
NeRF 전체 코드가 너무 길고 어디부터 손대야 할지 갈피를 못잡던 도중..
NeRF github page에서 NeRF-pytorch를 jupyter notebook에서 실행한 약식 코드를 발견했다.
NeRF 코드를 처음 다루는 사람들이 한줄 한줄 이해하면서 따라가면 많이 도움될 것 같다!
TinyNeRF/NeRF 코드 (jupyter 버전)
import os,sys
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt#Search for GPU to run on
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#Load in data
rawData = np.load("/tiny_nerf_data.npz")
images = rawData["images"]
poses = rawData["poses"]
focal = rawData["focal"]
H, W = images.shape[1:3]
H = int(H)
W = int(W)
print(images.shape, poses.shape, focal)
testimg, testpose = images[99], poses[99]
plt.imshow(testimg)
plt.show()
images = torch.Tensor(images).to(device)
poses = torch.Tensor(poses).to(device)
testimg = torch.Tensor(testimg).to(device)
testpose = torch.Tensor(testpose).to(device)def get_rays(H, W, focal, pose):
i, j = torch.meshgrid(
torch.arange(W, dtype=torch.float32),
torch.arange(H, dtype=torch.float32)
)
i = i.t()
j = j.t()
dirs = torch.stack(
[(i-W*0.5)/focal,
-(j-H*0.5)/focal,
-torch.ones_like(i)], -1).to(device)
rays_d = torch.sum(dirs[..., np.newaxis, :] * pose[:3, :3], -1)
rays_o = pose[:3,-1].expand(rays_d.shape)
return rays_o, rays_ddef positional_encoder(x, L_embed=6):
rets = [x]
for i in range(L_embed):
for fn in [torch.sin, torch.cos]:
rets.append(fn(2.**i *x))#(2^i)*x
return torch.cat(rets, -1)
def cumprod_exclusive(tensor: torch.Tensor) -> torch.Tensor:
cumprod = torch.cumprod(tensor, -1)
cumprod = torch.roll(cumprod, 1, -1)
cumprod[..., 0] = 1.
return cumprod
def render(model, rays_o, rays_d, near, far, n_samples, rand=False):
def batchify(fn, chunk=1024*32):
return lambda inputs: torch.cat([fn(inputs[i:i+chunk]) for i in range(0, inputs.shape[0], chunk)], 0)
