Evolver: A Deep Learning Processor With On-Device Quantization–Voltage–Frequency Tuning
Problem to solve
- 기존에는 deep learning processor에 DNN deploy시 quantization-voltage-frequency(QVF) policy를 미리 결정한다.
- Q, V, F는 latency와 energy 모두에 영향을 미치므로, Q와 V, F를 따로 tuning 하면 local minima에 빠질 수 있다.
- 수많은 종류의 edge device와 application scenario에 맞추어 QVF tuning을 수행하기 어렵다.
How to solve
- QVF tuning을 local device에서 같이 진행.
- RL(Q-learning)을 사용하여 optimal QVF policy 탐색.
QVF tuning
DNN의 ALE(Accuracy, Latency, Energy)는 QVF(Quantization, Voltage, Frequency)에 의해 영향을 받는다. 따라서 edge device에 DNN을 deploy하기 전에 hardware, application scenario, user preference 등에 따라 QVF tuning이 수행되어야 한다.
QVF tuning의 objective function은 다음과 같이 나타낼 수 있다.
는 hard constraint 이며, 의 factor를 가진다. 이 값들은 user나 specific application에 의해서 결정된다.
Architecture
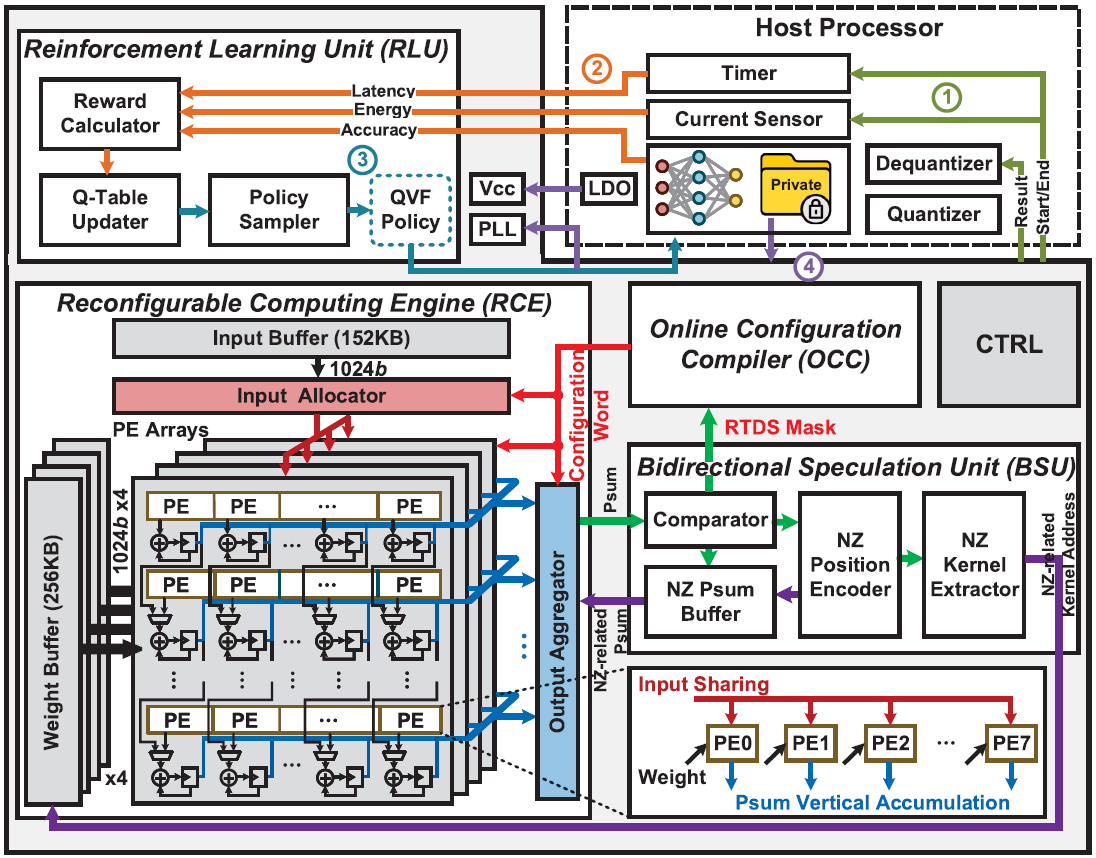
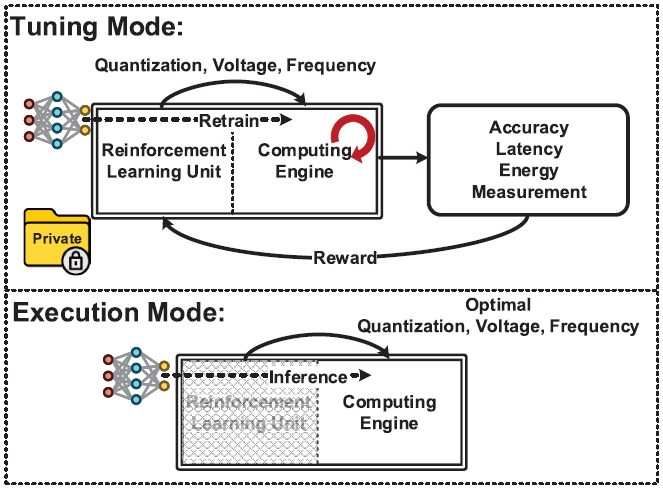
Evolver는 2가지 mode로 동작한다. Tuning mode에서는 RL(Q-learning)을 통해 optimal한 QVF를 탐색하며, execution mode에서는 앞서 탐색한 QVF 동작 조건하에 inference를 수행한다.
Evolver는 host processor와 같이 동작한다. Host processor는 tuning mode에서 QVF에 따른 ALE feedback을 제공하며 quantization을 수행한다.
