Nerfies 논문 : https://arxiv.org/pdf/2011.12948.pdf
Nerfies 프로젝트 홈페이지 : https://nerfies.github.io/
Dynamic scene NeRF의 대표 논문.
Selfies를 찍을 때 정도의 흔들림을 보정해서 안정적인 rendering을 제공하는 모델로 이해했는데
제대로 읽어봅시다ㅎㅎ
먼저 Motivaiton, Contributions, Future direction을 먼저 제시하니 급한 분들은 이것만 읽어도 내용이 대강 파악이 될 것입니다.
Motivation
- Hand-held 카메라로 사람을 모델링할 때 문제점 2가지
- Nonrigidity: 완벽하게 가만히 포즈를 취하기가 힘들다.
- Challenging materials: 머리카락, 유리, 그리고 earings 등은 reconstruct하기가 힘들다.
- Regularization이 없는 경우 deformation field는 왜곡와 over-fitting에 취약함.
Contributions
- Nerual network에 의해 정의된 deformation field에 적합한 rigidly priors 사용
- 제한 없는 deformation field의 사용은 under-constrained optimization 문제로 이어질 수 있다. 따라서 우리는 continuous, bad local minima를 피하는 coarse-to-fine annealing 기법인 elastic regularization을 적용했다.
- NeRF의 coarse-to-fine sampling에서 더 발전된 기법을 적용한 것으로 이해함.
- Casual mobile phone 캡쳐들로부터 free-viewpoint selfies를 재구성
즉, 고퀄리티의 Selfie를 찍을 수 있다!
Future direction
- 더 크고 빠른 움직임을 다룰 수 있도록 함.
- Topological variations (입을 벌리거나 다무는 동작)을 잘 포착하지 못하는 문제 해결해야 함.
- 학습/추론 속도 개선
Abstract
- 우리는 모바일 phone으로 캡쳐된 사진/비디오를 이용하여 deformable scene을 photorealistically 재구성하는 최초의 방법을 제시한다.
- 우리의 접근법은 추가로 각 관찰된 point들을 canonical 5D NeRF에 warp하는 연속적 volumetric deformation을 최적화하는 것에 의해 neural radiance fields (NeRF)를 변형하였다.
- 우리는 NeRF와 유사한 deformation fields가 local minima에 취약하고 더 robust한 최적화를 할 수 있게 해주는 좌표 기반의 모델들을 위한 coarse-to-fine 최적화 방법을 제시한다.
- Elastic regularization: geometry processing과 NeRF-like model들에 대한 physical simulation을 이용하는 것에 의해, 우리는 deformation field의 elastic regularization을 제시하여 robustness를 높였다.
- 우리는 우리의 방법이 causally captured selfie photoes/videos를 deformable NeRF models로 바꿔서 임의의 시점으로부터 subject의 photorealistic rendering을 허용하여 이를 "nerfies"라고 부른다.
- 우리는 다른 viewpoint들에서 같은 포즈의 train/validation 이미지들을 생성하면서 2개의 휴대폰을 사용하여 time-synchronized data를 수집하는 것에 의해 우리의 방법을 평가했다.
- 우리는 우리의 방법이 non-rigidly deforming scene들을 신뢰성있게 재구성하며 고해상도로 unseen view들을 재현하는 것을 보여주었다.
- 우리의 방법은 Neural Radiance Fields (NeRF)를 model shape deformation에 일반화하는 것에 의해 위 challenge들을 다루는 접근법을 소개한다.
- 우리의 기법은 짧은 video로부터 free-viewpoint를 제공하는 고해상도의 3D reconstruction을 다루면서 머리카락, 안경, 그리고 다른 view-dependent 물질들을 정확하게 캡쳐한다.
1. Introduction
- Hand-held camera를 사용하여 사람들을 모델링하는 것을 어렵게 만드는 요인은 다음과 같다.
- Nonrigidity: 우리는 완벽하게 가만히 있기가 힘들다.
- Challenging meterials: 대부분의 reconstruction 방법들에 사용되는 가정을 깨는 머리카락, 유리, 그리고 earings 등
- 우리는 deformation fields를 multi-layer perceptron (MLP)로 나타냈고 관측에 따라 달라지는 각 이미지에 대해 학습된 latent code에 의해 조절된다.
- 제한이 없는 경우, the deformation fields는 왜곡과 over-fitting에 취약하다.
- 우리는 Mesh fitting에 성공적으로 적용된 elastic energy formulation을 적용했다.
