DIANA: An End-to-End Energy-Efficient DIgital and ANAlog Hybrid Neural Network SoC
Problem to solve
- Digital NN accelerator와 Analog IMC는 layer type에 따라서 optimal한 approach가 달라진다.
- Digital NN accelerator는 AiMC에 비해 bit precision을 높일 수 있고, 좀 더 flexible하지만 AiMC에 비해 energy efficiency와 throughput이 부족하다.
- AiMC는 digital NN accelerator에 비해 energy efficient하고 throughput per area가 훨씬 좋지만, digital NN accelerator에 비해 bit precision이 낮고 flexible하지 못하다.
- Ideal한 processor는 layer의 특성에 따라 digital 혹은 AiMC acceleration을 활용할 수 있어야 한다.
How to solve
- Digital NN core와 AiMC core를 같이 사용하여 연속된 layer를 동시에 실행.
- Input channel이 작은 first layer와 classification 역할을 수행하는 FC layer는 digital NN accelerator가 수행하고, huge computation이 필요한 hidden layer들은 AiMC가 수행.
- Shared activation memory는 digital NN core와 AiMC core 모두 접근 가능하도록 구성.
- RISC-V core를 통해 scheduling 및 digital NN core, AiMC core control.
Architecture
Digital NN core
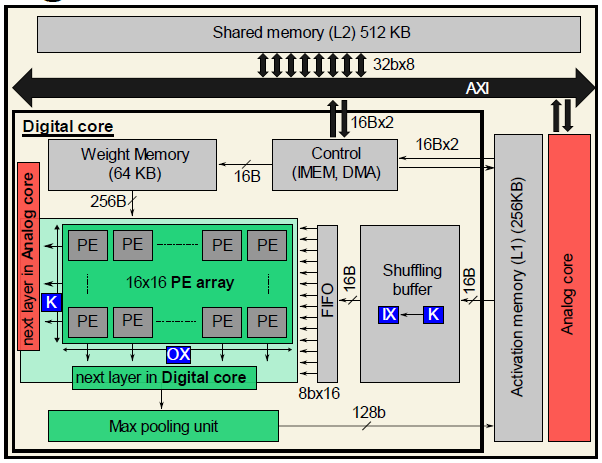
16 x 16 크기의 PE array와 max pooling unit을 통해 2-8b input/weight의 convolution, FC, element-wise operation이 가능하다. Convolution 연산에 대해 output-stationary dataflow를 가지고 있으며, activation FIFO를 통해 sliding window operation을 수행하여 data를 reuse한다. PE array는 row-wise로는 output channel별, column-wise로는 column별 연산을 수행한다.
Digital NN core와 AiMC core는 다른 spatial unrolling을 사용하므로, 다음 layer에 따라 output의 data ordering을 다르게한다. 만약 다음 layer가 digital NN core에서 수행된다면, horizontal-parallel(CHW)하게 수행되며, AiMC에서 수행될 경우에는 channel-parallel(HWC)하게 수행된다.
Analog in-Memory compute(AiMC) core
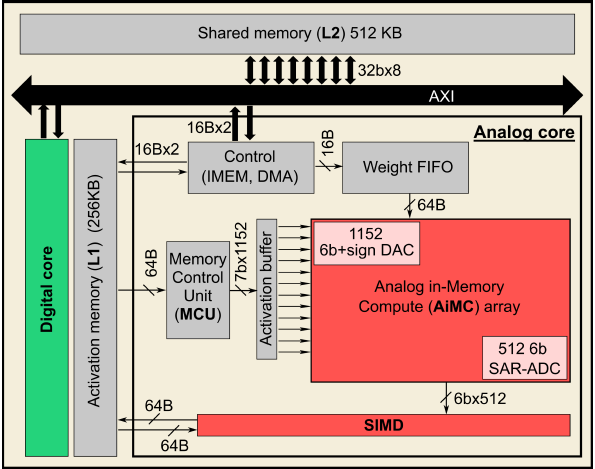
AiMC core는 1152 x 512 크기이며, 크기가 큰 convolution layer를 연산하는데 사용된다. Convolution 연산은 weight-stationary dataflow로 수행된다. Input은 signed-magnitude 방식의 7b이며, DAC를 통해 6b의 time pulse로 변환된다. Weight는 ternary로, 1개의 cell안에 2개의 SRAM를 가지고 있다.
