Part 3. Python Basics for AI
chapter 6) Pandas 1
네이버 AI 부스트캠프의 Pre-course 수업을 듣던 중 공부한 내용을 정리하고, 추가적으로 따로 공부한 부분이 생기면 함께 필기했습니다.
대부분의 캡쳐, 정보는 부스트캠프 강의에서 얻었으며 오직 개인 공부의 목적으로 포스팅합니다.
강의 링크는 여기에
Pandas 1
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리. 엑셀을 다룰 때 사용할 수 있는 대표적인 도구.
- "Panel data" -> pandas
- 고성능 array 계산 라이브러리인 numpy와 통합하여, 강력한 '스프레드시트'처리 기능을 제공
- 인덱싱, 연산용 함수, 전처리 함수 등을 제공함
- 데이터 처리 및 통계 분석을 위해 사용
(데이터 프레임 내 기본 개념 설명(열, 행 같은 개념)과 판다스 설치과정은 생략합니다. conda로 설치하는 법을 모르는 이가 이 포스트를 본다면 아나콘다 먼저 설치하시고 가상환경과 라이브러리 설치법 또한 알아야 합니다. 부스트캠프에서는 conda를 이용해서 가상환경을 생성 후 conda install pandas로 설치함. )
1. Pandas overview
1) 데이터 로딩
import pandas as pd
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
df_data = pd.read_csv(
data_url, sep="\s+", header=None
)
df_data.head()
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
| 0 |
0.00632 |
18.0 |
2.31 |
0 |
0.538 |
6.575 |
65.2 |
4.0900 |
1 |
296.0 |
15.3 |
396.90 |
4.98 |
24.0 |
| 1 |
0.02731 |
0.0 |
7.07 |
0 |
0.469 |
6.421 |
78.9 |
4.9671 |
2 |
242.0 |
17.8 |
396.90 |
9.14 |
21.6 |
| 2 |
0.02729 |
0.0 |
7.07 |
0 |
0.469 |
7.185 |
61.1 |
4.9671 |
2 |
242.0 |
17.8 |
392.83 |
4.03 |
34.7 |
| 3 |
0.03237 |
0.0 |
2.18 |
0 |
0.458 |
6.998 |
45.8 |
6.0622 |
3 |
222.0 |
18.7 |
394.63 |
2.94 |
33.4 |
| 4 |
0.06905 |
0.0 |
2.18 |
0 |
0.458 |
7.147 |
54.2 |
6.0622 |
3 |
222.0 |
18.7 |
396.90 |
5.33 |
36.2 |
df_data.columns = [
"CRIM",
"ZN",
"INDUS",
"CHAS",
"NOX",
"RM",
"AGE",
"DIS",
"RAD",
"TAX",
"PTRATIO",
"B",
"LSTAT",
"MEDV",
]
df_data.head()
|
CRIM |
ZN |
INDUS |
CHAS |
NOX |
RM |
AGE |
DIS |
RAD |
TAX |
PTRATIO |
B |
LSTAT |
MEDV |
| 0 |
0.00632 |
18.0 |
2.31 |
0 |
0.538 |
6.575 |
65.2 |
4.0900 |
1 |
296.0 |
15.3 |
396.90 |
4.98 |
24.0 |
| 1 |
0.02731 |
0.0 |
7.07 |
0 |
0.469 |
