오늘은 가장 기본의 되는 NeRF의 코드 분석을 하고자 한다.
저번 포스팅에 이어 NeRF에 포함된 다른 코드를 분석해보자!
NeRF 오픈소스 코드: https://github.com/yenchenlin/nerf-pytorch
분석할 코드는 run_nerf_helpers.py이다.
코드 분석
class Embedder
# Positional encoding (section 5.1)
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs
self.create_embedding_fn()
def create_embedding_fn(self):
embed_fns = []
d = self.kwargs['input_dims']
out_dim = 0
if self.kwargs['include_input']:
embed_fns.append(lambda x : x)
out_dim += d
max_freq = self.kwargs['max_freq_log2']
N_freqs = self.kwargs['num_freqs']
if self.kwargs['log_sampling']:
freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2.**0., 2.**max_freq, steps=N_freqs)
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']:
embed_fns.append(lambda x, p_fn=p_fn, freq=freq : p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
def get_embedder(multires, i=0):
if i == -1:
return nn.Identity(), 3
embed_kwargs = {
'include_input' : True,
'input_dims' : 3,
'max_freq_log2' : multires-1,
'num_freqs' : multires,
'log_sampling' : True,
'periodic_fns' : [torch.sin, torch.cos],
}
embedder_obj = Embedder(**embed_kwargs)
embed = lambda x, eo=embedder_obj : eo.embed(x)
return embed, embedder_obj.out_dim- Positional encoding을 구현하는 class이다. Positional encoding은 주어진 입력에 대한 공간적인 정보를 인코딩하여 모델에 제공하는 기술로 주로 시퀀스 데이터를 다룰 때 사용된다.
- create_embedding_fn 메소드: positional encoding 함수를 만드는 메소드입니다. 먼저, 입력 차원 수와 입력을 포함할지 여부에 따라 embed_fns 리스트를 초기화합니다. 그런 다음, 주파수 밴드를 계산하고 각 주파수에 대한 주기 함수를 적용하여 positional encoding 함수를 만듭니다.
- embed 메소드는 주어진 입력에 대해 모든 positional encoding 함수를 적용하고 결과를 연결하여 반환합니다.
- get_embedder 함수는 주어진 매개변수를 기반으로 positional encoding 함수와 출력 차원을 생성합니다. 이 함수는 주어진 매개변수 multires에 따라 주파수 밴드의 수와 최대 주파수를 조정하고, Embedder 클래스를 사용하여 positional encoding 함수를 만듭니다. 최종적으로 생성된 positional encoding 함수와 출력 차원을 반환합니다.
class NeRF
def init()
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False):
"""
"""
super(NeRF, self).__init__()
