1. 자연어 처리(NLP, Natural Language Processing)란?
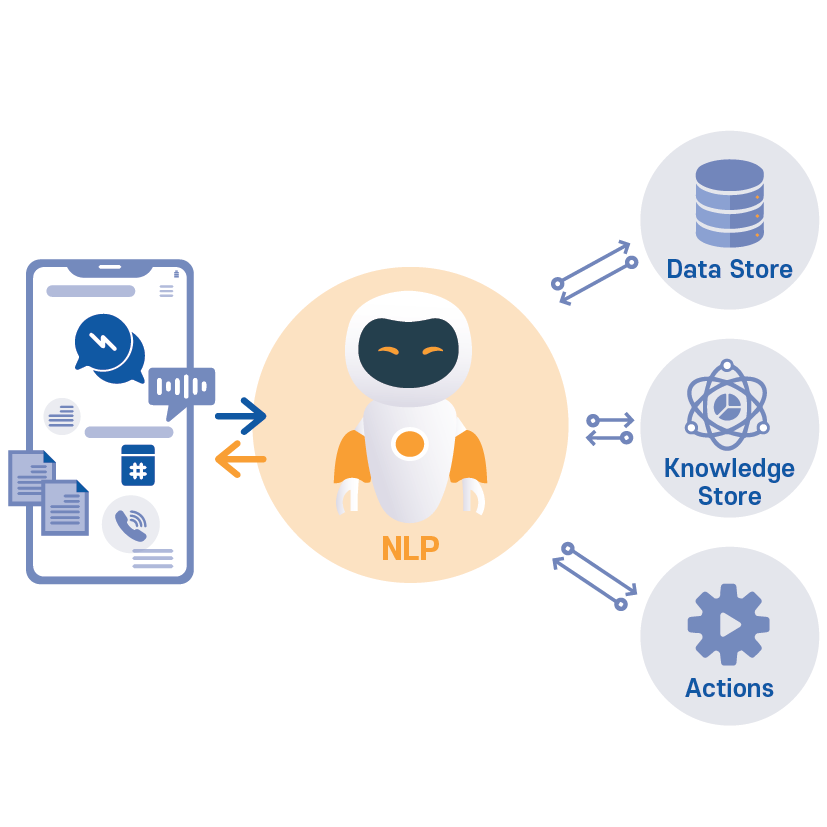
*이미지출처: http://word.tta.or.kr/dictionary/
"자연어 == 사람이 쓰는 언어"
자연어처리란 사람이 쓰는 언어를 컴퓨터가 이해·분석·생성하도록 만드는 기술로 응용 분야는 챗봇, 번역기, 감성 분석, 음성 비서, 텍스트 요약 등이 있다.
1-1. NLP(자연어처리)가 필요한 이유
<예시>
(1) "나는 밥을 먹었다"
(2) "밥을 먹은 건 나야"
(3) "나 밥 먹었어"
👉 우리 눈에는 1~3번이 모두 같은 의미지만, 사람이 쓰는 언어는 컴퓨터 입장에서 너무 복잡함! 컴퓨터는 문자열이 다르면 전혀 다른 걸로 인식!
-
컴퓨터는 숫자만 이해한다
- 텍스트 그대로는 계산 불가
- NLP → 단어와 문장을 벡터(숫자)로 변환 -
자연어는 애매하다 (모호성 문제)
- "배" = 배(ship), 배(pear), 배(stomach)
- NLP → 문맥을 보고 올바른 의미 파악 -
언어는 다양하다
- "좋아한다" vs "좋아해" → 같은 의미지만 다르게 표현
- NLP → 정규화, 형태소 분석으로 같은 의미로 처리
즉, NLP는 인간 언어의 복잡성을 기계가 처리할 수 있게 다듬는 기술!
1-2. 자연어 처리의 흐름
(1) 전처리 → (2) 벡터화(임베딩) → (3) 모델 학습 → (4) 예측/응답 → (5) 후처리1-3. 코퍼스(Corpus)
자연어처리에 사용하는 텍스트 데이터 모음, 사람이 실제로 말하거나 쓴 문장들을 모아놓은 데이터 덩어리로 텍스트 기반의 AI 모델(BERT, GPT 등)은 수백만~수십억 개의 문장들을 보고 언어 패턴을 학습한다.
| 종류 | 예시 | 설명 |
|---|---|---|
| 뉴스 코퍼스 | 뉴스 기사 10만 개 | 정보 전달형 문체 학습 |
| SNS 코퍼스 | 트위터/인스타 댓글 | 비공식/구어체 학습 |
| 영화 리뷰 | 긍정/부정 라벨 포함 | 감정 분석에 사용 |
| 위키백과 | 위키 문서 전체 | 지식 기반 언어 학습 |
| 번역 코퍼스 | 한-영 문장 쌍 | 기계 번역 학습용 |
| 대화 코퍼스 | 고객센터 상담 내역 | 챗봇 개발용 |

기록은 기억을 지배한다.