
오늘의 포스팅은 반려견 상담 AI 챗봇, PetMind 개발기의 마지막 포스팅으로 프론트엔드 구현과 배포 과정을 담았습니다. 이에 앞서 1, 2, 3편을 아직 읽지 못하셨다면 순서대로 읽어주시길 부탁드립니다! :0
Team Project: PetMind, 반려견 상담 AI 챗봇 개발기(1) 바로가기
Team Project: PetMind, 반려견 상담 AI 챗봇 개발기(2) 바로가기
Team Project: PetMind, 반려견 상담 AI 챗봇 개발기(3) 바로가기
개발 과정: 프론트엔드 구현 및 배포
프론트엔드는 HTML/CSS/JS를, 배포는 Docker와 AWS EC2/RDS/S3를 활용하였는데요, 배포까지의 진행 과정과 그 안에서 만난 문제점 및 해결과정에 대해 정리 해보았습니다.
11. 프론트엔드
프론트엔드는 피그마로 만들어두었던 디자인과 컨셉을 화면으로 표현하는 부분에선 크게 어려운 부분이 없었습니다만 달력과 같은 동적 UI를 구현하고 연결하는 부분에서 약간의 어려움을 겪었습니다. (아래는 화면설계서의 일부입니다)
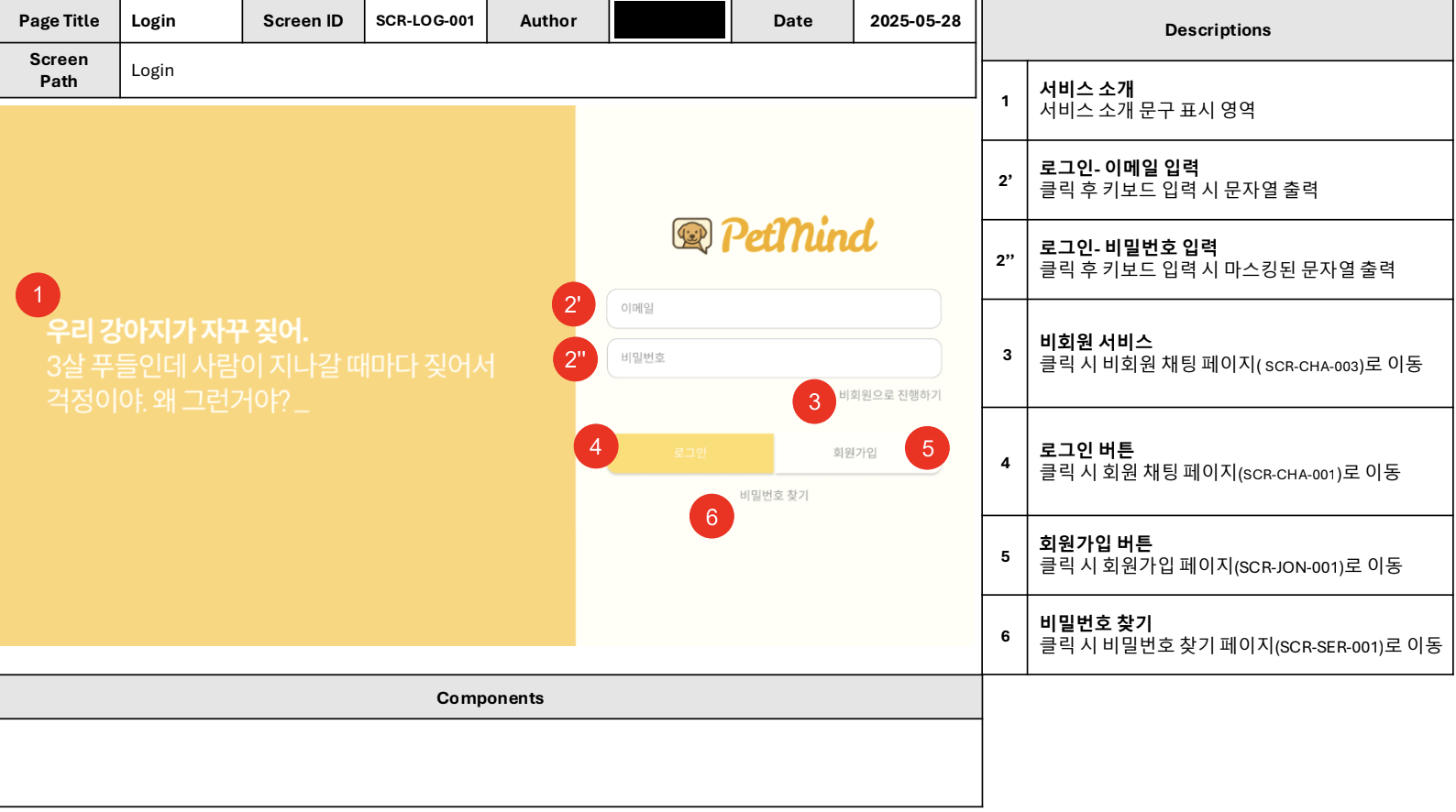
그 밖에 팀원이 맡은 페이지를 각자 개발하다보니, 처음엔 header / main / footer 레이아웃이 일관되지 않고, 변수명 충돌이 일어나는 경우도 있었습니다. 그래서 팀원들과 다음과 같이 기초적인 부분을 공유하였는데요,
-
기본 템플릿 정의
공통 레이아웃: header / main / footer
CSS 클래스명, 그리드/플렉스 구조 통일 -
컴포넌트 설계
재사용 가능한 버튼, 폼, 카드 등 컴포넌트 미리 정의
팀원마다 컴포넌트 라이브러리를 공유 -
스타일 가이드 작성
컬러, 폰트, 간격, 버튼 스타일 통일
이처럼 여러 팀원이 함께 작업할 경우 구조와 스타일을 미리 정의해두면, 화면의 일관성을 확보하고 코드 중복 최소화 및 컴포넌트 재사용성을 높일 수 있다는 점을 깨닫게 되었습니다.
사실 현업에 계신 분들에겐 매우 당연한 일이겠지만 저처럼 입문자에겐 프로젝트를 통해 협업을 하며 깨닫게 되는 부분들이 참 많았던 프론트엔드 개발이었습니다.
12. 도커(Docker)/AWS EC2로 배포하기
로컬 환경에서 테스트한 Django 앱과 관련 서비스를 실제 사용자에게 제공하기 위해 배포하기 위해 Docker를 활용해 앱을 컨테이너화하고, AWS EC2 서버에 올려 진행하였습니다.
- Docker 컨테이너화: 앱, DB, Nginx 등 기능별 서비스를 각각 컨테이너로 분리하여 관리
