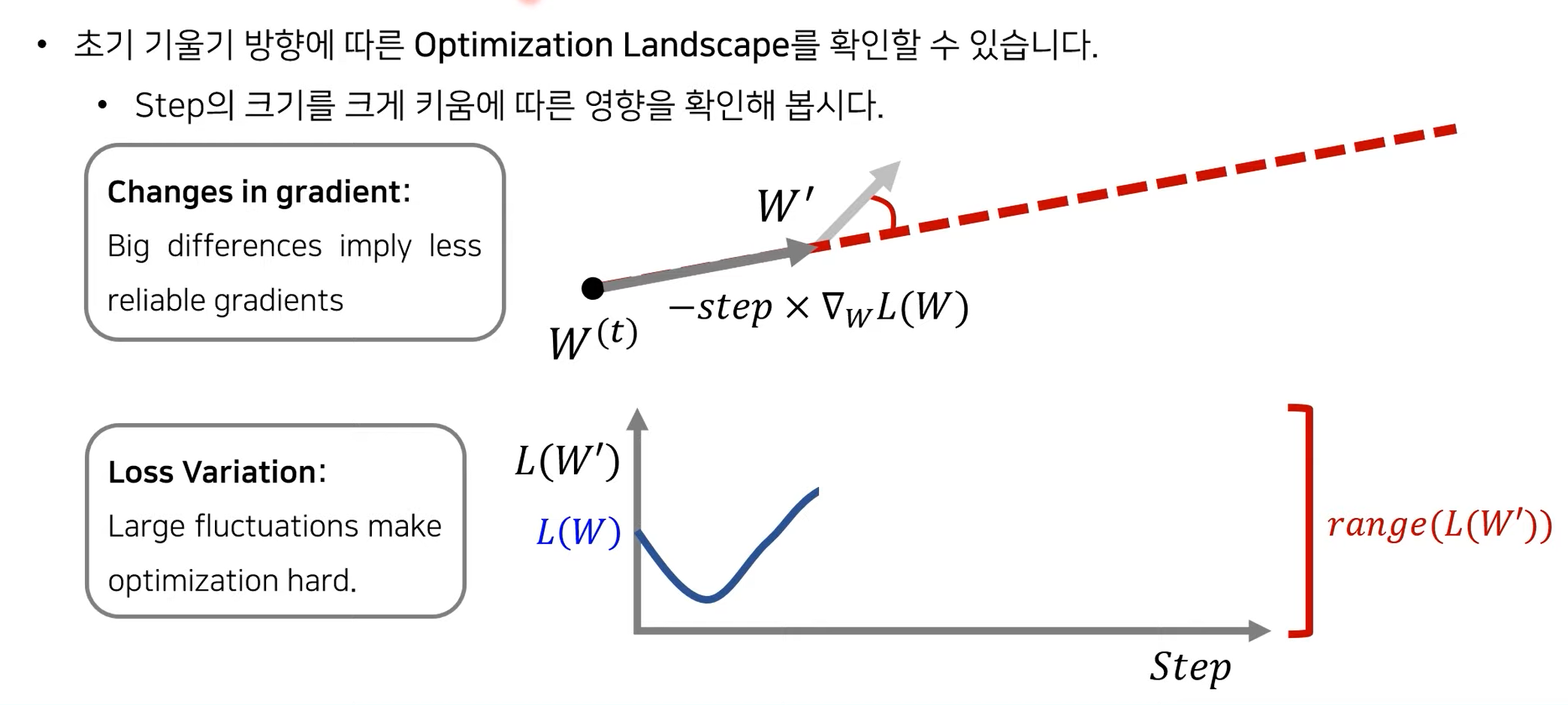
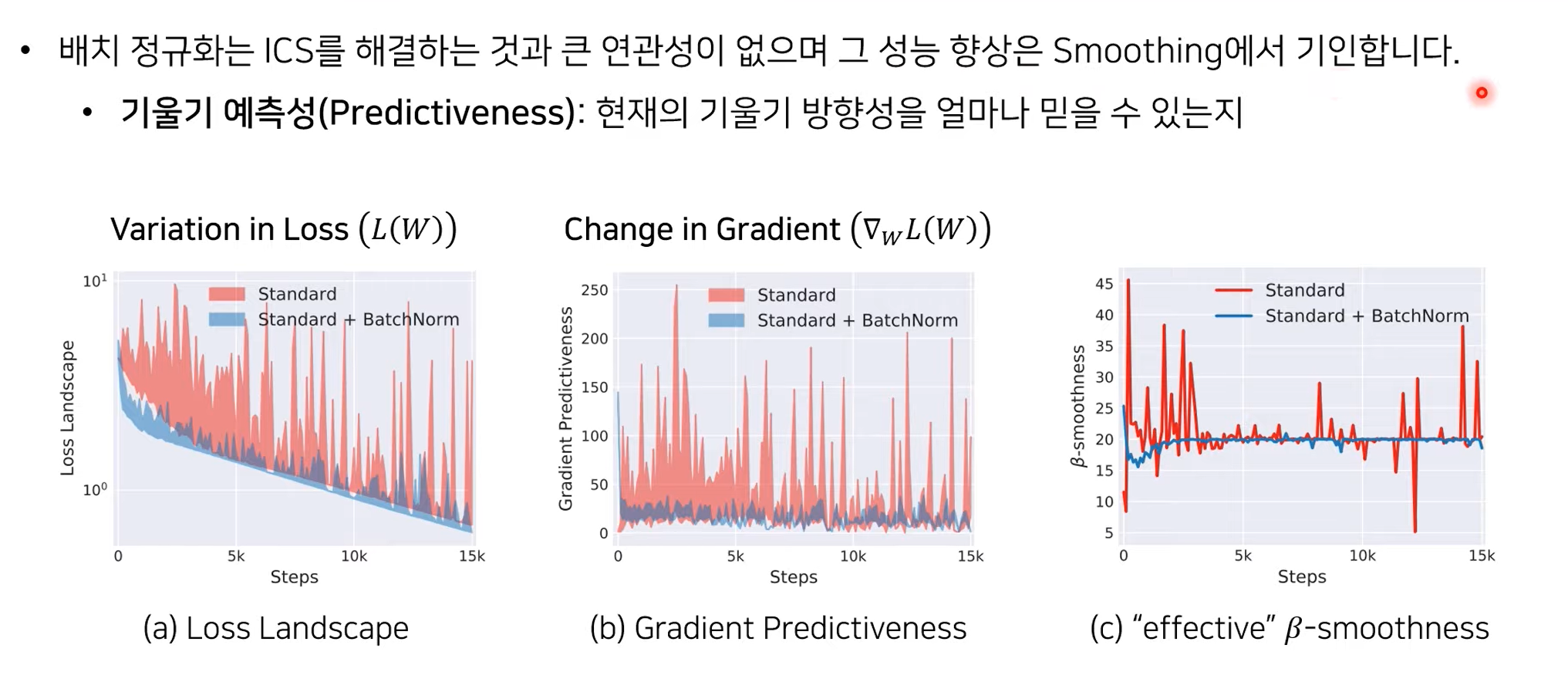