- 그러나 우리의 volumetric deformation field는 regularization을 크게 단순화했는데 이는 자동 미분을 통해 deformation field의 Jacobian을 쉽게 계산할 수 있고 이것의 singular value를 직접 regularize할 수 있기 때문이다.
- Our contributions
- NeRF의 확장: 각 관측에서 deformation field를 최적화하는 non-rigidly deforming object들을 다룬다.
- Neural network에 의해 정의된 deformation fields에 적합한 rigidly priors
- 최적화 중에 높은 주파수를 모델링하기 위한 deformation field의 capacity를 조절하는 coarse-to-fine regularization 접근법
- Casual mobile phone 캡쳐들로부터 free-viewpoint selfies를 재구성하는 시스템
2. Related work
Non-Rigid Reconstruction
- Non-rigid reconstruction은 scene을 geometric model과 deformation model로 분해하여 각 관측에 대해 geometric model을 분해한다.
- Dynamic-Fusion: 공간에서 움직이는 하나의 RGBD 카메라를 써서 canonical model, a deformation, 그리고 카메라 pose를 동시에 구한다.
- 이전의 연구와는 다르게, 우리의 시스템은 depth나 multi-view capture 시스템을 요구하지 않고 monocular RGB 입력에 대해 작동한다.
- Neural Volumes: 3D CNN으로부터 regress된 voxel grid와 warp field를 사용하여 deformable scene의 3D 표현을 학습한다.
- 그러나 그들의 방법은 하나의 카메라로부터 캡쳐된 수십개의 synchronized 카메라들을 요구한다.
- Yoon et al.은 움직이는 카메라 궤적으로부터 dynamic scene을 재구성하지만 이 방법은 monocular depth estimation 형태의 강한 semantic priors에 강하게 의존한다.