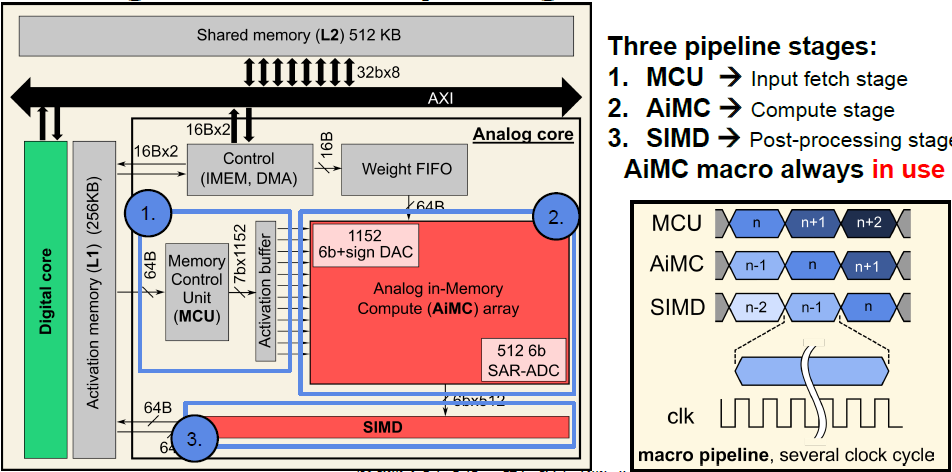
AiMC core의 동작은 아래와 같은 3단계로 나뉜다.
- Input fetch stage
Memory Control Unit(MCU)가 shared activation memory에서 input data를 fetch한 후, activation buffer에 저장한다. - Compute stage
AiMC에 의해 연산이 수행된다. - Post-processing stage
Partial sum accumulation, batch norm., pooling 등의 SIMD 연산을 수행한다.
위의 3단계는 pipelining되어서 AiMC는 항상 연산을 수행하도록 하여 AiMC의 temporal utilization을 극대화하였다.
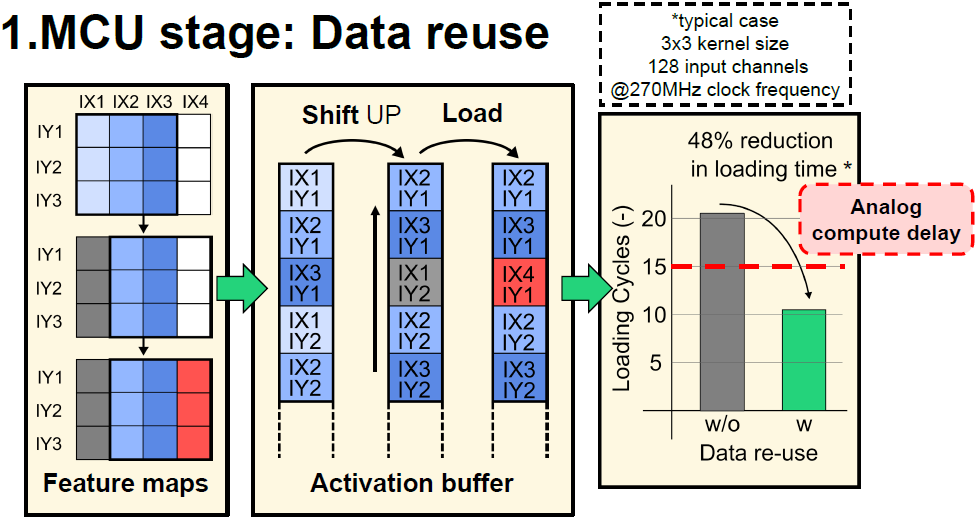
Convolution 연산은 channel-wise로 수행되므로, 다음 연산을 위해서는 input feature map이 X방향으로 1칸 이동해야 한다. 이때 이전에 사용했던 input을 1칸 shift up한 후, activation buffer에 없는 input만 load함으로써 memory access를 줄인다. Data reuse를 통해 activation loading cycle이 약 48% 감소하였고, AiMC core의 연산 cycle 보다 loading cycle이 더 짧게 되어 AiMC core의 temporal utilization을 증가시킬 수 있다.
