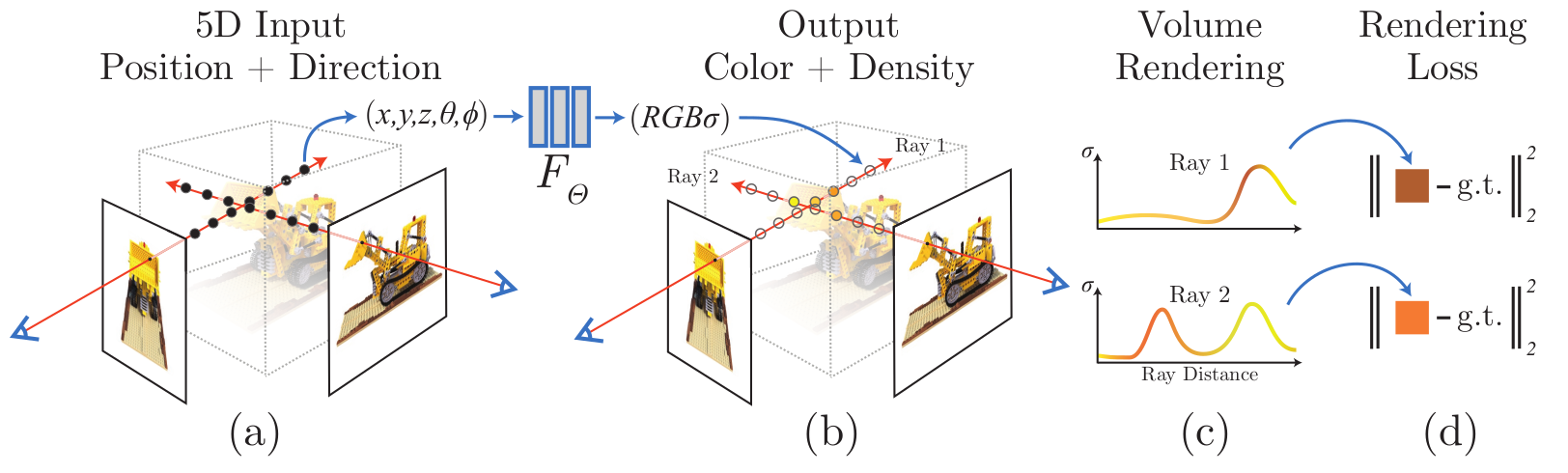
오늘은 가장 기본의 되는 NeRF의 코드 분석을 하고자 한다.
코드가 넘 길고 많지만..꼭 넘어야 하는 산이기에 열심히 해보자.
NeRF 오픈소스 코드: https://github.com/yenchenlin/nerf-pytorch
분석할 코드는 run_nerf.py이다.
코드 분석
batchfy

- chunk는 한번에 처리할 수 있는 ray의 개수이다. input을 chunk 단위로 나눠서 fn에 넣고 torch.cat으로 합친다.
batchify_rays
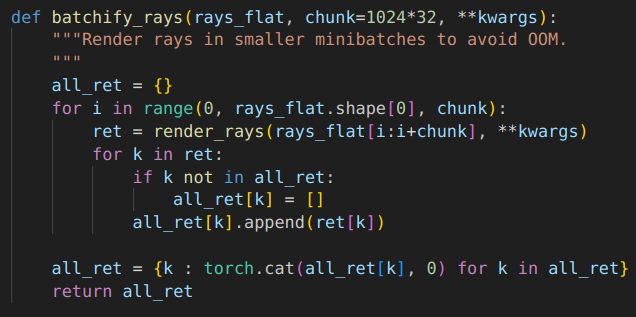
- render_rays() 결과인 ret을 all_ret dictionary에 담는다.
render
def render(H, W, K, chunk=1024*32, rays=None, c2w=None, ndc=True,
near=0., far=1.,
use_viewdirs=False, c2w_staticcam=None,
**kwargs):
"""Render rays
Args:
H: int. Height of image in pixels.
W: int. Width of image in pixels.
focal: float. Focal length of pinhole camera.
chunk: int. Maximum number of rays to process simultaneously. Used to
control maximum memory usage. Does not affect final results.
rays: array of shape [2, batch_size, 3]. Ray origin and direction for
each example in batch.
c2w: array of shape [3, 4]. Camera-to-world transformation matrix.
ndc: bool. If True, represent ray origin, direction in NDC coordinates.
near: float or array of shape [batch_size]. Nearest distance for a ray.
far: float or array of shape [batch_size]. Farthest distance for a ray.
use_viewdirs: bool. If True, use viewing direction of a point in space in model.
c2w_staticcam: array of shape [3, 4]. If not None, use this transformation matrix for
camera while using other c2w argument for viewing directions.
