이번 시간엔 Open API를 이용해 데이터를 가져오는 방법과 BeautifulSoup을 통해 데이터를 크롤링 해오는 방법에 대해 정리 해보았다.
1. Open API 란?
오픈 API는 공개적으로 사용할 수 있도록 제공되는 API(Application Programming Interface)로, 개발자가 표준화된 방법으로 특정 서비스나 데이터에 접근할 수 있도록 하는 것이다.
1-1. Open API의 특징
위의 설명을 읽었다면 오픈하지 않는 API도 있느냐 하는 궁금증이 생길텐데 물론 API는 선택에 따라 공개/비공개를 할 수 있다. 그렇다면 왜 굳이 힘들여서 만든 정보를 공개하느냐? 바로 API 공개를 통하여 생태계 확장, 혁신 촉진, 수익 창출 같은 긍정적인 효과를 가져올 수 있기 때문이다. 하지만 보안, 운영 비용, 전략적 손실 같은 부정적인 영향이 생길 수도 있기에 회사는 공개 여부를 결정할 때 비용-편익 분석과 보안에 대하여 검토해야 하고 또, 공개하더라도 인증 키(API Key), 요청 제한, 사용자 권한 관리를 통해 남용과 위험을 최소화하는 방법이 필요하다.
1-2. Open API를 통한 데이터 수집 방법
NAVER Developers: https://developers.naver.com/docs/serviceapi
나는 수업시간에 네이버 디벨로퍼스를 이용했는데 위 페이지에 들어가서 네이버 아이디로 로그인을 한 뒤 api 이용 신청을 하면 내 아이디 고유의 Client ID와 Client Secret이 생성된다. 그리고 각 항목별로 필수 파라미터와 참고 사항이 나와있으니 잘 읽어보고 필요한 코드를 작성해주면 된다.
import urllib.request
import urllib.parse
import json
# api 호출을 위한 client_id, client_secret 변수 설정
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
encText = urllib.parse.quote('오늘 점심')
# 요청 url
url = "https://openapi.naver.com/v1/search/news.json?query=" + encText #json 방식
# url = "https://openapi.naver.com/v1/search/news.xml?query=" + encText #xml 방식
# request 객체 생성 -> 헤더 생성
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
# 실제 요청 후 응답
response = urllib.request.urlopen(request)
print(response.getcode()) # 응답코드 400(오타, 잘못된 url 등), 500번대(서버에러, 서비스 제공하는 쪽의 에러)이면 실패, 200이면 성공!, getcode(): 응답코드반환
response_body = response.read() # read(): 응답 내용 반환
print(response_body.decode('utf-8')) # 각각의 객체 형태로 뉴스 기사를 가져온다!2. BeautifulSoup 이란?
BeautifulSoup은 Python 기반의 HTML, XML 파일을 파싱(parsing)하여 정적페이지의 데이터를 추출하는 라이브러리로 파싱하기 위해선 html의 구조를 먼저 알아야한다.
2-1. HTML 이란?
HTML(하이퍼텍스트 마크업 언어)은 웹 페이지의 구조를 정의하는 데 사용되며, 다양한 태그로 구성되어있다. 아래는 네이버 메인 페이지의 구조를 가져온 것으로 가장 위에 보면 <!DOCTYPE html> 이라고 명시되어 있다.
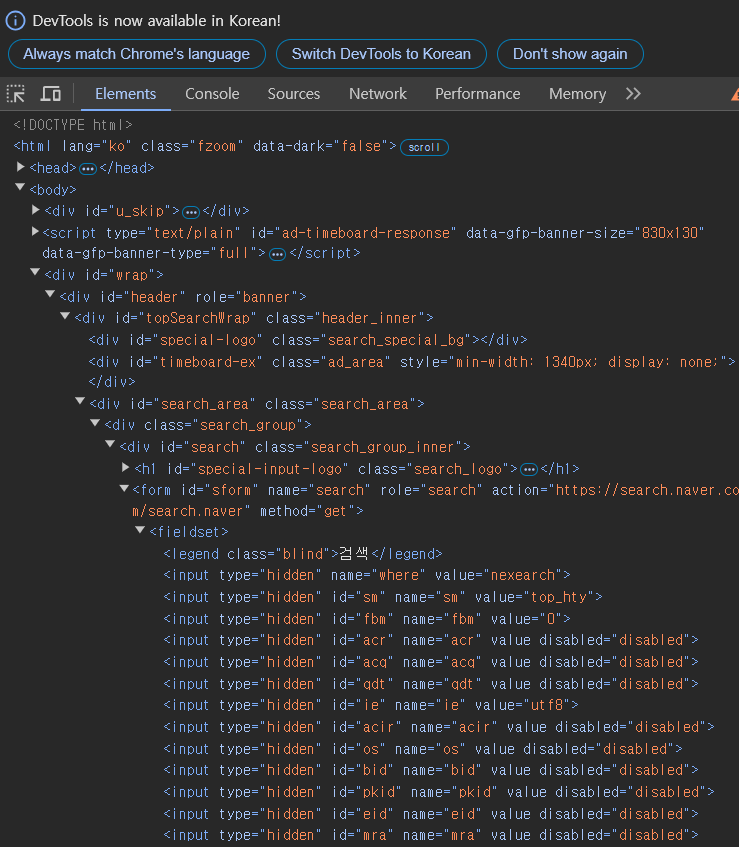 예전에 혼자 BeautifulSoup으로 크롤링을 시도해 본 적이 있었는데 그땐 잘 동작하지 않았었고 그 이유를 알 수 없었는데 이번에 강의를 듣다보니 아마 html의 구조를 제대로 알지 못해 태그를 잘못 적지 않았을까 하는 추측. 하여간 BeautifulSoup을 사용하기 전에 html의 구조와 태그를 대략적으로 알고 있어야 원하는 정보를 불러올 수 있다.
