Comment :
torch.utils.data.DataLoader에 대한 기초 개념 (데이터의 개수와 batch size)참고 : DataLoader 기초사용법 및 Custom Dataset 생성법 [+]
__len__, __getitem__, 즉 length를 뱉을 수 있어야되고, index를 주었을 때 해당 index에 맞는 데이터를 뱉을 수 있는...
참고 : DataLoader parameter 설명-1
참고 : DataLoader paraemter 설명-2
참고 : DataLoader Sampler 설명
참고 : torch.utils.data.Sampler documentation
참고 : PyTorch - Dataset 정리 [+]custom dataset 만드는 방법-확장편(?)
![]()
DataLoader
torch.utils.data.DataLoader: 학습에 사용될 전체 데이터를 가지고 있다가, iter개념으로 데이터를 뱉어준다.
00. Settings
import torch
from torch.utils.data import DataLoader
from torch.utils.data.sampler import SubsetRandomSampler
# [+]
import torchvision
from torchvision import datasets
from torchvision import transformsex) DataLoader에 사용할 MNIST 데이터 불러오기 및 Transform 정의
# Define 'transformation'
transform = transforms.Compose( [
# transforms.Resize( (28, 28) ),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
# transforms.Normalize( (0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
)
# Data Download
train_set = datasets.CIFAR10('./LHK_data',
train=True,
download=True,
transform=transform )
test_set = datasets.CIFAR10('./LHK_data',
train=False,
download=True,
transform=transform )[!] transforms를 통해서 Tensor로 바꿔주지 않으면 DataLoader iter로 부를때 이상해짐
[!] transform 변수에 저렇게 transforms.Compose를 통해서 이미지(?)를 어떻게 변형시킬 것인지를 순차적으로 한꺼번에 적어준다.
[!] torchvision.datasets를 통해서 먼저 데이터(여기서는 CIFAR10 데이터)를 받아주는것도 잊지말자!
[!] train_set, test_set 둘다 받아보긴했으나 여기서는 DataLoader에 대해 정리하는것이므로 train_set만 사용할 예정임!
01. DataLoader 생성
data_loader = DataLoader(train_set,
batch_size = 64
shuffle=True
)[!] torch.utils.data.DataLoader를 통해서 DataLoader (data_loader)를 만들어준다.
02. DataLoader의 개수, 단위
print(len(data_loader.dataset))
print(len(data_loader))
>>>
50000
782[+] len(data_loader.dataset) = 실제 (전체) 데이터의 개수
[+] len(data_loader) = 실제 (전체) 데이터의 개수 / batch_size
- ex) 내가 가진 데이터셋의 데이터개수가 50,000장이고 batch_size를 64로 설정했을때
len(data_loader)의 반환값은? 50000 / 64 = 781.25 782
"뭐 약간 batch size만큼의 batch (단위) data를 782번 정도 줄게"* 이런느낌?
data, target = next(iter(data_loader))
print(data.shape)
print(target.shape)
>>>
torch.Size([64, 3, 32, 32])
torch.Size([64])[!] DataLoader는 iterator개념이므로 next(iter(data_loader))를 통해서 첫번째(?) return값을 data와 target에 받아서 확인해봄
[+] 현재 CIFAR-10 데이터셋의 이미지는 32 x 32 x 3 사이즈이다. 즉 32 pixels x 32 pixels x 3 depth(RGB) 사이즈
[+] 또한 batch size는 64로 해놨다.
data에는 [64 x 3 x 32 x 32]사이즈의 Tensor
즉, [Batch size x Depth x Width x Height] = [Batch size x Image size] 사이즈의 Tensor
target에는 [64] 사이즈의 Tensor
즉, [Batch size] 만큼의 label값
(CIFAR-10 데이터셋은 10개의 클라스를 가진 데이터이므로 0~9 값이 64개가 있을것이다)
03. DataLoader Argument들
DataLoader(dataset,
batch_size = 1,
shuffle = False,
sampler = None,
batch_sampler = None,
num_workers = 0,
collate_fn = None,
pin_memory = False,
drop_last = False,
timeour = 0,
worker_init_fn = None,
prefetch_factor = 2,
persistent_workers = False
)어우... 너무 많다. 지금 당장 모든 Arguement들을 다 알 필요는 없으므로 중요한 순으로 정리해보자
3-1. Dataset
Dataset Types
The most important argument of DataLoader constructor is dataset, which indicates a dataset object to load data from. PyTorch supports two different types of datasets:
DataLoader에서 가장 중요한 argument, 데이터를 불러올 데이터셋 object
In PyTorch, 두 종류의 데이터셋이 있음
- map-style datasets
- iterable-style datasets
Map-style datasets
[+] non-integral : 정수가 아닌
A map-style dataset is one that implements the __getitem__() and __len__() protocols, and represents a map from (possibly non-integral) indices/keys to data samples.
__getitem__(), __len__() 선언 필요
For example, such a dataset, when accessed with dataset[idx], could read the idx-th image and its corresponding label from a folder on the disk.
