Part 3. Python Basics for AI
chapter 5) Numpy 2
네이버 AI 부스트캠프의 Pre-course 수업을 듣던 중 공부한 내용을 정리하고, 추가적으로 따로 공부한 부분이 생기면 함께 필기했습니다.
대부분의 캡쳐, 정보는 부스트캠프 강의에서 얻었으며 오직 개인 공부의 목적으로 포스팅합니다.
강의 링크는 여기에
Numpy 2
1. Handling shape
1) reshape
- Array의 Shape의 크기를 변경함, element의 갯수는 동일.
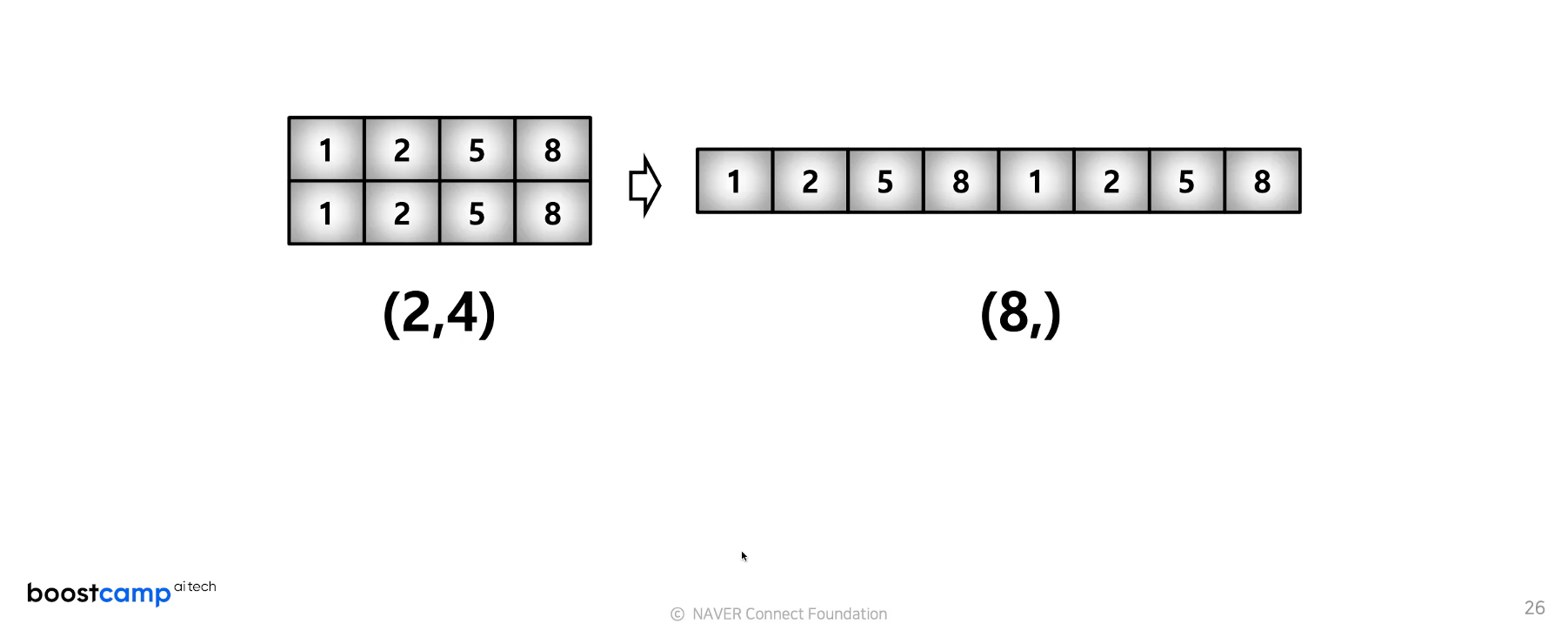
test_matrix = [[1,2,3,4], [1,2,5,8]]
np.array(test_matrix).shape
# >> (2, 4)이를 reshape 하면
np.array(test_matrix).reshape(8,)
# >> array([1, 2, 3, 4, 1, 2, 5, 8])이렇게 한줄로 변함.
- -1 : size를 기반으로 row 개수 선정
(2,4)의 shape을 뒤의 2열에 맞춰서(=,2) 행을 정해라(=-1,)
np.array(test_matrix).reshape(-1,2).shape2) flatten
- 다차원 array를 1차원 array로 변환
2. indexing & slicing
1) Indexing for numpy array
- list와 달리 이차원 배열에서 [0,0] 표기법을 제공함
- matrix일 경우 앞은 row 뒤는 column을 의미함.
