D-NeRF 논문 : https://arxiv.org/abs/2011.13961
D-NeRF 프로젝트 홈페이지 : https://www.albertpumarola.com/research/D-NeRF/index.html
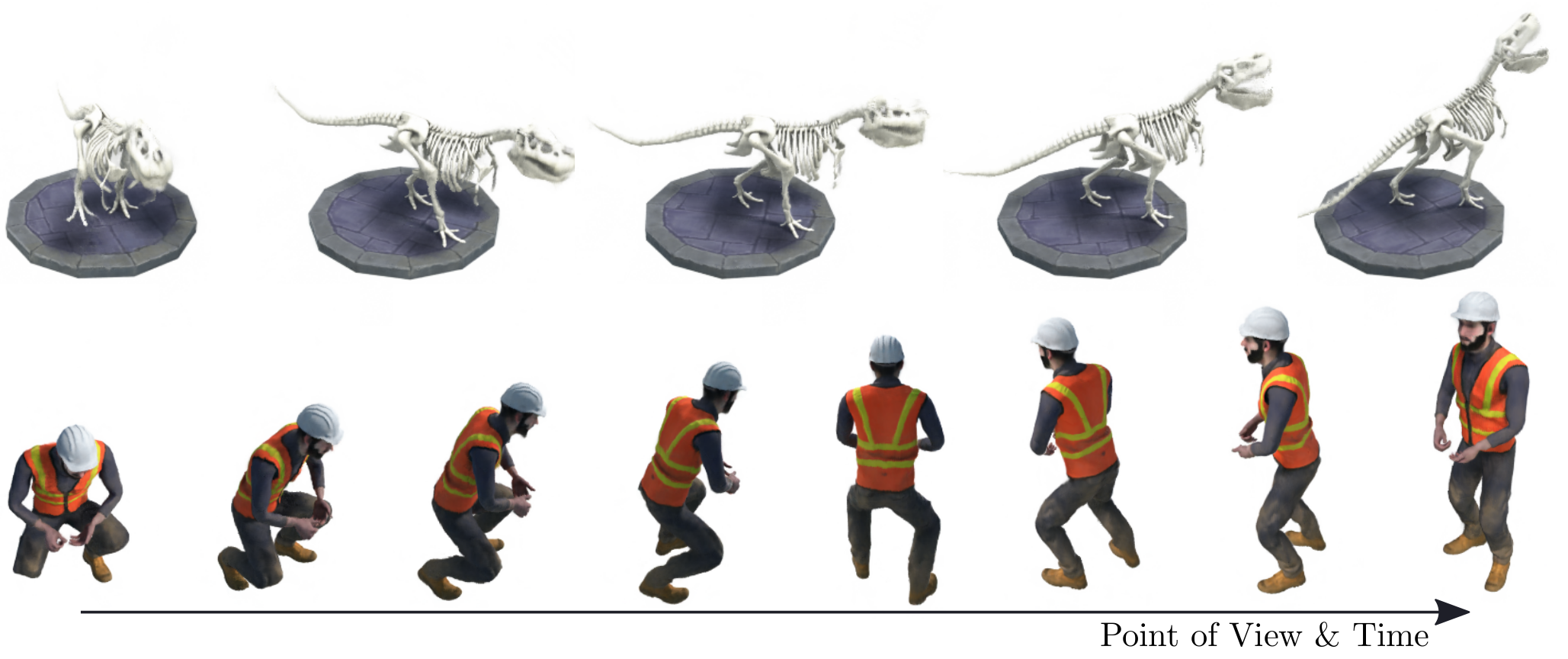
Figure 1: We propose D-NeRF, a method for synthesizing novel views at an arbitrary point in time, of dynamic scenes with complex non-rigid geometries.
Motivation
- 기존의 NeRF는 정적인 scene들에만 적용 가능한 문제점이 있었다.
- 기존 Neural implicit representation의 경우, 3D ground-truth supervision 또는 multi-view camera setting을 요구함.
Contributions
- 우리는 시간 당 single camera view만 요구하며 3D ground truth나 미리 계산된 3D reconstruction을 요구하지 않는다.
- end-to-end로 학습될 수 있다.
- Deformation network와 Canonical network라는 2가지 network를 도입
- Deformation network: time t에서의 scene의 각 point들과 a canonical scene configuration 사이의 공간적 mapping인 (x,y,z,t) → (Δx,Δy,Δz)을 학습한다.