예전에 혼자 BeautifulSoup으로 크롤링을 시도해 본 적이 있었는데 그땐 잘 동작하지 않았었고 그 이유를 알 수 없었는데 이번에 강의를 듣다보니 아마 html의 구조를 제대로 알지 못해 태그를 잘못 적지 않았을까 하는 추측. 하여간 BeautifulSoup을 사용하기 전에 html의 구조와 태그를 대략적으로 알고 있어야 원하는 정보를 불러올 수 있다.
2-2. HTML의 태그
| 분류 | 태그 | 설명 |
|---|---|---|
| 문서 구조 | <html> | 루트태그 |
<head> | 메타 정보 | |
<body> | 내용 | |
| 텍스트 | <h1> ~ <h6> | 제목 <h1>이 가장 크고 <h6>이 가장 작다 |
<p> | 단락을 정의 | |
<br> | 줄바꿈 | |
<strong> | 텍스트 강조, 굵게 | |
<em> | 텍스트 기울임 | |
| 목록 | <ul> | unordered-list(순서 없는 목록) |
<ol> | ordered-list(순서 있는 목록) | |
<li> | 항목 | |
| 링크 및 미디어 | <a> | 하이퍼링크 |
<img> | 이미지 삽입 | |
<audio> <video> | 오디오와 비디오 파일 삽입 | |
| 표 (Table) | <table> | 표를 정의 |
<tr> | 행(row) | |
<td> | 셀(cell) | |
<th> | 표의 헤더 셀 | |
| 폼 (Form) | <form> <input> | 사용자 입력을 받는 폼 |
<button> <textarea> | 버튼과 멀티라인 텍스트 입력 필드 | |
| 구조적 요소 | <div> | 레이아웃과 스타일링-블록 요소 |
<span> | 레이아웃과 스타일링-인라인 요소 | |
| 메타 및 스크립트 | <meta> <title> <link> | 문서 정보, 제목, 외부 CSS 연결 등을 정의 |
<script> | 자바스크립트 삽입 |
2-3. HTML의 구조
HTML의 구조는 크게 <head> 태그와 <body> 태그로 나누어져 있는데,
<head> 태그는 문서의 설정 및 메타데이터를 정의하며, 사용자는 보지 못하지만 브라우저와 검색엔진이 이를 활용하고, <body> 태그는 사용자에게 보이는 콘텐츠를 포함하며, 실제 웹페이지의 "보이는 부분"을 구성한다.