a = np.array([[1, 2, 3], [4.5, 5, 6]], int)
print(a)
print(a[0,0]) # 0번째 row, 0번째 column = 1
print(a[0][0]) # 위와 동일- 그 위치에 할당도 가능
a[0,0] = 12 # Matrix 0,0에 12 할당2) Slicing for numpy array (더 중요!)
- list와 달리 행과 열 부분을 나눠서 slicing이 가능함
- matrix의 부분 집합을 추출할 때 유용함
a = np.array([[1,2,3,4,5],[6,7,8,9,10]],int)
a[:,2:] # 전체 행(row)의 2열(column)이상 = [3,4,5],[8,9,10]
a[1,1:3] # 1행의 1열 ~ 2열 = 7,8
a[1:3] # 1행 ~ 2행의 전체 = 6,7,8,9,10. 2행은 없으므로 1행만 보여줌.- 다른 예시
a = np.arange(100).reshape(10,10)
# 100개의 element를 10행 10열의 모양에 넣어라.
a[:, -1]
# 전체 행, 맨 마지막 열
# >> array([9, 19, 29, 39, 49, 59, 69, 79, 89, 99])건너 뛰어서 선택할때.
- arr[:,::2] = arr[전체 행, 전체 열인데 2개마다]
- arr[::2,::3] = arr[전체 행인데 2개마다, 전체 열인데 3개마다]
> 아래 그림을 참고

3. Creation function
1) arange
- array의 범위를 지정하여 값의 list를 생성하는 명령어
- 시작 수는 포함, 마지막 끝 숫자는 포함하지 않음
np.arrange(0, 5, 0.5)` => (시작, 끝, step)
\>> array([0., 0.5, 1., 1.5, 2., 2.5, 3., 3.5, 4., 4.5])
# floating point도 표시 가능- 다른 예시) 0에서 10까지 3칸씩 띄어라
list(range(0,10,3))
# >> [0, 3, 6, 9]- reshape을 같이 쓰는 기법을 많이 사용
np.array(30).reshape(5, 6)
# 0부터 29까지 30개의 원소를 5행 6열로2) ones, zeros and empty
(1) zeros
- 0으로 가득찬 ndarray 생성
<기본 모양 :np.zeros(shape, dtype, order)>
= 여기서 shape은 항상 튜플 값으로 적어줘야함.
np.zeros(shape=(10,), dtype=np.int8) #10 - zero vector 생성.
# >> array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype =int8)
np.zeros((2,5))
# 2 by 5 - zero matrix 생성. shape 파라미터가 기본.(2) ones
- 1로 가득찬 ndarray 생성
<기본 모양 :np.ones(shape, dtype, order)>
(3) empty
- shape만 주어지고 비어있는 ndarray 생성 (memory initialization이 되지 않음 = 메모리 공간을 잡지 않아서 실행시마다 값이 바뀜, 아래의 이유로.)
- 그러나 그 메모리 내에서 그 빈 공간이 그 전에 사용했던 것 일수 있으므로, 그런 경우 값이 남아있다.