Returns:
rgb_map: [batch_size, 3]. Predicted RGB values for rays.
disp_map: [batch_size]. Disparity map. Inverse of depth.
acc_map: [batch_size]. Accumulated opacity (alpha) along a ray.
extras: dict with everything returned by render_rays().
"""
if c2w is not None:
# special case to render full image
rays_o, rays_d = get_rays(H, W, K, c2w)
else:
# use provided ray batch
rays_o, rays_d = rays
if use_viewdirs:
# provide ray directions as input
viewdirs = rays_d
if c2w_staticcam is not None:
# special case to visualize effect of viewdirs
rays_o, rays_d = get_rays(H, W, K, c2w_staticcam)
viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True)
viewdirs = torch.reshape(viewdirs, [-1,3]).float()
sh = rays_d.shape # [..., 3]
if ndc:
# for forward facing scenes
rays_o, rays_d = ndc_rays(H, W, K[0][0], 1., rays_o, rays_d)
# Create ray batch
rays_o = torch.reshape(rays_o, [-1,3]).float()
rays_d = torch.reshape(rays_d, [-1,3]).float()
near, far = near * torch.ones_like(rays_d[...,:1]), far * torch.ones_like(rays_d[...,:1])
rays = torch.cat([rays_o, rays_d, near, far], -1)
if use_viewdirs:
rays = torch.cat([rays, viewdirs], -1)
# Render and reshape
all_ret = batchify_rays(rays, chunk, **kwargs)
for k in all_ret:
k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:])
all_ret[k] = torch.reshape(all_ret[k], k_sh)
k_extract = ['rgb_map', 'disp_map', 'acc_map']
ret_list = [all_ret[k] for k in k_extract]
ret_dict = {k : all_ret[k] for k in all_ret if k not in k_extract}
return ret_list + [ret_dict]
- c2w: Camera to World paramter
- get_rays(H, W, K, c2w)를 통해 rays_o, rays_d를 추출
- k_sh는 sh tensor를 변형한 것이며 ret_list는 k가 'rgb_map', 'disp_map', 'acc_map' 중 하나일 때 all_ret[k]를 원소로 하는 리스트이며 ret_dict는 k가 위 3가지 map에 속하지 않을 때 key를 k, value를 all_ret[k]로 하는 리스트이다.
render_path
def render_path(render_poses, hwf, K, chunk, render_kwargs, gt_imgs=None, savedir=None, render_factor=0):
H, W, focal = hwf
if render_factor!=0:
# Render downsampled for speed
H = H//render_factor
W = W//render_factor
focal = focal/render_factor
rgbs = []
disps = []
t = time.time()
for i, c2w in enumerate(tqdm(render_poses)):
print(i, time.time() - t)
t = time.time()
rgb, disp, acc, _ = render(H, W, K, chunk=chunk, c2w=c2w[:3,:4], **render_kwargs)
rgbs.append(rgb.cpu().numpy())
disps.append(disp.cpu().numpy())
if i==0:
print(rgb.shape, disp.shape)
"""
if gt_imgs is not None and render_factor==0:
p = -10. * np.log10(np.mean(np.square(rgb.cpu().numpy() - gt_imgs[i])))
print(p)
"""
if savedir is not None:
rgb8 = to8b(rgbs[-1])
filename = os.path.join(savedir, '{:03d}.png'.format(i))
imageio.imwrite(filename, rgb8)
rgbs = np.stack(rgbs, 0)
disps = np.stack(disps, 0)
return rgbs, disps
- Speed를 위해 downsample하기
- render() 함수를 통해 rgbs, disps를 구하고 np.stack으로 처리하여 return
create_nerf
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)
input_ch_views = 0
embeddirs_fn = None
if args.use_viewdirs:
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
output_ch = 5 if args.N_importance > 0 else 4
skips = [4]
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars = list(model.parameters())
model_fine = None
if args.N_importance > 0:
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars += list(model_fine.parameters())
network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
# Create optimizer
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
start = 0
basedir = args.basedir
expname = args.expname
##########################
# Load checkpoints
if args.ft_path is not None and args.ft_path!='None':
ckpts = [args.ft_path]
else:
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if 'tar' in f]
print('Found ckpts', ckpts)
if len(ckpts) > 0 and not args.no_reload:
ckpt_path = ckpts[-1]
print('Reloading from', ckpt_path)
ckpt = torch.load(ckpt_path)
start = ckpt['global_step']
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
# Load model
model.load_state_dict(ckpt['network_fn_state_dict'])
if model_fine is not None:
model_fine.load_state_dict(ckpt['network_fine_state_dict'])
##########################
render_kwargs_train = {
'network_query_fn' : network_query_fn,
'perturb' : args.perturb,
'N_importance' : args.N_importance,
'network_fine' : model_fine,
'N_samples' : args.N_samples,
'network_fn' : model,
'use_viewdirs' : args.use_viewdirs,
'white_bkgd' : args.white_bkgd,
'raw_noise_std' : args.raw_noise_std,
}
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train}
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0.
