A 5 nm 254 TOPS/W and 221 TOPS/mm2 Fully Digital Computing-in-Memory Macro Supporting Wide Range Dynamic-Voltage-Frequency Scaling and Simultaneous MAC and Write Operations
Problem to solve
- 기존 Analog-based CIM(ACIM)는 transistor variation에 의한 정확도 하락과 ADC의 overhead가 문제점이었다.
- Current based의 경우 current cell의 non-linearity와 local variation이 문제.
- Charge based의 경우 capacitance와 ADC의 dynamic voltage range가 문제.
How to solve
- Digital-based CIM(DCIM)을 통해 충분한 accuracy 달성이 가능하고, input/weight의 bit width이 좀 더 flexible하다.
- DCIM은 technology scaling을 통한 이득을 얻을 수 있다.
DCIM vs ACIM
DCIM
APR을 사용하는 DCIM의 경우 technology가 7nm → 5nm로 scaling down됨에 따라 logic density는 1.5 ~ 2배 증가하고, power efficiency과 performance는 1.2배 증가한다.
ACIM
Technology scaling에 따른 이득이 따르는 DCIM과 달리, ACIM의 경우 technology가 scaling down됨에 따라 고려해야 할 사항들이 많다.
- Voltage가 scaling down됨에 따라 ADC의 dynamic range를 고려해야 한다.
- Current-based ACIM의 경우 technology가 scaling down됨에 따라 DIBL(Drain Induced Barrier Lowering)으로 인한 drain current의 non-linearity가 심해진다.
- Capacitor-based ACIM의 경우 technology가 scaling down됨에 따라 capacitance가 감소한다.
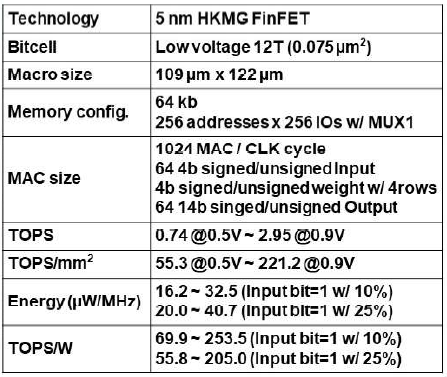
5nm 공정에서 DCIM은 ACIM에 비해 약 1.3배의 power efficiency와 약 1.4배의 performance, area efficiency를 가졌다. 또한, ACIM은 output truncation이나 ADC로 인한 gain error에 의해 accuracy degradation이 발생하는 반면, DCIM은 truncation이 발생하지 않으며 input/weight의 bit width도 좀 더 flexible하다.
Architecture
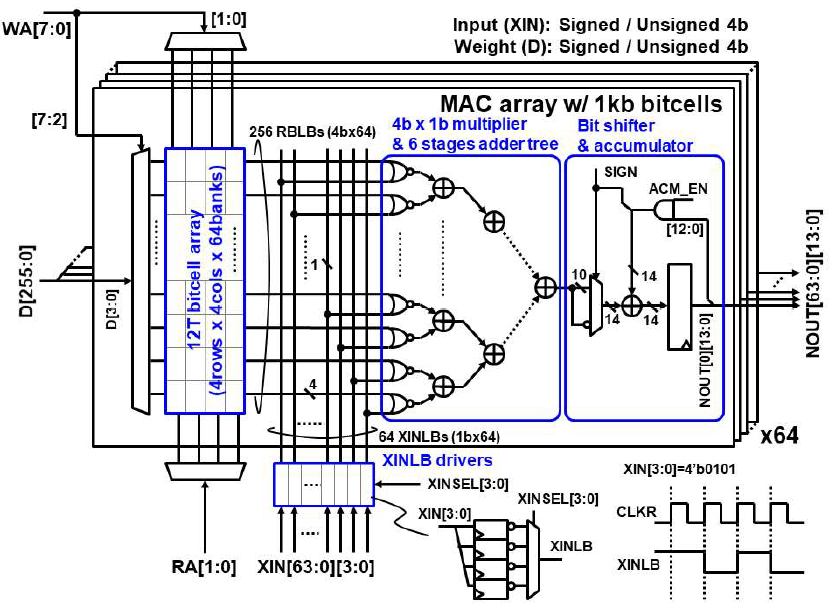
DCIM macro는 64개의 1 kb MAC array와 bit-wise multiplier, adder tree, bit shifter, accumulator로 구성되어 있다. MAC array는 4 row x 4 column x 64 bank로 구성되어 있고, 각 cell는 12T이다.