- Canonical network: tuple (x+Δx,y+Δy,z+Δz,θ,π) 이 주여졌을 때 각 방향으로 방사된 scene radiance와 volume density를 regress한다.
- 2가지 network를 통해 camera view와 time 변수, 이에 따라 움직임을 통제하면서 novel image들을 생성할 수 있게 되었다.
Future direction
- Jumping jack과 같이 빠르고 큰 움직임에도 blurry하게 보이지 않고 clear rendering이 가능한 네트워크 구조 고안
Abstract
-
Neural radiance fields (NeRF)는 5D input 좌표 (공간적 위치와 viewing direction)를 deep network에 학습시켜서 a volume density와 view-dependent emitted radiance를 출력으로 내보낸다.
-
전례없는 생성된 이미지에서 전례없는 photorealism을 달성했지만 정적인 scene들에만 적용가능한 문제점이 있었다.
-
이 논문에서 우리는 NeRF를 dynamic domain으로 확장하여 scene을 움직이는 단일 카메라로부터 rigid와 non-rigid motion을 포함하는 object의 novel image들을 재구성하고 rendering할 수 있는 D-NeRF를 도입하였다.
-
이러한 목적을 달성하기 위해 우리는 time을 추가적인 시스템 입력으로 고려했고 학습 과정을 2가지 process로 나누었다.
- 한 network는 scene을 canonical space로 encode한다.
- 다른 network는 특정 시점에 canonical representation을 deformed scene으로 mapping한다.
-
2가지 mapping은 fully-connected networks를 사용하여 동시에 학습된다.
-
2가지 network들이 학습되면 D-NeRF는 novel image들을 camera view와 time 변수, 그리고 이에 따라 물체의 움직임를 통제하면서 novel image들을 rendering할 수 있게 된다.
-
우리는 rigid하고 연결된 움직임 또는 non-rigid 움직임을 갖는 물체들을 포함하는 scene들에 대해 우리의 접근법의 효율성을 입증했다.
1. Introduction
-
Neural Radiance Fields (NeRF)는 공간적 위치 (x, y, z)와 카메라 views (, )의 5D inputs으로부터 emitted radiance와 volume density로의 mapping을 encode하는 간단한 multilayer perceptron network들을 보여준다.
이 학습된 mapping은 extraordinary realism과 함께 free-viewpoint rendering을 가능하게 했다. -
이어지는 연구들은 심각한 조명 변화와 빠른 추론을 위한 sparse voxel fields를 제시했지만 이러한 접근법들은 움직이는 물체들이 없는 정적인 scene을 가정하는 문제점이 있었다.
-
본 연구에서 우리는 그러한 가정을 완화하고 최초의 가만히 있거나 움직이는 /변형이 있는 물체들로 구성된 dynamic scene들에 적용가능한 end-to-end neural rendering system을 제시한다.
-
우리의 연구가 기존의 4D view synthesis와 다른 점은 다음과 같다.
- 우리는 하나의 카메라만 요구한다.
- 우리는 미리 계산된 3D reconstruction을 요구하지 않는다.
- 우리의 접근법은 end-to-end로 학습될 수 있다.
-
Dynamic NeRF (D-NeRF)는 학습을 2가지 모듈로 분해했다.
- 첫번째 모듈은 time 에서의 scene의 각 point들과 a canonical scene configuration 사이의 공간적 mapping인 () ()을 학습한다.
- 두번째 모듈은 tuple () 이 주여졌을 때 각 방향으로 방사된 scene radiance와 volume density를 regress한다.
-
이 두가지 mapping들은 모두 convolutional layer 없이 deep fully connected networks로 학습된다.
-
학습된 모델은 novel 이미지들을 합성하며 camera views, time component의 continuum () 또는 the dynamic state of the scene에 대해 control을 제공한다.
-
우리는 복잡한 body pose들을 수행하는 사람의 연속 동작으로부터 deformation의 매우 다른 형태들을 수행하는 scene들에 대해 D-NeRF를 평가했다.
-
우리는 학습을 canonical scene과 scene flow로 나눔으로써 D-NeRF가 camera view와 time component들을 control하면서 높은 quality의 이미지들을 rendering 할 수 있다는 것을 보여주었다.