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizerraw2outputs
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False):
"""Transforms model's predictions to semantically meaningful values.
Args:
raw: [num_rays, num_samples along ray, 4]. Prediction from model.
z_vals: [num_rays, num_samples along ray]. Integration time.
rays_d: [num_rays, 3]. Direction of each ray.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray.
disp_map: [num_rays]. Disparity map. Inverse of depth map.
acc_map: [num_rays]. Sum of weights along each ray.
weights: [num_rays, num_samples]. Weights assigned to each sampled color.
depth_map: [num_rays]. Estimated distance to object.
"""
raw2alpha = lambda raw, dists, act_fn=F.relu: 1.-torch.exp(-act_fn(raw)*dists)
dists = z_vals[...,1:] - z_vals[...,:-1]
dists = torch.cat([dists, torch.Tensor([1e10]).expand(dists[...,:1].shape)], -1) # [N_rays, N_samples]
dists = dists * torch.norm(rays_d[...,None,:], dim=-1)
rgb = torch.sigmoid(raw[...,:3]) # [N_rays, N_samples, 3]
noise = 0.
if raw_noise_std > 0.:
noise = torch.randn(raw[...,3].shape) * raw_noise_std
# Overwrite randomly sampled data if pytest
if pytest:
np.random.seed(0)
noise = np.random.rand(*list(raw[...,3].shape)) * raw_noise_std
noise = torch.Tensor(noise)
alpha = raw2alpha(raw[...,3] + noise, dists) # [N_rays, N_samples]
# weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True)
weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1]
rgb_map = torch.sum(weights[...,None] * rgb, -2) # [N_rays, 3]
depth_map = torch.sum(weights * z_vals, -1)
disp_map = 1./torch.max(1e-10 * torch.ones_like(depth_map), depth_map / torch.sum(weights, -1))
acc_map = torch.sum(weights, -1)
if white_bkgd:
rgb_map = rgb_map + (1.-acc_map[...,None])
return rgb_map, disp_map, acc_map, weights, depth_map- NeRF() 함수는 coarse sampling이며 model.parameters()를 list에 담아 grad_vars에 저장함.
- if args.N_importance > 0 이라면 NeRF()함수는 fine_sampling 역할을 하며 이를 model 변수에 저장한다. 이 때 model.parameters()는 list로 형 변환하여 grad_vars 변수에 더해준다.
render_rays
def render_rays(ray_batch,
network_fn,
network_query_fn,
N_samples,
retraw=False,
lindisp=False,
perturb=0.,
N_importance=0,
network_fine=None,
white_bkgd=False,
raw_noise_std=0.,
verbose=False,
pytest=False):
"""Volumetric rendering.
Args:
ray_batch: array of shape [batch_size, ...]. All information necessary
for sampling along a ray, including: ray origin, ray direction, min
dist, max dist, and unit-magnitude viewing direction.
network_fn: function. Model for predicting RGB and density at each point
in space.
network_query_fn: function used for passing queries to network_fn.
N_samples: int. Number of different times to sample along each ray.
retraw: bool. If True, include model's raw, unprocessed predictions.
lindisp: bool. If True, sample linearly in inverse depth rather than in depth.
perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified
random points in time.
N_importance: int. Number of additional times to sample along each ray.
These samples are only passed to network_fine.
network_fine: "fine" network with same spec as network_fn.
white_bkgd: bool. If True, assume a white background.
raw_noise_std: ...
verbose: bool. If True, print more debugging info.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model.
disp_map: [num_rays]. Disparity map. 1 / depth.
acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model.
raw: [num_rays, num_samples, 4]. Raw predictions from model.
rgb0: See rgb_map. Output for coarse model.
disp0: See disp_map. Output for coarse model.
acc0: See acc_map. Output for coarse model.
z_std: [num_rays]. Standard deviation of distances along ray for each
sample.
