
이번 강의에서 다룰 내용은 "Sequence to Sequence Models"이다. Sequence라는 단어의 뜻은 순서가 있는 일이라는 의미를 가지고 있다. 따라서 입력과 출력이 모두 sequence인 경우에 대한 내용임을 짐작할 수 있다.
Sequence to Sequence Models
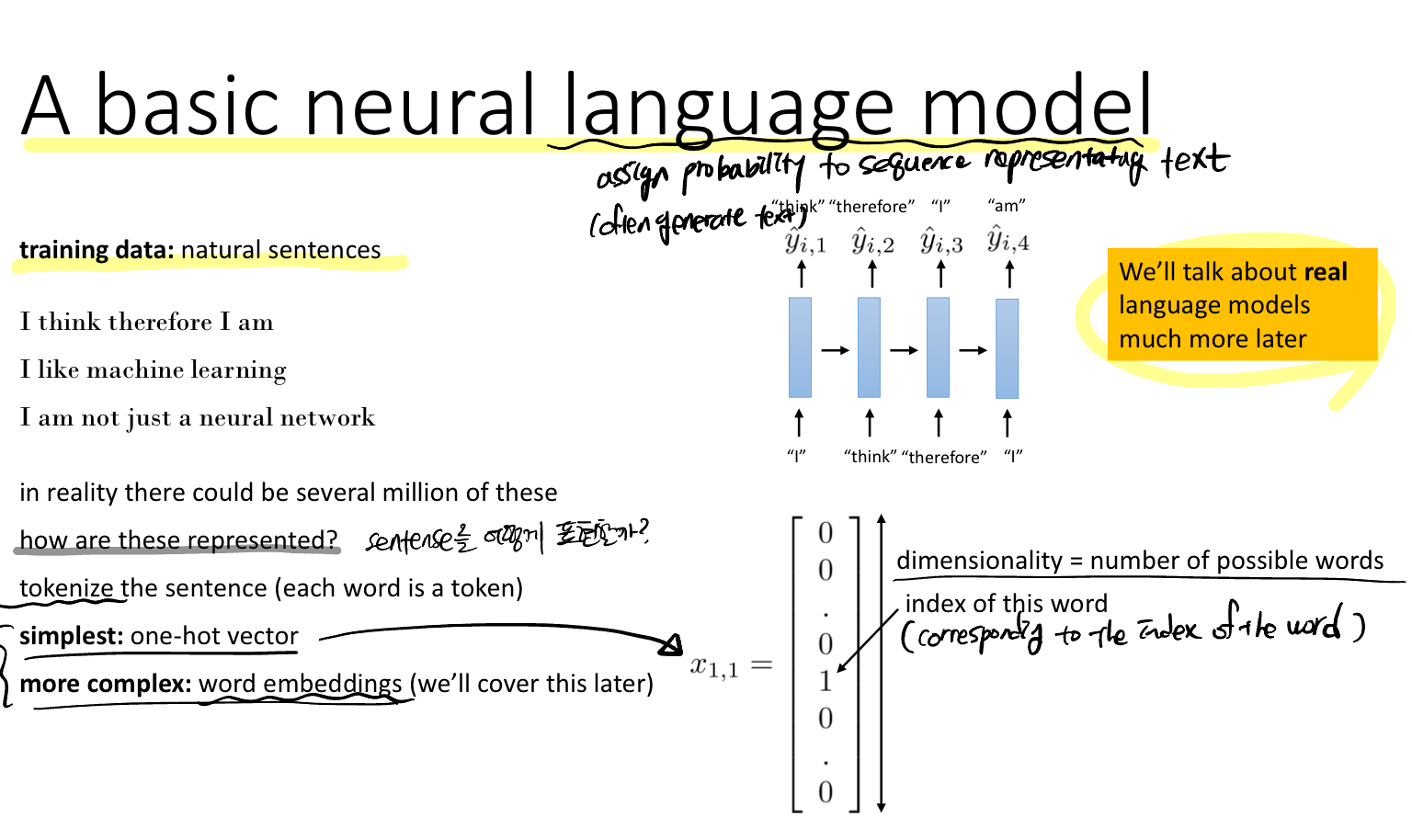
sequence 특성을 갖는 데이터 중 가장 쉽게 떠올리는 것이 우리가 쓰는 언어다. 그렇다면 어떻게 언어를 표현할 수 있을까?
언어를 토큰화(각 단어가 토큰, 즉 숫자로 표현)하는 것으로 두 가지 방법은 제안한다. 첫 번째는 one-hot vector, 두 번째는 word embeddings이 있다. 하지만 원핫벡터는 dim이 단어의 숫자에 비례하기 때문에 상당히 커질 수 있다는 단점이 있다.
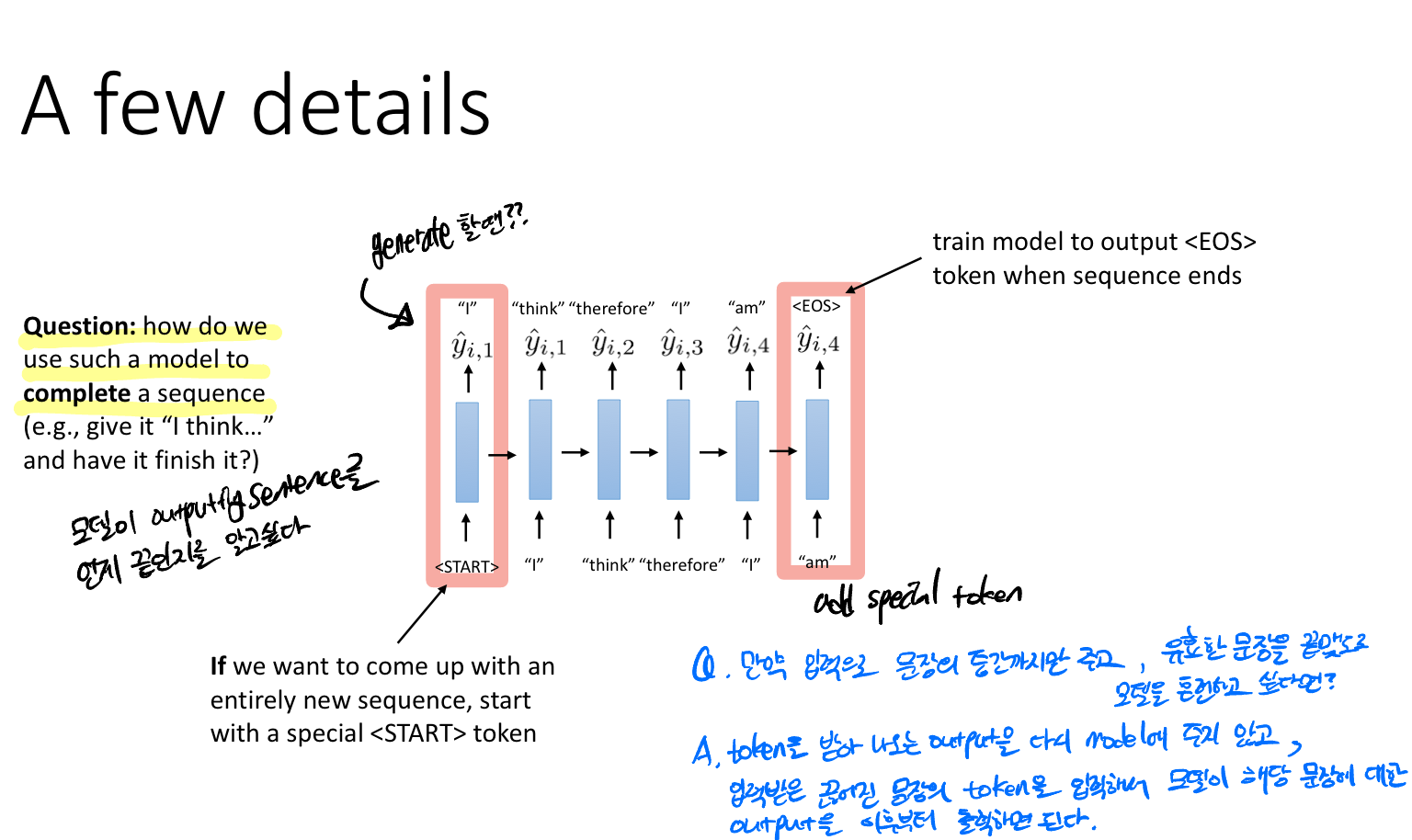
Q. 모델은 문장이 언제 시작하고 언제 끝날지를 어떻게 알고 완성할까?
문장의 시작에는 < START >토큰을 끝 부분에는 < EOS > 토큰을 위치하는 것으로 약속한다.