z = torch.linspace(near, far, n_samples).to(device)
if rand:
mids = 0.5 * (z[..., 1:] + z[...,:-1])
upper = torch.cat([mids, z[...,-1:]], -1)
lower = torch.cat([z[...,:1], mids], -1)
t_rand = torch.rand(z.shape).to(device)
z = lower + (upper-lower)*t_rand
points = rays_o[..., None,:] + rays_d[..., None,:] * z[...,:,None]
flat_points = torch.reshape(points, [-1, points.shape[-1]])
flat_points = positional_encoder(flat_points)
raw = batchify(model)(flat_points)
raw = torch.reshape(raw, list(points.shape[:-1]) + [4])
#Compute opacitices and color
sigma = F.relu(raw[..., 3])
rgb = torch.sigmoid(raw[..., :3])
#Volume Rendering
one_e_10 = torch.tensor([1e10], dtype=rays_o.dtype).to(device)
dists = torch.cat((z[..., 1:] - z[..., :-1],
one_e_10.expand(z[..., :1].shape)), dim=-1)
alpha = 1. - torch.exp(-sigma * dists)
weights = alpha * cumprod_exclusive(1. - alpha + 1e-10)
rgb_map = (weights[...,None]* rgb).sum(dim=-2)
depth_map = (weights * z).sum(dim=-1)
acc_map = weights.sum(dim=-1)
return rgb_map, depth_map, acc_map#helper functions
mse2psnr = lambda x : -10. * torch.log(x) / torch.log(torch.Tensor([10.])).to(device)
def train(model, optimizer, n_iters = 3001):
#Track loss over time for graphing
psnrs = []
iternums = []
plot_step = 500
n_samples = 64
for i in range(n_iters):
#Choose random image and use it for training
images_idx = np.random.randint(images.shape[0])
target = images[images_idx]
pose = poses[images_idx]
#Core optimizer loop
rays_o, rays_d = get_rays(H, W, focal, pose)
rgb, disp, acc = render(model, rays_o, rays_d, near=2., far=6., n_samples=n_samples, rand=True)
optimizer.zero_grad()
image_loss = torch.nn.functional.mse_loss(rgb, target)
image_loss.backward()
optimizer.step()