- Docker Compose: 여러 컨테이너를 한 번에 빌드하고 실행할 수 있도록 조율
- AWS EC2 배포: Ubuntu 인스턴스를 생성하여 컨테이너 실행 환경 제공
- 환경 변수 관리(.env): 서버에서 필요한 설정값(SECRET_KEY, DB 비밀번호 등)을 안전하게 전달
그런데 배포 과정에서 한 가지 문제가 발생했습니다. 바로 업로드한 이미지가 로컬 환경에서는 정상적으로 처리 되었지만, 서버 환경에서는 로딩 되지 않는 현상이었는데요, 문제 해결을 위해 파악한 몇가지 원인은 다음과 같습니다:
- 컨테이너 내부 경로와 로컬 경로 차이
- .env 파일의 S3 키나 버킷 정보 미설정
- AWS IAM 권한 미설정
찾아낸 원인은 경로와 권한 문제로 이미지 파일을 찾지 못하는 문제였습니다. 그래서 이미지 경로를 다음과 같이 수정해주었습니다.
- 기존 코드:
def get_base64_image에서 이미지 경로가media/또는/media/로 시작하는 경우, 해당 부분을 제거하여 상대 경로를 얻고 있었음 - 수정된 코드:
def get_base64_image의 인자명을image_path에서image_path_or_url로 변경하고, 이미지 경로가media/또는/media/로 시작하는 경우를 처리하는 로직 추가
이 과정을 통해, 배포 환경에서 발생할 수 있는 경로와 권한 문제를 디버깅하며 서버에서 안정적으로 이미지와 데이터를 처리할 수 있도록 조치하였습니다.
또한, EC2 서버가 계속 다운되는 문제가 있었는데 기존 사용하던 t3.micro에서 t3.small로 업그레이드 하니 바로 해결되었습니다. 아래는 리소스 사용량 추정표인데요:
| 구성 요소 | 메모리 사용량 | CPU 사용량 |
|---|---|---|
| Django 애플리케이션 | 200-500MB | 1 vCPU |
| MySQL 8.0 | 500MB-1GB | 0.5 vCPU |
| 이미지 처리 (Pillow) | 100-300MB | 0.5 vCPU |
| Docker 오버헤드 | 200-400MB | 0.2 vCPU |
| 시스템 예약 | 500MB | 0.3 vCPU |
| 총합 | 1.5-2.7GB | 2.5 vCPU |
메모리 요구사항과 CPU 요구사항을 고려했을 때, t3.medium이 권장되었지만 저희는 시험 서버였고, 테스터가 많지 않아 동시 접속량이 낮았기 때문에 최초 사용하던 micro에서 small로 한단계 업그레이드 만으로 충분한 운영이 가능했습니다.