self.D = D
self.W = W
self.input_ch = input_ch
self.input_ch_views = input_ch_views
self.skips = skips
self.use_viewdirs = use_viewdirs
self.pts_linears = nn.ModuleList(
[nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])
### Implementation according to the official code release (https://github.com/bmild/nerf/blob/master/run_nerf_helpers.py#L104-L105)
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
### Implementation according to the paper
# self.views_linears = nn.ModuleList(
# [nn.Linear(input_ch_views + W, W//2)] + [nn.Linear(W//2, W//2) for i in range(D//2)])
if use_viewdirs:
self.feature_linear = nn.Linear(W, W)
self.alpha_linear = nn.Linear(W, 1)
self.rgb_linear = nn.Linear(W//2, 3)
else:
self.output_linear = nn.Linear(W, output_ch)
def forward(self, x):
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
h = input_pts
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = F.relu(h)
if i in self.skips:
h = torch.cat([input_pts, h], -1)
if self.use_viewdirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1)
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
return outputs 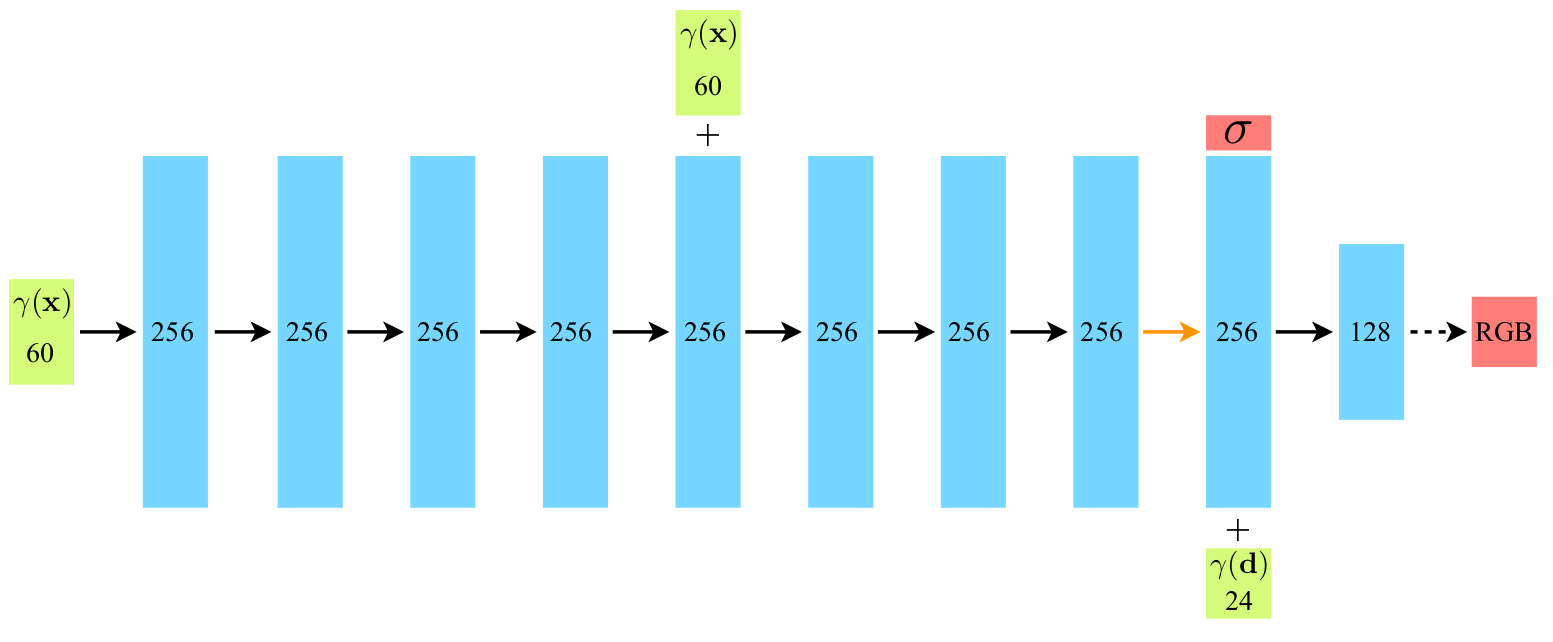
self.pts_linears = nn.ModuleList([nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])- D = 8일 때, i는 0부터 6까지 증가하며 self.skips = [4]이므로 i = 4일 때 layer에서 skip connection이 들어 옴.
- feature_linear: nn.Linear(W, W)
- alpha_linear: nn.Linear(W, 1)
- rgb_linear: nn.Linear(W//2, 3)
get_rays()
# Ray helpers
def get_rays(H, W, K, c2w):
i, j = torch.meshgrid(torch.linspace(0, W-1, W), torch.linspace(0, H-1, H)) # pytorch's meshgrid has indexing='ij'
i = i.t()
j = j.t()
dirs = torch.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -torch.ones_like(i)], -1)
# Rotate ray directions from camera frame to the world frame
rays_d = torch.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1) # dot product, equals to: [c2w.dot(dir) for dir in dirs]