if i%plot_step==0:
#Render shown image above as model begins to learn
with torch.no_grad():
rays_o, rays_d = get_rays(H, W, focal, testpose)
rgb, depth, acc = render(model, rays_o, rays_d, near=2., far=6., n_samples=n_samples)
loss = torch.nn.functional.mse_loss(rgb, testimg)
psnr = mse2psnr(loss).cpu().item()
psnrs.append(psnr)
iternums.append(i)
plt.figure(figsize=(10,5))
plt.subplot(121)
#copy from gpu memory to cpu
picture = rgb.cpu()
plt.imshow(picture)
plt.title(f'Iterations: {i}')
plt.subplot(122)
plt.plot(iternums, psnrs)
plt.title('PSNR')
plt.show()VeryTinyNerfModel 클래스 (tiny_network)
class VeryTinyNerfModel(torch.nn.Module):
def __init__(self, filter_size=128, num_encoding_functions=6):
super(VeryTinyNerfModel, self).__init__()
# Input layer (default: 39 -> 128)
self.layer1 = torch.nn.Linear(3 + 3 * 2 * num_encoding_functions, filter_size)
# Layer 2 (default: 128 -> 128)
self.layer2 = torch.nn.Linear(filter_size, filter_size)
# Layer 3 (default: 128 -> 4)
self.layer3 = torch.nn.Linear(filter_size, 4)
# Short hand for torch.nn.functional.relu
self.relu = torch.nn.functional.relu
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.relu(self.layer2(x))
x = self.layer3(x)
return xrun_nerf
#Run all the actual code
nerf = VeryTinyNerfModel()
nerf = nn.DataParallel(nerf).to(device)
optimizer = torch.optim.Adam(nerf.parameters(), lr=5e-3, eps = 1e-7)
train(nerf, optimizer)Tiny_network 실행 결과
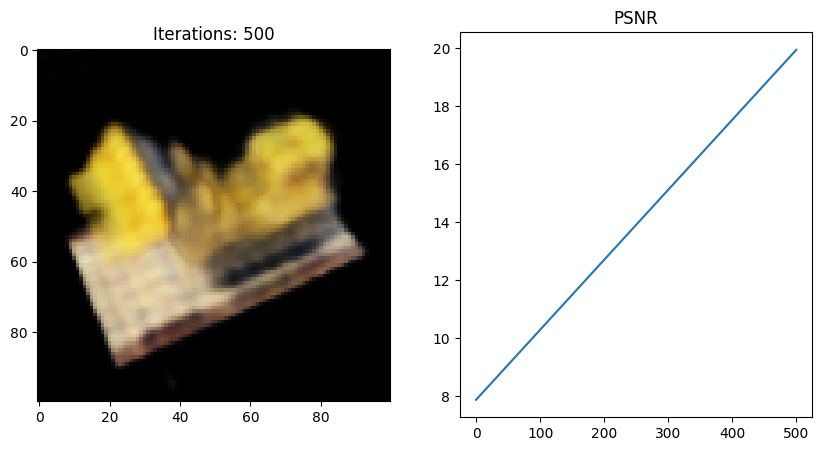
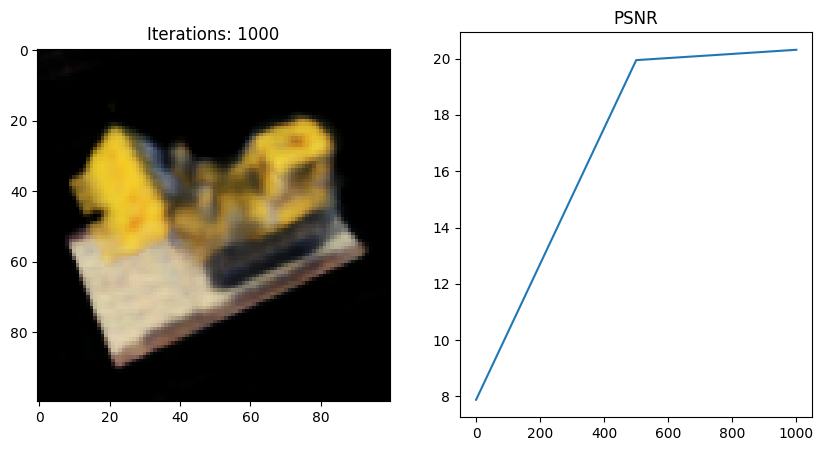
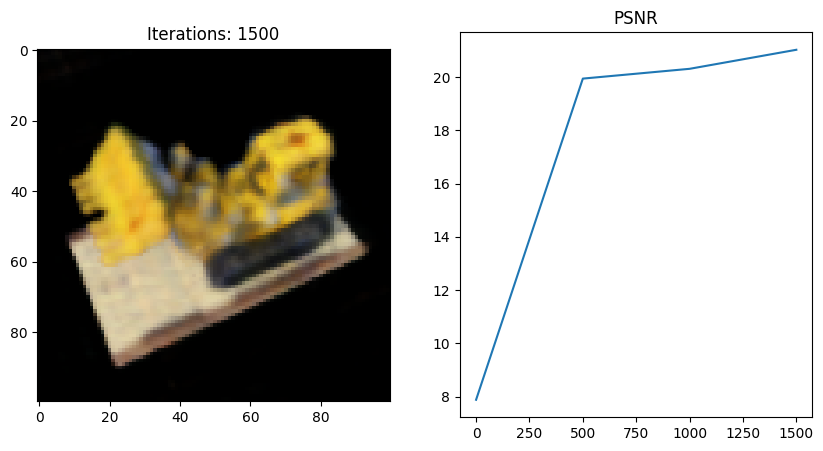
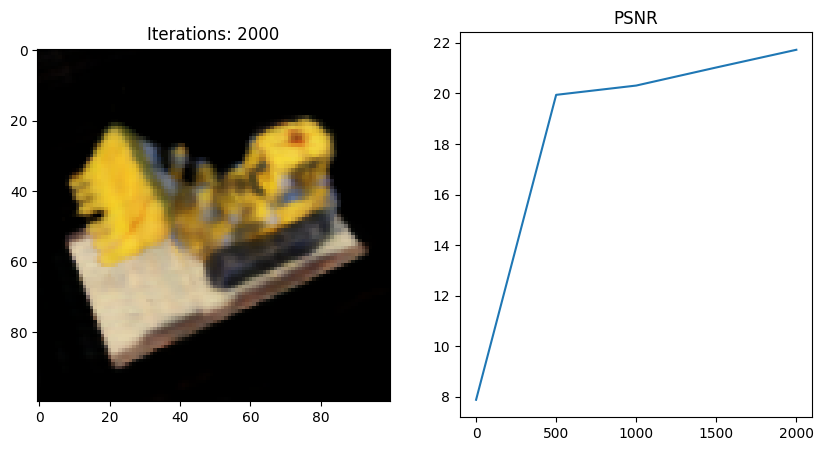
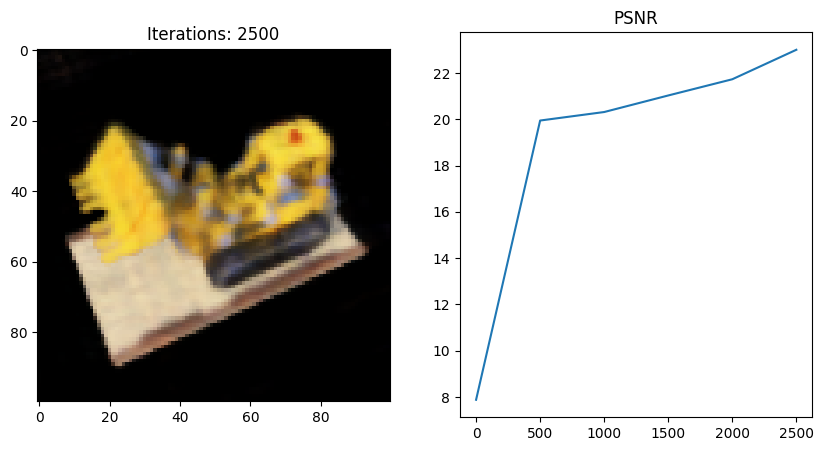
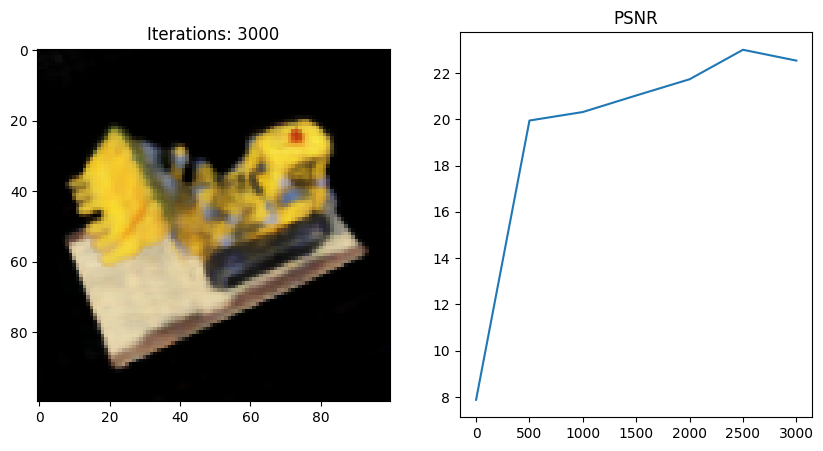
이번엔 마지막에서 두번째 코드 블럭을 내가 직접 작성한 NeRF full code로 돌려보았다.
