1. 모델 검증
1-1. 교차 검증
교차 검증(Cross-Validation) 은 데이터를 여러 폴드로 나눠 학습/검증을 반복해 성능을 추정하는 방법이다. 단일 홀드아웃보다 변동성이 적고 과적합 위험을 줄여준다.
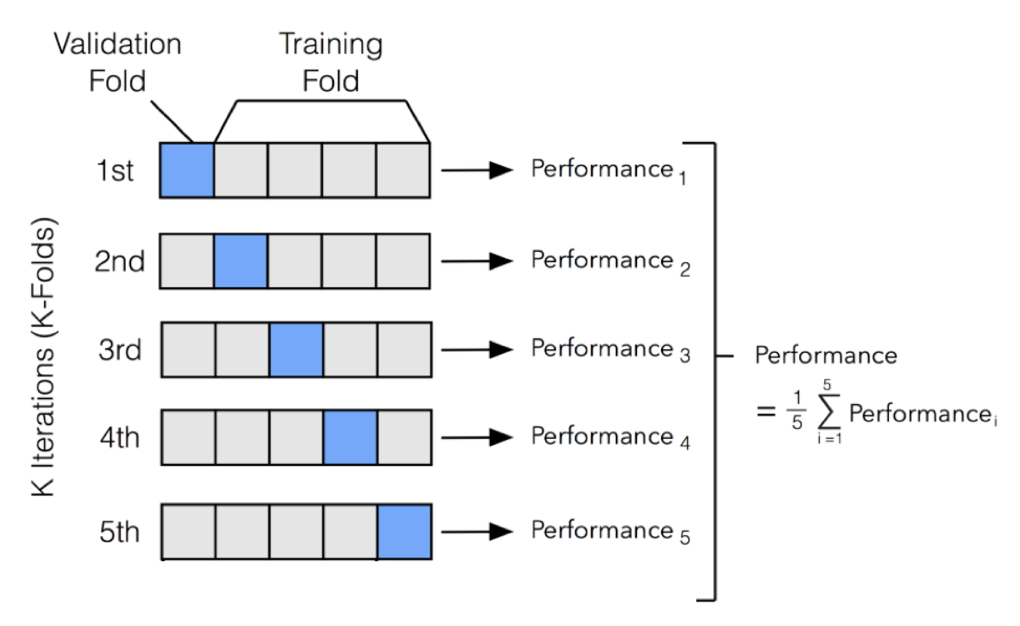
출처: https://incodom.kr
- k-겹 CV: 데이터를 k등분(예: k=5). k번 반복하며 한 폴드는 검증, 나머지는 학습. 평균 성능과 표준편차를 함께 기록.
- Stratified k-겹: 클래스 비율 유지(불균형 분류 필수).
- Group k-겹: 같은 그룹(예: 같은 사용자, 같은 환자)이 학습/검증에 동시에 들어가지 않도록 차단(리크 방지).
- Time Series CV: 시간 순서를 보존해 앞으로만 예측(rolling/expanding window).
- Nested CV: 안쪽 루프에서 하이퍼파라미터 튜닝, 바깥 루프에서 성능 추정 → 튜닝 편향 제거.
1-2. 혼동행렬 해석 및 평가 (분류)
혼동 행렬은 분류 알고리즘의 성능을 평가하는 데 사용되는 표입니다. 예측된 레이블을 실제 레이블과 비교하여 모델이 얼마나 잘 수행되고 있는지 명확하게 보여줍니다. 이 행렬은 모델이 어떤 종류의 오류를 범하고 있는지 이해하는 데 특히 유용하며, 개선할 부분을 식별하는 데 도움이 됩니다.
