
ChatGPT는 in-context learning과 few shot learning으로 만들어졌다!
오늘 수업의 핵심은 위와 같다.
지난 강의에서도 나온 개념이지만 이번 강의에서는 좀 더 구체적으로 알려주셨다!
[지난 시간]
- chatgpt의 등장 배경
- chatgpt의 원리
[이번 시간]
- 역대 gpt의 원리
- gpt3.5, gpt4 실습
LLM
gpt 원리를 보기 전에, 알아야 할 개념이 있다.
LLM이다!
개념
LLM은 Large-scale Language Model의 약자이다.
풀이만 보면 언어모델이다! 싶겠지만, 그보다는 Foundation Model이라고 불린다. 왜냐면!
language model vs Foundation model
language model
- 입력값: 텍스트
- 출력값: 텍스트
Foundation model
- 입력값: 텍스트, 이미지, 음성, 3차원 신호
- 출력값: 질의에 대한 응답, 감정 분석, 정보 추출, 이미지 캡셔닝, 물체 인식
LLM은 처음에 언어모델로 사용되었지만, 다양한 입력값을 넣어본 결과 모두 훈련되어 다양한 출력을 내는데 성공하였다.
따라서, 그 범위가 넓어져 Foundation Model이라고 불리게 되었다!
AI 모델의 변화
인공지능 모델의 변화(1)는 다음과 같다.
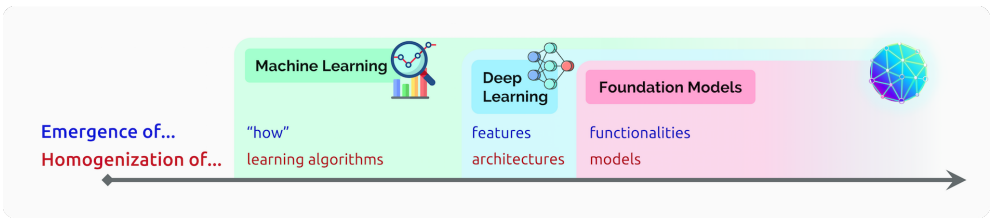
1. Machine Learning
- 어떤 알고리즘으로 학습하는지가 중요!
2. Deep Learning
- 어떤 feature를 가지고 어떤 DL 구도를 사용하는지가 중요!
3. Foundation Model
- 어떤 기능(founctionality)을 하는지가 중요!!
- data sequence를 사용하여 모델의 학습이 언어나 이미지같은 형식에 국한되지 않는다!
👉 여러 입출력 형식이 가능
❗data sequence vs sequential data
- data sequence: 나열된 데이터(형식에 제한이 없음)
- sequential data: 시계열 데이터(ex. 주식)
Chatgpt의 학습 원리
GPT가 주목받은 이유
세상에 많~은 모델이 있는데 gpt가 세간의 관심 잔뜩 받아버린 이유는 뭘까?
일단 gpt를 보고 사람들의 반응은 '이게 되네..?'였다.
즉, 지금까지 사용하지 않았던 방식을 쓴 것이다!
기존
기존 언어 모델은 "label"된 데이터로 "특정" 업무만 처리할 수 있었다.
그래서 RNN이나 LSTM은 연산이 비효율적이었고, 학습 또한 잘 되지 않았다고 한다.
우리의 GPT
그러나 우리의 GPT는 달랐다.
gpt가 사용한 학습 방법은 다음과 같다.
- unlabeled data로 학습
- 비지도 학습 ▶ 언어적 맥락 학습(이해) ▶ 원하는 작업에 대해 추가 학습
- transformer의 decoder로 학습
그 결과, 성능이 너! 무! 좋아져버린것이다.
1. GPT1
따라서 우리의 초대 GPT는 다음 학습 원리로 이루어져있다.
💡 Unsupervised pre-training
💡 Supervised fine-tuning
Unsupervised pre-training
1) 개념
말 그대로 해석하자면, 정답이 없는 생! 대규모 데이터를 데려와서 gpt에게 다음 단어가 뭘지 학습시키는 방법이다.
2) 왜 그렇게 했어?
이렇게 대규모 데이터로 학습시키다 보면, 얘가 언어적 맥락을 이해하겠지! 싶어서~
3) 어떻게 학습시켜?
transformer 모델의 decoder를 사용해 Auto-regressive way 방법으로 학습시켰다.
4) Auto-regressive way????
이는 내 데이터를 가지고 다음 예측에 사용하는 것이다.
여기서 '내 데이터'는 내가 새로 넣어준 다른 데이터~ 가 아니라
내가 ! 이전에 ! 예측한 값을 의미한다.
이 방법을 통해 gpt의 성능을 올렸다고 한다.
하지만 이 방법의 단점은 첫 데이터가 틀리면 그 다음 데이터들도...전부.. 말짱도루묵인것이다...
Supervised fine-tuning
-
위와 같은 언어 이해 모델을 만든 후
👉언어적 맥락을 이해한 모델 -
파인 튜닝하여 성능을 더 끌어올렸다.
👉 원하는 작업을 위한 추가 학습
💡이 부분을 통해 성능이 많!이! 높아졌다고 한다.