- ShapeFlow는 학습된 template으로 divergence-free deformations인 3D shapes를 학습한다.
- 대신에 우리는 elastic energy regularization을 제시한다.
Domain-Specific Modeling
- 기존 연구와 달리 우리의 연구는 domain-specific knowledge에만 의존하지 않고 인간의 안경과 머리카락과 같은 whole scene을 모델링할 수 있게 해준다.
Coordinate-based Models
- 우리의 방법은 좌표 기반의 모델의 성공 위에 만들어졌으며 spatial field를 multilayer perceptron (MLP)의 weights에 encode하여 discrete representations보다 더 적은 메모리를 요구한다.
- 우리의 연구는 NeRF가 non-rigid scene들을 다루도록 확장한다.
Concurrent work
1) 우리는 시간 대신에 per-example latent와 함께 deformation을 조절한다.
2) 우리는 deformation field의 as-rigid-as-possible regularization을 제시한다.
3) Coarse-to-fine regularization을 제시하여 local minima에 빠지는 것을 막는다.
4) Deformation field의 향상된 SE(3)를 제시한다.
- 다른 concurrent work들은 monocular depth estimation이나 flow-estimation과 같이 외부적인 supervision을 이용하여 ambiguities를 해결한다.
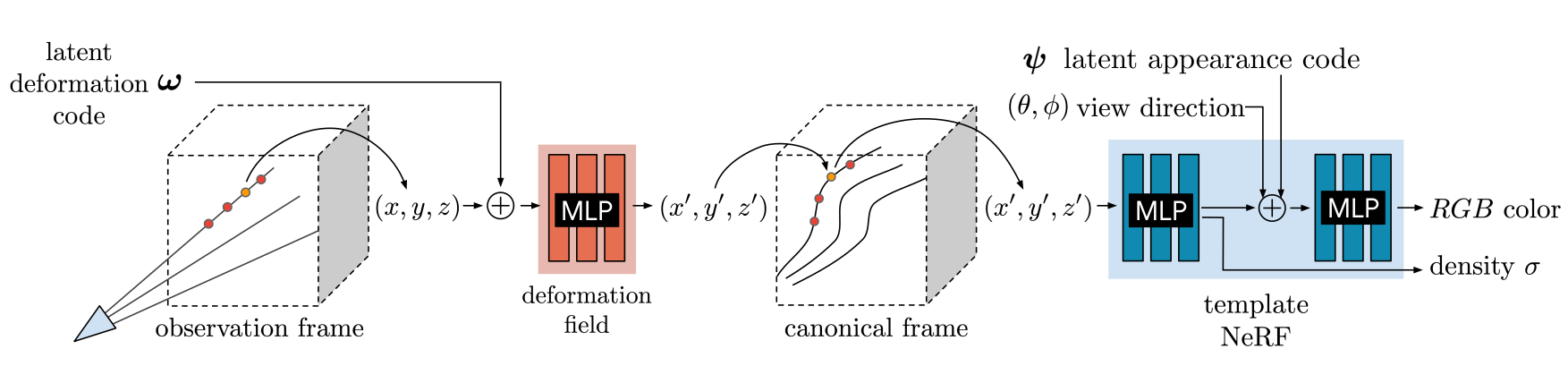
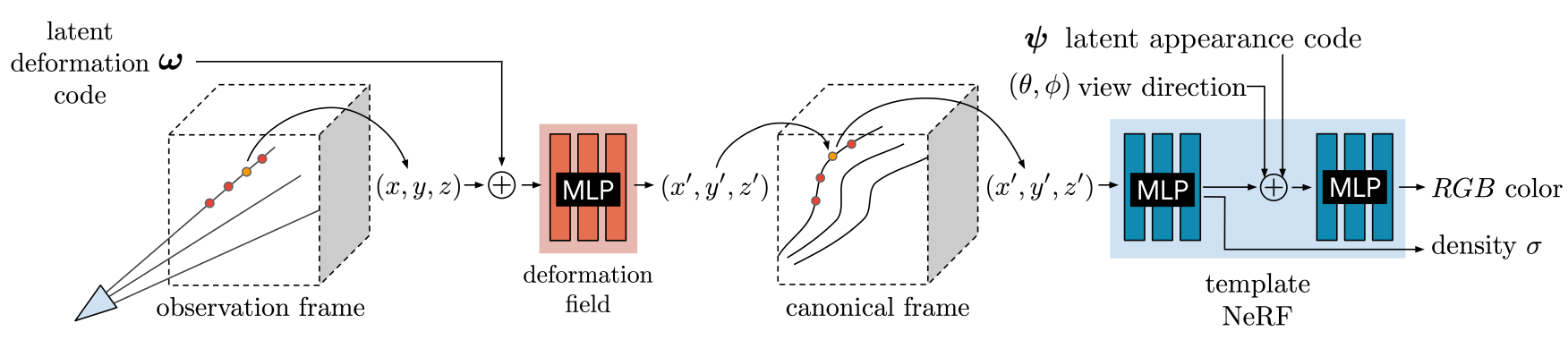
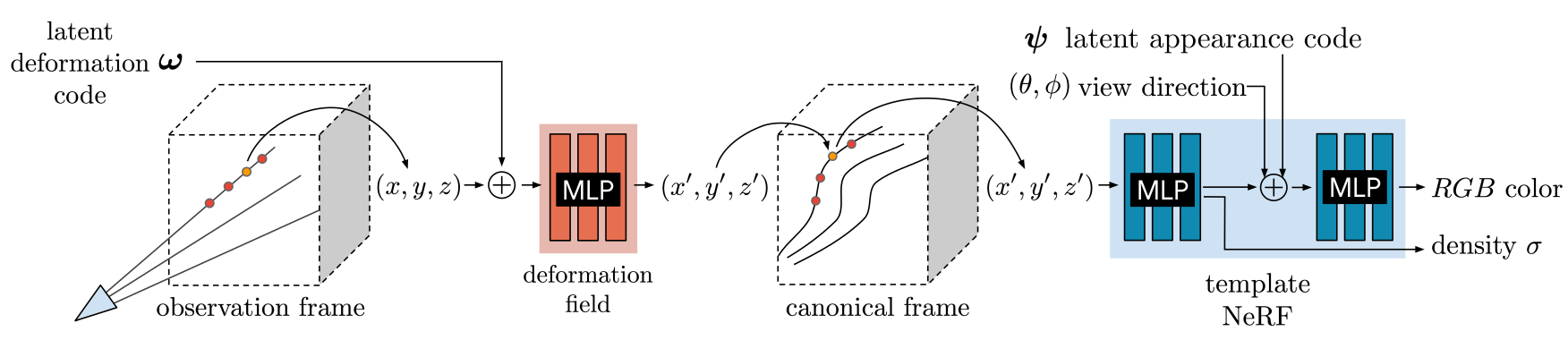
Figure 2: We associate a latent deformation code () and an appearance code () to each image.
- Figure 2에서 우리는 변환된 sample 과 viewing direction (, )을 MLP의 input으로 넣어서 NeRF 방식으로 ray를 따라 sample들을 통합한다.