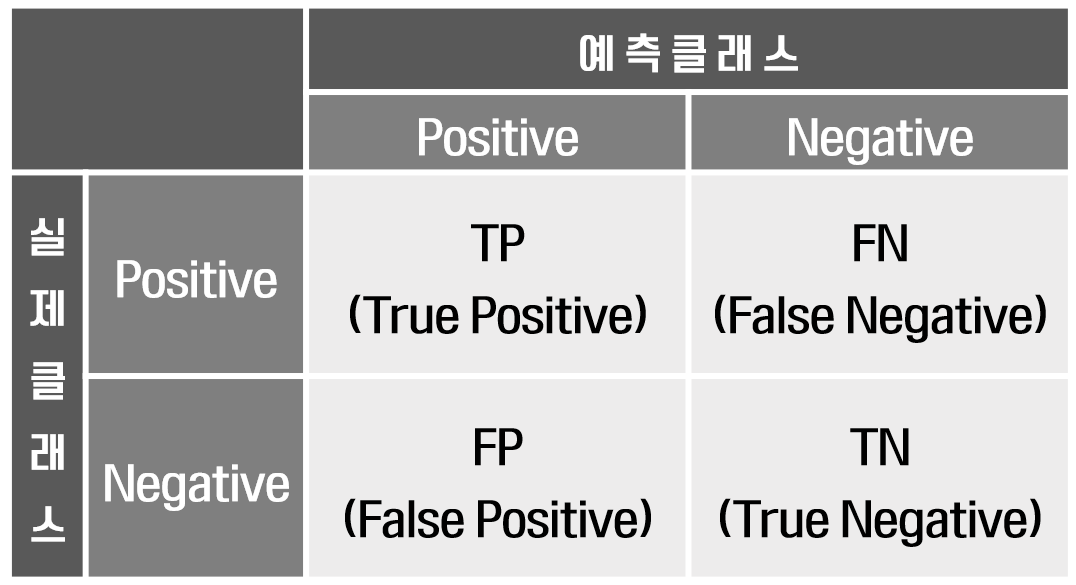
출처: https://leehah0908.tistory.com/19
1) 정확도(Accuracy)
- 전체 중 맞춘 비율. 클래스 불균형일 때 과대평가됨(“거의 전부 음성” 데이터에서 항상 음성이라고만 해도 높게 나옴).
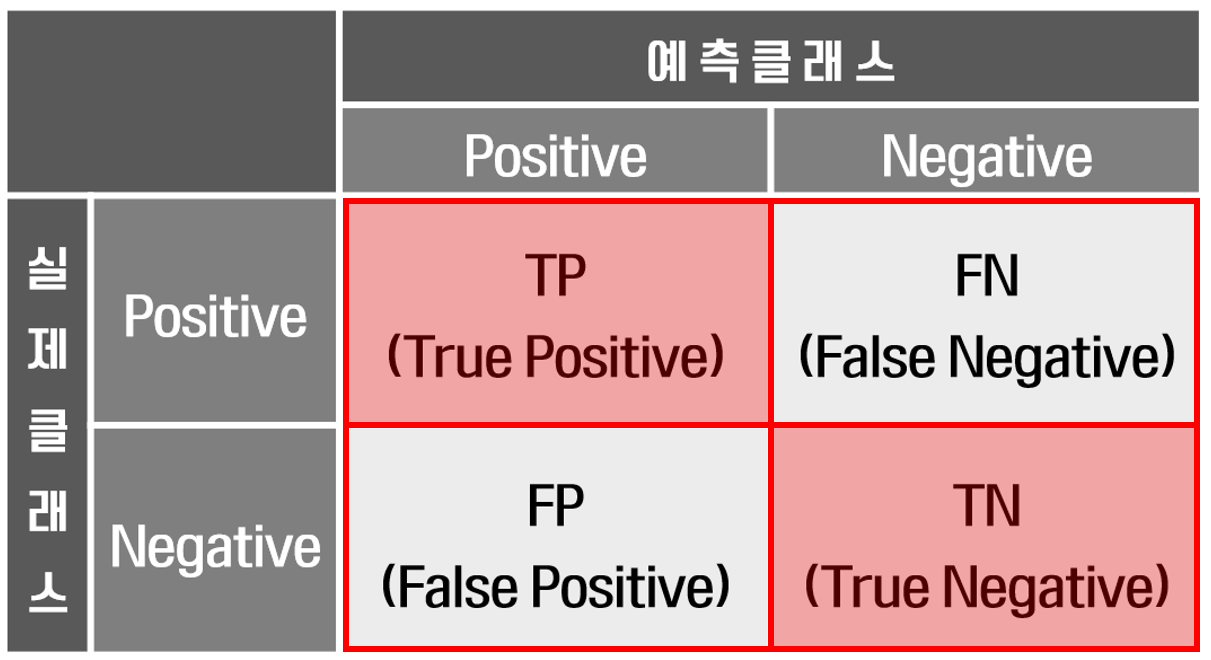
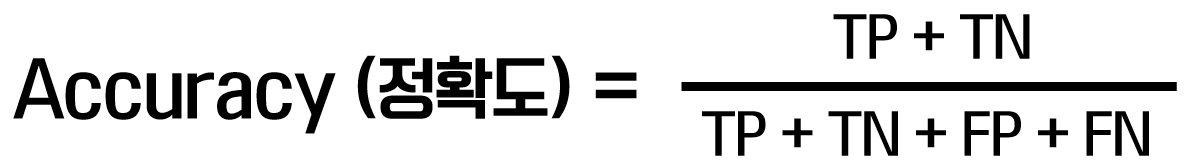
2) 정밀도(Precision)
- 양성으로 판단한 것 중 진짜 양성의 비율. 거짓 양성(FP) 비용이 클 때 중요(스팸 필터의 오탐, 금융 이상 탐지의 정상 계정 차단 등).