6.421 |
78.9 |
4.9671 |
2 |
242.0 |
17.8 |
396.90 |
9.14 |
21.6 |
| 2 |
0.02729 |
0.0 |
7.07 |
0 |
0.469 |
7.185 |
61.1 |
4.9671 |
2 |
242.0 |
17.8 |
392.83 |
4.03 |
34.7 |
| 3 |
0.03237 |
0.0 |
2.18 |
0 |
0.458 |
6.998 |
45.8 |
6.0622 |
3 |
222.0 |
18.7 |
394.63 |
2.94 |
33.4 |
| 4 |
0.06905 |
0.0 |
2.18 |
0 |
0.458 |
7.147 |
54.2 |
6.0622 |
3 |
222.0 |
18.7 |
396.90 |
5.33 |
36.2 |
df_data.values
array([[6.3200e-03, 1.8000e+01, 2.3100e+00, ..., 3.9690e+02, 4.9800e+00,
2.4000e+01],
[2.7310e-02, 0.0000e+00, 7.0700e+00, ..., 3.9690e+02, 9.1400e+00,
2.1600e+01],
[2.7290e-02, 0.0000e+00, 7.0700e+00, ..., 3.9283e+02, 4.0300e+00,
3.4700e+01],
...,
[6.0760e-02, 0.0000e+00, 1.1930e+01, ..., 3.9690e+02, 5.6400e+00,
2.3900e+01],
[1.0959e-01, 0.0000e+00, 1.1930e+01, ..., 3.9345e+02, 6.4800e+00,
2.2000e+01],
[4.7410e-02, 0.0000e+00, 1.1930e+01, ..., 3.9690e+02, 7.8800e+00,
1.1900e+01]])
2. Series
- column vector를 표현하는 object
1) Pandas의 구성
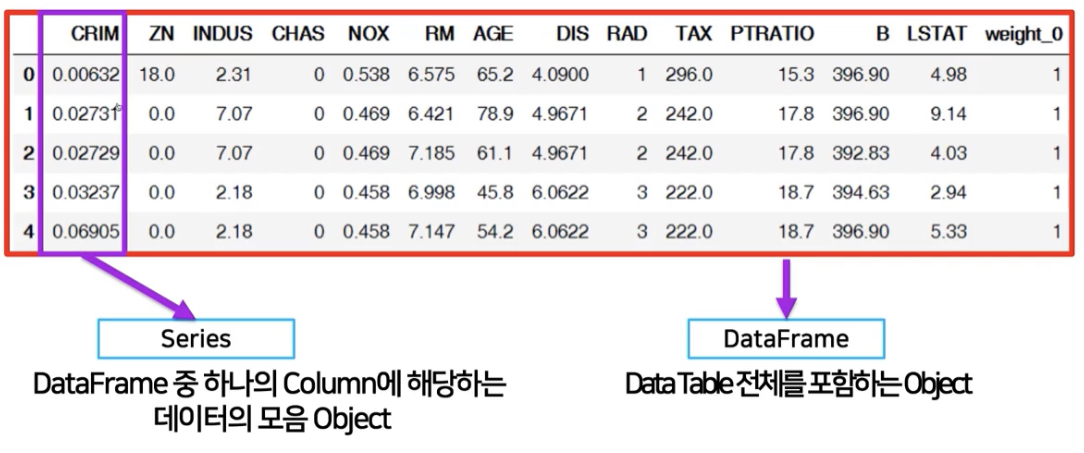
- Pandas 안의 Numpy라고 이해하면 쉽다. (numpy.ndarray를 기본으로 해서 만든 서브클래스)
- Data : 어느 타입의 데이터든 가능
- Numpy와 다르게 Index 값을 따로 지정할 수 있다.
(예 : A, B, C / 20 35 49 => 이렇게 순서 다른 숫자로도 가능)
- Duplicates가 가능하다.
from pandas import Series, DataFrame
import numpy as np
list_data = [1,2,3,4,5]
list_name = ['a', 'b', 'c', 'd', 'e']
example_obj = Series(data = list_data, index = list_name)
example_obj
a 1
b 2
c 3
d 4
e 5
dtype: int64
dict_data = {"a":1, "b":2, "c": 3, "d":4, "e":5}
example_obj = Series(dict_data, dtype = np.float32, name="example_data")
example_obj
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
example_obj["a"]
example_obj["a"] = 3.2
example_obj = example_obj.astype(float)
- 인덱스 값을 기준으로 데이터가 만들어짐. 인덱스 개수가 7개고 데이터 개수가 5개면 인덱스를 기준으로 7개의 인덱스가 생기고 데이터가 없는 3칸은 nan 값을 가짐.