<!DOCTYPE html>
<html>
<head>
<!-- 문서의 메타데이터 (사용자에게 보이지 않음) -->
<title>문서 제목</title>
<meta charset="UTF-8">
<meta name="description" content="설명">
<link rel="stylesheet" href="style.css">
<script src="script.js"></script>
</head>
<body>
<!-- 사용자에게 보이는 콘텐츠 -->
<h1>안녕하세요</h1>
<p>이것은 본문 내용입니다.</p>
</body>
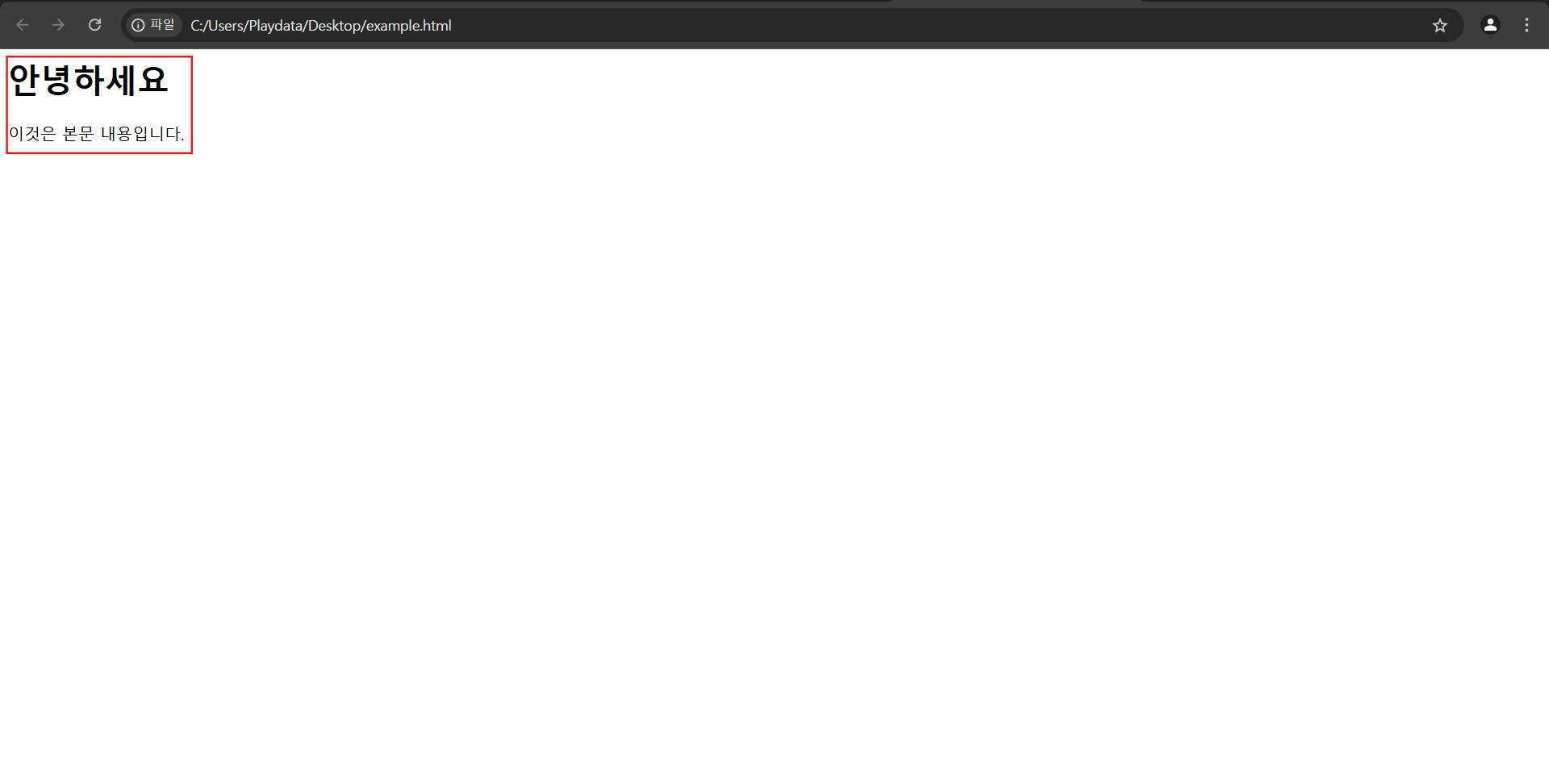
</html>위의 코드로 html 파일을 만들면 <body> 태그 안에 적힌 내용이 아래와 같이 출력되는 것을 확인할 수 있다.
2-4. BeatifulSoup의 활용 예시
아래의 예시는 html의 태그를 활용하여 BeatifulSoup으로 웹페이지의 이미지를 가져와 저장하는 과정이다.
import os
import requests
from bs4 import BeautifulSoup
# 이미지를 다운로드할 웹 페이지 URL
url = 'https://example.com'
# 요청 보내기
response = requests.get(url)
bs = BeautifulSoup(response.text, 'html.parser')
# 이미지 저장할 폴더 경로
save_folder = 'downloaded_images'
# 페이지에서 모든 <img> 태그 찾기
images = bs.find_all('img')
# 이미지 다운로드 및 저장
for idx, img in enumerate(images):
img_url = img.get('src') # 이미지 URL 가져오기
# 상대 경로인 경우 절대 경로로 변환
if img_url and not img_url.startswith('http'):
img_url = url + img_url
try:
# 이미지 요청
img_response = requests.get(img_url)
img_response.raise_for_status() # 요청에 실패한 경우 예외 발생
# 이미지 파일명 (파일 이름은 인덱스를 붙여서 저장)
img_filename = os.path.join(save_folder, f'image_{idx+1}.jpg')
# 이미지 파일 저장
with open(img_filename, 'wb') as file:
file.write(img_response.content)
print(f'Image {idx+1} saved as {img_filename}')
except requests.exceptions.RequestException as e:
print(f'Error downloading {img_url}: {e}')HTML 참고자료 https://developer.mozilla.org/
크롤링 참고자료1 https://velog.io/@dorong_park/
크롤링 참고자료2 https://pointer81.tistory.com/
정적/동적페이지 참고자료1 https://wikidocs.net/141607
정적/동적페이지 참고자료2 https://yozm.wishket.com/