Map-style datasets는 datasets[index]로 접근 시 해당 인덱스의 이미지와 라벨에 접근한다.
인덱스가 존재하는 데이터셋
Iterable-style datasets
An iterable-style dataset is an instance of a subclass of IterableDataset that implements the __iter__() protocol, and represents an iterable over data samples. This type of datasets is particularly suitable for cases where random reads are expensive or even improbable, and where the batch size depends on the fetched data.
랜덤으로 읽기가 어렵고, data에 따라 batch size가 달라지는 데이터(?)에 적합
__iter__() 선언 필요
For example, such a dataset, when called iter(dataset), could return a stream of data reading from a database, a remote server, or even logs generated in real time.
Stream data, real-time log에 적합
3-1-1. Custom Dataset 만들기
class CustomDataset(Dataset):
def __init__(self, image_folder_path, transform=None):
"""
Args:
(생략) : JSON, csv등 라벨링, 어노테이션 등 추가정보를 담고있는...
image_folder_path : 모든 이미지가 존재하는 디렉토리 경로
transform : 샘플에 적용될 Optional transform
"""
self.image_folder_path = image_folder_path
self.transform = transform
def __len__(self):
return len(os.listdir(self.image_folder_path)) # 이미지폴더 리스트화 -> len -> 총 data개수
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_name = os.path.join(self.image_folder_path,
os.listdir(self.image_folder_path)[idx])
#image = np.array(Image.open(img_name)) # NumPy array return용
image = Image.open(img_name).convert('RGB') # PIL image return용
if self.transform:
image = self.transform(image)
return image [!] 간단하게 index를 주면 해당 index에 맞는 이미지 데이터를 반환하는 기능을 가진 클래스, (라벨링 없음)
3-2. Batch_size
batch의 크기.