indexes = ["a","b","c","d","e","f","g"]
series_obj = Series(dict_data, index = indexes)
series_obj
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
f NaN
g NaN
dtype: float64
3. DataFrame
1) dataframe memory
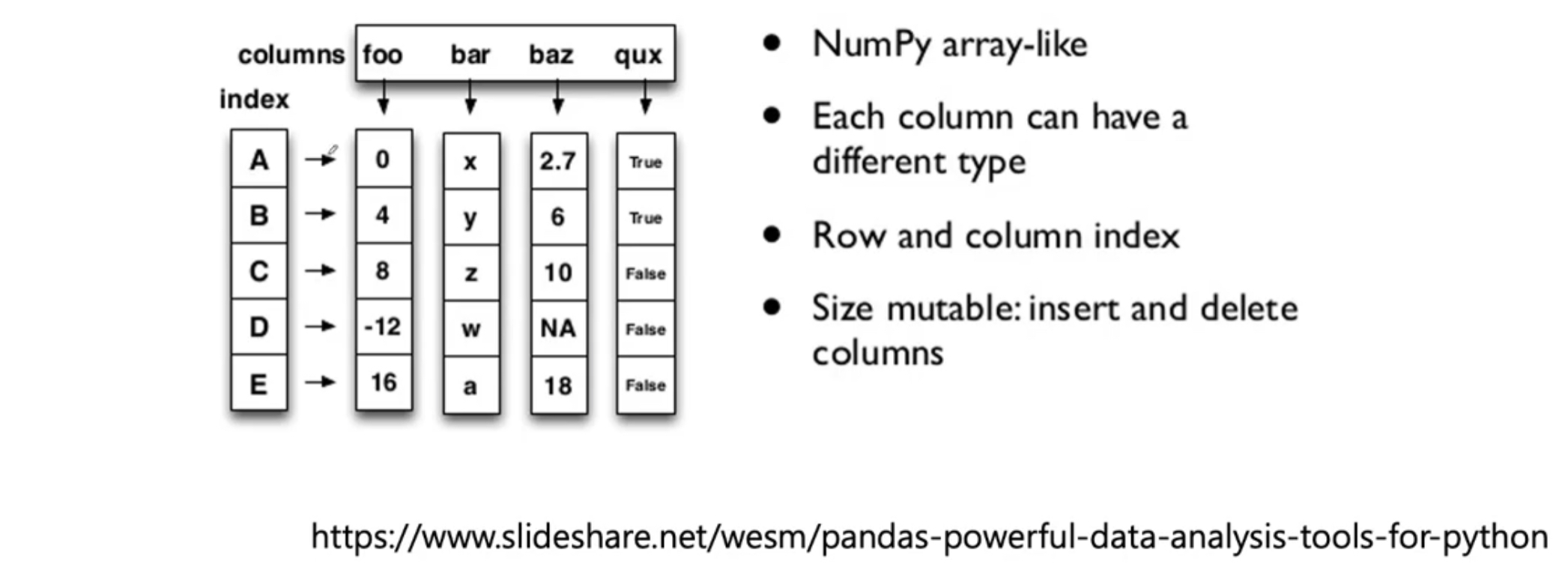
- 위에 적혀있듯 각 컬럼 별로 다른 데이터를 넣을 수 있따.
2) Dataframe 생성
raw_data = {
"first_name" : ["Jason", "Molly", "Tina", "Jake", "Amy"],
"last_name" : ["Miller", "Jacobson", "Ali", "Milner", "Cooze"],
"age" : [42, 52, 36, 24, 73],
"city" : ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"]
}
df = pd.DataFrame(raw_data, columns= ["first_name", "last_name", "age","city"])
df
|
first_name |
last_name |
age |
city |
| 0 |
Jason |
Miller |
42 |
San Francisco |
| 1 |
Molly |
Jacobson |
52 |
Baltimore |
| 2 |
Tina |
Ali |
36 |
Miami |
| 3 |
Jake |
Milner |
24 |
Douglas |
| 4 |
Amy |
Cooze |
73 |
Boston |
raw_data
{'age': [42, 52, 36, 24, 73],
'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston'],
'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze']}
DataFrame(raw_data, columns = ["age", "city"])
|
age |
city |
| 0 |
42 |
San Francisco |
| 1 |
52 |
Baltimore |
| 2 |
36 |
Miami |
| 3 |
24 |
Douglas |
| 4 |
73 |
Boston |
df = DataFrame(raw_data, columns = ["first_name","last_name","age", "city","debt"])
df
|
first_name |
last_name |
age |
city |
debt |
| 0 |
Jason |
Miller |
42 |
San Francisco |
NaN |
| 1 |
Molly |
Jacobson |
52 |
Baltimore |
NaN |
| 2 |
Tina |
Ali |
36 |
Miami |
NaN |
| 3 |
Jake |
Milner |
24 |
Douglas |
NaN |
| 4 |
Amy |
Cooze |
73 |
Boston |
NaN |
3) Data indexing(loc, iloc)
- loc : index location, 인덱스 이름으로 찾기
- iloc : index position, 인덱스 번호(순서)로 찾기
df.loc[:,["first_name","last_name"]]
|
first_name |
last_name |
| 0 |
Jason |
Miller |
| 1 |
Molly |
Jacobson |
| 2 |
Tina |
Ali |
| 3 |
Jake |
Milner |
| 4 |
Amy |
Cooze |
df["age"].iloc[1:]
1 52
2 36
3 24
4 73
Name: age, dtype: int64
s = pd.Series(np.nan, index = [49, 48, 47, 46, 45, 1, 2, 3, 4, 5])
s.loc[:3]
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
dtype: float64
s.iloc[:3]
49 NaN
48 NaN
47 NaN
dtype: float64
4) Data Handling
(1) Column에 새로운 데이터 할당
- <기본 형식> 데이터프레임 이름.컬럼 이름 = 할당할 조건문.