XIN(XINLB) driver는 64개의 4b signed/unsigned input을 MAC array에 넣어준다. XINLB driver 내부의 4:1 MUX를 통해 1 cycle에 input의 1b 씩 MAC array에 넣어주어 bit-wise multiplication을 수행한다. Bit-wise multiplication은 NOR 연산을 통해 수행하며, 반전된 weight와 input 간의 NOR 연산을 수행하면 기존 값들 같의 AND 연산을 수행한 것과 동일하다. 따라서, XINLB driver는 XIN을 반전하여 XINLB를 출력하며, weight 또한 RBLB를 통해 반전된 weight를 사용한다.
매 cycle마다 64 x 4b의 weight와 64 x 1b의 input간의 bit-wise multiplication이 수행되며, adder tree를 거쳐 누적된 값은 bit shifter를 통해 input의 bit position에 맞게 정렬된다. Bit shifter와 accumulator는 signed/unsigned 모두 지원한다.
MAC array
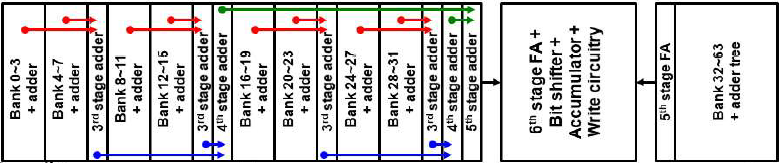
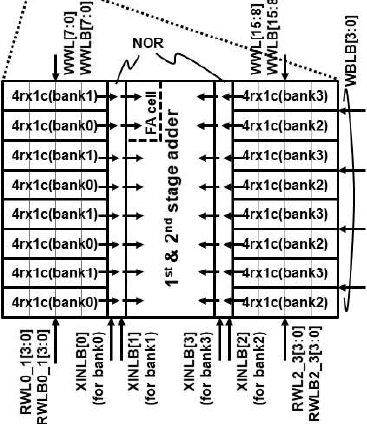
MAC array는 4개의 bank 단위로 구성된다. 왼쪽과 오른쪽에 bank가 2개씩 교차로 위치하며, 1st stage adder를 통해 2개의 bank에 대해 덧셈을 수행한다. 각 bank는 4개의 row를 가짐으로, 1st stage adder의 결과는 5b이고, 2nd stage adder의 결과는 6b이다.
Bank가 64개 이므로 6th stage adder까지 걸쳐 모든 bank에 대한 값을 더할 수 있고, 결과는 10b이다. Input이 4b이므로, bit-wise multiplication을 4번 반복하여 최종적으로 14b 결과를 얻는다.
Bitwidth flexibility
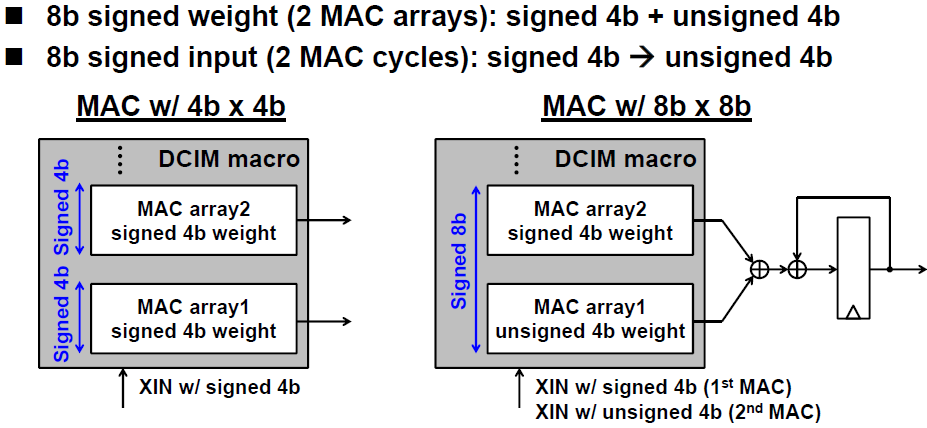
기본적으로 input과 weight 모두 4b 이지만, 2개의 MAC array를 사용함으로써 8b input/weight를 지원한다. 4b input/weight의 경우 기본적으로 bit shifter와 accumulator가 signed mode로 동작하고, 8b input/weight의 경우 MSB쪽 MAC array는 signed mode로, LSB쪽 MAC array는 unsigned mode로 동작하며, 두 MAC array의 연산값을 더해주어 최종 결과를 얻는다.
Metrics