Tuning mode
Tuning mode는 4단계로 구성된다.
1. Evolver에 의해 선택된 QVF policy로 host processor가 ALE를 측정한다.
2. Reward computing을 위해 host processor가 측정한 ALE를 evolver로 돌려보낸다.
3. RLU(Reinforcement Learning Unit)이 Q-table을 update하고, 새로운 QVF policy를 선택한다.
4. Host processor를 통해 model을 requantize한다.
Execution mode
Inference을 수행하는 execution mode에서는 RLU를 power-gating하여 전력소모를 줄인다.
Q-learning based QVF tuning
Evolver는 Q-learning을 기반으로 QVF tuning을 수행한다. QVF tuning은 개의 state를 가지는 MDP(Markov Decision Process)로 modeling 되었다. 처음 개의 state는 각 layer의 input-weight precision pair를 나타내며, 마지막 state는 operating voltage-frequency pair를 나타낸다. Agent는 부터 까지 순차적으로 state를 선택한다.
Local device는 RL의 environment 역할을 수행하며, 선택된 QVF policy에 대해 ALE 결과를 측정하고 이에 따른 reward를 agent에게 제공한다. Reward는 다음과 같이 표현된다.
State 에서 action 를 선택했을 경우, Q-value 는 다음과 같은 식을 통해 update 된다.
는 state 에서의 Q-value 중의 최댓값을 의미한다.
위 식에는 2가지 hyperparameter가 존재한다. 는 Q-learning rate로, 새로운 정보와 기존 정보의 비율을 조절한다. 는 discount factor로, short-term reward와 future reward 간의 비율을 조절한다.
Q-value가 빠르게 수렴하도록, Q-value update는 state 진행방향의 역순으로 수행된다.