Deformable Neural Radiance Fields
- Casually captured image들이 주어졌을 때, non-rigidly deforming scene들을 모델링하는 방법을 보여준다.
- 우리는 non-rigidly deforming scene을 template volume represented as a neural radiance field (NeRF)로 분해한다.
- The deformation field는 NeRF에 대한 우리의 핵심 확장으로 우리가 움직이는 물체들을 표현할 수 있게 해준다.
NeRF를 deformation field와 함께 최적화하는 것은 under-constrained optimization 문제로 이어질 수 있다. - 우리는 deformation에 a background regularization이자, continuous, bad local minima를 피하는 coarse-to-fine annealing 기법인 elastic regularization을 도입했다.
3.1. Neural Radiance Fields
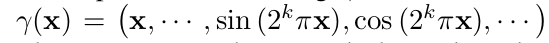
- NeRF는 입력 와 에 대해 positional encoding을 통해 좌표 vector 를 증가하는 주파수의 sine과 cosine 함수를 사용하여 높은 차원의 공간으로 mapping한다.
- 이는 MLP가 고주파의 신호들을 낮은 주파수 domain에서 model할 수 있게 해준다.
- 우리는 각 관측되는 프레임에 대해 appearance latent code 를 제공하여 입력 프레임들에 대한 appearance variation(e.g., exposure과 white balance)들을 다루는 color output을 조절하도록 했다.
3.2. Neural Deformation Fields
- 우리는 NeRF가 non-rigidly deforming scene들을 reconstruction할 수 있도록 확장했다.
- NeRF를 통해 빛을 직접 cast하는 대신에 우리는 이것을 canonical template으로 사용했다. 이 Template은 scene의 상대적인 구조와 모양을 포함하며 rendering이 template의 non-rigidly deformed version을 사용할 것이다.
- Observation space의 좌표 x를 canonical space의 좌표 x'으로 mapping해준다.
- 다음 mapping을 사용하여 모든 time step에서 deformation fields를 모델링했다.
- : (x, ) x'
- 이는 per-frame learned latent deformation code 에 의해 조정됨.
- 각 latent code는 frame 에서 scene의 상태를 encode한다.
- Canonical-space radiance field 와 observation-to-canonical mapping 가 주어졌을 때, observation-space radiance field는 다음과 같이 평가될 수 있다.
- G(x, d, , ) = F(T(x, ), d, )
- Rendering할 때, 우리는 단순히 빛을 쏘고 observation frame에서 point들을 sampling한다. 그러고 나서 deformation field를 사용해 sampled point들을 template에 mapping한다.

- Figure 3: Visualizations of the recovered 3D model in the observation and canonical frames of reference, with insets shoing orthographic views in the forward and left directions.
3.3. Elastic Regularization
-
The deformation field는 ambiguity를 더해서 optimization을 더 어렵게 한다.
-
우리는 elastic energy를 사용하여 rigid motion으로부터 local deformation의 deviation을 측정했다.
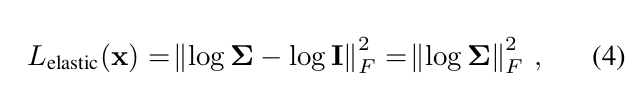
-
Elastic regularization loss의 수식은 아직 잘 이해를 못했지만..; rigid transformation으로부터 Jacobian 의 벗어남을 penalize하는 수식으로 이해하면 될듯하다.

Figure 5: the subject는 자신의 머리를 회전시키며 (top) 웃는다(bottom). -
Positional encodingd이 m = 4일때 웃는 것을 포착하지 못하고 m = 8일 때 머리의 회전을 포착하는데 실패했다.
-
Coarse=to-fine regularization (c2f)을 적용한 경우 모델은 둘 다 capture한다.
3.4. Background Regularization
- 우리는 추가적으로 regularization term을 더해서 background가 움직이는 것을 막는다.
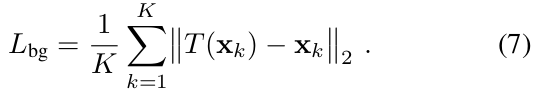
Background point들이 움직이는 것을 막는 것과 동시에 이 regularization은 observation 좌표 frame을 canonical 좌표 frame으로 정렬해주는 이득이 있다.