-
Side-product로서, 우리의 방법은 time-varying geometry를 포착하고 단일 시점으로부터 특정한 deformation 하에 있는 scene을 관측하는 것에 의해 얻어지는 완전한 3D mesh를 생성한다.
2. Related Work
Neural implicit representation for 3D geometry
Neural implicit representation
- Neural implicit representation을 사용하면 낮은 메모리 사용량만으로도 연속적인 surface reconstruction이 가능
- 3D ground-truth geometry에 접근해야하는 필요성에 의해 implicit representations for 3D representation은 많이 제한됨.
- Occupancy flow: space와 time에서 모든 point들에 motion vector를 할당하는 연속적인 vector vield를 학습하는 것에 의해 non-rigid geometry를 다룬 최초의 연구였다.
- 그러나 3D ground-truth supervision을 요구함.
- Neural volumes: implicit voxel warp field에 의해 향상된 encoder-decoder voxel-based 표현을 통해 높은 quality의 reconstruction 결과를 생성한다.
- 그러나 multi-view 이미지 capture 환경을 요구함.
- D-NeRF는 3D ground-truth supervision이나 multi-view camera setting 없이 monocular data에만 의존하여 학습된 non-rigid하고 time-varying scene들을 위한 implicit representation을 생성할 수 있는 최초의 접근법이다.
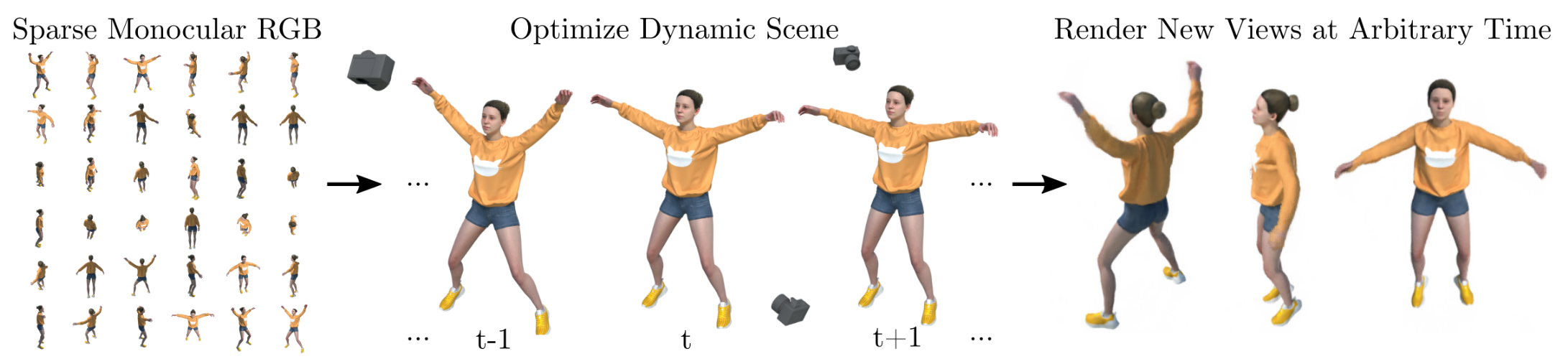
Figure 2: Problem Definition. Given a sparse set of images of a dynamic scene moving non-rigidly and being captured by a monocular camera, we aim to design a deep learning model to implicitly encode the scene and synthesize novel views at an arbitrary time.
- Non-rigid scene들을 다루기 위해 대부분의 방법들은 Dynamic 3D textured mesh를 재구성하는 것에 의해 이 문제에 접근한다.
- 그러나 monocular image들로부터 non-rigid surfaces의 3D reconstruction은 심각하게 ill-posed로 알려져 있다.
- D-NeRF는 다른 사전 연구들과 다르게, 3D reconstruction을 요구하지 않고 end-to-end로 학습될 수 있으며 시간 당 single view를 요구한다.
- 또다른 appealing characteristic은 이것이 내재적으로 time-varying 3D volume density와 emitted radiance를 학습한다는 것이다. 이는 novel view synthesis를 view interpolation 대신 ray-casting 문제로 바꾸고 이는 놀랍게도 임의의 viewpoint들로부터 이미지들을 rendering하는데 있어 더 robust하다.
