생성 모델과 U-Net의 조합이 흥미로워 읽게 된 논문입니다.
2023.6.28 모두의 연구소 Medical AI Lab에서 발표한 내용입니다.
A U-Net Based Discriminator for Generative Adversarial Networks 논문 원본
논문 소개

2021년에 작성된 논문이며 위 세 저자가 작성하였습니다.
이 논문은 생성적 적대 신경망 GAN 생성 모델과 U-Net의 퓨전으로 생성 모델의 이미지의 일관성이 떨어지는 점을 해소하기 위함을 목적에 두고 있습니다.

해당 논문 저자의 유튜브에서 발췌한 PPT 내용으로 빨간 동그라미 안을 보시면 상아가 두개거나, 머리가 두개 등 기존 GAN은 생성된 이미지의 일관성이 전역적/지역적 부족하다는 이슈를 이야기하며 이미지의 얼룩덜락한 패턴이나 동물 이미지의 다리가 없는 것들을 예시로 들고 있습니다.
따라서 이 논문에서는 위와 같은 문제를 해소하기 위해
1. 기존의 판별자를 u-net 형태로 변형하는 것
2. 픽셀별 정규화 기술 도입
두가지를제시하고 있습니다.
이를 도입하면서 얻는 기대 효과는 이미지에 대한 데이터 표현 유지와 판별기를 더욱 강화함으로써 상호작용으로 인한 생성자에 대한 성능 향상으로 더 나음 샘플들을 얻을 수 있다고 말하고 있습니다.
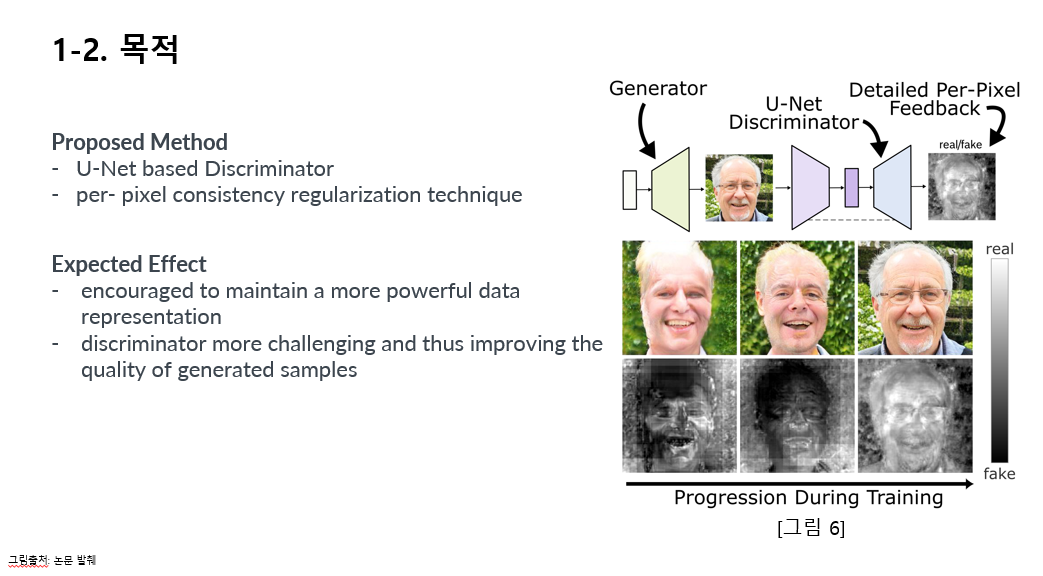
그림 6을 통해 요약적으로 보시면
모델 구조가 기존모델에 비해 판별자 파트에서 U-Net이 도입됬다는 것과 아래 이미지들을 통해 픽셀별로 리얼과 페이크 비율을 보여주고 있음을 볼 수 있습니다.
첫줄은 U-Net GAN 모델이 생성한 이미지들과 둘째줄은 각 이미지에 해당하는 U-Net discriminator의 픽셀별 피드백입니다. 이미지들은 왼쪽에서 오른쪽으로 학습이 진행됨에 따라 픽스된 noise vector로부터 만들어진 결과입니다.