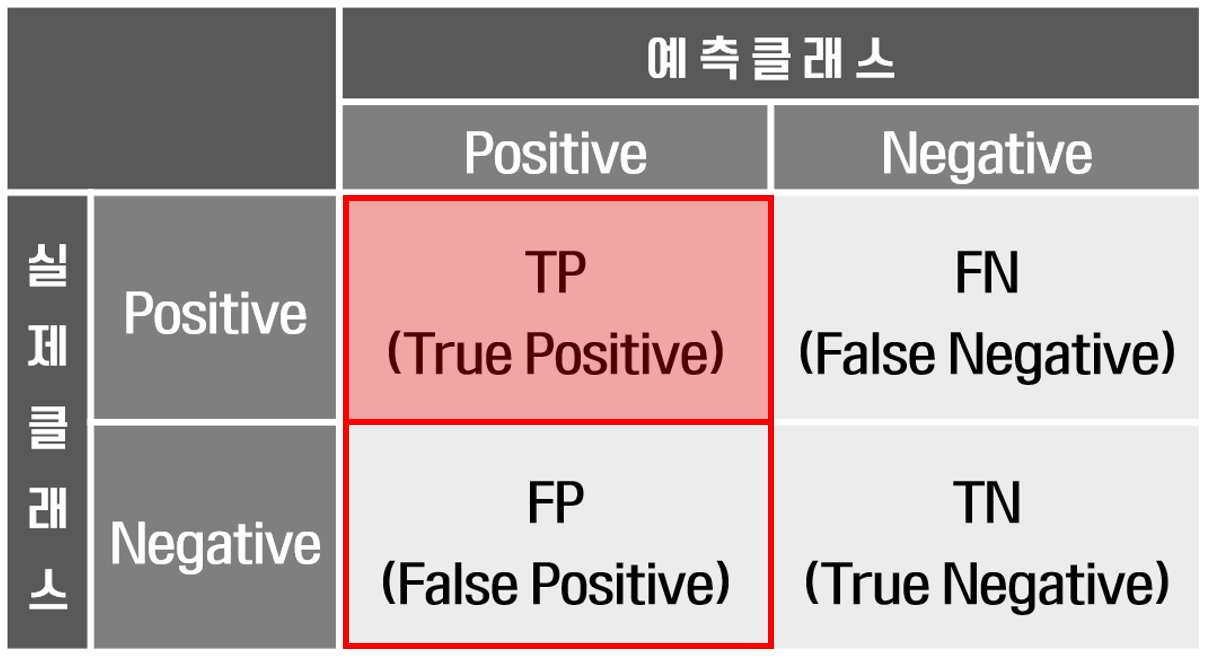

3) 재현율(Recall, Sensitivity)
- 실제 양성 중 잡아낸 비율. 거짓 음성(FN) 비용이 클 때 중요(질병 놓치면 안 됨).