Q. 만약 입력으로 전체 문장으로 주는 것이 아니라, 문장의 일부만 주어주고 문장으로 완성하길 바란다면?
입력받은 일부의 문장의 토큰을 모델에 입력으로 주어서 해당 문장에 대한 출력을 이후부터 출력하는 방법으로 해결할 수 있다.
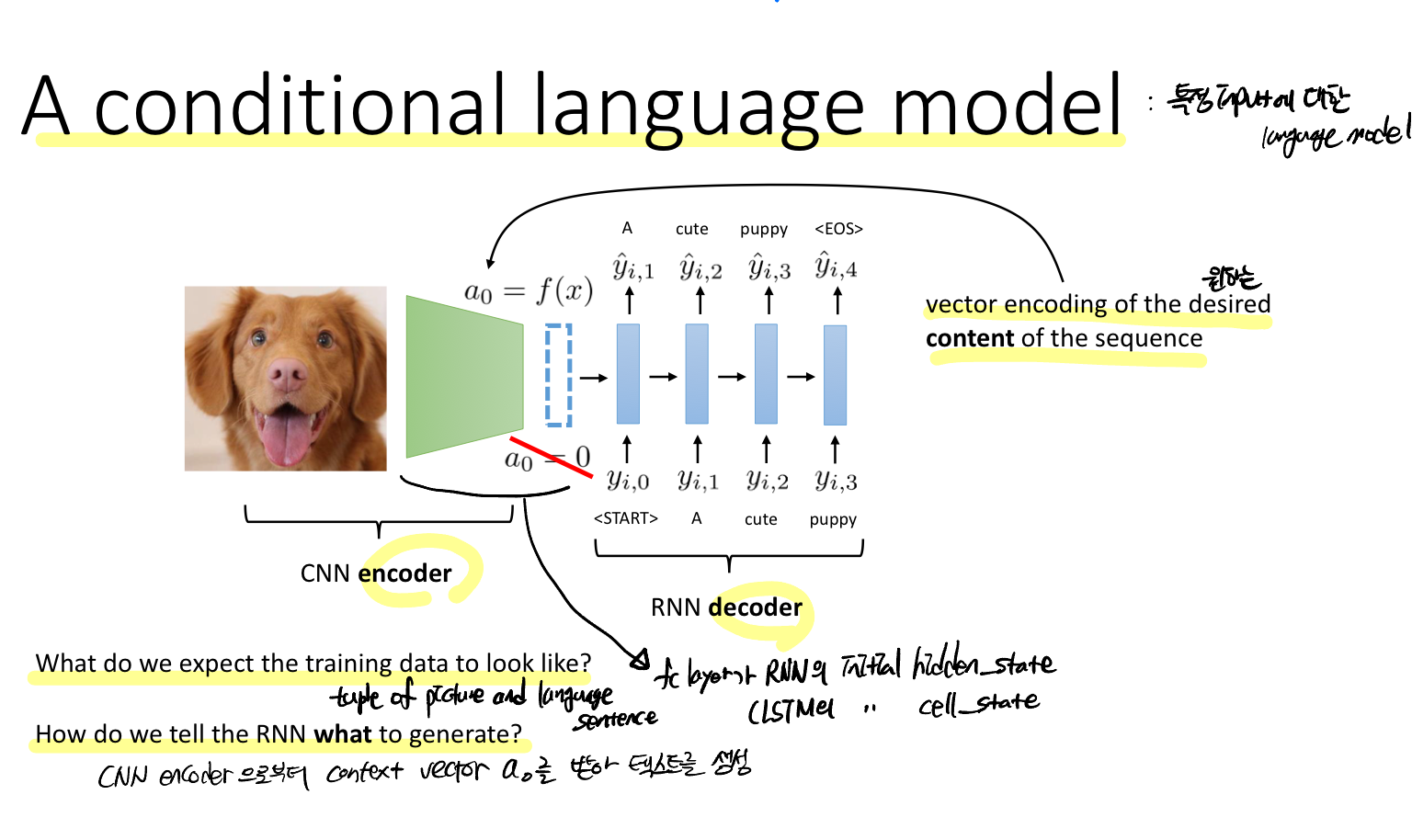
RNN 모델의 hidden_state의 초기값을 CNN 모델의 출력으로 주어진다면? 즉, CNN을 Encoder로 RNN을 Decoder로 쓰면 이미지를 텍스트로 표현할 수 있을 것이다.