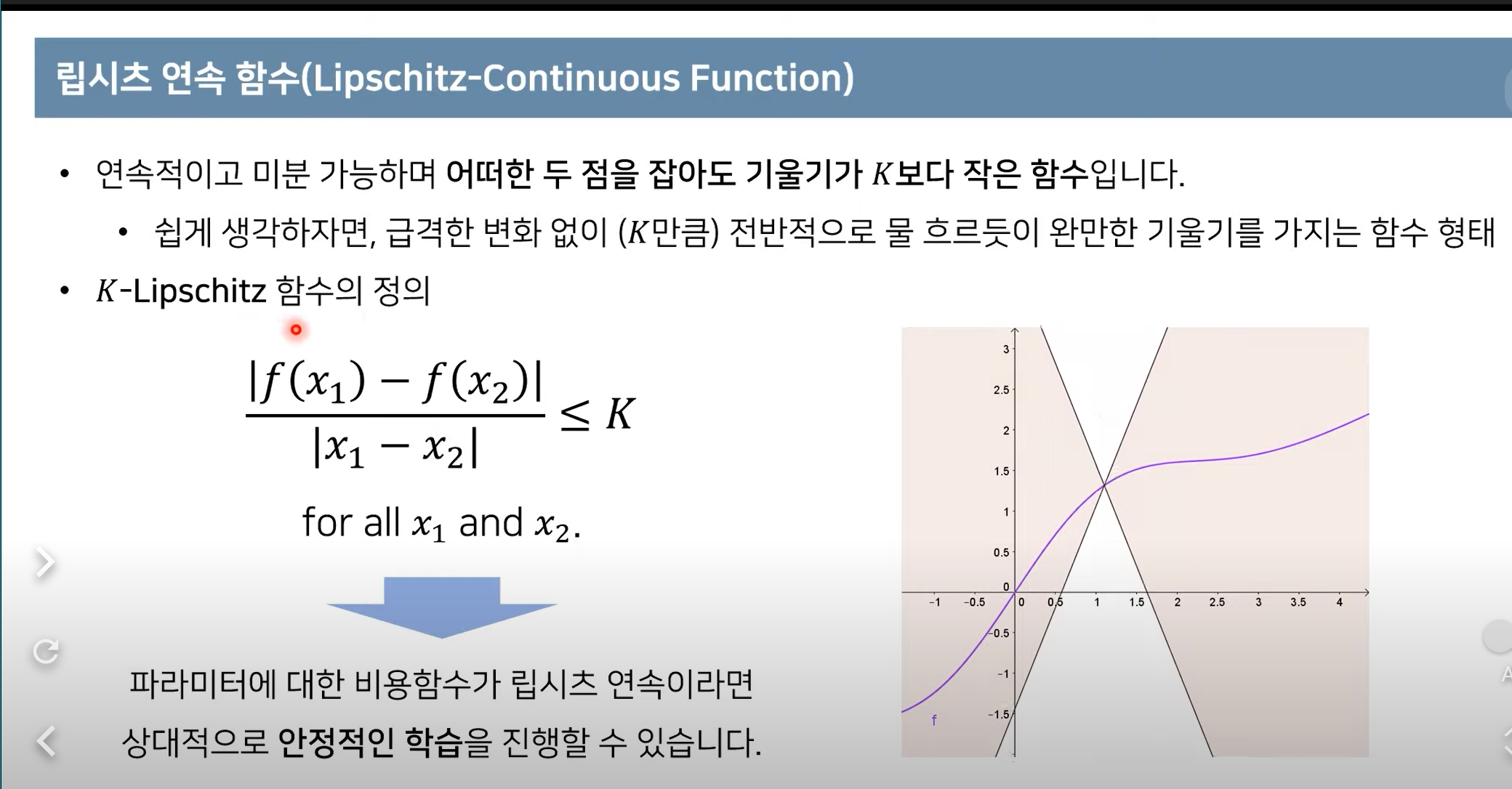
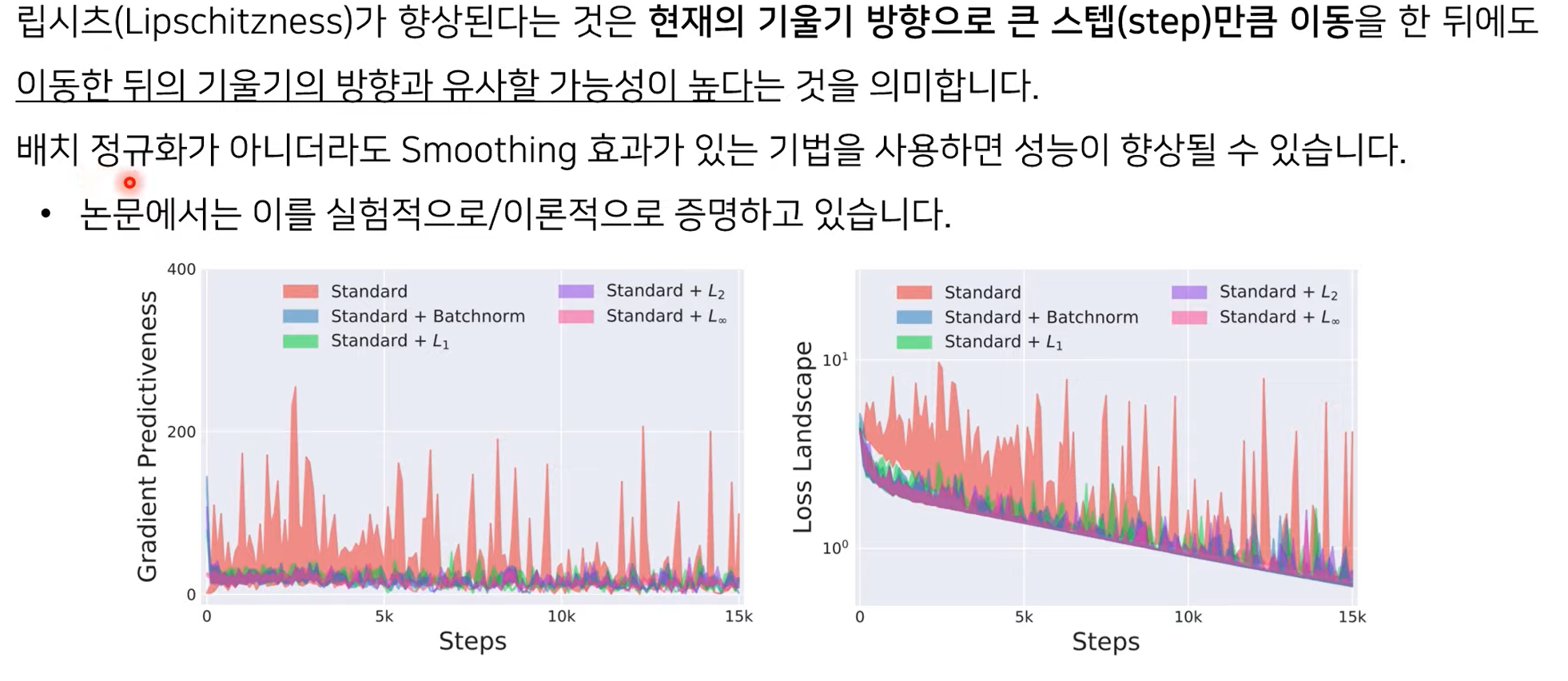
Batch normalization의 Smoothing 효과

Nice to meet you. I would really appreciate your feedbacks. Thank you