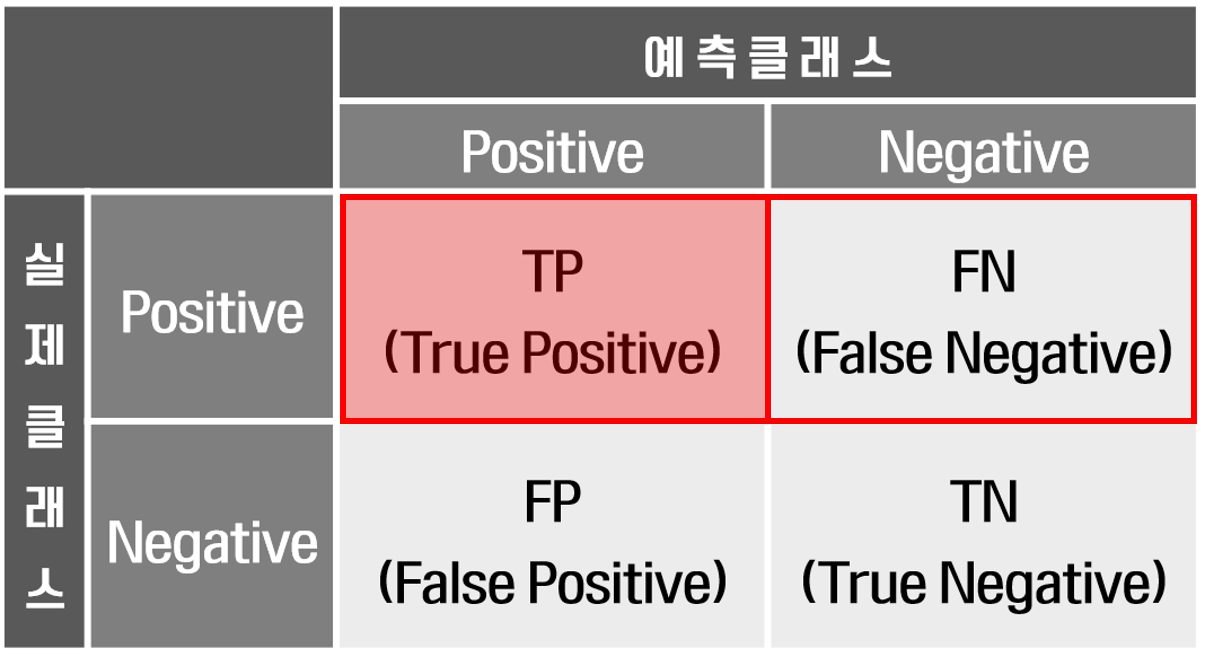

4) F1-score
- 정밀도와 재현율의 조화평균. 두 지표를 균형 있게 보려는 경우.
- 가중이 필요하면 Fβ-score(재현율 가중↑) 활용.
5) AUC / ROC
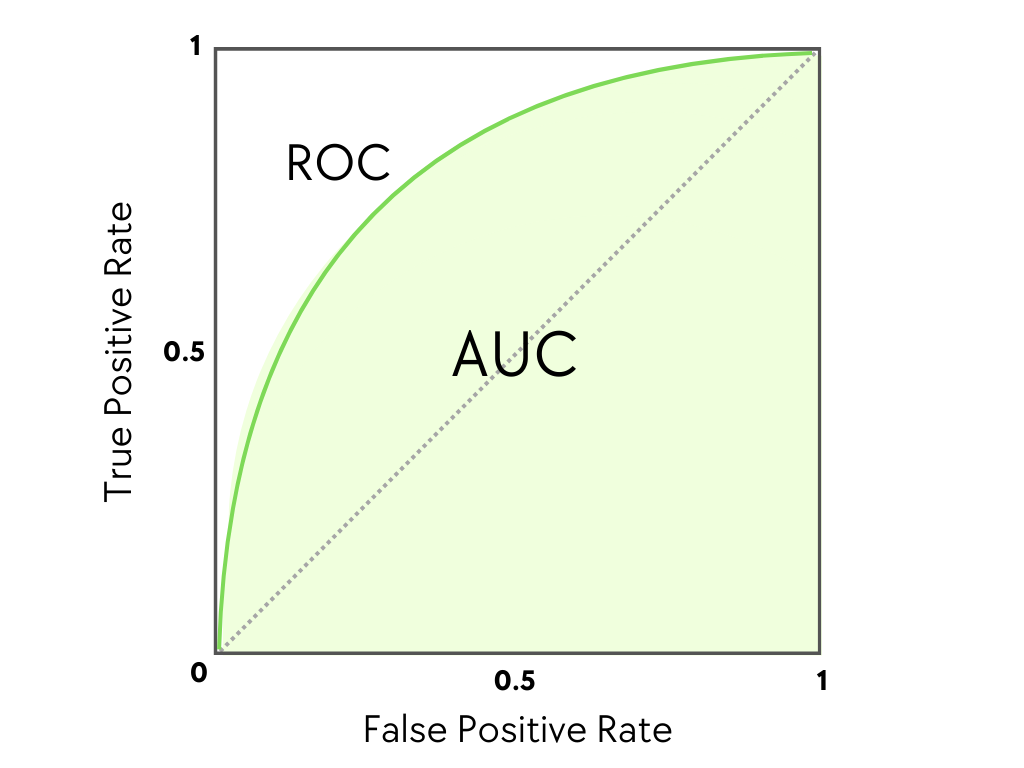
출처: https://www.blog.trainindata.com
- ROC 곡선: 임계값을 바꿔가며 TPR(재현율)-FPR(위양성율)을 그린 곡선.