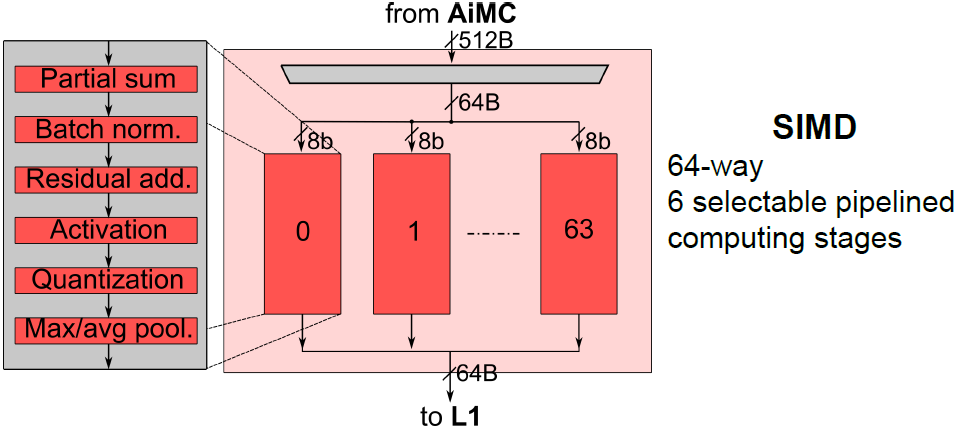
64-way SIMD module은 AiMC의 연산 결과에 element-wise operation을 수행하며, 64 channel output에 대해 parallel하게 연산한다. SIMD operation은 다음과 같이 6단계로 pipelining 되어있다.
- Partial sum addition
- Batch norm.
- Residual addition
- Activation(ReLU, Leaky-ReLU)
- Re-quantization
- Max/Avg pooling
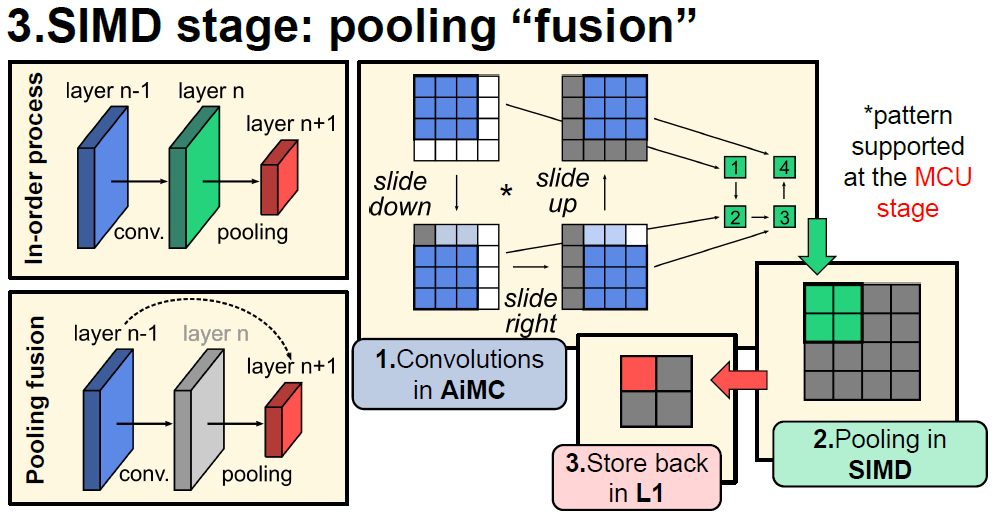
기존에는 convolution을 수행한 결과에 대해 pooling을 수행하여 2단계로 연산이 수행되었는데, MCU에서 pooling pattern에 맞추어 input을 넣어주고, SIMD module에서 pooling을 수행함으로써 convolution + pooling을 한번에 수행할 수 있다.