둘째줄의 결과에서 픽셀이 밝을 수록 discriminator의 confidence score가 real에 가까운 것입니다. 예를 들어, 남자의 이마가 얼굴에 비해 비대하여 fake로 인식되었고 검은색을 나타냅니다.해당 부분은 학습이 진행되면서 개선된 것을 오른쪽의 리얼 흰색 부분의 비율이 늘어난 것을 통해 확인할 수 있습니다.
방법
1. Discriminator에 U-Net 도입
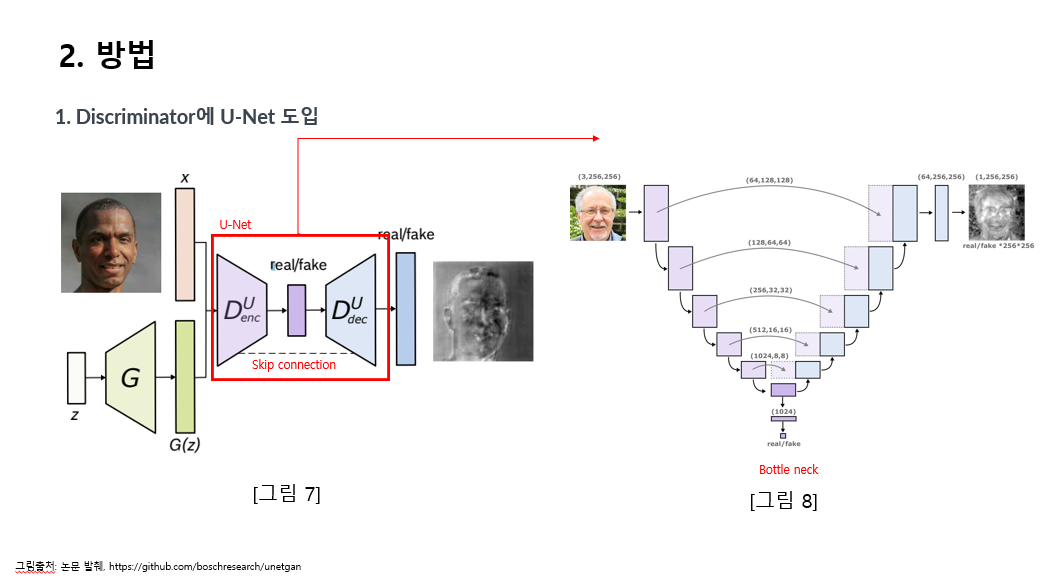
그림 7을 보시면 모델 구조에 대해 보실 수 있는데요,
판별기의 부분을 u-net 처럼 인코더 디코더 부분을 형성하였고, 그림 8에서 확인할 수 있습니다.
그림 7은 점선으로 표현된 인코더 디코더 사이의 스킵 커넥션 또한 u-net에서 착안하여 이미지에 대한 정보 손실을 최소화하고 세부적인 정보를 더욱 반영할 수 있습니다. 픽셀 각각에 대하여 진위 여부를 판별하여 loss에 반영함으로써 생성자가 세부적으로 진짜에 가까운 이미지를 생성할 수 있게하려는 의도입니다.
그림 8에서 인코더가 입력을 점진적으로 다운샘플링하여 이미지의 특징을 추출하며 bottleneck 이후 업샘플링에서는 원본 이미지와 비슷한 이미지 크기를 복원하고 픽셀별 위치 정보를 보존하는데 역할을 가지고 있습니다. 기존 판별기와의 차이점을 u-net 도입을 통해 픽셀 단위로 분류를 수행한다는 것입니다.