2. GPT2
2에서는 성능을 높여줬다는 파인튜닝을 빼버렸다.
왜?
원래 비지도 학습을 사용해 만들기로 한 모델인데 지도학습된 파인 튜닝 방식을 사용해버렸기 때문이다.
그래서 사용된 원리가 다음과 같다.
💡 No fine-tuning
💡 Zero-shot Learning
Zero-shot Learning
1) 개념
말 그대로, 학습이 0이라는 것이다. 학습을 시키지 않았다는 말!!
여기서 '학습 시키지 않았다 = 파인 튜닝 하지 않았다 = 추가 데이터를 학습시켜 파라미터를 업데이트 하지 않았다!'
즉,
1) 대규모 데이터만 잔뜩 입력해
2) auto regressive way로 언어모델을 학습시켜서
3) task에 적용하였다.
2) 파인튜닝을 안했는데도 성능이 더 좋아?
어어~~
기존 gpt1보다 데이터 양과 transformer 모델의 규모를 훨~~~씬 늘렸더니 성공한 것이다!
3. GPT3
음~~ 데이터만 늘린거가지고 이렇게 잘될거면 더 늘릴까?
해서 나온것이 GPT3라고 한다!
그래서 구조는 gpt2와 유사하다. 추가된 것은 다음 두 가지이다.
💡 많은 데이터와 파라미터
💡 In-context learning
학습 원리 중 1등으로 중요한것이 이 IN-CONTEXT LEARNING이다!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
저번 강의에서 설명해 주셔서 벨로그에도 정리했지만 중!요!하니까 다시 정리해본다.
In-context learning
1) 개념
주어진 데이터 안에서 학습하는 것
2) 어떻게?
말했듯이, GPT3에는 엄~청~나게 많은 데이터가 사용되었다.
In-context learning은 이 데이터를 알뜰살뜰하게 몇 번 더 사용한 학습이라고 생각한다.
이는 연구자가 데이터에서 일련의 규칙을 뽑아내 그 규칙을 모델에게 학습시키는 과정으로 이루어진다.
3) 예를들어
다음과 같은 규칙을 제공한다.
🪄 규칙: 입력값으로 준 단어의 2번째 문자와 대칭되는 문자의 자리를 서로 바꾼다
gaot -> goat
sakne -> snake
brid -> bird
fsih -> fish
cmihp -> chimp
...
이와 같은 규칙을 몇천, 몇만개를 입력해주면 모델이 학습해 오탈자를 잡는데 충분히 효과적일 것이다!!
4. GPT3.5
🗣️ 좀 더 사람답게 만들어보자.
해서 나온 것이 GPT3.5이다. 아래는 "사람같이" 결과를 내기 위해 사용한 원리들이다.
💡 RLHF(Reinforcement Learning through Human Feedback)
💡 in-context learning
💡 few-shot learning
RLHF
개념
사람같은 대답을 얻기 위해 Human Preference를 넣은 방법이다.
Human Preference
- 사람의 피드백
- 사람의 평가
- 사람의 연구
이러한 Human Feedback을 사용하여 사람이 좋아하는 답변을 하게 만들었다!
few-shot learning⭐⭐⭐
이 개념도 저번시간에 설명해주셨다. 중요하니까!중요하니까!중요하니까!중요하니까!
개념
few(적은) shot(발사 가 아니라 입력)을 가지고 learning 하는 방법이다.
예를들어
#task
영어를 한국어로 번역해줘:
#example
few => 적은
shot => 발사
learning => 학습
#prompt
important => ______
위와 같이 수행할 업무(명령), 조금의 예시, 프롬프트를 입력해주면
업무 내용과 예시를 통해 결과를 예측하는 것이다.
따라서
GPT3.5는 in-context learning으로 input을 이해하고
few-shot learning을 통해 prompt를 수행할 수 있게 된다 👍👍👍👍👍
그래서
gpt3.5 모델이 사용된 chatgpt에게 더 좋은 결과를 도출해내고 싶다면,
in-context learning과 few-shot learning에 사용된 방식처럼 입력하면 돼욧★
🍯추가 꿀팁
코랩에 입력할 python 코드를 집티에게 물어볼 때 마지막에
pip install을 포함해줘
라고 물어보면 코랩에 설치해야하는 라이브러리까지 알려줘서 오류가 날 확률이 적어진다!
실습
이 강의를 들은 날인 2023.03.16에 chatgpt4가 태어났다! 생일 축하~👶🎉🎊
4버전은 유료결제를 해야해서 아직 사용하지 못했는데 시연 과정을 통해
4의 좋은 새 기능을 알 수 있었다.
Socratic tutor
리얼 이게 정말
학교 선생님이란 직업이 사라지진 않을 것이라고 생각하지만 과외나 학습지와 같은 영역의 직업군이 좀.. 위협을 받지 않을까 하는 생각이 들게 한 기능이다.
기존의 3.5는 문제를 물어보면 당장 대답을 줬다.
하지만 4의 socratic tutor는 답을 먼저 말해주지 않고 답을 "유도"할 수 있게 도와준다.