- 조건문에 해당하는 내용이 해당 컬럼의 데이터로 들어간다.
df.debt = df.age > 40
df
|
first_name |
last_name |
age |
city |
debt |
| 0 |
Jason |
Miller |
42 |
San Francisco |
True |
| 1 |
Molly |
Jacobson |
52 |
Baltimore |
True |
| 2 |
Tina |
Ali |
36 |
Miami |
False |
| 3 |
Jake |
Milner |
24 |
Douglas |
False |
| 4 |
Amy |
Cooze |
73 |
Boston |
True |
values = Series(data=["M", "F", "F"], index = [0,1,3])
df["sex"] = values
df
|
first_name |
last_name |
age |
city |
debt |
sex |
| 0 |
Jason |
Miller |
42 |
San Francisco |
True |
M |
| 1 |
Molly |
Jacobson |
52 |
Baltimore |
True |
F |
| 2 |
Tina |
Ali |
36 |
Miami |
False |
NaN |
| 3 |
Jake |
Milner |
24 |
Douglas |
False |
F |
| 4 |
Amy |
Cooze |
73 |
Boston |
True |
NaN |
(2) Transpose
- <기본 형식> 데이터프레임 이름.T (소문자는 에러남. 대문자T)
- 행과 열의 데이터가 서로 바뀜 (방향 바뀐다고 이해하면 쉬움)
df.T
|
0 |
1 |
2 |
3 |
4 |
| first_name |
Jason |
Molly |
Tina |
Jake |
Amy |
| last_name |
Miller |
Jacobson |
Ali |
Milner |
Cooze |
| age |
42 |
52 |
36 |
24 |
73 |
| city |
San Francisco |
Baltimore |
Miami |
Douglas |
Boston |
| debt |
True |
True |
False |
False |
True |
| sex |
M |
F |
NaN |
F |
NaN |
df.values
array([['Jason', 'Miller', 42, 'San Francisco', True, 'M'],
['Molly', 'Jacobson', 52, 'Baltimore', True, 'F'],
['Tina', 'Ali', 36, 'Miami', False, nan],
['Jake', 'Milner', 24, 'Douglas', False, 'F'],
['Amy', 'Cooze', 73, 'Boston', True, nan]], dtype=object)
(3) CSV 변환
df.to_csv()
(4) Column을 삭제, 제외 후 출력
- del : 데이터 내의 컬럼 삭제 (데이터 변함)
<기본 형식> del df이름["컬럼명"]
- drop : 그냥 빼고 출력 (데이터는 변하지 않음)
<기본 형식> df이름.drop("컬럼명", axis = 방향)
df.drop("debt",axis = 1)
|
first_name |
last_name |
age |
city |
sex |
| 0 |
Jason |
Miller |
42 |
San Francisco |
M |
| 1 |
Molly |
Jacobson |
52 |
Baltimore |
F |
| 2 |
Tina |
Ali |
36 |
Miami |
NaN |
| 3 |
Jake |
Milner |
24 |
Douglas |
F |
| 4 |
Amy |
Cooze |
73 |
Boston |
NaN |
del df["debt"]
df
|
first_name |
last_name |
age |
city |
sex |
| 0 |
Jason |
Miller |
42 |
San Francisco |
M |
| 1 |
Molly |
Jacobson |
52 |
Baltimore |
F |
| 2 |
Tina |
Ali |
36 |
Miami |
NaN |
| 3 |
Jake |
Milner |
24 |
Douglas |
F |
| 4 |
Amy |
Cooze |
73 |
Boston |
NaN |
(5) Dict 안에 Dict 형식
- 사실상 별로 사용할 일은 없지만, 가끔 Json 파일이 이렇게 넘어옴.
이런 데이터의 경우 데이터 프레임으로 부를 수 있다는 것을 위해 알아둘 것.
- <기본 형식> dict이름 = {"0열 이름" : {"인덱스 이름" : 해당 데이터 값, "인덱스 이름" : 해당 데이터 값},
"1열 이름" : {"인덱스 이름" : 해당데이터 값, "인덱스 이름" : 해당 데이터 값}}
pop = {"Nevada":{2001:2.4, 2002:2.9}, "Ohio": {2000: 1.5, 2001:1., 2002: 3.6}}
DataFrame(pop)