Q. 학습 데이터는 어떤 형태일까? 학습 데이터는 이미지와 이미지를 설명하는 텍스트로 구성된 튜플 형태이다.
Q. RNN 모델이 무엇을 생성할지 어떻게 알려줄까? CNN Encoder로부터 학습된 context vector를 초기 hidden_state로 사용해 텍스트를 생성한다.
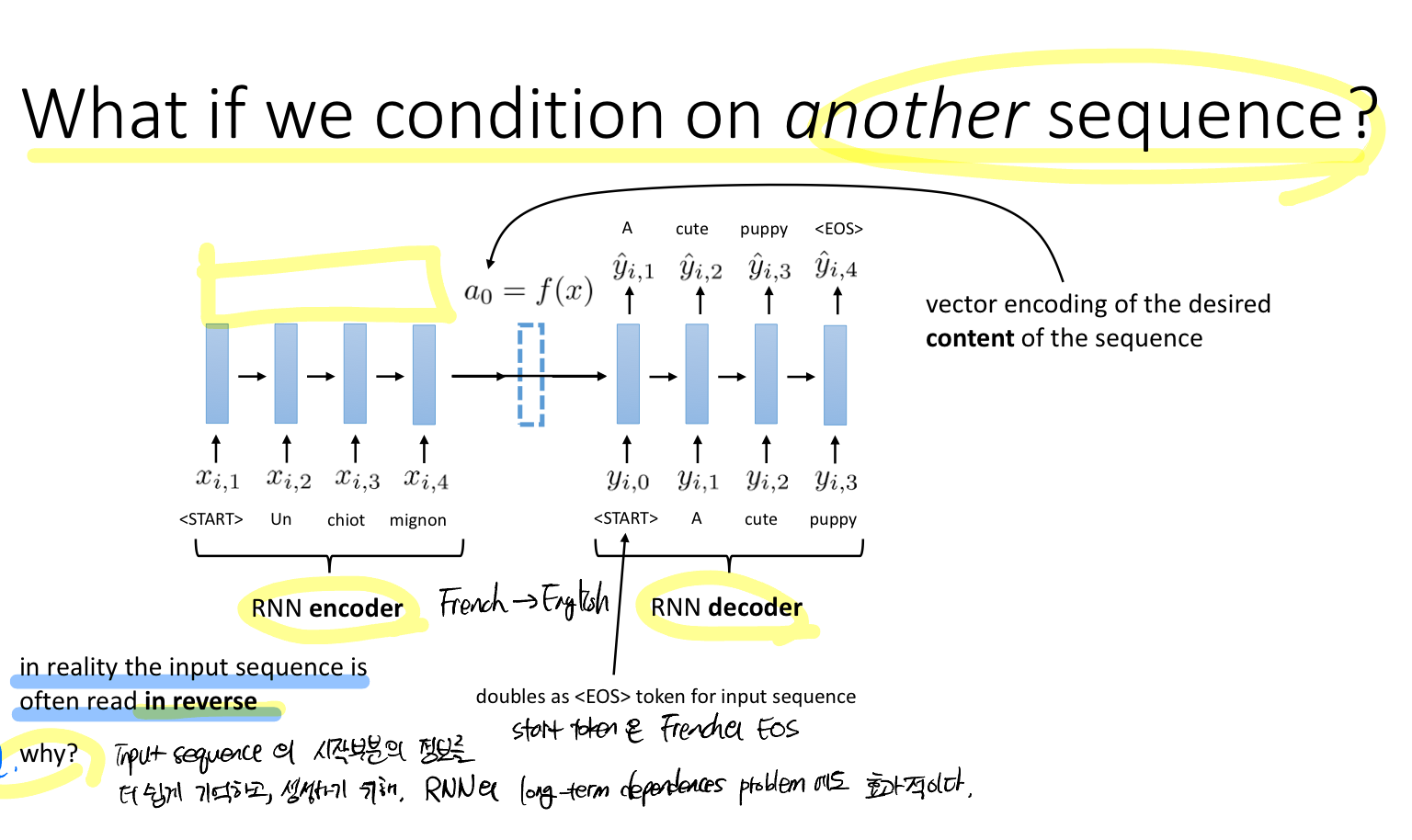
Q. 다른 시퀀스에 조건을 걸면 어떨까?
프랑스어를 영어로 번역하는 task를 생각해보자. 그럼 먼저 RNN 모델로 프랑스어에 대한 context vector를 뽑아내야 한다. 입력 시퀀스의 EOS 토큰은 출력 시퀀스의 START 토큰으로도 사용한다.
또한, 실제로는 입력 시퀀스를 종종 역순으로 사용하기도 한다고 한다. 이는 RNN 모델의 long-term dependences problem에 효과적이다.
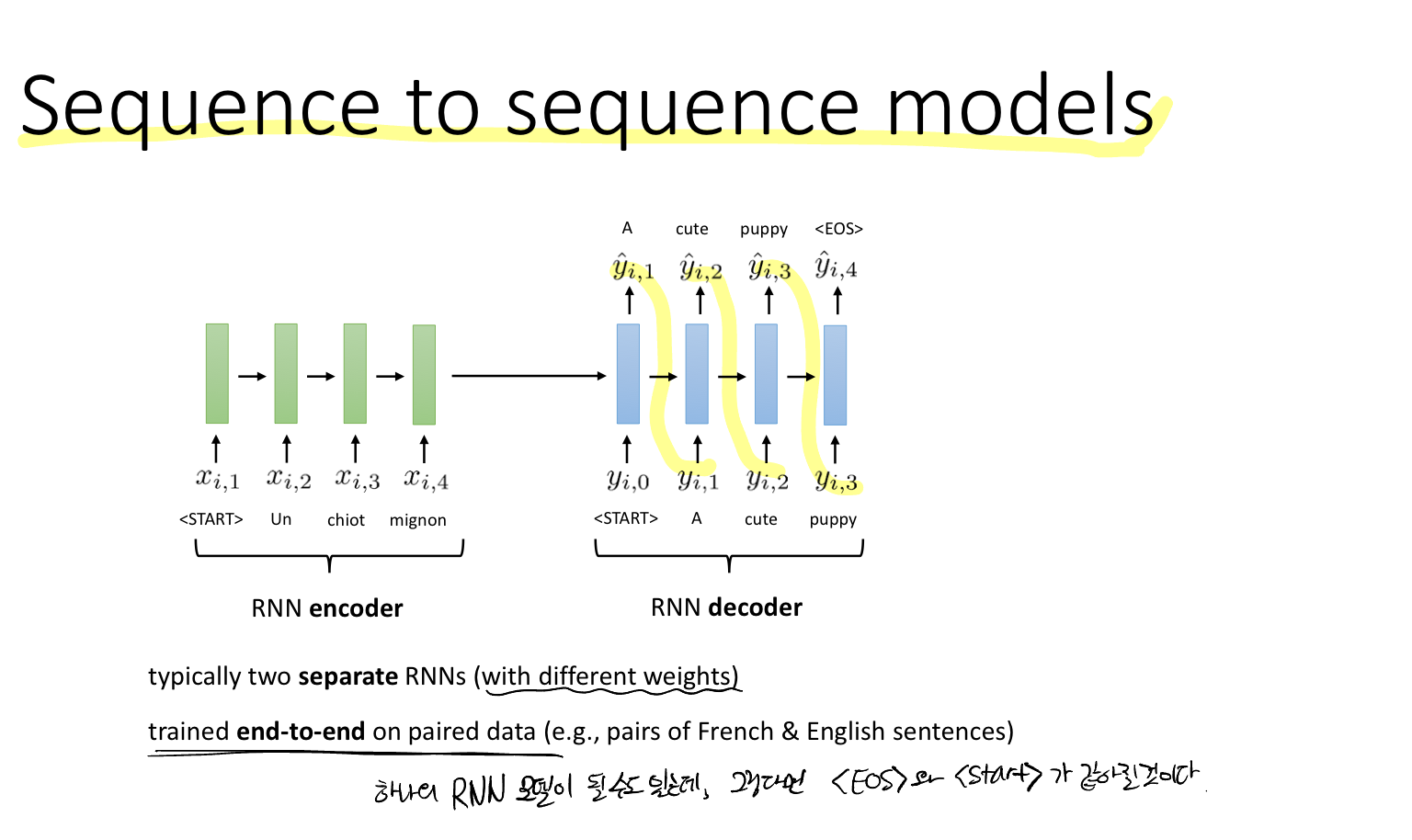
즉, 입력과 출력 시퀀스는 서로 다른 가중치를 사용하는 두 RNN 모델을 사용한다. 쌍을 이루는 데이터(예를 들어 프랑스어-영어)에 대해 엔트투엔드 학습한다.
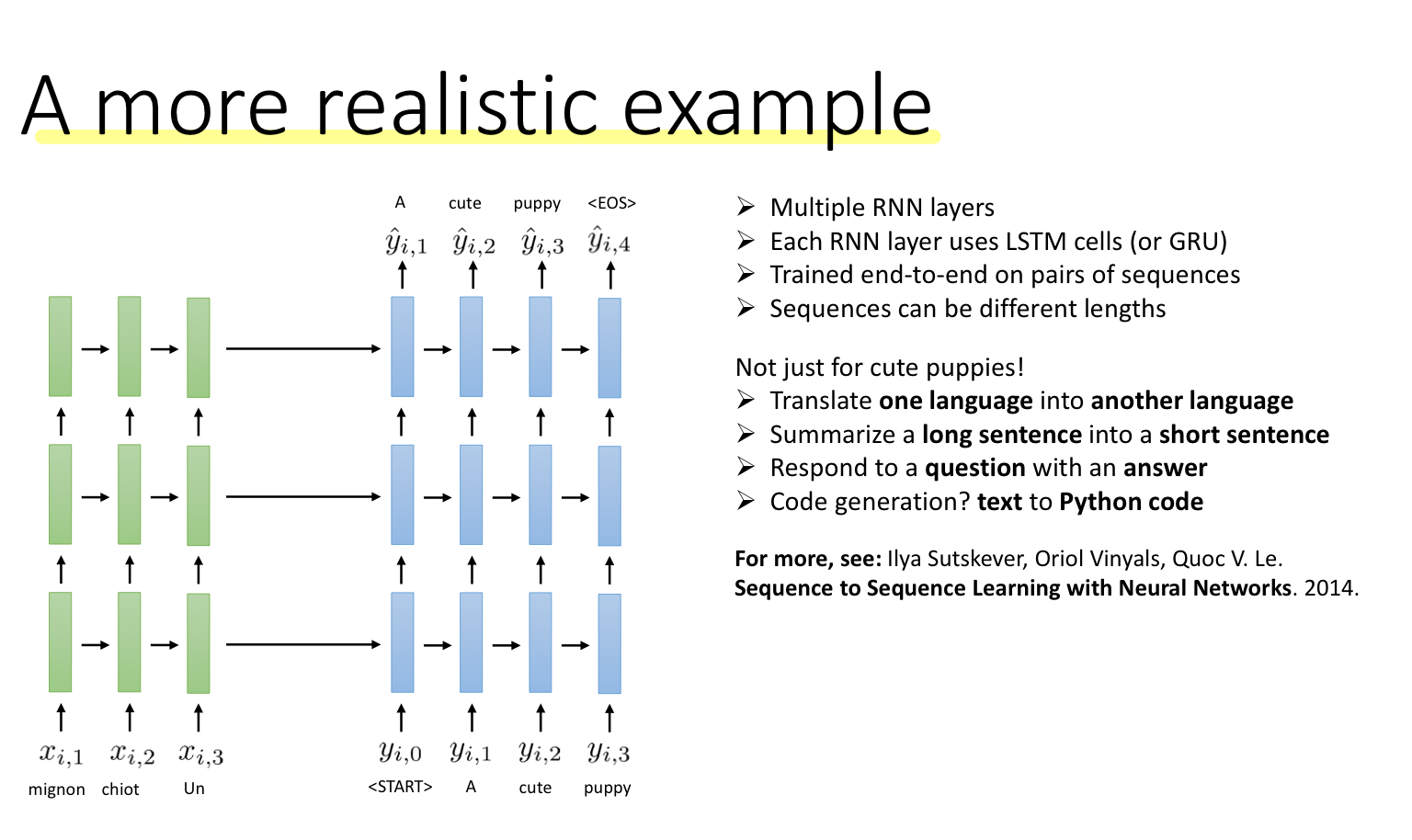
여러 RNN 계층을 쌓아 더 복잡한 특징과 표현을 학습할 수 있다. 각 레이어를 LSTM 혹은 GRU을 사용할 수 있다.