# Translate camera frame's origin to the world frame. It is the origin of all rays.
rays_o = c2w[:3,-1].expand(rays_d.shape)
return rays_o, rays_d- Extrinsic matrix

- Intrinsic matrix
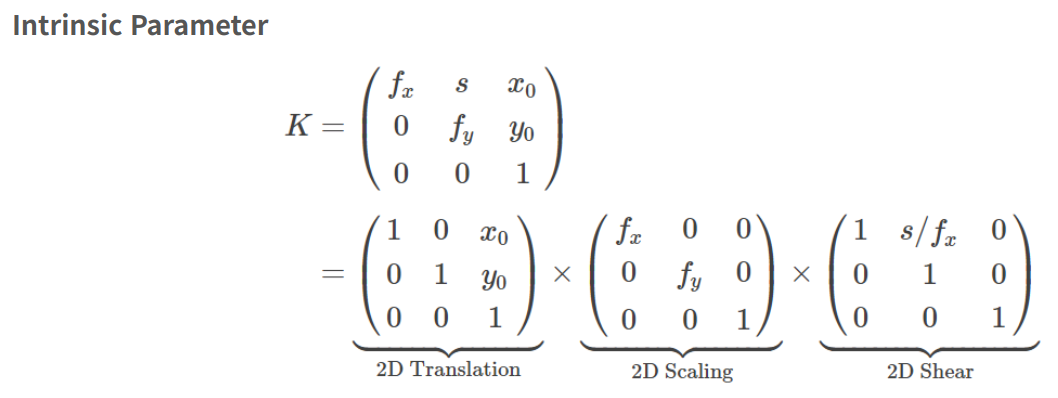
dirs = torch.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -torch.ones_like(i)], -1)- dirs:
- torch.stack([(i - )/, -(j - )/, -torch.ones_like(i)], -1)과 같이 normalized plane으로 mapping
- rays_d: rotation matrix인 c2w[:3, :3]을 이용해서 ray의 방향을 계산
- rays_o: translation matrix인 c2w[:3, -1]을 이용해서 ray의 tranlation을 계산
- rays_o와 rays_d를 return
sample_pdf
# Hierarchical sampling (section 5.2)
def sample_pdf(bins, weights, N_samples, det=False, pytest=False):
# Get pdf
weights = weights + 1e-5 # prevent nans
pdf = weights / torch.sum(weights, -1, keepdim=True)
cdf = torch.cumsum(pdf, -1)
cdf = torch.cat([torch.zeros_like(cdf[...,:1]), cdf], -1) # (batch, len(bins))
# Take uniform samples
if det:
u = torch.linspace(0., 1., steps=N_samples)
u = u.expand(list(cdf.shape[:-1]) + [N_samples])
else:
u = torch.rand(list(cdf.shape[:-1]) + [N_samples])
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
new_shape = list(cdf.shape[:-1]) + [N_samples]
if det:
u = np.linspace(0., 1., N_samples)
u = np.broadcast_to(u, new_shape)
else:
u = np.random.rand(*new_shape)
u = torch.Tensor(u)
# Invert CDF
u = u.contiguous()
inds = torch.searchsorted(cdf, u, right=True)
below = torch.max(torch.zeros_like(inds-1), inds-1)
above = torch.min((cdf.shape[-1]-1) * torch.ones_like(inds), inds)
inds_g = torch.stack([below, above], -1) # (batch, N_samples, 2)
# cdf_g = tf.gather(cdf, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
# bins_g = tf.gather(bins, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
matched_shape = [inds_g.shape[0], inds_g.shape[1], cdf.shape[-1]]
cdf_g = torch.gather(cdf.unsqueeze(1).expand(matched_shape), 2, inds_g)
bins_g = torch.gather(bins.unsqueeze(1).expand(matched_shape), 2, inds_g)
denom = (cdf_g[...,1]-cdf_g[...,0])
denom = torch.where(denom<1e-5, torch.ones_like(denom), denom)
t = (u-cdf_g[...,0])/denom
samples = bins_g[...,0] + t * (bins_g[...,1]-bins_g[...,0])
return samples이 코드는 확률 밀도 함수(PDF)로부터 샘플을 추출하는 함수입니다. 여기서는 hierarchical sampling이라는 방법을 사용하여 PDF로부터 샘플을 추출합니다. 코드의 각 부분을 살펴보겠습니다.
먼저, 입력으로 주어진 bins는 구간(bin)이고, weights는 해당 구간의 가중치입니다. N_samples는 추출할 샘플의 수입니다. det과 pytest는 부가적인 플래그로, deterministic sampling과 pytest용으로 사용됩니다.
주어진 가중치를 사용하여 PDF를 계산합니다. 이를 위해 가중치를 정규화하고, 각 구간의 누적 분포 함수(CDF)를 계산합니다.
uniform distribution에서 샘플을 추출합니다. 이때 det이 True이면 등간격으로, False이면 무작위로 샘플을 추출합니다.
pytest 모드가 활성화되어 있다면, Numpy의 난수 생성을 사용하여 샘플을 덮어씌웁니다.
CDF의 역함수를 이용하여 uniform 샘플을 실제 값으로 변환합니다. 이를 위해 각 샘플에 대해 해당하는 구간의 경계값을 찾습니다.
찾은 구간에 대해 선형 보간을 수행하여 최종 샘플을 계산합니다.
이 함수는 PyTorch를 사용하여 작성되었으며, 주어진 입력에 따라 벡터화되어 효율적으로 동작합니다.
- pdf와 cdf 계산 후 samples를 return한다.