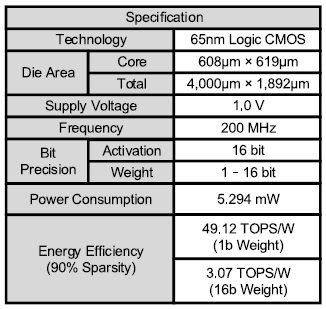
Z-PIM: A Sparsity-Aware Processing-in-Memory Architecture With Fully Variable Weight Bit-Precision for Energy-Efficient Deep Neural Networks
Problem to solve
- 기존 PIM들은 energy efficiency를 위해 8b 이하의 weight들만 지원하였다.
- 기존 PIM들은 sparsity handling을 지원하지 않아 불필요한 연산을 수행하였다.
How to solve
- Custom 8T SRAM과 computational logic을 통해 memory bandwitdh bottleneck 해결.
- Bit-serial operation을 통한 1-16b의 weight 지원.
- Unique data mapping/flow를 통한 sparsity handling 지원.
Architecture
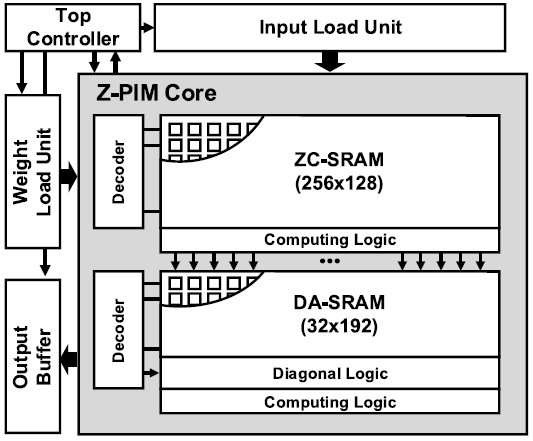
Z-PIM Core는 ZC(Zero-skipping Convolution)-SRAM, DA(Diagonal-Accumulation)-SRAM, row decoder로 구성되어있다. ZC-SRAM, DA-SRAM 모두 8T SRAM array와 추가적인 computing logic, digonal logic으로 구성되어있다. Data-wise shift operation과 같이 Z-PIM 내부에서 효율적으로 수행되기 어려운 연산들은 top controller에 의해 수행된다.
ZC-SRAM
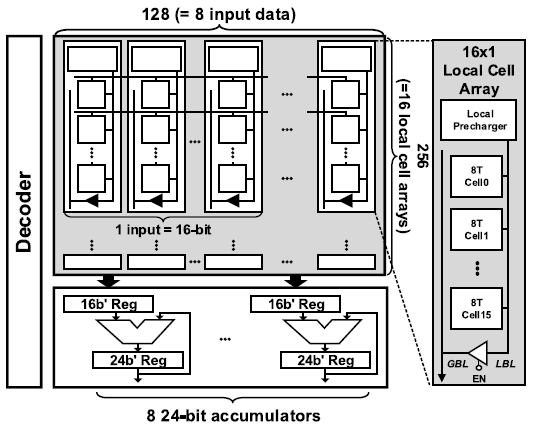
ZC-SRAM은 256x128 크기의 8T SRAM으로 구성되어있다. 또한, ZC-SRAM은 16x1 크기의 local cell array로 구성되며, 각 local cell array는 local pre-charger와 local bitline(LBL)을 가진다. Local cell array들의 LBL은 global bitline(GBL)과 연결되어있다.
기존 CIM macro들이 weight stationary이었던 것에 비해, Z-PIM은 input stationary를 채택했다. 따라서, 기존 CIM macro들은 CIM macro에 weight을 저장한 후 input을 입력하는 방식이었다면, Z-PIM은 input을 먼저 저장한 후 weight를 입력하는 방식이다.
Convolution 연산을 위해 ZC-SRAM은 8개의 16b input을 저장하며, 1-16b weight가 row별로 pre-charge된다. 연산결과를 누적하기 위해 8개의 24b accumulator가 SRAM array 뒷단에 존재한다. 16b 연산결과가 최대 256번 누적되어야 하므로, accumulator의 bit-width는 이다.