Utilization improvement
Output unrolling
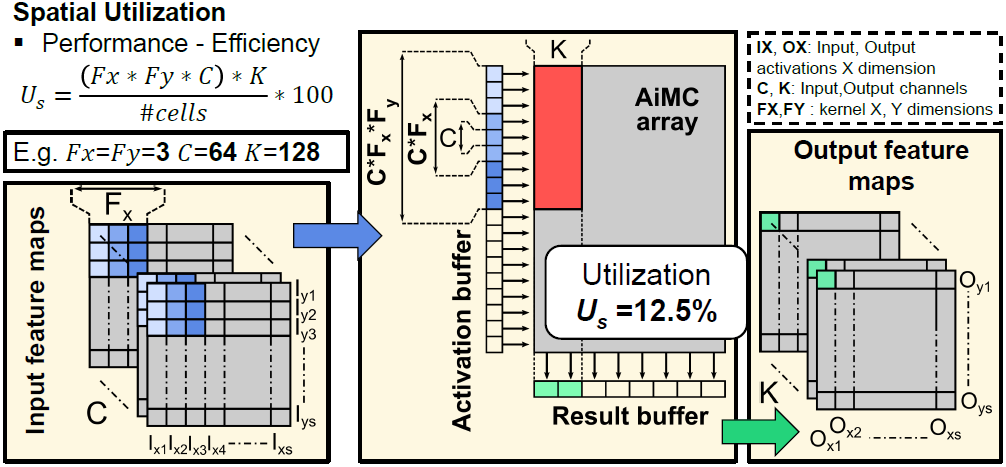
AiMC는 kernel-order mapping을 사용한다. 위 그림과 같이 인 경우, 의 row와 의 column을 차지한다. AiMC가 1152 x 512 크기이므로, spatial utilization은 12.5% 밖에 되지 않는다.
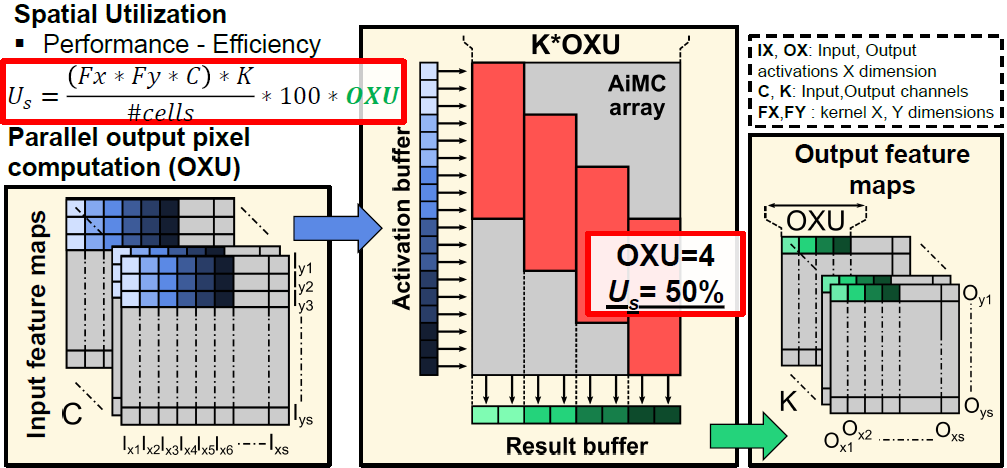
위와 같이 column-wise로 만큼 parallel하게 연산하면 spatial utilization이 만큼 증가하며, 한번에 연산이 수행되는 output channel도 만큼 증가한다.