- AUC: ROC 아래 면적(1에 가까울수록 좋음). 클래스 불균형에 비교적 둔감. 양성 비율이 극단적으로 낮을 땐 PR AUC(Precision-Recall AUC) 가 더 민감하게 차이를 보여준다.
1-3. 회귀모델 평가
1) MAE (Mean Absolute Error)
- 오차의 절대값 평균. 이상치에 강건, “평균적으로 얼마만큼 틀리는가”를 직관적으로 보여준다.
2) MSE (Mean Squared Error)
- 오차를 제곱해 평균. 큰 오차에 가중 처벌(이상치 민감). 최적화가 부드럽고 수학적으로 다루기 쉬움.
3) RMSE (Root MSE)
- MSE의 제곱근. 원 단위로 해석 용이(실무 리포트에서 선호).
4) R² (결정계수)
- 0~1(또는 음수 가능). 1에 가까울수록 설명력이 높음. 단, 과도한 변수 추가 시 과대평가되는 경향 → 조정 R²나 검증 점수와 함께 제시 권장.
2. 모델 성능 고도화
2-1. 성능 평가
- 모델 성능 평가는 학습된 모델이 새로운 데이터에서 얼마나 잘 작동하는지 확인하는 과정이다.
- 모델을 평가하는 방법에는 다음과 같은 방식이 있다.
- Hold-Out Validation: 데이터셋을 학습/검증/테스트로 나누어 모델을 평가
- Cross-Validation: 여러 개의 데이터 조각을 활용하여 반복적으로 모델을 평가
- Bootstrap Sampling: 데이터 샘플링을 반복적으로 수행하여 모델의 신뢰구간을 측정
- 학습 곡선과 검증 곡선을 분석하여 과적합이나 과소적합 여부를 판단할 수 있다.
2-2. 성능 향상
1) 특성공학(Feature Engineering)
더 나은 입력 데이터를 설계하여 모델의 예측력을 높인다.
- 파생 변수(Feature Creation) 생성
- 여러 개의 기존 변수를 조합하여 새로운 변수를 만드는 기법
- 다항 특성 생성(Polynomial Features)
- 비선형 관계를 표현하기 위해 기존 변수를 조합하여 새로운 다항식 특성을 추가
- 로그 변환(Log Transformation)
- 데이터의 분포를 정규화하여 선형 모델에서 더 좋은 성능을 내도록 변환
- 스케일링(Scaling)
- 표준화(Standardization): 평균을 0, 표준편차를 1로 맞춤
- 정규화(Normalization): 최소값을 0, 최대값을 1로 맞춤
2) 하이퍼파라미터 튜닝
하이퍼파라미터는 모델의 학습 과정에 영향을 미치는 설정 값이자 모델이 학습하는 과정에서 직접 조정되지 않는 매개변수로, 사용자가 직접 설정해야 하는 값이다. 적절한 하이퍼파라미터를 설정하면 과적합(Overfitting)과 과소적합(Underfitting)을 방지할 수 있고, 일반화 성능을 향상시킬 수 있다.
- 그리드 서치(Grid Search): 주어진 하이퍼파라미터 값들의 가능한 모든 조합을 탐색하여 최적의 성능을 내는 조합을 찾는 방식.
- 랜덤 서치(Random Search): 가능한 모든 조합을 탐색하는 그리드 서치와 달리, 지정된 범위 내에서 무작위로 조합을 선택하여 모델을 학습하고 평가하는 방식.
3) 앙상블 학습
- 앙상블 학습은 여러 개의 모델을 결합하여 성능을 높이는 방법으로 여러 모델의 예측을 결합하여 더 나은 결과를 얻는다.
- Bagging(랜덤포레스트): 분산 감소, 과적합에 강함.
- Boosting(XGBoost/LightGBM/CatBoost): 약학습기 누적 개선, 탭울러에서 강력.
- Stacking/Blending: 서로 다른 모델의 보완적 장점 결합.
- 주의: 복잡도·지연·운영비용 증가.
4) 데이터 증강
- 비전: 회전/크롭/색변환, CutMix/MixUp, AutoAugment.
- 텍스트: 역번역·동의어 치환·스팬 마스킹(의미 보존 중요).
- 오디오: 시간 스트레치, 피치 변환, 잡음 주입, SpecAugment.
- 불균형: 클래스별 오버샘플링(SMOTE/ADASYN) 또는 언더샘플링, 클래스 가중치.
참고 자료
블로그(1): https://13akstjq.github.io
블로그(2): https://leehah0908.tistory.com/19

기록은 기억을 지배한다.