(4) something_like
- 기존 ndarray의 shape크기 만큼 1,0 또는 empty array를 반환.
test_matrix = np.arange(30).reshape(5,6)
# 0~29까지 5,6의 쉐이프로 만듬.
np.ones_like(test_matrix)
# 위에서 만든 test_matrix와 같은 모양의 ones를 만듦.(ones 기능)
3) identity, eye, diag
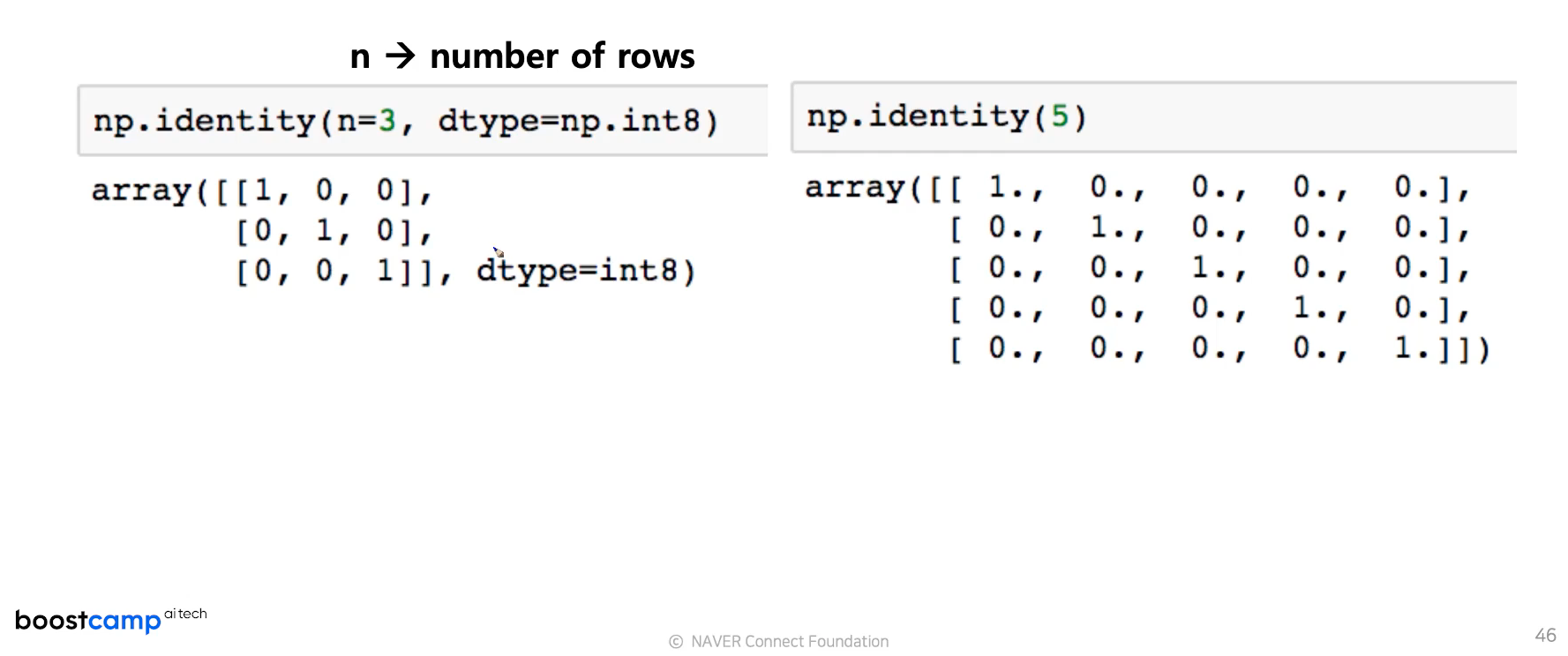
(1) indentity
- 단위 행렬(i 행렬)을 생성함
<기본 모양 :np.identity(n, dtype, order), dtype과 order은 optional>
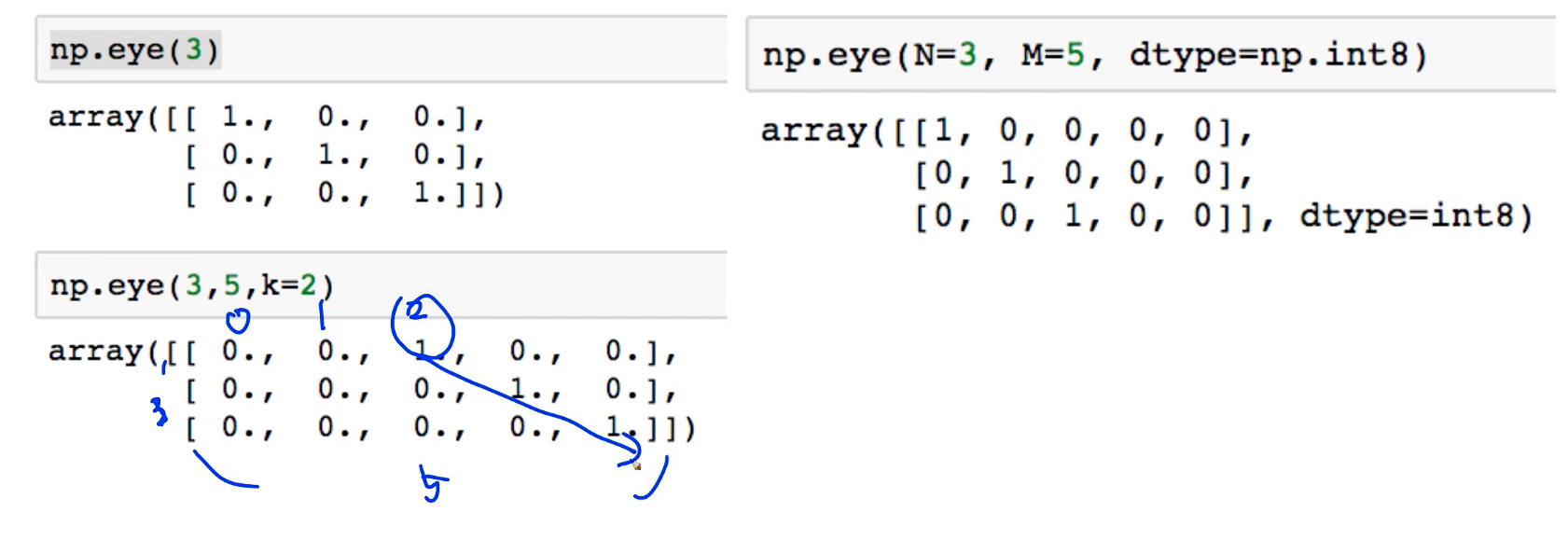
(2) eye
- 대각선인 1인 행렬, k값의 시작 index의 변경이 가능
- n = 행의 수, m = 열의 수
<기본 모양 :np.eye(n, m, k), m과 k는 optional>
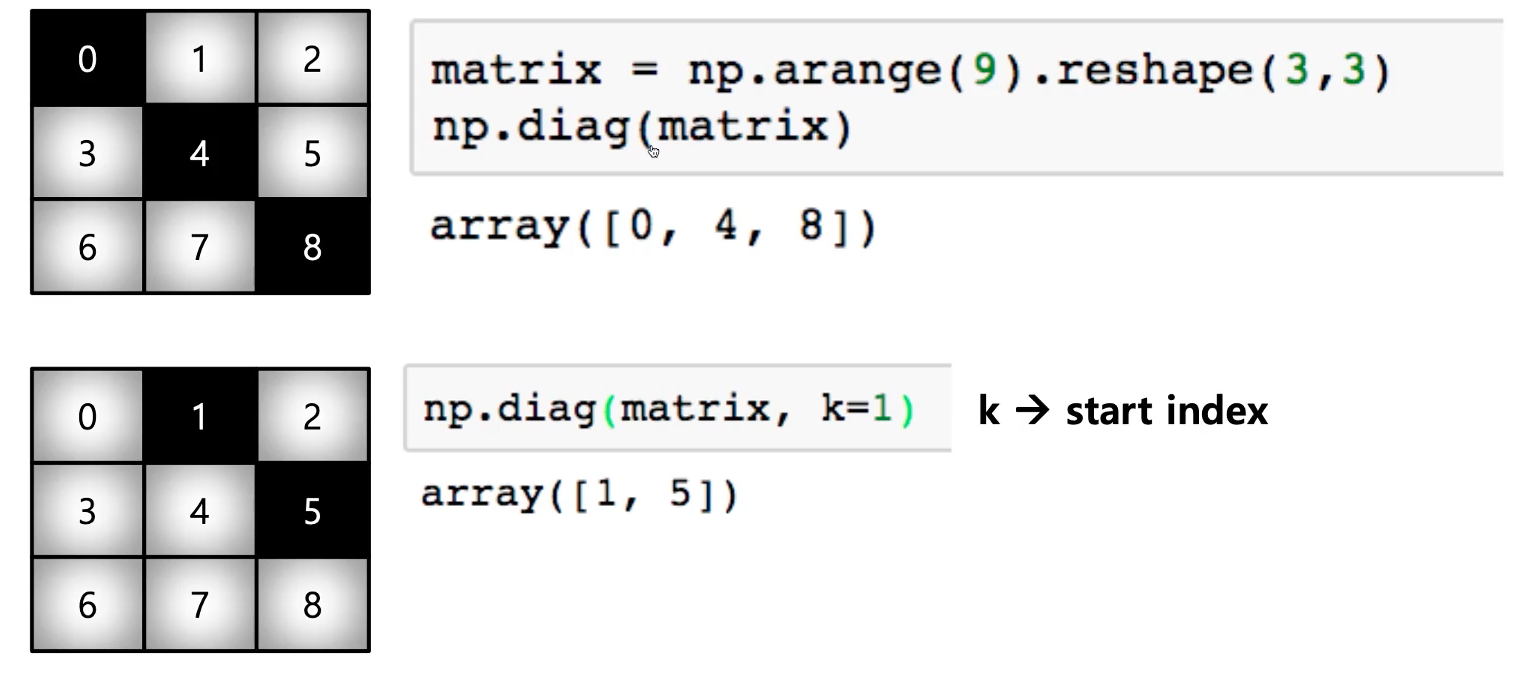
(3) diag
- 대각 행렬(diagonal matrix)의 값을 추출함
4) Random Sampling
- 데이터 분포에 따른 sampling으로 array를 생성
![[부스트캠프 AI Tech 3기 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_markup_images/dd956f0e291d4addb91c63b1dea6d2b2/f693c856-302c-4d7e-8420-e2af5fe9dcc3.jpg)
- 예시