Decoding with beam search

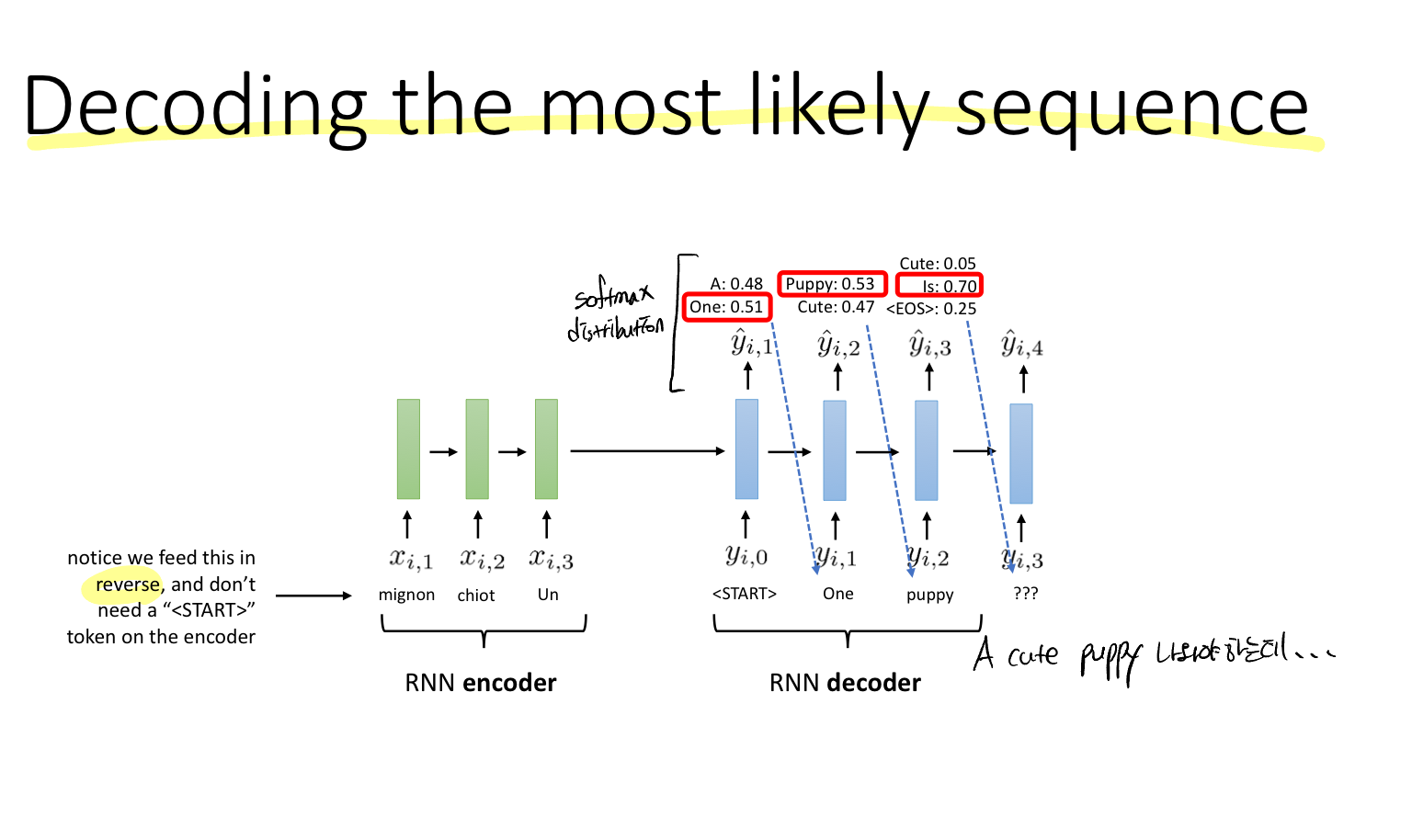
RNN encoder는 START 토큰이 필요하지 않다.
Q. 각 출력을 어떻게 표현할 수 있을까?
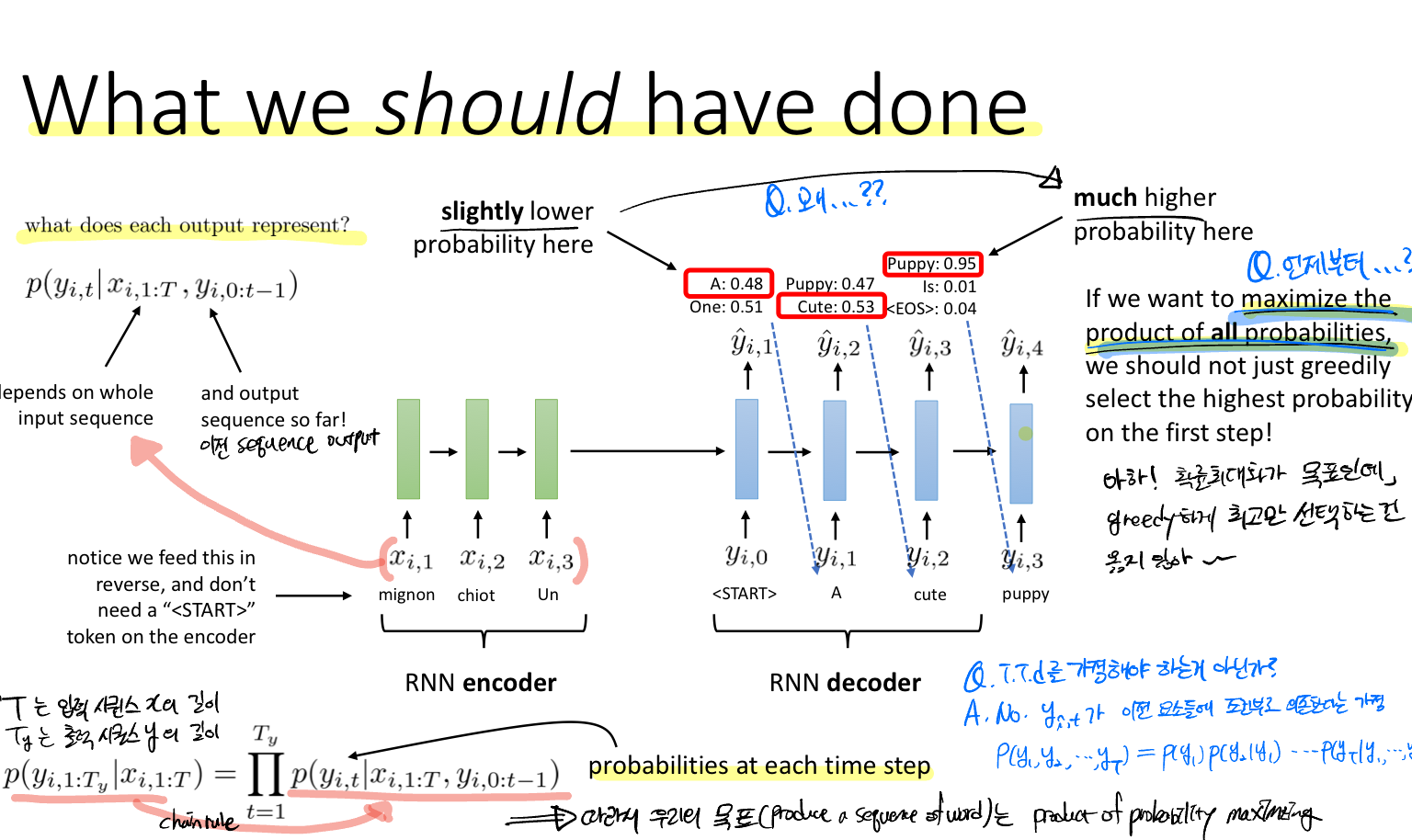
각 레이어의 출력은 조건부 확률에 의한 결과라고 볼 수 있는데, 하나는 모든 입력 시퀀스 또 다른 하나는 출력 시퀀스의 이전 레이어까지의 시퀀스이다.