13. 응답 구조 한 눈에 보기
마지막으로 내용을 총 정리하여 질의응답 구조를 한 눈에 볼 수 있도록 정리 해보았습니다.
우선 Django 앱을 기능별 Docker 컨테이너로 구성하여 AWS EC2 서버에 배포하였고, AI 모델은 별도 서버(RunPod)에 배포하여, 모델 응답은 RunPod API를 통해 받고, 웹앱 서비스는 EC2에서 처리되도록 구조를 분리하였습니다.
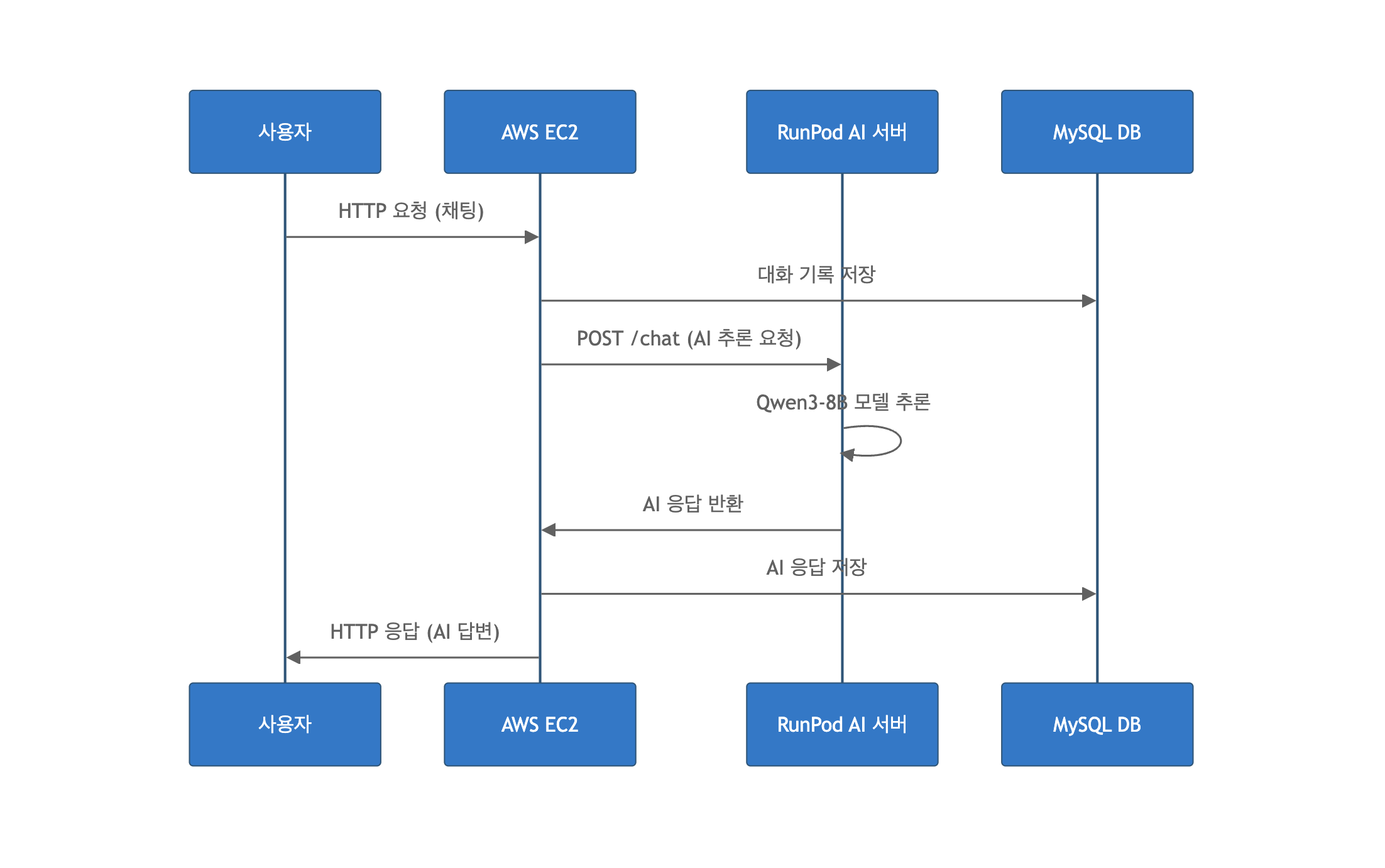
위 첨부한 이미지를 참고하면 조금 더 쉽게 이해하실 수 있는데요,
사용자가 질문을 입력하면 요청이 EC2 서버로 전달되고, 서버는 RunPod의 AI 모델에 추론을 요청합니다. 모델 추론이 완료되면 결과가 다시 EC2 서버로 반환되고, 서버는 사용자에게 AI 답변을 전달합니다.