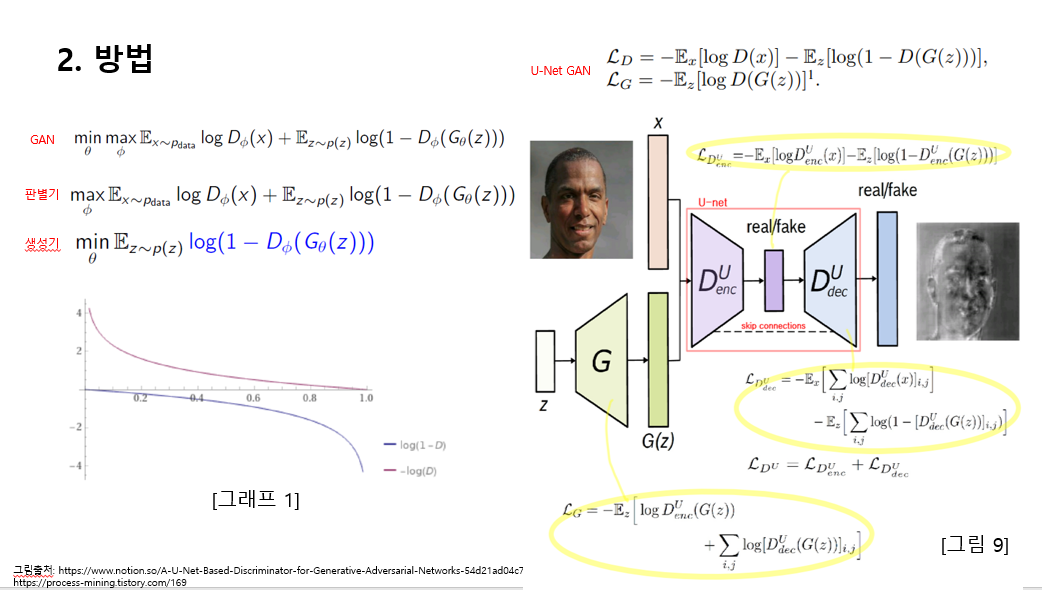
이에 대해서 수식적으로 보시면 가장 위에 있는 수식이 실제 GAN 모델의 수식인 objective function인데요,판별자는 위 식에서 dx를 최대한 1로 가깝게 만들고 dgz를 최대한 0에 가깝게 만듦으로써 식을 최대화하는 방향으로 학습합니다. 반면에 생성자는 dgz를 최대한 1에 가깝게 만들어서 오브젝트 펑션을 최소화하는 것을 목적으로 합니다. 위 수식에서 판별기하는 최대화 하는 방향, 생성기는 최소화하는 방향으로 제시합니다.
실제로 사용되는 u-net gan 수식에서 생성자 부분을 보시면 마이너스가 붙어있습니다. 왜냐하면
실제로 gan 수식의 오브젝트 펑션을 활용해서 이에 대해서 수식적으로 보시면 가장 위에 있는 수식이 실제 gan 모델의 수식인 objective function인데요,
판별자는 위 식에서 dx를 최대한 1로 가깝게 만들고 dgz를 최대한 0에 가깝게 만듦으로써 식을 최대화하는 방향으로 학습합니다. 반면에 생성자는 dgz를 최대한 1에 가깝게 만들어서 오브젝트 펑션을 최소화하는 것을 목적으로 합니다. 위 수식에서 판별기하는 최대화 하는 방향, 생성기는 최소화하는 방향으로 제시를 합니다.
실제로 사용되는 u-net gan 수식에서 생성자 부분을 보시면 마이너스가 붙어있습니다.
왜냐하면 실제로 gan 수식의 objective function을 활용해서 GAN을 학습하면 실제로는 학습이 잘 되지 않는 경우가 있습니다.왜냐하면 그래프 1을 보시면 생성기 성능이 안좋을 때 해당 함수를 따르면 파란색 선의 그라디언트가 굉장히 작아서 학습이 빠르게 될 수가 없게 됩니다.
그렇기 때문에 대신에 objective function 대신 빨간색 선에 나와잇는 –log(D(g(z)))
즉, u-net gan 식에 나와있는 생성자 objective function 식을 사용하게 됩니다. 이 새로운 objective function 식은 기존의 objective function과 같은 의미를 갖고 있으면서도 훨씬 그라디언트가 크기 때문에 학습이 잘된다는 점에서 저 마이너스 식을 사용합니다.
그런데 판별자 식의 경우에도 마이너스 칠이 되어있는데, 이 부분은 논문에서는 나와있지 않고 제 추측으로는 생성자 마이너스에 맞춰 마이너스로 맞춰준게 아닌가 라고 생각이 들고요, 정확하지 않습니다. (이부분에 대해 아시는 분들이 있다면 피드백 부탁드립니다.)
그림 9를 보시면 판별자에서 인코더 디코더 식이 조금 다릅니다.