3. Problem Formulation
-
우리는 3D point x = 가 주어졌을 때, view direction 와 time instant 에 의해 조절되며 출력으로 emitted color 와 volume density 를 내보내는 mapping 을 예측하고자 한다.
mapping -
우리는 mappingn 을 와 로 나누어 더 나은 결과를 얻었다.
- : canonical configuration에서의 scene을 의미
- : time instant 에서의 scene과 canonical scene 사이의 mapping을 의미한다.
-
Point x와 viewing direction , time instant 가 주어졌을 때, 우리는 point의 위치를 canonical configuration으로 다음과 같이 변환한다.
- 이 떄 일 경우,
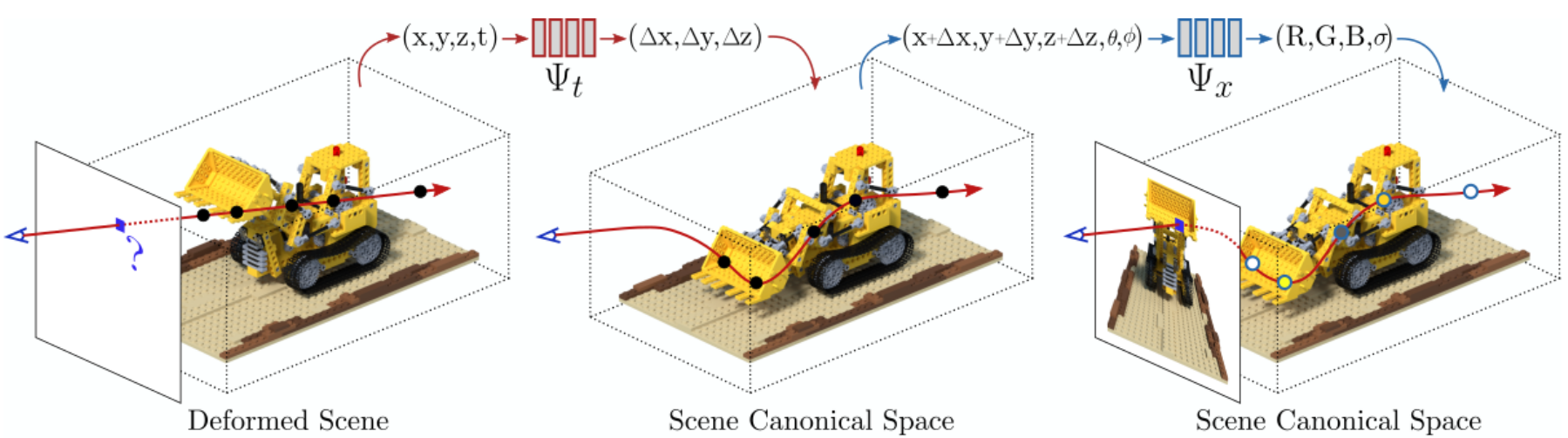
Figure 3: D-NeRF Model. 제안된 구조는 2가지 main blocks로 구성된다. A deformation network 는 all scene deformation을 common canonical configuration으로 mapping하며, canonical network 는 volume density와 view-dependent RGB를 color를 모든 카메라 ray들로부터 regress한다.
-
이렇게 함으로써 scene은 더이상 time instance와 무관하지 않게 되고 공통의 canonical space anchor를 통해 연결되어 있다.
-
따라서, viewing direction 아래의 할당된 emitted color와 volume density는 canonical configuration에서 다음과 같다.
: Camera pose 에서 얻어진 이미지 를 의미
4. Method
- 우리는 dynamic scene의 sparse 이미지들로부터 학습된 view synthesis를 위한 novel neural renderer인 D-NeRF를 제시했다.
- 우리는 NeRF 위에 작업했고 non-rigid scene들도 다룰 수 있게 일반화하였다.
- NeRF는 rigid scene들에 대해 multiple view들을 요구하지만 D-NeRF는 시간 당 single view로 학습된 연속적인 non-rigid scene들을 위한 volumetric density representation으로 학습할 수 있다.
D-NeRF는 2가지 main neural network 모듈로 구성되어 있다. - Canonical network
- An MLP (Multilayer perceptron)이며 는 3D point x와 a view direction 를 emitted color c와 volume density 로 바꾸면서 scene을 canonical configuration으로 encode함.