결국 우리가 원하는 것은 높은 확률을 선택하는 것인데, 매 스텝(각 레이어)마다 최고의 확률을 선택하는 것(그리디한 선택)이 옳지 않다는 것이다. 이전 RNN에 대한 강의에서 이전 레이어의 출력이 다음 레이어의 입력으로 들어가는 것이 연속적인 데이터의 조건부 확률이라고 했었다. 따라서 우리의 목표함수는 하단에 나와있는 모든 확률의 곱이라고 볼 수 있다.
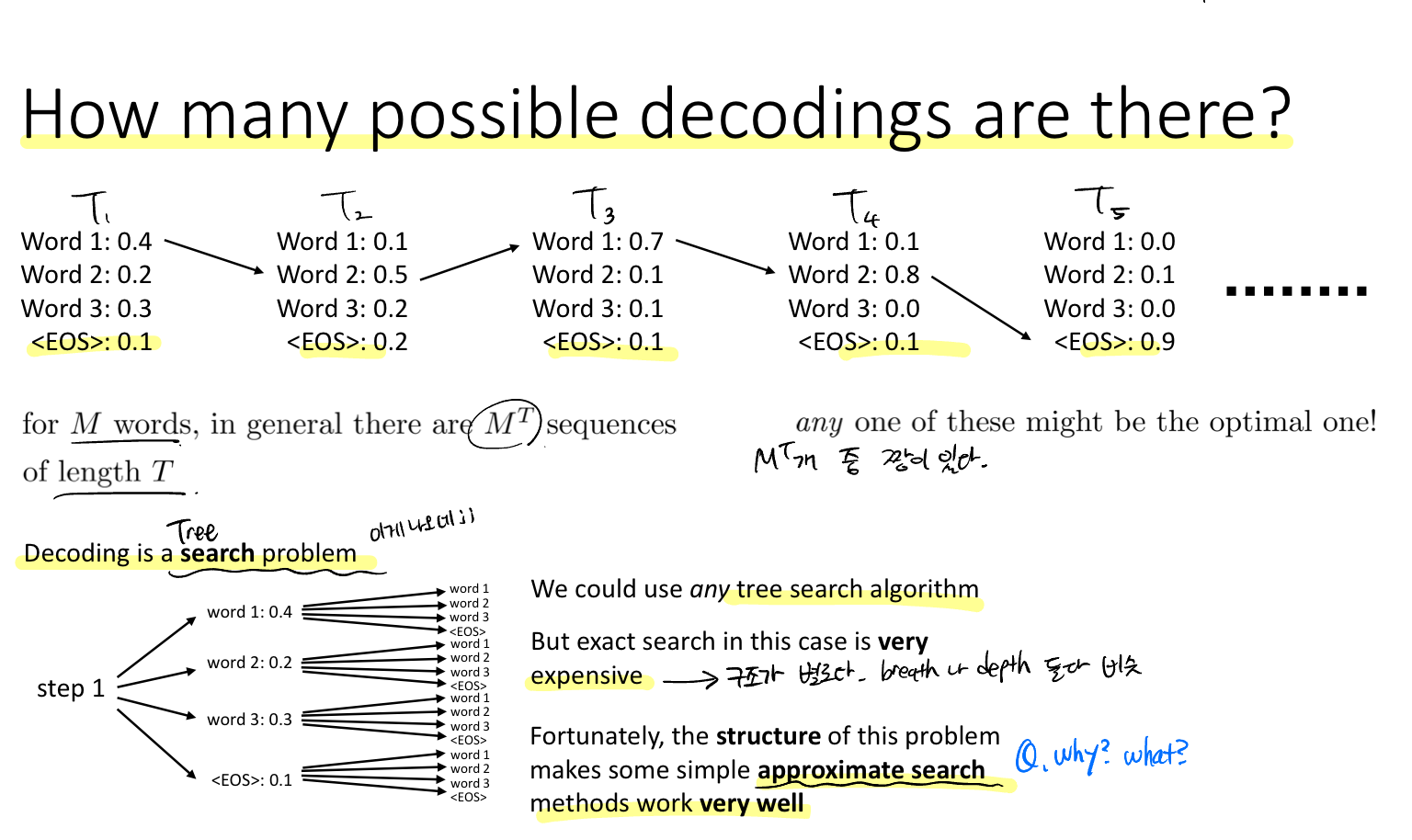
Q. 가능한 디코딩은 얼마나 많을까?
M개의 단어가 주어져 있고, 시퀀스의 길이가 T일 때 총 가능한 갯수는 M의 T승이 된다. 이 중에 가장 높은 확률을 갖는 선택을 해야한다.
이 문제를 Tree Search problem으로 볼 수 있다. 하지만 이 방법은 비효율적이다. 왜냐하면 BFS/DFS 방법 모두 효과적이지 않기 때문이다. 다행히도 구조상 간단한 몇 가지 접근 방식이 잘 작동한다고 한다.

첫 단어를 항상 높은 확률의 단어를 선택하는 것보다 낮은 확률의 단어를 선택하는 것이 결과적으로 좋은 결과를 나타낸다는 것이다. 즉, 그리디한 방법은 효과적이지 않지만 어느정도는 그리디를 사용할 수 있다는 것이다.
Solution: 매 스텝마다 K개의 best sequence를 저장해서 업데이트 하는 방법
K=1인 경우가 일반적인 그리디한 방법이다. 보통 K가 5~10 사이의 값을 사용한다.