ZC-SRAM이 AND 연산을 수행하는 과정은 다음과 같다. AND 연산은 Local cell array 내부에서 수행된다.
- Local pre-charger가 weight load unit으로 부터 weight중 1b을 받아 LBL을 해당 값으로 pre-charge한다.
- RWL을 통해 local cell array 내부의 한 cell에 저장된 input data bit을 읽는다. 이 과정에서 input data bit과 weight bit 간에 AND 연산이 수행되며, 결과값은 LBL을 통해 나타내진다.
- LBL에 위치한 결과값이 local cell array 내부의 GBL driver를 통해 GBL로 이동한다.
DA-SRAM
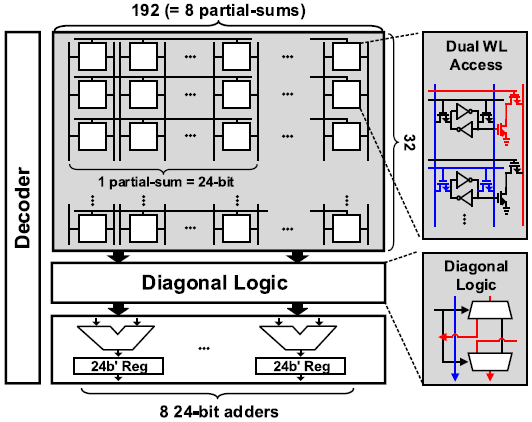
DA-SRAM은 32 x 192 크기의 8T SRAM으로 구성되어있다. 8개의 24b partial sum을 저장하기 위해 DA-SRAM의 column은 이다. DA-SRAM의 각 row는 ZC-SRAM의 연산 결과를 저장한다. DA-SRAM은 RBL과 WBL을 통해 동시에 2 row를 읽어 accumulation을 수행한다. 연산결과들의 bit position을 맞추기 위해 digonal logic이 1b shift 연산을 수행하며 8개의 24b accumulator를 통해 partial sum들을 누적한다.
Dataflow
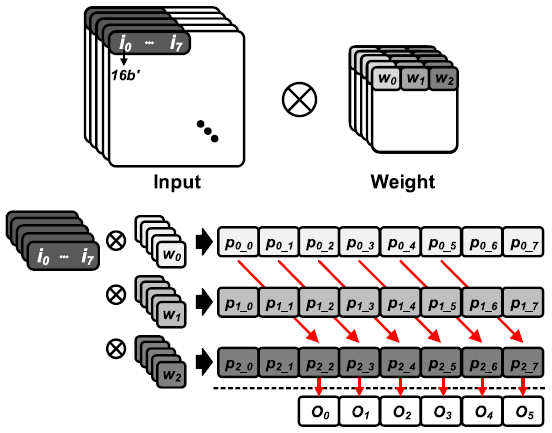
Z-PIM의 dataflow는 크게 3단계로 구분된다.
Channel-wise accumulation
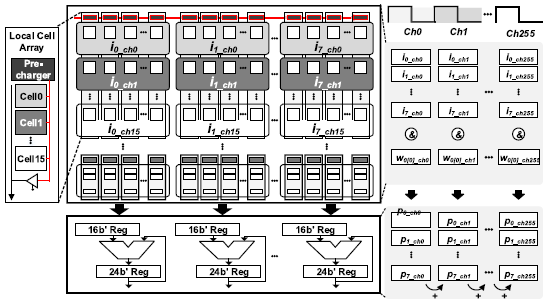
ZC-SRAM은 256x128 크기이므로, 8개의 16b input이 row-wise로 channel 별로 저장된다(row0에는 channel[0], row1에는 channel[1]). 이후 row-wise로 weight가 1b씩 pre-charge되어 and 연산을 수행한다. 연산결과는 8개의 24b accumulator에서 input 별로 누적되고, 모든 channel에 대해 accumulation이 끝나면 연산 결과는 DA-SRAM으로 이동한다. Channel-wise accumulation이 끝나면 256-channel 16b 8-input과 1b weight의 곱의 partial sum이 구해진다.