- 다른 부분은 이해만 해도 되지만 이 부분은 NeRF의 핵심적 내용들이 집약되어 있다. network 부분은 논문의 이 network 그림을 따라가면서 꼭 다 이해하고 직접 작성해보는 연습을 해보도록 하자.
NeRF 클래스 (full_network)
- 원래 코드에서 약간 변경한 NeRF의 full network 코드로 다른 부분은 이해 정도로 넘어가도 이 코드들은 한줄씩 직접 타이핑해보면서 아래 network 구조 그림과 같이 이해해보고 모르면 다시 논문 찾아보면서 공부했다.
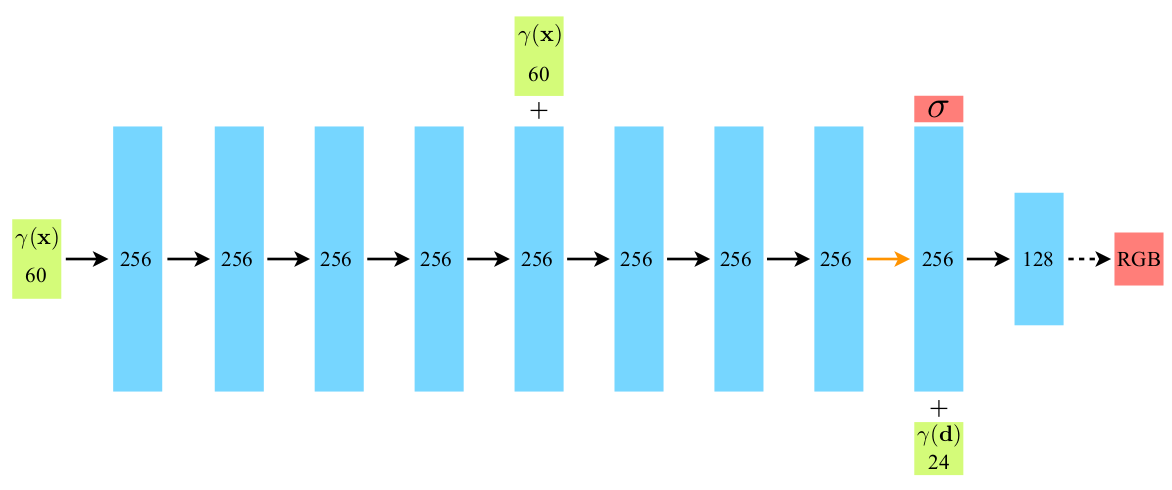
Figure: NeRF network 구조
#Larger Model definition
class NeRF(nn.Module):
def __init__(self):
super(NeRF, self).__init__()
depth = 8
width = 256
output_ch = 4
use_viewdirs = False
self.use_viewdirs = use_viewdirs
self.skips = [4]
self.input_ch = 3
self.input_ch_views = 36
#Form the layers of the neural net, pts_linear and views_linear are necessary