- Deformation network
- 또 다른 MLP 로 이는 time 에서의 scene과 canonical configuration에서의 scene 사이의 transformation을 정의하는 deformation field를 예측한다.
4.1. Model Architecture
Canonical Network
- Canonical configuration의 사용으로 우리는 모든 이미지들에서 모든 대응하는 point들의 정보를 모야주는 scene 표현을 찾고자 한다.
- Canonical network 는 canonical configuration에서 volumetric density와 color를 encode하도록 학습되었다.
- Point의 3D 좌표 x가 주어졌을 때, 우리는 이것을 256차원의 feature vector로 encode하고 이 feature vector는 camera viewing direciton 와 concatenate된다. 그리고 fully connected layer로 전파되어 canonical space에서 주어진 point에 대해 emitted color 와 volume density 를 생성한다.
Deformation network
-
The deformation network 는 특정 time instant에서의 scene과 canonical space에서의 scene 사이의 deformation field를 예측하도록 최적화된다.
-
Time 에서 3D point x가 주어졌을 때, 는 학습되어 displacement x를 출력으로 내보내며 이는 주어진 위치를 canonical space의 x + x로 변환한다.
-
모든 실험에서, generality의 loss를 잃지 않고, 우리는 canonical scene을 에서의 scene이 되도록 정의함.
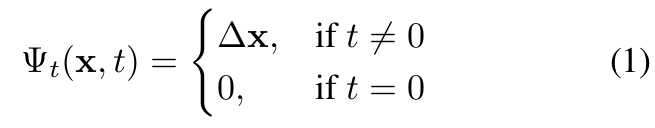
-
이전 연구에서 raw coordinates와 angles를 neural network에 직접적으로 넣는 것은 low performance를 내는 것을 알 수 있었다.
-
우리는 canonical network와 deformation network를 모두 x, d, 를 더 높은 차원의 공간에 encode한다.
4.2. Volume Rendering
-
NeRF의 6D neural radiance field에서 non-rigid deformation을 설명하기 위해 NeRF volume rendering equation을 이용함.
-
x() = o + d를 projection center 로부터 pixel 까지의 camera ray를 따르는 point라고 하자. Ray에서 near와 far bounds 과 를 고려할 때, time 에서 pixel 의 기대되는 color 는 다음과 같다.
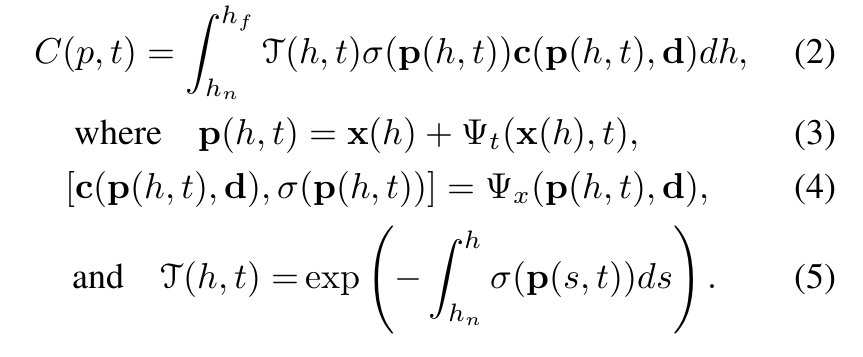
-
The 3D point p()는 우리의 Deformation Network 를 사용하여 canonical space로 변환된 camera ray x()의 point를 의미한다.
-
: 발사된 ray가 부터 까지 어떤 입자와도 충돌하지 않을 누적 확률
-
랜덤 set of quadrature points 들을 선택하기 위해 계층화된 sampling 전략이 고르게 분포된 ray-bins에서 uniformly sample들을 추출하는 데데 적용되었다.
-
A pixel color는 다음과 같다.