인코더부분에서 식이 판별자 objective function이 동일하게 들어가고 있고요 , 디코더 부분에서 시그마가 추가 되어있습니다. 이거는 각 픽셀에 대해 분류를 수행하는 파트이기 때문에 I,j에 나눠 값 계산 후 합쳐지게 됩니다. 그래서 판별기의 총합은 인코더식과 더하기 식이 합쳐져 있습니다 .생성기의 경우 판별자의 영향을 받기 때문에 인코더식 생성자 objective function 더하기 각 픽셀별 디코더 objective function이 더해진 형태입니다.
2. per- pixel consistency regularization technique
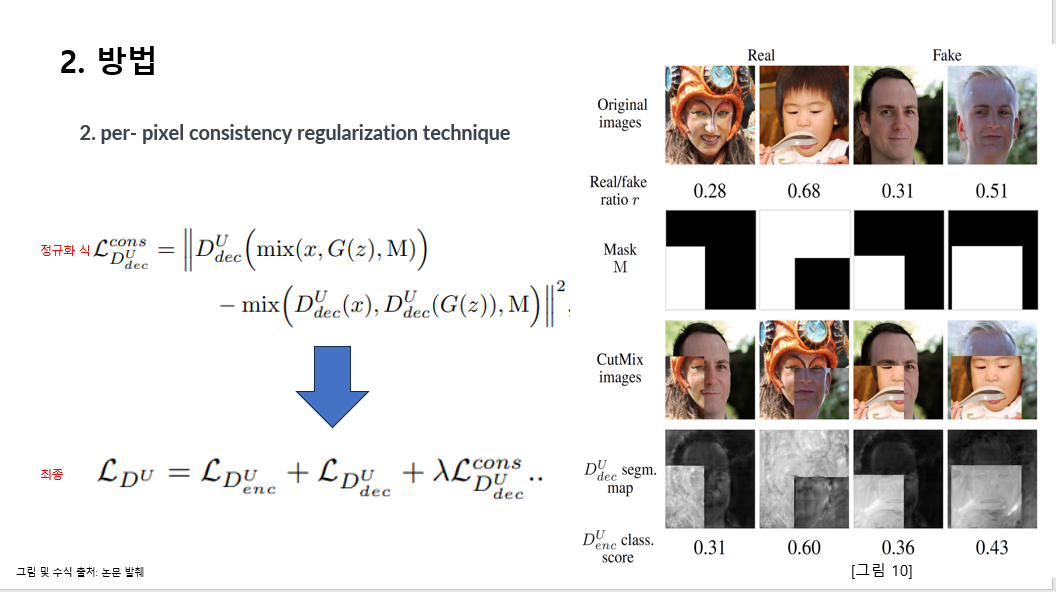
각 픽셀별 정규화 기술 작용입니다 .
잘 훈련된 픽셀 기반 판별자라면 이미지의 리얼 페이크 도메인 변형에 대해서도 픽셀별 예측 결과가 동일해야한다고 해서 cutmix augmentation을 필요한 per-pixel consistency regularization을 도입했습니다 .
진짜 이미지와 생성자가 생성한 가짜 이미지를 섞은 이미지(CutMix)를 판별자에 통과시킴으로써 판별자가 한 장의 이미지 내에서 국소적으로도 판별능력을 일관성있게 확보하도록 하였는데요,
그림 10을 보시면 오리지널 이미지의 리얼이미지 가짜 이미지가 있습니다,
리얼/ 페이크 비율을 통해 마스크 엠을 생성합니다.
하얀 부분은 리얼이미지 검은 부분은 페이크 이미지로 아래 컷믹스 이미지를 보시면 이해가 빠르실 것 같습니다. CutMix 이미지를 판별기를 통해 나온 맵을 보면 리얼 이미지의 부분은 하얀 것을 볼 수 잇습니다. 판별자의 도메인 변화 에 대한 대응을 저 클래스 스코어의 차이로 보게 되는 것입니다.
저 기술을 활용해서 최종 판별자 objective function값을 도출하는데요
정규화 식은 진짜 이미지 x와 가짜 이미지 gz에 대하여
(x와 gz 각각을 CutMix해서서 판별자에 통과시켜 나온 것을)
(x와 gz 각각을 판별자에 통과시켜 나온 것을 CutMix한 결과의 차이입니다.