pts_linear = [nn.Linear(self.input_ch, width)] + [nn.Linear(width+self.input_ch, width) if i in self.skips
else nn.Linear(width, width) for i in range(depth-1)]
self.pts_linear = nn.ModuleList(pts_linear)
self.views_linear = nn.ModuleList([nn.Linear(self.input_ch_views + width, width//2)])
if use_viewdirs:
self.feature_linear = nn.Linear(width, width)
self.alpha_linear = nn.Linear(width, 1)
self.rgb_linear = nn.Linear(width//2, 3)
else:
self.output_linear = nn.Linear(width, output_ch)
def forward(self, x):
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
h=input_pts
for i, l in enumerate(self.pts_linear):
h = self.pts_linear[i](h)
h = F.relu(h)
if i in self.skips:
h = torch.cat([input_pts, h], -1)
if self.use_viewdirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1) #concate feautures with our input
for i, l in enumerate(self.views_linear):
h = self.views_linear[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
return outputs- run_nerf 코드는 동일
Full_network 실행 결과
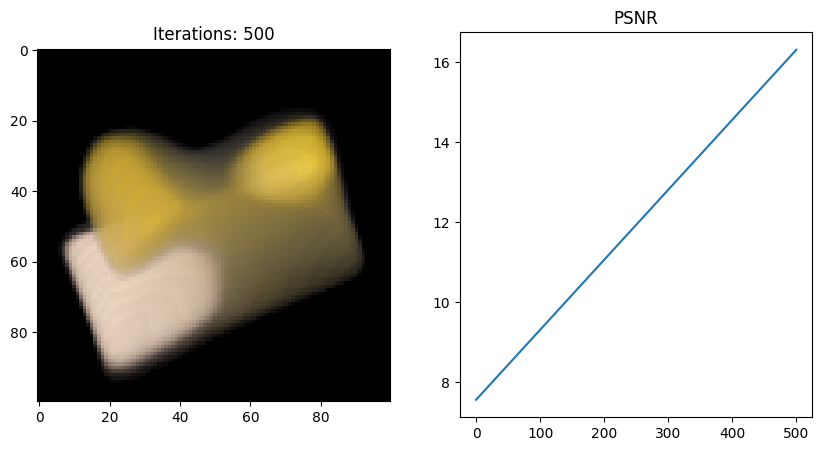
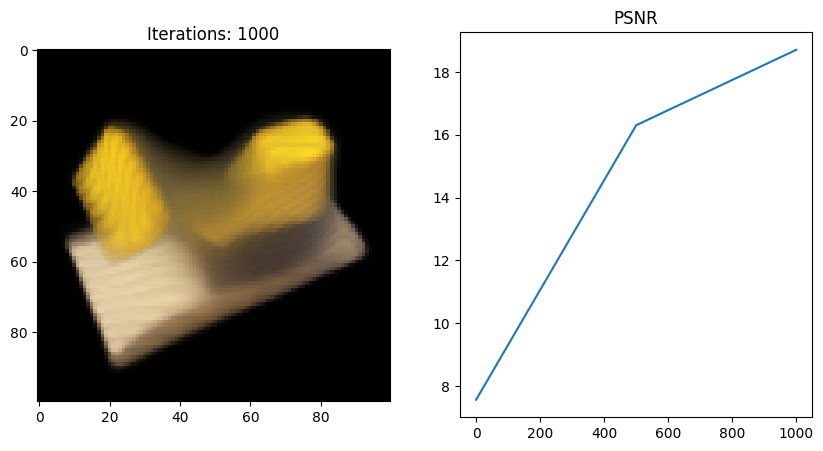
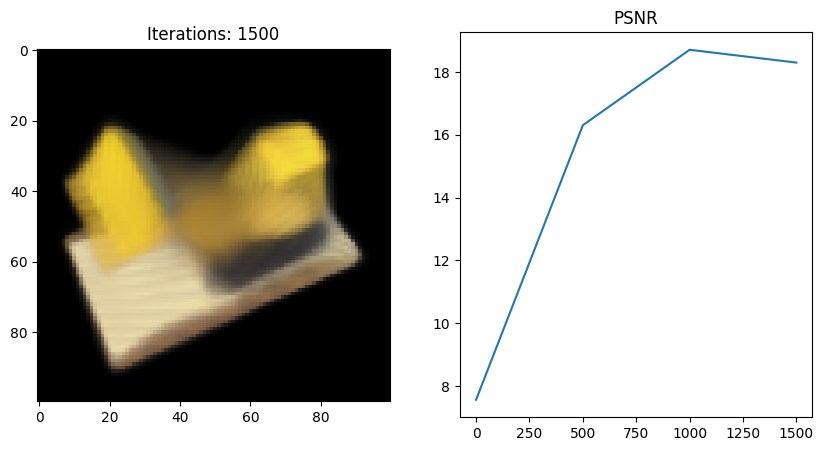
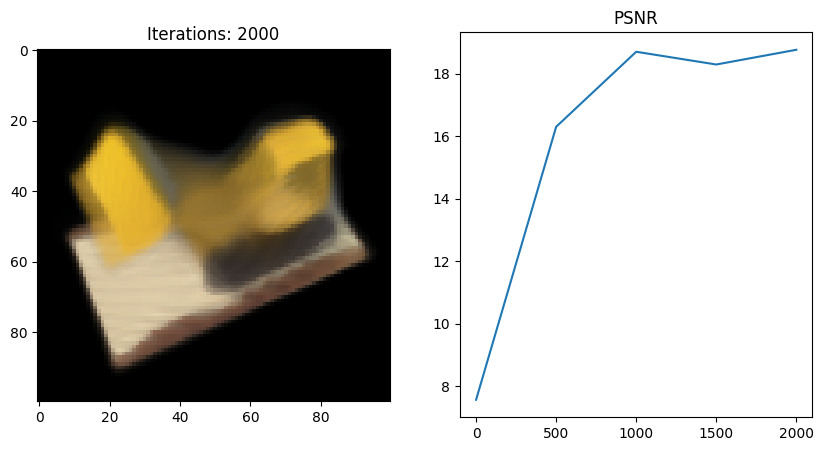
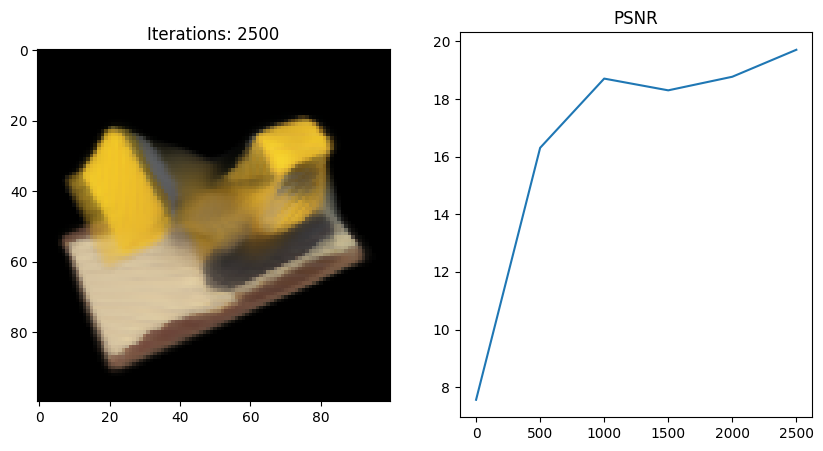
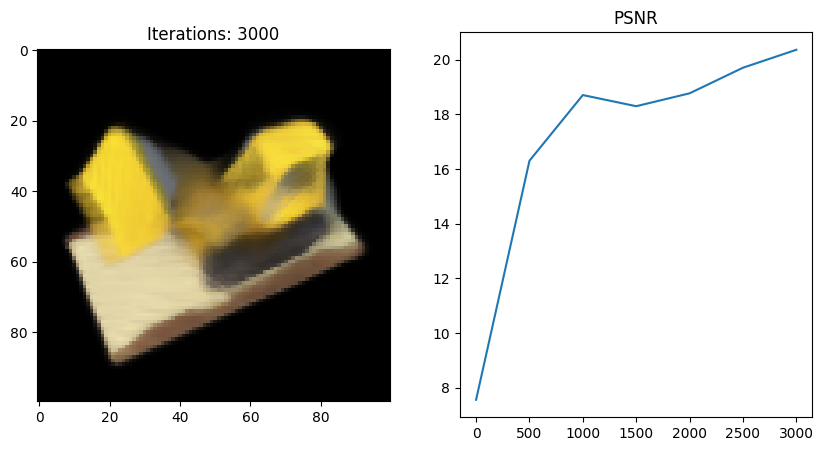
- 왜인지 모르겠지만 full network 코드를 사용했을 때 Tiny 버전보다 PSNR이 떨어지는 것 같다;;
그 이유에 대해 좀 더 분석해보고 알게되면 포스팅할 예정..
3D vision 개발자 아킬라의 블로그