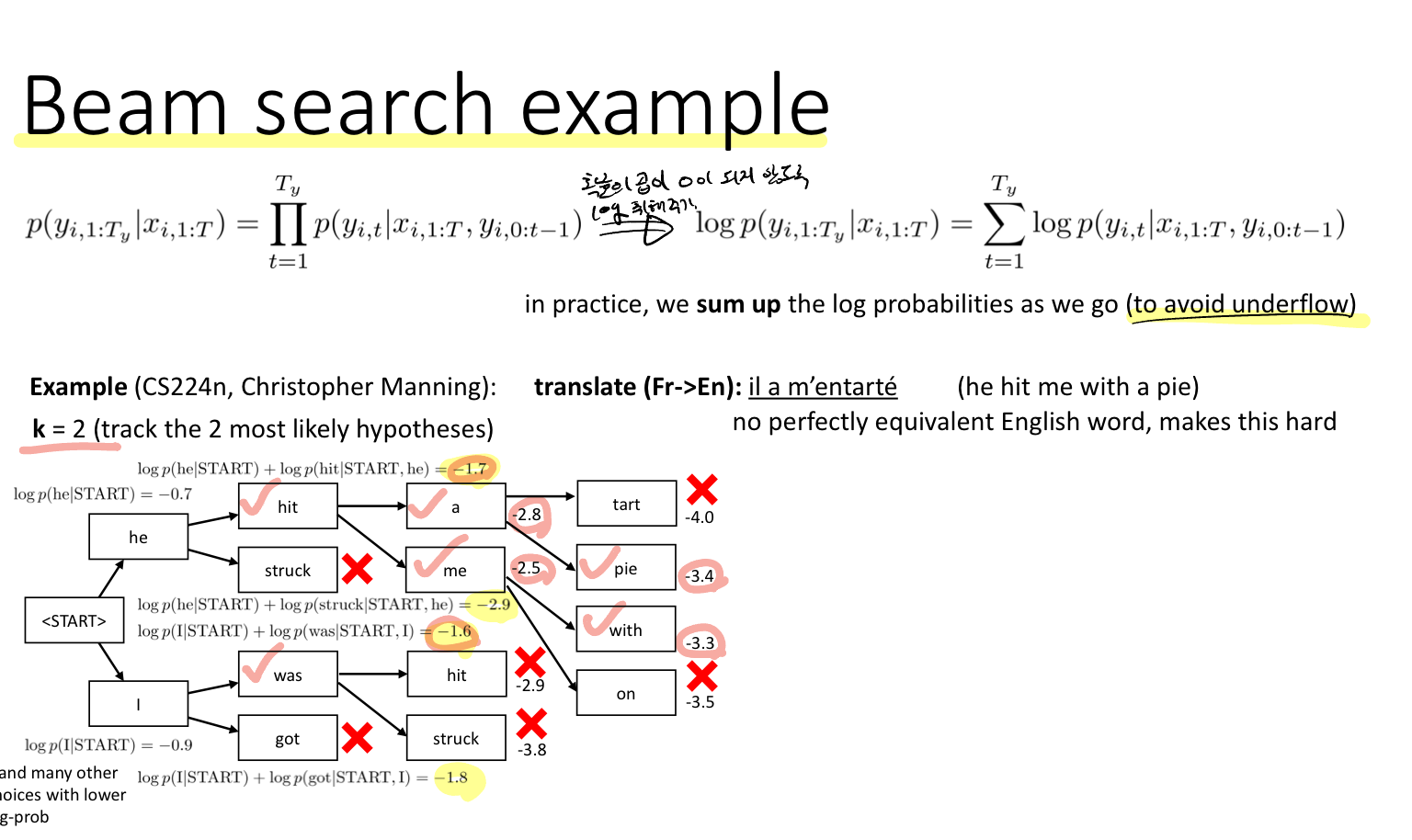
ML Basic에서 배웠듯이 확률의 곱은 0으로 수렴할 수 있기 때문에 log를 취해 표현한다. 이 방법을 이용해 프랑스어에서 영어로 번역하는 task에 대한 예시가 위에 주어져있다. 이때 K는 2로 두었다.

이 작업을 반복해서 Maximize the product of all probabilities 한다.
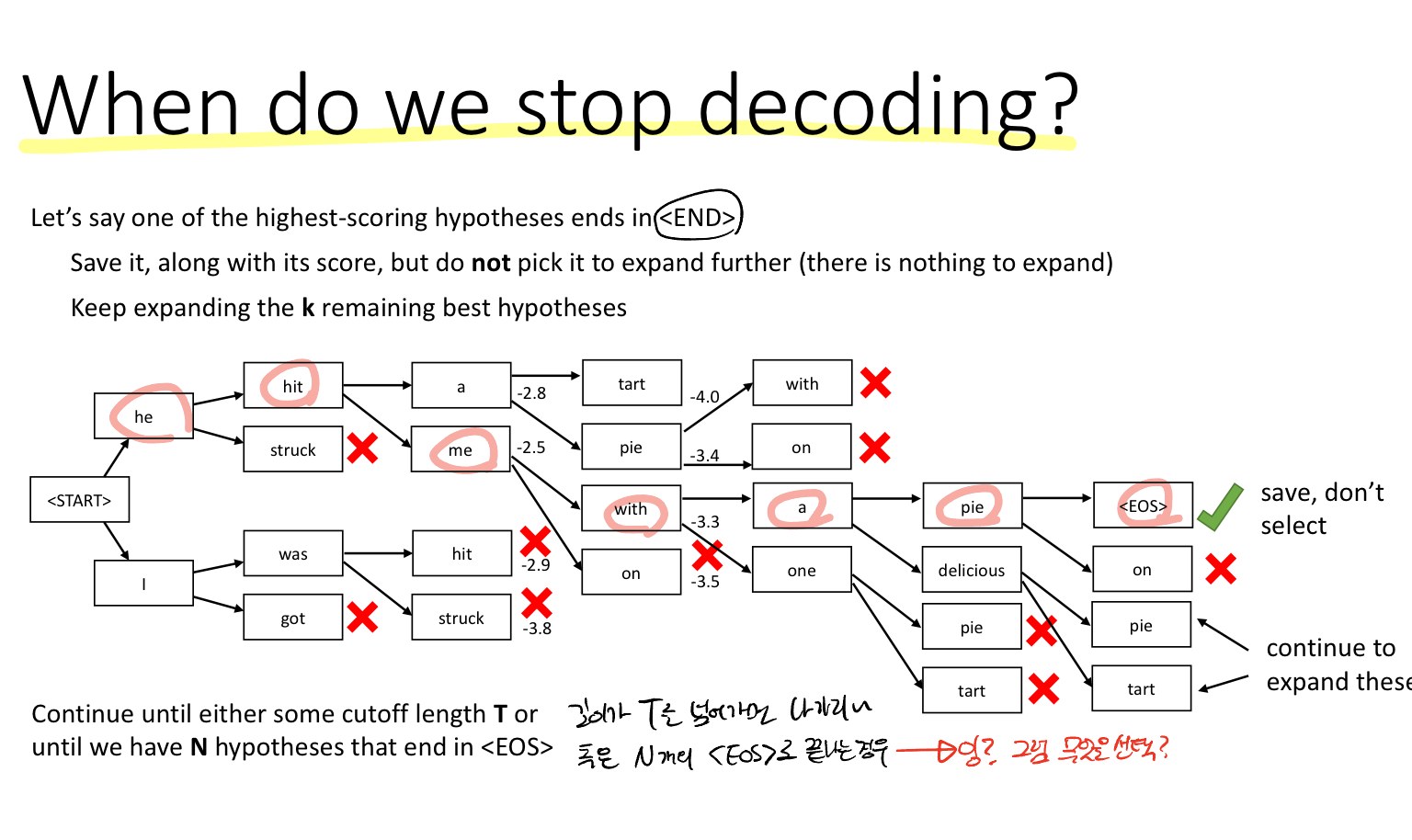
이 역시 EOS 토큰이 나오면 decoding을 멈춘다.

확률은 항상 1보다 작기 때문에 log(p)는 항상 0보다 작다. 따라서 시퀀스의 길이가 길어질수록 음수를 계속 더해가는 것이기 때문에 총 스코어는 작아진다. 이를 방지하기 위해 시퀀스의 길이로 나누어 준다.

최종적으로 요약하면 다음과 같다.
Attention


Problem: 입력 시퀀스의 길이가 아무리 길어도 고정된 크기의 context vector로 변환시켜 출력 시퀀스의 입력으로 주어야하기 때문에 context vector에 구속되는 문제가 있다
Solution: 디코딩할 때 입력 시퀀스를 peek 엿볼 수 있다면 어떨까?