값이 적게 나오면 나올수록 도메인 변형에도 대응이 가능하다는 것이겠죠
그래서 최종적으로 판별자 objective function은
인코더 식 +디코더식 + 컷믹스한 차이 값을 더한 형태입니다**
실험
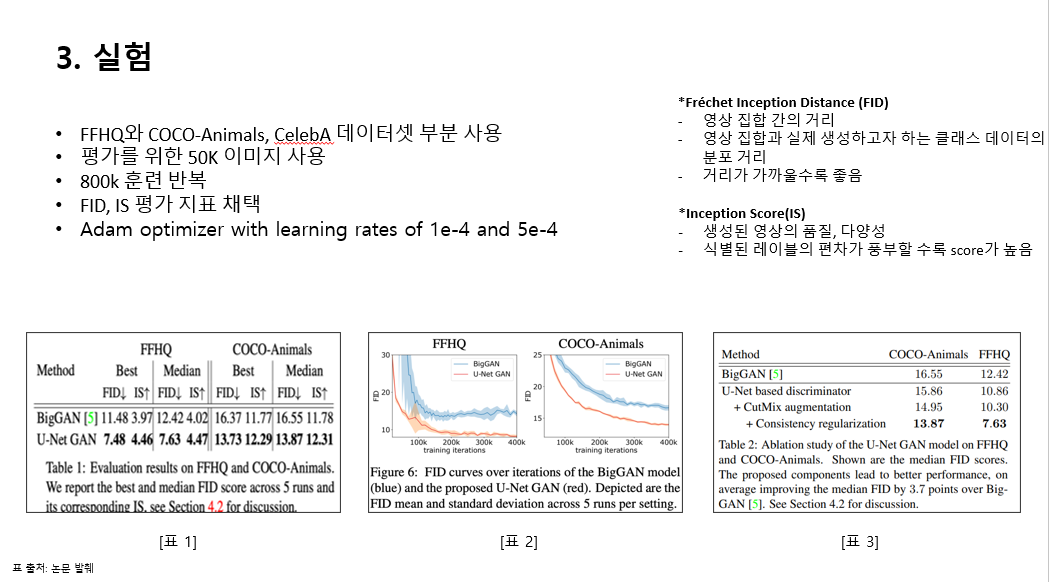
실험은 위와 같은 조건으로 진행했다고 하며
표를 보시면 FID, IS라는 것이 보이는데요, 이는 생성모델의 평가지표입니다 .
FID는 영상집합간의 거리로 영상 집합과 실제 생성하고자 하는 클래스 데이터 분포거리를 의미하며 거리가 가까울수록 좋다고 합니다
Is 는 생성된 영상의 품질, 다양성을 표현하면 편차가 풍부할 수록 점수가 높다고 합니다.
표 1에서는 비교대상을 2019년에 나온 "BigGAN"을 선정했으며
위 두개의 데이터셋을 가지고 5회 운영했을 때 FID 스코어의 최고점과 중간점을 비교했으며
전체적으로 FID 의 수치는 낮고 IS의 수치가 높은 것을 볼수 있었습니다.
표 2도 5회 런에 대한 FID 평균 및 표준 편차역시 u-net gan이 두개의 데이터셋에서 낮게 나옴을 비교하고 있습니다 .
표3은 각 기능들을 추가로 훈련시켯을 때의 FID 점수이며 추가할때마다 점수가 낮아지는 것을 볼 수 있습니다.
결과

도출된 결과입니다.
왼쪽 이미지는 FFHQ라는 인물 데이터셋을 활용한 결과이며 , 설명하기를 왼쪽에서 오른쪽으로 사진 이동을 했을 떄 합성된 이미지가 굉장히 자연스럽게 변화하고 ,크게 인물의 위치가 변화하지 않듯이 글로벌 및 로컬 정보가 잘 보존됨을 보여준다고 합니다.
옆에는 동물 COCO 데이터셋을 활용한 이미지이며, 아까 가장 처음에 나왔던 문제점 예시 사진과는 달리 딱히 이상한 점이 눈에 띄지는 않습니다 .