Layer fusion
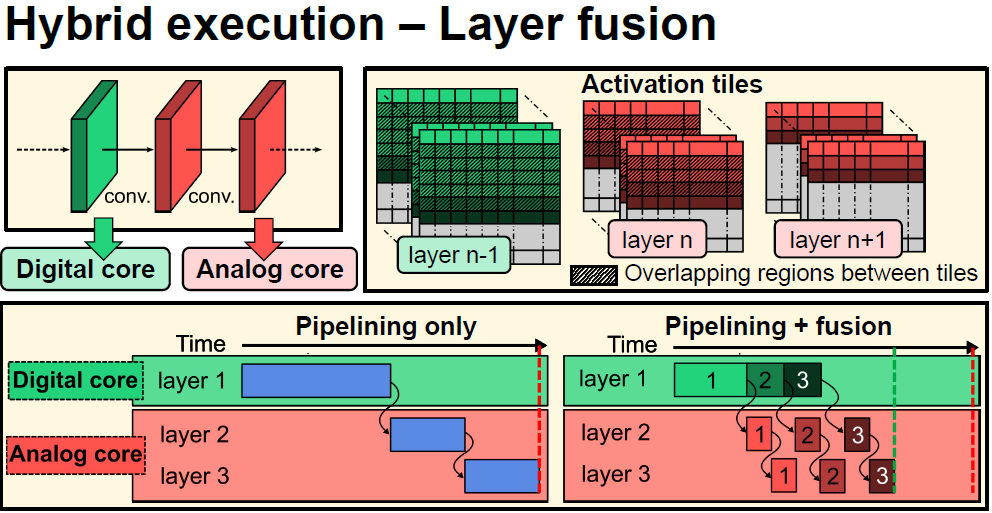
기존 pipeling은 한 layer의 연산이 끝나면 다음 layer의 연산을 수행하는 식으로 진행되었다. 이와는 다르게 이전 layer로 부터 연산하기에 충분한 activation이 모이면, 해당 activation에 대해 연산을 먼저 수행한다. 한 layer의 계산이 다 끝날 때 까지 기다리지 않기 때문에 activation을 memory에 저장했다가 다시 불러오지 않고, 연산에 사용하여 memory 사용량이 감소하며, 연산에 소요되는 시간 또한 감소한다.
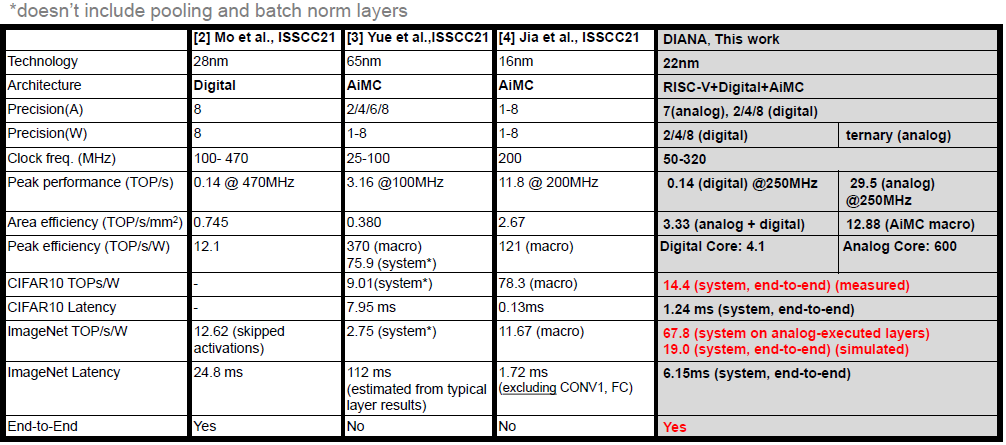
Metrics