# 균등분포
np.random.uniform(0,1,10).reshape(2,5)
# (시작값, 끝값, 데이터 갯수)
# 정규분포
np.random.normal(0,1,10).reshape(2,5)
# 가장 많이 쓰이는 것중 하나인 exponential 분포
np.random.exponential(scale=2, size=100) 5) Operation functions
sum
<기본 형식 : array name.sum()>
-
ndarray의 element들 간의 합을 구함, list의 sum 기능
sum(list name)과 동일 -
예시
test_array = np.arange (1,11)
# array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
test_array.sum(dtype=np.float)
# 55.0axis
-
모든 operation function을 실행할 때 기준이 되는 dimension 축
-
괄호 순으로 생각하면 쉬움. (3, 4) = (axis = 0일때 기준(세로), axid = 1일때 기준(가로))
-
axis = 0 : 행 방향(1행, 2행, 3행... 이렇게 '행의 개수' 세는 방향), axis = 1 : 열 방향(1열, 2열, 3열..이렇게 '열의 개수' 세는 방향)
갑자기 행방향 열방향이 너무 헷갈렸다... 설명해주는 참고 링크
<기본 형식 : test_array.sum(axis=1), test_array.sum(axis=0)>
![[부스트캠프 AI Tech 3기 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_markup_images/dd956f0e291d4addb91c63b1dea6d2b2/6e41ce13-09ba-4589-accf-db0a66cc6ff8.jpg)
axis(Third order tensor)
- 괄호 순으로 생각하면 쉬움. (3, 3, 4) = (axis = 0일때 기준(차원), axid = 1일때 기준(세로, 행 세는 방향), axid =2일때 기준(가로, 열 세는 방향))
<기본 형식 : third_order_tensor_name.sum(axis=0) >
![[부스트캠프 AI Tech 3기 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/0ffd3bda-1f68-4350-8025-a273694b9273.jpg)
mean, std
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/767c81bb-0fb6-43e0-9acf-f38e75614927.jpg)
mathematical functions
-
그 외에도 다양한 수학 연산자를 제공함 (np.something 호출)
-
exponential : exp, expml, exp2, log, logl0, loglp, log2,power, sqrt
trigonometric : sin, cos, tan, acsin, arccos, atctan hyperbolic : sinh, cosh, tanh, acsinh, arccosh, atctanh
6) concatenate / vstack / hstack
- numpy array를 합치는(붙이는) 함수
vstack / hstack
- 붙이는 방향에 따라 위아래를 붙이면 vstack, 양 옆으로 붙이면 hstack.
