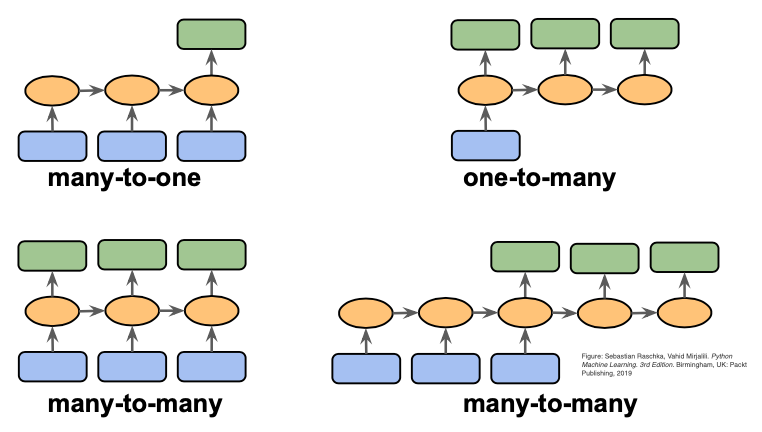
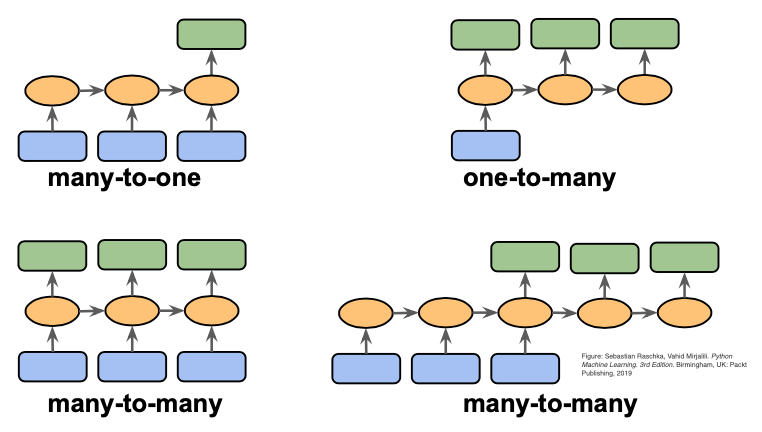
이미지 출처: https://deeplearningmath.org/sequence-models
시퀀스 모델링(Sequential Modeling)
시퀀스 모델(Sequence Models)은 순차 데이터(텍스트, 음성, 시계열 등) 를 처리하기 위한 딥러닝 모델을 말한다.
- 전통적 시퀀스 모델: RNN → LSTM → GRU (순차 데이터 기억 → 개선 → 경량화)
- 발전: Seq2Seq → Attention → Transformer (번역/생성 → 문맥 중요도 → 병렬 처리)
- 현대 LLM: Transformer 기반 (BERT, GPT, Qwen 등)
1. RNN (Recurrent Neural Network)이란?
- 시계열 데이터 → 이전 상태 기억
- 입력()을 받으면 은닉 상태()를 업데이트하고, 출력()을 생성
- 은닉 상태 는 다음 시점으로 전달되어 이전 정보가 누적됨
입력 x_t → 은닉 상태 h_t → 출력 y_t
↓
(다음 시점 h_{t+1}로 전달)1-1. 동작 과정
(1) 토큰화된 각 단어(토큰)를 RNN 입력으로 전달
(2) 은닉층(hidden layer)에서 처리
(3) 출력층(output layer)으로 예측값 생성
(4) 동시에 은닉 상태 를 다음 단계 입력으로 전달
✅ 각 시점의 은닉 상태 는 다음 시점으로 전달
✅ 은닉 상태 를 이용해 출력 생성
✅ 모든 단계에서 이전 정보가 누적되며 학습
1-2. 출력층 (Output Layer)
출력층은 은닉 상태를 변환하여 최종 출력을 만드는 부분이다.
- 일반적으로 Dense layer + 활성화 함수(sigmoid, softmax) 사용
- 출력 방식은 Task에 따라 달라짐
| Task | 출력층 필요 여부 | 이유 |
|---|---|---|
| 감정 분석 | ✅ 필요 | 긍정/부정 확률 계산 (sigmoid) |
| 기계 번역 ✅ 필요 단어별 확률 계산 (softmax) | ||
| 개체명 인식 (NER) | ✅ 필요 | 각 단어에 대한 태그 예측 (softmax) |
| 피처 추출 | ❌ 불필요 | 은닉 상태 자체를 사용 |
| 다층 RNN | ❌ 불필요 (중간 층) | 다음 RNN 층으로 은닉 상태 전달 |
1-3. 출력층 (Output Layer) 작동 방식
예제 1: 감정 분석 (긍정/부정)
입력 문장 → 임베딩 → RNN → 은닉 상태 h_T → Dense(1, sigmoid) → 출력 (긍정 확률 0.91)- 입력 문장: "이 영화 진짜 재미있다!"
- 출력층: Dense(1, activation='sigmoid')
- 출력(예측값): 0.91 (긍정 확률 91%)
예제 2: 기계 번역
"나는" → RNN → 은닉 상태 h1 → 출력층(Dense+Softmax) → "I"
"학교에" → RNN → 은닉 상태 h2 → 출력층(Dense+Softmax) → "go"
"간다" → RNN → 은닉 상태 h3 → 출력층(Dense+Softmax) → "to" - 입력 문장: "나는 학교에 간다"
- 출력층: Dense(어휘 크기, activation='softmax')
- 출력(예측값): ["I", "go", "to", "school"] (각 단어에 대한 확률이 가장 높은 결과 선택)
** 실제 번역은 훨씬 복잡하기에 간단한 설명을 위해 위와 같이 1:1로 단어를 매핑 하였음. 실제 번역 시,Seq2Seq (Encoder–Decoder)구조를 이용해 입력 전체 문장을 인코딩 → 번역을 디코딩 함.

기록은 기억을 지배한다.