3.5. Coarse-to-Fine Deformation Regularization
-
Registration과 flow estimation 중 일어나는 흔한 trade-off는 modeling minute과 large motions 사이의 선택으로 이는 과도하게 smooth한 결과 또는 incorrect registration (local minima)로 이어질 수 있다.
-
Coase=to-fine 전략은 이 문제를 저해상도에서 먼저 풀고 반복적으로 해상도를 높이고 정제함으로써 이 문제를 우회한다.
-
우리의 deformation model은 비슷한 문제를 겪고 coarse-to-fine regularization을 제시하여 이를 완화한다.
-
Fig. 5에서 positional encoding 값이 작으면 smile의 minute motion을 포착하지 못하고 m이 크면 머리의 회전을 포착하지 못하는데 이는 the template이 unoptimized deformation field에 overfitting되었기 때문이다.
-
이 tradeoff를 해결하기 위해, 우리는 low-frequency bias에서 시작하여 high-frequency bias르 끝나는 coarse-to-fine 접근법을 제시함.
-
Tancik et al. [55]에 의하면 positional encoding은 NeRF의 MLP의 Neural Tangent Kernel (NTK)로 해석될 수 있으며 m은 kernel의 "bandwidth"를 조정한다.
-
주파수가 낮을 때: wide kernel을 도입하여 데이터의 under-fitting을 야기함
-
주파수가 높을 때: narrow kernel을 도입하여 데이터의 over-fitting을 야기함
-
우리는 parameter 를 도입해서 NTK의 bandwidth를 점진적으로 강화하고자 했다.
-
각 frequency band 를 위한 weight는 다음과 같다.
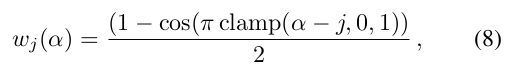
- parameter [0, m] 를 선형적으로 강화함
4. Nerfies: Casual Free-Viewpoint Selfies
- Casually captured selfies로부터 human subject들을 높은 퀄리티로 재구성하는 "nerfies"를 제시함.
- 우리의 시스템은 대부분 가만히 있는 selfie 사진들의 시퀀스를 입력 받음.
Camera Registration
- Static background에 대해 camera registration을 진행하며 COLMAP을 사용해 각 이미지의 포즈와 camera intrinsics를 계산한다.
- 이 단계는 sequence를 등록하기 위해 background에 충분한 feature들이 있음을 가정함.
Foreground Segmentation
- SfM은 움직이는 물체들의 feature를 match하면서 background에서 심각한 misalignment를 야기할 수 있다. 이 경우 foreground segmentation network를 사용하여 검출될 수 있는 subject의 이미지 feature들을 버리는 것이 도움이 됨을 알았다.
Experiments
5.1. Implementation Details
- 우리는 NeRF의 MSE photometric loss를 사용하며 loss를 다음과 같이 측정한다.
- 모든 실험에 대해
5.2. Evaluation Dataset
-
우리는 학습동안 보지 못한 viewpoint로부터 scene을 얼마나 신뢰성있게 재생성하는지 평가할 수 있어야했다.
-
우리는 하나의 평가 목적을 갖고 simple multi-view data capture rig를 형성하고자 했다.
-
우리의 장치는 Fig.9와 같이 2개의 Pixel 3's rigidly attached pole이며 data capture를 2가지 방식으로 진행했다.
(a) Front-facing camera를 사용하여 time-synchronized photo들을 촬영함.
(b) Back-facing camera를 사용하여 우리가 audio에 맞춰 수동으로 synchronize한 2개의 video를 기록함. -
우리는 또한 Neural Scene Flow Fields (NSFF)와 함께 single view를 encoder의 입력으로 해서 Neural Volumes (NV)의 high quality 모델을 비교했다.
-
COPMAP을 사용하여 이미지들의 rigid relative camera pose constraints를 등록함.
5.3. Evaluation
Quantitative Evaluation
- 우리는 NeRF와 NeRF + latent baseline을 비교함.
- D-NeR: D-NeRF는 latent code (+trans) 대신에 position encoded time 와 함께 deformation field를 조절함.
- NSFF: NSFF와 baseline은 temporal information을 사용하지만 다른 baseline들과 우리의 방법은 그렇지 않다.
- NSFF는 estimated flow나 auxilliary supervision을 사용하지 않음
- PSNR와 LPIPS로 평가했으며 모든 시퀀스들에 대해 LPIPS 측면에서 baseline들을 압도함
Ablation Study
- 우리는 우리의 contribution들을 SE(3) deformations, elastic regularization, background regularization, 그리고 coarse-to-fine optimization
- Elastic regularization을 강하게 가할수록 (), dynamic scenes에 대해 더 향상된 결과를 얻었고 quasi-static scenes에 대해 미미하게 영향을 줌.