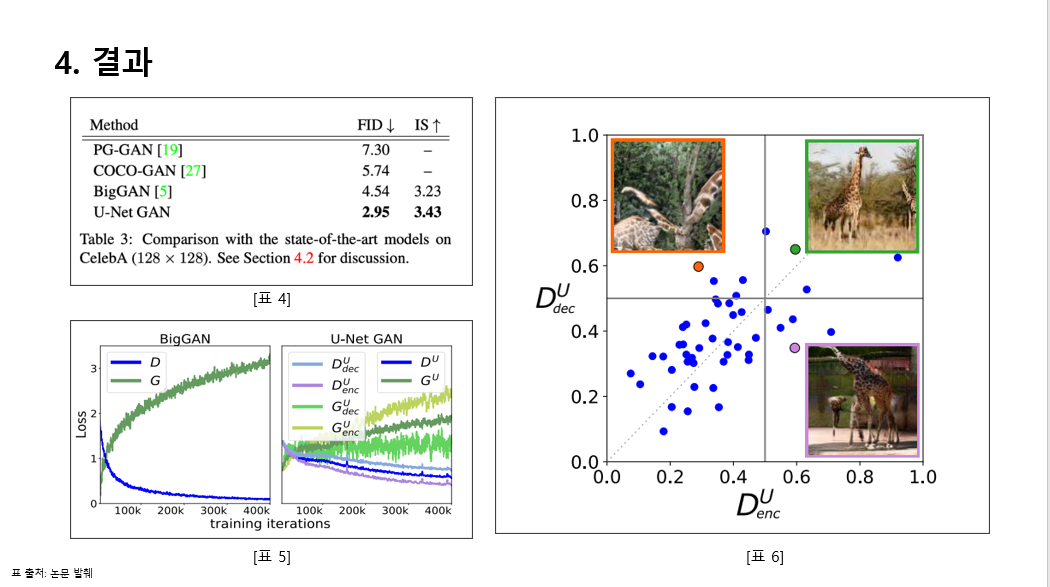
표 4에서는 CelebA 에대한 데이터셋의 각 모델에 대한 FID와 IS를 비교했을 떄 U-NET GAN이 가장 높은 성능을 가지는 것을 판별할 수 있었습니다.
표 5에서는 U-NET GAN의 손실함수 속도가 BigGAN보다 천천히 감소한다고 보였습니다. 이는 유넷간이 더 긴 훈련으로 이어질 수 있고 이가 개선될 수 있는 가능성을 보여준다고 합니다
근데 모델 붕괴는 일반적으로 BigGAN(> 200k 반복)보다 훨씬 일찍(~30k 반복) 발생합니다(이 부분에서 의문점이 드네요.. 여튼)
표 6은 판별기의 훈련 배치에 따른 샘플당 예측을 시각화했습니다.인코더가 이미지 레벨, 디코더가 픽셀 레벨을 표현한다고 합니다.
주황색: 지역적으로 일관성 있지만 전체적으로 일관성이 없음,
보라색: 전체적으로 일관성이 있지만 지역적으로는 일관성이 없음.
녹색: 이상적.
인코더와 디코더 예측이 밀접하게 결합되지 않는다는 사실은 이 두 구성 요소가 보완적이라는 것을 더욱 의미한다고 합니다.
결론

개인적인 생각

특히 모델 붕괴에 대한 의문점의 경우, 생성 모델에서 모델 붕괴는 생성자와 판별자 중 한쪽으로 치우치는 것을 의미하는데 모델 붕괴가 일찍 일어나는 경우 정말 성능이 좋다고 할 수 있는지 의문이네요. 발표 후 박사 학위 중이신 부랩짱님도 이에 대해 논문에서 살펴 보셨을 때 모델의 오류를 빠르게 잡아낼 수 있다..? 같은 약간 변명 아닌 변명을 하는 느낌이 있었다고 하셨네요.
이외에도 저의 그래프 해석 능력 부족으로 마지막 데이터 분포표 같은 경우 잘 해석을 하지 못했다는 점이 있겠습니다.
참조
https://taehojo.github.io/deeplearning-for-everyone/gan.html
https://m.blog.naver.com/chrhdhkd/222013835684
https://www.youtube.com/watch?v=POJSITSZ_U0
https://github.com/boschresearch/unetgan
https://openbackyard.tistory.com/161
https://ebbnflow.tistory.com/167
https://dacon.io/codeshare/5499
https://wakaranaiyo.tistory.com/327
https://velog.io/@tobigs-gm1/basicofgan
https://process-mining.tistory.com/169
https://go-hard.tistory.com/38
워낙 처음 해보는 논문 리뷰이기도 많은 분들의 포스트를 참조했습니다...
이에 대해 피드백과 댓글 주시면 감사드리겠습니다 ^^
피드백 환영입니다!