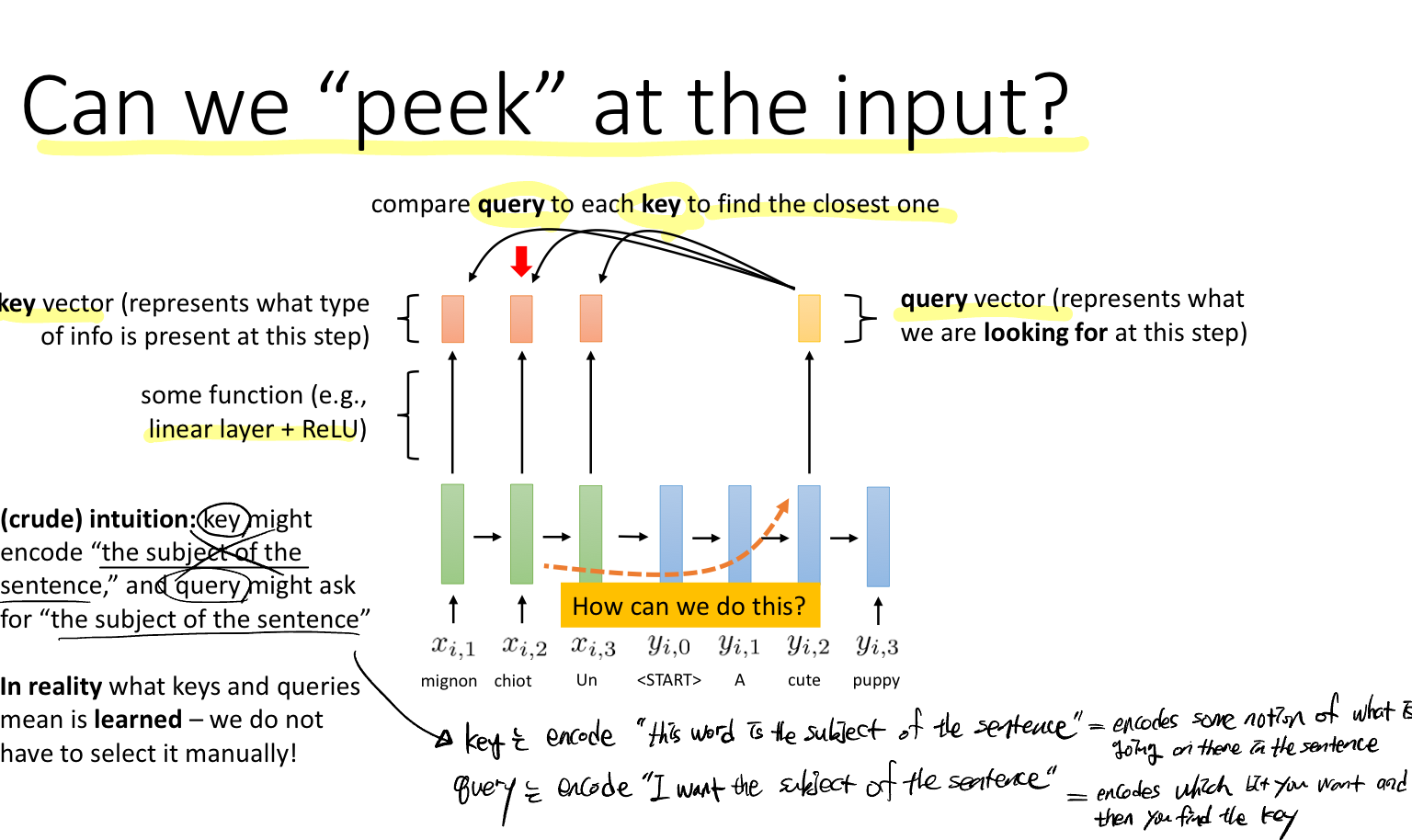
이때 Query와 Key라는 새로운 개념이 나온다. 쿼리는 출력 시퀀스에서 현재 단계에서 우리가 찾고자 하는 정보이고, 키는 입력 시퀀스의 각 단계의 정보 유형을 말한다.
예를 들어, "귀여운 강아지"라는 말을 프랑스어(mignon chilot Un)에서 영어(A cute puppy)로 바꿀 때, 귀엽다라는 의미의 cute가 프랑스어로 무엇인지 비교하여 그 정보에 집중하겠다는 것이다.
그럼 어떻게 비교해서 찾을 것인가? 이때 내적과 같은 유사성 측정값을 사용해서 수행한다. 그리고 직접 쿼리와 키를 선택하는 것이 아니라 학습 과정에서 이 또한 학습된다는 것이다.
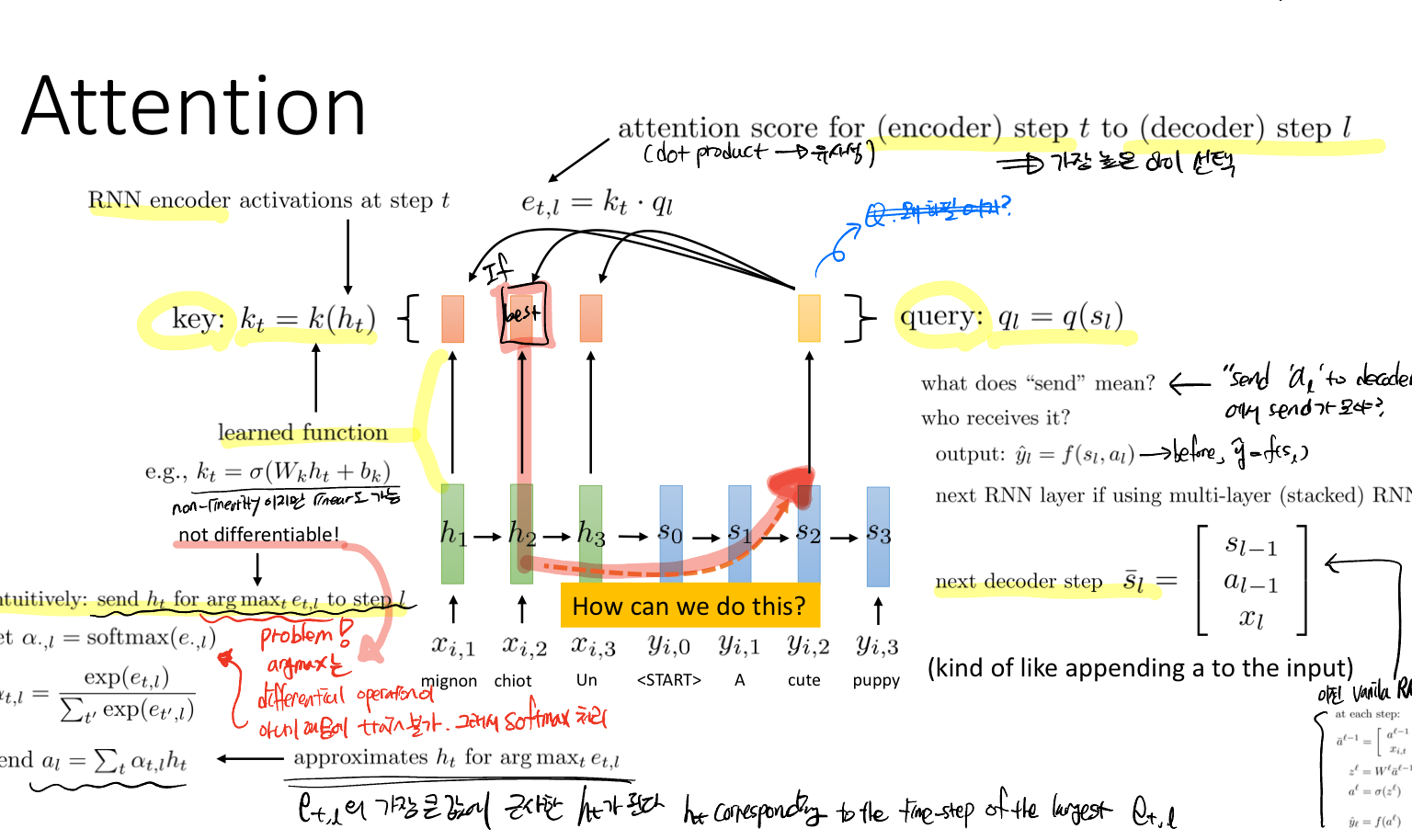
찾고자 하는 정보인 쿼리와 모든 입력 시퀀스의 레이어에서 나온 각각의 키와 내적 값인 attention score를 구한다. 이 결과를 softmax를 취해 attention weight를 구한다. 이 가중치 결과는 각 레이어의 활성화가 현재 디코더 레이어에 얼마나 기여하는 가를 나타낸다.
그리고 인코더 활성화의 가중치 합인 context vector는 디코더에서 관련된 입력 시퀀스의 정보를 통합하여 출력을 생성하는 데에 사용된다.