과정을 풀어서 설명해보자면 다음과 같이 볼 수 있습니다:
[로컬 개발 환경]
├─ Dockerfile
│ - Python 환경 설정
│ - 의존성 설치 (requirements.txt)
│ - 앱 코드 복사
│ - Gunicorn 실행 명령
│
├─ docker-compose.yml
│ - 서비스 정의
│ - web (Django)
│ - db (MySQL)
│ - nginx (리버스 프록시)
│ - 포트, 환경변수, 볼륨 설정
│
├─ default.conf
│ - Nginx 리버스 프록시 설정
│
├─ gunicorn.conf.py
│ - Gunicorn 워커 수, 바인드, 타임아웃 등 설정
│
└─ .env
- Django SECRET_KEY, DB 비밀번호 등 환경 변수
[배포 순서]
1. GitHub에 코드 push (.env 제외)
2. AWS EC2 Ubuntu 인스턴스 생성
3. SSH 접속 (ssh -i "KEY.pem" ubuntu@EC2_IP)
4. Git clone → 프로젝트 가져오기
5. .env 파일 업로드
6. docker-compose build → 이미지 생성
7. docker-compose up -d → 컨테이너 실행
[EC2 서버]
├─ web 컨테이너 (Django + Gunicorn)
├─ db 컨테이너 (MySQL)
└─ nginx 컨테이너 (리버스 프록시, default.conf 사용)
[서비스 접속]
브라우저 → http://EC2_PUBLIC_IP:포트/앱이름/
│
└─ Nginx → web 컨테이너 → 앱 처리 → DB 조회 후 응답이렇게 앞서 설명드렸던 도커와 AWS EC2 서버를 활용한 배포까지 정리하고 나니 비로소 프로젝트가 끝났다는 느낌이 듭니다. AWS의 과금 방식에 혹 실수로 키를 노출하거나 너무 큰 금액이 청구되진 않을까 걱정하며 배포를 무서워했던게 엊그제 같은데, 큰 사고 없이 며칠 간 서버를 열어 실사용자를 받고 최종 발표와 시연까지 잘 마쳤습니다.
4회에 걸친 길고 긴 포스팅은 프로젝트 영상으로 마무리할까 싶습니다.
아래 이미지를 클릭하시면 동영상 재생이 가능합니다. 또한 맨 아래 PetMind GitHub 링크를 넣어뒀으니 많은 관심과 피드백 부탁드립니다! 끝까지 읽어 주셔서 감사합니다! :D
최종 프로젝트를 마치며..
"팀프로젝트"라는 하나의 과정이 끝났습니다.
PetMind가 원하는 수준에 도달했느냐를 물어보신다면 솔직히 말해 그렇지는 않습니다.
음성데이터셋이 있었다면 음성처리도 구현하고 싶었고, 논문 등의 신뢰도 높은 데이터를 더 많이 수집하여 개발해보고 싶었습니다. 그러나 데이터를 구하는 문제나, 비정형 데이터 다루기, 파인튜닝, 임베딩모델/벡터DB 선정, 프레임워크 등 모든 과정은 선택의 연속이었으며, 여러 선택지 사이에서 2개월 간 꾸준히 더 발전된 서비스를 위해 노력했다는 점에서 우리 팀원들에게 박수를 보내고 싶습니다.
개발 인생 6개월 차, 처음으로 실사용자의 피드백을 받아봤던 PetMind 프로젝트를 좋은 사람들과 함께 할 수 있어 멋진 경험이었습니다. 2개월 간 함께 해준 팀원들, 강사님, 멘토님 감사합니다!! :D