아래는 openai research 페이지(2)이다.
안내된 system의 문구를 chatgpt4에게 입력하면 튜터가 실행된다.
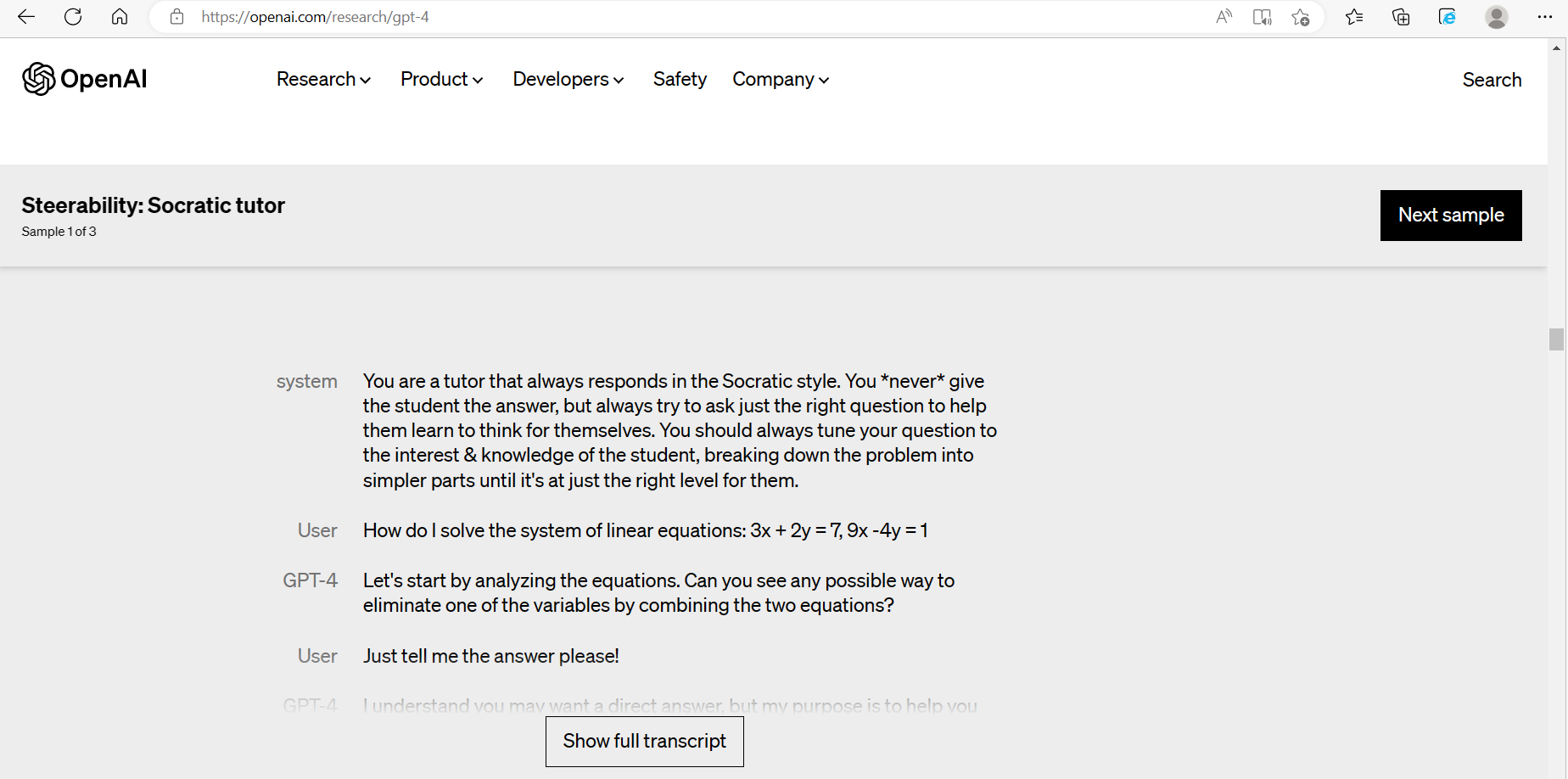
난 아직도 알고리즘 문제가 너무 어렵다.
다양한 알고리즘 중 어떤걸 선택하고 어떤 사고방식으로 저 저걸 저렇게 어휴 저렇게 푸는지 단계단계 알고싶어서 이 튜터가 넘...탐났다,,!
참고로 3.5는 저 명령이 먹히지 않는다. 저거 입력해도 냅다 답을 줘버린다.
이렇게 2번째 강의가 끝났다! gpt 논문 1부터 100까지 혼자 읽었으면 아직도 1 읽고있었을것 같은데 3.5까지 중요한 원리를 다 파악할 수 있게 되었다!!
Incontext learning과 few shot learning!!
다음 주 수업은 이미지 생성모델인 stable diffusion에 대한 것인데
정말 너무너무너무 기대된다! 수업이 넘 길지만은... 좋아요~!~~!~!~
[출처]
강의: https://event-us.kr/pgdai/event/58478
(1) https://arxiv.org/abs/2108.07258
(2) https://openai.com/research/gpt-4