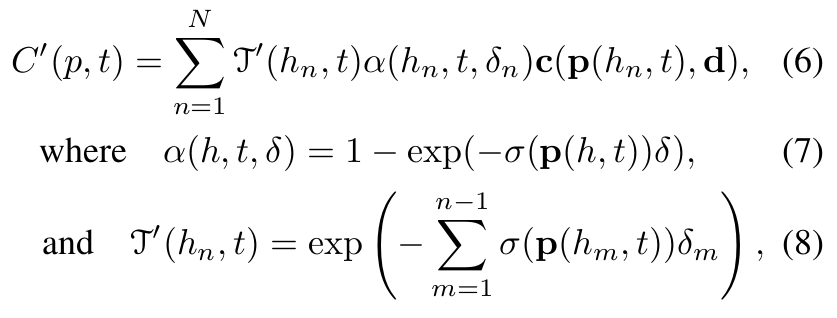
- : 2개의 quadrature point들 사이의 거리
4.3. Learning the Model
- : 2개의 quadrature point들 사이의 거리
-
Canonical network 와 deformation network 는 RGB images 와 camera pose matrices 의 mean squared error를 최소화하는 것에 의해 동시에 학습된다.
-
Training loss는 rendered pixel과 real pixel 간의 mean squared error와 같다.
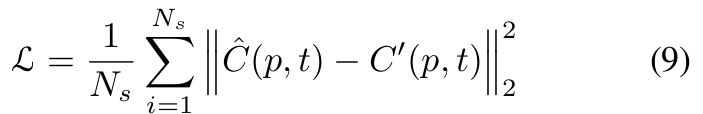
-
: pixel's ground truth color
5. Implementation Details
- The canonical network 와 deformation network 는 간단한 8-layer의 MLP with ReLU activations로 구성되어 있다.
- 모델은 ray를 따라 64번 sampling된 batch size rays와 함께 800 iterations 동안 image들로 학습되었다.
6. Experiments
6.1. Dissecting the Model

Figure 4: Visualization of the learned scene representation.
-
우리는 canonical configuration에서 scene을 표현하는 canonical network를 평가했다.
-
Rendered RGB image는 canonical network의 평가 결과이다.
-
두번째 실험에서는 canonical scene을 이미지의 특정 shape으로 mapping하는 consistent한 deformation fields를 예측하는 network의 능력을 평가한다.
-
2가지 예시에서 4번째 column은 t = 0일 때의 canonical shape 안의 color-coded point들을 t = 0.5와 t = 1일 때의 다른 shape configurations로 mapping하는 displacement field를 시각화한다.
-
또 다른 질문은 D-NeRF가 어떻게 shadows/shading effects와 같은 현상을 어떻게 모델링하는지이며 이는 모델이 시간이 지남에 따라 같은 point의 형태 변화를 encode할 수 있는지를 의미한다.
-
Fig. 5에서 우리는 3개의 공이 있는 scene을 보여주며 이 scene은 다른 물질들 (plastic-green, 반투명 유리- blue, 금속 - red)로 구성되어 있다.
-
이 그림은 특정 time instant에서 canonical configuration과 scene 사이의 대응하는 point들을 표시한다.
-
D-NeRF는 canonical configuration을 warping하는 것에 의해 shading effects를 합성할 수 있다.
- Floor shadow가 어떻게 warping되는지를 보면, t = 0.5일 때 red ball의 그림자에서 point가
t = 1일 때 canonical space에서 다른 영역으로 mapping된다.
- Floor shadow가 어떻게 warping되는지를 보면, t = 0.5일 때 red ball의 그림자에서 point가
6.2. Quantitative Comparison

Figure 6: 질적인 비교. Novel view synthesis results of dynamic scenes.