Bit-wise accumulation
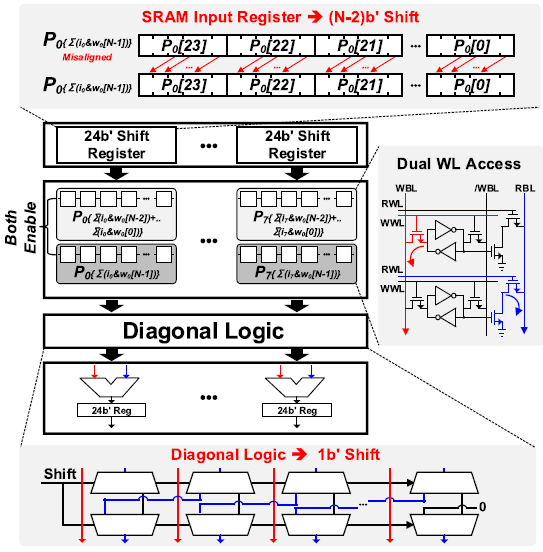
Bit-wise accumulation은 DA-SRAM에서 수행된다. 8개의 16b input이 weight의 1b씩 곱해져 partial sum을 이루었으므로, partial sum을 shift하여 weight의 bit-position을 맞추어 partial sum끼리 값을 더한다. 만약 weight가 16b이면 16개의 partial sum들의 합을 구한다. Bit position을 맞추기 위해 SRAM input register가 ZC-SRAM으로부터의 input을 shift하여 DA-SRAM에 저장시킨다.
DA-SRAM은 WBL과 RBL을 통해 동시에 2 row의 값을 읽을 수 있다. DA-SRAM의 한 row에는 partial sum이 저장되며, 이 row와 다음에 연산할 row를 동시에 enable 시켜 partial sum을 구한 후 결과값을 다시 DA-SRAM에 저장한다. Weight의 bit-precision만큼 partial sum accumulation을 반복하면 되므로, weight는 1-16b의 arbitary bit-precision를 가질 수 있다. Bit-wise accumulation이 끝나면 256-channel 16b 8-input과 16b weight의 곱의 partial sum이 구해진다.
Spatial-wise accumulation
Bit-wise accumulation을 통해 하나의 weight에 대한 partial sum이 구해지며, 다른 weight들에 대한 partial sum들 간의 합을 통해 convolution output을 구한다. 이는 Z-PIM core가 아닌 top controller에 의해 수행된다.
Zero-skipping
Z-PIM은 기존 PIM들이 weight를 PIM에 저장하고 input을 나중에 입력하는 것과 달리, input을 PIM에 저장하고 weight을 입력하는 dataflow를 가지고 있다. 이는 대부분의 경우 input이 weight에 비해 sparsity가 낮고, 여러 NN에 적용하기 위해서는 다양한 bit precision을 지원해야하기 때문이다.
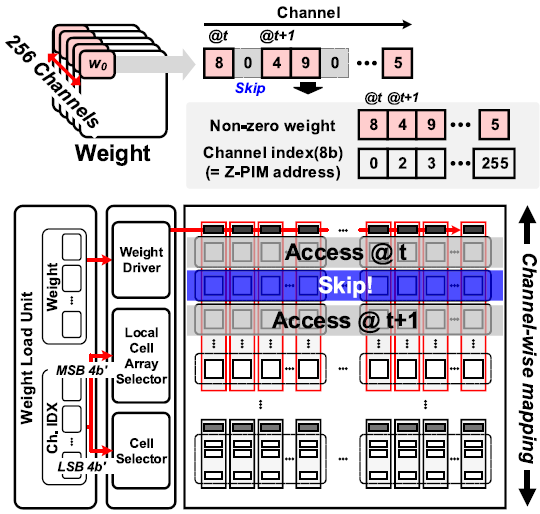
Z-PIM은 input이 row별로 channel-wise하게 입력되므로, weight가 0인 channel에 대해서는 MAC 연산을 수행하지 않고 skip한다. 이를 위해 top controller는 offline으로 계산된 non-zero weight와 해당 channel index를 ZC-SRAM의 weight load unit으로 보낸다.
