이미지 출처: https://www.researchgate.net/
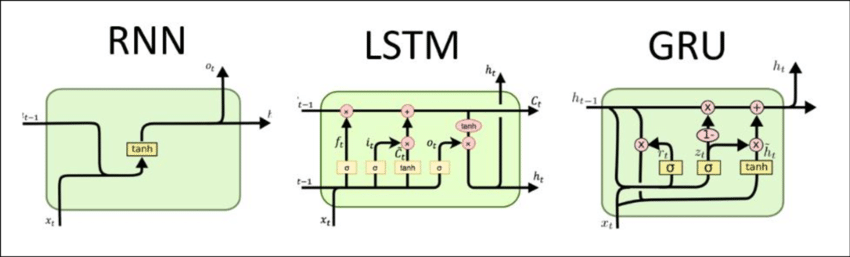
RNN vs LSTM vs GRU
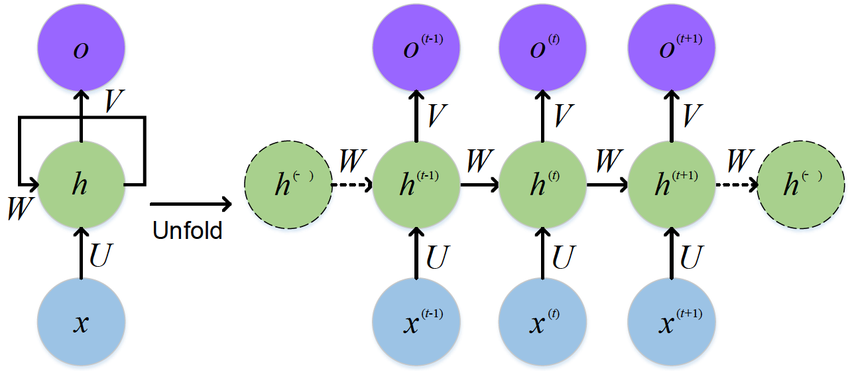
1. RNN (Recurrent Neural Network)
이미지 출저: https://www.researchgate.net/
- 이전 시점의 출력(또는 hidden state)을 다음 시점의 입력과 함께 사용 → 시계열·자연어 데이터 처리 가능
- 문제점:
- 역전파 과정에서 기울기 소실/폭발(Vanishing/Exploding Gradient) 발생 → 앞부분 정보가 뒷부분에 잘 전달되지 않음
- 입력이 길어질수록 장기 의존성(Long-term dependency) 문제 발생
👉 문맥이 긴 문장이나 긴 시계열 데이터는 학습하기 어려움.
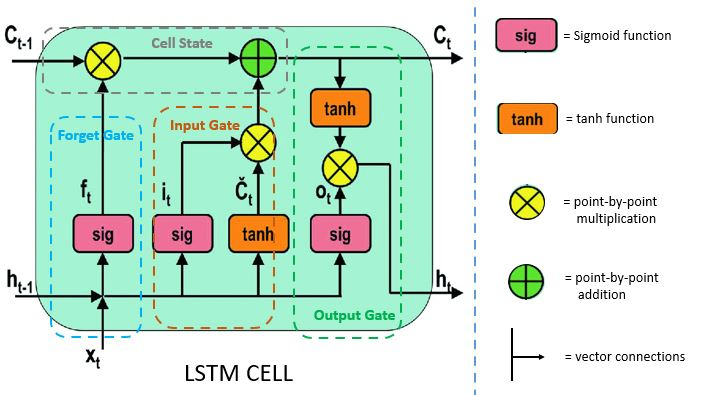
2. LSTM (Long Short-Term Memory)
이미지 출저: https://www.pluralsight.com/
-
RNN의 기울기 소실 문제를 해결하기 위해 고안
-
핵심 구조: Cell State + 3가지 게이트
(1) Forget Gate → 불필요한 정보는 버림
(2) Input Gate → 새로운 정보를 얼마나 저장할지 결정
(3) Output Gate → 최종적으로 어떤 정보를 출력할지 결정 -
장점: 장기 의존성 문제 해결 → 문맥을 더 길게 기억 가능, 복잡한 문맥 이해에 효과적
-
단점: 게이트가 3개라 연산량이 많고, 학습 속도가 느림
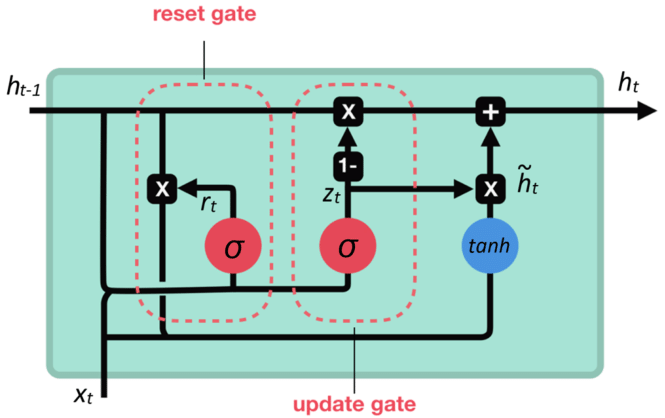
3. GRU (Gated Recurrent Unit)
이미지 출저: https://www.researchgate.net/
-
LSTM은 성능은 좋지만 구조가 복잡하여 단순화 + 효율성 개선한 구조가 GRU
-
핵심 구조:
- Cell state와 Hidden state를 합침
- 게이트 수를 줄여 Update Gate + Reset Gate (2개)만 사용
-
장점:
- 계산량이 줄어 LSTM보다 빠르고 효율적
- 성능은 LSTM과 비슷하거나 더 좋은 경우도 있음 (데이터셋에 따라 다름)
-
단점: LSTM보다 세밀한 정보 제어는 어렵다는 평가도 있음

기록은 기억을 지배한다.