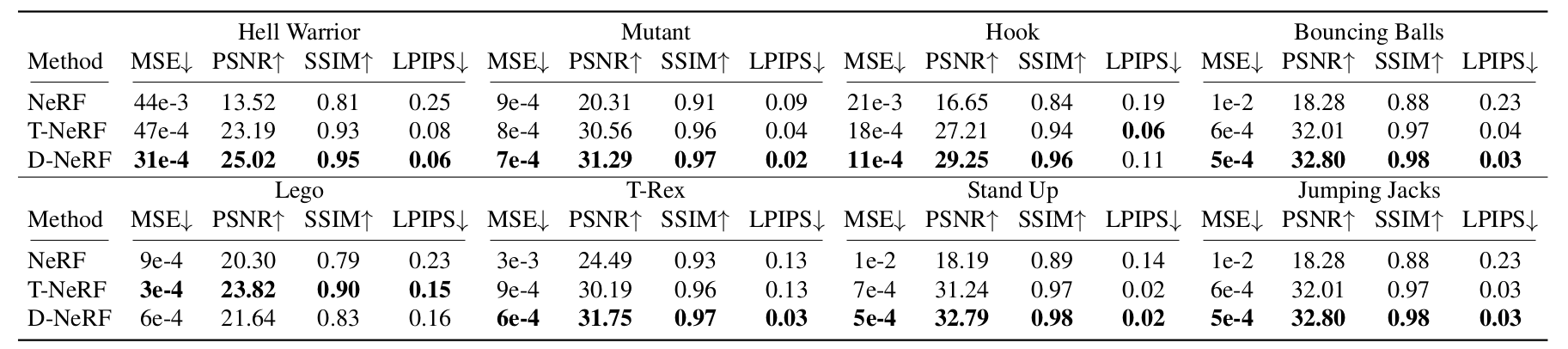
Table 1: Quantitative Comparision. We report MSE/LPIPS (lower is better) and PSNR/SSIM (higher is better)
- 우리는 D-NeRF의 quality를 novel view synthesis 문제에 대해 평가헀고 이를 original 5D input ()를 사용하여 scene을 표현하는 NeRF, D-NeRF의 canonical configuration에 대한 고려 없이 scene이 6D input 에 의해 표현되는 NeRF의 확장인 T-NeRF와 비교해보았다.
- Table 1은 8개의 dynamic scene들에 대해 우리의 데이터셋에 대한 양적인 결과를 요약했다.
- 우리는 평가를 위해 몇가지 metric을 사용했다.
- Mean Squared Error (MSE), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM) 그리고 Learned Perceptual Image Patch Similarity (LPIPS)
- Table 1은 우리의 데이터셋에서 8개의 dynamic scene으로부터 얻은 양적인 결과이다.
- Fig. 6은 visual inspection을 위한 novel view에서 sample들의 예시를 보여준다.
- NeRF는 rigid case만을 위해 디자인되었기 때문에 dynamic scene들을 모델링하지 못했고 모든 deformation의 blurry mean representation으로 수렴했다.
반면에 T-NeRF는 high quality detail을 잘 복구하진 못했지만 dynamics를 비교적 잘 포착할 수 있었다.
- D-NeRF는 novel view에서 원본 이미지의 high detail들까지 보존하고 있는데 각 deformation state가 single viewpoint로부터 관찰된 것을 감안할 때 이는 놀라운 결과이다.
6.3. Additional Results
- 우리는 D-NeRF로 다룰 수 있는 scenario들의 넓은 범위를 보여주기 위해 추가적인 결과들을 보여줬다.
- Fig. 7은 4개의 scene들에 대해 2개의 novel viewpoint들로부터 다른 time instants에서 rendering된 이미지들을 묘사한다.
- 우리는 몇 가지 종료의 dynamics를 다룰 수 있다.
- Tractor scene의 연속적인 움직임
- Jumping Jacks를 하는 인간의 움직임과 warrior scenes
- Bouncing Ball들의 비동기적인 움직임

Figure 7: Time & View Conditioning. 학습된 canonical space에서 시간에 따라 view의 2가지 novel point들로부터 diverse scene들을 합성한 결과
- Jumping Jacks를 할 때 두 팔이 blurry한 것을 제외하고 모든 경우들에 대해 sharp하고 neat scene을 보여주었다.
- 그러나 이것이 rendered image의 quality를 해치지 않았고 이는 network가 canonical configuration을 warp해서 rendering quality를 최대화함을 보여준다.
7. Conclusion
- 우리는 dynamic scene을 모델링하는 접근법인 novel neural radiance field인 D-NeRF를 제시했다.
- 우리의 방법은 움직이는 카메라로부터 획득된 a sparse set of images로부터 end-to-end로 학습될 수 있고 미리 계산된 3D priors나 동일 scene configuration을 다른 viewpoints로부터 관측할 필요가 없다.
- D-NeRF의 main idea는 time-varying deformation을 표현하는 2가지 모듈이다.
- 하나는 canonical configuration을 학습한다.
- 다른 하나는 time instant 에서 scene의 displacement field를 학습한다.
- 평가를 통해 우리는 D-NeRF가 연속된 물체들로부터 복잡한 body gesture들을 수행하는 human bodies까지 다른 종류의 deformation을 겪는 scene들의 높은 quality의 novel view를 생성할 수 있음을 증명했다.
더 공부할 내용
- Canonnical space