"""
N_rays = ray_batch.shape[0]
rays_o, rays_d = ray_batch[:,0:3], ray_batch[:,3:6] # [N_rays, 3] each
viewdirs = ray_batch[:,-3:] if ray_batch.shape[-1] > 8 else None
bounds = torch.reshape(ray_batch[...,6:8], [-1,1,2])
near, far = bounds[...,0], bounds[...,1] # [-1,1]
t_vals = torch.linspace(0., 1., steps=N_samples)
if not lindisp:
z_vals = near * (1.-t_vals) + far * (t_vals)
else:
z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))
z_vals = z_vals.expand([N_rays, N_samples])
if perturb > 0.:
# get intervals between samples
mids = .5 * (z_vals[...,1:] + z_vals[...,:-1])
upper = torch.cat([mids, z_vals[...,-1:]], -1)
lower = torch.cat([z_vals[...,:1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
z_vals = lower + (upper - lower) * t_rand
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples, 3]
# raw = run_network(pts)
raw = network_query_fn(pts, viewdirs, network_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
if N_importance > 0:
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
z_vals_mid = .5 * (z_vals[...,1:] + z_vals[...,:-1])
z_samples = sample_pdf(z_vals_mid, weights[...,1:-1], N_importance, det=(perturb==0.), pytest=pytest)
z_samples = z_samples.detach()
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples + N_importance, 3]
run_fn = network_fn if network_fine is None else network_fine
# raw = run_network(pts, fn=run_fn)
raw = network_query_fn(pts, viewdirs, run_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
ret = {'rgb_map' : rgb_map, 'disp_map' : disp_map, 'acc_map' : acc_map}
if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return ret-
N_rays: 레이의 개수를 나타내는 변수입니다. ray_batch의 첫 번째 차원의 크기입니다.
-
rays_o, rays_d: 각 레이의 출발점(origin)과 방향(direction)을 나타내는 변수입니다. ray_batch에서 각각 첫 3개의 값과 그 다음 3개의 값을 가져와서 형태를 [N_rays, 3]로 만듭니다.
-
viewdirs: 뷰 디렉션(view direction)을 나타내는 변수입니다. ray_batch의 마지막 3개의 값입니다. 그러나 ray_batch의 마지막 차원이 8보다 큰 경우에만 존재하며, 그렇지 않으면 None으로 설정됩니다.
-
bounds: 각 레이의 시작과 끝을 나타내는 변수입니다. ray_batch에서 6번째와 7번째 값으로 구성되며, 이를 [N_rays, 1, 2]의 형태로 재구성합니다.
-
near, far: bounds에서 추출된 값으로, 각 레이의 시작점과 끝점을 나타냅니다.
-
t_vals: 레이의 거리 값을 나타내는 변수입니다. 0부터 1까지의 값을 N_samples 수만큼 등간격으로 생성합니다.
-
z_vals: 레이의 깊이(depth) 값을 나타내는 변수입니다. lindisp가 False인 경우에는 선형으로 거리를 계산하고, True인 경우에는 로그 스케일로 거리를 계산합니다. 이 값은 각 레이와 각 샘플에 대해 계산되며, [N_rays, N_samples]의 형태로 확장됩니다.
-
if perturb > 0일 때
- mids, upper, lower를 계산한 뒤, z_vals와 같은 크기의 t_rand 생성.
- z_vals = lower + (upper - lower) * t_rand와 같이 ray의 깊이를 구한 뒤
- pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] 에서 point의 위치 계산
if N_importance > 0:
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
z_vals_mid = .5 * (z_vals[...,1:] + z_vals[...,:-1])
z_samples = sample_pdf(z_vals_mid, weights[...,1:-1], N_importance, det=(perturb==0.), pytest=pytest)
z_samples = z_samples.detach()
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples + N_importance, 3]
run_fn = network_fn if network_fine is None else network_fine
# raw = run_network(pts, fn=run_fn)
raw = network_query_fn(pts, viewdirs, run_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
ret = {'rgb_map' : rgb_map, 'disp_map' : disp_map, 'acc_map' : acc_map}
if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return ret
- N_importance > 0 이면 추가 샘플링이 가능하며 이 때 fine sampling을 진행한다.
이 때 위와 같은 방식으로 ray의 깊이인 z_vals와 포인트의 위치인 pts를 계산한다. - raw = network_query_fn(pts, viewdirs, run_fn)를 통해 raw값을 구한다.
- rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
- raw2outputs 함수를 통해 raw를 입력으로 넣었을 때 output으로 rgb_map, disp_map, acc_map, weights, depth_map을 얻을 수 있다.
- 최종적으로 ret dictionary에 rgb, disp, acc, z_std를 key로 하여 값들을 저장하고 ret을 return하게 된다.
- 참고 블로그
https://xoft.tistory.com/15