RLU(Reinforcement Learning Unit)
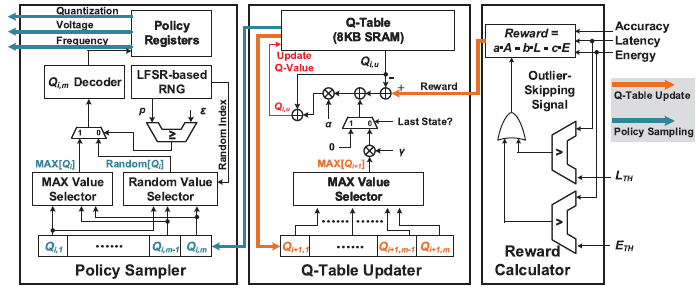
RLU의 architecture는 위의 그림과 같다. 8 kB Q-table SRAM은 16개의 bank로 구성되어 있고, 각 bank는 16b x 256으로 구성되어 있다. Q-value는 row-by-row로 저장되므로, 최대 state 갯수는 256개이며, bank가 16개 이므로 각 state는 최대 16개의 16b action을 가질 수 있다.
8개 layer을 가지는 VGG-8의 경우, state는 아래와 같이 나태낼 수 있다. 1~8 state는 각 layer의 bit precision을 나타내고, 마지막 state는 voltage, frequency를 나타낸다.
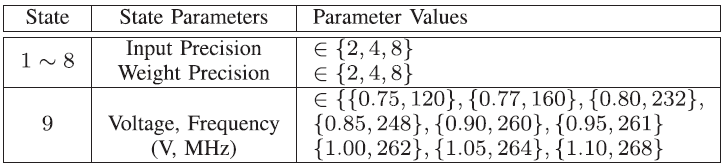
위의 state에 따른 Q-table은 아래와 같이 나타낼 수 있다.
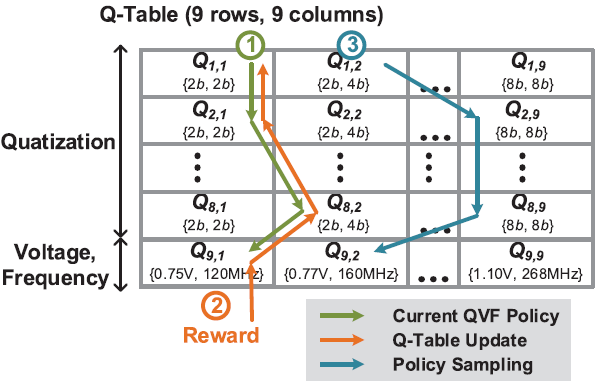
Reward Calculator
선택된 QVF policy에 대해, 측정된 ALE 결과가 reward calculator로 입력되며, 사전에 정해진 parameter 를 가지고 reward를 계산한다. ALE 값들은 범위로 normalize되며, 16b format으로 나타내어진다.
Q-Table Updater
RC에 의해 reward가 계산되면, 부터 까지 역순으로 Q-value를 update시킨다.
Policy Sampler
Q-table update가 끝나면, PS는 -greedy policy에 의거하여 다음 policy를 선택한다. 이를 위해 8b LSFR를 사용하여 난수를 생성한다.
-greedy policy에 의해 의 확률로 random action을 취하며, 의 확률로 greedy action을 취한다. 순차적으로 선택된 action들은 policy register에 차례로 저장된다. QVF tuning 과정동안 을 점점 감소시키며 agent의 행동이 exploration에서 exploitation으로 점진적으로 변화하도록 한다.
Maximum iteration count에 도달할 때 까지 위의 과정을 반복하며, 최종적으로 가장 높은 reward을 달성한 policy를 execution mode에서 사용한다.
Evolver는 outlier-skipping scheme을 사용하여, QVF policy에 해당하는 ALE가 사전에 설정된 조건을 만족하지 못하였을 경우, RC는 outlier-skipping signal을 발생시켜 ALE 측정을 수행하지 않고 reward를 0으로 설정한다. 이를 통해 VGG-8에서 약 37%의 outlier에 대해 training을 skip할 수 있었다.
