1. 데이터 읽기
import pandas as pd
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
feature_name = feature_name_df.iloc[:, 1].values.tolist()
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
X_train.columns = feature_name
X_test.columns = feature_name
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])
X_train.shape, X_test.shape, y_train.shape, y_test.shape2. PCA 함수 만들기
from sklearn.decomposition import PCA
def get_pca_data(ss_data, n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
return pca.transform(ss_data), pca3. PCA fit
HAR_pca, pca = get_pca_data(X_train, n_components=2)
print(HAR_pca.shape) # (7352, 2)
print(pca.mean_.shape, pca.components_.shape) # (561,) (2, 561)4. PCA 결과 저장 함수
cols = ['pca_' + str(n) for n in range(pca.components_.shape[0])]
def get_pd_from_pca(pca_data, cols_num):
cols = ['pca_' + str(n) for n in range(cols_num)]
return pd.DataFrame(pca_data, columns=cols)
HAR_pd_pca = get_pd_from_pca(HAR_pca, pca.components_.shape[0])
HAR_pd_pca['action'] = y_train5. 그래프로 모양 확인
import seaborn as sns
sns.pairplot(HAR_pd_pca, hue='action', height=5,
x_vars=['pca_0'], y_vars=['pca_1'])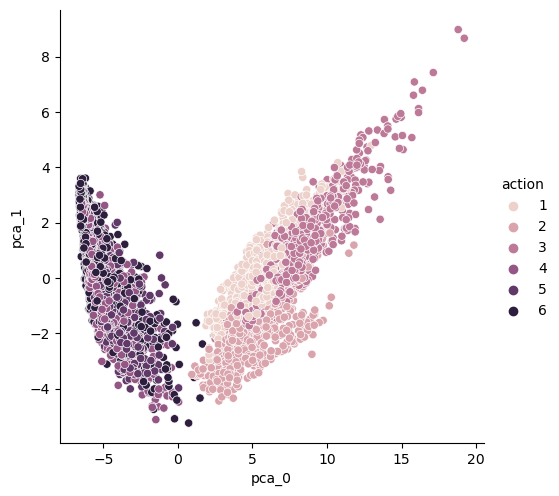
6. explainedvariance_ratio 출력함수
- 500개 특성을 두 개로 줄인 결과
- 3개 sum of variance_ratio: 0.7158893015785952 → 10개 sum of variance_ratio: 0.8050386904374958(상승한다)
import numpy as np
def print_variance_ratio_(pca):
print('variance_ratio: ', pca.explained_variance_ratio_)
print('sum of variance_ratio: ', np.sum(pca.explained_variance_ratio_))
print_variance_ratio_(pca)
'''
variance_ratio: [0.6255444 0.04913023]
sum of variance_ratio: 0.6746746270487921
'''7. RandomForest 시간 비교
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth': [6,8,10],
'n_estimators':[50,100,200],
'min_samples_leaf':[8,12],
'min_samples_split':[8,12]
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, params, cv=2, n_jobs=-1)
grid_cv.fit(HAR_pca, y_train.values.reshape(-1, ))
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score').head()
8. 베스트 파라미터에 테스트
- 주의: 여기서 561개 특성이 그대로인 X_test를 pca.transform 시킨다.
학습을 완료시키고 넣어야 데이터가 오염되지 않는다!
from sklearn.metrics import accuracy_score
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(HAR_pca, y_train.values.reshape(-1, ))
pred1 = rf_clf_best.predict(pca.transform(X_test))
accuracy_score(y_test, pred1) # 0.85307091957923319. xgboost
- 오류 발생:
Invalid classes inferred from unique values of "y". Expected: [0 1 2 ... 1387 1388 1389], got [0 1 2 ... 18609 24127 41850] - xgboost downgrade :
pip install xgboost==0.9.0 - 시간이 많이 줄어든다!
import time
from xgboost import XGBClassifier
evals = [(pca.transform(X_test), y_test)]
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(HAR_pca, y_train.values.reshape(-1, ), early_stopping_rounds=10, eval_set=evals)
print('Fit time: ', time.time() - start_time) # Fit time: 4.43171501159668
from sklearn.metrics import accuracy_score
accuracy_score(y_test, xgb.predict(pca.transform(X_test))) # 0.8571428571428571Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it