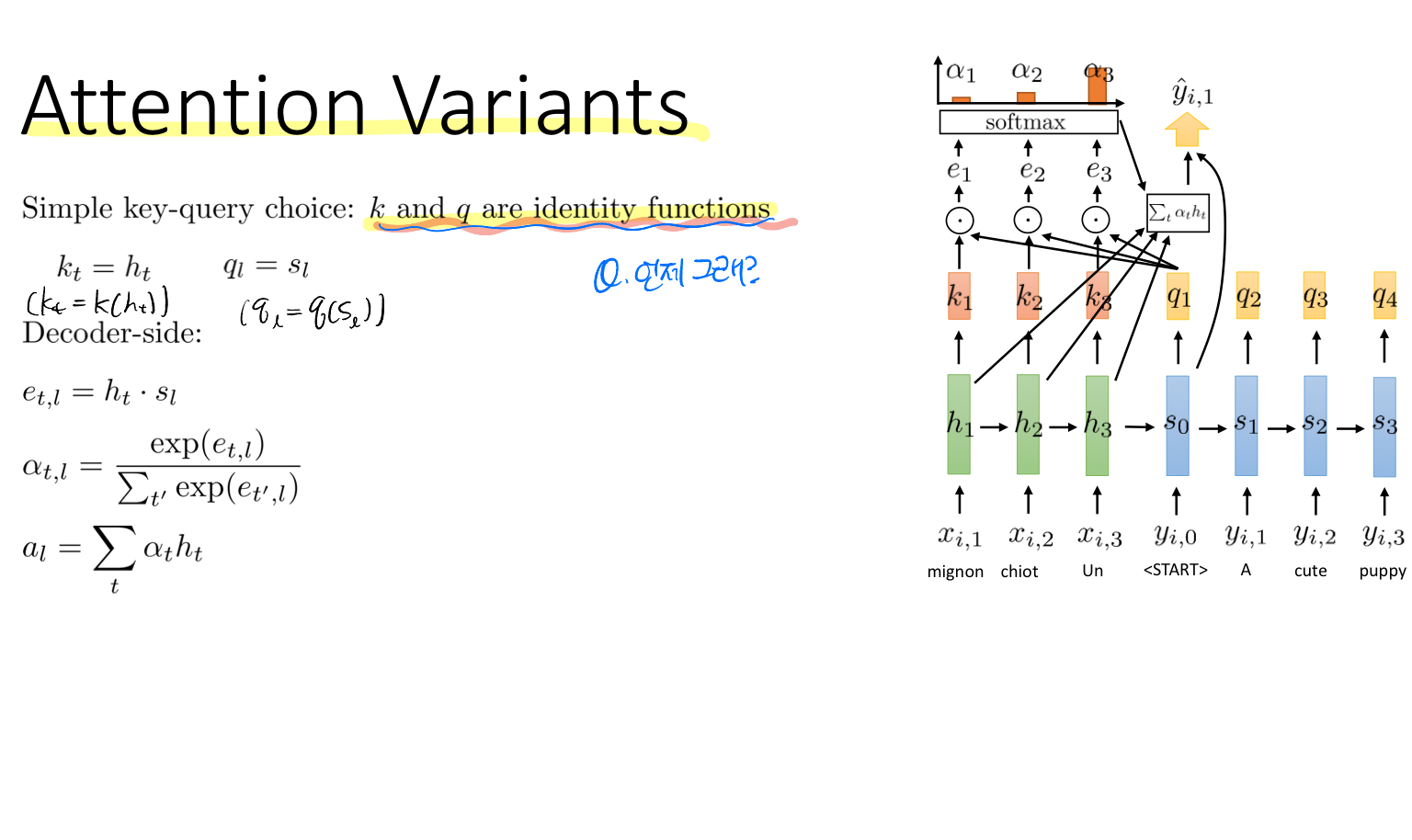
attention이 어떻게 동작하는 지 과정을 표현한 그림이다. 그리고 아래는 여러 케이스에 대한 이야기(키와 쿼리가 단위함수일 때, 키와 쿼리가 선형적일 때, learned value encoding일 때)를 나타내고 있다.

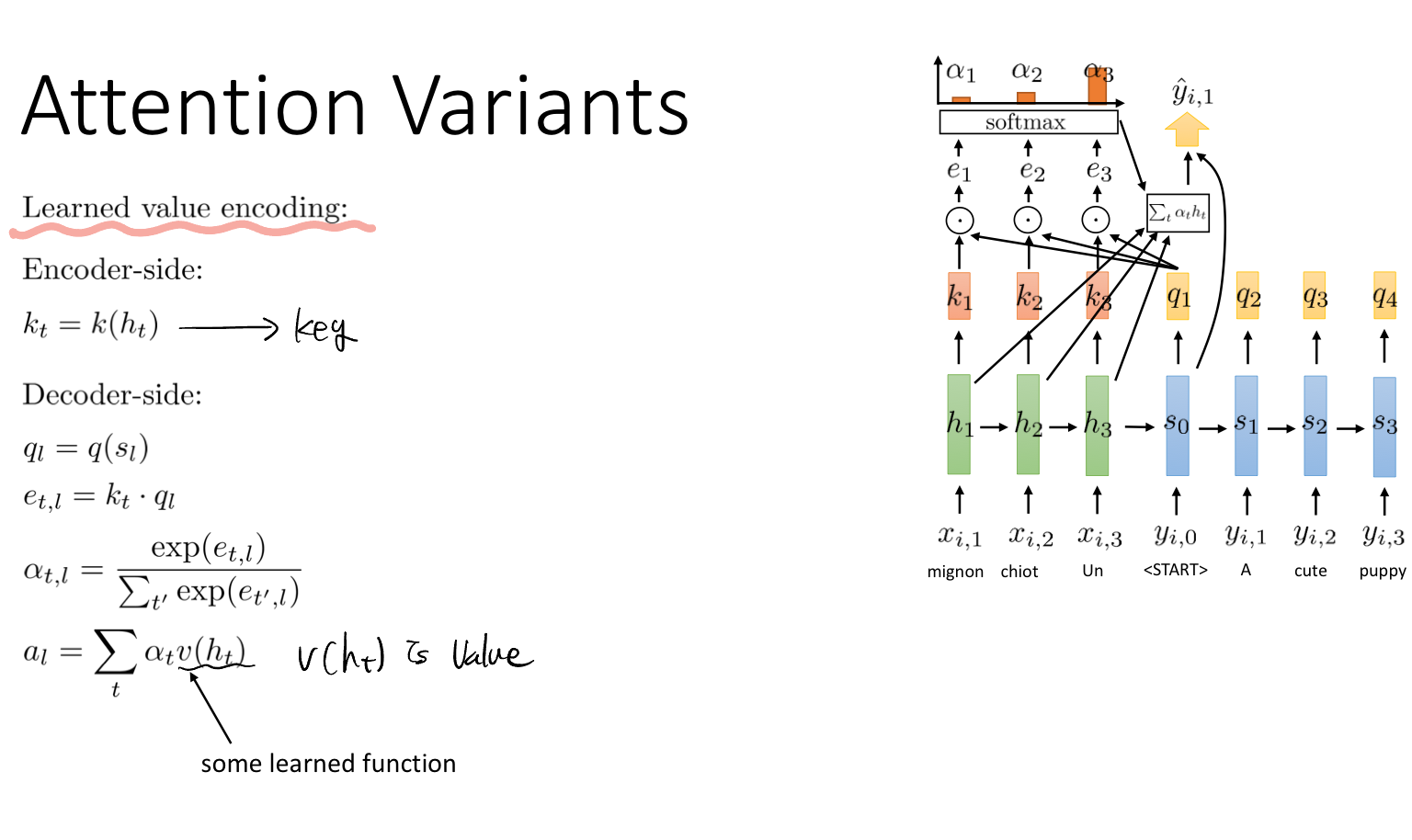

마지막으로 attention 연산이 효과적인 이유에 대한 내용이다. 어텐션의 디코더는 모든 인코더와 연결되어 있기 때문에 복잡성이 O(1)이 된다. 또한, 디코더와 인코더의 직접적인 연결 덕분에 gradient 정보를 잘 유지하고 학습할 수 있게 된다.