Z-PIM은 256의 row를 가지고 있고, 1개의 local cell array는 16의 row로 구성되어있다. Pre-charge는 local cell array 단위로 수행되기 때문에, 8b의 channel index는 상위 4b의 local cell array index와 하위 4b의 word line index로 나뉜다. Local cell array index가 pre-charge를 수행할 local cell array를 결정하고, word line index를 통해 local cell array 내부에서 readout을 수행한다.
Hierarchical bitline
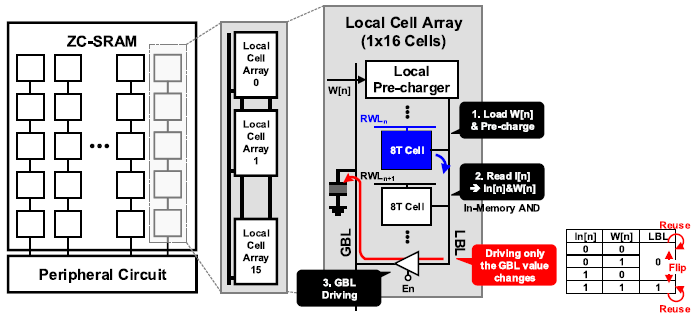
ZC-SRAM은 pre-charge가 LBL을 통해 수행된다. 기존 SRAM들은 pre-charge가 모든 row간에 연결된 GBL을 통해 수행되었는데, GBL의 길이가 길어 capacitance가 커지게 되어 pre-charge에 소비되는 energy가 컸다. 반면에 LBL은 GBL에 비해 상대적으로 길이가 짧고, capacitance도 상대적으로 작아져 pre-charge에 소비되는 energy 또한 감소한다.
또한, PIM 결과값이 이전과 같은 경우 GBL의 charge를 re-use할 수 있으며, GBL driver는 연산 결과값이 반전될 때만 GBL을 drive하면 된다. AND 연산의 경우 결과값이 0이 될 확률이 비교적 높아 GBL driver가 꺼져있을 확률도 높아진다.
Read-operation pipelining
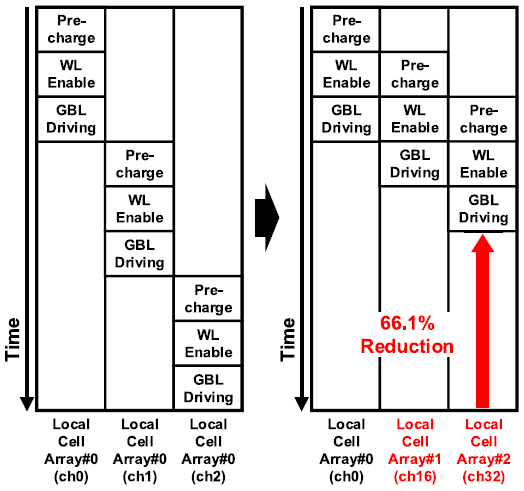
앞서 언급하였듯이, PIM 연산은 3단계로 이루어져 있다. 연산이 row 단위로 순차적으로 수행되면, 한 row의 결과값을 읽기 전까지는 LBL의 값을 바꿀 수 없으므로 GBL driving이 끝나고 나서야 LBL pre-charge가 가능해진다. 이러한 문제를 해결하기 위해 Z-PIM은 연산을 row 단위로 순차적으로 수행하지 않고, local cell array 단위로 순차적으로 수행한다(Row0, row1, ..., row255 LCA0(row0), LCA1(row16), ..., LCA15(row240)).
연산 수행 순서를 재배열함으로써 read-operation의 3-stage pipelining이 가능해져 throughput이 향상되었다.
Metrics