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/c4f4da13-43e0-4c13-972e-7e1d5d086221.jpg)
concatenate
- axis = 0 : 행 방향으로 붙이기, axis = 1 : 열 방향으로 붙이기
newaxis (+ reshape, tile)
- 새로운 축을 추가할 때 쓰는 함수.
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_markup_images/dd956f0e291d4addb91c63b1dea6d2b2/353ff942-f1e4-432a-8e3b-146f3c00523f.jpg)
-
이런 모양의 array는 b인 [5, 6]도 Dimension의 모양을 바꾸어줘야하는데, (위의 그림에서 보라색 선) 이때, newaxis 함수를 이용해 축을 추가할 수 있다. 더 자세한 설명 링크 (newaxis는 축 추가만 하는데 채워가며 축 추가하는 tile의 설명도 되어있음)
-
array_name.reshape(-1,2) 를 해도 2열 기준으로 생성되니 맞춰지긴 함.
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/cf1ec8e8-3346-43ba-8f19-b04fc97d3125.jpg)
7) Array operations
Element-wise operations
- array간 shape이 같을 때 일어나는 연산
- numpy는 array간의 기본적인 사칙 연산을 지원함 (같은 위치에 있는 것끼리)
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/ead84391-a033-4c21-930a-616096ba24a2.jpg)
Dot product
- Matrix의 기본 연산, dot 함수 사용
- pytorch에서 논문 구현시 많이 사용
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_markup_images/dd956f0e291d4addb91c63b1dea6d2b2/bcb7f6c6-1ef3-4b98-a6ac-dafe53a22e30.jpg)
transpose (전치 행렬)
- transpose 또는 T attribute 사용
- pytorch에서 논문 구현시 많이 사용
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/1c392e66-5ac2-410f-9df9-38d0eb659e2b.jpg)
broadcasting
- shape이 다른배열간 연산을 지원하는 기능
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/893303b8-0ab9-474d-85d4-ca0763943f43.jpg)
- Scalar - vector 외에도 vector - matrix 간의 연산도 지원
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/b1be23d1-3f6c-409e-9e07-35f3d32c3058.jpg)
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_markup_images/dd956f0e291d4addb91c63b1dea6d2b2/6bd85812-9605-4433-bd61-270051c7fe5a.jpg)
numpy performance #1
- timeit : jupyter 환경에서 코드의 퍼포먼스를 체크하는 함수 (속도 측정)
![[부스트캠프 Pre-Course] Numpy 2(중간부터) image](https://slid-capture.s3.ap-northeast-2.amazonaws.com/public/capture_images/dd956f0e291d4addb91c63b1dea6d2b2/9a340758-dd89-4dec-bcfb-4263ae22ce2a.jpg)
-
일반적으로 속도는 아래 순
for loop < list comprehension < numpy -
100,000,000 번의 loop이 돌 때, 약 4배 이상의 성능 차이를 보임
-
Numpy는 C로 구현되어 있어, 성능을 확보하는 대신 파이썬의 가장 큰 특징인 dynamic typing을 포기함
-
대용량 계산에서는 가장 흔히 사용됨-Concatenate 처럼 계산이 아닌, 할당에서는 연산 속도의 이점이 없음