반복문을 통한 __iter__().__next__()를 돌리면
[Batch size x Data shape] 의 사이즈로 Tensor return함.
Tensor로 변환이 안되는 데이터는 에러가남
3-3. Shuffle
데이터를 DataLoader에서 섞어서 사용하겠는지에 대한 여부를 설정 가능 (bool 값)
3-4. Sampler
index를 컨트롤하는 방법.
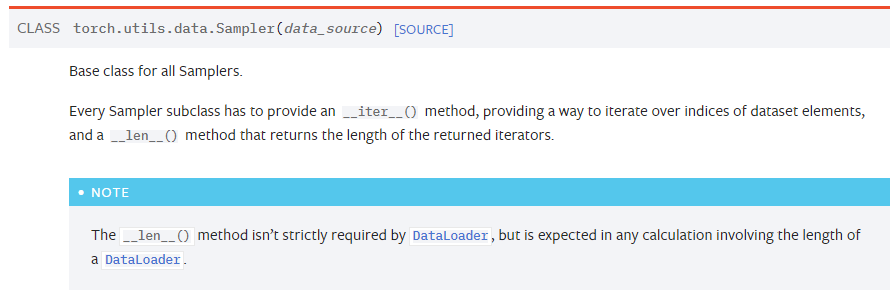
[!] shuffle 파라미터는 False여야함 섞지않고 직접 인덱스를 컨트롤, 즉 섞든 말든 해야하므로
[!] torch.utils.data.Sampler object를 사용해야함, 아래 는 Sampler list임
-
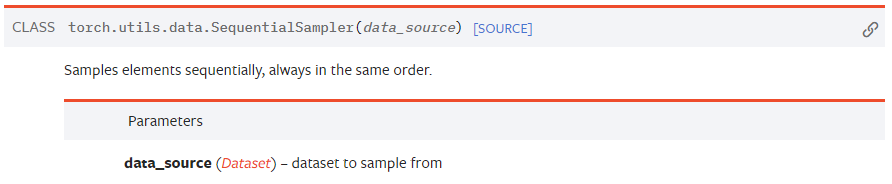
SequentialSampler: 주어진 데이터셋에서 그냥 순서대로 뽑겠다 Samples
-
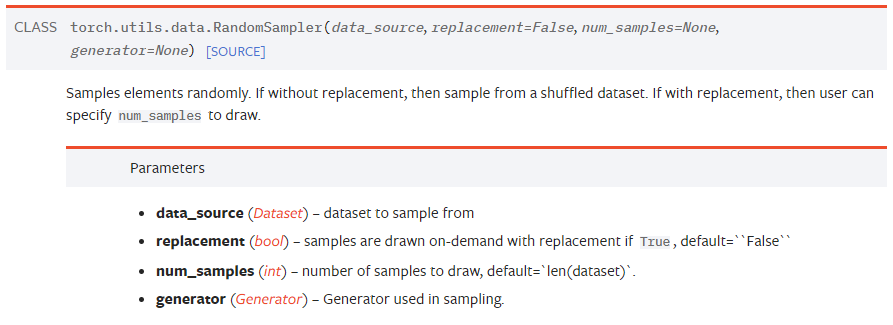
RandomSampler: 주어진 데이터셋에서 랜덤하게 뽑겠다 [+] replacement,즉 복원도 가능
-
SubsetRandomSampler: 주어진 리스트 내의 인덱스값으로만 (주어진 데이터셋에서) 랜덤하게 뽑겠다. [+] Subset : 부분집합
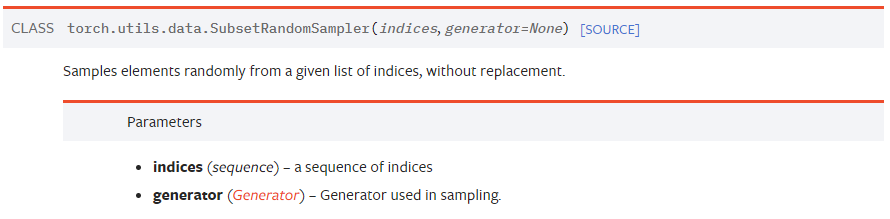
ex) SubsetRandomSampler 사용법, 즉 RandomSampler를 쓰고싶은데 Train / Valid셋을 나누려고 SubsetRandomSampler를 사용하는거임!(이거때문에 이 글 작성한거임)# train_set : torchvision.datasets에서 가져온 Training 데이터셋 num_train = len(train_set) # 50,000 indices = list( range(num_train) ) # 0부터 50,000까지의 숫자가 순서대로 나열된 리스트 np.random.shuffle(indices) # 0부터 50,000까지의 숫자가 순서없이 뒤섞인 리스트가 됨 split = int( np.floor( 0.2 * num_train ) # 10,000 train_idx, valid_idx = indices[split:], indices[:split] train_sampler = SubsetRandomSampler(train_idx) valid_sampler = SubsetRandomSampler(valid_idx) train_loader = torch.utils.data.DataLoader(train_data, ... , sampler=train_sampler) valid_loader = torch.utils.data.DataLoader(train_data, ... , sampler=valid_sampler) -
WeightRandomSampler
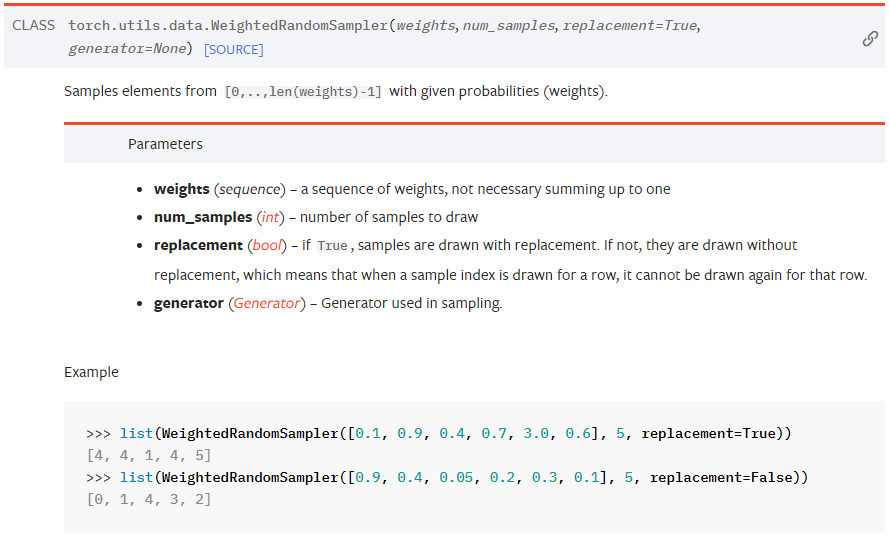
-
BatchSampler
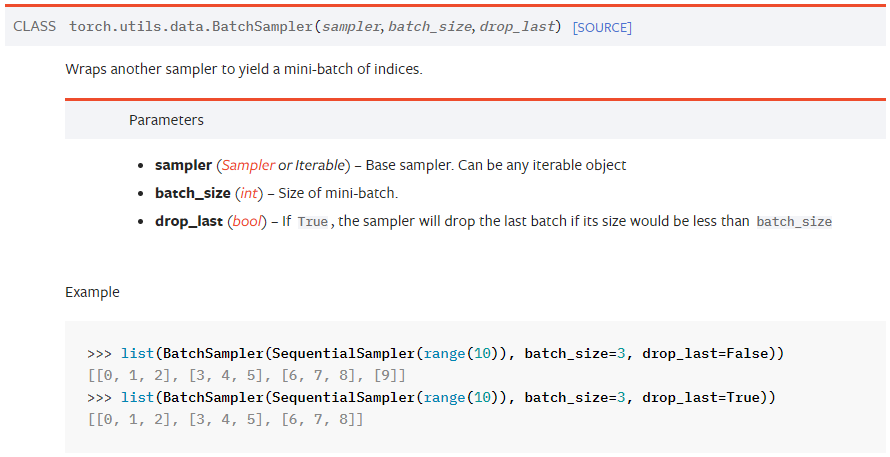
-
DistributedSampler