- Elastic regularization은 under-constrained 상황에 대해 distortion artifact들을 fix한다.
- Coasre-to-fine regularization을 가하는 것은 quasi-static scene들에 대해 약간 성능을 낮추며 dynamic scnene들에 대해 성능을 크게 저하시킨다.
Elastic regularization
- Under-constrained case들에 대해 도움이 되며 왜곡을 현저하게 줄인다.
Depth Visualizations
- 우리는 density field의 depth renders를 사용하여 reconstruction의 quality를 시각화함.
Limitaitons
- 우리의 방법은 topological changes (e.g., opening/closing of the mouth)에 어려움을 겪고 빠른 움직임이 있는 특정 프레임들에는 실패함.
- Deformation이 제한되지 않아서 static region들이 변할 수 있고 이는 PSNR과 LPIPS의 괴리로 이어짐
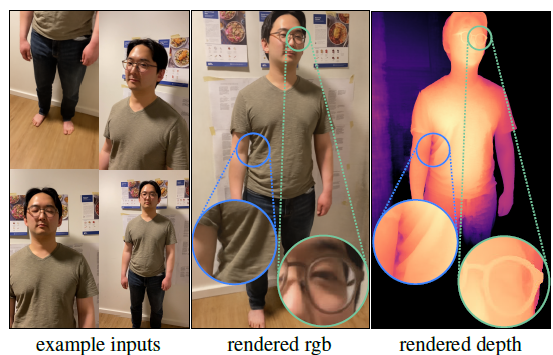
Figure 8: Our method reconstructs full body scenes captured by a second user with high quality details
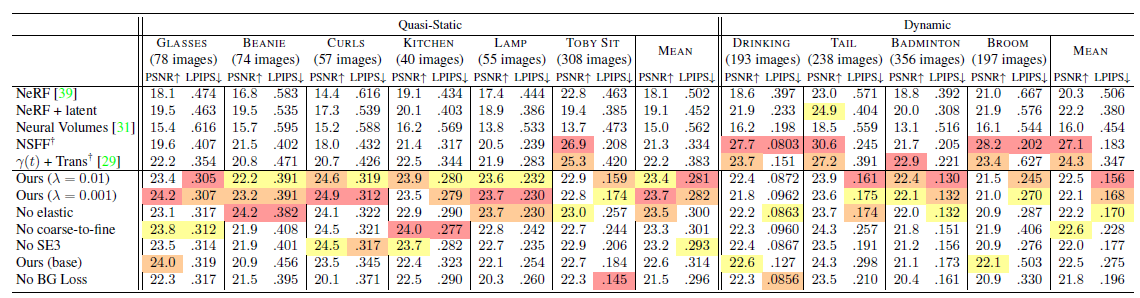

Figure 10: Comparisons of baselines and out method on dynamic scenes. PSNR/LPIPS metrics on bottom right with the best colored red. Note
- Dynamic scene에 대한 PSNR/LPIPS 결과인데 PSNR (Peak Signal to Noise Ratio)은 신호 대 잡음비로 높을수록 좋고
LPIPS (Learned Perceptual Image Patch Similarity)는 낮을수록 좋다.
Dynamic scene들에 대해 Nerfies가 가장 좋은 성능을 보이고 몇몇은 NSFF가 더 높은 성능을 보여준다.

Figure 11: Comparisons of baselines and our method on quasi-static scenes.
- Static scene들에 대해서는 Nerfies가 가장 좋은 성능을 보여준다. 압도적이군..
Conclusion
- Deformable Neural Radiance Fields는 non-rigidly deforming scenes를 모델링하는 것에 의해 NeRF를 확장함
- Rigid deformation prior와 coarse-to-fine deformation regularization이 high-quality 결과를 얻는데 핵심이 됨
- Casual selfie capture (nerfies)로 응용을 보여줬고 human subject를 높은 정확도로 재구성함.
- Future work는 더 크고/빠른 움직임을 다루거나 topological variations, 그리고 학습/추론 속도를 향상시키는 것이다.
Nerfies를 통해 좀 더 realistic하게 셀카를 찍을 수 있을 것 같다^^ 코드 분석은 NeRF 이후에 진행해야겠다.
그럼 Nerfies 논문 리뷰를 마친다.